C++11核心特性深度解析
目录
1. 列表初始化(Uniform Initialization)
2.C++11的底层机制:std::initializer_list
C++11是C++发展史上的里程碑式更新,带来了革命性的语言特性和标准库增强。本文将系统剖析其核心机制,助你掌握现代C++编程精髓。
一、C++11:现代C++的开端
C++11(原称C++0x)于2011年8月发布,是自C++98以来最重要的更新。其核心目标包括:
-
统一初始化:提供一致的初始化语法
-
性能优化:引入移动语义减少拷贝开销
-
抽象增强:提升类型系统和泛型编程能力
-
并发支持:内置多线程和内存模型
版本演进路线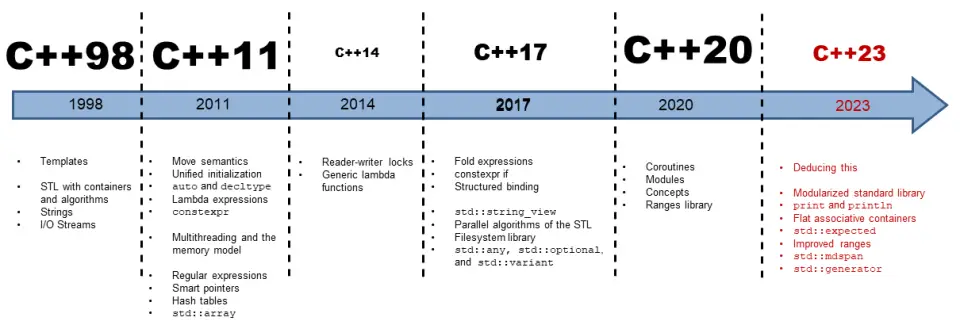
1. 列表初始化(Uniform Initialization)
目的:消除不同类型初始化的语法差异
(1) C++98传统的{}
C++98中⼀般数组和结构体可以⽤{}进⾏初始化

(2)C++11中的{}
-
C++11以后想统⼀初始化⽅式,试图实现⼀切对象皆可⽤{}初始化,{}初始化也叫做列表初始化。
-
内置类型⽀持,⾃定义类型也⽀持,⾃定义类型本质是类型转换,中间会产⽣临时对象,最后优化 了以后变成直接构造。
-
{}初始化的过程中,可以省略掉=
-
C++11列表初始化的本意是想实现⼀个⼤统⼀的初始化⽅式,其次他在有些场景下带来的不少便 利,如容器push/inset多参数构造的对象时,{}初始化会很方便


(3)简概
// 传统初始化方式混杂
Point p = {1, 2}; // 聚合初始化
Date d(2023, 1, 1); // 构造函数初始化
// C++11统一语法
int x{5}; // 内置类型
std::vector<int> v{1,2,3}; // 容器初始化
Date d{2023, 1, 1}; // 自定义类型2.C++11的底层机制:std::initializer_list
(1)详解
-
上⾯的初始化已经很⽅便,但是对象容器初始化还是不太⽅便,⽐如⼀个vector对象,我想⽤N个
-
值去构造初始化,那么我们得实现很多个构造函数才能⽀持, vector<int> v1 = {1,2,3};vector<int> v2 = {1,2,3,4,5};
-
C++11库中提出了⼀个std::initializer_list的类, auto il = { 10, 20, 30 }; // the type of il is an initializer_list ,这个类的本质是底层开⼀个数组,将数据拷⻉ 过来,std::initializer_list内部有两个指针分别指向数组的开始和结束。
-
这是他的⽂档:initializer_list,std::initializer_list⽀持迭代器遍历。
-
容器⽀持⼀个std::initializer_list的构造函数,也就⽀持任意多个值构成的 {x1,x2,x3...} 进⾏ 初始化。STL中的容器⽀持任意多个值构成的 {x1,x2,x3...} 进⾏初始化,就是通过std::initializer_list的构造函数⽀持的。

(2)简概
template<class T>
class vector {
public:
vector(std::initializer_list<T> init) {
for(const auto& e : init)
push_back(e);
}
};二、右值引用与移动语义
C++98的C++语法中就有引⽤的语法,⽽C++11中新增了的右值引⽤语法特性,C++11之后我们之前学习的引⽤就叫做左值引⽤。⽆论左值引⽤还是右值引⽤,都是给对象取别名。
