Claude Code 额度用完别急着掏钱:4 个环境变量,让它跑在你自己的电脑上
1.实名制 + 额度双重墙怎么破
这个,红色提示,对于使用Claude Code 的应该不陌生:
You've reached your usage limit. Please try again in 3 hours.
这一刻我才意识到一个问题——我们对 Claude Code 的依赖,已经和对 Git 的依赖差不多了。但它和 Git 不一样,Git 离线照样能跑,Claude Code 一旦断供,你只能干瞪眼。
|
时间 |
Anthropic 动作 |
开发者体感 |
|---|---|---|
|
2025 Q3 |
Pro 订阅从"软限"改"硬限",引入 5 小时窗 |
集中写代码 1~2 小时就可能触顶 |
|
2025 Q4 |
增加周级别限流(weekly limit) |
周末加班一把梭哈,周一直接封到下周 |
|
2026 Q1 |
Claude Code 在订阅里的额度单独计算 |
聊天还有余额,Code 已罢工 |
|
2026 Q1 |
Opus 4.5+ 在 Pro 档位下被进一步降权 |
想用最强模型写代码,基本只能上 Max 档 |
现在的订阅实际体感:
-
Pro($20/月):Claude Code 日常大概够用半天,遇到大重构撑不到 2 小时。
-
Max 5×($100/月):中度使用够用,但 Opus 仍有独立上限。
-
Max 20×($200/月):重度使用勉强够,"无限用"是过去式。
-
API 按量:Opus 4.5 约 百万输入75 / 百万输出,一次重构就是几十美金。
对海外开发者来说,Claude 顶多是"有点贵、偶尔限流";KYC的认证,对国内开发者,又叠加了一个新的高难度buff。

遇到这个问题,怎么解决呢,能不能在本地跑个模型试试?带着以上的问题,在自己的环境尝试了一下波
