LangChain模型调用详解
RAG
Source:多种类型的数据源:视频、图片、文本、代码、文档等。
Load:将多源异构数据统一加载为文档对象。
Transform:对文档进行转换和处理,比如将文本切分为小块。
Embed:将文本编码为向量。
Store:将向量化后的数据存储起来。
Retrieve:从文本库中检索相关的文本段落。
调用模型
将api_key和base_url写在变量中
# pip install langchain langchain-openai
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1", # 平台提供的 URL
api_key="sk-...", # 平台提供的 API-Key
)
completion = client.chat.completions.create(
model="openai/gpt-oss-20b:free", # 模型名称
messages=[{"role": "user", "content": "将'你好'翻译成意大利语"}], # 用户输入
)
print(completion.choices[0].message.content)管理api_key和base_url
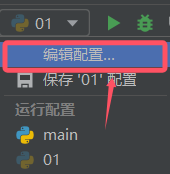
1.将api_key和base_url写到环境变量中,读取环境变量来获取api_key和base_url
点击编辑配置
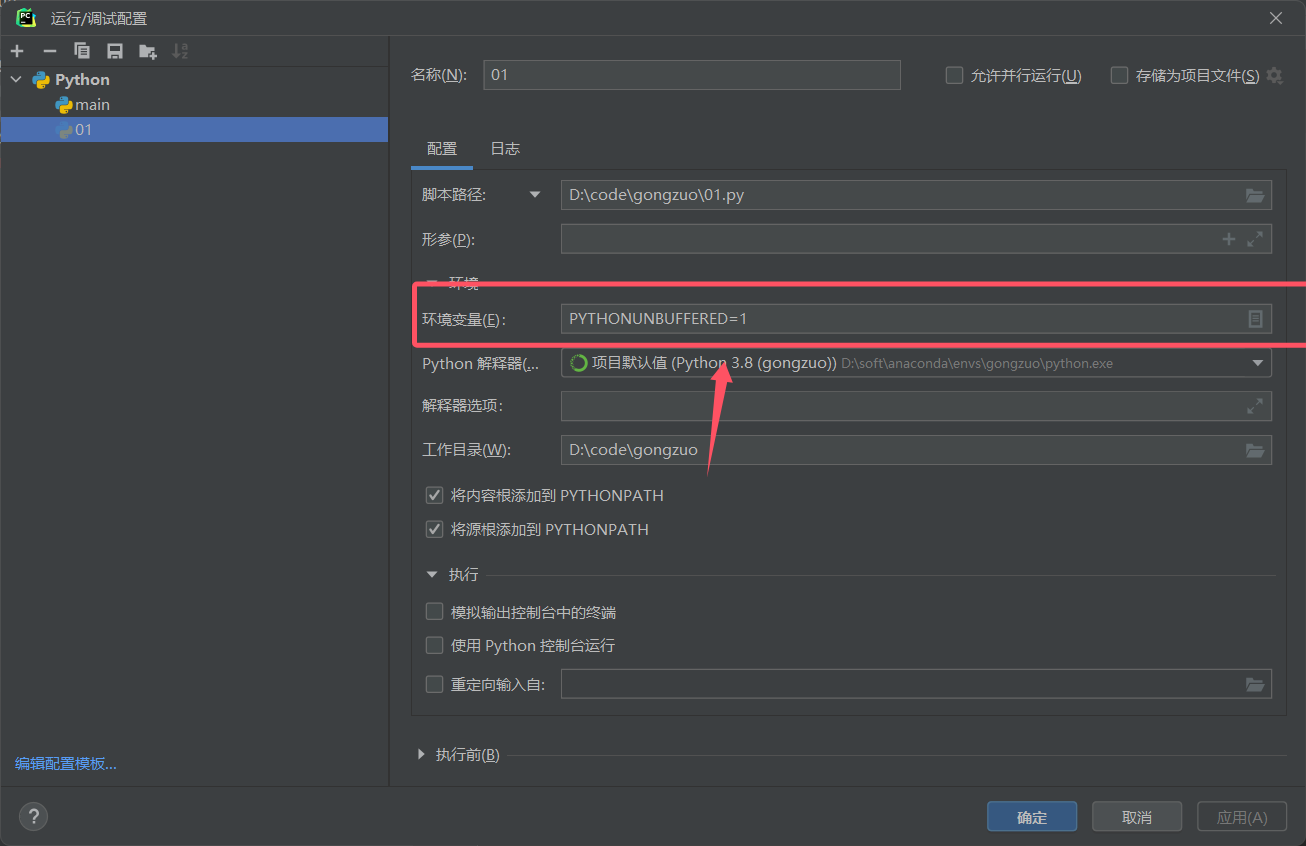
点击环境变量
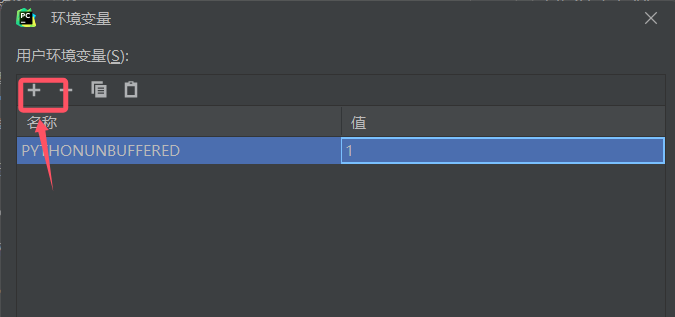
添加环境变量
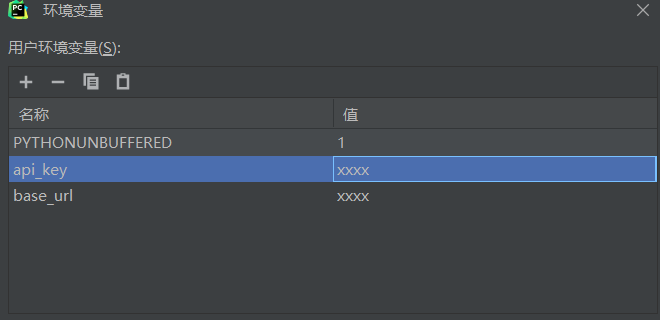
添加api_key和base_url
在代码中通过 os.getenv() 读取
import os
from openai import OpenAI
client = OpenAI(
base_url=os.getenv("base_url"),
api_key=os.getenv("api_key"),
)
completion = client.chat.completions.create(
model="openai/gpt-oss-20b:free",
messages=[{"role": "user", "content": "你好"}],
)
print(completion.choices[0].message.content)2.通过配置文件来配置,在代码中加载配置文件(推荐)
创建 .env 文件(项目根目录)
OPENAI_API_KEY="sk-…"
OPENAI_BASE_URL=" https://openrouter.ai/api/v1"方式一:显式读取 .env 中的环境变量
# pip install python-dotenv
import os
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv() # 默认加载 .env
client = OpenAI(
base_url=os.getenv("OPENAI_BASE_URL"), # 平台提供的 URL
api_key=os.getenv("OPENAI_API_KEY"), # 平台提供的 API Key
)
completion = client.chat.completions.create(
model="openai/gpt-oss-20b:free",
messages=[{"role": "user", "content": "将'你好'翻译成意大利语"}],
)
print(completion.choices[0].message.content)方式二:依靠 OpenAI 的默认行为读取 .env 环境变量(推荐)
OpenAI 在创建时,会自动到环境变量中找 OPENAI_API_KEY 以及OPENAI_BASE_URL。如果在 .env 中配置的名字和上面的两个名字一样,无需再次赋值,只通过 dotenv.load_dotenv() 加载环境配置信息即可。
# pip install python-dotenv
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv() # 默认加载 .env
client = OpenAI()
completion = client.chat.completions.create(
model="openai/gpt-oss-20b:free",
