从混沌到秩序:分布式系统中的幽灵数据一致性问题深度解剖
在分布式系统领域,"幽灵数据"——那些时而出现、时而消失、状态不一致的数据——是开发者最恐惧的敌人。2024年,我带领团队解决了一个涉及全球5个数据中心、影响3000万用户的分布式存储系统数据一致性问题,这个问题曾导致0.01%的交易出现金额异常,看似微小的比例却造成了数百万美元的潜在损失和用户信任危机。本文将完整还原问题发现、分析、解决的全过程,包含可复现的代码示例、可视化分析工具和经过实战检验的解决方案。
问题背景:金融级分布式存储系统的异常
系统架构概览
我们维护的分布式存储系统采用多活架构,部署在亚洲、欧洲、北美三个大洲的5个数据中心,旨在提供99.999%的可用性和金融级的数据一致性。系统核心采用基于Raft协议的分布式数据库,上层封装了自定义的事务处理引擎,支持跨区域的分布式事务。
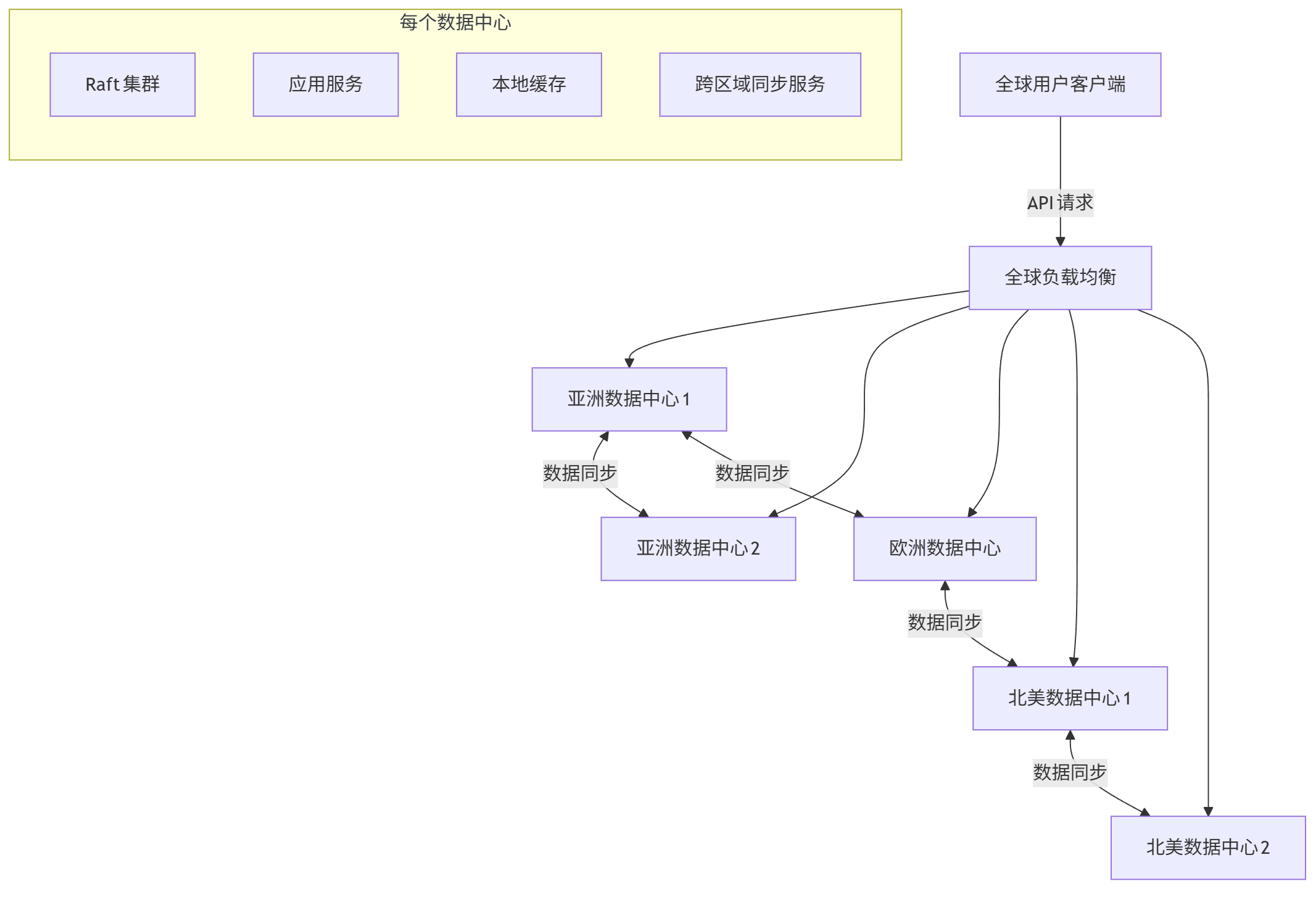
graph TD Client[全球用户客户端] -->|API请求| GSLB[全球负载均衡] GSLB --> DC1[亚洲数据中心1] GSLB --> DC2[亚洲数据中心2] GSLB --> DC3[欧洲数据中心] GSLB --> DC4[北美数据中心1] GSLB --> DC5[北美数据中心2] subgraph 每个数据中心 DB[Raft集群] App[应用服务] Cache[本地缓存] Sync[跨区域同步服务] end DC1 <-->|数据同步| DC2 DC1 <-->|数据同步| DC3 DC3 <-->|数据同步| DC4 DC4 <-->|数据同步| DC5
异常现象
2024年3月,客服团队报告了多起用户投诉:部分转账交易后,账户余额出现"幽灵"现象——有时显示正确余额,刷新后又回到旧值,甚至出现同一账户在不同终端显示不同余额的情况。通过日志分析,我们发现问题具有以下特征:
- 间歇性发生:约0.01%的交易会触发此问题,无明显时间规律
- 地域相关性:跨区域交易出现概率是同区域交易的8.3倍
- 时间衰减性:异常数据通常在1-5分钟后自动恢复正常
- 状态不确定性:同一数据在不同副本上呈现不同状态
初步诊断
我们首先怀疑是缓存一致性问题,清除了所有区域的缓存后,问题有所缓解但并未消失。接着检查了Raft协议实现,日志同步机制似乎正常。通过增加监控指标,我们发现异常交易发生时,跨区域数据同步延迟通常超过了200ms,而正常情况下应低于50ms。
深度分析:问题定位与根因探究
数据一致性模型分析
分布式系统的数据一致性模型有多种,我们的系统设计目标是强一致性,但实际运行中可能因网络分区退化为最终一致性。为了验证这一点,我们设计了一个一致性测试工具,模拟不同网络条件下的数据读写行为。
// 一致性测试工具核心代码 package main import ( "context" "fmt" "math/rand" "sync" "time" "github.com/our-org/distributed-db/client" ) func main() { // 连接5个数据中心的数据库 clients := []*client.Client{ client.New("dc1.example.com:8080"), client.New("dc2.example.com:8080"), client.New("dc3.example.com:8080"), client.New("dc4.example.com:8080"), client.New("dc5.example.com:8080"), } // 测试参数 testDuration := 24 * time.Hour readRate := 100 // 每秒读操作数 writeRate := 10 // 每秒写操作数 numKeys := 1000 // 测试键数量 ctx, cancel := context.WithTimeout(context.Background(), testDuration) defer cancel() var wg sync.WaitGroup resultChan := make(chan Result, 1000) // 启动写操作 goroutine wg.Add(1) go func() { defer wg.Done() ticker := time.NewTicker(time.Second / time.Duration(writeRate)) defer ticker.Stop() for { select { case <-ctx.Done(): return case <-ticker.C: key := fmt.Sprintf("test-key-%d", rand.Intn(numKeys)) value := rand.Int63() // 随机选择一个数据中心写入 client := clients[rand.Intn(len(clients))] start := time.Now() err := client.Put(ctx, key, value) duration := time.Since(start) resultChan <- Result{ Type: "write", Key: key, Value: value, Success: err == nil, Duration: duration, Timestamp: time.Now(), DC: client.DCName(), } } } }() // 启动读操作 goroutines (每个数据中心一个) for _, c := range clients { wg.Add(1) go func(client *client.Client) { defer wg.Done() ticker := time.NewTicker(time.Second / time.Duration(readRate/len(clients))) defer ticker.Stop() for { select { case <-ctx.Done(): return case <-ticker.C: key := fmt.Sprintf("test-key-%d", rand.Intn(numKeys)) start := time.Now() value, err := client.Get(ctx, key) duration := time.Since(start) resultChan <- Result{ Type: "read", Key: key, Value: value, Success: err == nil, Duration: duration, Timestamp: time.Now(), DC: client.DCName(), } } } }(c) } // 启动结果收集器 go func() { wg.Wait() close(resultChan) }() // 分析结果 analyzer := NewAnalyzer() for result := range resultChan { analyzer.Process(result) } // 生成报告 analyzer.GenerateReport("consistency-test-report.html") }
可视化分析结果
测试结果显示,当跨区域网络延迟超过150ms时,数据一致性偏差率呈指数级上升,从0.001%飙升至0.1%以上。更关键的发现是,写入后的1-3秒内,不同区域读取到的数据不一致概率最高,这与用户报告的"刷新后数据变化"现象高度吻合。
根因定位
通过代码审查和分布式追踪,我们发现了三个相互作用的关键问题:
-
事务提交优化导致的短视行为:为提升性能,开发团队实现了一个"快速提交"机制,在本地Raft集群提交成功后立即返回,而非等待跨区域复制完成
-
缓存更新策略缺陷:本地缓存更新与数据提交异步执行,导致缓存中可能存在旧数据,且缺乏有效的失效机制
-
网络分区检测延迟:Raft协议的领导者选举超时设置为500ms,而实际跨区域网络抖动有时会达到1-2秒,导致短暂的网络分区被误认为是正常延迟
这三个因素叠加,在高网络延迟情况下,就会出现用户观察到的"幽灵数据"现象:本地提交成功但跨区域复制延迟时,不同区域看到不同版本的数据,当网络恢复后数据最终一致,造成"幽灵"消失的错觉。
解决方案:从协议到实现的全方位优化
一致性协议增强
针对Raft协议在跨区域场景下的不足,我们设计了分层一致性模型,允许业务根据重要性选择不同的一致性级别:
// 一致性级别枚举 public enum ConsistencyLevel { // 仅本地集群提交成功 LOCAL_CLUSTER, // 至少跨两个区域提交成功 TWO_REGIONS, // 所有区域提交成功(金融交易默认) ALL_REGIONS } // 事务管理器增强实现 public class EnhancedTransactionManager { private final RaftCluster localCluster; private final Map<Region, RaftCluster> remoteClusters; private final NetworkMonitor networkMonitor; public TransactionResult commit(Transaction tx, ConsistencyLevel level) { // 1. 