AI 马鞍工程(Harness Engineering)深入学习:给 AI 烈马套上可控的缰绳
AI马鞍工程深入学习
在之前的系列文章中,我们已经深入学习了 LangChain 基础框架、LangGraph 工作流编排、LlamaIndex 数据应用、CrewAI 多智能体协作,以及 MCP 互联互通标准。这些技术帮助我们构建了越来越强大的 AI 系统,但当我们把 AI 推向生产环境时,却发现了一个残酷的现实:模型越来越强,但 AI 依然不可靠。
你是否遇到过这些问题:
-
AI 写的代码第一次总是跑不起来,改 Bug 反而越改越多
-
聊着聊着 AI 就忘了之前的约定,把 200 行的约束忘得一干二净
-
项目迭代几次后,代码库越来越乱,架构约束被悄悄打破
-
单个 AI 能做简单任务,但复杂项目就会失控,最后还是要人工擦屁股
这正是 2026 年 AI 领域最热门的新范式 ——\\AI 马鞍工程(Harness Engineering)\\ 要解决的问题。它被称为 AI 生产化落地的最后一块拼图,也是 OpenAI、Anthropic、Stripe 等顶尖公司正在偷偷使用的核心技术。
一、什么是 AI 马鞍工程?
马鞍工程,英文名为 Harness Engineering,Harness 这个词的本义就是 "马具"—— 包括缰绳、马鞍、辔头、脚蹬这一整套装备。
这个领域有一个非常形象的核心比喻:
-
AI 模型 = 千里马:它跑得快、力量大、天赋异禀,能拉车、能耕田、能日行千里
-
马鞍工程 = 马具系统:它不是马本身,而是把马的力量引导到正确方向的工具
没有马具的千里马,再厉害也只能在草原上瞎跑;而有了完整马具的千里马,才能拉着车、载着人,安全、可控、高效地到达目的地。

正式定义
从学科定义来看,马鞍工程被精确界定为:设计围绕 AI 代理的系统、约束与反馈回路,以确保其在生产环境中可靠运行的工程学科。
业界有一个著名的公式:
Agent = Model + Harness
这个公式揭示了现代 AI 系统的本质:底层的大模型提供基础的智能能力,而 Harness(马鞍)则负责将这种能力转化为可靠、可控、可扩展的生产级系统。
为什么它突然火了?
2026 年初,两个案例引爆了整个行业:
-
OpenAI 的百万行代码项目:3 个工程师,5 个月时间,完全依靠 AI 生成了 100 万行生产级代码,没有一行人工编写的代码,产品已经在内部正式上线。
-
LangChain 的基准测试逆袭:LangChain 的编程 Agent,在没有换模型的情况下,仅仅优化了 Harness 部分,基准测试得分就从 52.8% 提升到 66.5%,排名直接从 30 名开外冲到了前 5。
这两个案例证明了一个颠覆性的结论:AI 编程的瓶颈,已经不在模型有多聪明,而在你围绕模型搭的这套环境和流程够不够好。