messages=[{"role": "user", "content": "将'你好'翻译成意大利语"}],
)
print(completion.choices[0].message.content)LangChain API调用模型
输入:接受文本 PromptValue 或消息列表 List[BaseMessage],每条消息需指定角色(如 SystemMessage、HumanMessage、AIMessage)
输出:返回带角色的消息对象(BaseMessage 子类),通常是 AIMessage
import os
from langchain.chat_models import init_chat_model
from langchain.messages import SystemMessage, HumanMessage, AIMessage
# 模型初始化相关参数
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
# 提示词消息列表
messages = [
SystemMessage(content="你是一个诗人"),
HumanMessage(content="写一首关于春天的诗"),
]
resp = llm.invoke(messages)
print(type(resp)) # <class 'langchain_core.messages.ai.AIMessage'>
print(resp.content)模型初始化相关参数
初始化一个模型最简单的方法就是使用 init_chat_model,并设置必要的参数
|
参数 |
说明 |
|
model |
模型名称或标识符 |
|
base_url |
发送请求的 API 端点的 URL。常由模型的提供商提供 |
|
api_key |
与模型提供商进行身份验证所需的 API 密钥 |
|
temperature |
控制模型输出的随机性。数字越高,回答越有创意;数字越低,回答越确定 |
|
timeout |
在取消请求之前,等待模型响应的最大时间(以秒为单位) |
|
max_tokens |
限制响应中的总tokens 数量,控制输出长度 |
|
max_retries |
请求失败时系统尝试重新发送请求的最大次数 |
对话模型的Message
对话模型的输入可以是文本提示、消息提示或是字典格式。
(1)文本提示
文本提示是字符串,适用于不需要保留对话历史的直接生成任务。
resp = llm.invoke("你好")(2)消息提示
将消息对象列表输入模型,方便管理对话历史,包含系统指令以及处理多模态数据。
messages = [
SystemMessage("你是个诗人"),
HumanMessage("写首关于春天的诗"),
]
resp = llm.invoke(messages)(3)字典格式
也可以按照 OpenAI 聊天补全格式创建字典列表组成消息。一条消息通常包含 role(角色)、content(内容)、metadata(元数据)。
messages = [
{"role": "system", "content": "你是个诗人"}, # 系统
{"role": "user", "content": "写首关于春天的诗"}, # 角色
]
resp = llm.invoke(messages)(4)消息类型
|
消息类型 |
描述 |
|
SystemMessage |
代表一组初始指令,用于引导模型的行为。可以使用系统消息来设定语气、定义模型的角色,并建立响应的指导方针 |
|
HumanMessage |
表示用户输入 |
|
AIMessage |
模型生成的响应,包括文本内容、工具调用和元数据 |
|
ToolMessage |
表示工具调用的输出 |
调用方法
(1)流式调用和非流式调用
- 非流式调用:用户提出需求请编写一首诗,系统在静默数秒后突然弹出了完整的诗歌。如同一种“提交请求,等待结果”的流程,实现简单,但体验单调。
- 流式调用:用户提问,请编写一首诗,当问题刚刚发送,系统就开始一字一句(逐个token)进行回复,更像是“实时对话”,贴近人类交互的习惯。
非流式调用:invoke() 调用
import os
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
messages = [
{"role": "system", "content": "你是一名数学家"},
{"role": "user", "content": "请证明黎曼猜想"},
]
resp = llm.invoke(messages)
print(resp.content)流式调用:stream() 流式输出
