StarRocks FE 内存异常排查实战:从监控到根因定位(附真实案例)

大多数数据库是为“人”设计的。在这种模式下,分析师提交查询、等待数秒、查看结果,然后再进行下一轮操作。这种线性、低频、对延迟相对宽容的交互逻辑,塑造了过去一代分析基础设施。但面对 AI Agents,这套逻辑失效了。
AI Agents 的运行方式截然不同。它们瞬时发起数十条并发查询,毫秒级迭代中间结果,要求数据保持秒级新鲜度,同时应对多用户与多流水线的并行压力。当这种高频、强并行的交互模式作用于传统架构时,数据库会迅速沦为系统瓶颈——这本质上并非硬件性能不足,而是原有架构无法适配这种新型交互模式。
StarRocks 从设计之初就专注于极致的并发处理与亚秒级响应。随着 AI Data Agent 跨越原型阶段、进入大规模生产环境,StarRocks 正在成为该场景下的首选引擎。其核心优势体现在以下几个维度:
从单一提问到海量查询
传统分析引擎基于低频、相对固定的访问模式而构建。但 AI Agent 的交互逻辑,几乎挑战了这一架构的所有设计假设。
以一个典型的业务场景为例:面对“为什么上季度欧洲区营收下滑?”的提问,人类分析师通常只需执行两三个核心查询即可得出结论。而 AI Agents 的处理逻辑则截然不同:它会拆分区域营收、细分产品线、关联营销活动并对异常指标进行深度下钻。
这种“一问多查”的模式,会将单个提问实时裂变为数十条动态生成的 SQL。 这种爆发式的负载往往会造成严重的资源争抢——当 Agent 在后台进行深度推理时,前端生产环境的仪表盘可能因资源耗尽而响应中断。
这一转变带来了五大结构性挑战,而绝大多数数据库在最初设计时并未考虑应对这些问题。