1.核心概念
-
左值:持久对象(可取地址)
左值是⼀个表⽰数据的表达式(如变量名或解引⽤的指针),⼀般是有持久状态,存储在内存中,我 们可以获取它的地址,左值可以出现赋值符号的左边,也可以出现在赋值符号右边。定义时const 修饰符后的左值,不能给他赋值,但是可以取它的地址。
-
右值:临时对象(不可取地址)
右值也是⼀个表⽰数据的表达式,要么是字⾯值常量、要么是表达式求值过程中创建的临时对象 等,右值可以出现在赋值符号的右边,但是不能出现出现在赋值符号的左边,右值不能取地址。
-
将亡值(xvalue):可被移动的资源
2.左值引用和右值引用
(1) 详解
- Type& r1 = x; Type&& rr1 = y; 第⼀个语句就是左值引⽤,左值引⽤就是给左值取别 名,第⼆个就是右值引⽤,同样的道理,右值引⽤就是给右值取别名。
- 左值引⽤不能直接引⽤右值,但是const左值引⽤可以引⽤右值
- 右值引⽤不能直接引⽤左值,但是右值引⽤可以引⽤move(左值)
- template <class T> typename remove_reference<T>::type&& move (T&& arg); move是库⾥⾯的⼀个函数模板,本质内部是进⾏强制类型转换,当然他还涉及⼀些引⽤折叠的知 识,这个我们后⾯会细讲。
- 需要注意的是变量表达式都是左值属性,也就意味着⼀个右值被右值引⽤绑定后,右值引⽤变量变 量表达式的属性是左值
- 语法层⾯看,左值引⽤和右值引⽤都是取别名,不开空间。从汇编底层的⻆度看下⾯代码中r1和rr1 汇编层实现,底层都是⽤指针实现的,没什么区别。底层汇编等实现和上层语法表达的意义有时是 背离的,所以不要然到⼀起去理解,互相佐证,这样反⽽是陷⼊迷途。


(2) 简概
// 左值引用 vs 右值引用
int a = 10;
int& lref = a; // 左值引用
int&& rref = 10; // 右值引用
int&& rref2 = std::move(a); // 显式转换3.移动构造和移动赋值
-
移动构造函数是⼀种构造函数,类似拷贝构造函数,移动构造函数要求第⼀个参数是该类类型的引 ⽤,但是不同的是要求这个参数是右值引⽤,如果还有其他参数,额外的参数必须有缺省值。
-
移动赋值是⼀个赋值运算符的重载,他跟拷贝赋值构成函数重载,类似拷贝赋值函数,移动赋值函 数要求第⼀个参数是该类类型的引⽤,但是不同的是要求这个参数是右值引⽤。
-
对于像string/vector这样的深拷贝的类或者包含深拷贝的成员变量的类,移动构造和移动赋值才有 意义,因为移动构造和移动赋值的第⼀个参数都是右值引⽤的类型,他的本质是要“窃取”引⽤的 右值对象的资源,⽽不是像拷贝构造和拷贝赋值那样去拷贝资源,从提⾼效率。下⾯的bit::string 样例实现了移动构造和移动赋值,我们需要结合场景理解
右值对象构造,只有拷贝构造,没有移动构造的场景
class String {
public:
// 移动构造函数
String(String&& s) noexcept
: data_(s.data_), size_(s.size_)
{
s.data_ = nullptr; // "窃取"资源
}
// 移动赋值运算符
String& operator=(String&& s) noexcept {
if(this != &s) {
delete[] data_;
data_ = s.data_;
size_ = s.size_;
s.data_ = nullptr;
}
return *this;
}
private:
char* data_;
size_t size_;
};4.完美转发
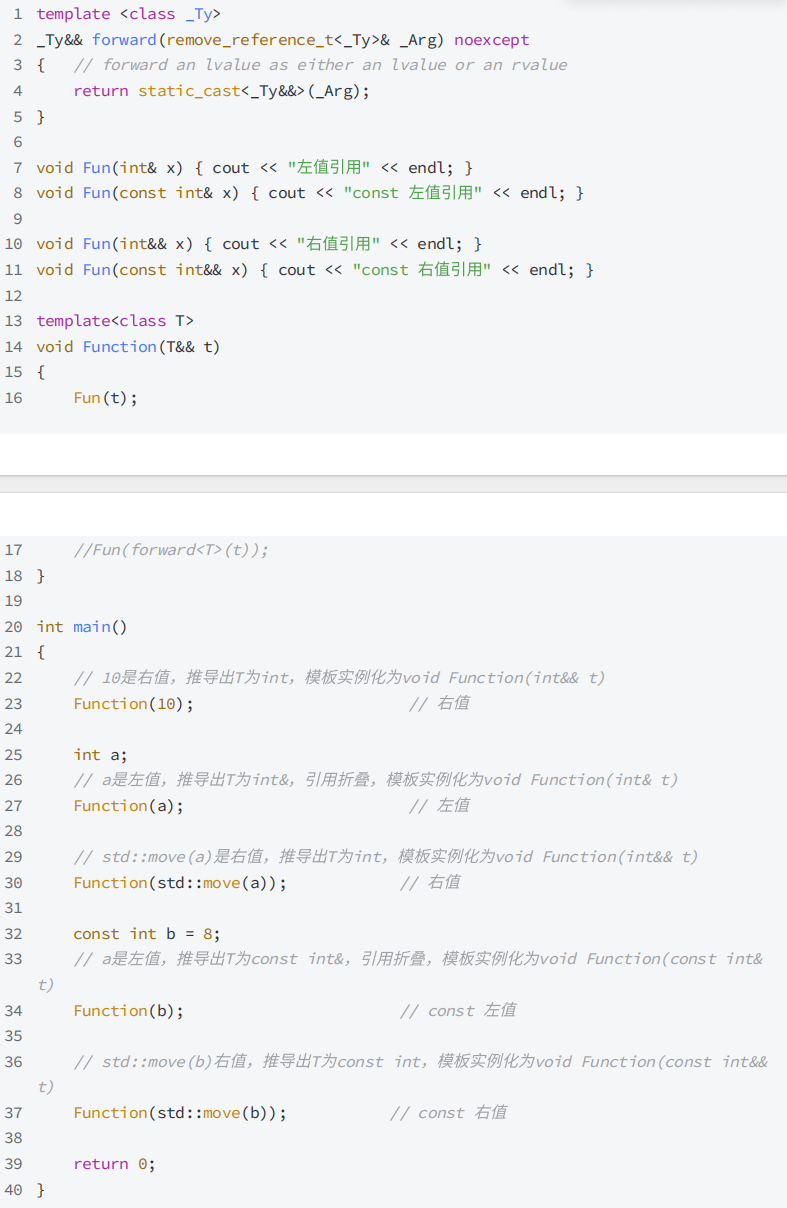
