23级山东大学软件学院创新实训-个人纪录(五)——灵语星火实训项目:Stable Diffusion 远程服务器部署与测试
一、扩散模型(Diffusion Model)简介
扩散模型是一类受非平衡热力学启发的生成模型。它的核心思想分为两个过程: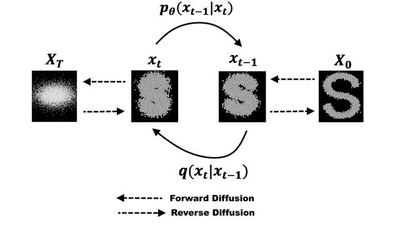
前向扩散过程(Forward Process)
向一张真实图像逐步添加高斯噪声,经过足够多的步骤后,图像完全退化为纯噪声。这个过程是固定的,不需要学习。
反向去噪过程(Reverse Process)
训练一个神经网络(通常是 U-Net)来预测每一步添加的噪声,从而将纯噪声逐步还原成一张有意义的图像。
训练时,模型学会根据当前带噪图像和时间步预测噪声,通过最小化预测噪声与真实噪声之间的误差来优化参数。推理(采样)时,模型从纯噪声开始,反复“减去”预测的噪声,最终生成高清图像。
扩散模型的发展里程碑包括 DDPM(Denoising Diffusion Probabilistic Models,2020)、DDIM(加速采样,2021)以及 基于分数的生成模型。相比 GAN,扩散模型生成多样性更好、训练更稳定,但早期速度较慢。
二、Stable Diffusion 概述
Stable Diffusion 是扩散模型发展中的一次重大突破,由 Stability AI 在 2022 年发布。它的核心创新是将扩散过程从庞大的像素空间转移到潜空间(Latent Space),极大降低了计算开销,使普通人也能在消费级显卡上运行。
2.1 核心架构
Stable Diffusion 主要由三个组件构成:
VAE(变分自编码器):将图像压缩到低维潜空间,解码时再重建回像素。潜空间的尺寸通常是原图的 1/8,大幅降低了扩散过程的维度。
U-Net:在潜空间中执行去噪预测,是模型的主体。它接收带噪声的潜变量、时间步和文本条件,输出预测的噪声。
CLIP Text Encoder:将文本提示词转换成高维语义向量,引导 U-Net 生成与文本描述一致的图像。
2.2 版本演进
版本 特点 发布时间
SD 1.x 基础版本,512×512 原生分辨率,广泛支持 2022
SD 2.x 改进文本理解,但社区生态较弱 2022
SDXL 1.0 原生 1024×1024,画面细节大幅提升 2023
SDXL Turbo/Lightning 1~4 步极速生成,适合实时应用 2023
SD3 / 3.5 全新架构(MMDiT),图像质量顶级 2024
三、远程服务器部署
下面以 Linux 服务器(Ubuntu 22.04)为例,部署最流行的 AUTOMATIC1111 webui。
3.1 硬件要求
组件 最低配置 推荐配置
GPU NVIDIA GTX 1060 6GB RTX 3060 12GB 或以上
显存 6 GB 12 GB
内存 16 GB 32 GB
存储 50 GB 可用空间 1 TB SSD
3.2 环境准备
(1) 安装 NVIDIA 驱动与 CUDA
以 Ubuntu 为例
sudo apt update
sudo apt install nvidia-driver-535
sudo reboot
验证安装:nvidia-smi 应显示 GPU 名称、驱动版本、CUDA 版本。
(2) 安装 Python 和 Git
sudo apt install python3.10 python3.10-venv git -y
