Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention翻译
⚠️ 在开始阅读之前,如果你对 实时 Agent / 数字人 / 多模态系统 / LiveKit 架构 感兴趣,
欢迎先到 GitHub 给项目点一个 ⭐ Star,这是对开源作者最大的支持。
🚀 AlphaAvatar 项目地址(强烈建议先收藏,该项目正在持续更新维护):
👉 https://github.com/AlphaAvatar/AlphaAvatar
🚀 AIPapers 项目地址(具有更全的有关LLM/Agent/Speech/Visual/Omni论文分类):
👉 https://github.com/AlphaAvatar/AIPaperNotes
摘要
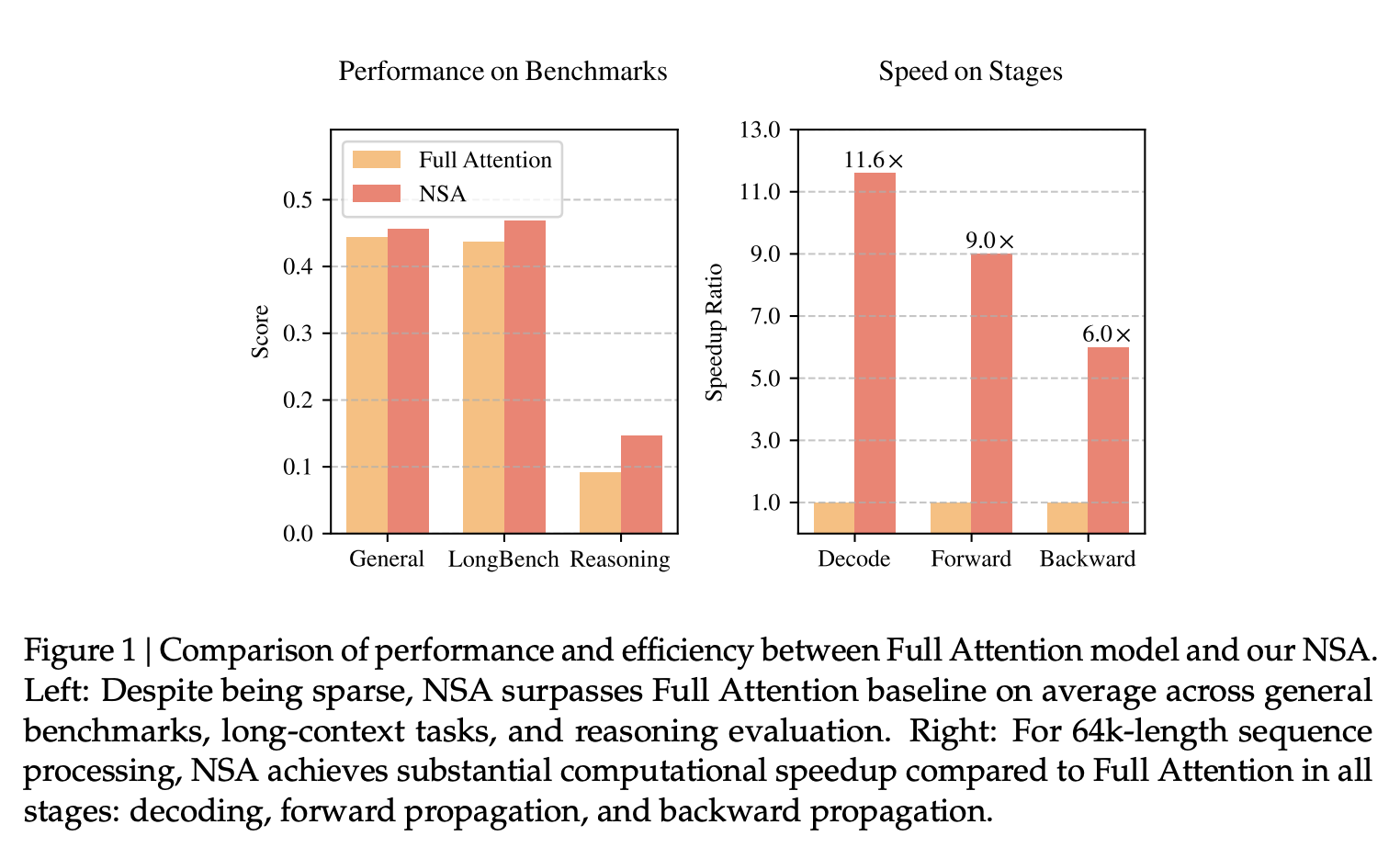
长上下文建模对于下一代语言模型至关重要,然而,标准注意力机制的高计算成本带来了巨大的计算挑战。稀疏注意力机制为在保持模型性能的同时为提高效率提供了一个很有前景的方向。我们提出了 Natively trainable Sparse Attention ——NSA,它将算法创新与硬件优化相结合,实现了高效的长上下文建模。NSA采用动态分层稀疏策略,结合了粗粒度 token 压缩和细粒度 token 选择,从而兼顾了全局上下文感知和局部精度。我们的方法通过两项关键创新推进了稀疏注意力机制的设计:(1)我们通过算术强度平衡的算法设计实现了显著的加速,并针对现代硬件进行了实现优化。(2)我们实现了端到端训练,在不牺牲模型性能的前提下减少了预训练计算。如图 1 所示,实验表明,使用 NSA 预训练的模型在通用基准测试、长上下文任务和基于指令的推理任务中,性能均达到或超过了全注意力模型。同时,在解码、前向传播和后向传播方面,NSA 在 64k 长度序列上实现了比 Full Attention 更大的速度提升,验证了其在整个模型生命周期中的效率。
1.Introduction
研究界日益认识到,长上下文建模是下一代大语言模型的一项关键能力,这主要得益于各种现实世界的应用,例如深度推理、仓库级代码生成以及多轮自主 Agent 系统。近期取得的突破性进展,包括 OpenAI 的 o 系列模型、DeepSeek-R1 和 Gemini 1.5 Pro,使得模型能够处理整个代码库、长篇文档,在数千个 token 中保持连贯的多轮对话,并跨远距离依赖关系执行复杂的推理。然而,随着序列长度的增加,传统注意力机制的高复杂度会成为严重的延迟瓶颈。理论估计表明,在解码 64k 长度的上下文时,使用 softmax 架构的注意力计算会占用总延迟的 70%–80%,这凸显了开发更高效注意力机制的迫切需求。
高效的长上下文建模的一种自然方法是利用 softmax 注意力机制固有的稀疏性,通过选择性地计算关键 query-key 对,可以在保持性能的同时显著降低计算开销。近期的研究进展通过多种策略验证了这一潜力:KV-cache 驱逐方法、分块 KV-cache 选择方法以及基于采样、聚类或哈希的选择方法。尽管这些策略前景广阔,但现有的稀疏注意力方法在实际应用中往往存在不足。许多方法未能实现与理论收益相当的速度提升;此外,大多数方法缺乏有效的训练时间支持,无法充分利用注意力稀疏模式。
为了克服这些局限性,有效稀疏注意力机制的部署必须应对两大关键挑战:(1) 硬件对齐的推理加速:将理论上的计算量减少转化为实际的速度提升,需要在预填充和解码阶段采用硬件友好的算法设计,以缓解内存访问和硬件调度瓶颈;(2) 训练算法设计:利用可训练算子实现端到端计算,从而在保持模型性能的同时降低训练成本。这些要求对于实现快速长上下文推理或训练的实际应用至关重要。然而,在考虑这两个方面时,现有方法仍然存在明显的不足。