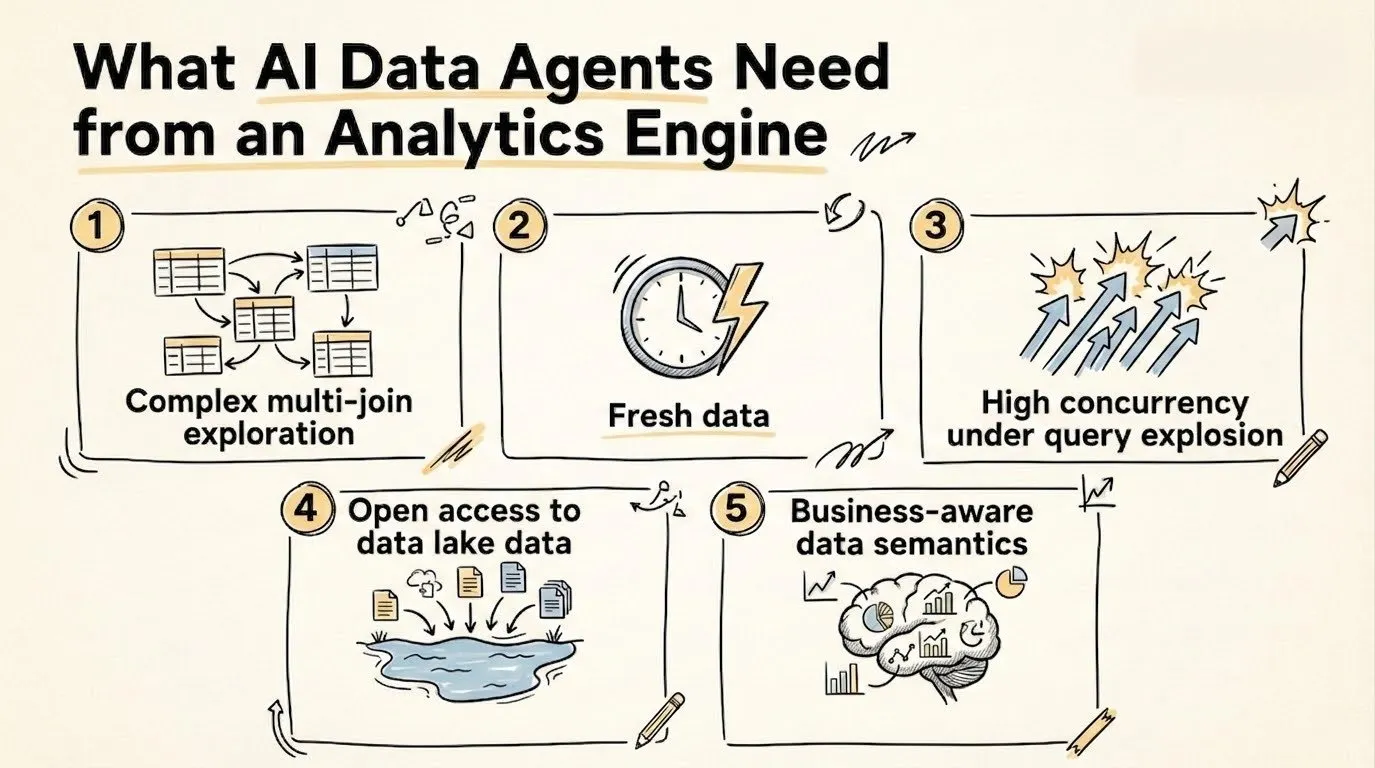
挑战 1:复杂的多表关联(Join)
Agent 生成的 SQL 往往涉及 5~10 张表的关联,包含嵌套聚合,并进行迭代式查询细化。若缺乏强大的优化器支撑,此类负载会迅速变得缓慢且不稳定。
挑战 2:实时运营数据
在业务监控、财务审计或客户运营等场景中,Agent 的推理决策要求数据达到秒级新鲜度。数小时前的旧数据只会产生无意义的结果。
挑战 3:查询爆发下的高并发
单个用户会话即可产生数十个并行查询。当扩展到数百个并发用户时,系统并发压力将呈指数级增长。
挑战 4:对数据湖格式的开放访问
企业数据广泛分布在 Iceberg、Hive、Hudi、Delta Lake 及各类事务系统中。Agent 需要一套统一的执行层来覆盖所有数据源。
挑战 5:具备业务感知的数据语义
仅生成语法正确的 SQL 远远不够。当 Agent 查询 “营收(revenue)” 时,系统必须明确其具体含义:是毛利、净利、已确认收入还是已入账收入,语义层面的偏差会直接导致结论错误。

解决方案 1:针对 AI 生成 SQL 的自愈合查询优化(Self-Healing Query Optimization)
AI 生成的 SQL 具有较强的不可预测性:Join 顺序多变、聚合嵌套与 CTE(公用表表达式)随机出现。传统的 CBO 通常针对人类编写的固定查询进行调优,面对 LLM 实时生成、且缺乏表统计信息与数据分布感知的查询时,难以生成稳定高效的执行计划。
