论文阅读《Omer Ben-Porat, Yishay Mansour, Michal Moshkovitz, Boaz Taitler. **Principal-Agent Reward Shap》
论文:Omer Ben-Porat, Yishay Mansour, Michal Moshkovitz, Boaz Taitler. Principal-Agent Reward Shaping in MDPs. AAAI 2024.
摘要
当一方代表另一方行事时,就会出现委托代理问题,从而导致利益冲突。经济学文献对委托代理问题进行了广泛研究,近期的研究已将其扩展到更复杂的场景,如马尔可夫决策过程(MDP)。本文进一步探索这一研究方向,探讨在预算约束下通过奖励塑造如何提升委托方的效用。我们研究了一个双人斯塔克尔伯格博弈,其中委托方和代理方具有不同的奖励函数,代理方为双方选择一个MDP策略。委托方会向代理方提供额外奖励,而代理方则出于自身利益最大化的目的,选择能够使其总奖励(即原始奖励与所提供奖励之和)最大的策略。我们的研究结果证明了该问题的NP难性,并针对两类实例——随机树和有限 horizon 的确定性决策过程——给出了多项式时间近似算法。
Introduction
一方代表另一方做出决策的情形十分常见。例如,在投资管理领域,投资者可能会聘请投资组合经理来管理其投资组合,以实现收益最大化为目标。然而,投资组合经理也可能有自己的偏好或激励机制,比如追求风险最小化或自身薪酬最大化,而这些目标可能与投资者的目标并不一致。这种冲突正是委托代理问题的经典案例,自20世纪70年代以来一直受到经济学家的广泛研究(参见,例如,Holmström 1979;Laffont 2003)。该研究领域的核心问题在于,委托人应如何采取行动以缓解激励不一致,从而实现其目标(Zhang和Zenios 2008;Gan等 2022;Ross 1973;Zhuang和Hadfield-Menell 2020;Hadfield-Menell和Hadfield 2019;Xiao等 2020;Ho、Slivkins和Vaughan 2014)。尽管关于委托代理问题的文献浩如烟海,但现代应用却带来了新的挑战:推荐系统作为委托人,而其用户则为代理人。以Waze这类导航App为例,该App的主要功能是为用户提供到达目的地的最快路线,但它自身也存在一些可能与其用户目标不一致的内部目标。例如,该App可能会激励用户探索使用频率较低的道路,或者引导用户驶近那些已支付广告费用的位置。此外,该App依赖用户上报来识别道路上的突发事件,但用户往往不愿主动上报。在这种情况下,导航App即为委托人,它可以通过游戏化机制、向广告主的店铺发放优惠券等多种策略,激励用户采取符合其自身目标的行为。由于主体在状态空间中的转移以及由此产生的委托代理交互可以建模为一个马尔可夫决策过程(MDP),尽管已有部分研究将委托代理问题置于MDP框架下进行探讨(Zhang和Parkes 2008;Yu和Ho 2022;Zhang、Cheng和Conitzer 2022a,b),但这一研究方向仍显不足。在MDP环境中缓解激励不一致这一根本性问题,仍有待进一步研究。本文致力于推进对这一复杂场景的研究。具体而言,我们将该场景建模为两个参与者——委托人与代理人——之间的一个联合MDP上的斯塔克尔伯格博弈。1 委托人和代理人分别拥有独特的奖励函数,分别记为RP和RA,它们将状态和动作映射为即时奖励。委托人获得的奖励取决于代理人的决策策略,因此她会通过我们记为RB的奖金奖励函数来激励代理人。我们假设委托人具有有限的预算,并将其建模为对RB范数的约束。代理人则以自我利益为导向,寻求能够最大化自身效用的策略,该效用为其奖励函数RA与委托人提供的奖金奖励函数RB之和。通过向代理人提供奖金奖励,委托人能够促使代理人采纳更符合其自身(即委托人)目标的策略。我们提出的技术性问题是:在预算约束条件下,委托人应如何设计奖金函数RB,以使其自身效用最大化?
