提示词系统
提示词系统是五层框架中最底层的知识资产层,负责提示词的存储、迭代、格式转换与生命周期管理。它与 Skill System 形成能力梯度:提示词是原子级指令片段,Skill 是经过结构化封装的可复用能力单元。本文档覆盖提示词库的架构设计、数据模型、转换工具链以及从提示词到 Skill 的演进路径。
架构总览
提示词系统的核心设计决策是以云端表格为唯一真实源,本地仓库仅作为入口索引和格式转换工具的宿主。这消除了多格式同步的歧义:所有提示词的创建、编辑、版本迭代都在 Google Sheets 中完成,本地工具按需将表格内容导出为 Markdown、JSONL 或 Excel 等目标格式。
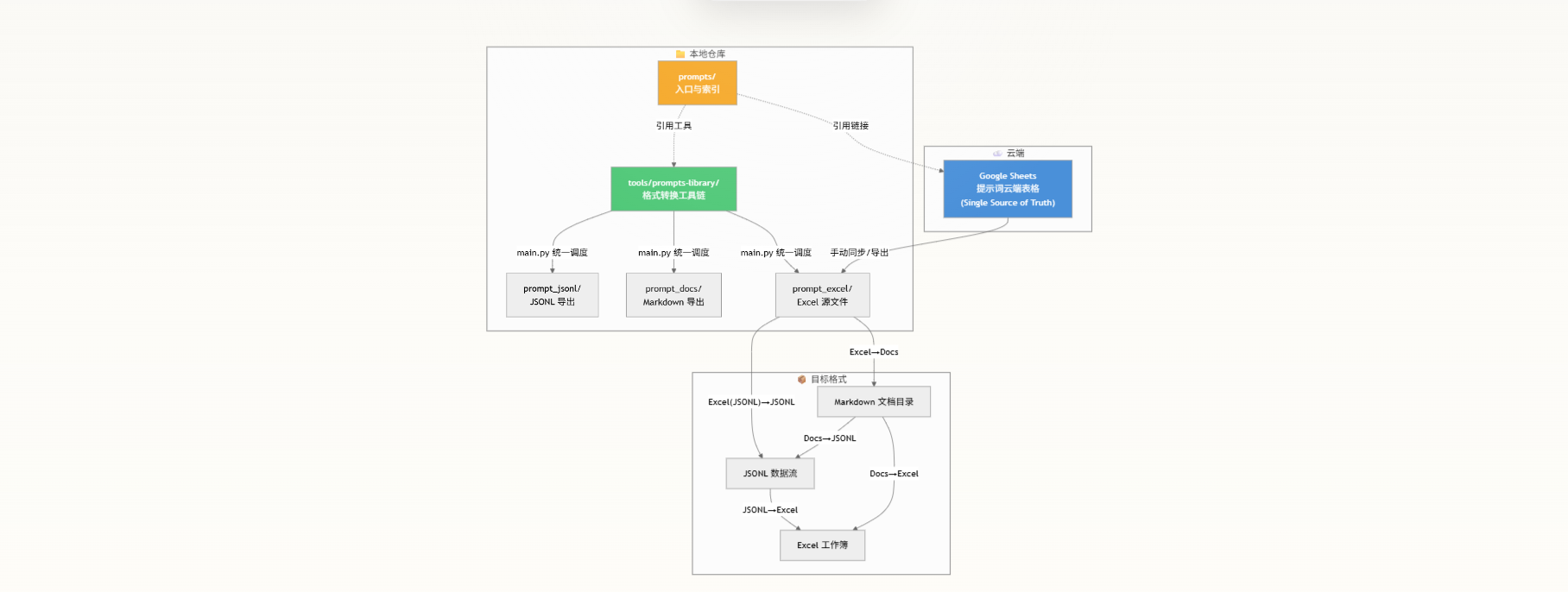
数据模型:三维提示词矩阵
提示词在云端表格中组织为一个三维矩阵结构,这是理解整个转换管线的关键。三个维度分别是:
| 维度 | 表格映射 | 含义 | 示例 |
|---|---|---|---|
| 分类 | 工作表 | 提示词的领域或用途类别 | 元提示词、系统提示词、编程提示词 |
| 横轴(列) | 版本迭代 | 同一提示词的演化过程 | 1a → 1b → 1c |
| 纵轴(行) | 提示词实例 | 不同的独立提示词 | 提示词1、提示词2、... |
每个单元格即是一条完整的提示词文本。当转换工具将 Excel 导出到文件系统时,这个三维矩阵被展平为目录结构:
prompt_docs/prompt_docs_YYYY_MMDD_HHMMSS/
└── prompts/
├── (1)元提示词/ │ ├── (1,1)_生成提示词的提示词.md # row=1, col=1 (版本1)
│ ├── (1,2)_优化版.md # row=1, col=2 (版本2)
│ ├── (2,1)_角色扮演生成.md # row=2, col=1
│ └── index.md # 自动生成的分类索引
├── (2)系统提示词/
│ ├── (1,1)_AI系统级提示词.md
│ └── index.md
└── index.json # 全局结构化索引
文件命名规范 (行,列)_标题.md 中的 (行,列) 元组充当跨介质主键——它确保 Excel 单元格与文件系统之间建立可逆的双向映射关系。标题部分仅用于提升人读可读性,回写 Excel 时会被忽略 。
提示词分类体系
云端表格中的每个工作表代表一个提示词类别。当前定义的分类如下:
| 工作表名称 | 分类定位 | 典型用途 |
|---|---|---|