针对这一痛点,StarRocks 内置的 CBO 优化器经过生产环境长期深度验证磨,能够有效应对统计信息缺失、采样偏差、数据倾斜以及执行计划不稳定等典型问题。尤其在 AI Agent 频繁生成的多表关联场景下,StarRocks 的 Global Runtime Filters 可在大规模事实表扫描阶段实现数量级的数据裁剪,带来 10 倍甚至 100 倍的性能提升。
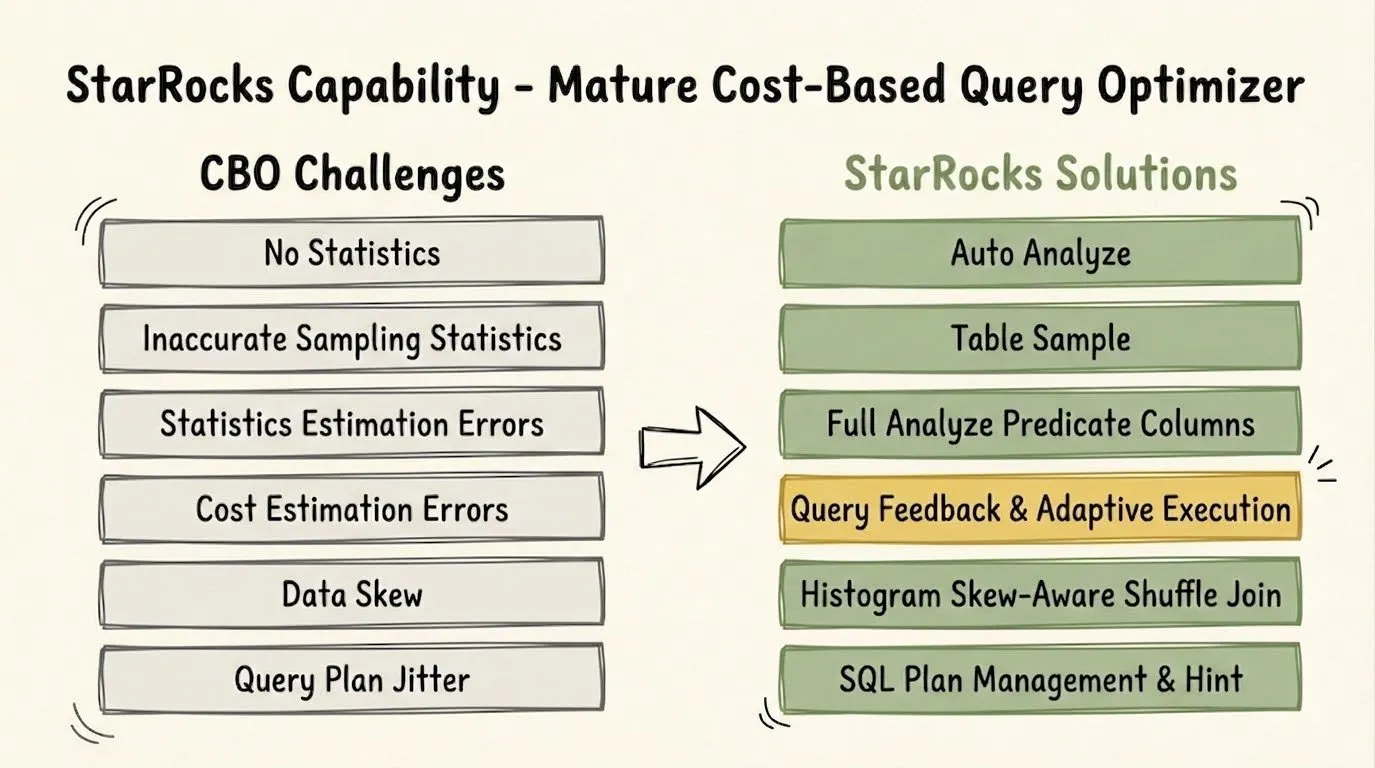
而更深层的能力,在于 Query Feedback 机制。AI Agent 生成的 SQL 如同 “黑盒”,关联顺序不可预测,在统计信息不完整的场景下,传统优化器难以有效处理。StarRocks 内置的 SQL Tuning Advisor 会实时监控执行过程,识别低效执行计划,并在后续查询中自动修正。这意味着,即便 Agent 生成的 SQL 初始性能不佳,也能无需人工干预,通过系统形成的自愈闭环持续优化。随着 Agent 查询模式不断演变,系统会自动稳定查询性能。
这在生产环境中尤为关键:无法在 Agent 运行过程中热修复 SQL,因此数据库必须具备自主自愈能力

解决方案 2:秒级数据时效与查询性能的兼得
在监控欺诈、实时库存跟踪或用户行为响应等场景中,AI Agent 对数据时效性有着极高的要求。延迟数小时的批处理数据往往会导致决策失误。陈旧数据不仅会导致错误结论,在 Agent 自动化工作流中,还会产生看似合理实则错误的结果,并向下游持续传导。
StarRocks 通过原生连接器直接从 Kafka、Flink 摄入流式数据,消除 ETL 延迟,使新数据近乎实时可查。