我们的贡献
本文首次为委托-代理奖励塑造问题提出了高效、近优的算法。该问题在之前的工作中已被考虑并证明是 NP 困难的(参见 1.1 节的详细讨论)。因此,之前的工作提出的解决方案从混合整数线性规划到可微启发式算法不等。相比之下,在本文中,我们确定了两类广泛的实例,尽管它们也是 NP 困难的,但可以被高效地近似。
第一类是具有树形结构的 MDP,我们称之为随机树(stochastic trees)。在随机树中,每个状态恰好有一个导向它的父状态,且多个状态可以具有相同的父状态。我们强调不是确定性的,给定一个状态和动作,下一个状态是该状态子节点上的分布。随机树非常适合处理涉及顺序依赖或分层决策的现实场景。例如,在供应链管理中,原材料采购等上游决策对制造和分销等下游活动具有级联效应。同样,在自然资源分配中,初始的开采或收割选择会创建后续决策的路径。
我们设计了随机树委托-代理奖励塑造算法(STAR),这是一种全多项式时间近似方案。它使用了一个令人惊讶的“无差异观察”:想象两种场景,一种是委托人不给予奖金,另一种是委托人提供高效奖金(高效性的定义见 2.3 节)。在这两种情况下,如果代理人做出最佳响应,他将获得相同的效用。这使我们能够采用自底向上的动态规划方法(见观察 1)并证明:
定理 1(定理 4 的非正式表述):令底层 MDP 为深度为
的
叉树,令
为预算为
时委托人问题的最优效用。给定任何小的正数常量
,我们的算法 STAR 保证通过使用
的预算获得至少
。
第二类问题是有限步长确定性决策过程(DDP)(Castro 2020; Post and Ye 2015)。与不确定性起核心作用的随机树不同,DDP 涉及以动作与结果之间清晰的因果关系为特征的场景。DDP 适用于许多现实应用,例如依赖规划的机器人和控制系统。重要的是,我们为随机树开发的机制在这里失效了。我们提出了另一种基于近似所有效用向量的帕累托前沿(Pareto frontier)的技术。我们设计了确定性有限步长委托-代理奖励塑造算法(DFAR),并证明:
定理 2(定理 5 的非正式表述):令底层 MDP 为步长为
为一个小的正数常量。我们的算法 DFAR 具有以下保证:
(
-离散奖励):如果委托人和代理人的奖励函数是
*(一般奖励):对于一般奖励函数,DFAR 需要
的预算来保证对预算为
的加性近似。
(运行时间):在上述两种情况下,执行 DFAR 的运行时间为
。
2 Model
总结:
Principal 不能直接控制 Agent 的策略,只能给 Agent 的某些状态-动作对加 bonus;Agent 看到 bonus 后,自私地最大化;Principal 的收益则由 Agent 最终策略在
下的价值决定。
H表示Agent 最多要连续决策多少步?
1.首先介绍MDP:
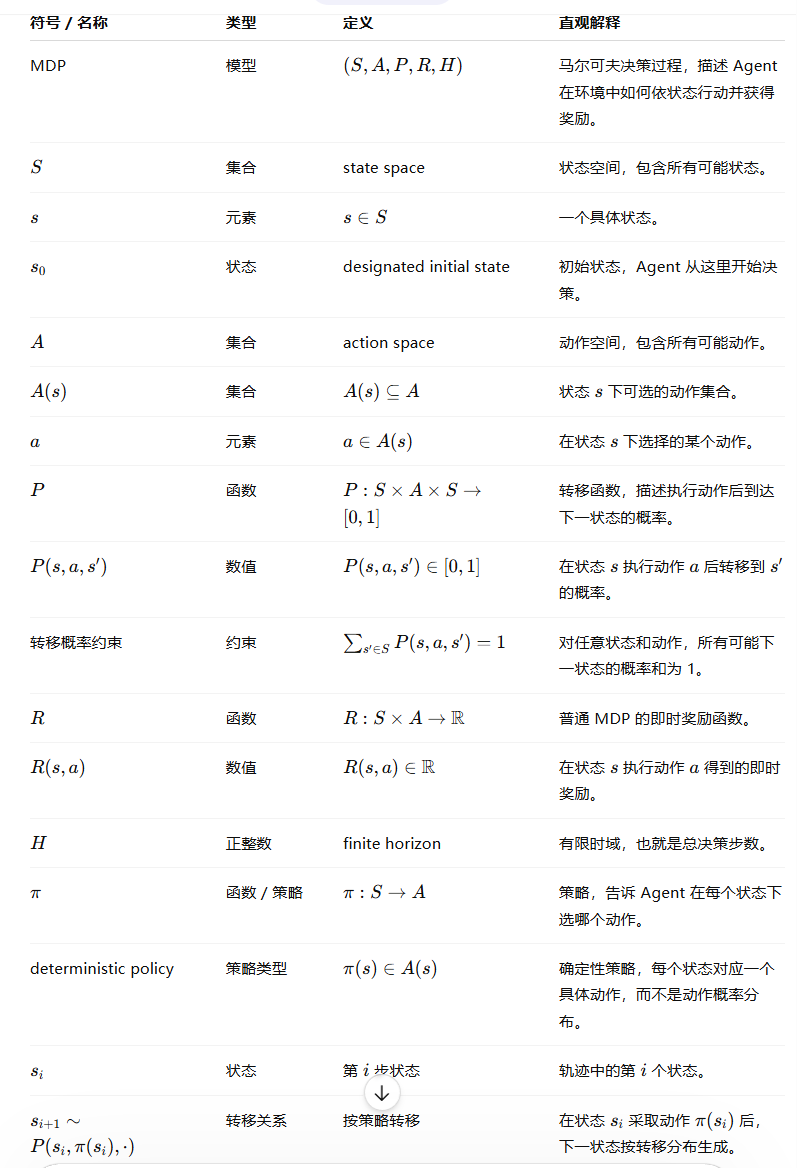
2.接着定义最优价值策
给定一个 MDP 和一个策略
,我们令
表示
的期望效用,即瞬时奖励的期望总和;即
其中。我们也令
表示从任何状态
开始时的奖励。为了方便起见,我们将最优策略集表示为
。当对象
在上下文中已知时,我们将其省略并表示为
,
和
。最后,我们采用
函数(参见例如 Wiering and Van Otterlo 2012),定义为
函数描述了在状态
选择动作
并在之后执行策略
的效用

