RevuAI:一个多智能体协作的智能评审平台
当 AI 不再只是"一个人在战斗",而是让多个智能体各司其职、协作甚至对抗——评审的质量将发生质变。
一、为什么需要智能评审?
在软件研发流程中,需求评审和代码评审是保障质量的关键环节。然而现实是:
- 人力有限:评审会议耗时耗力,参与者往往难以覆盖所有视角
- 视角单一:个人经验局限导致盲区,安全、性能、体验等问题容易遗漏
- 标准不一:不同评审者的关注点和严格程度差异巨大
- 反馈滞后:评审意见往往在流程后期才被发现,修复成本高
RevuAI 的核心理念是:让多个 AI 智能体扮演不同角色,从不同视角对需求和代码进行深度评审,从而弥补人工评审的不足,提升评审的全面性和效率。
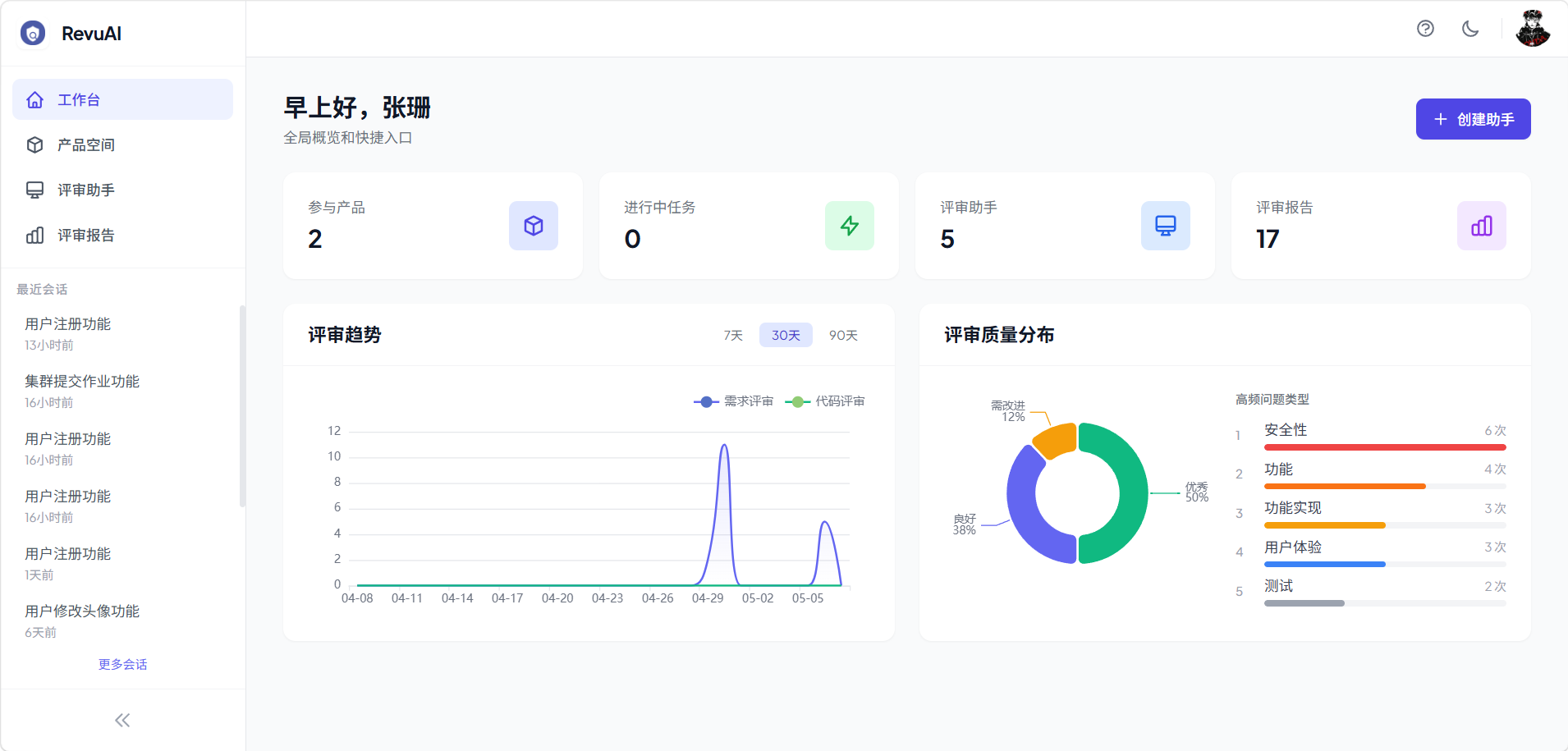
二、平台架构概览
RevuAI 采用前后端分离架构,由三个子系统组成:
| 子系统 | 技术栈 | 职责 |
|---|---|---|
