【python因果库实战28】LaLonde 数据集1

LaLonde 数据集
经济学家长期以来一直假设培训计划可以改善参与者的劳动力市场前景。为了测试(或证明)这一点,国家支持性工作 (NSW) 示范项目使用私人和联邦资金的结合方式启动。该项目在1975年至1979年间在美国15个地点实施。该计划为面临经济和社会问题的人群(如接受抚养儿童家庭援助的女性、前吸毒者、前罪犯以及前少年犯等)提供了为期6至18个月的培训。
参与者被随机分配到实验组(支持性工作计划)和对照组。但是,由于研究时间较长,早期加入项目的参与者与后期加入的参与者具有不同的特征。
因此,为了估计就业计划对将来就业的真实因果效应,需要调整这种协变量转移。
此外,我们还添加了一些从收入动态人口调查和当前人口调查获得的观察数据。这些人群没有接受任何培训,被视为对照组。
多年来,这个数据集已成为因果分析的常见基准。最初的分析是由 Robert LaLonde 完成的,并发表在他1986年的论文《使用实验数据评估培训计划的计量经济学评估》中。
这里的分析基于 Dehejia 和 Wahba 在他们1999年的论文《非实验研究中的因果效应:重新评估培训计划的评估》中进行的倾向性评分分析。
数据
首先,让我们从 Rajeev Dehejia 的网页下载数据集。
import pandas as pd
columns = ["training", # Treatment assignment indicator
"age", # Age of participant
"education", # Years of education
"black", # Indicate whether individual is black
"hispanic", # Indicate whether individual is hispanic
"married", # Indicate whether individual is married
"no_degree", # Indicate if individual has no high-school diploma
"re74", # Real earnings in 1974, prior to study participation
"re75", # Real earnings in 1975, prior to study participation
"re78"] # Real earnings in 1978, after study end
#treated = pd.read_csv("http://www.nber.org/~rdehejia/data/nswre74_treated.txt",
# delim_whitespace=True, header=None, names=columns)
#control = pd.read_csv("http://www.nber.org/~rdehejia/data/nswre74_control.txt",
# delim_whitespace=True, header=None, names=columns)
file_names = ["http://www.nber.org/~rdehejia/data/nswre74_treated.txt",
"http://www.nber.org/~rdehejia/data/nswre74_control.txt",
"http://www.nber.org/~rdehejia/data/psid_controls.txt",
"http://www.nber.org/~rdehejia/data/psid2_controls.txt",
"http://www.nber.org/~rdehejia/data/psid3_controls.txt",
"http://www.nber.org/~rdehejia/data/cps_controls.txt",
"http://www.nber.org/~rdehejia/data/cps2_controls.txt",
"http://www.nber.org/~rdehejia/data/cps3_controls.txt"]
files = [pd.read_csv(file_name, delim_whitespace=True, header=None, names=columns) for file_name in file_names]
lalonde = pd.concat(files, ignore_index=True)
lalonde = lalonde.sample(frac=1.0, random_state=42) # Shuffle
print(lalonde.shape)
lalonde.head()
(22106, 10)
