九、LangChain之核心组件--(7)文本向量(上)
7. 文本向量
7.1 嵌入与嵌入模型(Embedding and Embedding Models)
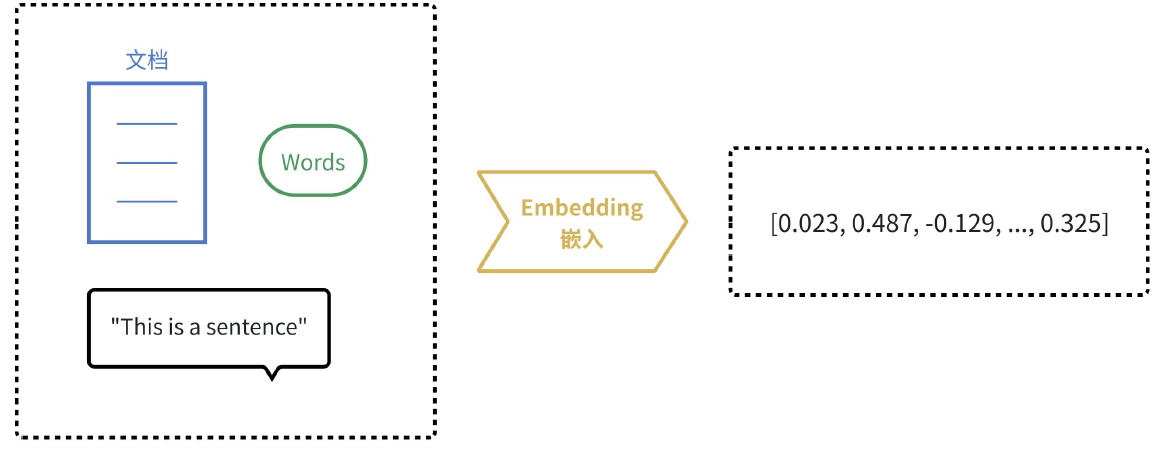
计算机天生擅长处理数字,但不理解文字、图片的含义。嵌入(Embedding)的核心思想就是将人类世界的符号(如单词、句子、产品、用户、图片)转换为计算机能够理解的数值形式(即向量,本质上是一个数字列表),并且要求这种转换能够保留原始符号的语义和关系。我们可以把它想象成一个翻译过程,把人类语言“翻译”成计算机的“数学语言”。
类比
"苹果" ──[嵌入模型]──▶ [0.023, 0.487, -0.129, ..., 0.325]
"香蕉" ──[嵌入模型]──▶ [0.019, 0.502, -0.118, ..., 0.341]
因为"苹果"和"香蕉"语义相近(都是水果),这两个向量的方向很接近
我们之前一直用的大语言模型是生成式模型。它理解输入并生成新的文本(回答问题、写文
章)。它内部实际上也使用嵌入技术来理解输入,但最终目标是“创造”。
而嵌入模型(Embedding Models)是表示型模型。它的目标不是生成文本,而是为输入的文本创建一个最佳的、富含语义的数值表示(向量)。如 OpenAI 的 "text-embedding-3-large" 嵌入模型;
Google 的 "gemini-embedding-001" 嵌入模型;阿里的 "Qwen3-Embedding-8B" 嵌入模型等。
生成式模型 vs 表示型模型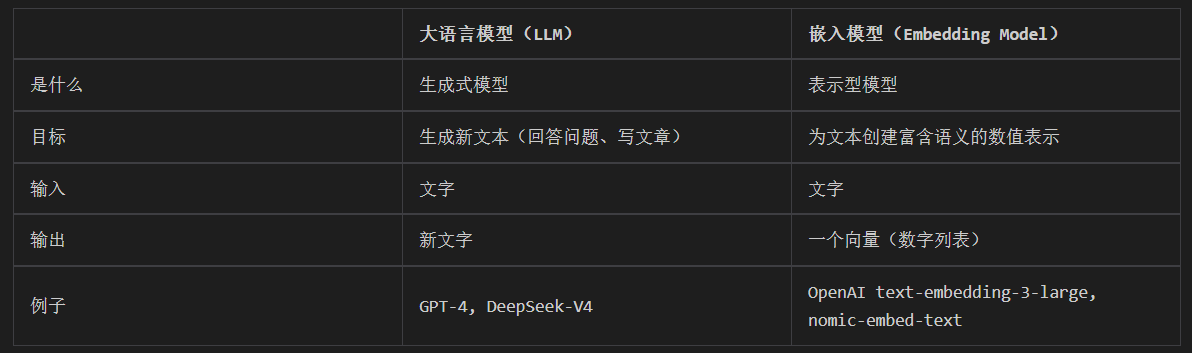
7.1.1 什么是向量?
