第4章 LlamaIndex知识管理与信息检索
💡 学习目标
- 掌握 LlamaIndex 的特点和基本用法
- 掌握 LlamaIndex 内置的工具
- 如何用好 SDK 简化基于 LLM 的应用开发
1. 大语言模型开发框架的价值是什么?
SDK:Software Development Kit,它是一组软件工具和资源的集合,旨在帮助开发者创建、测试、部署和维护应用程序或软件。
所有开发框架(SDK)的核心价值,都是降低开发、维护成本。
大语言模型开发框架的价值,是让开发者可以更方便地开发基于大语言模型的应用。主要提供两类帮助:
- 第三方能力抽象。比如 LLM、向量数据库、搜索接口等
- 常用工具、方案封装
- 底层实现封装。比如流式接口、超时重连、异步与并行等
好的开发框架,需要具备以下特点:
- 可靠性、鲁棒性高
- 可维护性高
- 可扩展性高
- 学习成本低
举些通俗的例子:
- 与外部功能解依赖
- 比如可以随意更换 LLM 而不用大量重构代码
- 更换三方工具也同理
- 经常变的部分要在外部维护而不是放在代码里
- 比如 Prompt 模板
- 各种环境下都适用
- 比如线程安全
- 方便调试和测试
- 至少要能感觉到用了比不用方便吧
- 合法的输入不会引发框架内部的报错
划重点:选对了框架,事半功倍;反之,事倍功半。
什么是 SDK? https://aws.amazon.com/cn/what-is/sdk/
SDK 和 API 的区别是什么? https://aws.amazon.com/cn/compare/the-difference-between-sdk-and-api/
🌰 举个例子:使用 SDK,4 行代码实现一个简易的 RAG 系统
LlamaIndex 默认的 Embedding 模型是 OpenAIEmbedding(model="text-embedding-ada-002")
# !pip install --upgrade llama-index
# !pip install llama-index-llms-dashscope
# !pip install llama-index-llms-openai-like
# !pip install llama-index-embeddings-dashscope
import os
os.environ['DASHSCOPE_API_KEY'] = 'sk-26016f12cd454ba99c5e1bf1e4ca0e3f'
import os
from llama_index.core import Settings
from llama_index.llms.dashscope import DashScope, DashScopeGenerationModels
# 1. 先查看DashScope支持哪些模型
print("可用模型:")
for model in dir(DashScopeGenerationModels):
if not model.startswith("_"):
print(f"- {model}: {getattr(DashScopeGenerationModels, model)}")
# 2. 设置模型
# 根据输出选择正确的模型名称
Settings.llm = DashScope(
model_name="qwen-plus", # 或者可能是 "qwen2.5-plus"、"qwen2.5-32b" 等
api_key=os.getenv("DASHSCOPE_API_KEY")
)
import os
from llama_index.core import Settings
from llama_index.llms.openai_like import OpenAILike
from llama_index.llms.dashscope import DashScope, DashScopeGenerationModels
from llama_index.embeddings.dashscope import DashScopeEmbedding, DashScopeTextEmbeddingModels
# LlamaIndex默认使用的大模型被替换为百炼
Settings.llm = OpenAILike(
model="qwen-max",
api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
is_chat_model=True
)
# Settings.llm = DashScope(model_name=DashScopeGenerationModels.QWEN_MAX, api_key=os.getenv("DASHSCOPE_API_KEY"))
# LlamaIndex默认使用的Embedding模型被替换为百炼的Embedding模型
# Settings.embed_model = DashScopeEmbedding(
# model_name="text-embedding-v1"
# model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V1,
# api_key=os.getenv("DASHSCOPE_API_KEY")
# )
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("deepseek v3有多少参数?")