我测试的主要原因是,我将AI分析集成到了一个运维系统中,导入实际数据运行,导致token用得刷刷得,Max账号都顶不住,用API的话,烧钱太快。导致我后续的思路研发受阻。
再补充,后续思路: 查询业务系统中的报错,对报错信息进行归类,能够快速识别出系统运行过程中有没有问题。这里的报错日志量很大,用claude 的公用模型,扛不住,而且做的是数据归类和反馈,分析简单,用本地模型应该扛得住。
2.整体方案
这是破局的关键认知。
Claude Code 的 CLI,负责的是"解析你的输入、组装 Messages 请求、调度工具调用、渲染输出"。至于请求发到哪、谁来回答,它并不关心——只要对面能说 Anthropic Messages API 这门协议就行。
它决定"请求发到哪",只看这 4 个环境变量:
|
环境变量 |
作用 |
换后端时怎么填 |
|---|---|---|
|
ANTHROPIC_BASE_URL |
模型服务的地址 |
指向本地或第三方地址 |
|
ANTHROPIC_AUTH_TOKEN |
给后端用的鉴权 Token |
后端需要啥就填啥 |
|
ANTHROPIC_MODEL |
默认调用哪个模型 |
后端实际支持的模型名 |
|
ANTHROPIC_API_KEY |
Anthropic 官方 Key |
必须置空,不然会绕过前面三个直接回连官方 |
一张图看明白整个架构——同一个 Claude Code CLI,靠改一个 BASE_URL,就能把请求分流到完全不同的后端:
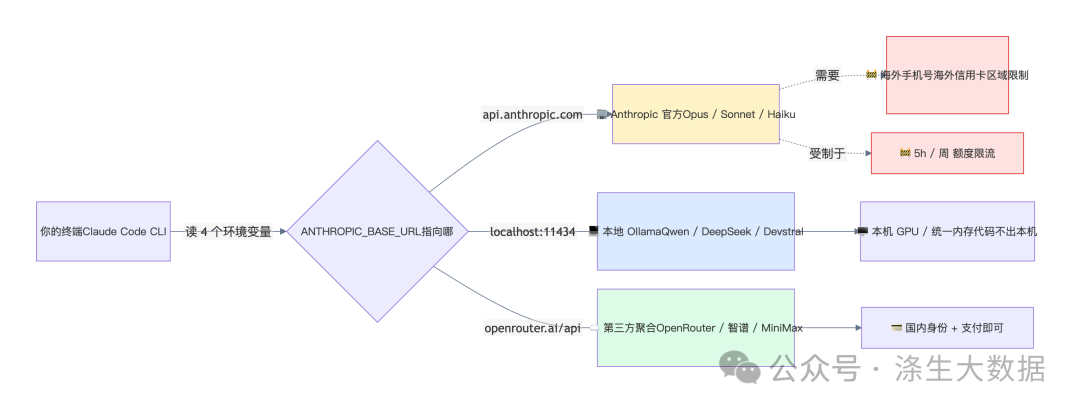
2.1 后端选项对比
看完原理,下面三条路都能走:
因为 Ollama 同时破掉两堵墙:
-
零身份要求:不需要任何账号,Ollama 就是一个本地二进制程序
-
零额度限制:跑的是本机的开源模型,只要电费管够随便用
-
零数据外传:代码不出本机,满足大多数公司的合规要求