-
Function(T&& t)函数模板程序中,传左值实例化以后是左值引⽤的Function函数,传右值实例化 以后是右值引⽤的Function函数。
-
但是结合我们在5.2章节的讲解,变量表达式都是左值属性,也就意味着⼀个右值被右值引⽤绑定 后,右值引⽤变量表达式的属性是左值,也就是说Function函数中t的属性是左值,那么我们把t传 递给下⼀层函数Fun,那么匹配的都是左值引⽤版本的Fun函数。这⾥我们想要保持t对象的属性, 就需要使⽤完美转发实现。
-
template <class T> T&& forward (typename remove_reference<T>::type& arg);
-
template <class T> T&& forward (typename remove_reference<T>::type&& arg);
-
完美转发forward本质是⼀个函数模板,他主要还是通过引⽤折叠的⽅式实现,下⾯⽰例中传递给 Function的实参是右值,T被推导为int,没有折叠,forward内部t被强转为右值引⽤返回;传递给 Function的实参是左值,T被推导为int&,引⽤折叠为左值引⽤,forward内部t被强转为左值引⽤ 返回。
三、类型分类
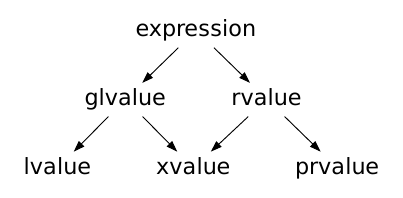
-
C++11以后,进⼀步对类型进⾏了划分,右值被划分纯右值(pure value,简称prvalue)和将亡值 (expiring value,简称xvalue)。
-
纯右值是指那些字⾯值常量或求值结果相当于字⾯值或是⼀个不具名的临时对象。如: 42、true、nullptr 或者类似 str.substr(1, 2)、str1 + str2 传值返回函数调⽤,或者整形 a、b,a++,a+b 等。纯右值和将亡值C++11中提出的,C++11中的纯右值概念划分等价于 C++98中的右值。
-
将亡值是指返回右值引⽤的函数的调⽤表达式和转换为右值引⽤的转换函数的调⽤表达,如 move(x)、static_cast<X&&>(x)
-
泛左值(generalized value,简称glvalue),泛左值包含将亡值和左值。
-
值类别 - cppreference.com 和 Value categories这两个关于值类型的中⽂和英⽂的官⽅⽂档,有兴 趣可以了解细节。
四、引用折叠
- C++中不能直接定义引⽤的引⽤如 int& && r = i; ,这样写会直接报错,通过模板或 typedef 中的类型操作可以构成引⽤的引⽤。
- 通过模板或 typedef 中的类型操作可以构成引⽤的引⽤时,这时C++11给出了⼀个引⽤折叠的规 则:右值引⽤的右值引⽤折叠成右值引⽤,所有其他组合均折叠成左值引⽤。
- 下⾯的程序中很好的展⽰了模板和typedef时构成引⽤的引⽤时的引⽤折叠规则,⼤家需要⼀个⼀ 个仔细理解⼀下。
- 像f2这样的函数模板中,T&& x参数看起来是右值引⽤参数,但是由于引⽤折叠的规则,他传递左 值时就是左值引⽤,传递右值时就是右值引⽤,有些地⽅也把这种函数模板的参数叫做万能引⽤。
- Function(T&& t)函数模板程序中,假设实参是int右值,模板参数T的推导int,实参是int左值,模 板参数T的推导int&,再结合引⽤折叠规则,就实现了实参是左值,实例化出左值引⽤版本形参的 Function,实参是右值,实例化出右值引⽤版本形参的Function。
// 由于引⽤折叠限定,f1实例化以后总是⼀个左值引⽤
template<class T>
void f1(T& x)
{}
// 由于引⽤折叠限定,f2实例化后可以是左值引⽤,也可以是右值引⽤