| 用户前端 | Vue 3 + Element Plus + Tailwind CSS + ECharts | 面向评审用户的操作界面 |
| 管理后台 | Vue 3 + TypeScript + Vite + Element Plus | 面向管理员的运营管理界面 |
| 后端服务 | FastAPI + SQLAlchemy + MySQL + ChromaDB | API 服务、智能体编排、知识库管理 |
AI 能力层集成 DeepSeek、Moonshot 等大语言模型,通过 LangChain/LangGraph 进行智能体编排,使用 Ollama + bge-m3 模型实现知识库语义检索。
三、核心功能
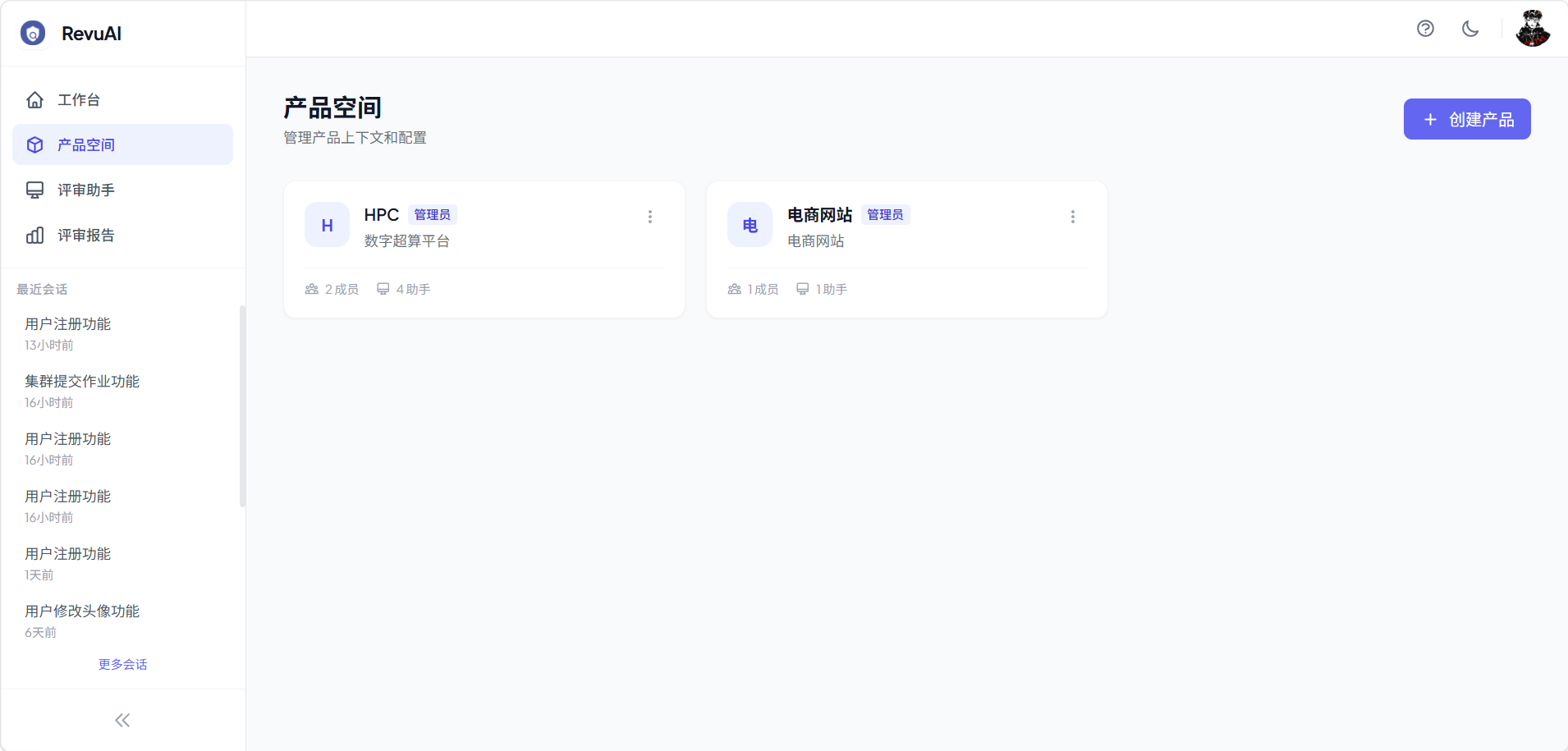
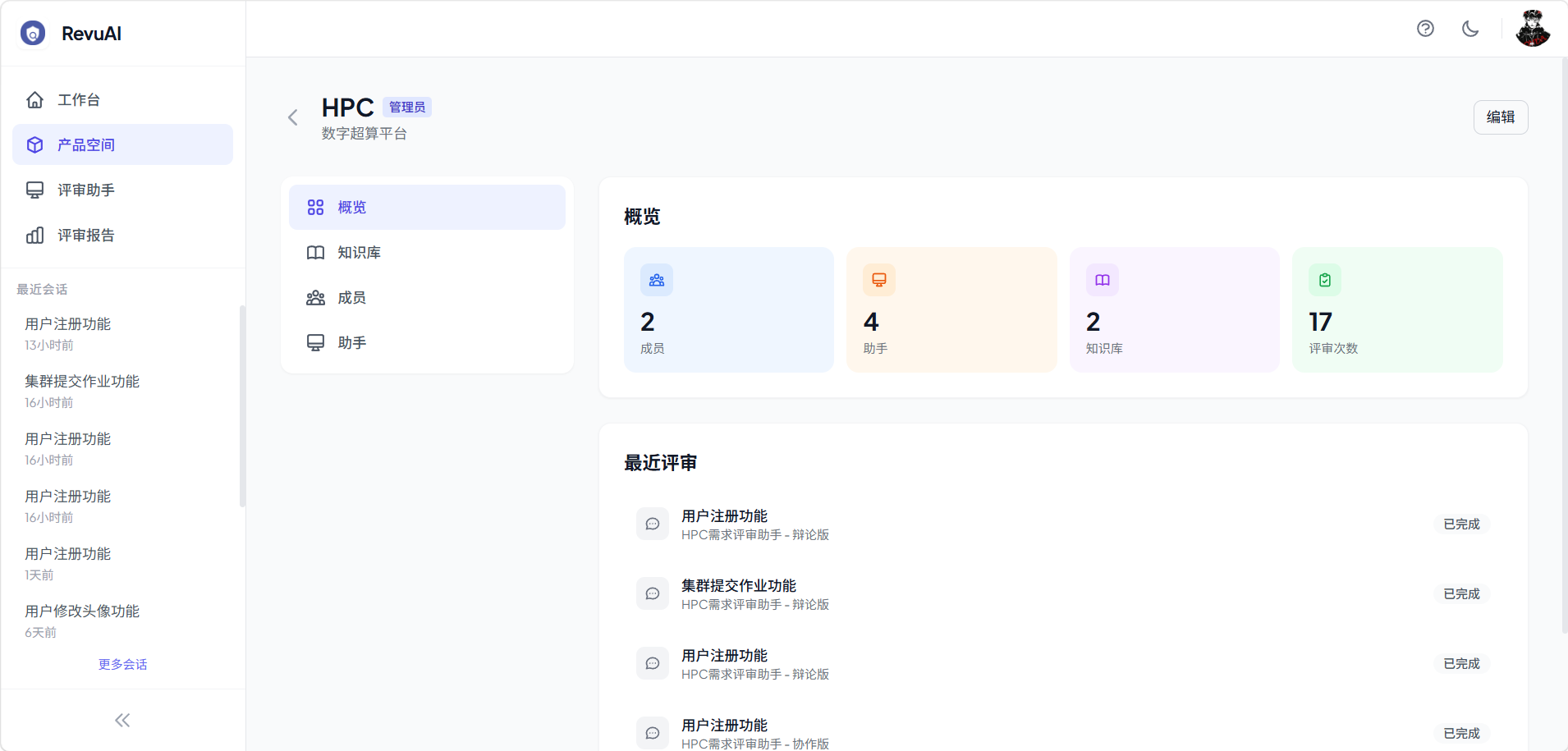
3.1 产品空间
RevuAI 以产品为核心组织所有资源。每个产品拥有独立的知识库、代码仓库、需求基线和评审助手,形成完整的评审上下文。