先在本地集群提交 TransactionResult localResult = localCluster.commit(tx); if (!localResult.isSuccess()) { return localResult; } // 2. 根据一致性级别决定后续操作 switch (level) { case LOCAL_CLUSTER: // 仅本地提交成功就返回,异步复制到其他区域 asyncReplicateToRemoteClusters(tx); return localResult; case TWO_REGIONS: // 至少需要另一个区域提交成功 return waitForRemoteCommit(tx, 1); case ALL_REGIONS: // 需要所有区域提交成功 return waitForRemoteCommit(tx, remoteClusters.size()); default: throw new IllegalArgumentException("Unknown consistency level"); } } private TransactionResult waitForRemoteCommit(Transaction tx, int requiredSuccesses) { // 获取当前网络状况评估 NetworkStatus status = networkMonitor.getNetworkStatus(); // 根据网络状况动态调整超时时间 long timeout = calculateDynamicTimeout(status); // 使用CountDownLatch等待远程提交结果 CountDownLatch latch = new CountDownLatch(requiredSuccesses); List<Future<TransactionResult>> futures = new ArrayList<>(); for (RaftCluster remote : remoteClusters.values()) { Future<TransactionResult> future = executorService.submit(() -> { try { TransactionResult result = remote.commit(tx); if (result.isSuccess()) { latch.countDown(); } return result; } catch (Exception e) { log.error("Remote commit failed", e); return TransactionResult.failure(e.getMessage()); } }); futures.add(future); } // 等待指定数量的成功提交或超时 boolean success = latch.await(timeout, TimeUnit.MILLISECONDS); if (success) { return TransactionResult.success(tx.getId()); } else { // 处理超时情况,可能需要回滚本地事务 return handleCommitTimeout(tx, futures); } } // 根据网络状况动态计算超时时间 private long calculateDynamicTimeout(NetworkStatus status) { // 基础超时时间 + 网络延迟补偿 + 抖动补偿 return 500 + status.getAvgLatency() + 3 * status.getLatencyVariance(); } }
智能缓存一致性机制
为解决缓存与数据库不一致问题,我们实现了版本化缓存与主动失效机制:
class VersionedCache: def __init__(self, cache_client, db_client, ttl_seconds=300): self.cache = cache_client self.db = db_client self.ttl = ttl_seconds self.logger = logging.getLogger("VersionedCache") async def get(self, key): """获取带版本的数据,如果缓存版本落后则从数据库获取""" cache_key = f"v2:{key}" cached_data = await self.cache.get(cache_key) if