template<class T>
void f2(T&& x)
{}
int main()
{
typedef int& lref;
typedef int&& rref;
int n = 0;
lref& r1 = n; // r1 的类型是 int&
lref&& r2 = n; // r2 的类型是 int&
rref& r3 = n; // r3 的类型是 int&
rref&& r4 = 1; // r4 的类型是 int&&
// 没有折叠->实例化为void f1(int& x)
f1<int>(n);
f1<int>(0); // 报错
// 折叠->实例化为void f1(int& x)
f1<int&>(n);
f1<int&>(0); // 报错
// 折叠->实例化为void f1(int& x)
f1<int&&>(n);
f1<int&&>(0); // 报错
// 折叠->实例化为void f1(const int& x)
f1<const int&>(n);
f1<const int&>(0);
// 折叠->实例化为void f1(const int& x)
f1<const int&&>(n);
f1<const int&&>(0);
// 没有折叠->实例化为void f2(int&& x)
f2<int>(n); // 报错
f2<int>(0);
// 折叠->实例化为void f2(int& x)
4f2<int&>(n);
f2<int&>(0); // 报错
// 折叠->实例化为void f2(int&& x)
f2<int&&>(n); // 报错
f2<int&&>(0);
return 0;
}五、可变参数模板
1. 基本语法及原理
-
C++11⽀持可变参数模板,也就是说⽀持可变数量参数的函数模板和类模板,可变数⽬的参数被称 为参数包,存在两种参数包:模板参数包,表⽰零或多个模板参数;函数参数包:表⽰零或多个函 数参数。
-
template <class ...Args> void Func(Args... args) {}
-
template <class ...Args> void Func(Args&... args) {}
-
template <class ...Args> void Func(Args&&... args) {}
-
我们⽤省略号来指出⼀个模板参数或函数参数的表⽰⼀个包,在模板参数列表中,class...或 typename...指出接下来的参数表⽰零或多个类型列表;在函数参数列表中,类型名后⾯跟...指出 接下来表⽰零或多个形参对象列表;函数参数包可以⽤左值引⽤或右值引⽤表⽰,跟前⾯普通模板 ⼀样,每个参数实例化时遵循引⽤折叠规则。
-
可变参数模板的原理跟模板类似,本质还是去实例化对应类型和个数的多个函数。
-
这⾥我们可以使⽤sizeof...运算符去计算参数包中参数的个数。
2. 包扩展
-
对于⼀个参数包,我们除了能计算他的参数个数,我们能做的唯⼀的事情就是扩展它,当扩展⼀个 包时,我们还要提供⽤于每个扩展元素的模式,扩展⼀个包就是将它分解为构成的元素,对每个元 素应⽤模式,获得扩展后的列表。我们通过在模式的右边放⼀个省略号(...)来触发扩展操作。底层 的实现细节如图所示。
-
C++还⽀持更复杂的包扩展,直接将参数包依次展开依次作为实参给⼀个函数去处理。

3.empalce系列接⼝
-
template <class... Args> void emplace_back (Args&&... args);
-
template <class... Args> iterator emplace (const_iterator position, Args&&... args);