为了实现更有效率的稀疏注意力机制,我们提出了 NSA,一种原生可训练的稀疏注意力架构,它集成了分层 token 建模。如图 2 所示,NSA 通过将 key-value 对组织成时间块,并通过三条注意力路径进行处理,从而减少了每次查询的计算量:压缩的粗粒度 token、选择性保留的细粒度 token 以及用于局部上下文信息的滑动窗口。然后,我们实现了专门的内核来最大限度地提高其实际效率。NSA 针对上述关键需求引入了两项核心创新:(1)硬件对齐系统:针对 Tensor Core 利用率和内存访问优化分块稀疏注意力,确保均衡的计算强度。(2)训练感知设计:通过高效的算法和反向算子实现稳定的端到端训练。这种优化使 NSA 能够同时支持高效部署和端到端训练。
我们通过在真实语言语料库上进行全面的实验来评估 NSA。我们使用一个包含 260B token、27B 参数的 Transformer 骨干网络进行预训练,并在通用语言评估、长上下文评估和链式推理评估中评估 NSA 的性能。此外,我们在 A100 GPU 使用优化的 Triton 实现上进一步比较了内核速度。实验结果表明,NSA 的性能与全注意力基线相当或更优,同时优于现有的稀疏注意力方法。此外,与全注意力相比,NSA 在解码、前向和后向阶段均实现了显著的加速,并且序列越长,加速比越高。这些结果验证了我们设计的分层稀疏注意力机制有效地平衡了模型能力和计算效率。
2.Rethinking Sparse Attention Methods
现在稀疏注意力方法在降低 Transformer 模型的理论计算复杂度方面取得了显著进展。然而,大多数方法主要在推理阶段应用稀疏性,同时保留预训练的全注意力骨干网络,这可能会引入架构偏差,限制其充分发挥稀疏注意力优势的能力。在介绍我们自主设计的稀疏架构之前,我们将从两个关键角度系统地分析这些局限性。
2.1 The Illusion of Efficient Inference
尽管许多方法在注意力计算方面实现了稀疏性,但由于以下两个挑战,它们未能相应地降低推理延迟:
Phase-Restricted Sparsity。诸如 H2O (Zhang et al., 2023b) 等方法在自回归解码阶段应用稀疏性,但在预填充阶段需要计算密集型的预处理(例如注意力图计算、索引构建)。相比之下,诸如 MInference (Jiang et al., 2024) 等方法则仅关注预填充阶段的稀疏性。这些方法无法在所有推理阶段实现加速,因为至少有一个阶段的计算成本与完全注意力机制相当。阶段专门化降低了这些方法在以预填充为主的工作负载(例如书籍摘要和代码补全)或以解码为主(例如长链推理)的工作负载中的加速能力。
Incompatibility with Advanced Attention Architecture。一些稀疏注意力方法无法适应现代高效的解码架构,例如 Mulitiple-Query Attention (MQA) 和 Grouped-Query Attention (GQA)。这些架构通过在多个 query 头之间共享 key-value 对(KV),显著降低了解码过程中的内存访问瓶颈。例如,在 Quest(Tang 等,2024)等方法中,每个注意力头独立选择其 KV-cache 子集。虽然这种方法在多头注意力(MHA)模型中展现出一致的计算稀疏性和内存访问稀疏性,但在基于 GQA 等架构的模型中则呈现出不同的情况。在 GQA 等架构中,KV-cache 的内存访问量对应于同一 GQA 组内所有 query 头选择结果的并集。这种架构特性意味着,尽管这些方法可以减少计算操作,但所需的 KV-cache 内存访问量仍然相对较高。这一限制迫使我们做出一个关键的选择:虽然一些稀疏注意力方法可以减少计算量,但它们分散的内存访问模式与先进架构的高效内存访问设计相冲突。
