GTVD:基于全依赖程序图的多层聚合漏洞检测方法
“随着软件规模与复杂度不断增长,自动化漏洞发现成为保障软件供应链安全的关键环节。传统方法往往依赖单一表示或浅层特征,难以捕获程序中的长程依赖与复杂语义关系。为此,来自 燕山大学 的团队提出了 GTVD(Full-Dependency Program Graph + Multi-Level Aggregation),通过更丰富的图表示与多层消息聚合策略,提升函数级漏洞检测的表示能力与识别精度。 ”
📄 论文标题:GTVD: a multi-level aggregation vulnerability detection method based on full-dependency program graph
📅 发表时间:Cluster Computing, 2025
🏫 作者单位:燕山大学
01
—
方法介绍
GTVD 的核心思想是用一种更完整的图表示结合多层聚合与自适应加权,解决传统 GNN 在长程依赖与信息衰减上的弱点。整体流程包括:FDPG(Full Dependency Program Graph)构建 → 节点向量化 → 多层消息聚合(MLMA)→ 自适应加权聚合(WAG)→ MLP 分类。
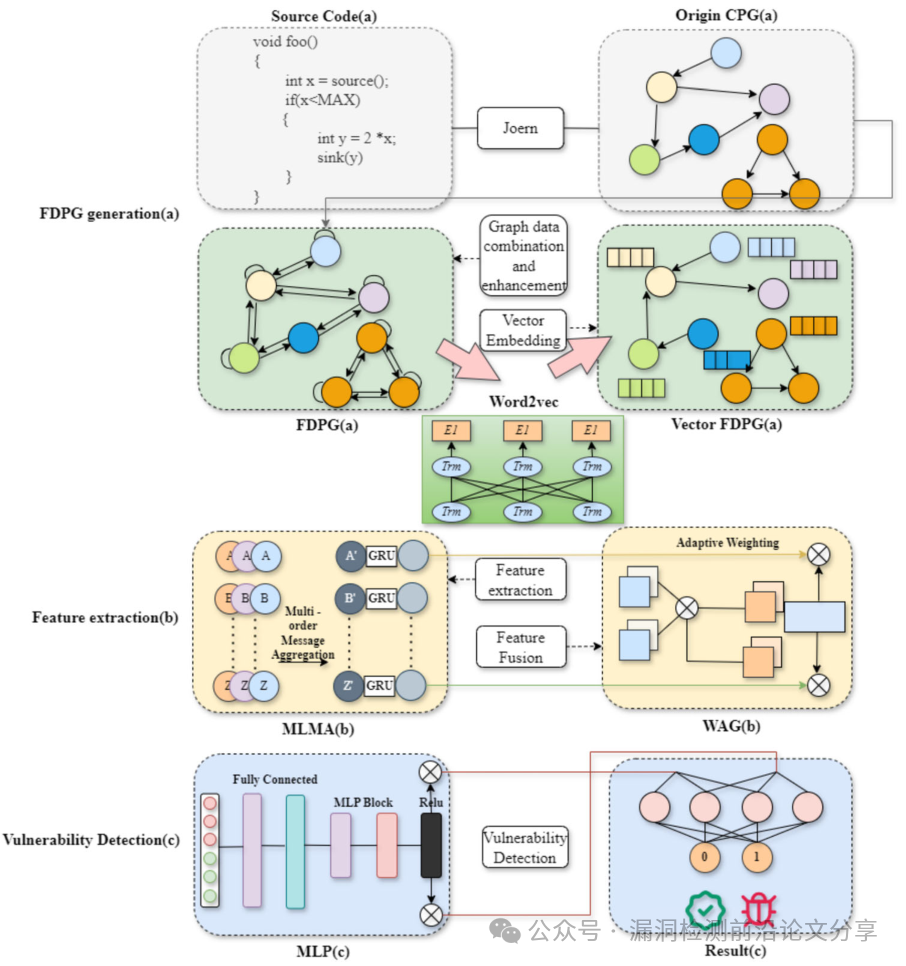
图 1. GTVD框架
小结:FDPG 通过集成 AST/CFG/PDG 并加入反向边与自环,增强了图结构的表达能力;MLMA 扩展了节点的感受野;WAG 则通过注意力/加权机制动态调整节点对全局表示的贡献。
02
—
关键机制
- FDPG:
用反向边和自环补全依赖,避免信息单向流失。
- MLMA:
一次迭代中融合多阶邻域信息,提升对复杂依赖的捕获。
- WAG:
引入自适应加权避免简单均匀聚合导致的噪声传播。
|
机制 |
实现方式 |
主要作用 |
|---|---|---|
|
Full Dependency Program Graph (FDPG) |
整合 CPG(AST/CFG/PDG),补入反向边与自环 |
全面编码语法与语义依赖,增强长程关系表达 |
|
Multi-Level Message Aggregation (MLMA) |
多阶消息传递,按不同邻域阶数聚合节点信息 |
扩大节点感受野,缓解信息衰减 |
|
Adaptive Weighted Aggregation (WAG) |
多头注意力 + MLP 动态计算节点权重 |
根据上下文调整节点贡献,提高图级表示质量 |
|
分类器 |
MLP + Softmax(二分类) |
将图表示映射到漏洞/非漏洞标签 |
03
—
实验结果
作者在三个公开大规模数据集上进行了全面评估:FFmpeg&Qemu、BigVul、Reveal。数据集统计与训练细节见论文;训练采用 8:1:1 划分,超参与收敛行为在文中有详细说明(Epoch 收敛约 90 轮)。
FFmpeg & Qemu:
|
模型 |
A |
P |
R |
F1 |
|---|---|---|---|---|
|
VulDeePecker |
49.91 |
46.05 |
32.55 |
38.14 |
|
SySeVR |
47.85 |
46.06 |
58.81 |
51.66 |
|
Russell |
57.60 |
54.76 |
40.72 |
46.71 |
|
IVDetect |
57.26 |
52.37 |
57.55 |
54.84 |
|
