机器学习概述:从概念到建模流程
机器学习概述:从概念到建模流程
机器学习概述
知识导图
机器学习概述
├─ 三大概念:AI(仿人类智能)→ ML(自动学习)→ DL(深度神经网络)
├─ 学习方式:基于规则(if-else) vs 基于模型(从数据学规律)
├─ 核心术语:样本、特征、标签、训练集、测试集
├─ 算法分类:监督/无监督/半监督/强化学习
├─ 建模流程:获取数据→数据处理→特征工程→模型训练→评估→上线
├─ 特征工程:提取、预处理、降维、选择、组合
├─ 模型拟合:欠拟合(太简单)、过拟合(太复杂)、泛化能力
└─ 开发环境:scikit-learn 工具库
1 人工智能三大概念
名词解释
人工智能(AI)
让机器模仿人类智能,使计算机像人一样思考、学习、决策。
机器学习(ML)
让计算机自动从数据中学习规律,无需人工显式编程规则。
深度学习(DL)
机器学习的一个分支,模拟大脑神经元结构,用多层神经网络学习复杂特征。
三者关系
-
机器学习是实现人工智能的途径
-
深度学习是机器学习的一种方法
2 两种学习方式(对比辨析)
2.1 基于规则的学习
-
人工编写 if-else 规则
-
适合规则明确的场景
-
缺点:复杂问题(图像、语音)无法写规则
2.2 基于模型的学习
-
从数据中自动学习规律
-
模型:如线性方程 y = ax + b
-
适合复杂任务:图像、语音、NLP(Natural Language Processing 自然语言处理)

对比表
| 方式 | 原理 | 适用场景 | 复杂度 |
|---|---|---|---|
| 规则学习 | 人工 if-else | 简单明确规则 | 低 |