StarRocks 支持 Primary Key,并基于 Delete-and-Insert 架构实现高效实时更新与删除。数据更新时,旧记录会被标记到基于 Bitmap 结构的 Delete Vector 中;查询扫描阶段即可直接跳过已标记数据,避免昂贵的实时合并开销,过期数据则由后台异步 Compaction 清理。
这种架构确保了在不损失查询性能的前提下,实现秒级的数据新鲜度。
此外,即将推出的增量物化视图(Incremental Materialized Views)将进一步强化该能力:针对重复执行或结构相似的查询模式,系统可实时维护预计算结果。对频繁执行同类查询的 Agent 而言,可实现显著的性能倍增。

解决方案 3:极致并发:为爆发式查询而生
AI Agent 带来的并发压力不仅在量级上远超传统场景,其负载结构也发生了根本性变化。单个用户会话即可触发数十个并行 SQL 查询;当这种模式扩展至数百个并发用户及多条 Agent 流水线时,系统必须在支撑每秒数千次查询的同时,避免因资源争抢导致的性能下降。
针对这一挑战,StarRocks 通过分层执行与资源隔离机制来应对:

向量化执行引擎(Vectorized Engine): 充分利用单节点的全部 CPU 性能,在分布式开销成为性能瓶颈之前,最大限度提升单节点吞吐量。
MPP 分布式执行(MPP distributed execution): 支持跨节点水平扩展,使集群无需变更架构,即可轻松消化持续增长的并发压力。
资源组与 Multi-warehouse : 资源组在节点层面实现负载隔离,Multi-warehouse 则将这种隔离能力延伸至整个集群。即便 AI Agent 的随机探索查询与生产环境的 BI 报表任务同时访问 S3 上的同一份数据,二者也不会产生资源争抢,互不干扰。