- 产品管理:创建产品、归档、成员邀请
- 成员权限:产品管理员(admin)和普通成员(member)两种角色
- 资源隔离:不同产品的知识库、助手、评审记录完全隔离
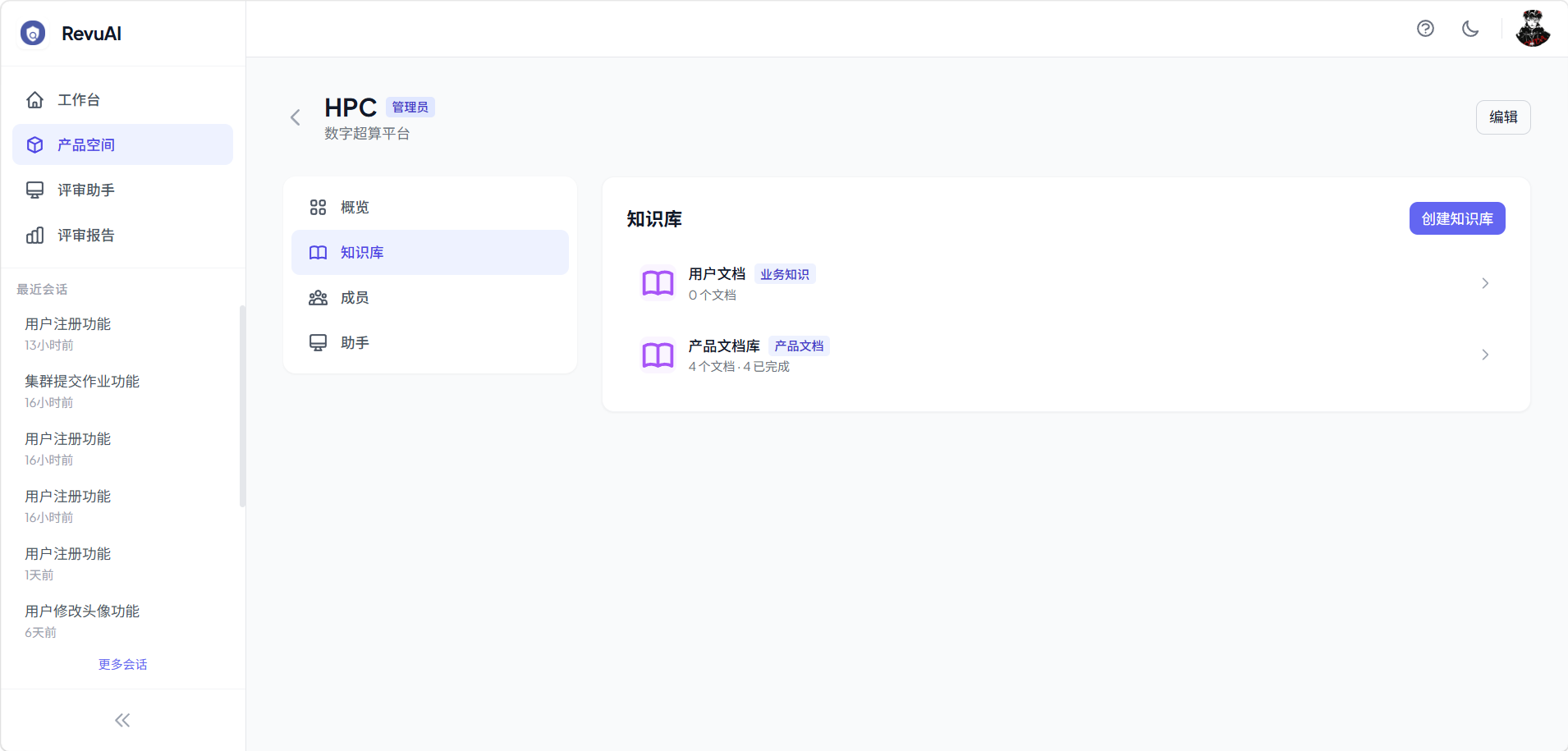
3.2 知识库管理
知识库是智能评审的"记忆",为评审提供上下文支撑。
- 多类型知识库:支持产品文档、需求文档、技术资料、业务知识四种类型
- 文档处理:上传文档后自动分块、向量化(bge-m3 嵌入模型),存入 ChromaDB
- 语义检索:评审时自动从知识库检索相关内容,注入智能体提示词
- 查询优化:支持 LLM 改写查询策略,提升检索精度
- 处理监控:实时查看文档处理状态
3.3 评审助手
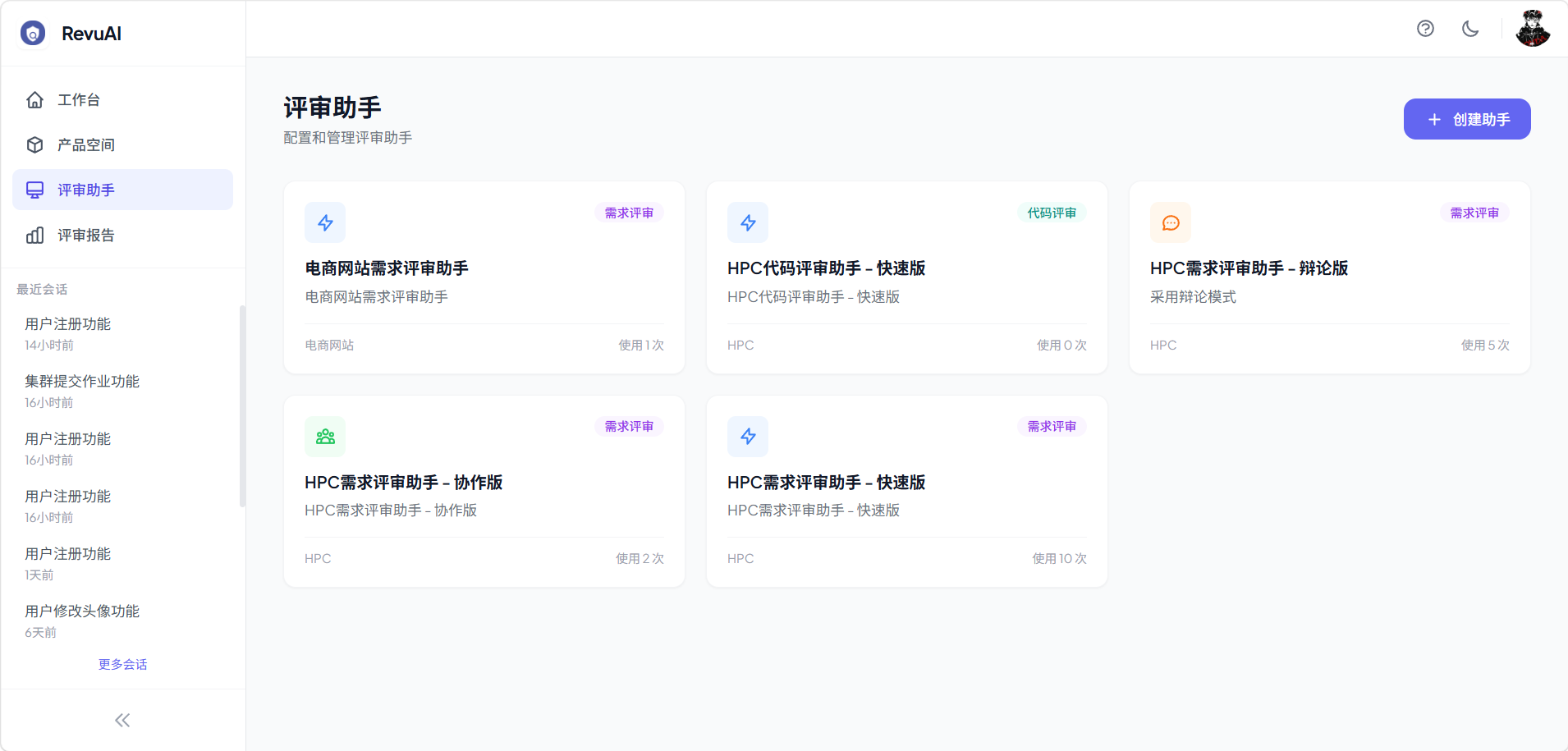
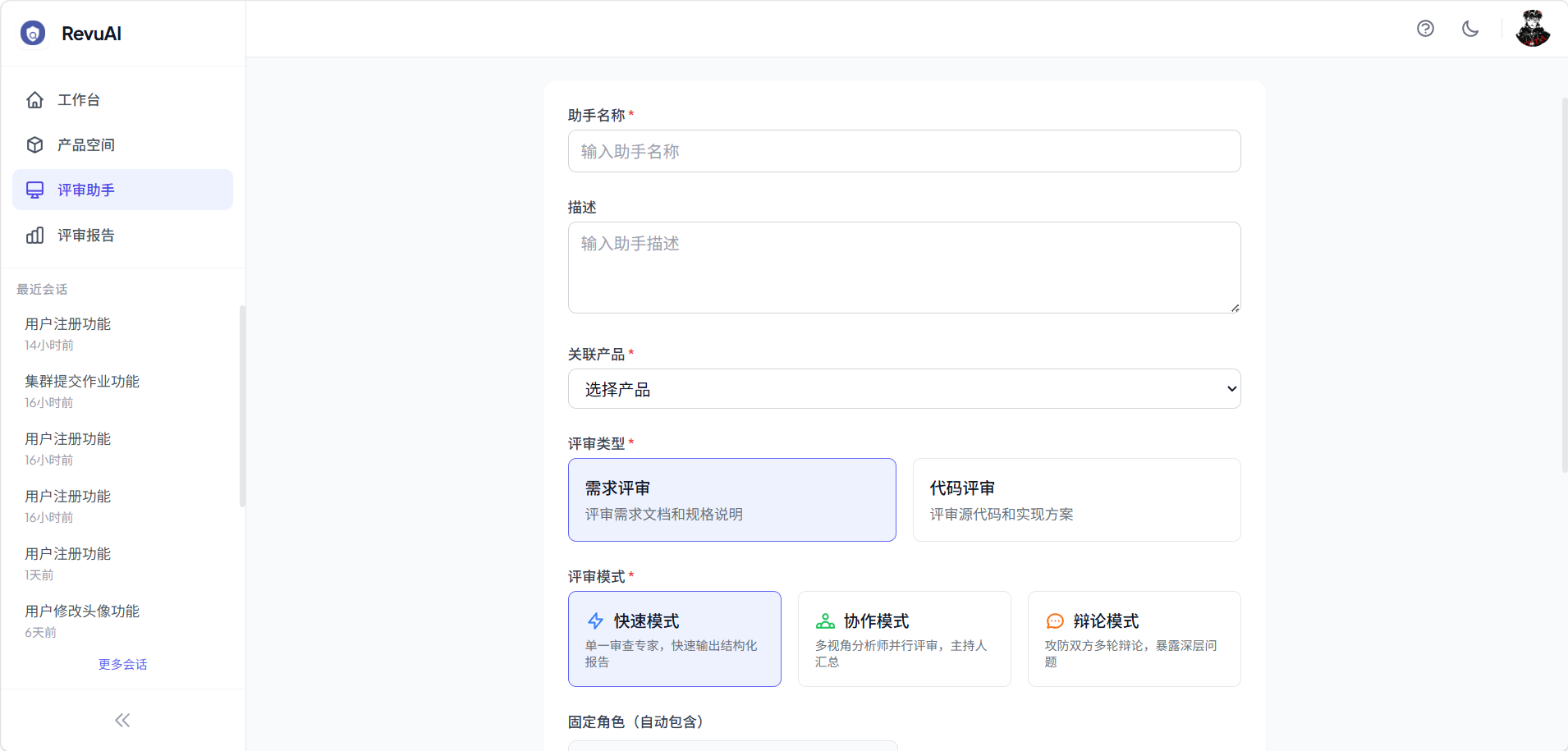
评审助手是连接产品与评审能力的桥梁,定义了评审的类型、模式和智能体配置。