BovdGFE |
56.46 |
50.18 |
50.63 |
47.27 |
|
AMPLE |
62.16 |
55.64 |
83.99 |
66.94 |
|
GRACE |
59.78 |
53.94 |
82.13 |
65.11 |
| GTVD (本文) | 61.39 | 56.27 | 60.53 | 52.32 |
BigVul:
|
模型 |
A |
P |
R |
F1 |
|---|---|---|---|---|
|
VulDeePecker |
81.19 |
38.44 |
12.75 |
19.15 |
|
SySeVR |
90.10 |
30.91 |
14.08 |
19.34 |
|
Russell |
86.85 |
14.86 |
26.97 |
19.17 |
|
IVDetect |
87.14 |
17.22 |
34.04 |
22.87 |
|
BovdGFE |
88.94 |
25.38 |
28.17 |
30.29 |
|
AMPLE |
93.14 |
22.98 |
34.58 |
32.11 |
|
GRACE |
90.73 |
32.52 |
39.08 |
35.50 |
| GTVD (本文) | 93.91 | 38.02 | 56.88 | 32.27 |
Reveal:
|
模型 |
A |
P |
R |
F1 |
|---|---|---|---|---|
|
VulDeePecker |
76.37 |
21.13 |
13.10 |
16.17 |
|
SySeVR |
68.51 |
16.21 |
52.68 |
24.79 |
|
Russell |
81.77 |
31.55 |
61.14 |
41.62 |
|
BovdGFE |
88.72 |
40.16 |
43.73 |
35.42 |
|
AMPLE |
92.71 |
51.06 |
46.15 |
48.48 |
|
GRACE |
89.73 |
33.21 |
61.53 |
43.13 |
| GTVD (本文) | 90.52 | 61.76 | 68.38 | 48.83 |
小结:GTVD 在三套数据集上的综合性能优于大多数基线:在 Accuracy 上对比最新基线的提升分别为 FFmpeg&Qemu +1.61%, BigVul +3.18%, Reveal +0.79%;此外在 Recall 指标上,GTVD 在 BigVul 与 Reveal 上分别最小提升了 17.8% 与 6.85%.
📌 总结
GTVD 通过三项设计(FDPG、MLMA、WAG)解决了图表示在长程依赖与信息衰减上的痛点,实现了在多数据集上的稳健提升。该方法对函数级漏洞检测尤为适用,并为将来把图表示与 LLM/混合方法结合提供了可行的方向。论文也指出未来工作将扩展到更多语言与跨项目泛化研究。
📣 欢迎留言讨论
-
你更看好“更丰富的图表示 + 更强的 GNN”路线,还是“把图结构信息以检索/提示的方式喂给 LLM”路线?
-
在企业级审计中,FDPG 这类复杂表示的工程成本是否值得?
📌 点赞 + 收藏 + 分享,你的支持,是我们持续解析高水平软件安全论文的最大动力!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 29
29 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)