项目实训——Werewolf-Agent 中DsPy的metric设计
前言
在前期的工作中,我们在项目中加入了DsPy来优化提示词生成,但是仅仅是初步地利用了它。在 DSPy 框架中,metric(评估指标)是编译器的“指南针”——它告诉优化器什么样的输出是"好的",什么样的输出需要"改进"。最近的工作就是要针对我们的狼人杀设计一套适用的metric。
一个好的 metric 不仅仅是"答案对不对",更需要定义 输出的整体质量 。
一、metric的难点:每个角色有不同的"对错标准"
在狼人杀中,对于ai输出结果的评估是没有一个具体的标准的,我们只能通过结合他们的身份来设计一个具体的针对方案:对于预言家而言,就是根据目标选择查验目标,查验目标对了就是对了,错就是错了,这个没有其他的更好的评估标准了。
但是到女巫、狼人这些角色,他们的决策就比较复杂了:女巫同时有两个决策:解药救不救、毒药毒谁。这两个决策不是独立的——如果狼人刀了自己,解药根本不存在;毒药毒了死人,规则上直接违规,狼人就还区分白天黑夜,黑夜是要直接与同伴交流,那就肯定要可以从输出中看到它们知道自己的同伴,与此同时逻辑推理也必不可少,但是白天发言的"对"更特殊——它不仅是逻辑推理,更是表演。模型输出了一段发言,评判这段发言好不好,不能看内容对不对,要看有没有暴露狼人身份(有没有说出"我们"、"狼同伴"这类词)。
二、当前metric设计思路
经过反复测试,目前,我采用的是一个固定的三层 metric 结构,每个角色通用:
总分 = 0.4 × 规则分 + 0.4 × 答案分 + 0.2 × 推理质量分
第一层:规则分——不可逾越的红线
规则分衡量的是"有没有做绝对不允许做的事"。这一层是硬约束,违反了就拿 0 分,没有任何商量余地。
这个规则是一个最重要的,所以我把它放在第一位。在测试中,我发现即使在提示词中反复强调一些规则如出局玩家不可以用毒毒杀,但是有时候大模型就会忽略这一点,这使得游戏无法正常运行,所以我们要设置这么一个规则分,这是我觉得很有必要的一部分。除此之外,为了保证大模型不会出现这种情况,我在提示词之外也设置了输出目标的检测,如果违规就必须重新打回生成。
接下来我用女巫为例:
def _witch_rule_compliant(example, pred, alive_players):
if save and save_used: # 解药已用却还救人 → 违规
return False
if poison is not None and poison_used: # 毒药已用却还毒人 → 违规
return False
if poison == witch_id: # 毒药毒自己 → 违规
return False
if poison is not None and poison not in alive_players: # 毒死人 → 违规
return False
return True这四个条件对应了狼人杀的四条女巫规则:不能重复用药、不能毒自己、不能毒死人。它们在任何局面下都不应该被违反,因此权重给到 0.4,如果这一步就违规的话,DsPy优化器肯定就不会选择这个作为最优解。
第二层:答案分——决策是否正确
答案分衡量的是"决策本身对不对"。对于单目标决策(预言家、狼人),这层很简单:pred.target == example.target。
但女巫有两个决策(解药 + 毒药),这层的处理需要更细致:
def witch_answer(example, pred, trace=None):
save_ok = (pred_save == true_save)
poison_ok = (pred_poison == true_poison)
if save_ok and poison_ok: return 1.0 # 全对
elif save_ok or poison_ok: return 0.5 # 对了一半
else: return 0.0 # 全错这是一个部分正确得分的设计。在现实中,女巫的解药和毒药经常不是同时出现的(解药只在第一晚有意义,毒药也不是每晚都用),所以完全一致的 1.0 或完全不一致的 0.0 其实都不能准确反映模型的真实水平。用 0.5 作为中间档,比二分法更诚实。
第三层:推理质量分——输出的过程是否合理
这一层的评分标准是我觉得最难的,就是它的一个标准很难把握,对于大模型的推理过程的分析,这段文字的打分确实是比较困难的,分析内容是否具体全面都是有待考据的,所以我给了最低的权重,这是在当下暂时设计的,在后面肯定是要慢慢优化的。