推荐使用 Conda 或 venv 创建虚拟环境,避免依赖冲突。
(3) 下载 WebUI 源码
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cd stable-diffusion-webui
3.3 启动 WebUI 与依赖安装
直接运行启动脚本,它会自动创建虚拟环境并安装 PyTorch 等依赖:
./webui.sh
常见报错与解决:
Couldn’t install clip / ModuleNotFoundError: No module named ‘pkg_resources’
原因是 setuptools 版本过旧。进入虚拟环境升级即可:
source venv/bin/activate
pip install --upgrade pip setuptools wheel
deactivate
然后重新运行 ./webui.sh。
The NVIDIA driver on your system is too old
升级 GPU 驱动(见 3.2 节),或安装与当前 CUDA 驱动匹配的 PyTorch 版本,但更推荐更新驱动。
No module named ‘ldm.modules.midas’
删除不完整的依赖仓库并让脚本重新拉取:
rm -rf repositories/stable-diffusion-stability-ai
./webui.sh
3.4 下载模型权重
WebUI 不会自动下载基础模型,需要手动放置到 models/Stable-diffusion/ 目录。以下推荐两个权重文件,任选其一即可。
cd models/Stable-diffusion/
SDXL 1.0(推荐,约 6.94 GB)
wget “https://hf-mirror.com/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0.safetensors”
SDXL Turbo(极速生成,约 6.9 GB)
wget “https://hf-mirror.com/stabilityai/sdxl-turbo/resolve/main/sd_xl_turbo_1.0_fp16.safetensors”
注:使用国内镜像 hf-mirror.com 可大幅提速。下载完成后,WebUI 界面刷新模型列表即可看到新权重。
3.5 优化启动参数
编辑 webui-user.sh(Linux)或 webui-user.bat(Windows),添加常用命令行参数:
export COMMANDLINE_ARGS=“–listen --port 7860 --xformers --medvram”
参数 说明
–listen 允许局域网内其他设备访问
–port 7860 自定义端口
–xformers 启用 xFormers 加速,降低显存占用
–medvram 中等显存优化(6~8 GB 推荐)
若 xFormers 未安装,可在虚拟环境中手动安装:
pip install xformers --index-url https://download.pytorch.org/whl/cu118
3.6 远程访问配置
本地运行后,WebUI 仅监听 127.0.0.1:7860。想让外部设备访问,有以下方案:
SSH 端口转发(安全推荐)
在本地电脑执行:
ssh -L 7860:localhost:7860 user@your-server-ip
然后浏览器访问 http://localhost:7860。
配合 Nginx 反向代理 + HTTPS
生产环境中建议配置域名和 HTTPS,确保传输安全。
–share 参数
启动时添加 --share,会生成一个临时的 Gradio 公共链接,但存在暴露风险,仅供临时测试。
四、测试过程
4.1 基础文生图测试
浏览器访问 WebUI 后,在 txt2img 标签页输入提示词,使用默认参数点击 Generate。
示例:
Prompt: a cat sitting in a library, highly detailed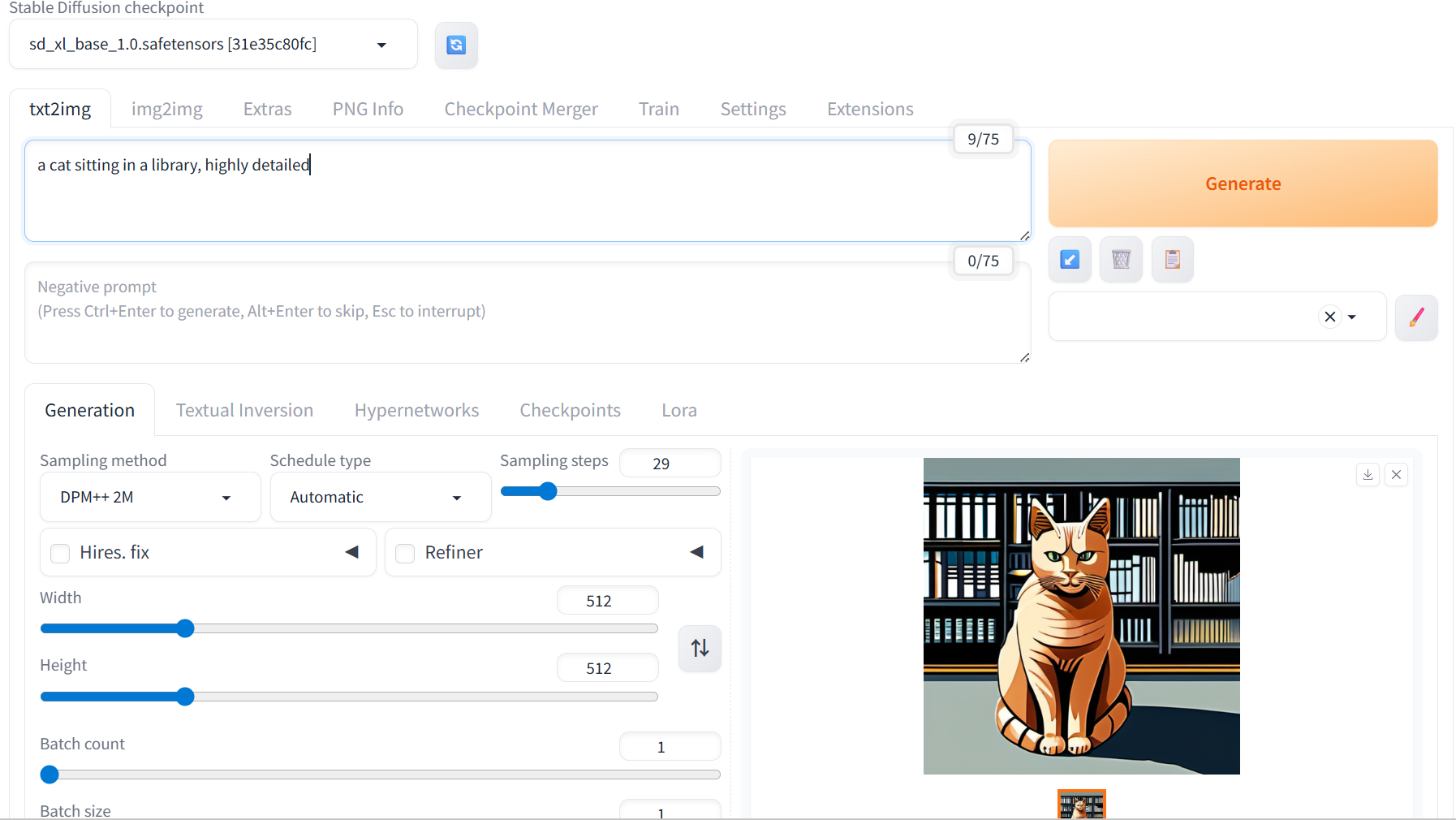
采样器: DPM++
步数: 29
CFG Scale: 7
分辨率: 512×512
若模型正确加载,十秒内即可在右侧看到生成结果。
4.2 参数调优与高级功能
参数 作用 建议
Sampler 控制去噪策略 Euler a / DPM++ 2M Karras 通用;DDIM 速度最快
Steps 迭代步数 20~30 步即可收敛,继续增加收益很小
CFG Scale 提示词引导强度 7~12 之间平衡质量和相关性
Seed 随机种子,固定可复现结果 -1 为随机
图生图(img2img):上传参考图并调整 Denoising strength,数值越高与原图差异越大。
文生图附加网络:LoRA、ControlNet 等扩展可精确控制人物、姿势、风格,需从 CivitAI 下载相应文件放入 models/Lora 等目录。
4.3 性能测试
使用 SDXL 模型在 RTX 3060 12GB 上实测:
显存占用:约 8.2 GB(启用 xformers 及 medvram)
生成 1024×1024 图像,20 步 Euler a 耗时约 12~15 秒
SDXL Turbo 模型 4 步采样仅需 2~3 秒
监控工具:在服务器上运行 nvidia-smi -l 1 可实时观察显存和 GPU 利用率。
4.4 常见错误速查
报错信息 原因 解决
No checkpoints found 模型文件缺失或路径错误 将 .safetensors 模型放入 models/Stable-diffusion/,刷新列表
CUDA out of memory 显存不足 降低分辨率,添加 --medvram 或 --lowvram
Cannot connect to huggingface.co 网络问题 使用 hf-mirror.com 镜像下载模型
No module ‘xformers’ 加速库未安装 不影响运行,可按上文手动安装
五、总结
本文从扩散模型原理出发,介绍了 Stable Diffusion 的工作方式,并给出了远程服务器上部署 AUTOMATIC1111 WebUI 的完整流程。后续这也是我们团队利用文生图技术进行AI生成故事配图的基础,后续工作将以这个为基础进行展开。
参考资源:
AUTOMATIC1111 WebUI GitHub
Stable Diffusion XL 官方模型
CivitAI 模型社区
Hugging Face 镜像站

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)