LoRA 微调
LoRA(低秩自适应)是应用最广泛的参数高效微调技术之一。以下讨论基于《分类微调大模型》中提供 的垃圾消息分类微调示例。然而,LoRA 微调同样适用于《指令微调大模型》中讨论的监督指令微调。
LoRA 简介
LoRA 是一种通过仅调整模型权重参数的一小部分,使预训练模型更好地适应特定且通常较小的数据集的技术。“低秩”指的是将模型调整限制在总权重参数空间的较小维度子空间,从而有效捕获训练过程中对权重参数变化影响最大的方向。LoRA 方法之所以有用且广受欢迎,是因为它能够高效地对大模型进行特定任务的微调,显著降低了通常所需的计算成本和资源。
假设一个大型权重矩阵 W 与特定层相关联,LoRA 可以应用于大语言模型中的所有线性层。 不过,为了便于说明,我们将重点关注单个层。
在训练深度神经网络时,反向传播过程中我们会学习一个矩阵 ΔW,其中包含了更新原始权重参数以最小化训练期间损失函数所需的信息。接下来,我们会将“权重”一词用作模型权重参数的简写。
在常规训练和微调中,权重更新定义如下所示:
LoRA 方法由 Hu 等人提出,它通过学习权重更新ΔW 的近似值,提供了一种更有效的替代方法:
在此方法中, A 和 B 是两个比W 小得多的矩阵, AB 表示 A 和 B 之间的矩阵乘法。
利用 LoRA,可以重新定义之前的权重更新公式。
下图并列展示了全量微调与 LoRA 的权重更新方法。
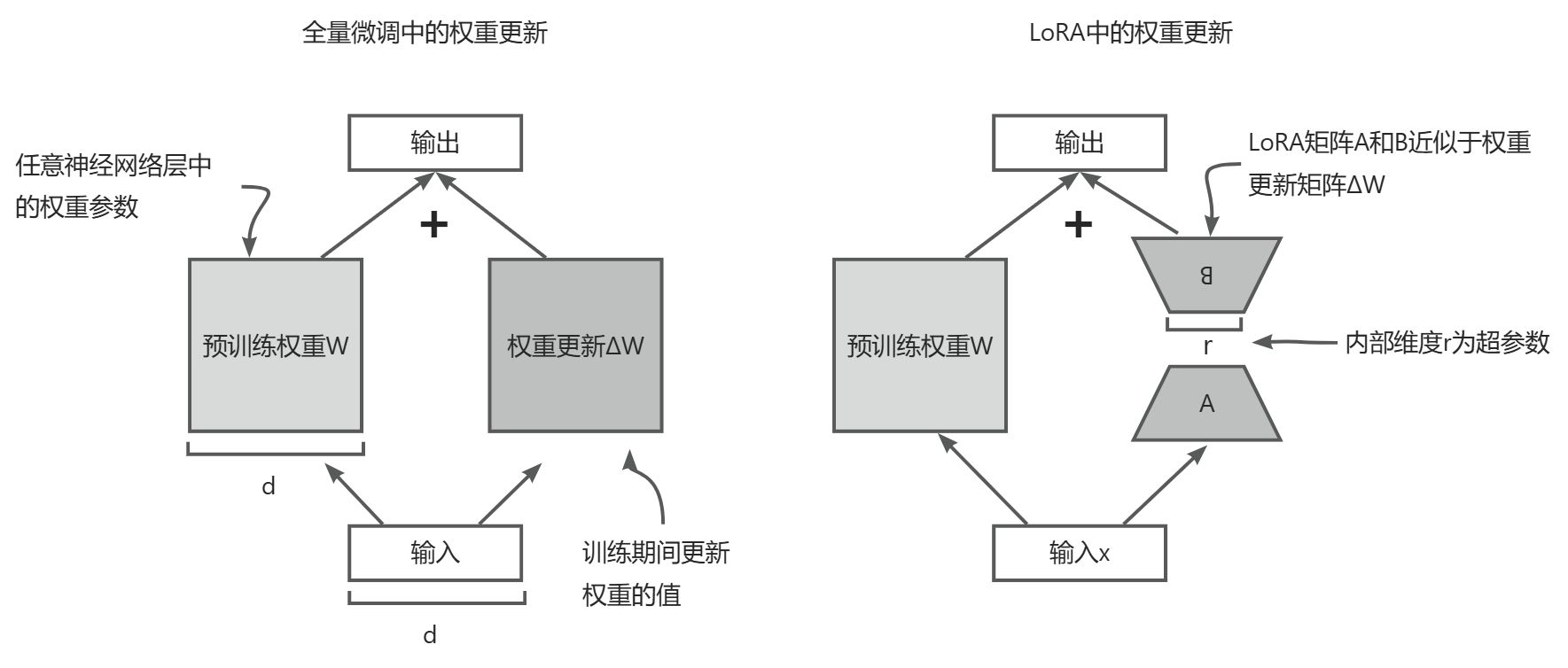
权重更新方法对比:全量微调与 LoRA。全量微调涉及直接用 ΔW 更新预训练的权重矩 阵 W(左)。而 LoRA 使用两个较小的矩阵 A 和 B 来近似 ΔW,其中矩阵乘积 AB 被加到 W 上,r 表示内部维度,它是一个可调的超参数(右)
如果仔细观察,你可能会注意到图中全量微调和 LoRA 的可视化表示与之前提出的公式略有不同。这种变化是由于矩阵乘法的分配律,它允许我们将原始权重与更新后的权重分开,而不是将它们组合在一起。例如,在全景微调中,当以 x 作为输入数据时,可以将计算表示为如下形式:
同样,可以将 LoRA 表示为以下公式:
除了可以减少训练期间需要更新的权重数量,将 LoRA 权重矩阵与原始模型权重分开的能力使 LoRA 在实践中更加有用。实际上,这一特性允许预训练的模型权重保持不变,并且在使用模型时可以动态地应用 LoRA 矩阵。
保持 LoRA 的权重分离在实践中非常有用,因为它使得模型定制变得更加灵活,无须存储多个完整版本的大语言模型。这降低了存储需求并提高了可扩展性,因为在为每个特定客户或应用程序进行定制时,只需调整和保存较小的 LoRA 矩阵即可。