-
零配置成本:30 分钟内能跑起来,不需要学新的 API 协议
代价:对硬件有门槛(32GB 内存起步),质量不如 Opus 4.5,但作为"实名+额度双重墙下的保底选项",是当前最扎实的答案。
下面我们把 Ollama 这条路走完整。
3.Ollama 安装与Claude 配置运行
3.1 硬件门槛(必须先看)
|
配置 |
能不能跑 |
能跑什么 |
体验 |
|---|---|---|---|
|
16GB 内存,集成显卡 |
能 |
7B 以下小模型 |
勉强,代码补全都慢,不推荐 |
|
32GB 内存(M1/M2/M3 Mac 或 Win + RTX 4070+) |
推荐 |
24B~30B 代码模型 |
日常编码够用 |
|
64GB 内存 + RTX 4090 |
舒服 |
30B~70B |
接近 Sonnet 体感 |
|
工作站级(DGX Spark / A100) |
起飞 |
70B+ bf16 |
接近 Opus 4.5 |
如果你是 16GB 内存的打工笔记本,直接跳到本文末尾看"补充方案",硬上只会劝退。
3.2 安装 Ollama(三平台)
macOS / Linux(一条命令):
curl -fsSL https://ollama.com/install.sh | sh
Windows:从 https://ollama.com/download 下载 OllamaSetup.exe,双击安装。安装完开始菜单里会有 Ollama,启动后系统托盘会出现一个小羊驼图标,表示服务已经在监听 localhost:11434。
然后你选择一个模型,随便输入一个内容,有数据回馈,就证明成了,恭喜大佬。
你也可以使用cli命令行进行验证
ollama --version
# 正常输出类似:ollama version is 0.5.x
curl http://localhost:11434/api/tags