print(response)2. LlamaIndex 介绍
官网标题:「 Build AI Knowledge Assistants over your enterprise data 」
LlamaIndex 是一个为开发「知识增强」的大语言模型应用的框架(也就是 SDK)。知识增强,泛指任何在私有或特定领域数据基础上应用大语言模型的情况。例如:
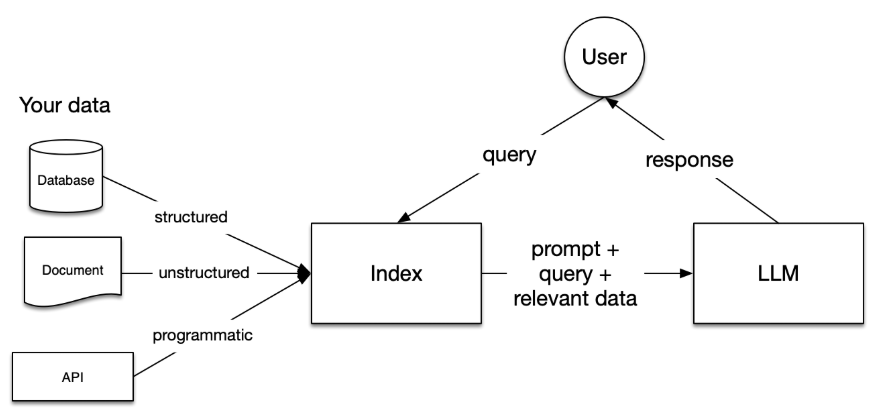
-
Question-Answering Chatbots (也就是 RAG)
-
Document Understanding and Extraction (文档理解与信息抽取)
-
Autonomous Agents that can perform research and take actions (智能体应用)
-
Workflow orchestrating single and multi-agent (编排单个或多个智能体形成工作流)
LlamaIndex 有 Python 和 Typescript 两个版本,Python 版的文档相对更完善。
-
Python 文档地址:https://docs.llamaindex.ai/en/stable/
-
Python API 接口文档:https://docs.llamaindex.ai/en/stable/api_reference/
-
TS 文档地址:https://ts.llamaindex.ai/
LlamaIndex 是一个开源框架,Github 链接:https://github.com/run-llama
LlamaIndex 的核心模块
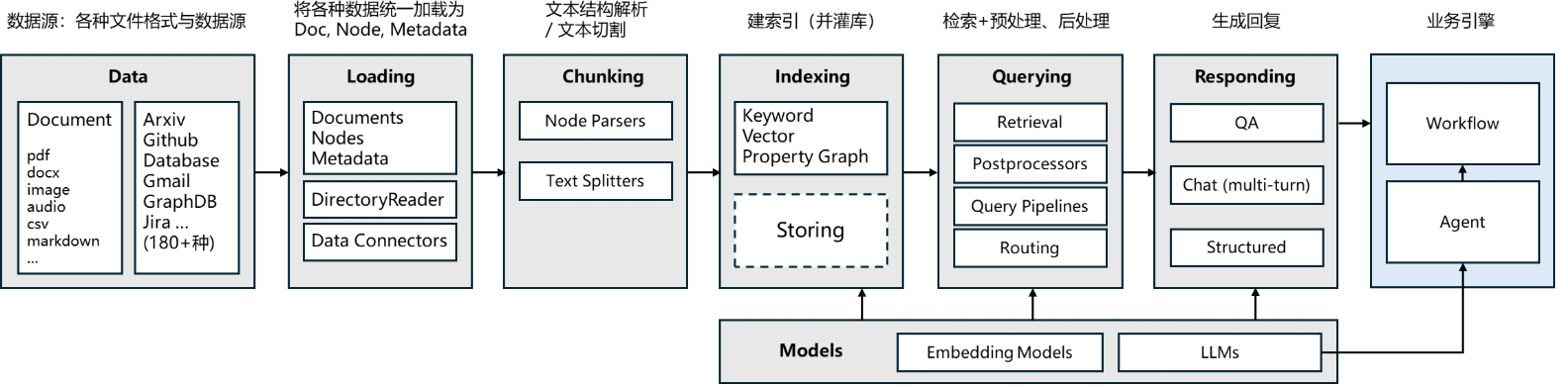
安装 LlamaIndex
# !pip install llama-index3.数据加载(Loading)
3.1、加载本地数据
SimpleDirectoryReader 是一个简单的本地文件加载器。它会遍历指定目录,并根据文件扩展名自动加载文件(文本内容)。
支持的文件类型:
.csv- comma-separated values.docx- Microsoft Word.epub- EPUB ebook format.hwp- Hangul Word Processor.ipynb- Jupyter Notebook.jpeg,.jpg- JPEG image.mbox- MBOX email archive.md- Markdown.mp3,.mp4- audio and video.pdf- Portable Document Format.png- Portable Network Graphics.ppt,.pptm,.pptx- Microsoft PowerPoint
注意:对图像、视频、语音类文件,默认不会自动提取其中文字。如需提取,参考下面介绍的 Data Connectors。
默认的 PDFReader 效果并不理想,我们可以更换文件加载器
LlamaParse
首先,登录并从 https://cloud.llamaindex.ai ↗ 注册并获取 api-key 。
然后,安装该包:
# !pip install llama-cloud-services3.2、Data Connectors
用于处理更丰富的数据类型,并将其读取为 Document 的形式。
例如:直接读取网页
# !pip install llama-index-readers-webfrom llama_index.readers.web import SimpleWebPageReader
documents = SimpleWebPageReader(html_to_text=True).load_data(
["网址/tx/"]
)
print(documents[0].text)更多 Data Connectors
4. 文本切分与解析(Chunking)
为方便检索,我们通常把 Document 切分为 Node。
在 LlamaIndex 中,Node 被定义为一个文本的「chunk」。
4.1、使用 TextSplitters 对文本做切分
例如:TokenTextSplitter 按指定 token 数切分文本
from llama_index.core import Document
from llama_index.core.node_parser import TokenTextSplitter