Tablet 级查询缓存(Tablet-level query cache): 不同于传统的结果集缓存,StarRocks 在物理存储单元(Tablet)层面缓存中间聚合结果。当后续查询的扫描范围与已有缓存存在重叠时,系统可直接复用缓存的中间结果,仅对新增范围进行重算。在 AI Agent 频繁触发的高并发场景中,该机制可将系统吞吐能力提升至数万 QPS 量级。
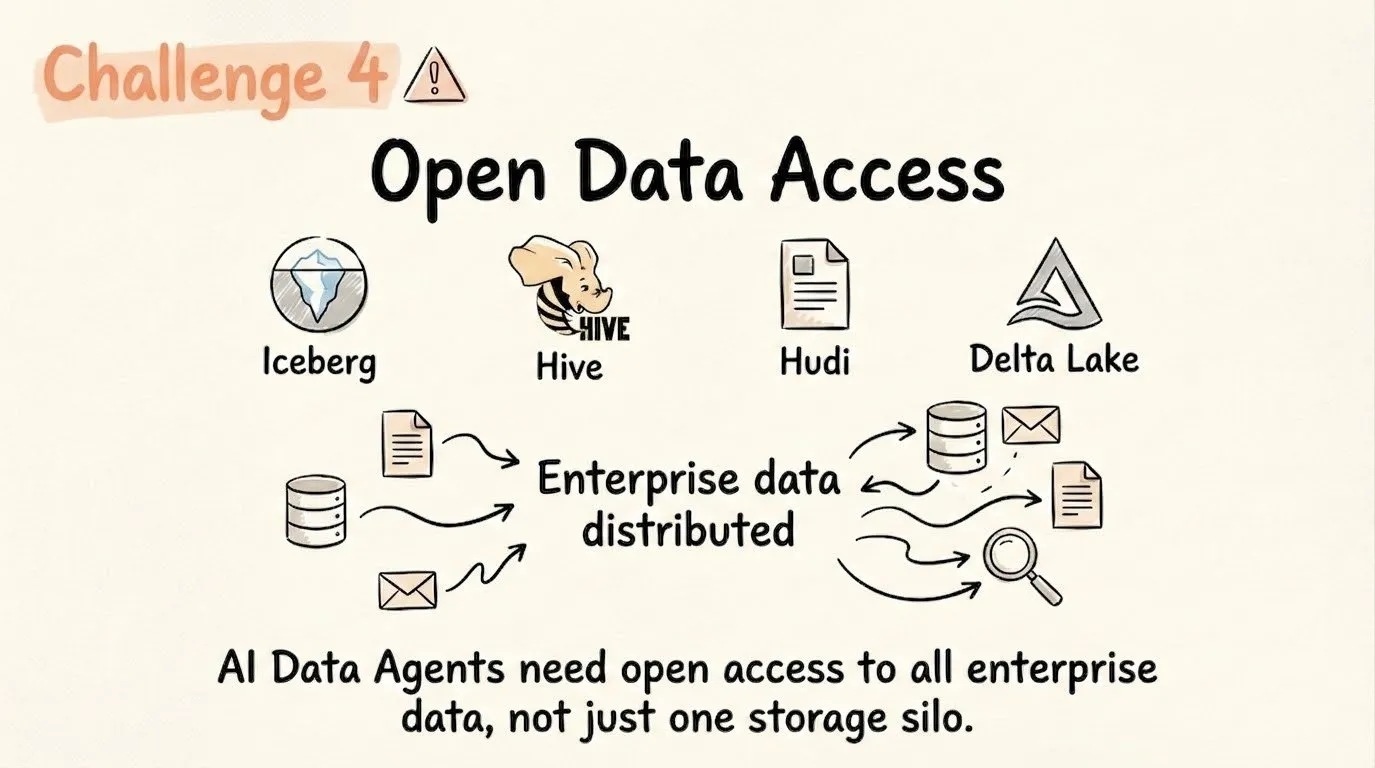
解决方案 4: Lakehouse 架构下的开放数据访问
企业数据通常呈现碎片化分布,非集中存储于单一位置。AI Agent 需要查询 Iceberg、Hive、Hudi 及 Delta Lake 以及 StarRocks 本地存储的数据,而无需预先通过繁琐的 ETL 进行数据归集。
StarRocks 支持对开放表格式的直接查询,并能以“零拷贝”方式访问 S3 数据。典型的生产实践是:将近一周的运营数据存入 StarRocks 原生表,以支撑实时更新和亚秒级响应;历史数据则保留在 Iceberg 中。Agent 仅需单一接口即可实现无缝跨源访问,无需构建额外的抽象层。
在开放表格式上的性能表现,是 StarRocks 的核心优势。在相同集群配置下, 基于 1TB TPC-DS 基准测试(使用 Iceberg 表),StarRocks 的执行性能优于 Trino。此外,StarRocks 还支持在 Iceberg 表之上构建物化视图,针对 Agent 大规模生成的重复查询模式,可进一步放大这一性能优势,显著提升查询效率。

StarRocks 的演进方向