首先我们要知道,嵌入的结果是就是一个向量,它本质上是一个数字列表(一维数组)。例如:
[0.023, 0.487, -0.129, ..., 0.325] 。对于向量来说,有两个关键概念需要了解:
向量维度:嵌入结果得到的列表长度是固定的,称为向量的“维度”。例如,OpenAI 的 text-embeddingada-002 模型会生成一个 1536 维的向量, text-embedding-3-large 模型会生成一个 3072 维的向量。维度越高,通常能捕捉更细微的语义信息,但也需要更多的计算和存储资源。
向量空间:想象一个无限延伸的、拥有无数个维度的宇宙,这个宇宙就是一个向量空间。这有点抽象,可以想象一下:
• 在三维世界里,一个点可以用 (x, y, z) 坐标表示,例如 (2, 5, -1) 。
• 在机器学习的高维向量空间中,一个点可能是 (0.1, 0.7, -0.2, 0.4, ..., 0.02) ,一个有几百或几千个数字的坐标。
在这个空间里,每个点(即每个向量)都能代表一个概念。例如在嵌入模型中,一个点可以代表一个单词、一句话、一张图片、一个用户、一部电影等。
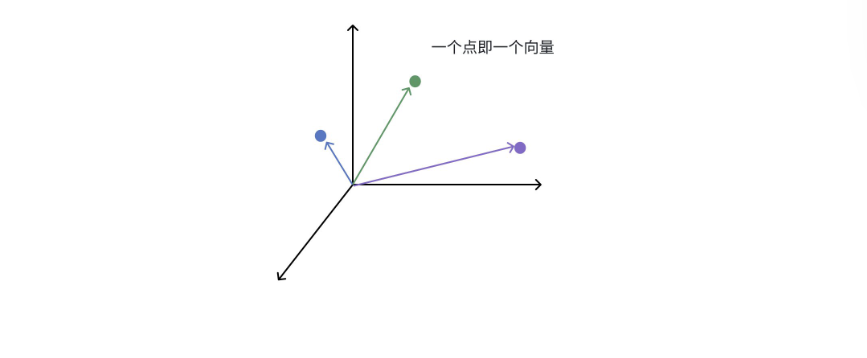
到这里,向量空间的威力就能体现出来:我们可以用数学来度量语义。可以通过计算两个向量之间
的“距离”或“相似度”来实现这一点。
如何度量"距离"?

• 欧氏距离(Euclidean Distance):就是我们高中几何学的两点之间的直线距离。距离越短,相似度越高。
• 余弦相似度(Cosine Similarity):它忽略向量的绝对长度(大小),只关注两个向量在方向上的差异。在文本和语义的世界里,“方向”代表“含义”,而“长度”往往只代表“文本的长度”或“词汇的多少”。换句话说,余弦相似度关注的是“你们是否指向同一个方向” / “你们是否代表同一个含义”
"苹果很好吃" 的向量
"苹果很好吃很好吃很好吃" 的向量(更长但方向相同)欧氏距离:距离很大(不相似)— 不对!
余弦相似度:方向一致(很相似)— 对!
因此,在捕捉语义上的相似性上,余弦相似度是更常用的度量方式。
我们又能反推出,由于使用向量来绘制向量空间,而向量是有维度的,维度越高,则更能捕捉极其细微和复杂的语义差别(比如“高兴”和“喜悦”的区别)。
这能干什么?这能解决一个传统数据库(如MySQL)不擅长的问题:基于内容的相似性搜索,而不是基于精确匹配的查询。
传统 MySQL:搜"一种红色的水果" → 找不到"苹果"的文档(没有关键词匹配)
语义搜索:embed("一种红色的水果") 和 embed("苹果是一种常见的水果") 的向量方向相近 → 能找到!