node_parser = TokenTextSplitter(
chunk_size=512, # 每个 chunk 的最大长度
chunk_overlap=200 # chunk 之间重叠长度
)
nodes = node_parser.get_nodes_from_documents(
documents, show_progress=False
)show_json(nodes[1].json())
show_json(nodes[2].json())LlamaIndex 提供了丰富的 TextSplitter,例如:
- SentenceSplitter:在切分指定长度的 chunk 同时尽量保证句子边界不被切断;
- CodeSplitter:根据 AST(编译器的抽象句法树)切分代码,保证代码功能片段完整;
- SemanticSplitterNodeParser:根据语义相关性对将文本切分为片段。
4.2、使用 NodeParsers 对有结构的文档做解析
例如:HTMLNodeParser解析 HTML 文档
from llama_index.core.node_parser import HTMLNodeParser
from llama_index.readers.web import SimpleWebPageReader
documents = SimpleWebPageReader(html_to_text=False).load_data(
["网址/tx/"]
)
# 默认解析 ["p", "h1", "h2", "h3", "h4", "h5", "h6", "li", "b", "i", "u", "section"]
parser = HTMLNodeParser(tags=["span"]) # 可以自定义解析哪些标签
nodes = parser.get_nodes_from_documents(documents)
for node in nodes:
print(node.text+"\n")5. 索引(Indexing)与检索(Retrieval)
基础概念:在「检索」相关的上下文中,「索引」即index, 通常是指为了实现快速检索而设计的特定「数据结构」。
索引的具体原理与实现不是本课程的教学重点,感兴趣的同学可以参考:传统索引、向量索引
5.1、向量检索
VectorStoreIndex直接在内存中构建一个 Vector Store 并建索引- 使用自定义的 Vector Store,以
Qdrant为例:# !pip install llama-index-vector-stores-qdrant
5.2、更多索引与检索方式
LlamaIndex 内置了丰富的检索机制,例如:
-
关键字检索
- BM25Retriever:基于 tokenizer 实现的 BM25 经典检索算法
- KeywordTableGPTRetriever:使用 GPT 提取检索关键字
- KeywordTableSimpleRetriever:使用正则表达式提取检索关键字
- KeywordTableRAKERetriever:使用RAKE算法提取检索关键字(有语言限制)
-
RAG-Fusion QueryFusionRetriever
-
还支持 KnowledgeGraph、SQL、Text-to-SQL 等等
5.3、检索后处理
LlamaIndex 的 Node Postprocessors 提供了一系列检索后处理模块。
例如:我们可以用不同模型对检索后的 Nodes 做重排序
更多的 Rerank 及其它后处理方法,参考官方文档:Node Postprocessor Modules
6. 生成回复(QA & Chat)
6.1 单轮问答(Query Engine)
import os
from llama_index.core import Settings
from llama_index.llms.dashscope import DashScope
# 配置DashScope模型
Settings.llm = DashScope(
model_name="qwen-max", # 或 "qwen-plus"
api_key=os.getenv("DASHSCOPE_API_KEY") # 确保已设置此环境变量
)
qa_engine = index.as_query_engine()
response = qa_engine.query("deepseek v3数学能力怎么样?")