使用 LoRA 进行参数高效微调
接下来,我们将使用 LoRA 来调整或微调大语言模型。我们首先初始化一个 LoRA 层,它创建了矩阵 A 和 B,并设置了 alpha 缩放因子和 rank(r)。该层可以接受输入并计算相应的输出, 如下图所示。
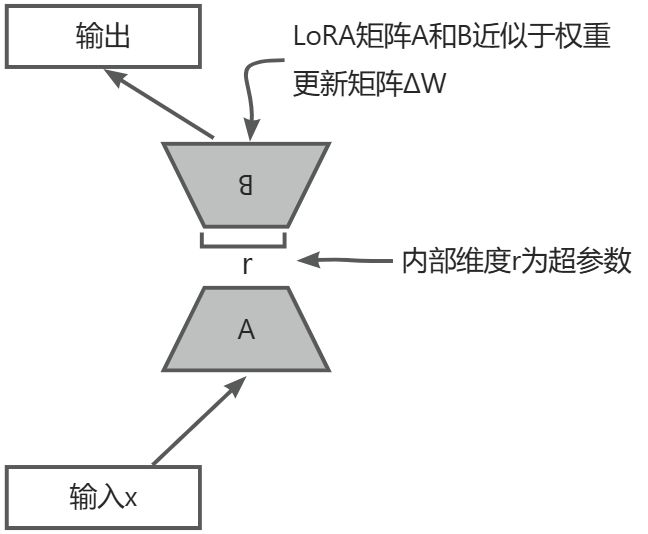
LoRA矩阵 A和 B应用于层输入并参与计算模型输出。这些矩阵的内部维度 r作为一种权 衡,可通过改变 A 和 B 的大小来调整可训练参数的数量
在代码中,该 LoRA 层可以按如下方式实现。
import math
class LoRALayer(torch.nn.Module):
def __init__(self, in_dim, out_dim, rank, alpha):
super().__init__()
self.A = torch.nn.Parameter(torch.empty(in_dim, rank))
torch.nn.init.kaiming_uniform_(self.A, a=math.sqrt(5))
self.B = torch.nn.Parameter(torch.zeros(rank, out_dim))
self.alpha = alpha
def forward(self, x):
x = self.alpha * (x @ self.A @ self.B)
return x
rank 控制着矩阵 A 和 B 的内部维度。本质上,该设置决定了 LoRA 引入的额外参数量,从而在模型的适应性和效率之间建立平衡。
另一个重要的设置是 alpha,它作为低秩自适应输出的缩放因子,决定适应层的输出对原始层输出的影响程度。这可以被视为调节低秩适应对层输出影响的一种方式。到目前为止, 我们实现的 LoRALayer 类使我们能够对层的输入进行转换。
在 LoRA 中,典型的目标是替换现有的线性层,从而允许权重更新直接应用于已有的预训练权重,如下图所示。
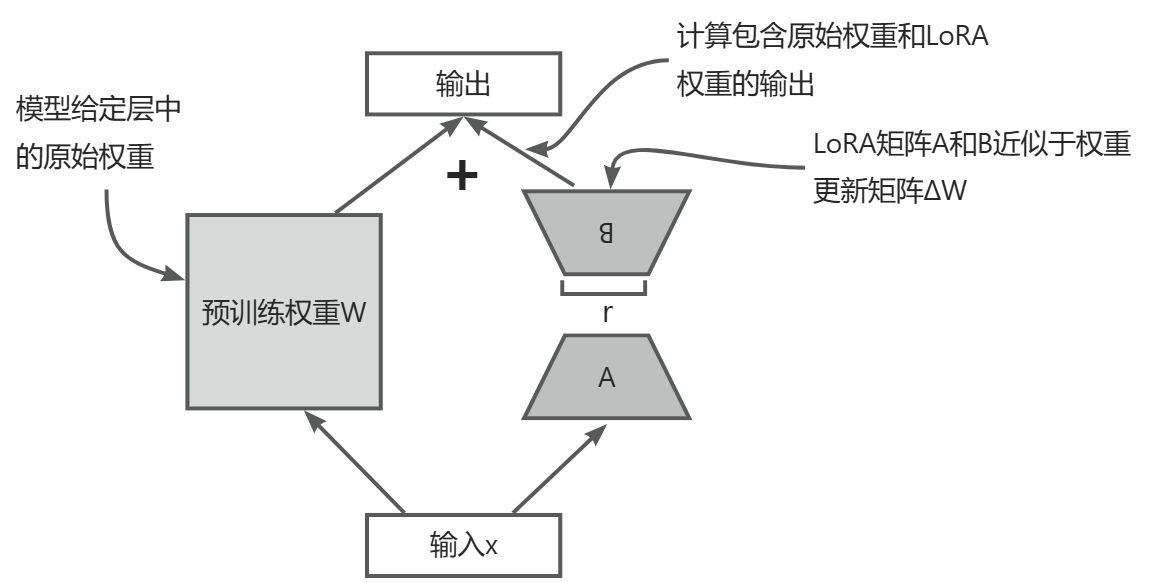
LoRA集成到模型层中的过程。一个层的原始预训练权重W与来自LoRA矩阵 A 和 B 的输出相结合,LoRA矩阵近似于权重更新矩阵 ΔW。最终输出通过将使用 LoRA 权重调整后的层输出与原始输出相加而计算得出