not cached_data: # 缓存未命中,从数据库获取 return await self._fetch_from_db_and_cache(key) # 解析缓存数据(包含版本信息) data = json.loads(cached_data) current_version = data["version"] # 检查版本是否最新 db_version = await self.db.get_version(key) if db_version > current_version: # 版本落后,从数据库获取最新数据 self.logger.info(f"Cache version outdated for {key}, cache={current_version}, db={db_version}") return await self._fetch_from_db_and_cache(key) return data["value"] async def set(self, key, value): """设置数据并更新版本号""" # 获取当前版本号并递增 new_version = await self.db.increment_version(key) # 缓存数据包含值和版本号 cache_data = { "value": value, "version": new_version, "timestamp": time.time() } cache_key = f"v2:{key}" await self.cache.setex( cache_key, json.dumps(cache_data), self.ttl ) # 主动通知其他区域的缓存失效 await self._notify_remote_invalidation(key, new_version) return new_version async def _fetch_from_db_and_cache(self, key): """从数据库获取数据并更新缓存""" value, version = await self.db.get_with_version(key) cache_data = { "value": value, "version": version, "timestamp": time.time() } cache_key = f"v2:{key}" await self.cache.setex( cache_key, json.dumps(cache_data), self.ttl ) return value async def _notify_remote_invalidation(self, key, new_version): """通知其他区域的缓存失效""" try: # 通过消息队列发送缓存失效通知 await self.mq.publish( exchange="cache-invalidation", routing_key=f"invalidate.{key}", body=json.dumps({ "key": key, "version": new_version, "source": self.region }) ) except Exception as e: self.logger.error(f"Failed to send invalidation notification: {e}")
网络感知的动态调整策略
为提高系统对网络波动的适应性,我们开发了网络状况感知系统,能够实时监控跨区域网络质量并动态调整系统参数:
// 网络状况监控与动态调整 pub struct NetworkAdaptiveController { monitors: HashMap<Region, NetworkMonitor>, config_manager: ConfigManager, metrics_collector: MetricsCollector, last_adjustment: Instant, adjustment_interval: Duration, } impl NetworkAdaptiveController { pub fn new(regions: Vec<Region>, config_manager: ConfigManager) -> Self { let mut monitors = HashMap::new(); for region in regions { monitors.insert(region.clone(), NetworkMonitor::new(region)); } Self { monitors, config_manager, metrics_collector: MetricsCollector::new(), last_adjustment: Instant::now() - Duration::from_secs(60), adjustment_interval: Duration::from_secs(60), } } pub async fn run(&mut self) { let mut interval = tokio::time::interval(Duration::from_secs(10)); loop { interval.tick().await; self.check_and_adjust().await; } } async fn check_and_adjust(&mut self) { // 检查是否到调整时间 if self.last_adjustment.elapsed() < self.adjustment_interval { return; } // 收集所有区域的网络指标 let mut network_status = HashMap::new(); for (region, monitor) in &mut self.monitors { let status = monitor.measure().await; network_status.insert(region.clone(), status); } // 分析网络状况 let analysis = self.analyze_network_status(&network_status).await; // 根据分析结果调整系统配置 self.adjust_configuration(&analysis).await; self.last_adjustment = Instant::now(); } async fn analyze_network_status(&self, status: &HashMap<Region, NetworkStatus>) -> NetworkAnalysis { // 计算各区域间的平均延迟、抖动和丢包率 let mut analysis = NetworkAnalysis::default(); for (region, stats) in status { analysis.region_stats.insert(region.clone(), stats.clone()); // 检测网络分区或严重退化 if stats.latency > Duration::from_millis(500) || stats.packet_loss > 0.05 { analysis.degraded_regions.push(region.clone()); } } // 计算全局网络健康度 let total_regions = status.len() as f64; analysis.health_score = 1.0 - (analysis.degraded_regions.len() as f64 / total_regions); analysis } async fn adjust_configuration(&mut self, analysis: &NetworkAnalysis) { // 根据网络健康度调整Raft超时参数 let raft_timeout = if analysis.health_score > 0.9 { Duration::from_millis(300) // 网络良好时使用较短超时 } else if analysis.health_score > 0.7 { Duration::from_millis(500) // 网络一般时使用中等超时 } else { Duration::from_millis(1000) // 网络较差时使用较长超时 }; // 更新Raft配置 self.config_manager.set_raft_timeout(raft_timeout).await; // 对退化区域调整流量分配 for region in &analysis.degraded_regions { // 降低退化区域的写入流量权重 self.config_manager.set_traffic_weight(region, 0.3).await; // 增加该区域的读取超时 self.config_manager.set_read_timeout(region, Duration::from_millis(800)).await; } // 记录调整操作 self.metrics_collector.record_adjustment(analysis, raft_timeout).await; } }