3.介绍MDP 中的委托-代理奖励塑造问题(PARS-MDP)

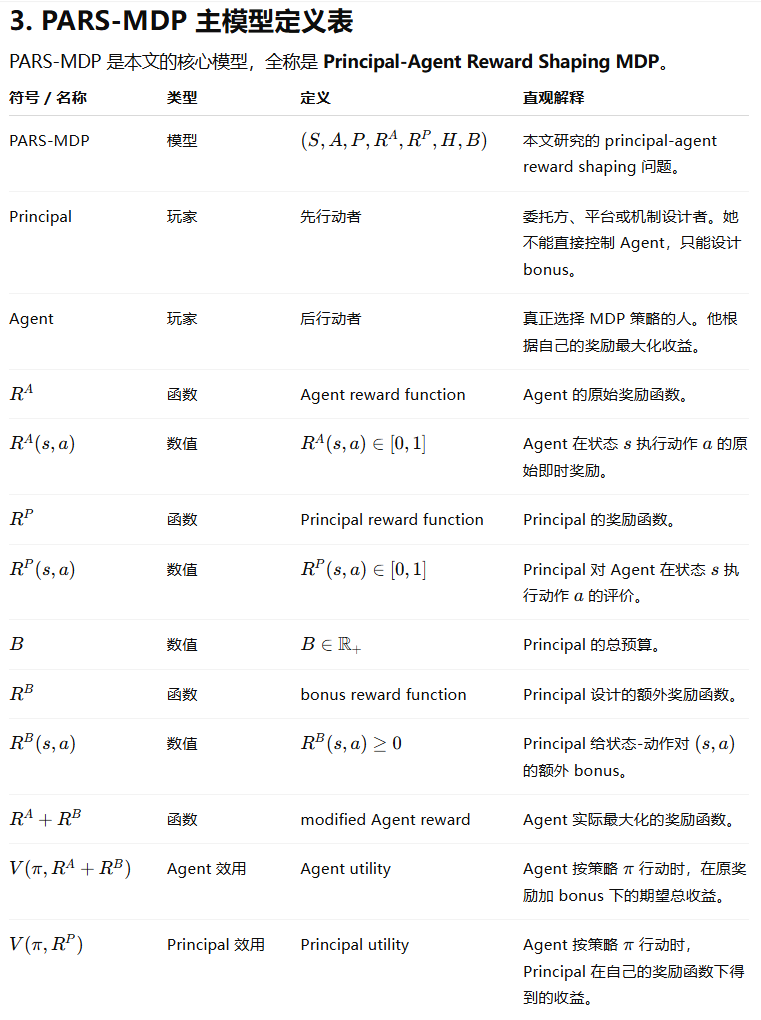

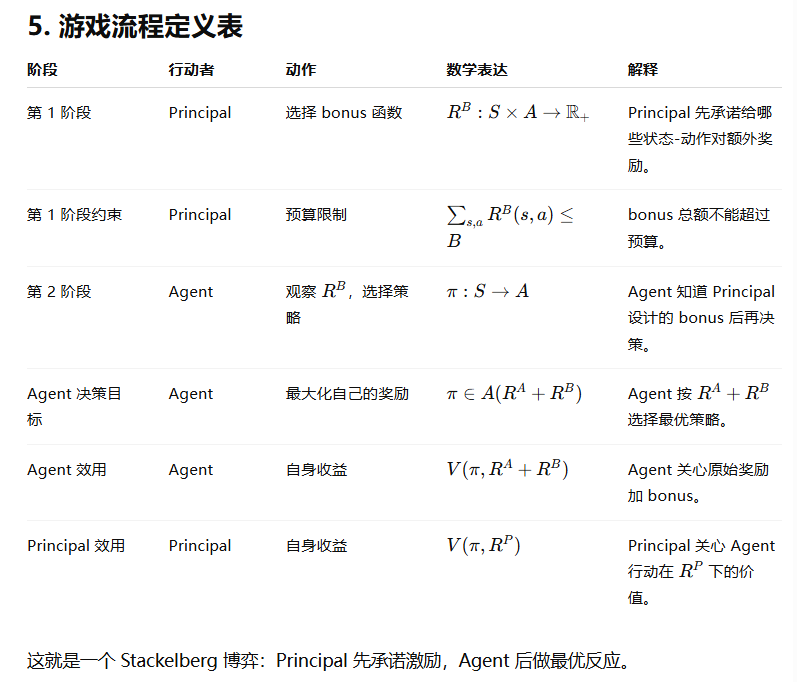
2.1 PARS-MDP as an Optimization Problem
定义问题
我们提议将 PARS-MDP 描述为委托人的优化问题,而不是博弈公式。直观上,代理人应使用 对奖金函数做出最佳响应。在有多个策略使
最大化的情况下,我们通过假设代理人选择最有利于委托人的那个策略来打破僵局。形式上,
。请注意,这具有普适性,尽管我们讨论了直接的补救措施(见附录)。因此,代理人的行动是可预测的,计算均衡策略的主要挑战是寻找委托人的最优行动。
接下来,我们将模型公式化为委托人的优化问题。她的目标是选择奖金函数,使得代理人选择的策略
最大化委托人的效用。形式上:
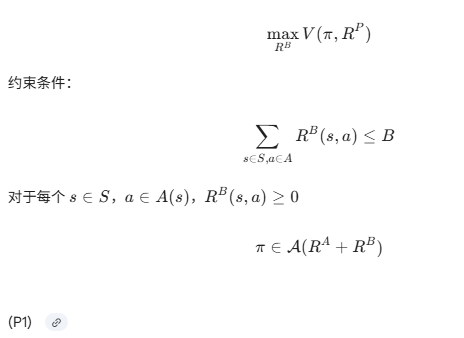
显然,如果没有,优化可以高效完成,即为代理人选择一个最大化委托人期望效用的最优策略。当我们引入变量
时,问题变得计算困难。直观地看,我们需要同时选择奖金奖励
和代理人的最佳响应策略。这种相关性是困难的核心;以下定理 3 表明该问题是 NP 困难的。

最终p1:

定理三:
Theorem 3. Problem P1 is NP-hard.
2.2 Warmup Examples
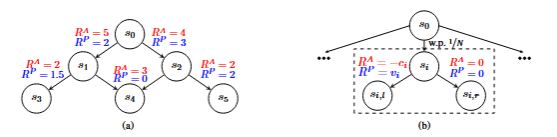
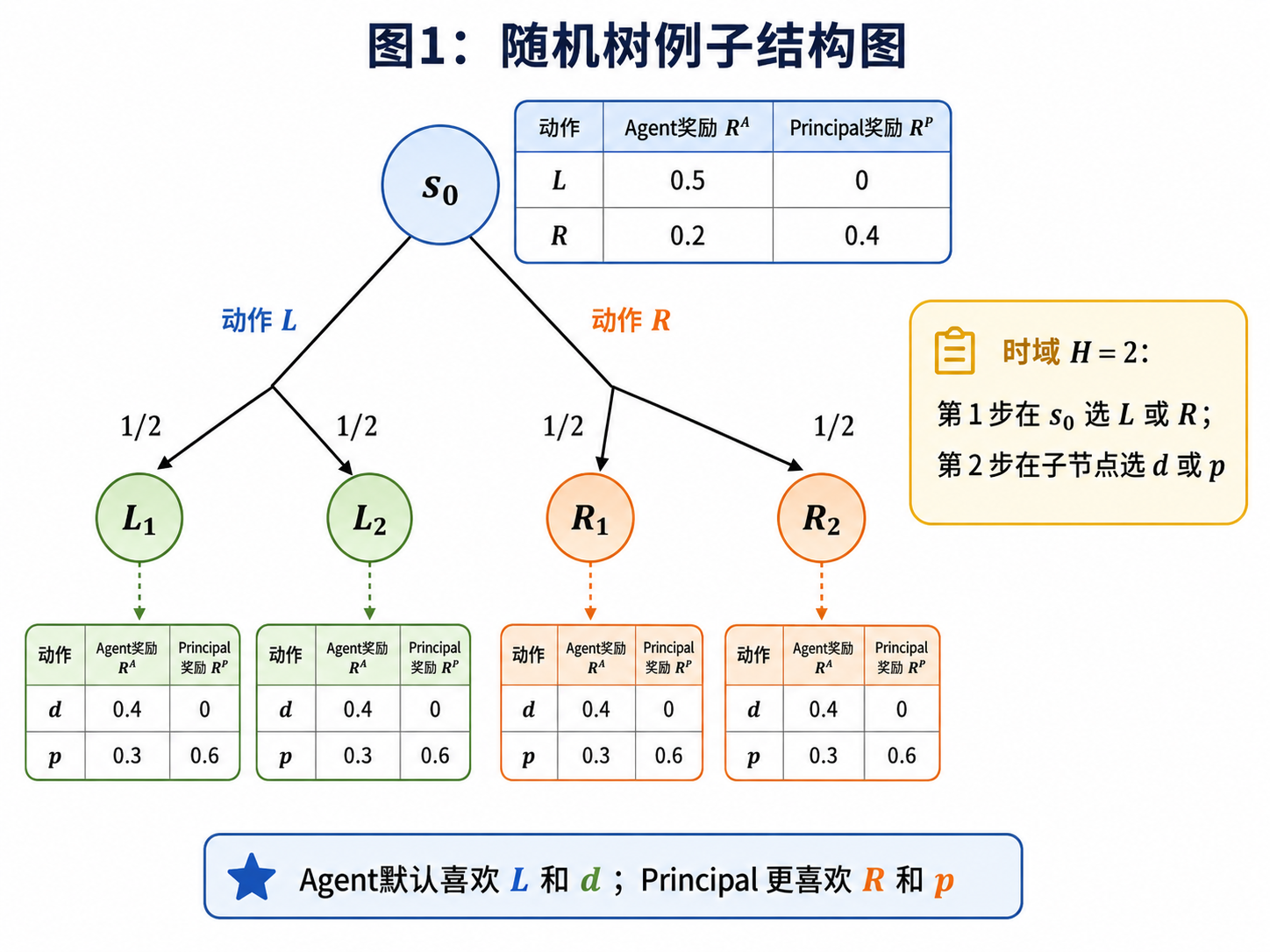
图1:示例1和示例2的实例。在两幅图中,智能体(主体)的奖励分别以红色(蓝色)标注在每条边旁边。图1a描述了一个具有确定性转移的无环图,图1b描述了一棵深度为2的随机树。
例一


例二:


0-1背包:
2.3 Implementable Policies
以下定义捕捉了可行策略集,即委托人可以通过选择可行奖金函数诱导的策略。
定义 1 (
使得
且
,则策略
是
例如,在例 1 中,诱导路径的策略是
可实现的,但不是
-可实现的。我们进一步强调策略的最小实现。
定义 2 (最小实现):令
的奖金函数
,都有
。
最小实现是预算高效的,指能激励代理人执行的最小奖金。重要的是,正如我们在附录中证明的,它们总是存在的。