| 元提示词 | 关于提示词的提示词 | 生成、优化、评审其他提示词的元指令 |
| 系统提示词 | AI 系统级配置 | 定义 AI 的角色、行为边界和输出格式 |
| 编程提示词 | 代码与工程 | 编程任务、代码审查、架构设计 |
| 用户提示词 | 端到端场景 | 面向最终用户的具体任务指令 |
这个分类体系的设计遵循“元→系统→领域→场景”的抽象层级,与 Problem Solving Framework 中的目标-约束-对象分层相对应。值得注意的是,提示词分类是扁平的(非层级),刻意避免了过度分类导致的检索摩擦。
格式转换工具链:Prompts Library Converter
tools/prompts-library/ 是提示词系统的核心基础设施,它提供 五种双向转换模式,以 main.py 作为统一入口进行调度。转换工具的设计遵循一个关键原则:内容纯净性——每个 .md 文件只包含单元格的原始文本,不允许附加 Markdown 标题、代码围栏、版本历史或时间戳等元信息。
五种转换模式
| 模式 | 命令 | 输入 → 输出 | 核心逻辑 |
|---|---|---|---|
| Excel → Docs | --mode excel2docs |
.xlsx → Markdown 目录 |
每个非空单元格生成 (r,c)_标题.md |
| Docs → Excel | --mode docs2excel |
Markdown 目录 → .xlsx |
解析文件名回写单元格位置 |
| Docs → JSONL | --mode docs2jsonl |
Markdown 目录 → .jsonl |
扫描 prompts/ 子目录提取结构化记录 |
| JSONL → Excel | --mode jsonl2excel |
.jsonl → .xlsx |
单元格存储 {"title":"...","content":"..."} JSON 对象 |
| Excel(JSONL) → JSONL | --mode jsonl_excel2jsonl |
JSONL 格式 .xlsx → JSONL 目录 |
自动检测内部 JSONL 格式,按工作表拆分输出 |
JSONL 数据格式
JSONL 是提示词系统的中间交换格式,每行一个 JSON 对象,承载完整的元信息:
{
"category_id": 2,
"category": "元提示词",
"row": 1,
"col": 1,
"title": "生成提示词的提示词",
"content": "你是一个提示词工程专家..."