print(response)流式输出
qa_engine = index.as_query_engine(streaming=True)
response = qa_engine.query("deepseek v3数学能力怎么样?")
response.print_response_stream()6.2 多轮对话(Chat Engine)
chat_engine = index.as_chat_engine()
response = chat_engine.chat("deepseek v3数学能力怎么样?")
print(response)response = chat_engine.chat("代码能力呢?")
print(response)流式输出
chat_engine = index.as_chat_engine()
streaming_response = chat_engine.stream_chat("deepseek v3数学能力怎么样?")
# streaming_response.print_response_stream()
for token in streaming_response.response_gen:
print(token, end="", flush=True)7. 底层接口:Prompt、LLM 与 Embedding
7.1 Prompt 模板
PromptTemplate 定义提示词模板
from llama_index.core import PromptTemplate
prompt = PromptTemplate("写一个关于{topic}的笑话")
prompt.format(topic="小明")ChatPromptTemplate 定义多轮消息模板
from llama_index.core.llms import ChatMessage, MessageRole
from llama_index.core import ChatPromptTemplate
chat_text_qa_msgs = [
ChatMessage(
role=MessageRole.SYSTEM,
content="你叫{name},你必须根据用户提供的上下文回答问题。",
),
ChatMessage(
role=MessageRole.USER,
content=(
"已知上下文:\n" \
"{context}\n\n" \
"问题:{question}"
)
),
]
text_qa_template = ChatPromptTemplate(chat_text_qa_msgs)
print(
text_qa_template.format(
name="小明",
context="这是一个测试",
question="这是什么"
)
)7.2 语言模型
from llama_index.llms.openai import OpenAI
llm = OpenAI(temperature=0, model="gpt-4o")
response = llm.complete(prompt.format(topic="小明"))
print(response.text)
response = llm.complete(
text_qa_template.format(
name="小明",
context="这是一个测试",
question="你是谁,我们在干嘛"
)
)
print(response.text)连接DeepSeek
# !pip install llama-index-llms-deepseek
import os
from llama_index.llms.deepseek import DeepSeek