为了整合原始线性层的权重,现在创建一个 LinearWithLoRA 层。该层利用之前实现的 LoRALayer,旨在替换神经网络中现有的线性层,比如 GPTModel 中的自注意力模块或前馈模块。
class LinearWithLoRA(torch.nn.Module):
def __init__(self, linear, rank, alpha):
super().__init__()
self.linear = linear
self.lora = LoRALayer(
linear.in_features, linear.out_features, rank, alpha
)
def forward(self, x):
return self.linear(x) + self.lora(x)
上述代码将标准线性层与 LoRALayer 结合在了一起。forward 方法通过将原始线性层和 LoRA 层的结果相加来计算输出。
由于权重矩阵 B(LoRALayer 中的 self.B)被初始化为零值,因此矩阵 A 和 B 的乘积将 产生零矩阵。这确保了乘法不会改变原始权重,因为加零不会对它们产生影响。
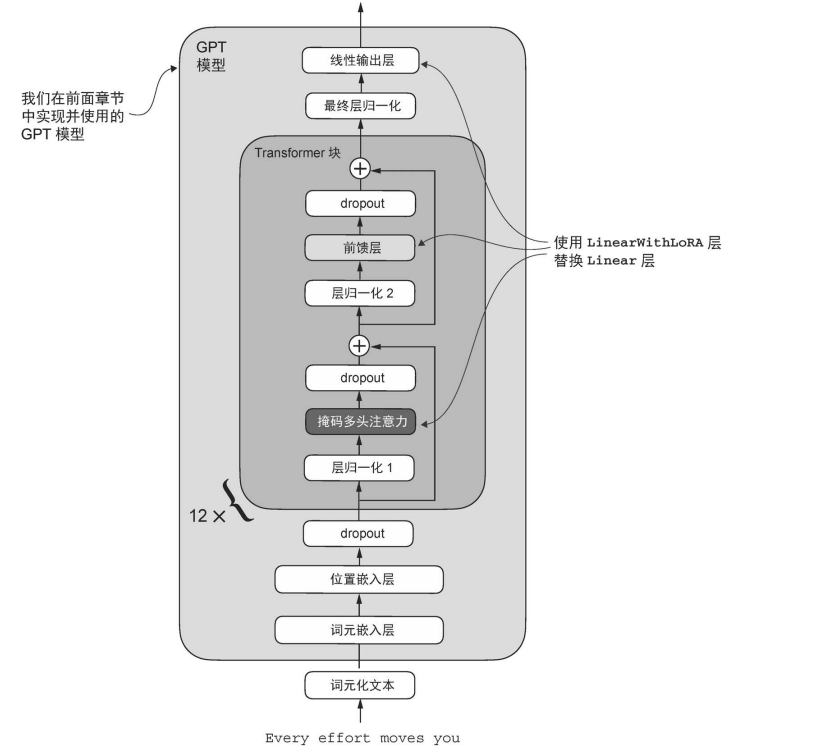
为了将 LoRA 应用到之前定义的 GPTModel 中,我们引入了 replace_linear_ with_lora 函数。该函数会将模型中所有现有的 Linear 层替换为新创建的 LinearWithLoRA 层。
def replace_linear_with_lora(model, rank, alpha):
for name, module in model.named_children():
if isinstance(module, torch.nn.Linear
setattr(model, name, LinearWithLoRA(module, rank, alpha))
else:
replace_linear_with_lora(module, rank, alpha)
现在我们已经实现了所有必要的代码,将 GPTModel 中的 Linear 层替换为新开发的 LinearWithLoRA 层,以便进行参数高效微调。接下来,我们将把 LinearWithLoRA 应用到 GPTModel 的多头注意力模块、前馈模块以及输出层中的所有 Linear 层。
参考
《从零构建大模型》

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)