-
C++11以后STL容器新增了empalce系列的接口,empalce系列的接⼝均为模板可变参数,功能上 兼容push和insert系列,但是empalce还⽀持新玩法,假设容器为container<T>,empalce还⽀持 直接插⼊构造T对象的参数,这样有些场景会更⾼效⼀些,可以直接在容器空间上构造T对象。
-
emplace_back总体而言是更高效,推荐以后使用emplace系列替代insert和push系列
-
第⼆个程序中我们模拟实现了list的emplace和emplace_back接⼝,这⾥把参数包不段往下传递, 最终在结点的构造中直接去匹配容器存储的数据类型T的构造,所以达到了前⾯说的empalce⽀持 直接插⼊构造T对象的参数,这样有些场景会更⾼效⼀些,可以直接在容器空间上构造T对象。
-
传递参数包过程中,如果是 Args&&... args 的参数包,要⽤完美转发参数包,方式如下 std::forward<Args>(args)... ,否则编译时包扩展后右值引⽤变量表达式就变成了左值。
list<pair<string, int>> lt;
lt.emplace_back("苹果", 1); // 直接构造pair六、新的类功能
1.成员变量声明时给缺省值
成员变量声明时给缺省值是给初始化列表⽤的,如果没有显⽰在初始化列表初始化,就会在初始化列 表⽤这个却绳⼦初始化。
class Foo {
int x = 10; // 声明时初始化
};2.defult和delete
- C++11可以让你更好的控制要使⽤的默认函数。假设你要使⽤某个默认的函数,但是因为⼀些原因 这个函数没有默认⽣成。⽐如:我们提供了拷⻉构造,就不会⽣成移动构造了,那么我们可以使⽤ default关键字显⽰指定移动构造⽣成。
- 如果能想要限制某些默认函数的⽣成,在C++98中,是该函数设置成private,并且只声明补丁已, 这样只要其他⼈想要调⽤就会报错。在C++11中更简单,只需在该函数声明加上=delete即可,该语法指⽰编译器不⽣成对应函数的默认版本,称=delete修饰的函数为删除函数。
class Person
{
public:
Person(const char* name = "", int age = 0)
:_name(name)
, _age(age)
{}
Person(const Person& p)
:_name(p._name)
,_age(p._age)
{}
Person(Person&& p) = default;
//Person(const Person& p) = delete;
private:
bit::string _name;
int _age;
};
int main()
{
Person s1;
Person s2 = s1;
Person s3 = std::move(s1);
return 0;
}七、Lambda表达式
1.语法结构
lambda 表达式本质是⼀个匿名函数对象,跟普通函数不同的是他可以定义在函数内部。
lambda 表达式语法使⽤层⽽⾔没有类型,所以我们⼀般是⽤auto或者模板参数定义的对象去接
收 lambda 对象。
lambda表达式的格式: [capture-list] (parameters)-> return type { function boby }
[capture-list] : 捕捉列表,该列表总是出现在 lambda 函数的开始位置,编译器根据[]来
判断接下来的代码是否为 lambda 函数,捕捉列表能够捕捉上下⽂中的变量供 lambda 函数使
⽤,捕捉列表可以传值和传引⽤捕捉,具体细节7.2中我们再细讲。捕捉列表为空也不能省略。