llm = DeepSeek(model="deepseek-chat", api_key=os.getenv("DEEPSEEK_API_KEY"), temperature=1.5)
response = llm.complete("写个笑话")
print(response)设置全局使用的语言模型
from llama_index.core import Settings
Settings.llm = DeepSeek(model="deepseek-chat", api_key=os.getenv("DEEPSEEK_API_KEY"), temperature=1.5)除 OpenAI 外,LlamaIndex 已集成多个大语言模型,包括云服务 API 和本地部署 API,详见官方文档:Available LLM integrations
7.3 Embedding 模型
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import Settings
# 全局设定
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small", dimensions=512)LlamaIndex 同样集成了多种 Embedding 模型,包括云服务 API 和开源模型(HuggingFace)等,详见官方文档。
8. 基于 LlamaIndex 实现一个功能较完整的 RAG 系统
功能要求:
- 加载指定目录的文件
- 支持 RAG-Fusion
- 使用 Qdrant 向量数据库,并持久化到本地
- 支持检索后排序
- 支持多轮对话
9. Text2SQL / NL2SQL / NL2Chart / ChatBI
9.1 基本介绍
Text2SQL 是一种将自然语言转换为SQL查询语句的技术。
这项技术的意义:让每个人都能像对话一样查询数据库,获取所需信息,而不必学习SQL语法。
9.2 典型应用场景
-
业务分析师的数据自助服务
-
智能BI与数据可视化
-
客服与内部数据库查询
-
跨部门数据协作与分享
-
运营数据分析与决策支持
9.3 Text2SQL核心能力与挑战
一个成熟的Text2SQL系统需要具备以下关键能力:
| 核心能力 | 说明 | 技术挑战 |
|---|---|---|
| 语义理解 | 理解用户真正的查询意图 | 处理歧义、上下文推断 |
| 数据库结构感知 | 了解表结构、字段关系 | 自动映射字段与实体 |
| 复杂查询构建 | 支持多表连接、聚合等 | 子查询、嵌套逻辑转换 |
| 上下文记忆 | 理解多轮对话中的指代 | 维护查询状态 |
| 错误处理 | 识别并修正错误输入 | 模糊匹配、容错机制 |
9.4 实现Text2SQL的技术架构
-
架构一:基于Workflow工作流方案
-
架构二:基于LangChain的数据库链方案
-
架构三:企业级解决方案
-
Vanna(开源)
-
阿里云(商业)
-
腾讯云(商业)
-
10. 工作流(Workflow)
10.1 工作流(Workflow)简介
工作流顾名思义是对一些列工作步骤的抽象。
LlamaIndex 的工作流是事件(event)驱动的:
- 工作流由
step组成 - 每个
step处理特定的事件 step也会产生新的事件(交由后继的step进行处理)- 直到产生
StopEvent整个工作流结束
LlamaIndex Workflows:https://docs.llamaindex.ai/en/stable/module_guides/workflow/
10.2 工作流设计
使用自然语言查询数据库,数据库中包含多张表
工作流设计: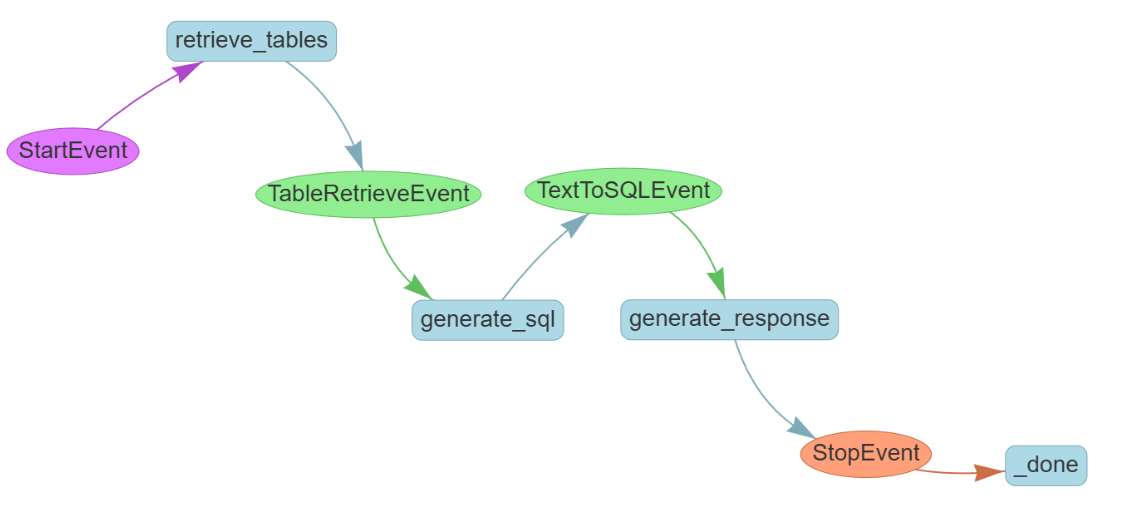
分步说明:
- 用户输入自然语言查询
- 系统先去检索跟查询相关的表
- 根据表的 Schema 让大模型生成 SQL