这部分代码参考意义并不大,只是我能想到的比较好一点的了。我从字数以及关键词部分进行打分,字数达不到要求或者没有包含一些关键词,得分都不会太高。
def witch_reasoning_quality(example, pred, trace=None):
score = 0.0
if any(f"Bot{i}" in reasoning for i in range(1, 6)):
score += 0.3 # 提到了具体玩家名 → 有具体分析
keywords = ["解药", "毒药", "救人", "狼人", "投票", "袭击"]
score += min(0.3, sum(1 for kw in keywords if kw in reasoning) * 0.1)
if len(reasoning) >= 50: score += 0.4
elif len(reasoning) >= 20: score += 0.2
return min(1.0, score)这种评分当然不是完美的——模型可能写很多字但都是废话。但它提供了足够的信号让 MIPRO 区分"有深度分析的推理"和"空洞的敷衍"。
三、狼人白天发言的特殊性:内容安全 metric
狼人白天发言是所有角色里 metric 设计最特殊的一个,因为它不是评判“决策对不对”,而是评判“有没有暴露身份”。
这是一个负向指标——我们要找的不是“说了什么好东西”,而是“有没有说坏话”。基于这个特性,我用了黑名单词检测:
FORBIDDEN_WORDS = ["狼同伴", "我们", "一起", "队友", "狼队", "同伴"]
def _day_speech_rule_compliant(pred) -> bool:
speech = getattr(pred, "speech", "") or ""
return not any(fw in speech for fw in FORBIDDEN_WORDS)只要发言里出现了任何一个黑名单词,规则分直接归零。这个设计有一个重要的副产品:MIPRO 在优化这个模块时,会让模型学会主动规避这些词汇,而不是靠外部过滤来处理输出。这是真正的内化,不是补丁。
推理质量分则从正向引导发言质量:
keywords = ["预言家", "女巫", "村民", "发言", "投票", "可疑",
"站边", "查杀", "逻辑", "分析"]发言里提到这些词越多,说明模型越像在进行真实的社会推理,而不是在背台词。
四、模块体系的演进:从 1个到 5个角色的结构思考
现在我已经根据预言家的模板,修改了女巫、狼人这些节点,将dspy应用于它们的节点上。
从最开始的预言家一个,到现在女巫、狼人夜晚讨论、狼人夜晚决策、狼人白天发言共5个dspy.Module,对应5个dspy.Signature,对应5组metric。它们的组织方式是一致的:
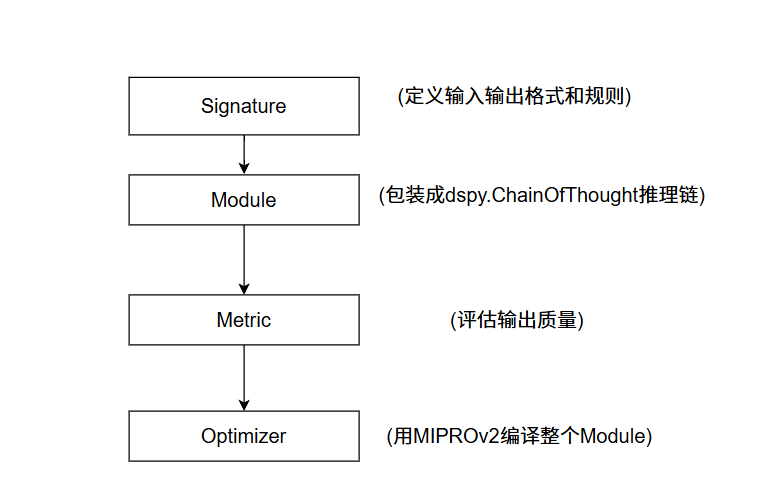
每新增一个角色,流程是固定的:先设计Signature的InputField/OutputField(这一步决定了数据 JSON 的 schema),再设计 Metric 的三层评估,最后在 Optimizer 里注册编译函数。
这个固定流程的好处是:新增角色不会破坏已有角色的代码。我们去获取训练数据时候也是确定的格式,不用再去重复修改。后期,我们可以根据当前六人局去设计9人或者十二人局,这样可以增强游戏的对局性,但是此时使用dspy就会显现出局限性,对于不同人数的狼人杀,我要去获取不同的训练数据,如果混用训练数据容易导致大模型回答不存在的角色等问题。
五、总结
回顾整个过程,有一个规律反复出现:
当你觉得模型"应该会但实际上不会"的时候,答案几乎总是在 metric 里,而不是在模型里。
模型是按 metric 给出的梯度方向优化的。如果你只衡量答案对不对,模型就只学会答对题。如果你衡量规则遵守,模型就学会规避违规。如果你衡量推理质量,模型就学会给出有深度的分析。但如果你不衡量一个维度,模型就永远不会往那个方向走。
metric 是系统的目标函数,而目标函数决定了系统能达到的上限。
对于狼人杀 AI 来说,当前的 metric 覆盖了规则遵守、决策正确和推理质量三个维度。下一步要做的是在这三个维度里继续深化:让女巫学会在解药和毒药之间做更精细的权衡决策,让狼人白天发言的 metric 真正能评估"发言的社会效果"而不是"发言的词汇组成"。每一步都是 metric 的深化,而不是模型的替换。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)