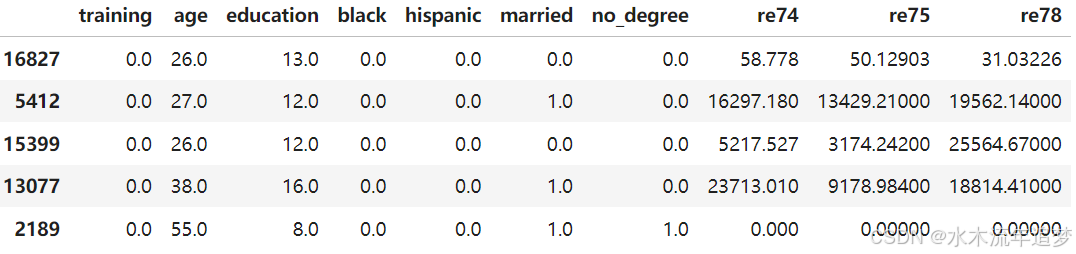
print(f'The dataset contains {lalonde.shape[0]} people, out of which {lalonde["training"].sum():.0f} received training')
The dataset contains 22106 people, out of which 185 received training
设计矩阵
收入指示变量
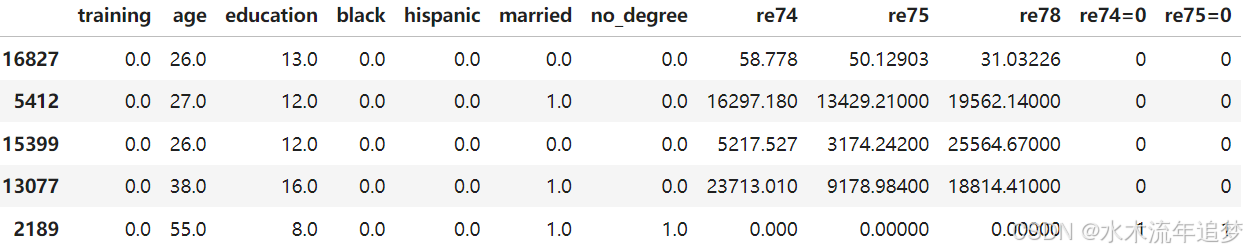
遵循 Gelman 等人在他们的 arm R 库中所进行的分析,我们将创建两个指示变量来表示1974年和1975年没有收入的情况。
lalonde = lalonde.join((lalonde[["re74", "re75"]] == 0).astype(int), rsuffix=("=0"))
lalonde.head()
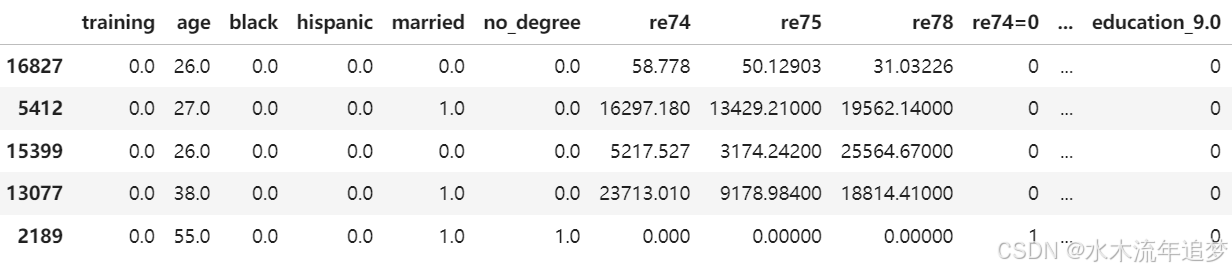
教育的因子化
由于受教育年限不应按数值来考虑,我们将对其进行因子化处理,转换为指示变量。
lalonde = pd.get_dummies(lalonde, columns=["education"], drop_first=True)
print(lalonde.shape)
lalonde.head()
(22106, 29)
变量选择
最后,我们提取协变量、处理变量和结果变量。
a = lalonde.pop("training")
y = lalonde.pop("re78")
X = lalonde
X.shape, a.shape, y.shape
((22106, 27), (22106,), (22106,))
模型
定义设计矩阵 X 后,我们可以继续定义因果模型。
遵循 Dehejia 和 Wahba 的倾向评分分析精神,我们将使用反向处理概率加权 (IPTW 或 IPW) 因果模型。
简而言之,该模型将建模参与者被分配到就业培训计划的概率,并利用它来模拟两个相同规模的人群:一个被分配到该计划的人群和另一个没有被分配的人群。在这个合成的人群中,我们可以使用1978年的实际收入来估计如果每个人都参加培训计划或者完全不参加会发生什么。
在定义因果模型本身之前,我们需要使用机器学习模型来估计倾向评分 —— 每个参与者被分配到就业培训的概率。
鉴于我们上面准备的设计矩阵,以及我们的处理变量是二元性质的,我们将选择逻辑回归来进行这项任务。
from sklearn.linear_model import LogisticRegression
learner = LogisticRegression(penalty='none', # No regularization, new in scikit-learn 0.21.*
solver='lbfgs', class_weight="balanced", # The classes are very imbalanced
max_iter=500) # Increaed to achieve convergence with 'lbfgs' solver
一旦我们定义了学习器,就可以简单地将其嵌入到因果模型中。
from causallib.estimation import IPW
ipw = IPW(learner)
估计因果效应
定义了因果模型之后(就是这么简单),我们可以继续估计就业培训对年收入的影响。
首先,我们将拟合我们的因果模型。
其次,我们将预测潜在的结果:如果每个人都参加就业培训或都不参加培训计划,1978年的收入会是多少。第三,我们将利用这两种潜在的结果来估计影响:即两种潜在结果之间的差值。
ipw.fit(X, a)
outcomes = ipw.estimate_population_outcome(X, a, y)
effect = ipw.estimate_effect(outcomes[1], outcomes[0])
print(outcomes)
0.0 9172.043485
1.0 6490.507791
dtype: float64
查看潜在结果,我们可以看到如果每个人都参加培训计划(处理变量=1)的话,研究结束时(1978年)的平均收入预测为6490美元;而如果所有人都不参加培训计划(处理变量=0)的话,同样的平均收入预测为9172美元。
确实,我们可能会得出结论,就业培训平均导致收入损失2682美元!
这看起来像是彻底的失败。但在现实中,这并没有道理,因为最多培训不会有所帮助,但它不应该有害。显然,这里有些地方不对劲,所以让我们仔细看看模型的表现。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)