}字段中 category_id 和 category 标识分类,row/col 保持与 Excel 矩阵的位置对应,title 截断至 80 字符,content 保留完整文本。当 JSONL 转换回 Excel 时,单元格仅保留 title 和 content 两个字段 。
工具使用方式
安装依赖后,你可以通过交互式或命令行两种方式使用转换器:
# 安装依赖
cd tools/prompts-library
python3 -m pip install -r requirements.txt
# 交互式选择(推荐首次使用)
python3 main.py
# 指定模式和路径(CI/自动化场景)
python3 main.py --select "prompt_excel/example.xlsx" --mode excel2docs
# 非交互执行(跳过所有提示)
python3 main.py --select "prompt_excel/example.xlsx" --mode excel2docs --non-interactive工具会自动检测 Excel 文件是否为内部 JSONL 格式(通过检查单元格内容是否以 { 开头且包含 title/content 字段),并据此选择正确的转换路径。
💡
prompt_jsonl/目录是生成物,已在.gitignore中忽略。切勿手动编辑或提交该目录。如需对 JSONL 数据进行版本控制,应将其导出至仓库外或通过 CI 管道管理。
输入输出目录约定
| 目录 | 角色 | 是否提交 Git |
|---|---|---|
prompt_excel/ |
Excel 源文件输入目录 | ✅ 是 |
prompt_docs/ |
Markdown 文档输入/输出目录 | ✅ 是 |
prompt_jsonl/ |
JSONL 输出目录 | ❌ 否(已 gitignore) |
行分类与内容路由
转换工具在处理 Excel 行时执行智能行分类,将不同类型的内容路由到不同的输出位置。这是内容纯净性原则的体现——提示词文件中只保留纯内容,元信息由自动化工具生成到专用文档中。
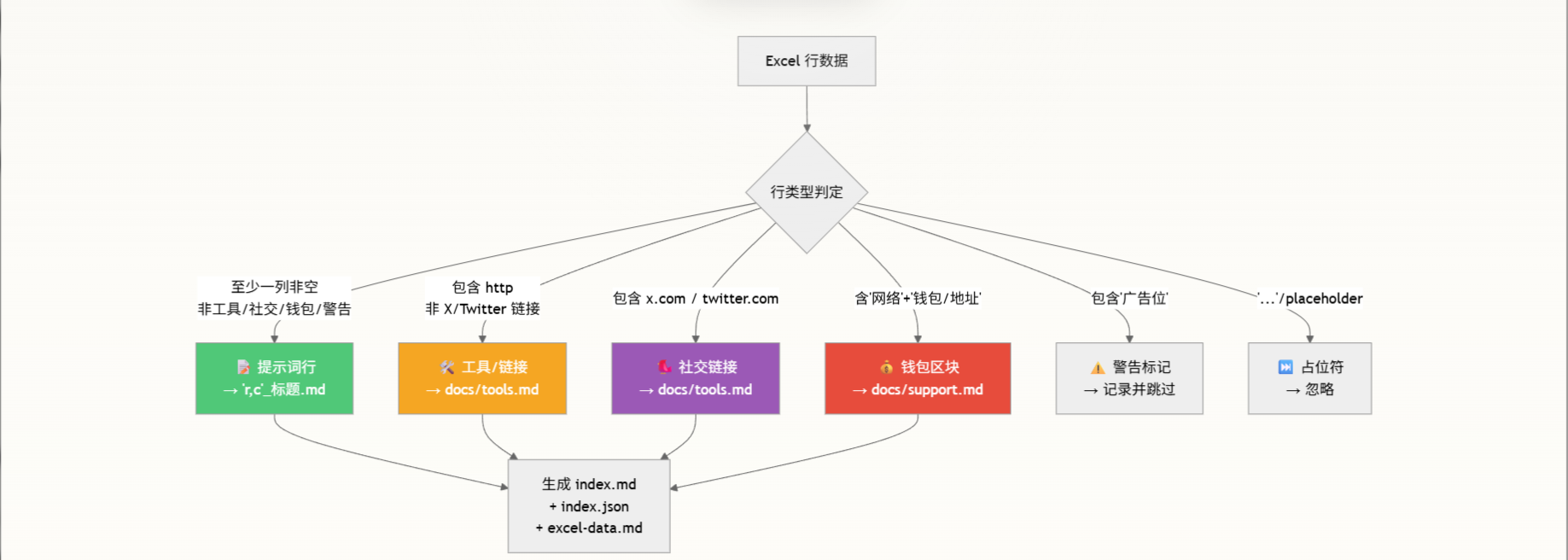
这种分类机制确保了提示词库输出的关注点分离:纯提示词内容进入 prompts/ 目录供直接使用,辅助信息(工具链接、钱包地址)归档到 docs/ 目录供参考,广告/占位等噪声则被自动过滤。
提示词到 Skill 的演进路径