- 用生成的 SQL 查询数据库
- 根据查询结果,调用大模型生成自然语言回复
10.3 数据准备
# 下载 WikiTableQuestions
# WikiTableQuestions 是一个为表格问答设计的数据集。其中包含 2,108 个从维基百科提取的 HTML 表格
# !wget "https://github.com/ppasupat/WikiTableQuestions/releases/download/v1.0.2/WikiTableQuestions-1.0.2-compact.zip" -O wiki_data.zip
# !unzip wiki_data.zip- 遍历目录加载表格
- 为每个表生成一段文字表述(用于检索),保存在
WikiTableQuestions_TableInfo目录 - 将上述表格存入 SQLite 数据库
10.4 构建基础工具
- 创建基于表的描述的向量索引
ObjectIndex是一个 LlamaIndex 内置的模块,通过索引 (Index)检索任意 Python 对象- 这里我们使用
VectorStoreIndex也就是向量检索,并通过SQLTableNodeMapping将文本描述的node和数据库的表形成映射 - 相关文档:https://docs.llamaindex.ai/en/stable/examples/objects/object_index/#the-objectindex-class
- 创建 SQL 查询器
- 创建 Text2SQL 的提示词(系统默认模板),和输出结果解析器(从生成的文本中抽取SQL)
- 创建自然语言回复生成模板
10.5 定义工作流
10.6 可视化工作流
10.7 工作流管理框架意义是什么
思考以下情况:
step的执行顺序有逻辑分支step的执行有循环step的执行可以并行- 一个
step的触发条件依赖前面若干step的结果,且它们之间可能有循环或者并行
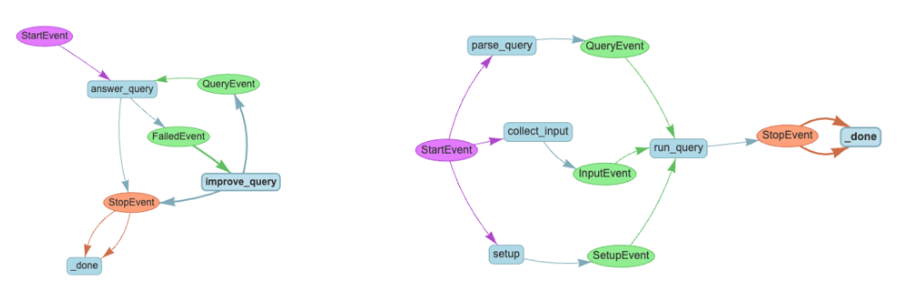
所以,工作流管理框架的意思是便于将单个事件的处理逻辑和事件之间的执行顺序独立开
关于 LlamaIndex 工作流的更详细文档:https://docs.llamaindex.ai/en/stable/examples/workflow/workflows_cookbook/
11. LlamaIndex 的更多功能
- 智能体(Agent)开发框架:https://docs.llamaindex.ai/en/stable/module_guides/deploying/agents/
- RAG 的评测:https://docs.llamaindex.ai/en/stable/module_guides/evaluating/
- 过程监控:https://docs.llamaindex.ai/en/stable/module_guides/observability/
以上内容涉及较多背景知识,暂时不在本课展开,相关知识会在后面课程中逐一详细讲解。
此外,LlamaIndex 针对生产级的 RAG 系统中遇到的各个方面的细节问题,总结了很多高端技巧(Advanced Topics),对实战很有参考价值,非常推荐有能力的同学阅读。
12. 学习打卡
- 掌握 LlamaIndex 框架核心模块
- 熟练使用 LlamaIndex 高效开发一个贴合自己需求的RAG系统
- 理解 LlamaIndex 中的工作流(Workflow)实现
- 结合自己的业务场景,通过NL2SQL技术来实现一个功能

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 15
15 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)