3 Stochastic Trees
如果 MDP 的结构是一棵树,作者提出 STAR 算法。它使用预算离散化和动态规划,在预算稍微放宽的情况下达到原预算下的最优 Principal 效用。论文说,STAR 在预算:B+ϵ∣S∣下,可以保证达到原预算 B 下的最优 Principal utility。这里 B是原始预算,∣S∣ 是状态数,ϵ 是离散化粒度
在本节中,我们关注具有树形布局的 PARS-MDP 实例。为了近似最优奖励,我们提出了随机树委托-代理奖励塑造算法(STAR),该算法在假设预算为 的情况下保证了最优的委托人效用。这里,
代表原始预算,
是状态数量,而
是一个可配置的离散化因子。值得注意的是,STAR 的运行时间复杂度为
。
在继续之前,我们断言基于树的实例尽管是该问题的一个特例,但仍然具有计算上的挑战性。要了解这一点,回想一下我们在例 2 中使用了浅层树来证明该问题是 NP 困难的。至关重要的是,值得注意的是,计算挑战并非源于树结构本身,而是源于随机性的存在。在确定性树的情况下,从开始的任何策略的轨迹总是通向一个叶节点。因此,委托人的任务简化为从至多
个叶子中选择一个叶节点。
首先,我们引入一些有用的符号。我们采用子节点和父节点的标准树图术语,其中如果存在 使得
,则
是
父节点,而
是
的子节点。为了方便起见,我们将状态
的子状态和父状态集合分别定义为
和
。由于树的深度受步长的限制,我们可以使用
来表示树深度的上限,它被定义为从状态
到叶状态的最长路径。此外,我们表示(任意一个)当
时代理人的最优策略,我们将其记为
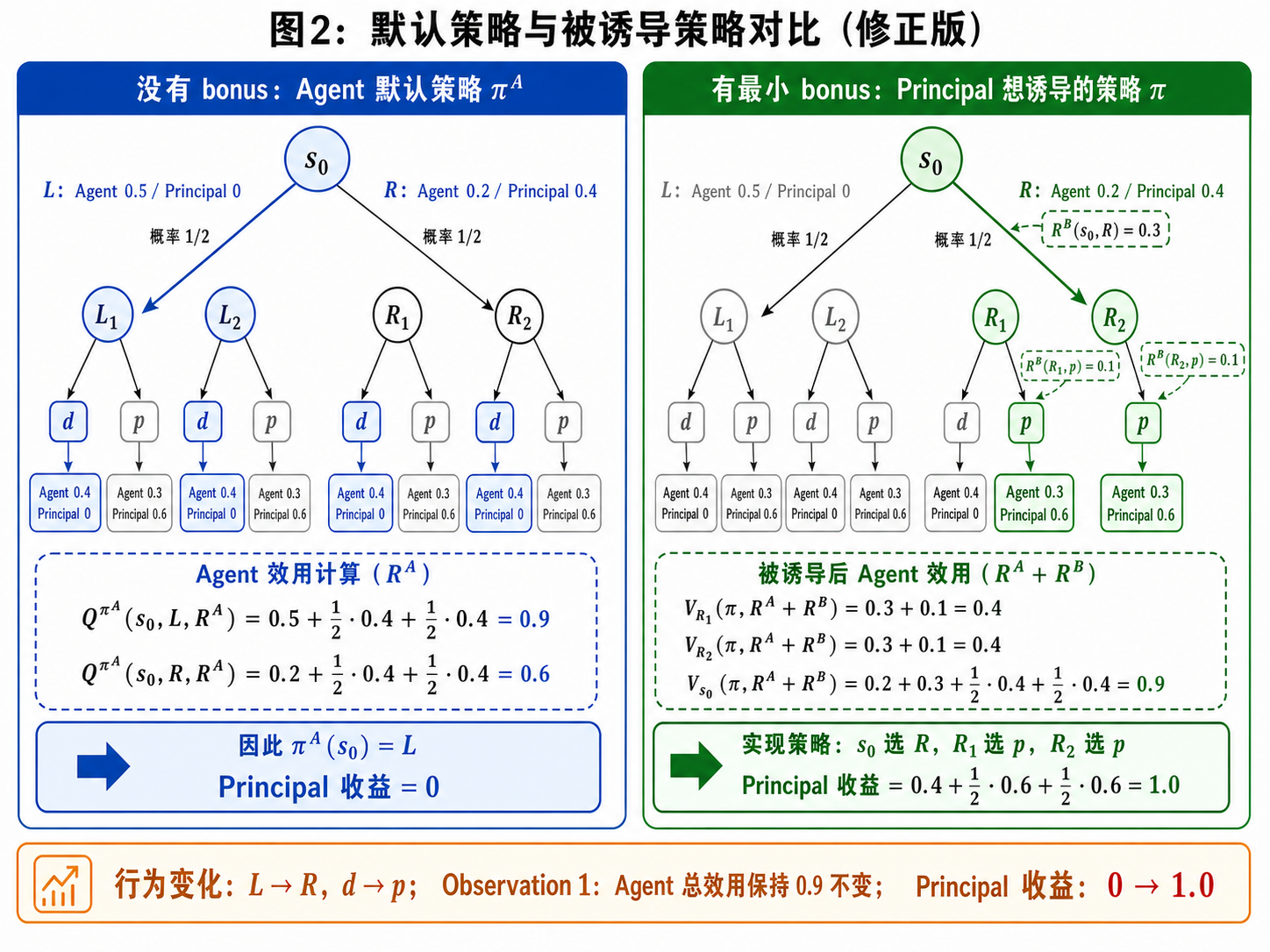
。这个策略代表了在没有奖金奖励时代理人的默认动作。
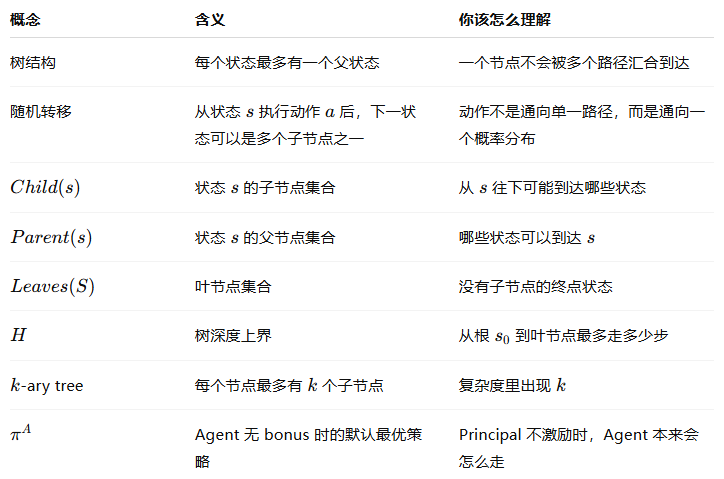
我们在下一小节正式介绍 STAR,并在这里勾勒出高层的直觉。它采用了一种动态规划方法,从叶状态开始并向根节点 迭代,同时将几乎所有看似最优的局部解向上游传播。我们使用“几乎”,是因为它使用了一种离散化形式(回想一下该问题是 NP 困难的)。为了解释为什么这种动态规划是非平凡的,固定任何任意内部(非叶)状态
。暂时假设委托人不放置任何奖金;因此,代理人根据
选择在
中的动作。由于
关于
的最优性,我们知道
。
为了激励代理人选择动作,委托人可以根据公式分配奖金:
(1)
方程(1)右侧的项通常被称为优势函数并用减号表示,它在强化学习中起着重要作用(参见例如(Wiering and Van Otterlo 2012))。

注意,这笔奖金仅包含对于状态-动作对 的(瞬时)奖励。然而,任何动态规划过程都会传播局部的奖金分配;因此,当把代理人从
转换为
时,我们必须考虑在
的子树中的奖金分配。也就是说,为了设定
以使代理人在
处转而执行
,我们不仅要考虑
,还要考虑我们传播的任何候选奖金函数
,并考虑代理人的最佳响应。由于离散化,这可能导致运行时间的显著膨胀和预算浪费。