上述能力构成了 StarRocks 的技术底座,但 StarRocks 的目标远不止于此,下一阶段目标,是推动分析引擎向 Intelligent Layer 演进——让引擎能够从每一次与 AI Agent 的交互中持续学习。
自进化 Agent 闭环
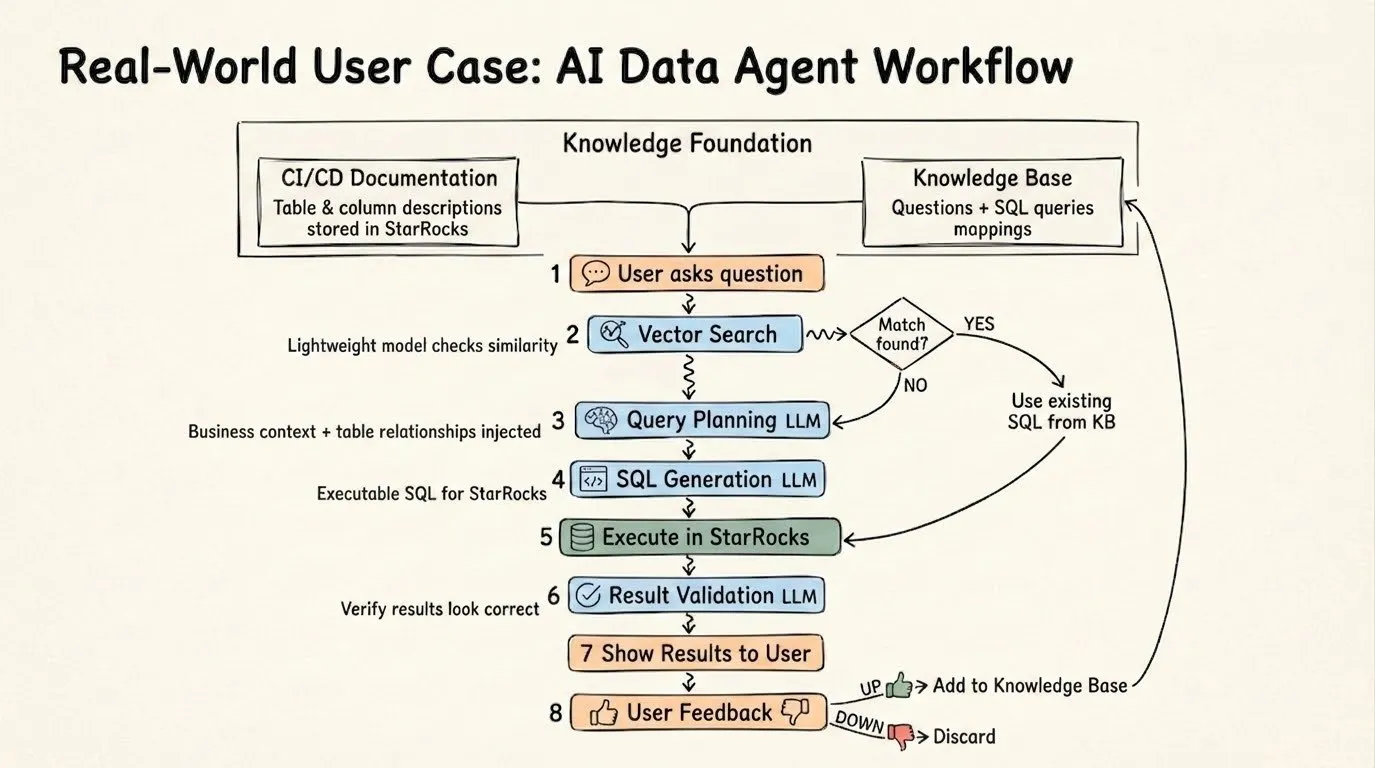
AI Data Agent 在 StarRocks 上的生产实践正趋于一种固定模式,其价值会随时间推移持续叠加:当新的查询需求出现时,系统会优先在知识库中检索已验证的相似查询。若找到匹配项,Agent 会直接复用经过验证的高质量 SQL,无需从零开始生成;
若未检索到匹配的历史查询,系统则结合表关联关系与业务上下文进行逻辑规划,生成新的 SQL 并提交执行。待查询结果通过验证后,该“问题-SQL”映射对会被存入知识库,形成新的可复用资源。
这种模式构建了一个持续自进化的闭环:检索(Retrieve)、规划(Plan)、执行(Execute)、验证(Validate)、学习(Learn)。在无需人工干预的情况下,Agent 的查询准确性与响应速度会随着交互数据的积累不断提升。
AI 原生分析的架构根基
选择适配 AI 原生分析的引擎,本质上是架构层面的决策,而非单纯的性能调优。本文所述的五大挑战并非边缘场景,而是任何需要在生产环境中稳定运行的 Agent 所需满足的基本要求:处理复杂的探索性查询、基于实时数据进行推理、在并发高峰下保持性能稳定、访问企业全量数据资产,以及返回根植于业务语义的准确结果。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)