Claude Code是什么,为什么它能力强大而国产替代不及预期
最近几个月,国内程序员圈子里有个现象越来越明显:越来越多的人开始想方设法"绕路"使用Claude Code。有人熬夜研究镜像站,有人托海外朋友代注册,还有人专门买了国外的SIM卡和虚拟信用卡,就为了能用上这个工具。
与此同时,Anthropic的门槛却越筑越高。2026年4月,Claude正式启用了强实名认证——不是简单的手机号验证,而是要求上传带照片的身份证明原件,还要实时自拍人脸识别。这几乎把中国大陆用户彻底挡在了门外。更关键的是,Anthropic早就明确禁止中国地区使用Claude服务,CEO达里奥·阿莫迪的对华强硬立场在业内众所周知 。
但越是封锁,需求反而越旺盛。这背后有个值得深思的问题:Claude Code到底强在哪?为什么国内这么多AI编程工具,就是替代不了它?作为一个Claude Code的深度用户, 今天就在这里说一说自己的见解。
一、Claude Code不是"代码补全工具",而是"编程Agent"
很多人第一次听说Claude Code,会本能地把它和GitHub Copilot、通义灵码这类工具归为一类——不就是AI帮你写代码吗?
这个理解差得太远了。
Claude Code的定位是Agentic Coding Tool(代理式编码工具)。它并不躲在IDE的角落里等你敲几个字符后弹出提示,而是直接接管终端,能够自主读取整个项目的代码库、分析依赖关系、执行Shell命令、运行测试、提交Git,甚至跨数十个文件进行架构重构。用Anthropic自己的话说,工程师只需要"定义目标并审查结果",而不是"指导每一步操作" 。
这种设计哲学深深根植于Unix的工具化思维。Claude Code原生支持管道操作,可以无缝嵌入CI/CD流程,也能通过MCP协议连接数据库、浏览器和外部API。它更像是一个经验丰富的高级工程师,而不是一个只会补全语法的实习生 。
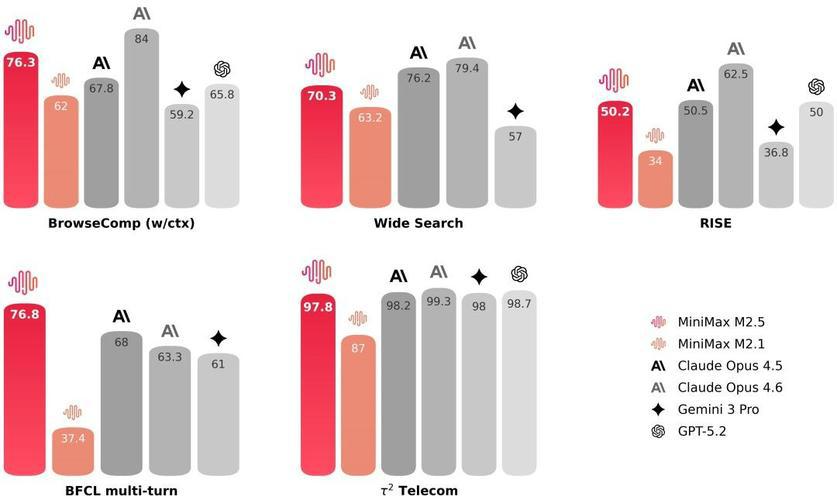
数据最能说明问题。在衡量AI解决真实工程问题能力的SWE-bench Verified基准测试中,Claude Opus 4.7的得分达到了87.6%,这意味着超过87%的真实GitHub issue可以被AI自主修复 。而在难度更高的SWE-bench Pro上,64.3%的成绩同样大幅领先竞品 。作为对比,目前国产最强代码模型GLM-5在同一测试中的成绩约为77.8% ,差距接近10个百分点。在复杂工程任务上,这10个百分点就是"能用"和"好用"的分水岭。
二、百万Token上下文:读懂整个项目,而不是一行代码
国产AI编程助手普遍有个痛点:它们大多只能理解当前文件或者有限的代码片段。你让它帮忙改一个接口,它看不到调用链;你让它优化一个模块,它不知道上下游的依赖关系。
Claude Code解决这个问题的方式简单粗暴——把上下文窗口拉到了100万Token 。这是什么概念?大约相当于7.5万行代码,或者2500页PDF文档。一个中型后端服务的完整仓库,它可以一次性读进去。
更关键的是,Claude不仅"装得多",还能"找得准"。在MRCR v2(大海捞针测试)中,它取得了78.3%的高分,证明模型能够在海量信息中精准定位关键细节 。这种长程理解能力让它可以处理真正的工程级任务:比如给你一份三个月前的技术文档,让它基于文档重构现有系统;或者在一个十万行代码的项目里,找出那个导致内存泄漏的隐藏依赖。
国产工具这边,Trae企业版提供128K上下文,CodeGeeX也是128K,其他大多未公开具体数字 。即便不考虑实际利用效率,光是窗口大小的物理差距就超过7倍。很多国产工具在处理跨文件重构时,只能依靠RAG(检索增强生成)技术做局部拼接,但代码的语义关联往往是隐性的,靠关键词检索很容易漏掉关键链路。