幸运的是,我们可以避免这种膨胀。下一个观察 1 断言,在最小实现奖金函数下,在任何状态 引导代理人执行
中的另一个动作与
子树的分配是解耦的。
观察一
观察 1. 令
为其最小实现。对于每一个
,都有
。
观察 1 乍一看不直观。在左侧,我们有这是在没有委托人和奖金奖励的情况下代理人获得的效用。在右侧,
是当委托人选取
(它是策略
的最小实现)时代理人的最优效用。将这两项等同起来表明,通过提供奖金奖励,委托人使得代理人在其默认策略
和这个 B-可实现策略之间变得无差异;也就是说,在放置奖金奖励后,代理人的效用并没有增加。这在整棵树中递归地为真。因此,只要我们考虑最小实现,我们就可以利用方程(1)中提出的瞬时奖金来激励代理人在
处执行
,而不必关心在
的子树中的奖金分配。

解耦的意思:

3.1 The STAR Algorithm

STAR 算法在算法 1 中实现。它将实例参数连同离散化因子作为输入,并输出一个几乎最优的奖金函数
。
- 第 1 行初始化了奖金的离散集合
,称为预算单位。
- 第 2 行初始化了变量
和
,我们用它们来存储委托人的局部最优解。
- 第 3 行将 curr 初始化为 Leaves(S),其中 Leaves(S) 是叶状态的集合。
- 逆向归纳过程是第 4 行的 while 循环。在整个执行过程中,curr 存储了其子树在先前迭代中已被处理的状态。只要 curr 非空,我们就进行迭代。
- 第 5 行,我们从 curr 中弹出具有最大深度的状态
。(优先处理更深的节点,保证在处理某个状态 sss 时,它的子树已经处理完。)
- 在第 6 行,我们为每个动作
计算使代理人从执行
转变所需的最少奖金。根据观察 1,这种局部偏离与我们针对最小奖金函数为 Child(s) 计算出的局部最优解是解耦的。
第 7 行和第 8 行是动态规划过程的核心。
- 在第 7 行,我们考虑每个动作
。我们将
设为从
且预算为
。为此,我们需要处理两项。第一项是局部的
,即如果代理人在
是如果代理人在状态
时间内计算出
、
分别为
也就是说,我们考虑在子节点和
的子树之间的所有可能预算分配,将
分配给前者,将
分配给后者。
- 动态规划的第二步出现在第 8 行,在这里我们归纳地计算
。回想一下,之前计算的
分配给对
(回想第 6 行)。因此,
。由于我们考虑离散的预算,我们假设用尽大于
,这意味着我们在归纳过程中削减了少许预算部分。
- 归纳计算之后,第 9 行更新了集合 curr。
- 第 11 行从
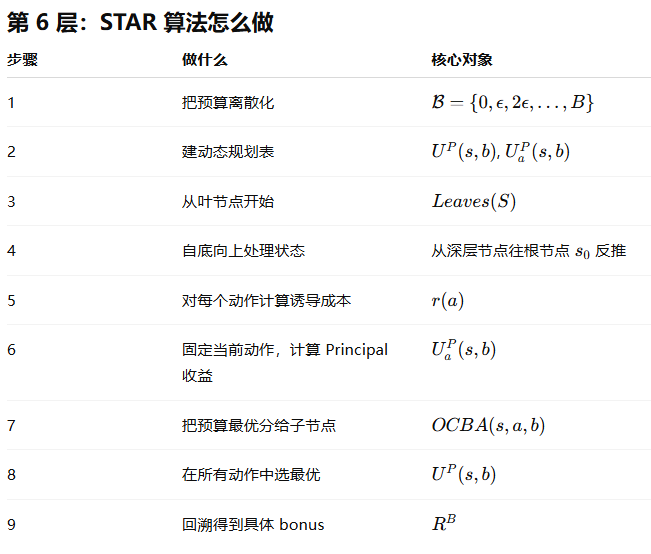
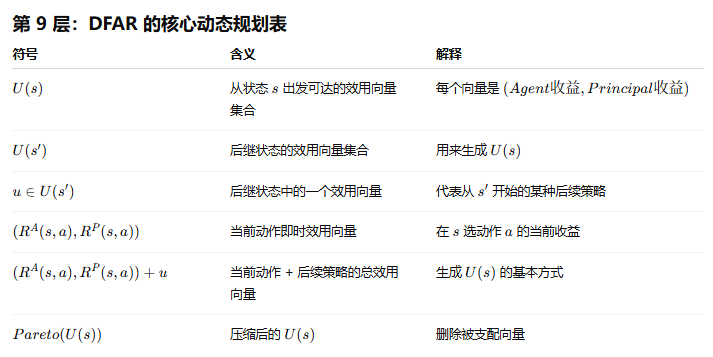
| 符号 | 含义 | 简单理解 |
|---|---|---|
| 从状态 (s) 开始,如果 Agent 在 (s) 选动作 (a),预算 (b) 下 Principal 的最优收益 | 固定当前动作后能拿多少 | |
| 从状态 (s) 开始,预算 (b) 下 Principal 的最优收益 | 当前动作也由 Principal 通过 bonus 间接选择 | |
| 诱导 Agent 选动作 (a) 的成本 | 要先付多少钱让 Agent 愿意选 (a) | |
| 动作 (a) 后,把预算 (b) 分给子树的最优收益 | 未来预算怎么分 |
| 递推 | 含义 |
|---|---|
| 如果当前动作固定为 (a),Principal 收益等于当前收益加未来子树收益 | |
| 要先扣掉诱导动作 (a) 的成本,再比较哪个动作最有利 |
| 项目 | 内容 |
|---|---|
| 全称 | Optimal Children Budget Allocation |
| 作用 | 给定当前状态 (s)、当前动作 (a)、预算 (b),决定预算如何分给子树 |
| 为什么需要它 | 因为动作 (a) 后可能随机进入多个子节点 |
| 二叉树例子 | 子节点为 (s_l,s_r) |
| 公式 | |
| b′ | 分给右子树的预算 |
| b−b′ | 分给左子树的预算 |
| 本质 | 枚举预算拆分方式,选 Principal 期望收益最大的拆法 |