7.1.2 嵌入模型应用场景
对于对于嵌入模型,实际上在示例选择器部分,我们已经使用过。当时使用的场景就是可以根据语义相似性完成示例的筛选。
根据嵌入的特性,由此延伸出了许多嵌入模型在 AI 应用的使用场景:
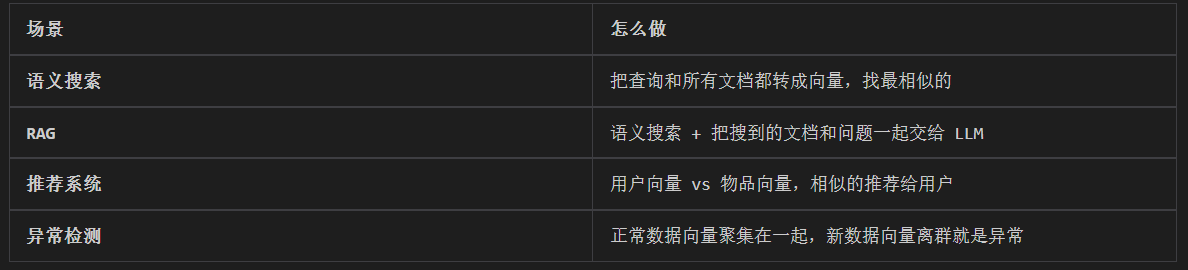
• 语义搜索(Semantic Search):传统搜索依赖关键词匹配(搜“苹果” ,只能找到包含“苹果” 这个词的文档)。语义搜索则能将查询(如“一种红色的水果” )和文档库中的所有文档都转换为向量。然后计算查询向量与所有文档向量的相似度,返回最相似的文档。这样即使文档里没有“红色” 和“水果” 这些词,但只要它是关于“苹果” 的,就能被找到。
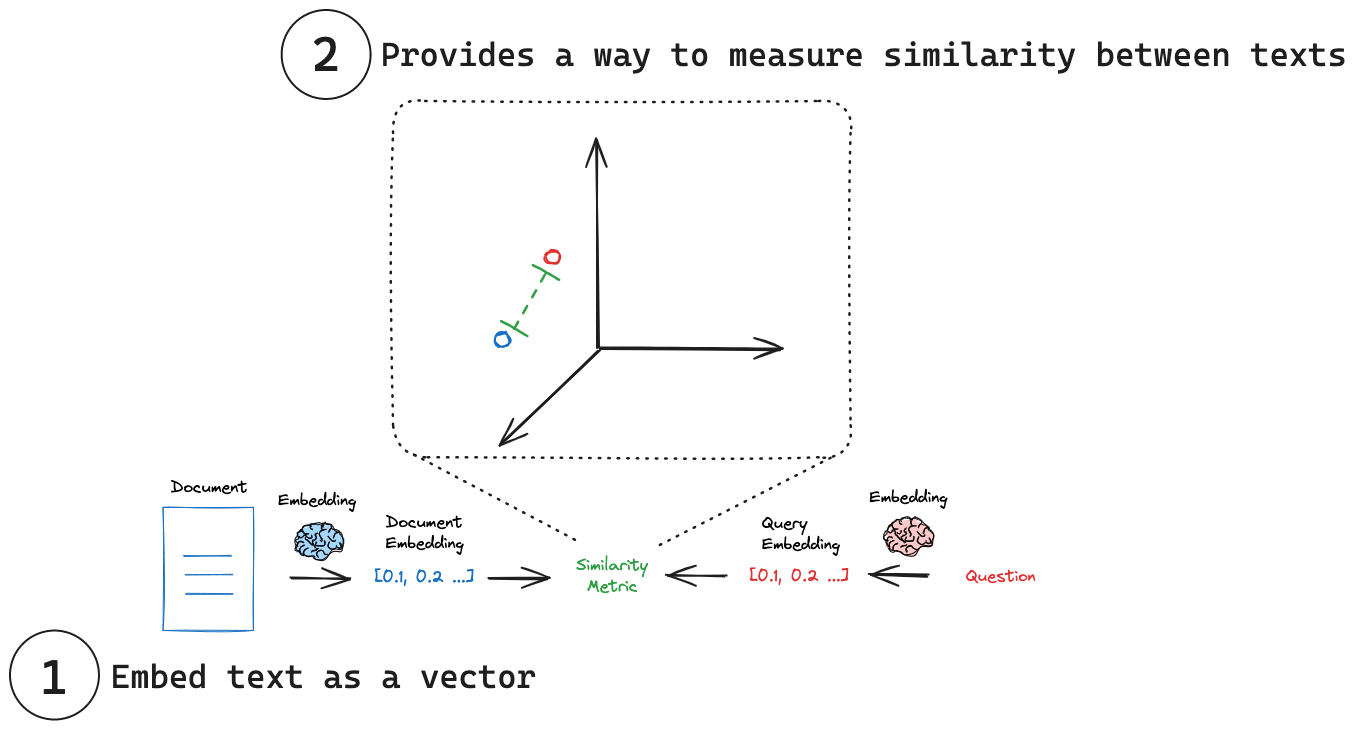
下图为我们展示了借助嵌入模型进行文档搜索的过程:
1. 为多文档生成其各自的向量,
2. 为搜索查询语句生成向量,
3. 衡量查询向量与每个文档向量之间的相似性,得到相似度最高的文档。
• 检索增强生成(Retrieval-Augmented Generation, RAG):这是当前大语言模型应用的核心模式。当用户向 LLM 提问时,系统首先使用嵌入模型在知识库(如公司内部文档)中进行语义搜索,找到最相关的内容,然后将这些内容和问题一起交给 LLM 来生成答案。这极大地提高了答案的准确性和时效性。
• 推荐系统(Recommendation Systems):将用户(根据其历史行为、偏好)和物品(商品、电影、新闻)都转换为向量。喜欢相似物品的用户,其向量会接近;相似的物品,其向量也会接近。通过计算用户和物品向量的相似度,就可以进行精准推荐。
• 异常检测(Anomaly Detection):正常数据的向量通常会聚集在一起。如果一个新数据的向量远离大多数向量的聚集区,它就可能是一个异常点(如垃圾邮件、欺诈交易)。
7.2 Embeddings 嵌入模型类
在 LangChain 中,有很多的嵌入模型提供方,使用不同的模型提供方,需要安装为其各自包,例如:
• OpenAI: pip install -U langchain-openai
• Ollama: pip install -U langchain-ollama
• Google Gemini: pip install -U langchain-google-genai
• 更多见LangChain Python integrations - Docs by LangChain
7.2.1 定义嵌入模型
在这里我们选择 嵌入用 Ollama 来进行后续操作。
这里介绍一下定义 OpenAI 下的嵌入模型使用:class langchain_openai.embeddings.base.OpenAIEmbeddings ,官方接口介绍见langchain_openai | LangChain Reference
定义 OpenAIEmbeddings 嵌入模型类与定义聊天模型类似,如下所示:
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-3-large", # 3072 维高质量向量
)
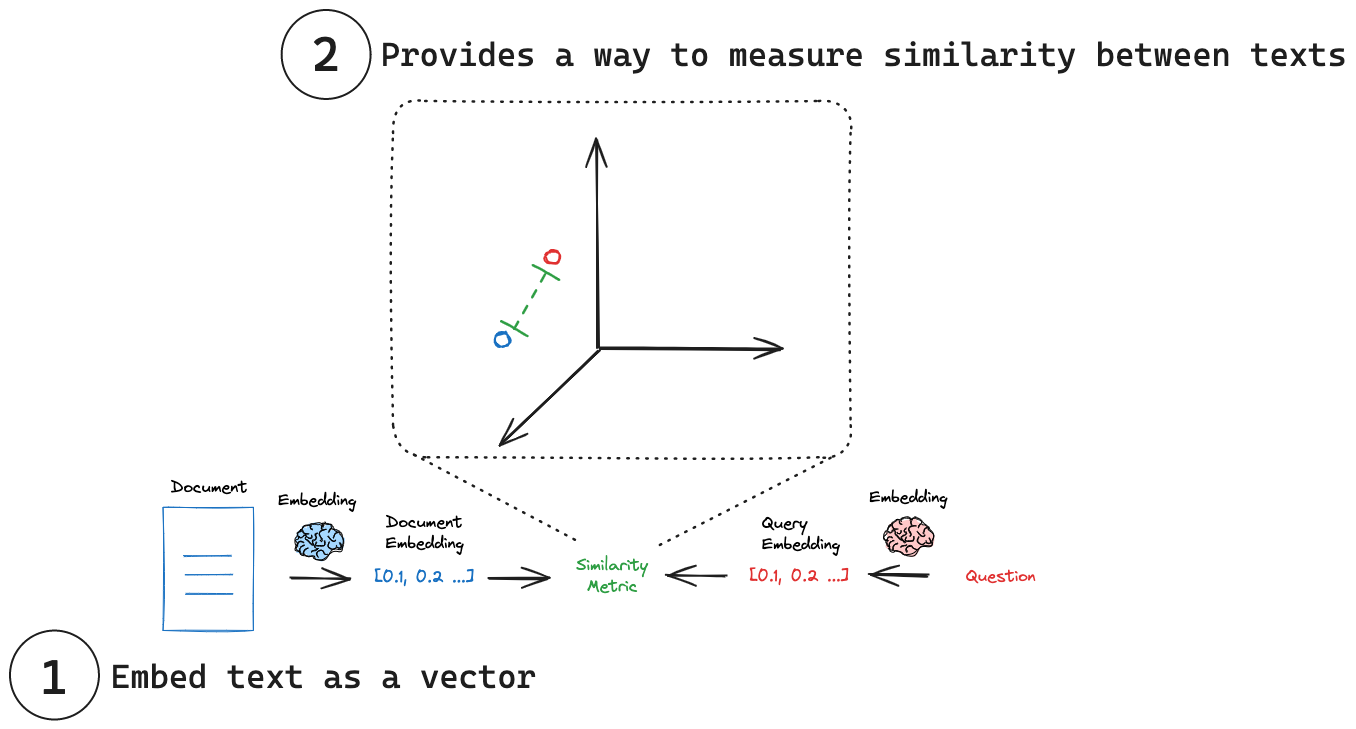
在 LangChain 框架中基础 Embeddings 类( OpenAIEmbeddings 继承了它)设计了两个核心方法
来处理文本嵌入,分别对应两种场景:

• .embed_documents() : 用于处理文档Documents 。它的输入是多个文本。例如要将一个
知识库里的所有段落都转换成向量后存入数据库,就会使用这个方法。
◦ 它返回一个【二维列表】List[List[float]] 。外层列表的每个元素对应一个输入文档,内层列表则是该文档的向量表示。
• .embed_query() : 用于处理查询Query 。它的输入是单个文本(一个字符串,str)。例
如,当用户提出一个问题时,需要将这个问题转换成向量,以便在数据库中搜索相似的文档段落,
就会使用这个方法。
◦ 它返回一个【一维列表】,里面是浮点数( List[float] ),代表单个查询文本的向量。