- 评审类型:需求评审、代码评审
- 评审模式:快速模式、协作模式、辩论模式(详见下一章)
- 知识库绑定:助手可绑定特定类型的知识库,评审时自动检索
- 智能体配置:可自定义各角色的提示词、模型和参数
3.4 评审报告
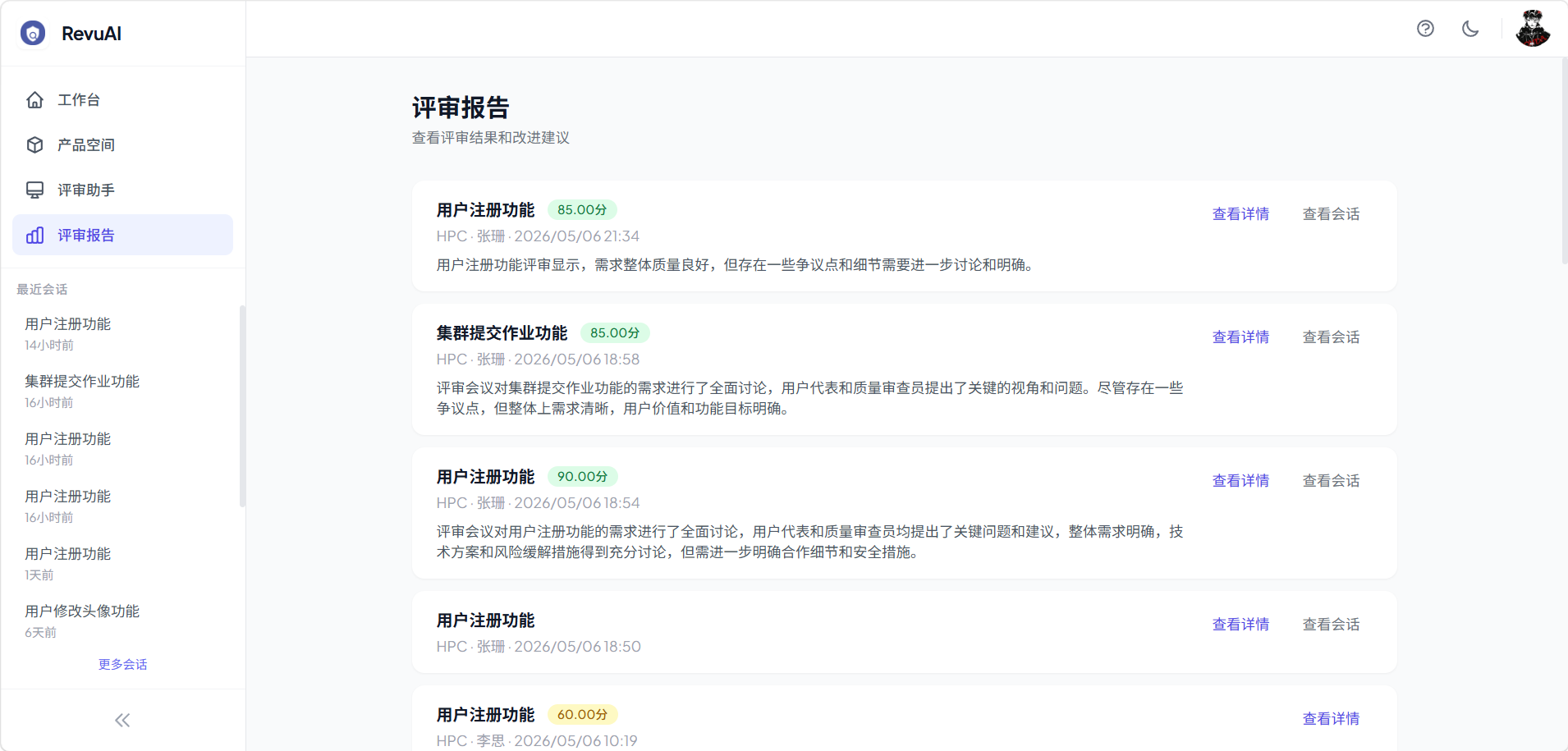
评审完成后自动生成结构化报告,包含:
- 综合评分:整体质量打分
- 关键指标摘要:一目了然的核心发现
- 维度分组:按完整性、可行性、安全性、性能、用户体验等维度分类展示
- 优先级排序:问题按 P0 → P3 优先级排列
- 改进建议:具体的优化方向
- 导出功能:支持 JSON 和 Markdown 格式导出
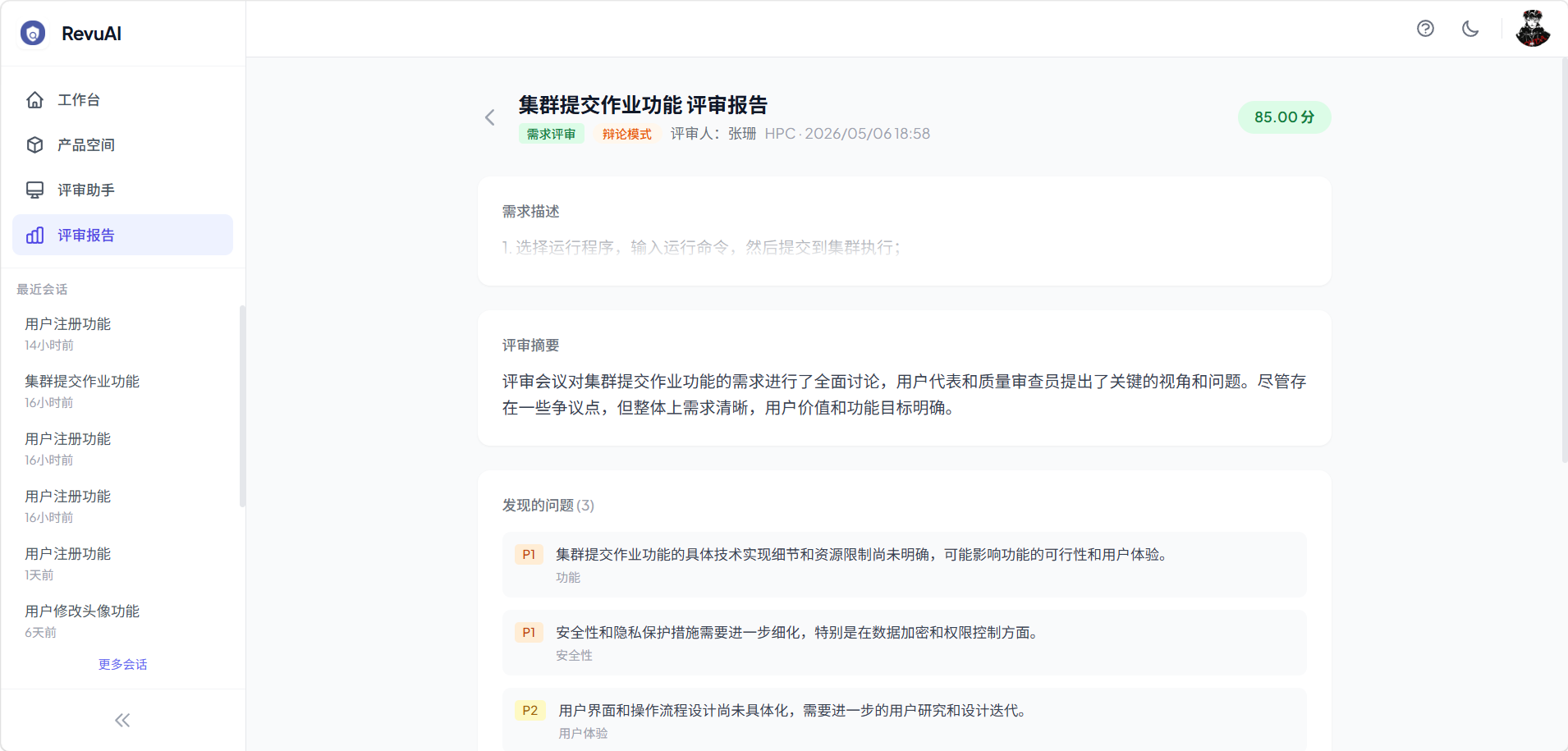
四、三种评审模式——平台的核心创新
RevuAI 最大的特色在于三种评审模式,覆盖从"快速扫描"到"深度对抗"的不同场景需求。
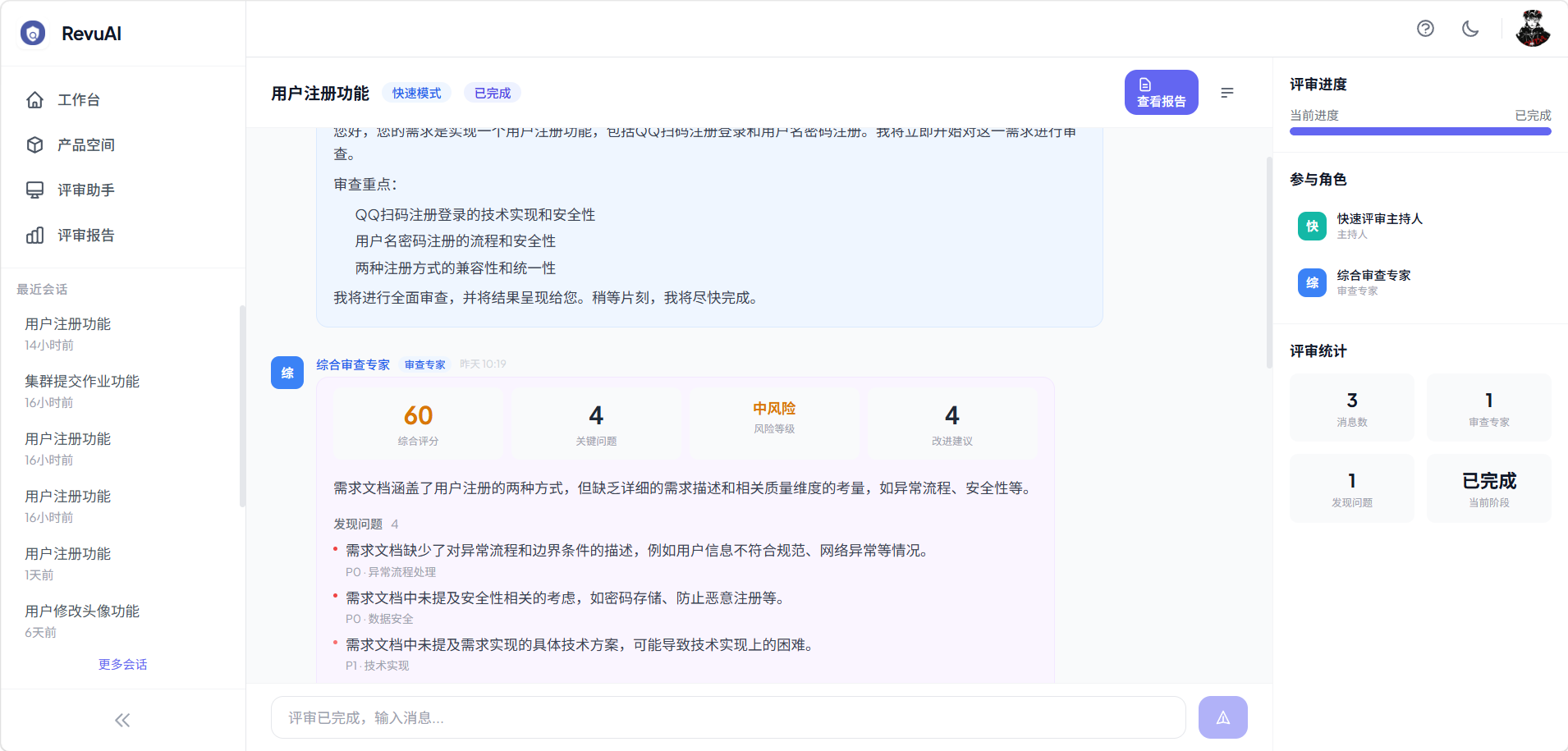