当模型能力已经足够强的时候,真正拉开差距的,就是谁的马鞍做得更好。
二、AI 工程的三代演进
马鞍工程不是凭空出现的,它是 AI 工程实践不断演进的结果,经历了三代清晰的发展阶段:
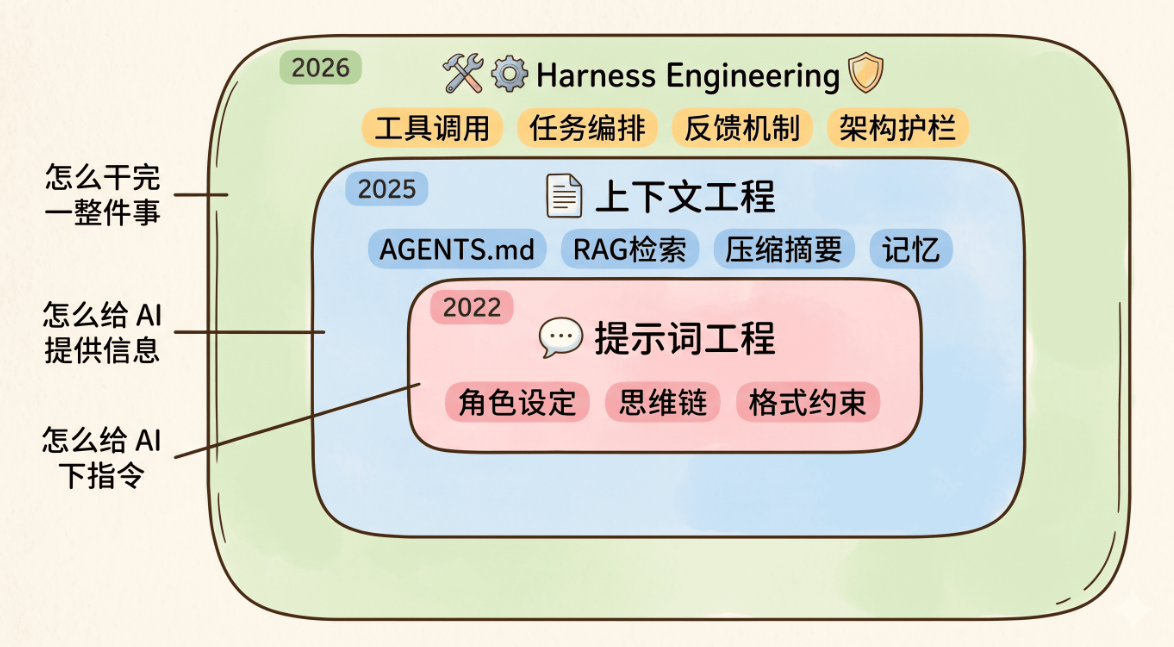
第一代:提示工程(2022-2024)
最早的 AI 工程,我们关注的是怎么通过对话让 AI 听懂你的需求。
我们学着给 AI 设定角色、约束输出格式、用思维链让它一步步思考、给几个示例让它模仿。这些技巧虽然简单,但确实能让单次交互的 AI 输出质量提升一大截。
但提示工程的局限很明显:它只关注单次交互,AI 聊久了就会忘,复杂任务根本 hold 不住。
第二代:上下文工程(2025)
在提示工程的基础上,我们开始关注怎么在对的时候把对的信息喂给 AI。
比如写 [AGENTS.md](AGENTS.md) 规则文件让 AI 了解项目背景,用 RAG 让 AI 能检索到相关资料,对过长的上下文做压缩和摘要,甚至给 AI 建立跨对话的记忆机制。
上下文工程解决了信息传递的问题,但它依然有局限:它只能优化单次推理,无法说明模型出错时会发生什么,也无法防止相同的错误下次再犯。
第三代:马鞍工程(2026 至今)
在上下文工程的基础上,我们终于走到了完整的系统层面:怎么设计整个运行环境,让 AI 能够持续、可靠地完成完整的任务。
马鞍工程不仅关注给 AI 提供什么信息,还要关注:
-
给 AI 配什么工具,让它能真正动手干活
-
大任务怎么拆分成小步骤,防止 AI 一把梭
-
出了问题怎么自己检查和修复
-
怎么防止代码质量随着迭代慢慢下滑
三者是层层包含的关系:
-
提示词是最内层,关注的是「怎么给 AI 下指令」
-
上下文包裹着提示词,关注的是「怎么给 AI 提供信息」
-
马鞍工程把它们全部包在里面,关注的是「怎么让 AI 持续靠谱地干完一整件事」
三、马鞍工程的核心架构
马鞍工程的技术实现围绕四大核心机制展开,形成完整的代理治理闭环:
1. 约束机制(Constrain):给 AI 划好边界
约束机制是马鞍的第一道防线,它的核心理念是:通过结构缩小可能性空间,而非通过行为指令。
简单来说,就是提前告诉 AI 什么能做,什么不能做,把那些错误的可能性从根源上删掉。
常见的约束包括:
-
API 边界定义:精确限定代理可调用的工具集合
-
工具权限分级:基于最小权限原则分配访问级别
-
架构规则强制:通过自定义 Linter 强制执行设计约束,比如分层架构的单向依赖
比如 Stripe 公司的架构约束:
Types → Config → Repo → Service → Runtime → UI
规则很简单:每一层只能 import 左边的层,绝对不能跨层调用,也不能有循环依赖。
你可能会问,限制这么多,会不会影响 AI 的创造力?