这些局限性源于许多现有的稀疏注意力方法侧重于 key-value 缩减或理论计算量缩减,但在高级框架或后端中难以显著降低延迟。这促使我们开发结合先进架构和硬件高效实现的算法,以充分利用稀疏性来提升模型效率。
2.2 The Myth of Trainable Sparsity
我们对原生可训练稀疏注意力机制的探索源于对仅用于推理的方法进行分析后得出的两个关键见解:(1) 性能下降:事后应用稀疏性会迫使模型偏离其预训练的优化轨迹。正如 Chen et al. (2024b) 所证明的,前 20% 的注意力机制只能覆盖总注意力得分的 70%,这使得预训练模型中的检索头等结构在推理过程中容易受到剪枝的影响。(2) 训练效率要求:高效处理长序列训练对于现代长 LLM 的开发至关重要。这包括在更长的文档上进行预训练以增强模型容量,以及后续的自适应阶段,例如长上下文微调和强化学习。然而,现有的稀疏注意力方法主要针对推理,而训练中的计算挑战在很大程度上仍未得到解决。这种局限性阻碍了通过高效训练开发更强大的长上下文模型。此外,将现有稀疏注意力机制应用于训练的尝试也暴露出一些挑战:
Non-Trainable Components。诸如 ClusterKV(包含 k-means 聚类)和 MagicPIG(包含基于 SimHash 的选择)等方法中的离散操作会在计算图中造成不连续性。这些不可训练的组件会阻碍梯度在 token 选择过程中的流动,从而限制模型学习最优稀疏模式的能力。
Inefficient Back-propagation。一些理论上可训练的稀疏注意力方法在实际训练中效率低下。例如,HashAttention 等方法采用的基于 token 粒度的选择策略,导致在注意力计算过程中需要从 KV-cache 加载大量单个 token。这种非连续内存访问阻碍了快速注意力技术(例如FlashAttention)的有效应用,因为这些技术依赖于连续内存访问和分块计算来实现高吞吐量。因此,这些实现被迫降低硬件利用率,从而显著降低了训练效率。
2.3 Native Sparsity as an Imperative
推理效率和训练可行性方面的这些局限性促使我们对稀疏注意力机制进行根本性的重新设计。我们提出了 NSA,一个原生稀疏注意力框架,它同时解决了计算效率和训练要求的问题。在接下来的章节中,我们将详细介绍NSA的算法设计和算子实现。
3.Methodology
我们的技术方法涵盖算法设计和内核优化。在接下来的小节中,我们首先介绍我们方法论的背景。然后,我们介绍 NSA 的总体框架,以及其关键算法组件。最后,我们详细介绍我们针对硬件优化的内核设计,该设计最大限度地提高了实际效率。
3.1 Background
注意力机制 广泛应用于语言建模中,其中每个query token qt\textbf q_tqt 计算其与所有前面的 key k:t\textbf k_{:t}k:t 的相关性得分,从而生成一个加权 value v:t\textbf v_{:t}v:t。形式上,对于长度为 ttt 的输入序列,注意力操作定义如下:
ot=Attn(qt,k:t,v:t)(1)\textbf o_t=Attn(\textbf q_t,\textbf k_{:t},\textbf v_{:t})\tag{1}ot=Attn(qt,k:t,v:t)(1)
其中 Attn 表示注意力函数:
Attn(qt,k:t,v:t)=∑i=1tat,ivi∑j=1tat,j,at,i=eqtTkidk.(2)Attn(\textbf q_t,\textbf k_{:t},\textbf v_{:t})=\sum^t_{i=1}\frac{a_{t,i}\textbf v_i}{\sum^t_{j=1}a_{t,j}},\quad a_{t,i}=e^{\frac{\textbf q^T_t\textbf k_i}{\sqrt{d_k}}}.\tag{2}Attn(qt,k:t,v:t)=i=1∑t∑j=1tat,jat,ivi,at,i=edkqtTki.(2)
这里,at,ia_{t,i}at,i 表示 qt\textbf q_tqt 和 ki\textbf k_iki 之间的注意力权重,dkd_kdk 是 key 的特征维度。随着序列长度的增加,注意力计算在整体计算成本中占据越来越大的比例,给长上下文处理带来了巨大的挑战。
算术强度 是指计算操作次数与内存访问次数的比值。它从根本上影响着硬件上的算法优化。每个 GPU 都有一个临界算术强度,该强度由其峰值计算能力和内存带宽决定,计算方法为这两个硬件极限的比值。对于计算任务,高于此临界阈值的算术强度会受到计算能力的限制(受限于 GPU 的浮点运算能力),而低于此阈值的算术强度则会受到内存的限制(受限于内存带宽)。
具体来说,对于因果自注意力机制,在训练和预填充阶段,批量矩阵乘法和注意力计算会消耗大量的算术运算,使得这些阶段在现代加速器上成为计算密集型的。相比之下,自回归解码由于每次前向传播生成一个 token,但需要加载整个 KV-cache,因此会受到内存带宽的限制,导致算术强度较低。这就导致了不同的优化目标——降低训练和预填充阶段的计算成本,同时减少解码阶段的内存访问。
3.2 Overall Framework
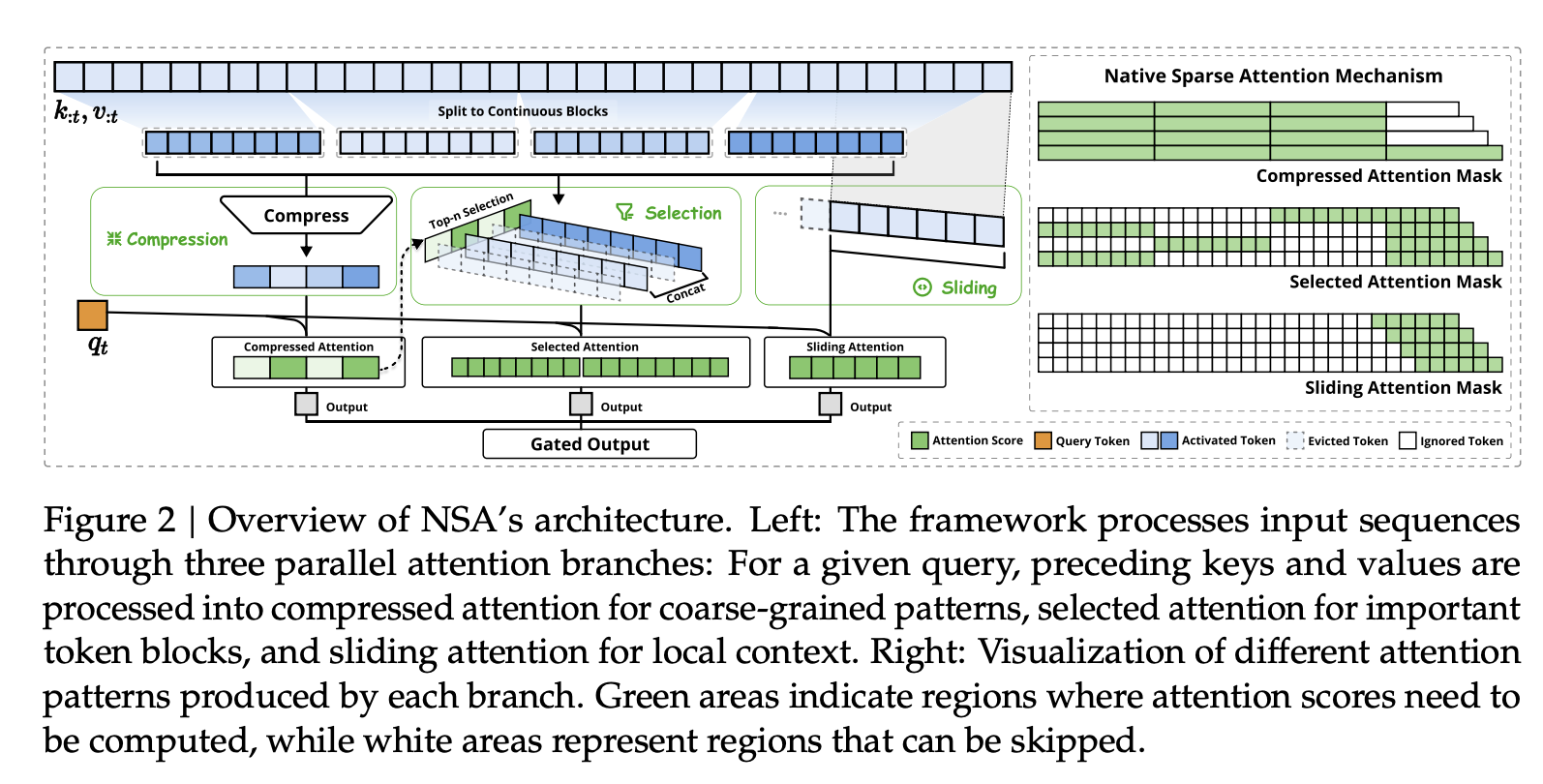
为了利用注意力机制在自然稀疏模式中的潜力,对于给定的每个 query qt\textbf q_{t}qt,我们提出用一组更紧凑、信息表示更丰富的 key-value 对 K~t,V~t\tilde K_{t}, \tilde V_tK~t,V~t 来替换公式 (1) 中的原始 key-value 对 k:t,v:t\textbf k_{:t}, \textbf v_{:t}k:t,v:t。具体来说,我们将优化后的注意力输出正式定义如下:
K~t=fK(q:t,k:t,v:t),V~t=fV(qt,k:t,v:t)(3)\tilde K_t=f_K(\textbf q_{:t},\textbf k_{:t}, \textbf v_{:t}),\quad \tilde V_t=f_V(\textbf q_t,\textbf k_{:t},\textbf v_{:t})\tag{3}K~t=fK(q:t,k:t,v:t),V~t=fV(qt,k:t,v:t)(3)
ot∗=Attn(qt,K~t,V~t)(4)\textbf o^*_t=Attn(\textbf q_t,\tilde K_t,\tilde V_t)\tag{4}ot∗=Attn(qt,K~t,V~t)(4)
其中,K~t,V~t\tilde K_t,\tilde V_tK~t,V~t 是基于当前 query qt\textbf q_tqt 和上下文记忆 k:𝑡,v:t\textbf k_{:𝑡},\textbf v_{:t}k:t,v:t 动态构建的。我们可以设计各种映射策略来获得不同类别的 K~tc,V~tc\tilde K^c_t, \tilde V^c_tK~tc,V~tc,并按如下方式组合它们:
ot∗=∑c∈Cgtc⋅Attn(qt,K~tc,V~tc).(5)\textbf o^*_t=\sum_{c\in \mathcal C}g^c_t\cdot Attn(\textbf q_t,\tilde K^c_t,\tilde V^c_t).\tag{5}ot∗=c∈C∑gtc⋅Attn(qt,K~tc,V~tc).(5)
如图 2 所示,NSA 有三种映射策略 C={cmp,slc,win}\mathcal C = \{cmp, slc, win\}C={cmp,slc,win},分别代表 key-value 对的压缩、选择和滑动窗口。gtc∈[0,1]g^c_t ∈ [0, 1]gtc∈[0,1] 是对应策略 ccc 的门控得分,它通过多层感知器 (MLP) 和 sigmoid 激活函数从输入特征中导出。令 NtN_tNt 表示重新映射的 key/value 的总数:
Nt=∑c∈Csize[K~tc].(6)N_t=\sum_{c\in \mathcal C}size[\tilde K^c_t].\tag{6}Nt=c∈C∑size[K~tc].(6)
我们通过确保 Nt≪tN_t ≪ tNt≪t 来保持较高的稀疏度。
3.3 Algorithm Design
在本小节中,我们介绍我们的重映射策略 fkf_kfk 和 fVf_VfV 的设计:token 压缩、token 选择和滑动窗口。
3.3.1 Token Compression
通过将连续的 key 或 value 块聚合为块级表示,我们可以获得压缩的 key 和 value,它们能够捕获整个块的信息。形式上,压缩 key 表示定义为:
K~tcmp=fKcmp(k:t)={φ(kid+1:id+l)∣0≤i≤⌊t−ld⌋}(7)\tilde K^{cmp}_t=f^{cmp}_K(\textbf k_{:t})=\left\{\varphi(\textbf k_{id+1:id+l})|0\le i\le \left\lfloor \frac{t - l}{d} \right\rfloor\right\}\tag{7}K~tcmp=fKcmp(k:t)={φ(kid+1:id+l)∣0≤i≤⌊dt−l⌋}(7)
其中,lll 为块长度,ddd 为相邻块之间的滑动步长,φ\varphiφ 是一个可学习的多层感知器 (MLP),它使用块内位置编码将块中的 key 映射到单个压缩 key。K~tcmp∈Rd𝑘×⌊t−ld⌋\tilde K^{cmp}_t ∈ \mathbb R^{d_𝑘×⌊\frac{t-l}{d}⌋}K~tcmp∈Rdk×⌊dt−l⌋ 是由压缩 key 组成的张量。通常,我们采用 d<ld < ld<l 来缓解信息碎片化。类似的公式也适用于压缩 value 表示 V~tcmp\tilde V^{cmp}_{t}V~tcmp。压缩表示能够捕获更粗粒度的高层语义信息,并降低注意力机制的计算负担。
3.3.2 Token Selection
仅使用压缩 key 可能会丢失重要的细粒度信息,因此我们需要有选择地保留单个 key 和 value。下面我们将介绍我们高效的 token 选择机制,该机制能够以较低的计算开销识别并保留最相关的 token。
Blockwise Selection。我们的选择策略以空间连续块的形式处理 key-value 序列,其主要动机在于两个关键因素:硬件效率考量和注意力分数的固有分布模式。分块选择对于在现代 GPU 上实现高效计算至关重要。这是因为与基于随机索引的读取相比,现代 GPU 架构在连续块访问方面展现出显著更高的吞吐量。此外,分块计算能够优化 Tensor Core 的利用率。这种架构特性使得分块内存访问和计算成为高性能注意力机制实现的基本原则,FlashAttention 的基于块的设计便是一个很好的例证。分块选择遵循注意力分数的固有分布模式。先前的研究表明,注意力分数通常表现出空间连续性,这意味着相邻的 key 往往具有相似的重要性级别。我们在 6.2 节中的可视化也展示了这种空间连续模式。