import os
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
messages = [
{"role": "system", "content": "你是一名数学家"},
{"role": "user", "content": "请证明以下黎曼猜想"},
]
# 使用 stream() 方法流式输出
for chunk in llm.stream(messages):
# 逐个打印内容块,并刷新缓冲区以即时显示内容
print(chunk.content, end="", flush=True)(2)批次调用与非批次调用
批次调用:将一组独立的请求批量发送给模型并行处理。
使用batch() 批量调用
import os
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
messages = [
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于春天的诗"},
],
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于夏天的诗"},
],
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于秋天的诗"},
],
]
resp = llm.batch(messages) # 批量调用,返回一个消息列表
print(resp)(3)同步调用和异步调用
- 同步调用:每个操作依次执行,直到当前操作完成后才开始下一个操作,总的执行时间是各个操作时间的总和。
- 异步调用:允许程序在等待某些操作完成时继续执行其他任务,而不是阻塞等待。这在处理 I/O 操作(如网络请求、文件读写等)时特别有用,可以显著提高程序的效率和响应性。
同步调用:使用 invoke() 同步调用
import os
import time
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
messagess = [
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于春天的诗"},
],
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于夏天的诗"},
],
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于秋天的诗"},
],
]
start_time = time.time()
resps = [llm.invoke(messages) for messages in messagess]
print(resps)
end_time = time.time()
print(f"Total time: {end_time - start_time}")
# Total time: 17.789486169815063异步调用:使用 ainvoke() 异步调用
import os
import time
import asyncio # 支持异步调用 协程
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
messagess = [
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于春天的诗"},
],
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于夏天的诗"},
],
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于秋天的诗"},
],
]
# 打包所有任务
async def async_invoke():
tasks = [llm.ainvoke(messages) for messages in messagess]
return await asyncio.gather(*tasks)
start_time = time.time()
resps = asyncio.run(async_invoke())
print(resps)
end_time = time.time()
print(f"Total time: {end_time - start_time}")
# Total time: 8.280137062072754
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)