4.1 快速模式
适用场景:时间紧迫,需要快速获得评审反馈
工作流程:审查专家结构化扫描 → 主持人总结
- 单轮评审,速度最快
- 由一个审查专家(Reviewer)全面扫描质量维度
- 主持人(Host)汇总形成结论
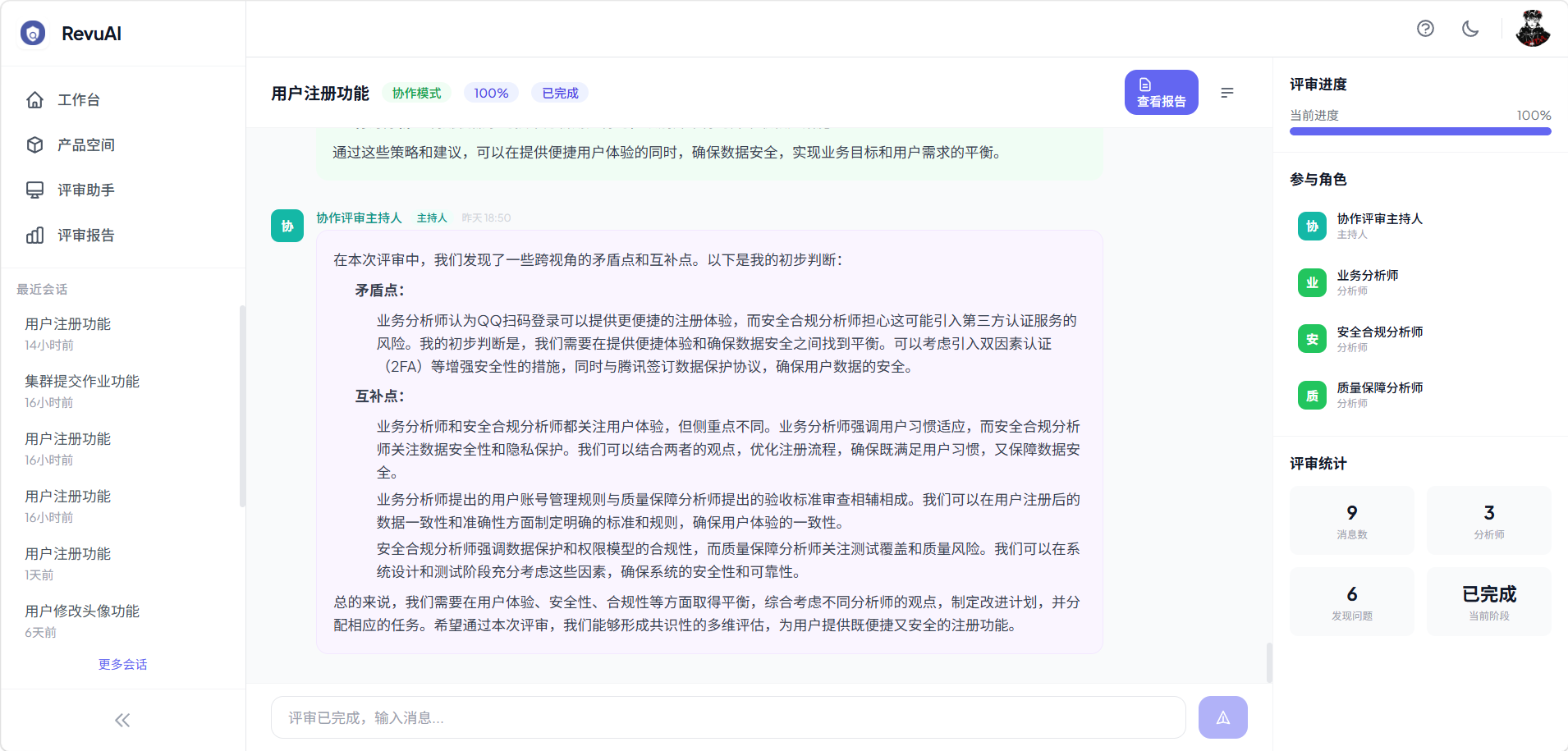
4.2 协作模式
适用场景:需要多视角分析,但不需要对抗式深度
工作流程:多分析师并行独立分析 → 主持人汇总 → 矛盾讨论 → 共识评估
- 五位分析师从不同视角并行分析:
| 分析师 | 视角 |
|---|---|
| 业务分析师 | 业务价值与市场契合度 |
| 技术分析师 | 技术可行性与架构影响 |
| 用户体验分析师 | 用户体验与交互设计 |
| 安全合规分析师 | 安全风险与合规要求 |
| 质量保障分析师 | 测试覆盖与质量标准 |
- 主持人汇总各分析师发现,识别矛盾并讨论
- 最终形成共识性评审结论