为了实现分块选择,我们首先将 key-value 对序列分割成选择块。为了识别对注意力计算最为重要的块,我们需要为每个块分配重要性分数。下面我们将介绍计算这些块级重要性分数的方法。
Importance Score Computation。计算块重要性分数可能会带来显著的开销。幸运的是,压缩 token 的注意力计算会产生中间注意力分数,我们可以利用这些分数来推导出选择块重要性分数,公式如下:
ptcmp=Softmax(qtTK~tcmp),(8)\textbf p^{cmp}_t=Softmax(q^T_t\tilde K^{cmp}_t),\tag{8}ptcmp=Softmax(qtTK~tcmp),(8)
其中 ptcmp∈R⌊t−ld⌋+1\textbf p^{cmp}_t ∈ \mathbb R^{⌊\frac{t−l}{d}⌋+1}ptcmp∈R⌊dt−l⌋+1 表示 qtq_tqt 与压缩 key K~tcmp\tilde K^{cmp}_tK~tcmp 之间的注意力得分。令 𝑙′ 表示选择块的大小。当压缩块和选择块共享相同的分块方案时,即 𝑙′=𝑙=𝑑𝑙^′ = 𝑙 = 𝑑l′=l=d,我们可以直接通过 ptslc=ptcmp\textbf p^{slc}_t = \textbf p^{cmp}_tptslc=ptcmp 得到选择块的重要性得分 ptslc\textbf p^{slc}_tptslc。对于分块方案不同的情况,我们根据选择块的空间关系推导其重要性得分。给定 𝑙⩽𝑙′,𝑑∣𝑙𝑙 ⩽ 𝑙^′, 𝑑 | 𝑙l⩽l′,d∣l 且 𝑑∣𝑙′𝑑 | 𝑙^′d∣l′,我们有:
ptslc[j]=∑m=0l′d−1∑n=0ld−1ptcmp[l′dj−m−n]\textbf p_t^{\mathrm{slc}}[j]= \sum_{m=0}^{\frac{l'}{d}-1} \sum_{n=0}^{\frac{l}{d}-1} \textbf p_t^{\mathrm{cmp}} \left[ \frac{l'}{d} j - m - n \right]ptslc[j]=m=0∑dl′−1n=0∑dl−1ptcmp[dl′j−m−n]
其中 [⋅][·][⋅] 表示用于访问向量元素的索引运算符。对于采用 GQA 或 MQA 的模型,如果 query 头之间共享 KV-cache,则必须确保这些 qeury 头之间块选择的一致性,以最大限度地减少解码期间的 KV-cache 负载。组内各 query 头之间共享的重要性得分正式定义为:
ptslc′=∑h=1Hptslc,(h),(10)\textbf p^{slc'}_t=\sum^H_{h=1}\textbf p_t^{slc,(h)},\tag{10}ptslc′=h=1∑Hptslc,(h),(10)
其中,上标 (h)(h)(h) 表示头索引,HHH 表示每个组中 query 头的数量。这种聚合方式确保了同一组内不同头之间数据块选择的一致性。
Top-n Block Selection。在获得选择块重要性得分后,我们保留按块重要性得分排序的 top-n 个稀疏块中的 token,公式如下:
It={i∣rank(ptslc′[i]≤n)}(11)\mathcal I_t=\{i|rank(\textbf p^{slc'}_t[i]\le n)\}\tag{11}It={i∣rank(ptslc′[i]≤n)}(11)