(parameters) :参数列表,与普通函数的参数列表功能类似,如果不需要参数传递,则可以连
同()⼀起省略。
->return type :返回值类型,⽤追踪返回类型形式声明函数的返回值类型,没有返回值时此
部分可省略。⼀般返回值类型明确情况下,也可省略,由编译器对返回类型进⾏推导。
{function boby} :函数体,函数体内的实现跟普通函数完全类似,在该函数体内,除了可以
使⽤其参数外,还可以使⽤所有捕获到的变量,函数体为空也不能省略。
int main()
{
// ⼀个简单的lambda表达式
auto add1 = [](int x, int y)->int {return x + y; };
cout << add1(1, 2) << endl;
// 1、捕捉为空也不能省略
// 2、参数为空可以省略
// 3、返回值可以省略,可以通过返回对象⾃动推导
// 4、函数题不能省略
auto func1 = []
{
cout << "hello bit" << endl;
return 0;
};
func1();
int a = 0, b = 1;
auto swap1 = [](int& x, int& y)
{
int tmp = x;
x = y;
y = tmp;
};
swap1(a, b);
cout << a << ":" << b << endl;
return 0;
}2 捕捉列表
-
lambda 表达式中默认只能⽤ lambda 函数体和参数中的变量,如果想⽤外层作⽤域中的变量就 需要进⾏捕捉
-
第⼀种捕捉⽅式是在捕捉列表中显⽰的传值捕捉和传引⽤捕捉,捕捉的多个变量⽤逗号分割。[x, y, &z] 表⽰x和y值捕捉,z引⽤捕捉。
-
第⼆种捕捉⽅式是在捕捉列表中隐式捕捉,我们在捕捉列表写⼀个=表⽰隐式值捕捉,在捕捉列表 写⼀个&表⽰隐式引⽤捕捉,这样我们 lambda 表达式中⽤了那些变量,编译器就会⾃动捕捉那些 变量。
-
第三种捕捉⽅式是在捕捉列表中混合使⽤隐式捕捉和显⽰捕捉。[=, &x]表⽰其他变量隐式值捕捉, x引⽤捕捉;[&, x, y]表⽰其他变量引⽤捕捉,x和y值捕捉。当使⽤混合捕捉时,第⼀个元素必须是 &或=,并且&混合捕捉时,后⾯的捕捉变量必须是值捕捉,同理=混合捕捉时,后⾯的捕捉变量必 须是引⽤捕捉。
-
lambda 表达式如果在函数局部域中,他可以捕捉 lambda 位置之前定义的变量,不能捕捉静态 局部变量和全局变量,静态局部变量和全局变量也不需要捕捉, lambda 表达式中可以直接使 ⽤。这也意味着 lambda 表达式如果定义在全局位置,捕捉列表必须为空。
-
默认情况下, lambda 捕捉列表是被const修饰的,也就是说传值捕捉的过来的对象不能修改, mutable加在参数列表的后⾯可以取消其常量性,也就说使⽤该修饰符后,传值捕捉的对象就可以 修改了,但是修改还是形参对象,不会影响实参。使⽤该修饰符后,参数列表不可省略(即使参数为空)。



八、 包装器
1.std::function
-
统一可调用对象类型:
template <class T>
class function; // undefined
template <class Ret, class... Args>
class function<Ret(Args...)>;-
储其他的可以调⽤对象,包括函数指针、仿函数、 lambda 、 bind 表达式等,存储的可调⽤对 象被称为 std::function 的⽬标。若 std::function 不含⽬标,则称它为空。调用空std::function 的⽬标导致抛出 std::bad_function_call 异常。
-
