项目实训(四)|RAG优化:从搭建到迭代优化
一、上周回顾:基础架构已完成
在正式进入本周工作之前,先简要回顾上周的成果——这也是本周迭代的起点。
上周完成了完整 RAG(Retrieval-Augmented Generation)架构的从零搭建,整个流程覆盖:
- 数据加载与切块:支持按固定大小进行文本分块,设置 overlap 保留上下文衔接
- 向量化与检索:对文档 chunk 进行 embedding,基于相似度完成语义检索
- LLM 召回生成:将检索结果注入 prompt,由大模型生成最终回答
- 个性化问答支持:通过构建初级、中级、高级三档提示词模板,实现基于用户水平的个性化知识问答
- 知识库管理脚本:支持 PDF、Markdown、Word 三种主流格式的自动导入
- 学习规划模块:完成了初步前端界面原型
基础架构跑通之后,迭代优化便提上了日程。
二、借助 AI 工具规划优化路径
面对"怎么优化"这个问题,本周尝试借助 AI 编码工具 Trae 对项目进行"蓝图描绘"。向 Trae 输入的提示词如下:
在我现有 RAG 的基础上,应该怎么去优化,从数据库扩充、技术细节优化、对比 RAG 前后问答质量方面入手。另外关注一下学习路线生成模块,可以用推荐算法做因人而异的个性化推荐吗?项目截止时间是 6 月 20 日。
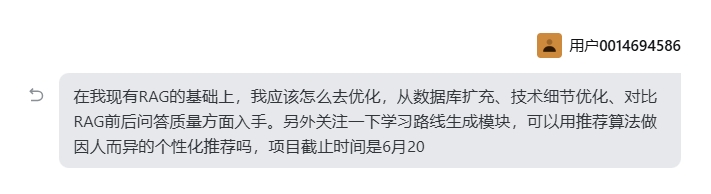
Trae 给出的优化方向与时间分配建议如下:
另外有高风险提示: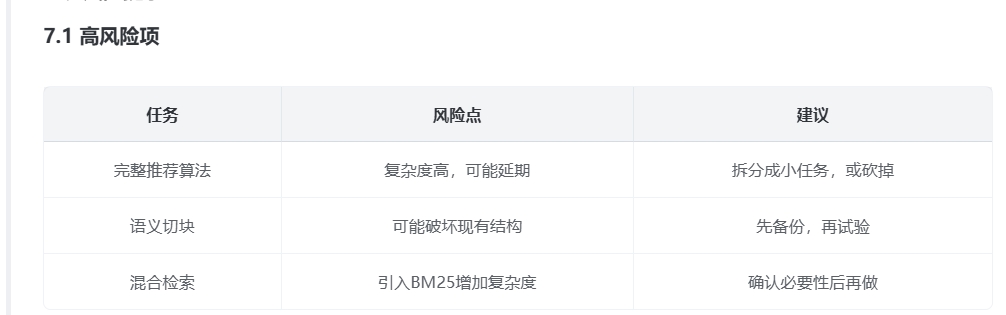
关于推荐算法的取舍思考
Trae 将推荐算法列为高风险、低优先级任务,这一结论值得深入思考。
从用户需求角度看,"因人而异的视频或推文知识推荐"确实能显著提升用户体验,满足多样化学习需求。但经过进一步调研发现,传统推荐系统(协同过滤、内容过滤等)依赖大量用户行为数据进行训练,而当前项目:
- 用户基数有限,冷启动问题突出
- 训练成本高,短期内难以收集足量反馈数据
- 与项目核心目标(RAG 问答质量提升)关联度较低
结论:学习路线规划模块维持原有设计,暂不引入推荐算法,将精力聚焦于 RAG 核心链路的质量提升。
💡 这次借助 AI 工具辅助决策的体验值得记录:Trae 的建议并不是直接执行的"命令",而是需要结合项目实际情况进行评估和取舍的参考输入。AI 工具的价值在于拓宽思路、提供结构化视角,最终的判断仍需人工介入。
三、本周核心工作
参照 Trae 的优化方向,本周工作主要围绕两条主线展开:知识库扩充与RAG 技术调优。
3.1 知识库扩充
知识库是 RAG 系统的"粮仓",其数量和质量直接决定了检索上限,因此知识库扩充是一项贯穿项目全周期的持续性工作,而非一次性任务。
本周在知识库建设上的工作重点:
- 补充多领域学习资料,覆盖更广泛的问答场景
- 对已有文档进行质量筛查,清理低质量、重复性内容
- 完善导入流程,确保不同格式文档解析的稳定性
知识库的厚度决定了 RAG 的天花板,技术优化再好,检索不到也是枉然。
3.2 构建评估测试集
没有评估的优化就是盲优化。 在开始调整任何技术参数之前,首先建立了一套可量化的评估体系,用于观察和对比实验效果。
测试集构建
- 构建包含 30~50 个标准问题的测试集,覆盖不同难度、不同领域
- 问题来源结合:真实用户可能提问的场景 + 知识库中有明确答案的内容
评估指标定义
| 指标 | 含义 |
|---|---|
| 关键词召回率 | 回答中包含参考答案关键词的比例,衡量信息覆盖完整度 |
| 引用准确率 | 检索到的文档片段与问题的相关性,衡量检索质量 |
| 回答完整度 | 回答是否完整覆盖问题的各个方面,避免答非所问 |
评估流程
建立定期回归测试机制:每次调整参数后,在同一测试集上跑一遍评估,横向对比不同配置下的效果差异,确保优化是正向的,而非"负优化"。
可行性评估:技术难度中等,但长期价值高——这是避免"感觉变好了"式优化的关键基础设施。
3.3 技术参数调优实验
在评估体系就位之后,开始对 RAG 检索链路的关键参数进行系统性调优。
调优对象
文本分块策略是本轮调优的核心,主要涉及两个参数:
chunk_size(切块大小):每个文本块的 token 数量chunk_overlap(重叠区域):相邻块之间共享的 token 数量
实验结果(初步)
通过在标准测试集上跑不同参数组合的对比实验,观察各配置下的召回率与引用准确率变化,逐步收敛至当前阶段的最优参数区间。具体数据将在下周汇总后附上对比图表。
四、阶段性思考
本周工作带来了几点值得沉淀的思考:
1. "先评估,再优化"是正确的工程姿势
在没有评估体系之前直接调参,无法判断改动是否有效。建立测试集和评估指标,是让优化工作可观测、可复现、可比较的前提条件。
2. 工具辅助决策,但不替代判断
Trae 提供的优化建议结构清晰、思路完整,节省了大量调研时间。但"推荐算法"一项的取舍说明:AI 工具的输出需要结合项目约束(时间、数据量、核心目标)进行人工评估,不能直接照单全收。
3. 知识库质量是 RAG 的地基
技术调优是在现有知识库的基础上做乘法,但如果知识库本身质量不高,再好的检索策略也难以弥补。知识库建设的持续投入是必要的。
五、下周计划
- 完成参数调优实验,输出对比报告(含图表)
- 继续扩充知识库,目标新增文档 XX 篇
- 探索混合检索策略(关键词检索 + 向量检索结合)
- 知识图谱 / 用户画像模块:完成技术选型调研
- 学习规划模块:推进后端接口对接
本文为项目开发周记,记录真实开发过程中的决策思路与技术探索,供后续复盘参考。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)