提示词系统并非孤立存在——它是能力抽象层级中的原子层。当提示词积累到一定复杂度,需要结构化的触发条件、边界约束和质量保障时,就应将其封装为 Skill。这是五层框架中从“知识资产”到“可执行能力”的关键跃迁。
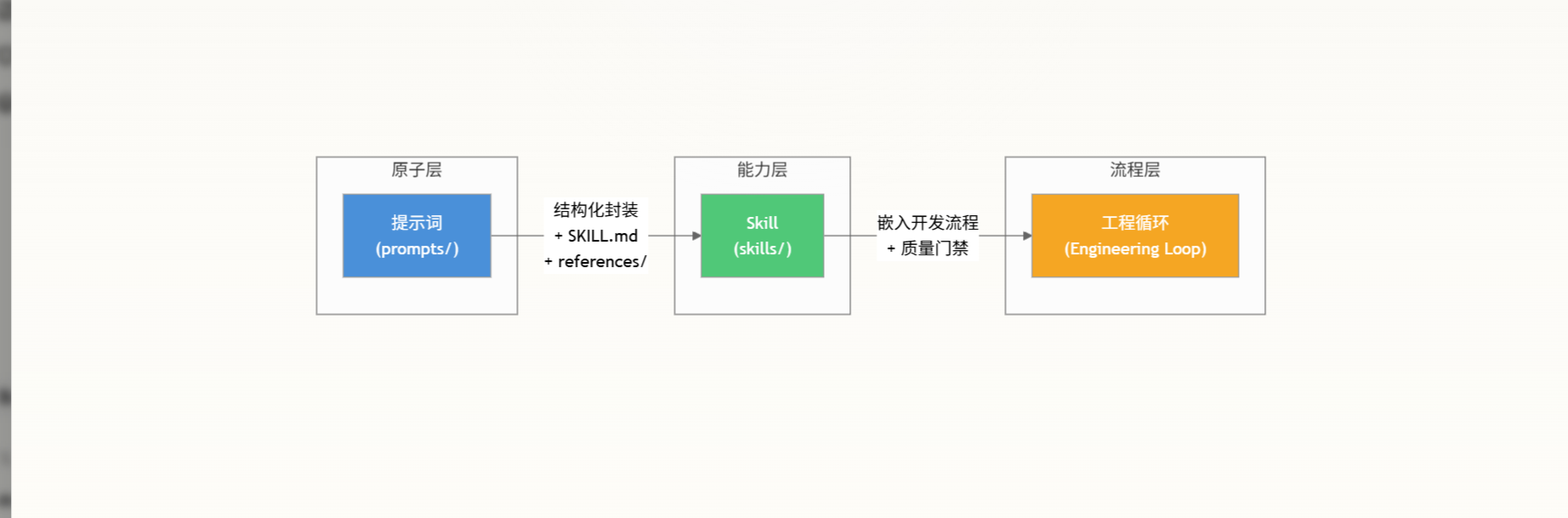
两者的本质区别可以用下表概括:
| 维度 | 提示词 | Skill |
|---|---|---|
| 结构 | 单个文本片段 | SKILL.md + references/ + scripts/ + assets/ |
| 激活机制 | 手动粘贴/引用 | YAML frontmatter 声明 + 触发关键词自动匹配 |
| 边界定义 | 无显式边界 | When to Use + Not For / Boundaries 强制声明 |
| 质量保障 | 人工评审 | Quality Gate 检查清单 + validate-skill.sh 自动化验证 |
| 可复用性 | 低(依赖上下文) | 高(自包含,含示例和验收标准) |
| 演进方向 | → 被封装为 Skill 的一部分 | → 嵌入 Engineering Loop |
💡:判断何时将提示词升级为 Skill 的经验法则:当同一条提示词被跨项目复用超过 3 次,或需要超过 3 个条件语句来描述其使用边界时,就该封装为 Skill。详细的 Skill 规范参见 Auto-Skill Meta-Skill。
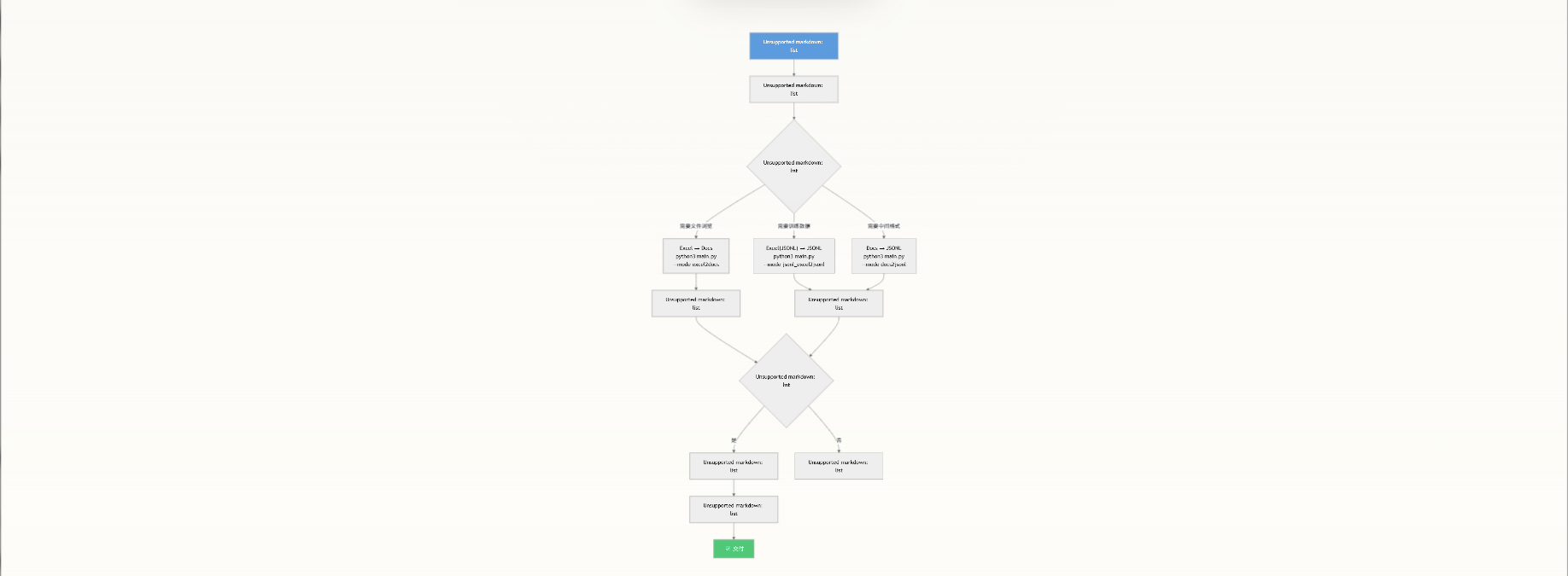
操作指南:端到端工作流
以下流程图展示了一条提示词从创建到最终交付的完整生命周期:
快速开始
对于首次使用者,建议按以下最小步骤操作:
- 浏览现有提示词:访问 提示词云端表格 了解现有资产
- 转换现有 Excel:将
.xlsx文件放入prompt_excel/,运行python3 main.py选择交互式转换 - 查看导出结果:在
prompt_docs/中浏览生成的 Markdown 文档目录结构
设计决策与取舍
提示词系统的架构选择反映了几个关键的设计哲学:
内容纯净性优先。提示词 .md 文件只保留单元格的原始文本,末尾追加一个换行。不包含 Markdown 标题、分隔线、代码围栏、版本历史或时间戳。所有元信息(统计、导航、版本矩阵)由自动化工具生成到 index.md 和 index.json 中。这避免了元信息造成的噪声与二义性,使提示词文件可以被直接复制、拼接或用于模型训练 。