其实分别对应下图中文档与查询的向量生成:
之所以设计成两个方法,是因为某些嵌入模型提供商(如 OpenAI、Cohere 等)会针对“被搜索的文档” 和“搜索查询本身” 采用不同的优化策略和模型。即使底层是同一个模型,也可能对两者进行不同的预处理(例如添加不同的指令前缀),以获得更好的搜索效果。
7.2.2 嵌入文档列表(离线批量索引)
embed_documents 的语义是 “索引”。它的目的是预处理大量文本,为它们创建向量表示,以便
后续被搜索。这一般是一个离线、批量处理的过程。代码如下:
完整的"加载 → 分割 → 嵌入"流程:
from langchain_ollama import OllamaEmbeddings
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import CharacterTextSplitter
# 1. 加载文档
loader = UnstructuredMarkdownLoader("./file/Day 1 详解:总览.md")
data = loader.load()
# 2. 分割成小块
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", chunk_size=200, chunk_overlap=50
)
documents = text_splitter.split_documents(data)
# 3. 提取纯文本
texts = [doc.page_content for doc in documents]
# 4. 嵌入:把所有文档块转成向量(用本地 Ollama,免费)
embeddings = OllamaEmbeddings(model="nomic-embed-text")
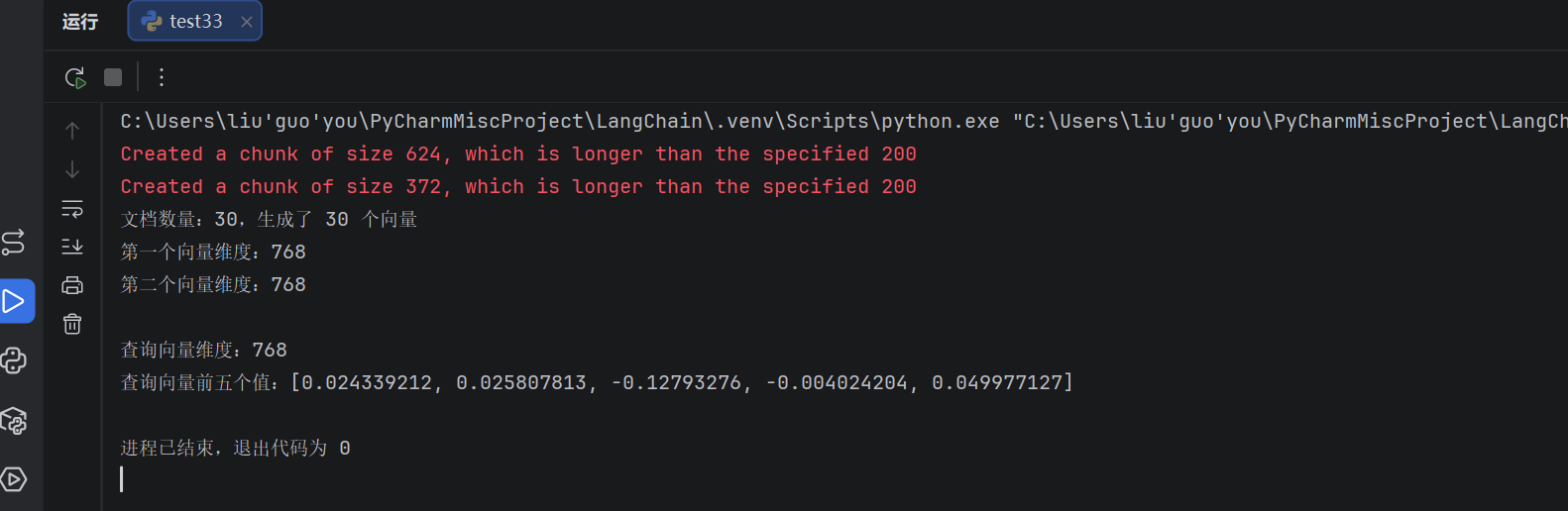
documents_vector = embeddings.embed_documents(texts)
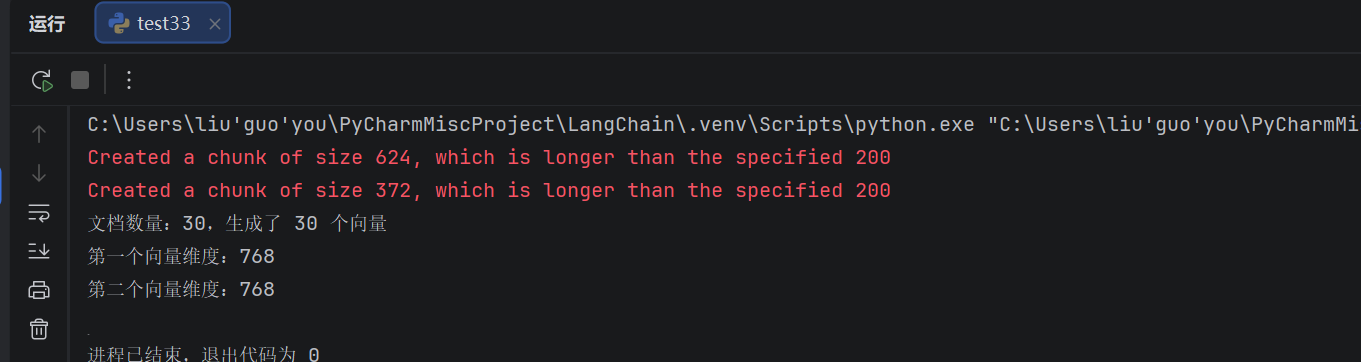
