附录3-DINOV3的基本使用
项目地址 https://github.com/facebookresearch/dinov3
DINOv3是meta公司(原名facebook)开源的视觉大模型,可以用作视觉机器人的基座模型
- DINOv1在2021年4月发布。DINOv2在2023年4月发布。DIVOv3在2025年8月发布
DINO(self-DIstillation with NO label )的意思是自蒸馏无标签
- 无标签:我们做目标检测、目标分类、目标分割等等传统视觉任务时都需要打标签进行标注,然后进行训练。无标签就是不需要再用人去标注了,第一个好处是不需要标注了,训练模型成本降低。第二个好处是模型范化能力强,模型不再只适合一个任务,一个模型可以适配多个任务
- 自蒸馏:知识蒸馏的意思是由一个大号模型模型训练一个小号大模型。自蒸馏可以为自己指导自己
- 自监督:监督学习是人类打标签喂给模型,然后模型进行学习。自监督学习是不用打标签,只给数据就行了。在DINO中自监督和自蒸馏可以理解为是一回事儿(但其实有区别)
1 下载模型
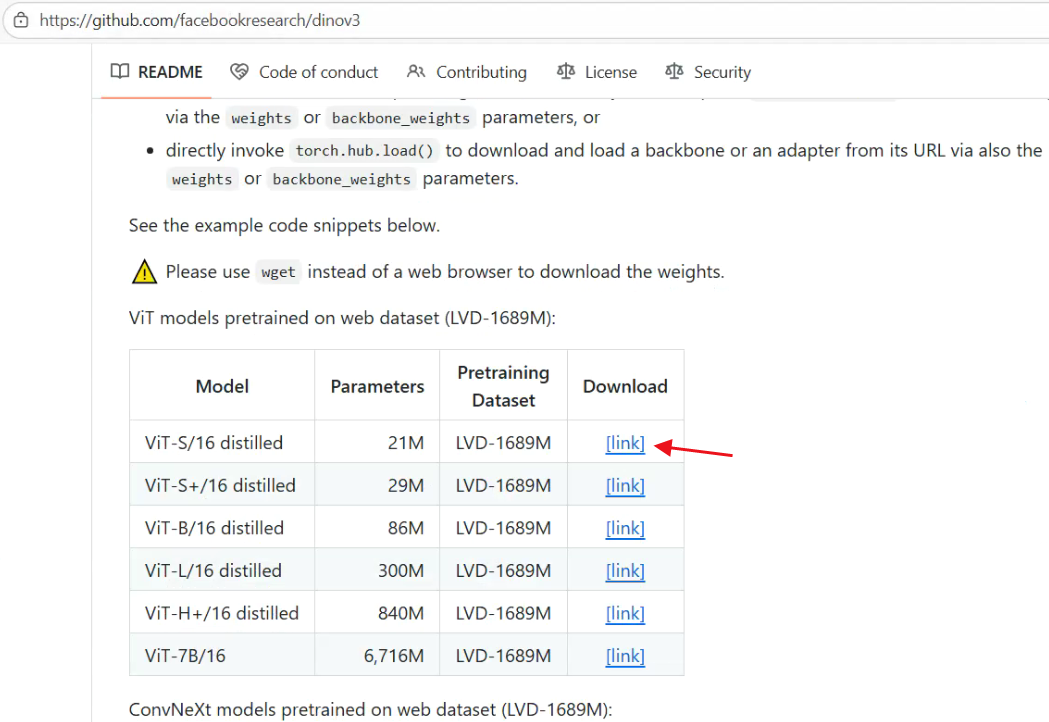
我们需要把这个里面的信息填上
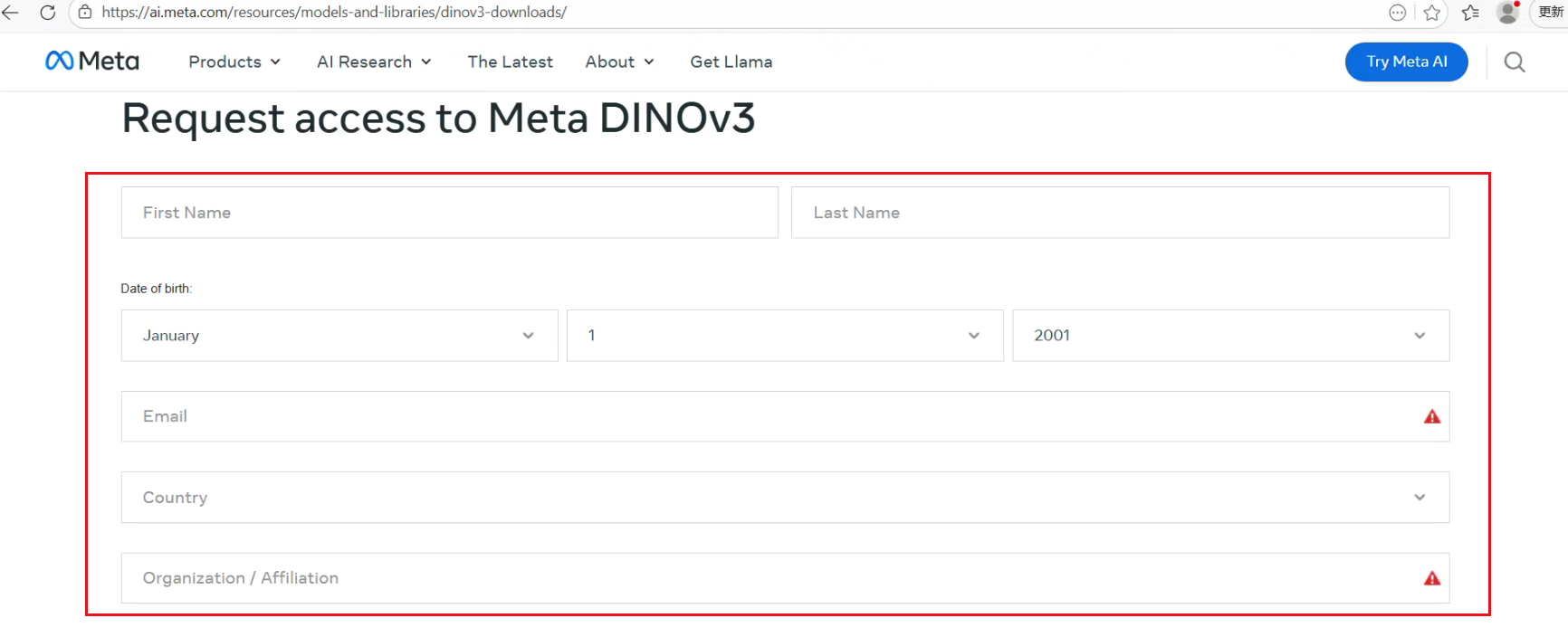
这个条款的意思是你可以用DINOv3商用,但你用的时候你需要把LICECE附上,阅读后打勾,然后同意并继续
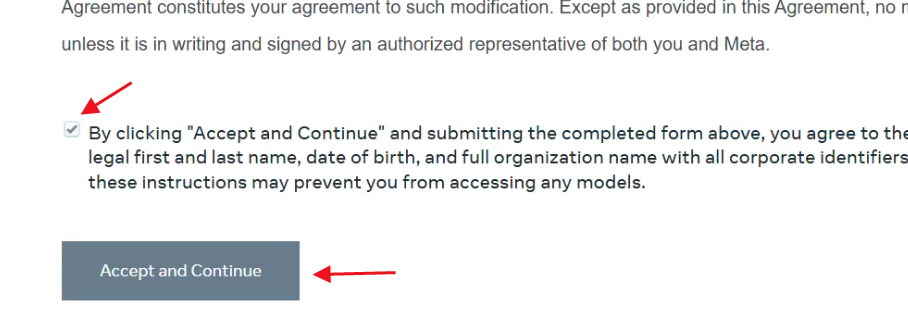
然后它会告诉你给你发邮件了
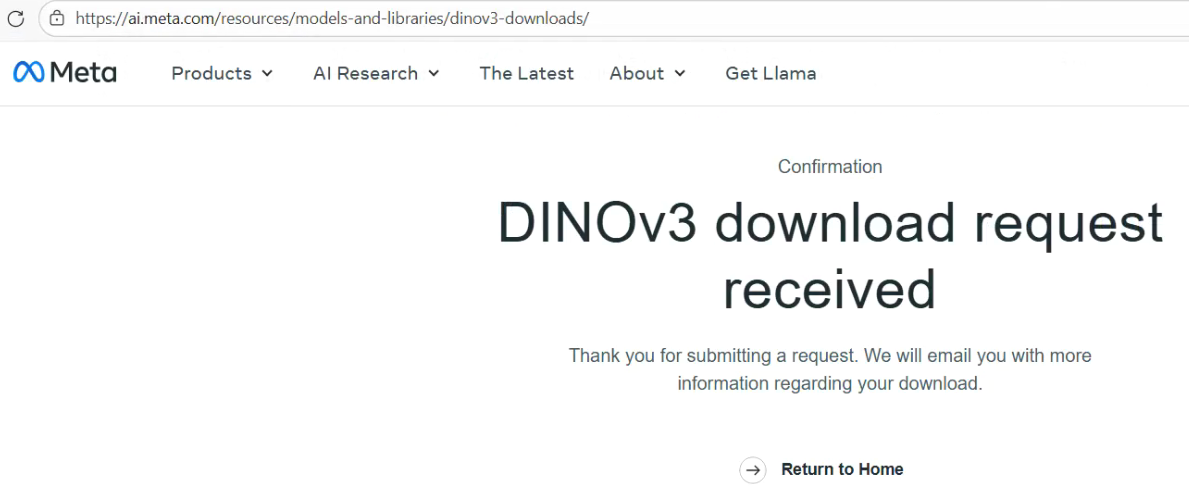
你可以看到这样邮件
![]()
里面有很多的下载链接,我们要下载的是 dinov3_vits16_pretrain_lvd1689m-08c60483.pth
这个模型只有80多M
![]()
2 数据集
数据集有四个文件夹,里面依次是飞机、猫、狗、湖的图片