K~tslc=Cat[{kil′+1:(i+1)l′∣i∈It}],(12)\tilde K^{slc}_t=Cat[\{\textbf k_{il'+1:(i+1)l'}|i\in\mathcal I_t\}],\tag{12}K~tslc=Cat[{kil′+1:(i+1)l′∣i∈It}],(12)
其中 rank(⋅)rank(·)rank(⋅) 表示降序排列的排名位置,rank=1rank = 1rank=1 对应于最高分,It\mathcal I_tIt 是所选块的索引集合,CatCatCat 表示拼接操作。K~tslc∈Rdk×nl′\tilde K^{slc}_t ∈ \mathbb R^{d_k×nl^′}K~tslc∈Rdk×nl′ 是由选择 key 组成的张量。类似的公式也适用于细粒度 value V~tslc\tilde V^{slc}_tV~tslc。所选 key 和 value 随后参与 qt\textbf q_tqt 的注意力计算,其定义见公式 (5)。
3.3.3 Sliding Window
在注意力机制中,局部模式通常适应速度更快,并且可能主导学习过程,从而阻碍模型有效地从压缩和选择 token 中学习。为了解决这个问题,我们引入了一个专门的滑动窗口分支来显式处理局部上下文,使其他分支(压缩和选择)能够专注于学习各自的特征,而不会受到局部模式的干扰。具体来说,我们在窗口 www 中维护最近的 token K~twin=kt−w:t,V~twin=vt−w:t\tilde K^{win}_t = \textbf k_{t−w:t},\tilde V^{win}_t = \textbf v_{t−w:t}K~twin=kt−w:t,V~twin=vt−w:t,并将不同信息源(压缩 token、选择 token 和滑动窗口)的注意力计算隔离到不同的分支中。然后,通过学习到的门控机制聚合这些分支的输出。为了进一步防止注意力分支之间的捷径学习,同时将计算开销降至最低,我们为三个分支提供了独立的 key-value 对。这种架构设计通过防止局部和长程模式识别之间的梯度干扰,实现了稳定的学习,同时引入了最小的开销。
在获得所有三类 key-value 对(K~tcmp,V~tcmp;K~tslc,V~tslc;和K~twin,V~twin\tilde K^{cmp}_t, \tilde V^{cmp}_t; \tilde K^{slc}_t, \tilde V^{slc}_t; 和 \tilde K^{win}_t, \tilde V^{win}_tK~tcmp,V~tcmp;K~tslc,V~tslc;和K~twin,V~twin)后,我们根据公式 (5) 计算最终的注意力输出。结合上述的压缩、选择和滑动窗口机制,这构成了 NSA 的完整算法框架。
3.4 Kernel Design
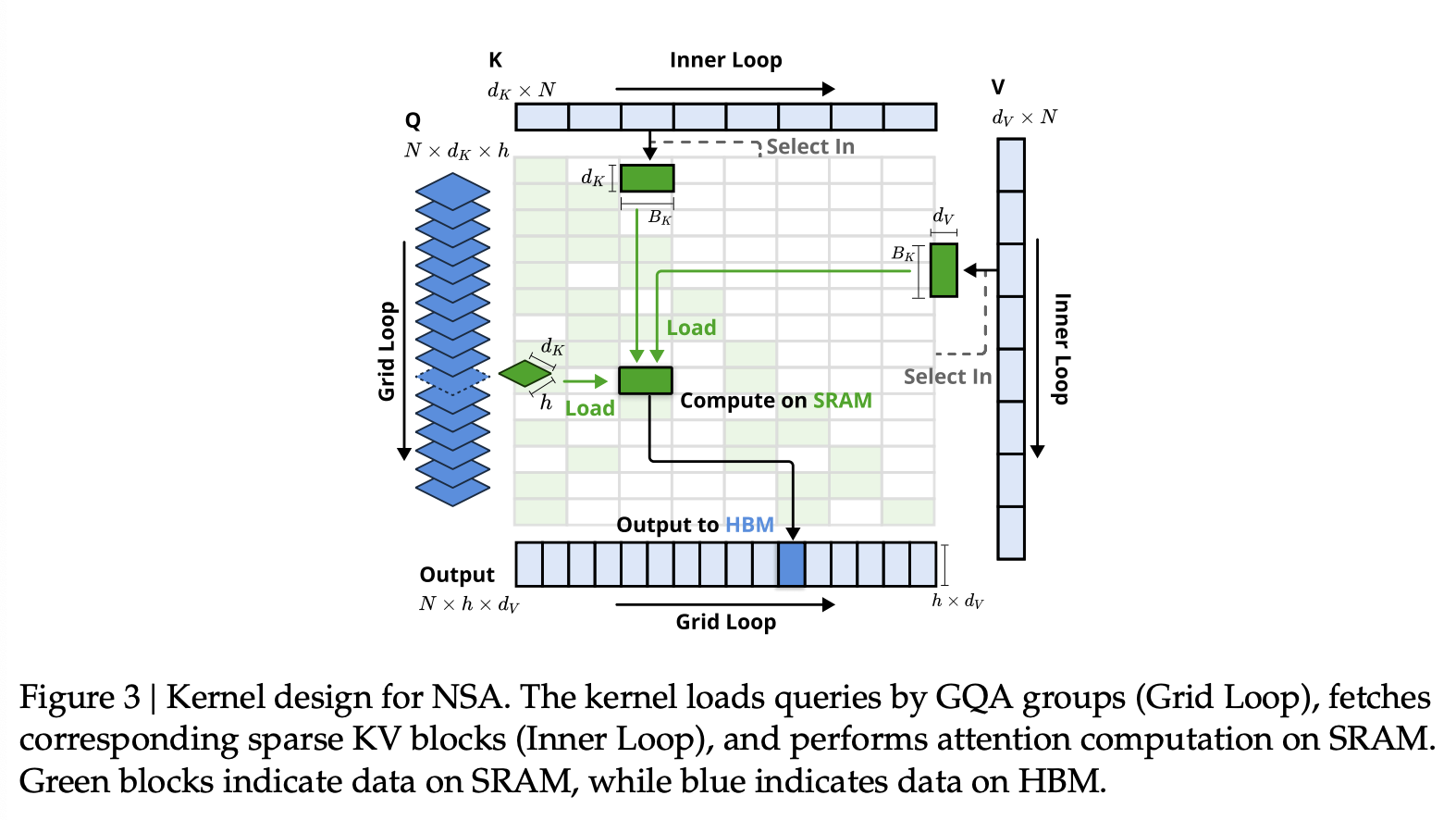
为了在训练和预填充过程中实现与 FlashAttention 相当的加速,我们在 Triton 上实现了硬件对齐的稀疏注意力内核。鉴于 MHA 内存密集且解码效率低下,我们专注于采用共享 KV-Cache 的架构,例如 GQA 和 MQA,并遵循当前最先进的 LLM 算法。虽然压缩和滑动窗口注意力计算与现有的 FlashAttention-2 内核兼容,但我们引入了专门用于稀疏选择注意力的内核设计。如果我们沿用 FlashAttention 将时间连续的query 块加载到 SRAM 中的策略,则会导致内存访问效率低下,因为块内的 query 可能需要不相交的 key-value 块。为了解决这个问题,我们的关键优化在于采用不同的 query 分组策略:对于 query 序列上的每个位置,我们将 GQA 组内的所有 query 头(它们共享相同的稀疏 key-value 块)加载到 SRAM 中。图 3 展示了我们的前向传播实现。所提出的内核架构具有以下主要特征:
- Group-Centric Data Loading。对于每个内循环,加载位置 ttt 处组中的所有 query 头 Q∈R[h,dk]Q ∈ \mathbb R^{[h,d_k]}Q∈R[h,dk] 及其共享的稀疏 key/value 块索引 It\mathcal I_tIt。
- Shared KV Fetching。在内循环中,按顺序将由 It\mathcal I_tIt 索引的连续 key/value 块加载到 SRAM 中,如 K∈R[Bk,dk],V∈R[Bk,dv]K ∈ \mathbb R^{[B_k,d_k]}, V ∈ \mathbb R^{[B_k,d_v]}K∈R[Bk,dk],V∈R[Bk,dv],以最小化内存加载,其中 BkB_kBk 是满足 Bk∣l′B_k|l'Bk∣l′ 的内核块大小。
- Outer Loop on Grid。由于不同 query 块的内部循环长度(与选定块计数 nnn 成正比)几乎相同,因此我们将 queyr/output 循环放在 Triton 的网格调度器中,以简化和优化内核。
该设计通过以下方式实现了接近最优的算术强度:(1)通过分组共享消除冗余的 KV 传输;(2)在 GPU 流式多处理器之间平衡计算工作负载。
4.Experiments
我们从三个方面评估 NSA:(1)通用基准测试性能,(2)长上下文基准测试性能,以及(3)链式推理性能,并与全注意力基线和最先进的稀疏注意力方法进行比较。我们将稀疏计算范式的效率分析推迟到第 5 节,届时我们将详细讨论训练和推理速度。
4.1 Pretraining Setup
遵循当前最先进的 LLM 的常见做法,我们的实验采用了一种结合分组查询注意力(GQA)和混合专家(MoE)的骨干网络,该网络总共包含 27B 个参数,其中 3B 个是有效参数。该模型由30层组成,隐藏层维度为 2560。对于 GQA,我们将分组数设置为 4,共设置了 64 个注意力头。每个注意力头的 query、key 和 value 的隐藏层维度分别配置为 dq=dk=192d_q=d_k=192dq=dk=192 和 dv=128d_v = 128dv=128。对于MoE,我们采用了DeepSeekMoE 结构,其中包含 72 个路由专家和 2 个共享专家,并将 top-k 个专家设置为 6 个。为了确保训练稳定性,我们将第一层的MoE 替换为 SwiGLU 形式的多层感知器(MLP)。所提出的架构在计算成本和模型性能之间实现了有效的平衡。对于 NSA,我们设置压缩块大小 l=32l = 32l=32,滑动步长 d=16d = 16d=16,选择块大小 l′=64l′ = 64l′=64,选择块数量 𝑛=16𝑛 = 16n=16(包括固定激活 1 个初始块和 2 个局部块),以及滑动窗口大小 w=512w = 512w=512。Full Attention 和稀疏注意力模型均在 270B 个 8k 长度文本的 token 上进行预训练,然后使用 YaRN 在 32k 长度文本上继续训练和有监督微调,以实现长上下文适应。两个模型均训练至完全收敛,以确保公平比较。如图 4 所示,我们的 NSA 和 Full Attention 基线的预训练损失曲线均呈现稳定平滑的下降趋势,其中 NSA 的性能始终优于 Full Attention 模型。
5.Efficiency Analysis

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)