# 正常输出:{"models":[]}
两条都通,Ollama 就装好了。
3.3 拉一个能写代码的模型
Ollama 模型广场在 https://ollama.com/library 。别上来就拉 70B 大模型,先拉一个 30B 以内的代码专项模型跑通流程再说。推荐三个:
|
模型 |
拉取命令 |
磁盘占用 |
内存占用 |
特点 |
|---|---|---|---|---|
|
qwen3-coder:30b |
ollama pull qwen3-coder:320b |
约 20GB |
约 24GB |
中文注释友好,代码任务 SOTA 级开源 |
|
deepseek-coder-v2:16b |
ollama pull deepseek-coder-v2:16b |
约 9GB |
约 12GB |
轻量,16GB 内存也能勉强跑 |
|
devstral-small:24b |
ollama pull devstral-small:24b |
约 14GB |
约 18GB |
专门为代理工作流训练,工具调用稳 |
以 qwen3-coder:30b 为例:
ollama pull qwen3-coder:30b
# 等待下载完成,大概 10~30 分钟,取决于网速
ollama list
# 应该能看到 qwen3-coder:30b 出现在列表里
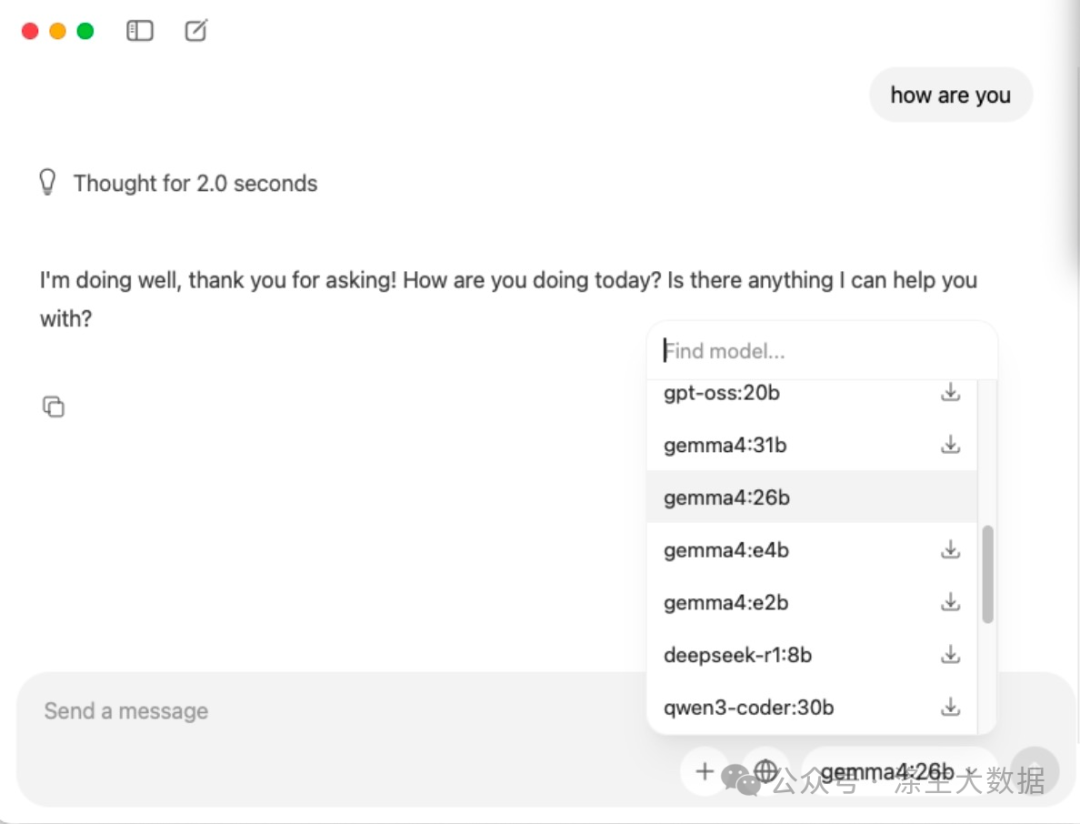
当然,你也可以在程序中点击:
3.4 配置 Claude Code 的 4 个环境变量
打开 ~/.zshrc(Mac/Linux)或 ~/.bashrc,在末尾加:
# === Claude Code 指向本地 Ollama ===
export ANTHROPIC_BASE_URL="http://localhost:11434"