定理4:STAR的形式化保证
定理 4. 令 I = (S, A, P. RA, RP, H, B) 为一棵 k 叉树,并令
为
的最优解。进一步,令
,其中
是一个小的常数,并令
表示
的输出。那么,执行
的运行时间,并且它的输出
对于任何
。
我们注意到,尽管定理 4 的运行时间中存在因子 B,STAR 仍是一个全多项式时间近似方案(FPTAS)。令为任何小的常数。通过设置
,我们使用了
的预算,并且执行耗时
。
| 项目 | 内容 |
|---|---|
| 原问题 | |
| 原始预算 | |
| 原预算下 Principal 最优值 | |
| STAR 实际使用预算 | |
| STAR 输出 | |
| 效用保证 | |
| 适用策略 | 任意 |
| 运行时间 | |
| 结论 | STAR 用稍微更大的预算,达到原预算下的最优 Principal 收益 |

定理四的目的是:证明:
虽然一般 PARS-MDP 是 NP-hard,虽然随机树仍然可以包含 NP-hard 的背包结构,但如果允许预算轻微放宽,并进行预算离散化,就可以设计出 STAR 算法,在多项式时间内达到原预算下的最优 Principal 效用。




4 Deterministic Decision Processes with Finite Horizon
具有有限步长的确定性决策过程
总结

在本节中,我们处理具有确定性决策过程布局和有限步长的 PARS-MDP 实例。正如我们在附录中所示,这类问题仍然是 NP 困难的。我们提出了确定性有限步长委托-代理奖励塑造算法(DFAR),该算法在算法 2 中实现。如果 和
是
-离散的,即某个小常数
的倍数,DFAR 为问题(P1)提供了最优解,并在
时间内运行,其中 H 是步长。作为推论,我们展示了 DFAR 为一般奖励函数
和
提供了双标准近似。也就是说,如果预算
的最优解为
,DFAR 需要
的预算来保证至少为
的效用。
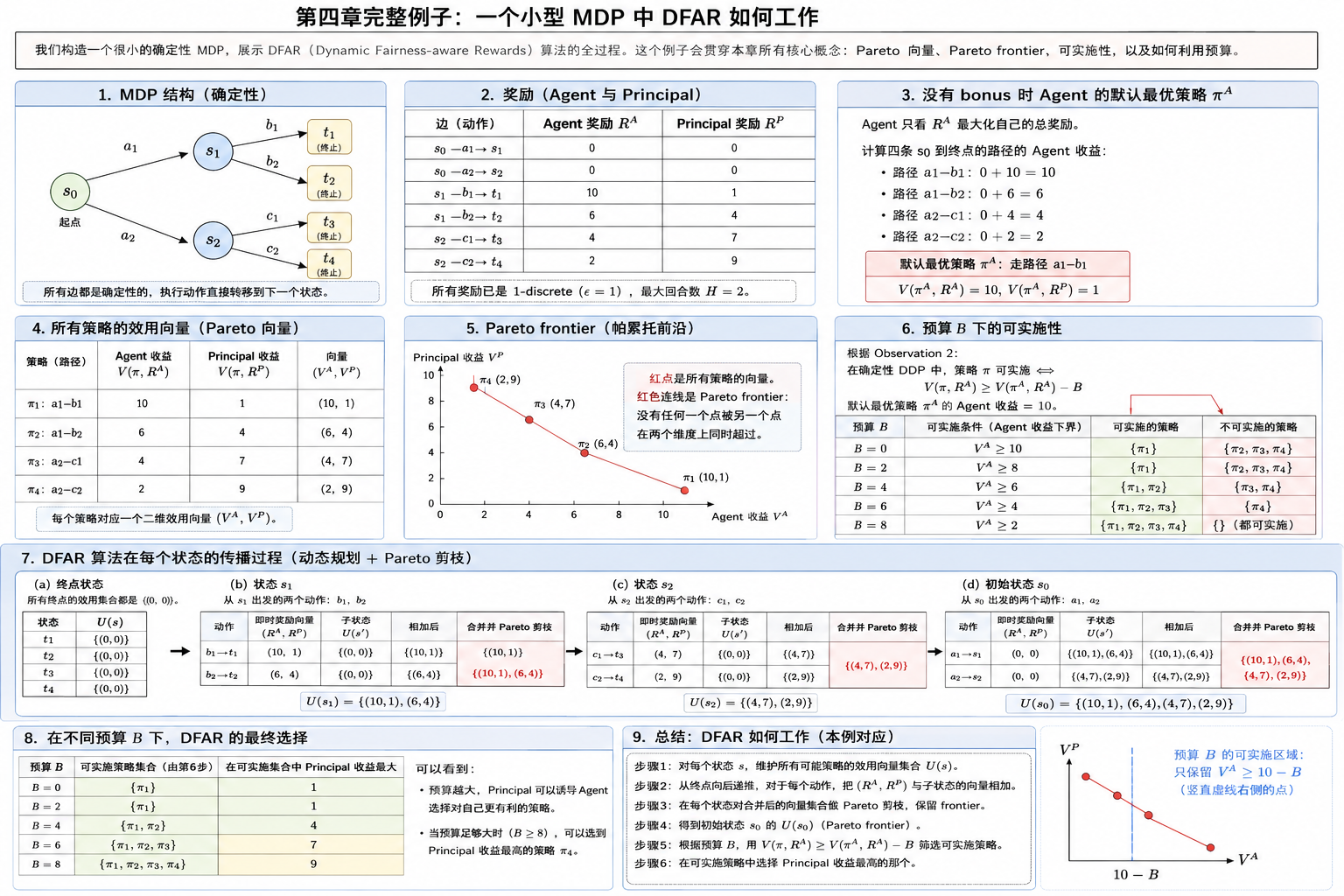
为了便于阅读,我们将注意力限制在无环 DDP 上,并在稍后的 4.2 小节中解释如何将我们的结果扩展到有环图。在提出此类实例的近似算法之前,我们注意到上一节的 STAR 算法不适用于具有无环布局的实例。STAR 中的主要挑战之一是在每个动作的子状态之间分配预算。在无环布局中,一个状态可能有多个父状态;因此,如果我们对非树布局遵循相同的技术,STAR 算法将为同一状态分配多个不同的预算,每个父节点分配一个预算。结果,单个状态-动作对可能会被分配多个奖金奖励。
为了处理无环布局,我们采用了不同的技术。为了解释我们算法背后的直觉,考虑所有效用向量的集合 U,其中是所有策略的集合,且
。U 中的每个元素是一个二维向量,其中的条目分别代表代理人和委托人的效用。理想情况下,我们希望在 U 中找到最佳效用向量:一个对应于 B-可实现策略并最大化委托人效用的向量。然而,我们有两个障碍。
第一个障碍
首先,构造 U 是不可行的,因为它的大小可能是指数级的。我们通过将两名玩家的奖励函数离散化为小常数的倍数来规避这一点。离散化奖励函数确保了效用也将是
-离散的。由于 H 构成了最高效用的上限(回想一下我们假设每个状态-动作对的
、
均以 1 为界),每个玩家最多可以有
种不同的效用;因此,
-离散集合 U 最多可以有
个不同的向量。帕累托前沿,即帕累托有效效用的集合,最多包含
个向量。我们的算法自底向上地传播帕累托有效效用。