恰恰相反,约束反而提升了效率。没有约束的时候,AI 要花 30% 的 token 在思考 "这个文件放哪?用什么命名规范?",而有了约束之后,100% 的 token 都用在解决问题上。
约束不是限制创造力,是消除决策疲劳。
2. 告知机制(Inform):让 AI 知道该知道的
告知机制解决的是 AI "知道什么" 的问题,确保 AI 永远拥有完成任务所需的全部信息。
核心技术包括:
-
静态上下文:[AGENTS.md](AGENTS.md) 规则文件、架构规范、API 文档
-
动态上下文:实时日志、测试结果、工作进度
-
按需加载:大文档拆分成小文件,AI 需要的时候再读
OpenAI 的最佳实践是:不要把几千行的规则塞进一个大文件,而是把 [AGENTS.md](AGENTS.md) 当成目录,只写 100 行的摘要和索引,详细的规范放到单独的文件里,AI 需要什么就自己去读。
3. 验证机制(Verify):检查 AI 做得对不对
验证机制提供了输出的质量保障,它分为两层:
计算型验证
就是我们熟悉的自动化检查:
-
单元测试、类型检查
-
Linter 代码检查
-
结构测试
这些检查速度快、成本低、结果确定,是第一道防线。
推理型验证
用另一个 AI 来审查前一个 AI 的输出:
-
多 Agent 互审
-
LLM as Judge 语义检查
Anthropic 的研究发现,让 AI 评估自己的输出,会系统性地失败;但如果用完全隔离的上下文,让另一个 AI 来审查,就能达到 90% 的准确率。
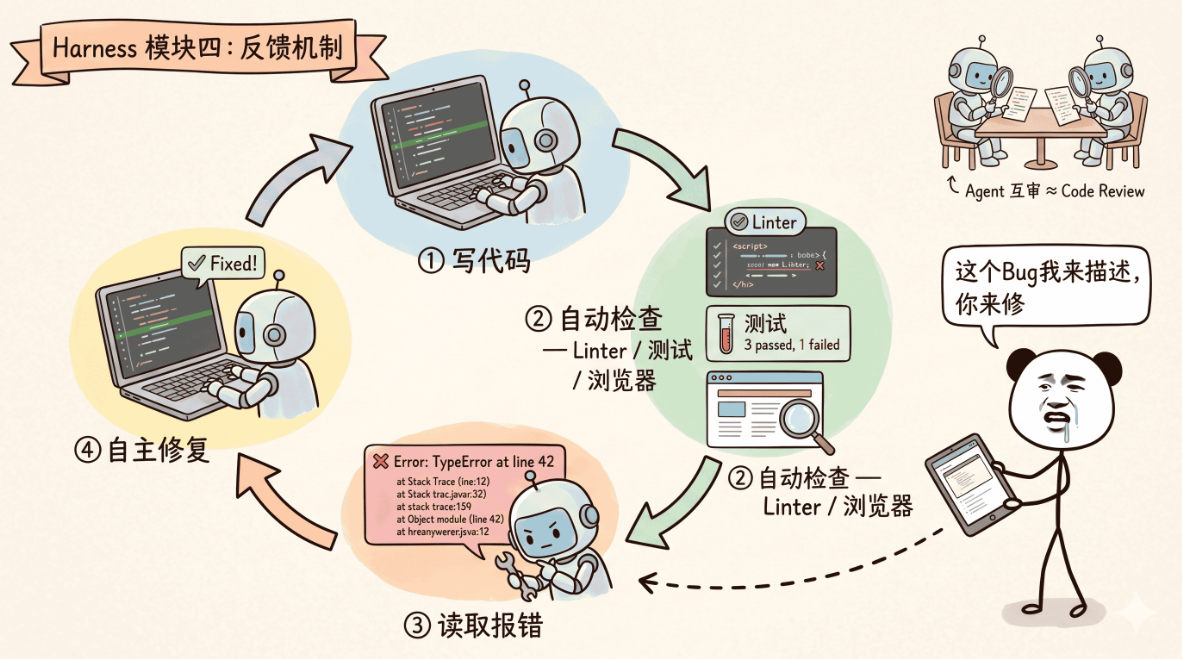
4. 纠正机制(Correct):犯错了自动修复
纠正机制实现了偏差检测与恢复,确保系统的韧性:
-
反馈回路:验证结果自动反馈给 AI,让它自己修复
-
自修复系统:定期扫描代码库,自动修复架构漂移
-
人工升级通道:复杂问题自动通知人类介入
有一个很重要的原则:成功应静默,失败才发声。测试通过的时候什么都不说,不污染上下文;只有测试失败的时候,才把错误信息告诉 AI,触发修复。
四、马鞍工程的五个核心模块
从实践层面,马鞍工程可以拆解为五个可落地的核心模块:
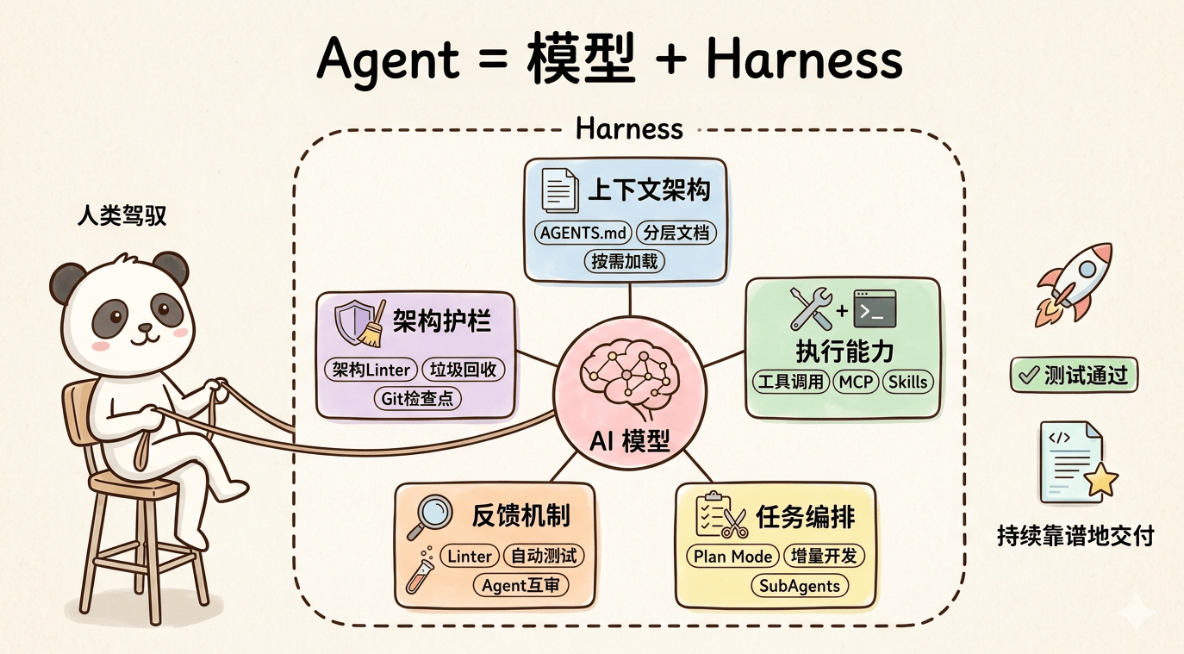
1. 上下文架构
让 AI 了解项目背景和规矩,包括 [AGENTS.md](AGENTS.md) 规则文件、分层文档、上下文压缩、渐进式加载。
2. 执行能力
给 AI 装上手脚和工具,包括工具调用、Bash 终端、文件系统、MCP 服务、Browser Use 浏览器自动化。
3. 任务编排
给 AI 安排好工作计划,包括任务拆分、Plan Mode 规划、增量开发、SubAgents 并行执行。
4. 反馈机制
让 AI 自己检查自己的工作,包括 Linter 检查、自动化测试、端到端测试、多 Agent 互审。
5. 架构护栏
防止代码越改越乱,包括架构约束 Linter、Pre-commit Hooks、垃圾回收机制、Git 检查点。
你会发现,这些其实都是我们做项目时常用的工程方法,只不过现在,我们把它们系统地应用到了 AI 编程上。
五、环境搭建:从 0 开始搭建你的第一个 Harness
马鞍工程可以循序渐进地落地,OpenAI 把它分为三个层级,你可以从最简单的开始:
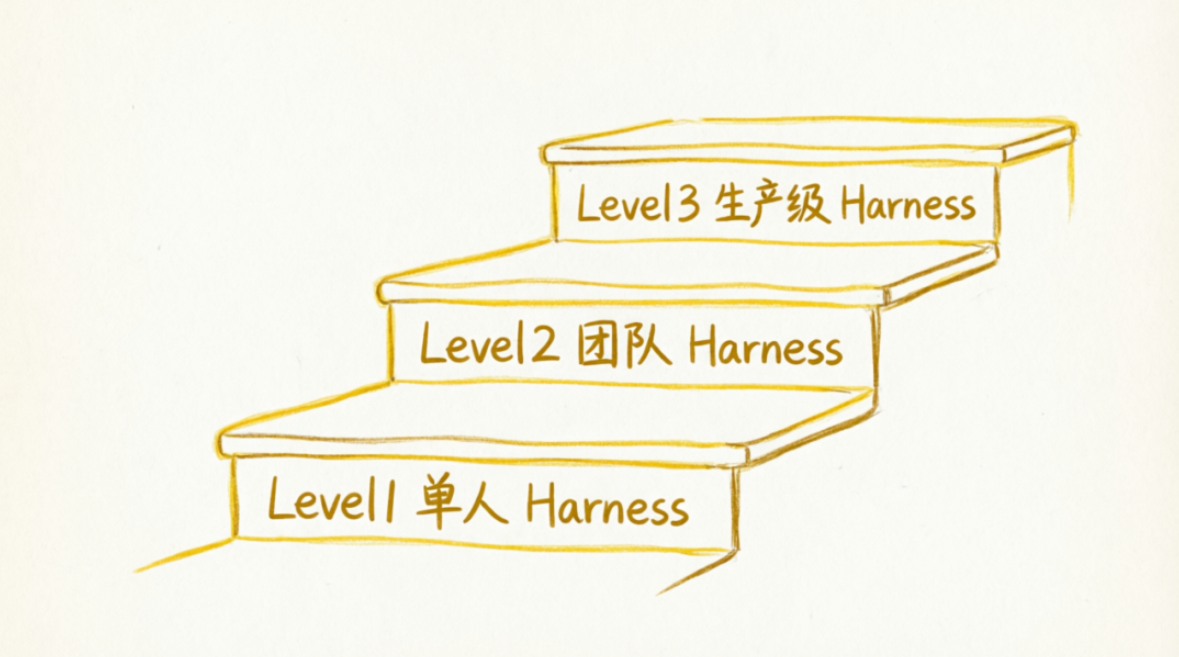