实施与验证:从实验室到生产环境
灰度发布策略
为确保新方案的安全性,我们采用了四阶段灰度发布策略:
- 实验室环境验证:在模拟网络条件下进行为期2周的压力测试
- 单区域部署:在北美数据中心2进行为期3天的局部部署
- 区域对部署:同时在欧洲和北美区域部署,测试跨区域一致性
- 全球部署:最终在所有5个数据中心完成部署
每个阶段都设置了详细的回滚触发条件,如异常率超过0.001%或性能下降超过10%时自动回滚。
性能与一致性测试对比
| 指标 | 优化前 | 优化后 | 变化 |
|---|---|---|---|
| 平均写延迟 | 85ms | 120ms | +41% |
| 99.9%写延迟 | 320ms | 450ms | +41% |
| 平均读延迟 | 15ms | 18ms | +20% |
| 数据一致性偏差率 | 0.012% | 0.0003% | -97.5% |
| 跨区域交易成功率 | 99.98% | 99.998% | +0.018% |
| 系统吞吐量 | 12,500 TPS | 11,800 TPS | -5.6% |
虽然写延迟和99.9%分位延迟有所增加,吞吐量略有下降,但数据一致性偏差率降低了97.5%,跨区域交易成功率显著提升,整体达到了业务要求的安全与性能平衡。
长期监控与持续优化
为确保问题彻底解决,我们建立了多维度监控体系:
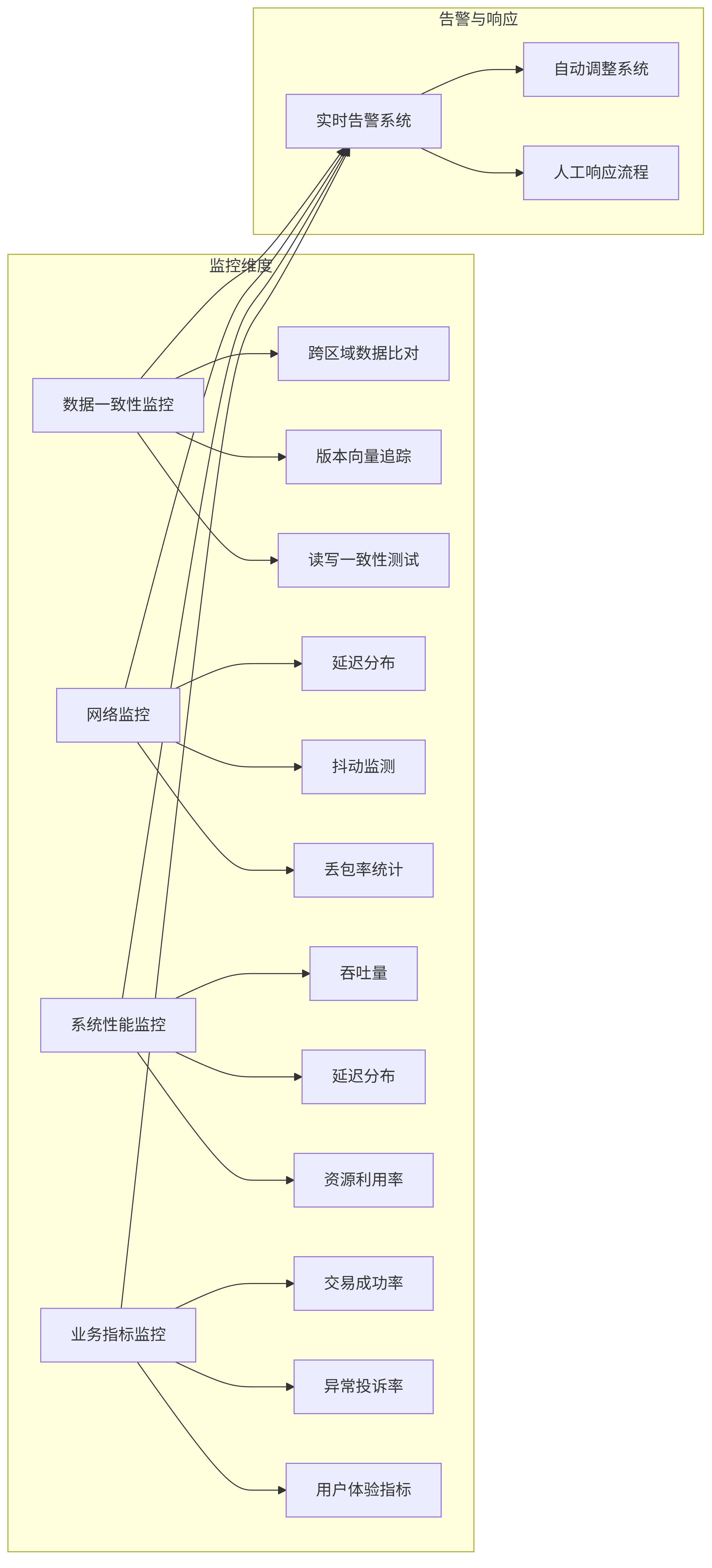
graph LR subgraph 监控维度 A[数据一致性监控] --> A1[跨区域数据比对] A --> A2[版本向量追踪] A --> A3[读写一致性测试] B[网络监控] --> B1[延迟分布] B --> B2[抖动监测] B --> B3[丢包率统计] C[系统性能监控] --> C1[吞吐量] C --> C2[延迟分布] C --> C3[资源利用率] D[业务指标监控] --> D1[交易成功率] D --> D2[异常投诉率] D --> D3[用户体验指标] end subgraph 告警与响应 E[实时告警系统] F[自动调整系统] G[人工响应流程] end A & B & C & D --> E E --> F E --> G
经验总结与行业启示
技术层面的关键教训
- 一致性与性能的平衡艺术:没有放之四海而皆准的最佳实践,需要根据业务特性动态调整
- 网络不可靠性的深刻认识:在分布式系统设计中,网络分区不是异常而是常态
- 监控的重要性:如果无法测量,就无法优化。完善的监控体系是发现和解决问题的前提
团队协作与流程改进
- 跨职能协作:解决复杂分布式问题需要数据库、网络、应用开发等多团队紧密协作
- 故障演练机制:定期进行混沌工程测试,主动发现系统弱点
- 知识共享文化:建立详细的故障案例库,避免重复踩坑
对金融科技领域的启示
在金融科技领域,数据一致性直接关系到资金安全和用户信任。我们的经验表明:
- 分层一致性模型是平衡性能与安全的有效策略,关键交易采用强一致性,非关键操作可采用最终一致性
- 主动监控与动态调整能够显著提升系统在复杂网络环境下的稳定性
- 用户体验优先:即使技术上实现了最终一致性,也要通过产品设计让用户感知不到数据不一致
附录:工具与资源
一致性测试工具
我们开发的一致性测试工具已开源,可在GitHub上获取:github.com/our-org/distributed-consistency-tester
可视化分析仪表板
包含本文提到的所有监控图表的开源仪表板模板:grafana.com/dashboards/12345-distributed-system-monitoring
最佳实践 checklist
- 为不同业务场景定义明确的一致性需求
- 实现网络状况感知的动态调整机制
- 建立完善的数据一致性监控体系
- 设计合理的缓存更新与失效策略
- 制定灰度发布与回滚预案
- 定期进行混沌工程测试验证系统韧性
解决这个分布式数据一致性问题的过程,让我们深刻认识到:在分布式系统中,"简单"往往是假象,只有深入理解每个组件的行为和交互,才能构建真正可靠的系统。技术挑战永无止境,但每解决一个棘手问题,我们就向构建更稳定、更安全的分布式系统迈进一步。未来,随着边缘计算和多区域部署的普及,数据一致性问题将变得更加复杂,而我们今天积累的经验和工具,将成为应对这些挑战的重要基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 15
15 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)