三、Agent能力:从"写代码"到"做工程"
如果说代码生成是"术",那么工程化能力就是"道"。Claude Code真正让开发者离不开的,是它在复杂工作流中的稳定性。
Anthropic在2025年底做过一个统计:Claude Opus 4.5不仅比前代模型更准确,还用更少的Token达到更好的效果 。传统成本计算只看每百万Token多少钱,但工程场景里真正重要的是"完成一个任务要花多少Token"。如果一个模型用10万Token才能修好的bug,另一个模型5万Token就能搞定,那么更贵的模型反而更便宜。这种效率优势在大型项目中会被无限放大。
Claude Code还有一个被低估的能力:代码自省(Self-correction)。它会在执行过程中主动检查自己的输出,发现错误后自动回溯修正。实测数据显示,它的代码重做率(Rework Rate)比同类工具低30% 。在真实开发中,"一次做对"和"反复返工"的体验差异,远比跑分差距更影响开发者的心态。
此外,Claude Code的Skills生态和CLAUDE.md持久化内存系统,让它能够记住项目的编码规范、架构偏好甚至团队习惯 。你第一次告诉它"我们团队不用Lombok",一个月后它依然记得。这种跨会话的记忆能力,国产工具目前几乎都不具备。
四、国产阵营:百花齐放,但各有天花板
当然,国产AI编程工具这几年的进步也不容忽视。通义灵码、文心快码(Comate)、Trae、CodeGeeX、腾讯云CodeBuddy等产品已经形成了相当完整的生态 。
通义灵码依托阿里云,在Java和Go后端开发场景里表现稳定,代码补全速度快,中文理解能力强。文心快码主打企业级安全合规,支持私有化部署,Figma转代码的功能在前端圈子里口碑不错 。Trae作为字节跳动推出的独立IDE,试图走"全流程闭环"路线,从PRD到部署一站式解决。CodeGeeX则完全免费开源,支持100多种编程语言,对学生和预算有限的开发者非常友好 。
这些工具在日常编码、单元测试生成、简单重构等场景里,确实已经能满足大部分需求。而且它们有Claude Code无法比拟的优势:国内直连零延迟、免费或极低价格、与微信/阿里云/腾讯云生态深度集成、数据不出境的合规保障 。
但问题在于,国产工具大多停留在"IDE插件"的产品形态,核心功能还是代码补全和聊天问答。当面对真正的复杂任务时,差距就会暴露出来。
2026年5月的一份AI编程工具横评显示,国产工具在Agent能力、多文件协同编辑、复杂推理三个维度上,与国际顶尖水平仍有明显距离 。有开发者反馈,国产模型在"跑分"上越来越好看,但实际使用体验与Claude Code相比,底层细节打磨和"硬智能"仍有提升空间 。比如一个典型的场景:让AI把用户认证从Session改为JWT,Claude Code能分析出需要修改哪些文件、调整哪些配置、甚至自动运行测试验证;而国产工具往往只能给出一个大致方案,具体实施还得开发者自己动手。
五、为什么国产替代不及预期?四个深层原因
1. 底层模型的"推理密度"差距
代码能力归根结底是大模型推理能力的体现。Claude在复杂逻辑推理、多步骤数学证明、长代码调试上的稳定性,目前仍是行业标杆 。它不会像某些模型那样在推理过程中"跳步",也不会为了迎合用户而编造看似合理实则错误的方案。这种"诚实度"在工程场景里极其重要——开发者宁愿听到"我不确定",也不想得到一个自信满满的错误答案。