Level 1:单人 Harness(1-2 小时搭建)
适合个人开发者,用 Cursor、Claude Code 等工具,只需要做四件事:
1. 创建 [AGENTS.md](AGENTS.md) 规则文件
在项目根目录创建 AGENTS\.md,这是给 AI 看的入职手册:
# 项目概述
这是一个用户管理系统的后端服务
# 技术栈
- 语言:Python 3.11
- 框架:FastAPI
- 数据库:PostgreSQL
- ORM:SQLAlchemy
# 开发规范
- 遵循 PEP8 编码规范
- 所有函数必须有类型注解
- 所有 API 必须带错误处理
- 单文件代码不超过 200 行
# 目录结构
- src/models/: 数据模型
- src/schemas/: Pydantic schema
- src/services/: 业务逻辑
- src/api/: API 接口
- tests/: 单元测试
# 架构约束
- 只能单向依赖:models → schemas → services → api
- 禁止跨层调用
- 禁止循环依赖
# 常用命令
- pytest: 运行测试
- black .: 代码格式化
- mypy src: 类型检查
2. 配置 Pre-commit Hook
创建代码提交前的自动检查:
# 安装 pre-commit
pip install pre-commit
# 创建 .pre-commit-config.yaml
cat > .pre-commit-config.yaml << EOF
repos:
- repo: https://github.com/psf/black
rev: 24.3.0
hooks:
- id: black
- repo: https://github.com/PyCQA/flake8
rev: 7.0.0
hooks:
- id: flake8
- repo: https://github.com/python/mypy
rev: v1.10.0
hooks:
- id: mypy
EOF
# 安装 hook
pre-commit install
3. 编写架构约束 Linter
创建自定义的架构检查脚本,检查分层依赖:
# scripts/check_architecture.py
import os
import ast
from typing import Set, Dict
# 定义层级顺序
LAYERS_ORDER = {
'models': 0,
'schemas': 1,
'services': 2,
'api': 3
}
def check_file_imports(file_path: str) -> list:
"""检查文件的导入是否符合层级约束"""
errors = []
# 获取当前文件所在的层
current_layer = None
for layer in LAYERS_ORDER.keys():
if f'src/{layer}/' in file_path:
current_layer = layer
break
if not current_layer:
return errors
current_level = LAYERS_ORDER[current_layer]
with open(file_path, 'r', encoding='utf-8') as f:
try:
tree = ast.parse(f.read())
except:
return errors
for node in ast.walk(tree):
if isinstance(node, ast.ImportFrom):
if node.module:
for layer in LAYERS_ORDER.keys():
if node.module.startswith(f'src.{layer}'):
import_level = LAYERS_ORDER[layer]
if import_level > current_level:
errors.append(
f"跨层导入违规: {file_path} 导入了 {node.module}, "
f"{current_layer} 层不能导入 {layer} 层"
)
return errors
def main():
errors = []
for root, _, files in os.walk('src'):
for file in files:
if file.endswith('.py'):
file_path = os.path.join(root, file)
errors.extend(check_file_imports(file_path))
if errors:
print("❌ 架构约束检查失败:")
for err in errors:
print(f" - {err}")
exit(1)
else:
print("✅ 架构约束检查通过")
exit(0)
if __name__ == "__main__":
main()
4. 配置自动化测试
确保 AI 能自己跑测试验证结果:
# tests/test_user_service.py
import pytest
from src.services.user_service import UserService
def test_user_registration():
service = UserService()
user = service.register_user("test", "test@test.com", "password")
assert user.username == "test"
assert user.email == "test@test.com"
def test_user_login():
service = UserService()
service.register_user("test", "test@test.com", "password")
result = service.login("test@test.com", "password")
assert result.success == True
到这里,你的第一个单人 Harness 就搭建完成了!只需要 2 小时,就能让你的 AI 编程效率提升一倍。
六、实战教程:构建带自修复的 AI 编程 Agent
接下来我们来做一个更完整的实战:构建一个带完整 Harness 的 AI 编程 Agent,它能自动写代码、自动跑测试、失败了自动修复。
完整代码
import os
import subprocess
from openai import OpenAI
client = OpenAI()
class HarnessAgent:
def __init__(self):