以上是 function 的原型,他被定义<functional>头⽂件中。std::function - cppreference.com 是function的官⽅⽂件链接。
-
函数指针、仿函数、 lambda 等可调⽤对象的类型各不相同, std::function 的优势就是统 ⼀类型,对他们都可以进⾏包装,这样在很多地⽅就⽅便声明可调⽤对象的类型,下⾯的第⼆个代 码样例展示了 std::function 作为map的参数,实现字符串和可调⽤对象的映射表功能。
2.std::bind
- 参数绑定与占位符
_1,_2:
simple ( 1 )template < class Fn , class ... Args>/* unspecified */ bind (Fn&& fn, Args&&... args);with return type ( 2 )template < class Ret, class Fn, class ... Args>/* unspecified */ bind (Fn&& fn, Args&&... args)
- bind 是⼀个函数模板,它也是⼀个可调⽤对象的包装器,可以把他看做⼀个函数适配器,对接收的fn可调⽤对象进⾏处理后返回⼀个可调⽤对象。 bind 可以⽤来调整参数个数和参数顺序。 bind 也在<functional>这个头⽂件中。
- 调⽤bind的⼀般形式: auto newCallable = bind(callable,arg_list); 其中 newCallable本⾝是⼀个可调⽤对象,arg_list是⼀个逗号分隔的参数列表,对应给定的callable的 参数。当我们调⽤newCallable时,newCallable会调⽤callable,并传给它arg_list中的参数。
- arg_list中的参数可能包含形如_n的名字,其中n是⼀个整数,这些参数是占位符,表⽰ newCallable的参数,它们占据了传递给newCallable的参数的位置。数值n表⽰⽣成的可调⽤对象 中参数的位置:_1为newCallable的第⼀个参数,_2为第⼆个参数,以此类推。_1/_2/_3....这些占 位符放到placeholders的⼀个命名空间中。
九、总结:C++11的核心价值
全面特性分类与影响分析
| 特性类别 | 代表特性 | 带来的革命性变革 |
|---|---|---|
| 核心语言 | 右值引用、Lambda表达式 | 实现了移动语义带来性能飞跃(如vector减少拷贝),函数式编程风格使编码更简洁直观 |
| 类型系统 | auto类型推导、decltype | 极大增强了泛型编程能力(如模板元编程),配合STL使用时代码可读性显著提升 |
| 内存模型 | 原子操作、内存序 | 首次标准化多线程支持,为跨平台并发编程提供可靠基础(如lock-free数据结构实现) |
| 标准库 | 智能指针、无序容器 | 引发资源管理革命(RAII范式),提供高性能哈希表等新数据结构(unordered_map等) |
C++11奠定了现代C++的基石,其设计哲学深刻影响了后续标准的演进。掌握这些核心特性,不仅能写出更高效的代码,更能理解当代C++的设计精髓。
附录:值类别关系图(C++11标准)
expression
/ \
glvalue rvalue
/ \ / \
lvalue xvalue prvalue(图中:glvalue=泛左值,xvalue=将亡值,prvalue=纯右值)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 52
52 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)