print(f"文档数量:{len(documents)},生成了 {len(documents_vector)} 个向量")
print(f"第一个向量维度:{len(documents_vector[0])}") # nomic-embed-text 是 768 维
print(f"第二个向量维度:{len(documents_vector[1])}")
7.2.3 嵌入单个查询(在线实时)
embed_query 的语义是 “搜索”。它的目的是在用户发起请求时,实时地将一个问题或指令转换
为向量,用于在已索引的文档向量中进行检索。这是一个在线、实时、按需处理的过程。
为单个查询生成向量的代码如下:
from langchain_ollama import OllamaEmbeddings
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import CharacterTextSplitter
# 1. 加载文档
loader = UnstructuredMarkdownLoader("./file/Day 1 详解:总览.md")
data = loader.load()
# 2. 分割成小块
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", chunk_size=200, chunk_overlap=50
)
documents = text_splitter.split_documents(data)
# 3. 提取纯文本
texts = [doc.page_content for doc in documents]
# 4. 嵌入:把所有文档块转成向量(用本地 Ollama,免费)
# embeddings = OllamaEmbeddings(model="nomic-embed-text")
# documents_vector = embeddings.embed_documents(texts)
#
# print(f"文档数量:{len(documents)},生成了 {len(documents_vector)} 个向量")
# print(f"第一个向量维度:{len(documents_vector[0])}") # nomic-embed-text 是 768 维
# print(f"第二个向量维度:{len(documents_vector[1])}")
# 5. 嵌入单个查询(在线实时)
embeddings = OllamaEmbeddings(model="nomic-embed-text")
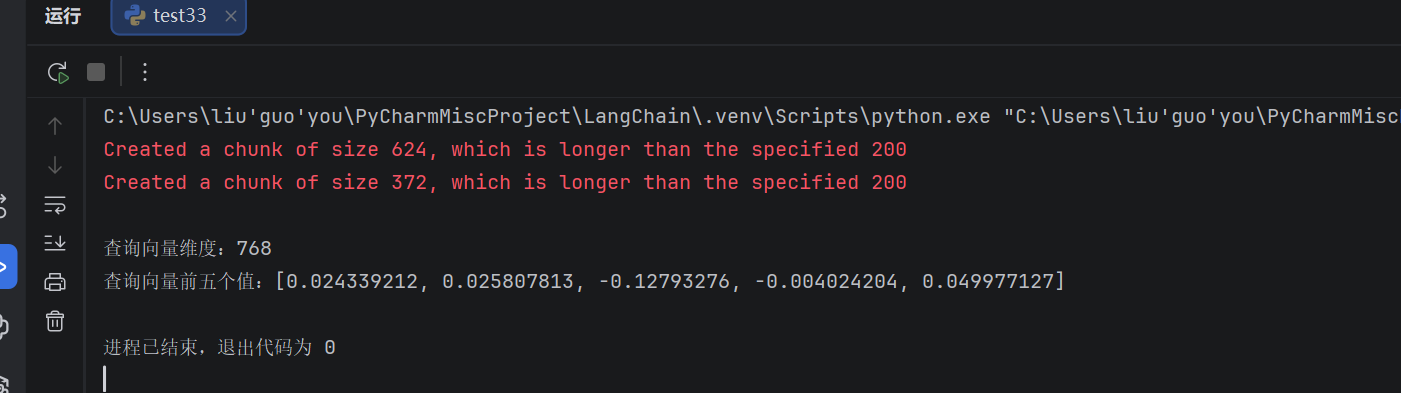
query_vector = embeddings.embed_query("### WEBSOCKET通信:")
print(f"\n查询向量维度:{len(query_vector)}")
print(f"查询向量前五个值:{query_vector[:5]}")
二者区别一目了然:
# embed_documents:多文本 → 二维列表
embeddings.embed_documents(["文本1", "文本2", "文本3"]) 我们代码里传的一个遍历结果text,其本质是一样的
# → [[0.1, 0.2, ...], [0.3, 0.4, ...], [0.5, 0.6, ...]]# embed_query:单文本 → 一维列表
embeddings.embed_query("一个问题")
# → [0.1, 0.2, 0.3, ...]
之前写过的 test25/test26 中:
OllamaEmbeddings(model="nomic-embed-text")
这就是一个嵌入模型。SemanticSimilarityExampleSelector 内部就是用它把示例转成向量,再计算余弦相似度来挑选的。
"happy" ──[nomic-embed-text]──▶ [0.12, -0.34, ...]
"worried" ──[nomic-embed-text]──▶ [0.09, -0.38, ...]