self.max_retries = 3
def load_agents_rules(self) -> str:
"""加载 AGENTS.md 规则"""
with open('AGENTS.md', 'r', encoding='utf-8') as f:
return f.read()
def run_lint_and_test(self) -> tuple[bool, str]:
"""运行检查和测试,返回是否成功和输出"""
try:
# 运行架构检查
result = subprocess.run(
['python', 'scripts/check_architecture.py'],
capture_output=True, text=True
)
if result.returncode != 0:
return False, result.stdout
# 运行 lint
result = subprocess.run(
['pre-commit', 'run', '--all-files'],
capture_output=True, text=True
)
if result.returncode != 0:
return False, result.stdout
# 运行测试
result = subprocess.run(
['pytest', 'tests/', '-v'],
capture_output=True, text=True
)
if result.returncode != 0:
return False, result.stdout
return True, "所有检查通过"
except Exception as e:
return False, str(e)
def generate_code(self, task: str, feedback: str = None) -> str:
"""让 AI 生成代码,支持反馈修复"""
rules = self.load_agents_rules()
messages = [
{
"role": "system",
"content": f"""你是一个专业的 Python 开发者。
请严格遵循以下项目规则:
{rules}
你需要根据需求编写代码,写完之后会自动运行测试。
如果测试失败,我会告诉你错误信息,你需要修复。
"""
},
{
"role": "user",
"content": f"任务:{task}"
}
]
if feedback:
messages.append({
"role": "user",
"content": f"之前的代码有以下错误,请修复:\n{feedback}"
})
response = client.chat.completions.create(
model="gpt-4o",
messages=messages,
temperature=0.7
)
return response.choices[0].message.content
def execute_task(self, task: str) -> str:
"""执行任务,带自动修复循环"""
print(f"🚀 开始执行任务:{task}")
feedback = None
for attempt in range(self.max_retries):
print(f"\n📝 第 {attempt + 1} 次尝试...")