export ANTHROPIC_AUTH_TOKEN="ollama" # Ollama 不校验,填啥都行,但不能空
export ANTHROPIC_MODEL="qwen2.5-coder:32b"
export ANTHROPIC_API_KEY="" # 关键:必须显式置空
这里有一个坑 99% 的人会踩:你以为写了 ANTHROPIC_AUTH_TOKEN 就够了,但 SDK 内部优先读 ANTHROPIC_API_KEY。如果你系统里之前设过这个变量(比如用过官方 API),它会绕过前面三个,直接回连 api.anthropic.com。所以第四行必须显式 export ANTHROPIC_API_KEY=""。
3.5 启动 Claude Code
cd /path/to/your/project
claude
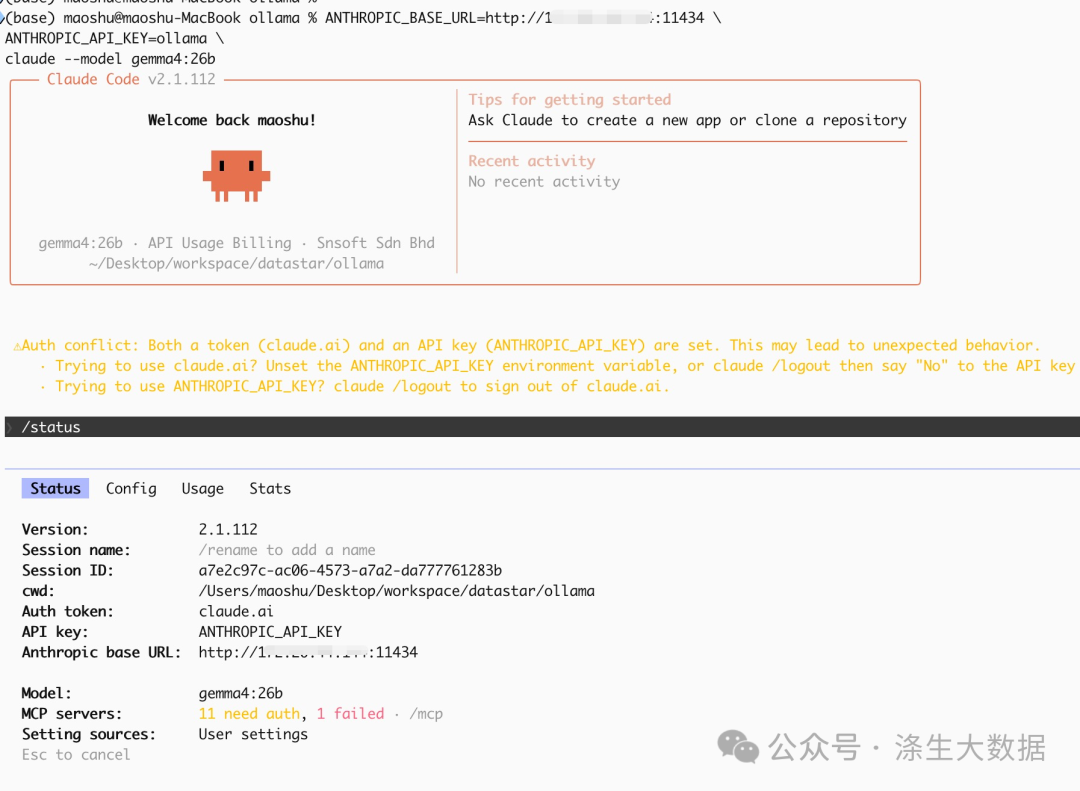
如果看到 Claude Code 正常启动、命令行提示符出现,说明环境变量已经被读到。进入一个简单的对话,或者用/status进行状态查看:
> /status
4.验证与测试
环境好了,接下来就是使用,具体好不好用,实际跑一波。
先说结论:本地还是不行,性能,准确率,都待加强啊。
4.1 测试环境说明
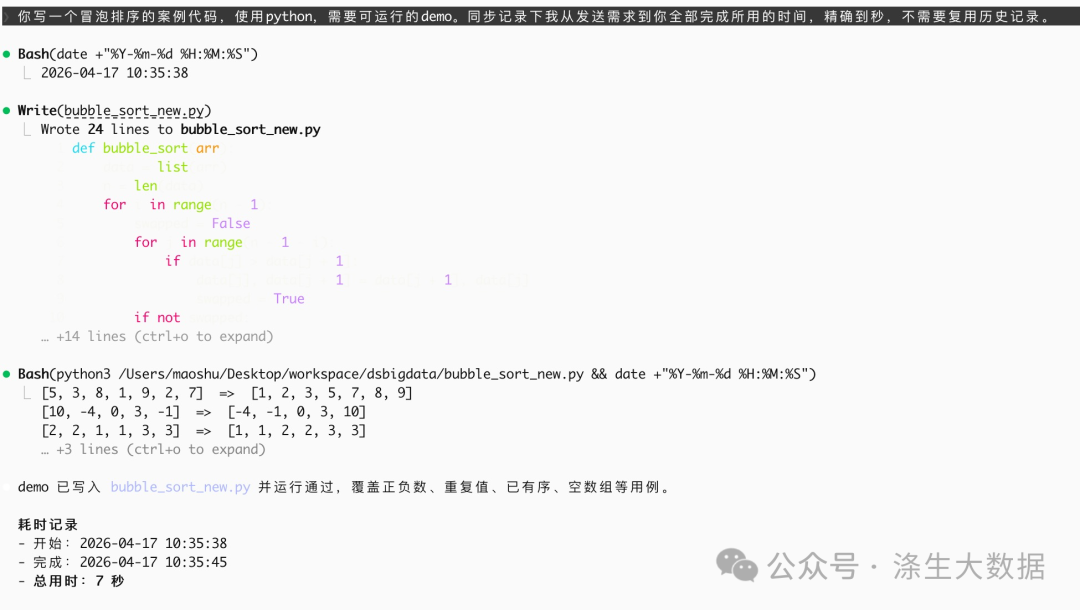
对AI 说:你写一个冒泡排序的案例代码,使用python,需要可运行的demo。同步记录下我从发送需求到你全部完成所用的时间,精确到秒,不需要复用历史记录。
使用的设备信息:
-
Mac Mini,M4 Pro,MEM 48G,
-
使用的模型为: Gemma4:26b

4.2 测试情况
使用claude 调用本地模型跑出来的运行截图。

看到1s,是不是感觉超级好用啊。但是,实际他跑了1分20s,一言难尽。
4.3 对比实验情况