Pareto frontier 就是那些“没有被另一个策略在两个维度上同时超过”的点


第二个障碍
第二个障碍是,我们计算出的帕累托前沿包含了对应于非 B-可实现策略从而不可行的效用向量。以下观察断言我们可以快速区分属于 B-可实现策略的效用向量。
观察 2. 如果转移函数是确定性的,那么一个策略是 B-可实现的当且仅当
。
因为 Pareto frontier 只说明一个策略在“Agent 原始收益”和“Principal 收益”之间是有效权衡点,但它没有说明 Principal 是否有足够预算让 Agent 愿意选这个策略。
换句话说:
Pareto 高效≠可实施

4.1 DFAR 算法

DFAR 算法接收实例参数,我们假设对于某个常数,
和
是
-离散的(推论 1 解释了如何放宽这个假设),并输出一个最优的
。
- DFAR 首先在第 1 行对每个状态 s 将集合
初始化为空集。
- 在第 2 行,我们将
的诱导图中的终止状态集合。(如果状态 s是终止状态,没有后续动作了。从终止状态开始,Agent 和 Principal后续都拿不到奖励,所以效用向量是:0,0)
- 第 3 行将
初始化为 Terminal (S) 的集合。(Spass表示已经处理过的状态集合。)
- 第 4 行是一个 while 循环,执行直到
- 在第 5 行,我们挑选一个尚未处理的状态 s,即
的一个终止状态。由于我们处理状态的方式,
。此外,由于图是无环的,这样的状态 s 必定存在。(选一个它的所有后继都已经处理过的状态)
- 在第 6 行,我们令
表示在 s 处执行
,
包含了从状态
开始的所有可达到的效用。换句话说,
,对应于某个策略
(其中
)的所有向量
。在此更新之后,
。

- 在第 7 行,我们移除帕累托无效的效用向量。我们在附录中证明了这可以在线性对数时间内完成。
- 结束 while 循环,第 8 行更新了
- 当我们在达到第 10 行时,
包含了所有可达到的效用向量,包括需要大于 B 的预算且因此不可行的效用向量。观察 2 协助区分与 B-可实现策略相关联的效用向量。我们选取最大化委托人效用的效用向量
,并自上而下地重建实现它的策略。
- 最后,我们通过对每一对
设置方程(1)的右侧来重建诱导该策略的最小实现

接下来,我们介绍 DFAR 提供的正式保证。定理五
定理 5. 令
是一个无环且确定性的实例,并假设对于小的常数
和
是
,且其输出
,
。
我们还利用定理 5 来处理非-离散的奖励函数。


根据下面的推论 1,DFAR 为一般奖励函数 和
提供了双标准近似。也就是说,它需要
的预算来提供
的加性近似。
推论 1. 令 I (S, A, P, RA, RP, H. B) 是一个无环且确定性的实例,令
为一个对于小常数
和
的实例。如果 DFAR(I) 输出
。

4.2 具有循环的确定性决策过程
我们开发 DFAR 是基于底层 DDP 没有循环的假设。在本小节中,我们讨论具有循环的 DDP 的情况。请注意,任何具有有限步长 H 的 DDP 都可以转化为具有 SH 个状态的无环分层图。由于篇幅限制,我们在附录中正式描述了这一构造。至关重要的是,与原始 DDP 中的 S 个状态相比,由此产生的 DDP 是无环的,并且具有 SH 个状态。因此,DFAR 运行时间保证中的每个因子 S 都应该替换为 ;因此,在修改后的无环 DDP 实例上执行 DFAR 的耗时为
。

5 Discussion
本文提出了一种在马尔可夫决策过程上进行委托代理建模的新方法,其中委托方具有有限的预算来调整代理的奖励函数。我们针对两类广泛的问题提出了两种高效的算法:随机树和有限 horizon 的动态规划分解问题。我们在附录中通过仿真实验验证了部分理论结果。此外,为了节省篇幅,我们还将若干扩展内容置于附录中。未来的研究方向包括为这两类实例以及更一般的实例设计更优的算法。另一个研究方向是处理学习场景,即当委托方、代理方或两者均存在不完全信息时的情形。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)