以 (行,列) 作为跨介质主键。行列坐标是 Excel 和文件系统之间唯一可靠的映射标识。文件夹名与工作表名的映射以 index.json 为准,直接根据文件夹名反向还原可能因净化规则(空格替换为下划线、特殊字符移除)而出现偏差。
云端表格为唯一真实源。本地不创建提示词文件——所有创建和编辑操作在云端表格中完成,本地仅存放转换工具和入口索引。这彻底消除了多端同步冲突的可能性。
约束与维护规则
在操作提示词系统时,需要遵守以下规则:
允许的操作:
- 更新
prompts/README.md中的链接和说明- 同步云端表格的结构变化到文档
- 在
tools/prompts-library/中修改转换逻辑(需先阅读main.py和对应脚本)- 新增依赖(必须同步更新
requirements.txt)
禁止的操作:
- 在本地
prompts/目录中创建提示词文件(应添加到云端表格)- 删除
prompts/README.md- 在任何目录中写入敏感信息(密钥、Token、个人路径)
- 提交生成目录、缓存和临时导出
- 手动编辑
prompt_jsonl/中的生成物
修改后的验证:修改转换工具后,至少运行 python3 main.py --help 确认入口正常。如改动影响仓库文档或链接,还需在仓库根目录运行 make test。
延伸阅读
理解提示词系统后,建议按以下顺序继续深入五层框架的其他层级:
- Skill System — 当提示词需要结构化封装时,学习如何将原子提示词升级为可复用的 Skill
- Engineering Loop — 了解 Skill 如何嵌入开发流程,形成人机协作的工程闭环
- Auto-Skill Meta-Skill — 掌握自动从文档/API/代码中提取并生成 Skill 的元技能
- Prompts Library Converter — 深入了解格式转换工具的技术实现细节
- Quality Gates — 理解贯穿所有层级的质量保障机制
Footnotes
-
文件名正则约束为
^\(\d+,\d+\)_.+\.md$。 -
参见
build_text_record()函数中的标题截断逻辑。 -
参见互转规范第3节“文件内容规范(强约束)”。
下一章:技能系统

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 19
19 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)