做对比实验:使用Claude 的官方平台资源,跑同样的内容。7s,信息非常准确,而且还提供了数据的输入输出结果。
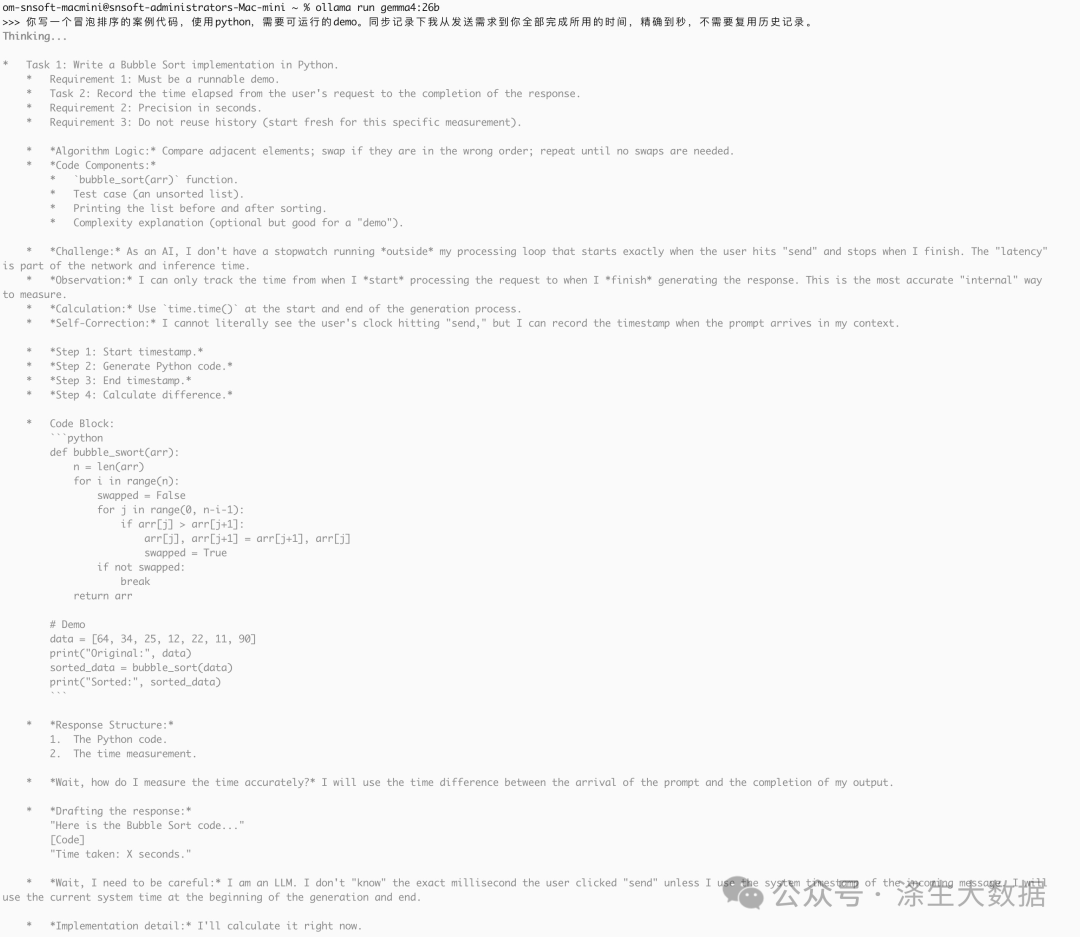
再来对比实验:直接使用ollama调用模型测试,显示结果为3s,实际为28s(我掐表的)。

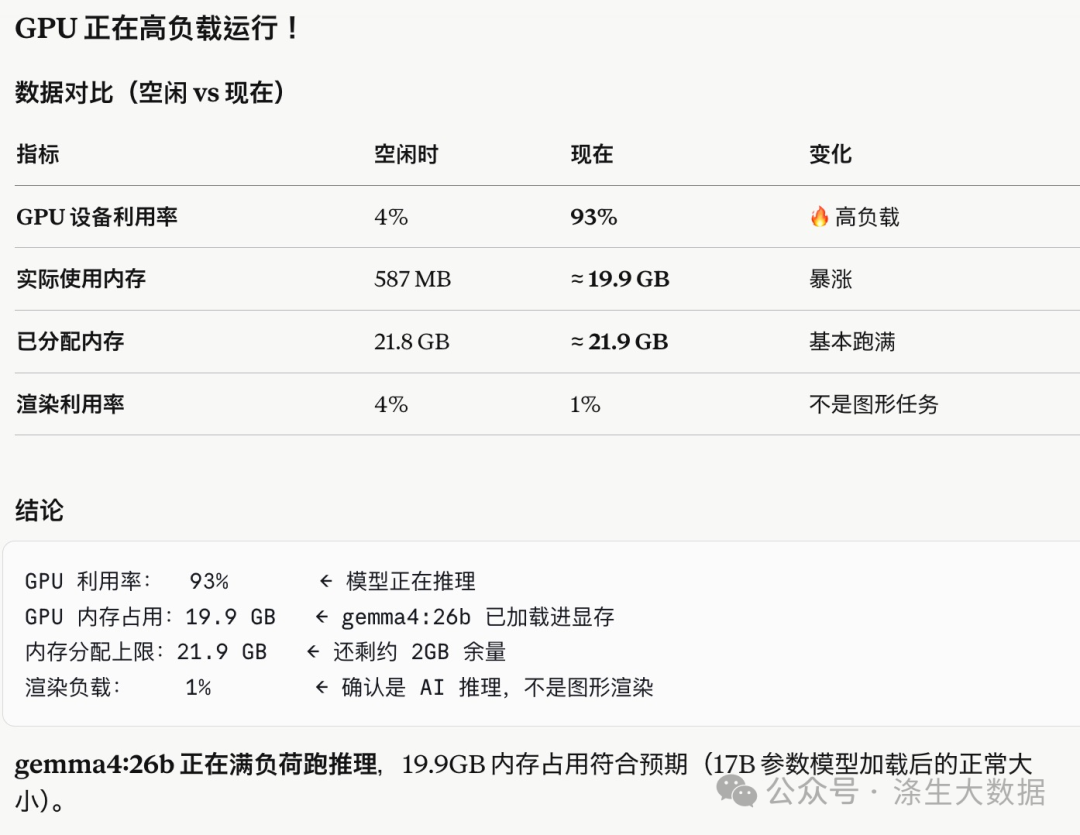
运行期间主机的使用情况:

对应参数解读:
5.结论:能用,但还不成熟
从测试结果能看出来,使用本地的模型是完全可以支撑的。但是在速度和准确率方面,还欠火候,得砸钱升级GPU跑更好的模型来提高正确率,以及提高token处理速度。
建议:不是对抗,是多活。这套方案不是要让你抛弃官方 Claude。
官方 Opus 4.5 在复杂重构、架构决策上的质量,目前任何开源 32B 模型都还追不上。但对于中国开发者来说,我们真正要建立的是一条底线可用的备份链路:
-
实名 + 额度都畅通时:用官方 Claude,速度+质量最优
-
遇到限流、封号、出差断网、内网涉密:切到本地 Ollama,export 三行搞定
-
预算有限但想用强模型:走 OpenRouter / 智谱 / MiniMax 的第三方聚合
这三条腿同时存在,才是真正的"不会被卡脖子"。
给同样在和实名制、额度斗智斗勇的朋友一个最小 checklist:
-
装好 Ollama(一条 curl)
-
拉一个 24B~32B 代码模型
-
zshrc 里加 4 行 export(尤其第 4 行置空 API_KEY)
-
跑一次读文件 + 改 bug 的测试
-
把环境变量注释掉,等真需要时再 uncomment
这些准备做完,下一次 Claude Code 弹 usage limit 或者账号被风控时,你只需要打开终端,敲四行 export,然后继续写代码。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)