# 生成/修复代码
code_output = self.generate_code(task, feedback)
print(f"✅ AI 已生成代码")
# 解析并保存代码
# 这里简化处理,实际项目中你需要解析 AI 输出的文件变更
# 并写入到对应的文件中
# 运行检查
print("🔍 运行自动检查...")
success, result = self.run_lint_and_test()
if success:
print(f"🎉 任务完成!所有检查通过")
return result
else:
print(f"❌ 检查失败,准备修复...")
feedback = result
print(f"⚠️ 达到最大重试次数,任务未完成")
return feedback
if __name__ == "__main__":
agent = HarnessAgent()
# 执行任务
task = """
实现一个用户管理的 API,包含:
1. 用户注册接口
2. 用户登录接口
3. 用户信息查询接口
"""
result = agent.execute_task(task)
print("\n最终结果:", result)
代码解析
这个 Agent 实现了完整的 Harness 闭环:
-
规则加载:首先加载 [AGENTS.md](AGENTS.md) 的项目规则,让 AI 知道该怎么干活
-
代码生成:AI 根据任务生成代码
-
自动验证:自动运行架构检查、Lint、测试,验证代码质量
-
反馈修复:如果验证失败,把错误信息反馈给 AI,让它自动修复
-
循环重试:最多重试 3 次,确保任务能可靠完成
这就是一个最简单的生产级 Harness Agent!有了它,你只需要告诉 AI 要做什么,剩下的它自己就能搞定,再也不用盯着它改 Bug 了。
七、高级特性:企业级马鞍工程
当你的团队规模扩大之后,你还可以升级到企业级的 Harness:
1. 熵管理(垃圾回收)
定期运行清理 Agent,防止代码库的熵增:
-
文档一致性 Agent:每天检查文档是否和代码同步
-
架构审计 Agent:每周扫描架构约束违规
-
死代码清理 Agent:自动清理无用的代码和文件
2. 可观测性
给 Harness 加上监控:
-
Agent 性能指标:成功率、平均完成时间
-
错误分类:统计最常见的错误类型,针对性优化 Harness
-
实时 Dashboard:监控所有 Agent 的运行状态
3. 多 Agent 编排
用我们之前学过的 CrewAI,把多个专业 Agent 组织成团队:
-
编码 Agent:负责写代码
-
测试 Agent:负责写测试
-
审查 Agent:负责代码审查
-
文档 Agent:负责更新文档
它们协作完成任务,效率比单个 Agent 高好几倍。
八、实践避坑指南
在落地 Harness 的过程中,这些坑一定要避开:
坑一:过度设计控制流
不要把 Harness 做得太复杂,模型在快速进化,今天需要复杂 pipeline 的功能,明天模型一个 prompt 就能搞定。Harness 要设计成可拆卸的。
坑二:把 Harness 当成静态系统
Harness 需要持续演进:每次 AI 犯错,都要更新 [AGENTS.md](AGENTS.md),把这个错误的修复沉淀到系统里。一个月后,你的 Harness 会越来越聪明。
坑三:约束不足或约束过度
-
约束不足:AI 漫无目的,产出混乱
-
约束过度:AI 束手束脚,无法创新
建议从最小约束集开始,根据 AI 的实际表现逐步调整。
坑四:忽视文档的基础设施属性
[AGENTS.md](AGENTS.md) 不是普通文档,是 Harness 的核心组件。每次 AI 犯错,都要更新它,把它当成代码一样维护。
九、总结
在这篇文章中,我们深入学习了 AI 马鞍工程(Harness Engineering),这是 2026 年 AI 领域最热门的新范式。
它告诉我们,当模型能力已经足够强的时候,真正的瓶颈已经不再是模型本身,而是我们怎么设计一套系统,把模型的能力引导到正确的方向,让它能够可靠、可控地为我们工作。
通过我们这个系列的学习,你已经掌握了从单智能体到多智能体、从基础框架到互联互通标准、从提示词到完整的 Harness 系统的完整技术栈,相信这能够帮助你构建出真正生产级的 AI 应用。
如果你对我们的系列文章感兴趣,可以回顾之前的内容:
-
[CrewAI 深入学习:构建多智能体协作工作流]
-
[MCP (Model Context Protocol) 深入学习:构建 AI Agent 互联互通标准]
-
[LangGraph 深入学习:构建智能代理工作流]
-
[LangChain 深入学习]
-
[AI Agent 开发实战:LlamaIndex 框架深度应用指南]
在下一篇文章中,我们将继续探索 AI 开发的前沿技术,敬请期待。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)