余弦相似度 → 0.95(看作同一类→情绪词)
import sys
import numpy as np
from langchain_ollama import OllamaEmbeddings
sys.stdout.reconfigure(encoding="utf-8")
# 1. 定义嵌入模型(本地免费,768维向量)
embeddings = OllamaEmbeddings(model="nomic-embed-text")
# 2. 把文字分别转成向量
# embed_query:单个文本 → 一维列表(768个浮点数)
vec_happy = embeddings.embed_query("happy")
vec_worried = embeddings.embed_query("worried")
vec_tall = embeddings.embed_query("tall")
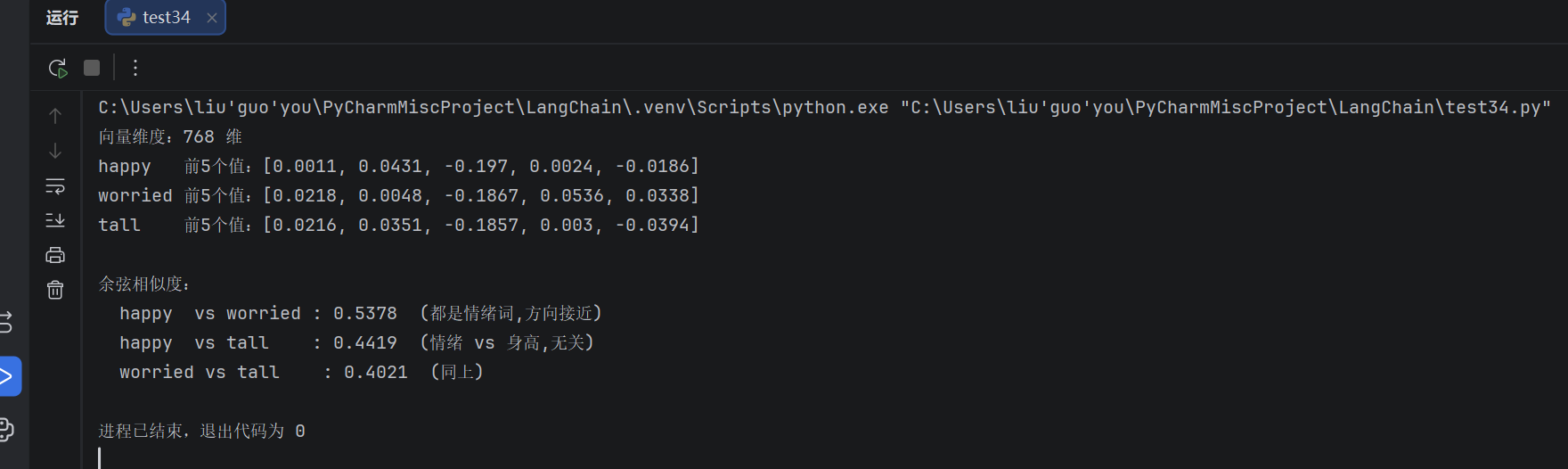
print(f"向量维度:{len(vec_happy)} 维")
print(f"happy 前5个值:{[round(v, 4) for v in vec_happy[:5]]}")
print(f"worried 前5个值:{[round(v, 4) for v in vec_worried[:5]]}")
print(f"tall 前5个值:{[round(v, 4) for v in vec_tall[:5]]}")
# 3. 计算余弦相似度
def cosine_similarity(a, b):
"""余弦相似度 = 两个向量夹角的余弦值。
1.0 = 方向完全相同(语义最接近)
0.0 = 方向垂直(语义无关)
-1.0 = 方向完全相反
为什么不用欧氏距离?
"happy" → 向量短
"happy happy" → 向量长,但方向相同
余弦只看方向,不看长度 → 正确判断为语义相同"""
a = np.array(a)
b = np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
sim_happy_worried = cosine_similarity(vec_happy, vec_worried)
sim_happy_tall = cosine_similarity(vec_happy, vec_tall)
sim_worried_tall = cosine_similarity(vec_worried, vec_tall)
print(f"\n余弦相似度:")
print(f" happy vs worried : {sim_happy_worried:.4f} (都是情绪词,方向接近)")
print(f" happy vs tall : {sim_happy_tall:.4f} (情绪 vs 身高,无关)")
print(f" worried vs tall : {sim_worried_tall:.4f} (同上)")
ok,终于写完了,继续学习向量存储,

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)