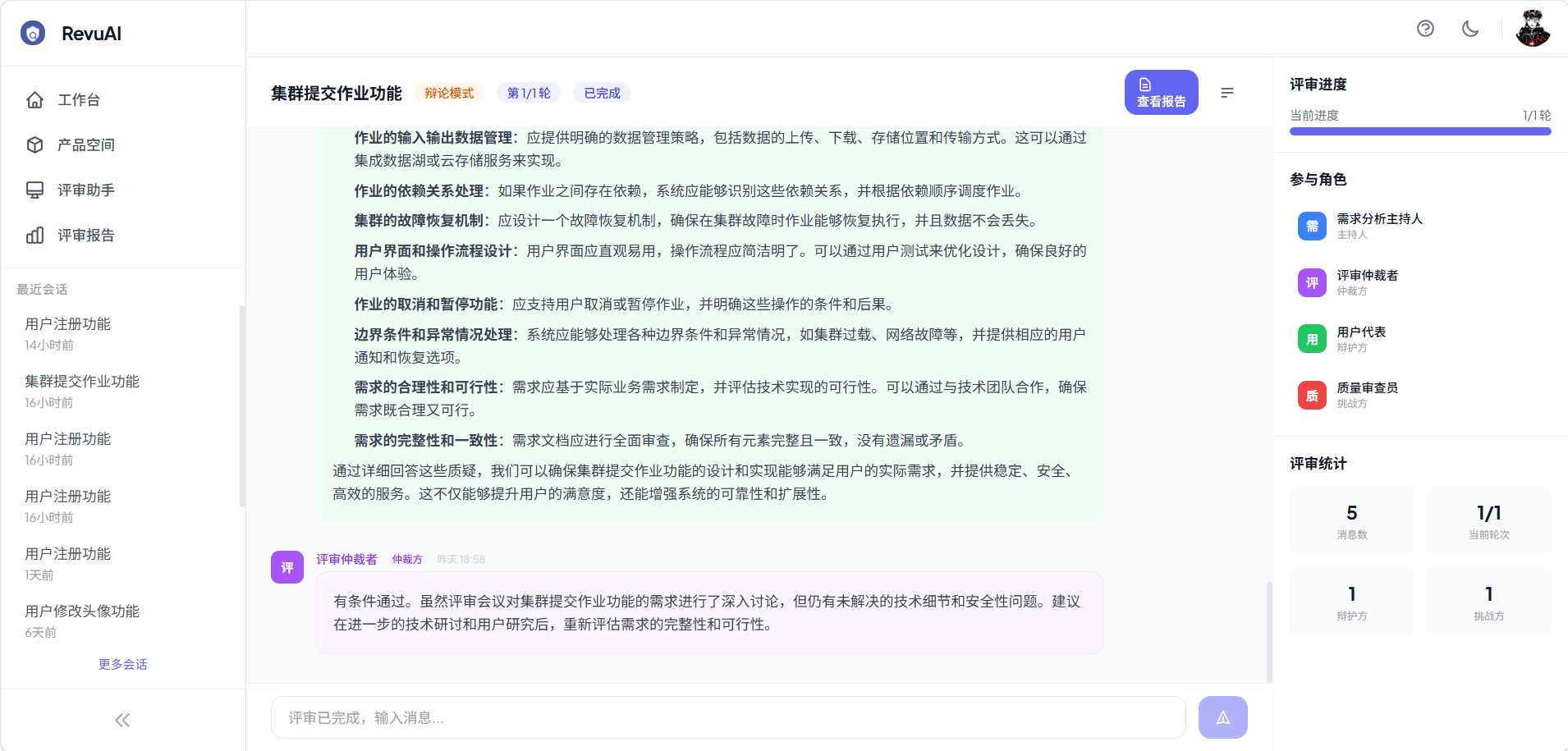
4.3 辩论模式
适用场景:高风险需求/代码,需要深度暴露缺陷
工作流程:主持人分析 → 多轮攻防辩论 → 仲裁者裁决
- 主持人(Moderator):引导辩论方向,判断是否继续
- 辩护方(Defender):从正面角度维护需求/代码的合理性
- 质疑方(Challenger):从反面角度质疑需求/代码的缺陷
- 仲裁者(Arbitrator):综合辩论结果,生成最终裁决
辩论模式支持最多 5 轮攻防,当双方达成共识或达到最大轮次时结束。这种对抗机制能够深度暴露隐藏问题,是传统单智能体评审无法实现的。
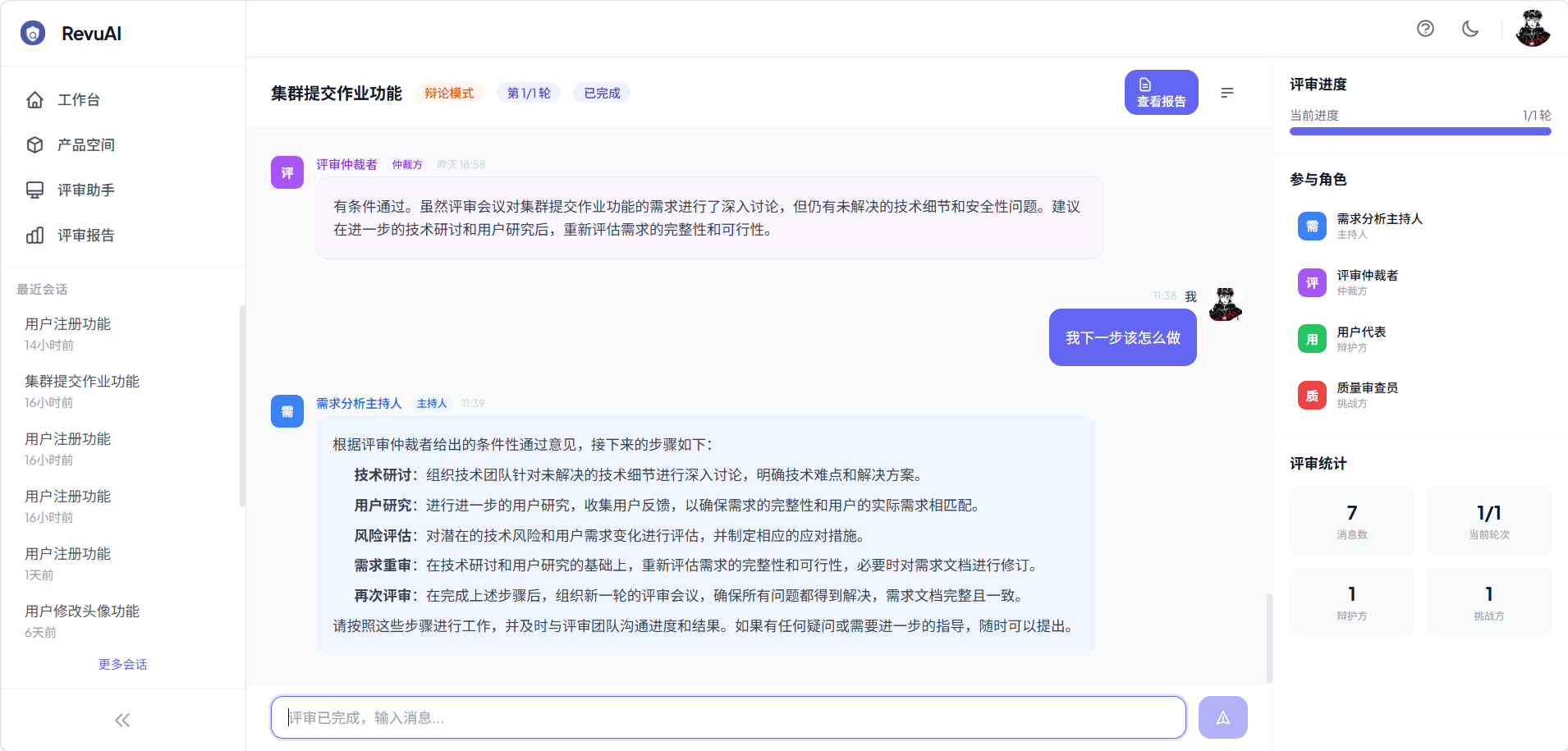
五、评审对话体验
评审过程以对话形式呈现,支持实时流式交互:
- SSE 实时推送:智能体输出 Token 级流式展示,打字机效果
- 角色着色:不同智能体角色使用不同颜色气泡,一目了然
- 阶段分隔:辩论模式展示轮次分隔,协作模式展示分析师进度