国产模型如GLM-5、Qwen3、DeepSeek-V3.2在基准测试中的成绩确实在快速追赶,但在需要持续注意力的高难度任务上,Claude Opus 4.6已经能做到在复杂多步骤任务中保持超过30小时的持续注意力 。这种长程稳定性不是靠堆参数就能解决的,它涉及训练方法、数据配比、对齐技术等一系列底层优化。
2. 产品架构的路径依赖
国产AI编程工具大多由云厂商或大模型公司推出,天然带有"生态绑定"的基因。通义灵码要推阿里云,CodeBuddy要推腾讯云,文心快码要推百度智能云。这种策略在商业化上无可厚非,但也导致产品设计的重心往往放在"如何更好地服务现有云用户",而不是"如何重新定义编程工作流"。
Claude Code则没有这种包袱。它从诞生之初就是一个独立的、面向工程化的Agent,不需要考虑怎么把用户导流到某个云平台。这种纯粹性让它在架构设计上可以更大胆——比如原生CLI形态、Unix管道支持、Hooks系统——而这些恰恰是资深开发者最看重的特性 。
3. 数据飞轮的缺失
Anthropic在2025年底收购Bun(高性能JavaScript运行时),2026年初又收购AI代理技术公司Vercept,目的很明确:从底层优化Claude Code的执行速度和可靠性,让它不仅能写代码,还能更高效地运行和测试代码 。这种垂直整合能力,建立在Anthropic对开发者需求的深度理解之上。
更关键的是,Claude Code已经形成了强大的数据飞轮。全球约4%的GitHub公开提交代码由其生成,每周活跃用户数量持续翻倍 ,这些真实用户反馈不断反哺模型优化。国产工具虽然用户量也不小,但在高端开发者群体中的渗透率仍然有限,导致很难收集到足够多的高质量复杂任务数据来训练模型。
4. 工程化体验的"最后一公里"
很多国产工具在Demo里表现惊艳,但真放到复杂项目里就会掉链子。比如多文件编辑时的原子性保障、Git冲突时的智能处理、大型代码库索引的构建速度、终端命令执行的沙箱安全——这些看似不起眼的细节,决定了工具能否真正融入工程师的日常workflow。
Claude Code在这方面下了苦功。它的并行Agent能力允许同时启动多个子Agent协作,内存系统能持久化项目上下文,甚至支持Ctrl+B后台运行 。这些工程化细节没有出现在任何基准测试里,却是开发者每天打交道时最真实的体验。
结语:差距在缩小,但替代仍需时间
必须承认,国产AI编程工具已经走过了"从无到有"的阶段,正在进入"从有到优"的攻坚期。对于大多数日常开发场景,通义灵码、Trae、CodeGeeX等免费工具完全够用,性价比极高。而且在中文理解、国内生态集成、数据合规等方面,国产工具有着天然优势。
但如果把视野放到复杂工程任务、大型代码库重构、高专业度的技术决策上,Claude Code目前仍然是那个"不得不服"的存在。它的强大不是某一个指标的领先,而是模型能力、产品架构、工程化体验、生态整合的系统优势。
国产替代不及预期,不是因为我们不努力,而是因为这条赛道上,对手也在全力奔跑。Claude Opus 4.7的SWE-bench成绩比4.6提升了6.8个百分点 ,这个增速本身就说明,顶尖水平的竞争远未到天花板。
对于国内开发者来说,现实是残酷的:Claude Code的门槛越来越高,想用就得付出额外成本。但这也给国产工具提了个醒——真正的替代不是功能的对标,而是体验的超越。当国产工具能让一个资深架构师在重构十万行代码时感到"放心",而不是"凑合",那才是真正的替代时刻。
那一天可能不会太远,但显然,还没到。
(注:本文部分数据引自公开技术报告与行业评测,仅供技术交流参考)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)