3 设备环境
NVIDIA GeForce RTX 3060
python版本3.11.13
torch用一条命令就能安装上
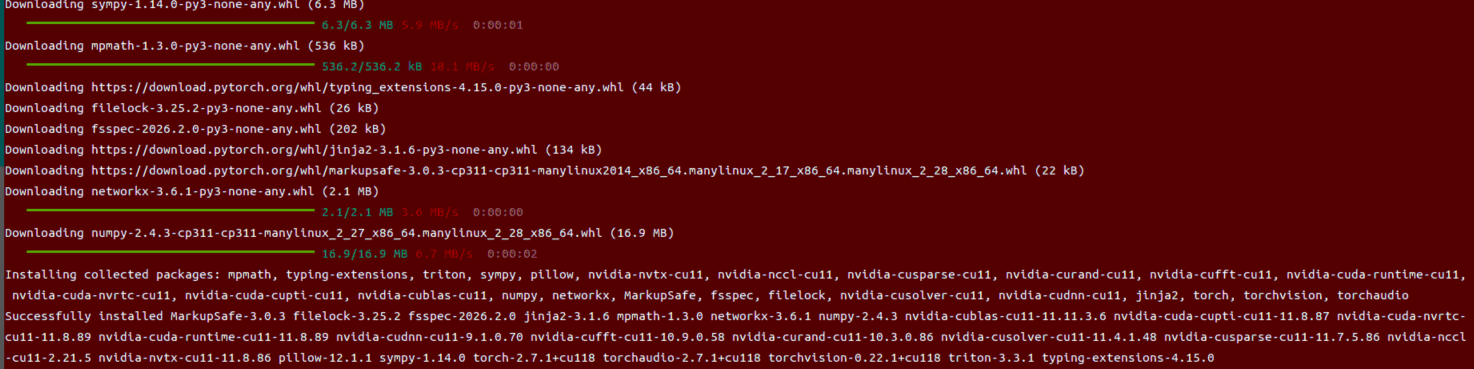
即使我的机器中并没有安装cuda
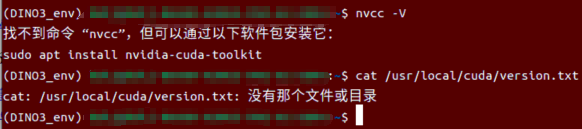
但发现也能正常用
其余的用pip就能安装上
4 加载
需要有这三个文件。dinov3-main就是github上找的源码,dinov3_vits16_pretrain_lvd1689m-08c60483.pth是我们下载的pth文件
运行下面的代码
![]()
如果成功就是执行了把pth文件放到另一个位置的操作

5 抽象
大模型的逻辑是把当前的图像数字化,从而让你方便去做其他任何的视觉任务,比如图像分类、目标检测、图像分割等
我们比如对于airplane_0.jpg这张图像进行抽象