- 状态栏:实时显示评审进行状态
- 用户交互:评审过程中可随时追问,与智能体对话
六、工作台
工作台是用户进入平台后的首页,提供一站式的评审工作入口:
- 欢迎区:个性化问候 + 快速发起评审入口
- 统计卡片:评审数量、通过率等关键指标及趋势
- 评审趋势图:近期评审活动可视化
- 质量分布图:评审质量评分分布
七、技术亮点
7.1 多智能体编排
基于 LangChain/LangGraph 实现分层智能体架构,由编排器(Orchestrator)统一调度不同角色的智能体,支持快速/协作/辩论三种模式的灵活切换。
7.2 知识库增强检索
评审启动时自动从产品知识库检索相关内容注入智能体提示词,让评审基于真实的项目上下文,而非泛泛而谈。支持 LLM 查询改写、相似度去重、按类型过滤等优化策略。
7.3 实时流式通信
基于 SSE(Server-Sent Events)实现评审过程的实时推送,用户可以像聊天一样观察智能体的思考过程,体验流畅自然。
7.4 Token 消耗追踪
每次 LLM API 调用均持久化记录 Token 消耗,管理后台提供趋势图和智能体分布分析,帮助运营者掌控成本。
八、适用场景
| 场景 | 推荐模式 | 说明 |
|---|---|---|
| 日常需求评审 | 快速模式 | 快速获得结构化反馈 |
| 重要需求评审 | 协作模式 | 多视角全面分析 |
| 高风险需求/代码 | 辩论模式 | 深度对抗暴露隐患 |
| 代码提交前自审 | 快速模式 | 提交前快速扫描 |
| 代码合并评审 | 协作/辩论模式 | 多角度审查代码质量 |
九、总结
RevuAI 通过多智能体协作机制,让 AI 评审从"单点判断"进化为"多角色协作"甚至"对抗式辩论"。这种设计不仅提升了评审的全面性和深度,更模拟了真实世界中高质量评审会议的运作方式——不同角色各司其职,在碰撞中逼近真相。
如果你有更好的建议,欢迎在评论区讨论交流。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)