发现我们把这张图抽象成了形状为(384,1)的浮点矩阵,也就是用384个浮点数表示了当前这张图像

6 抽象对比
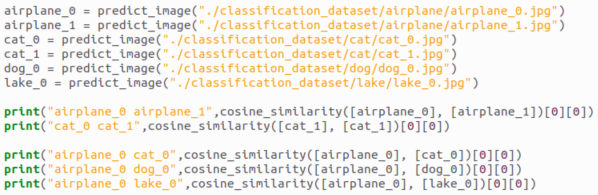
我们可以使用sklearn中的cosine_similarity将两个向量进行对比
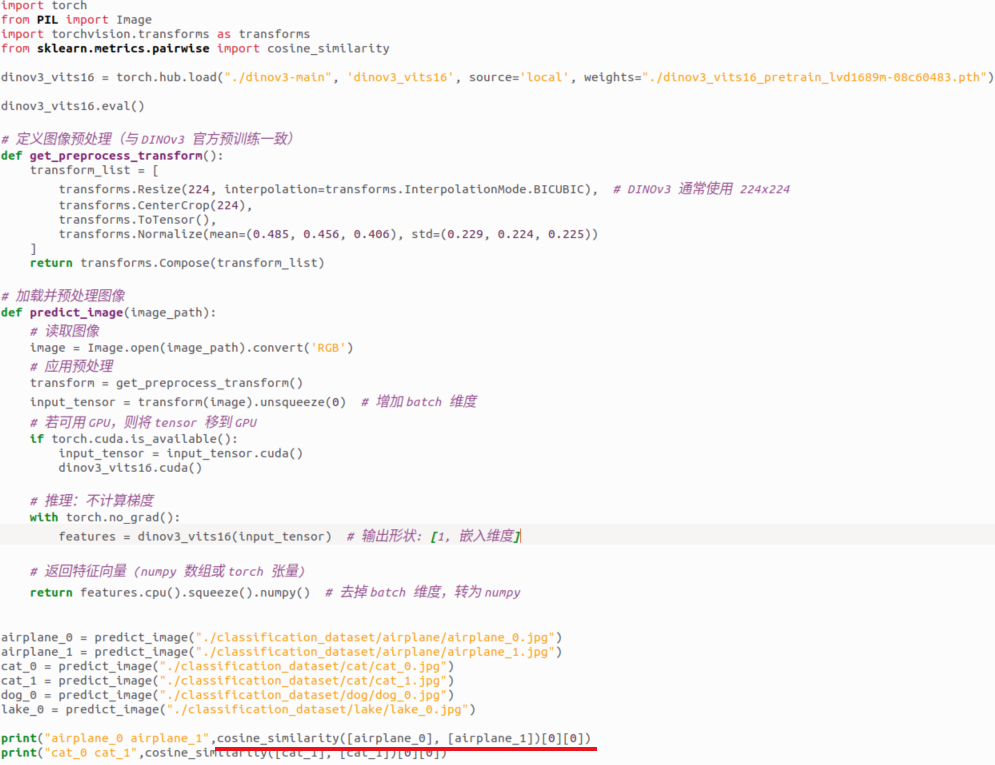
我们依次比较
- 飞机0和飞机1
- 猫0和猫1
- 飞机0和猫0
- 飞机0和狗0
- 飞机0和湖0
前面两组比较是类型相同的图片,我们发现他们的得分很高.后面三个是类型不同的图像,我们发现他们的得分很低
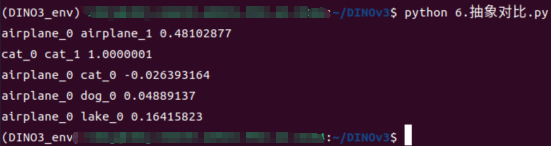
到这一步我们可以看出来,大模型在非训练的条件下,已经做到了某些训练过的小模型能做的事情

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)