| 模型学习 | 数据自动归纳 | 图像 / 语音 / 预测 | 高 |
3 机器学习应用领域
-
计算机视觉(CV):图像识别、无人驾驶
-
自然语言处理(NLP):智能翻译、对话
-
数据挖掘、医疗诊断、金融预测
4 机器学习发展史
-
1956:达特茅斯会议 → AI 元年
-
1997:深蓝战胜卡斯帕罗夫
-
2012:AlexNet → 深度学习兴起
-
2016:Google AlphaGO 战胜李世石(人工智能第三次浪潮)
-
2017:自然语言处理NLP的Transformer框架出现
-
2022:ChatGPT → AIGC 时代 ( Artificial Intelligence Generated Content 人工智能生成式内容)
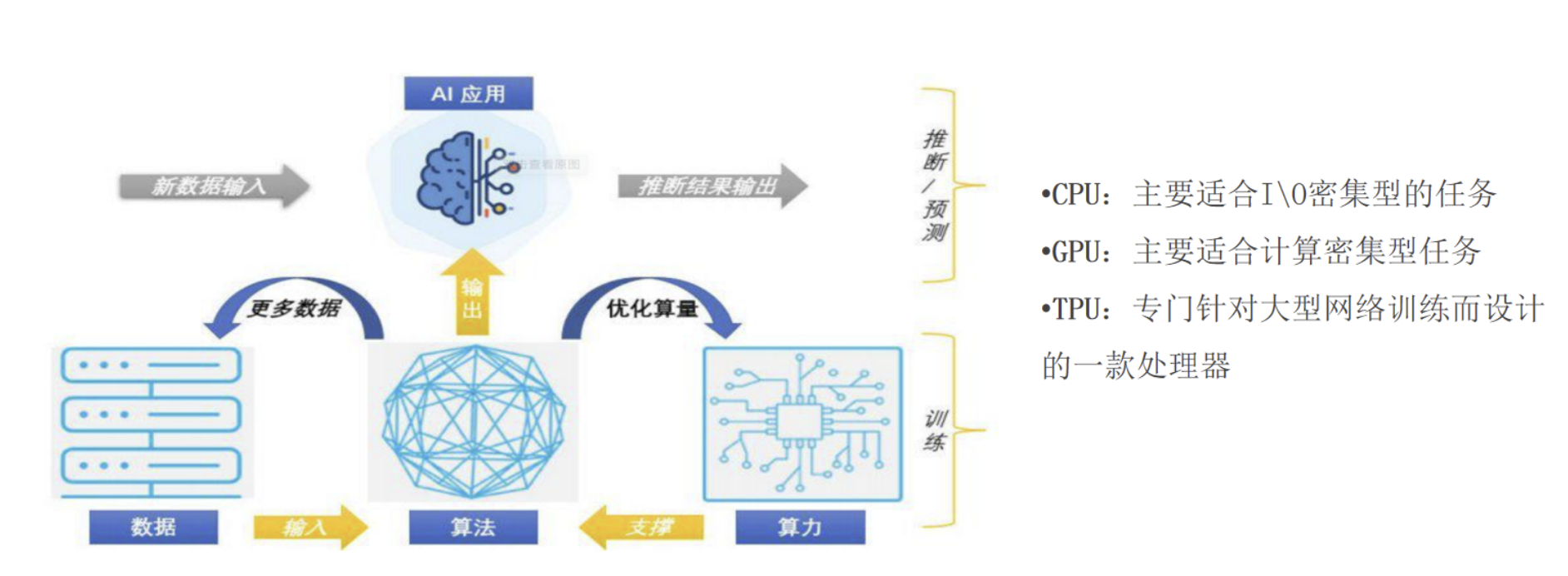
5 AI 发展三要素
数据、算法、算力
-
CPU:I/O 密集型
-
GPU:计算密集型
-
TPU:专为大模型训练设计
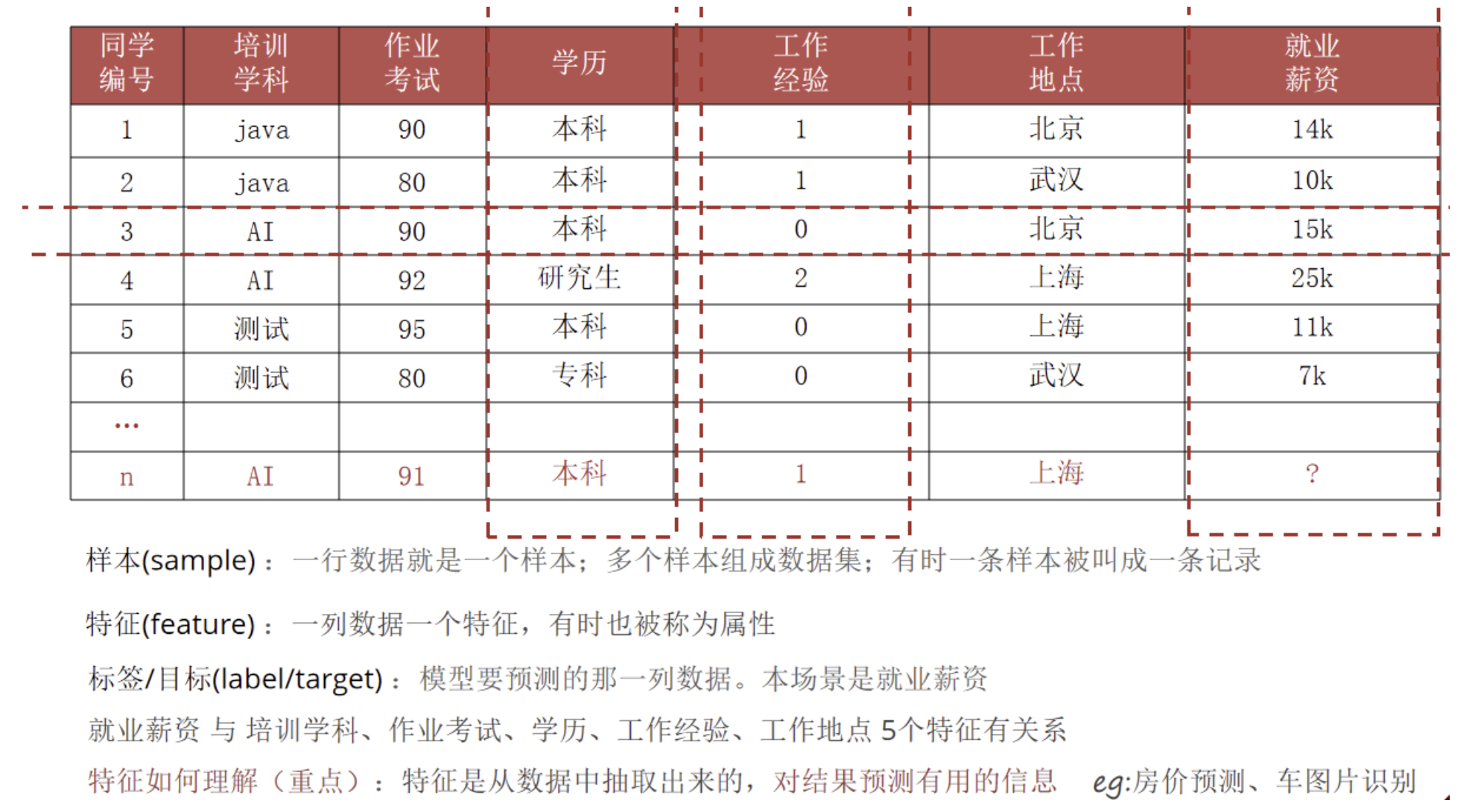
6 机器学习核心术语
名词解释
样本(sample):一行数据,一条记录
特征(feature):一列属性,用于预测的信息
标签(label/target):要预测的目标值
训练集(train):训练模型
测试集(test):评估模型
7 机器学习算法分类(对比辨析)
7.1 监督学习(有标签)
-
分类:预测离散值(好瓜 / 坏瓜)
-
回归:预测连续值(房价、薪资)
7.2 无监督学习(无标签)
-
聚类:按相似度自动分组
-
目标:发现数据内部结构
7.3 半监督学习
-
少量有标签 + 大量无标签
-
降低标注成本
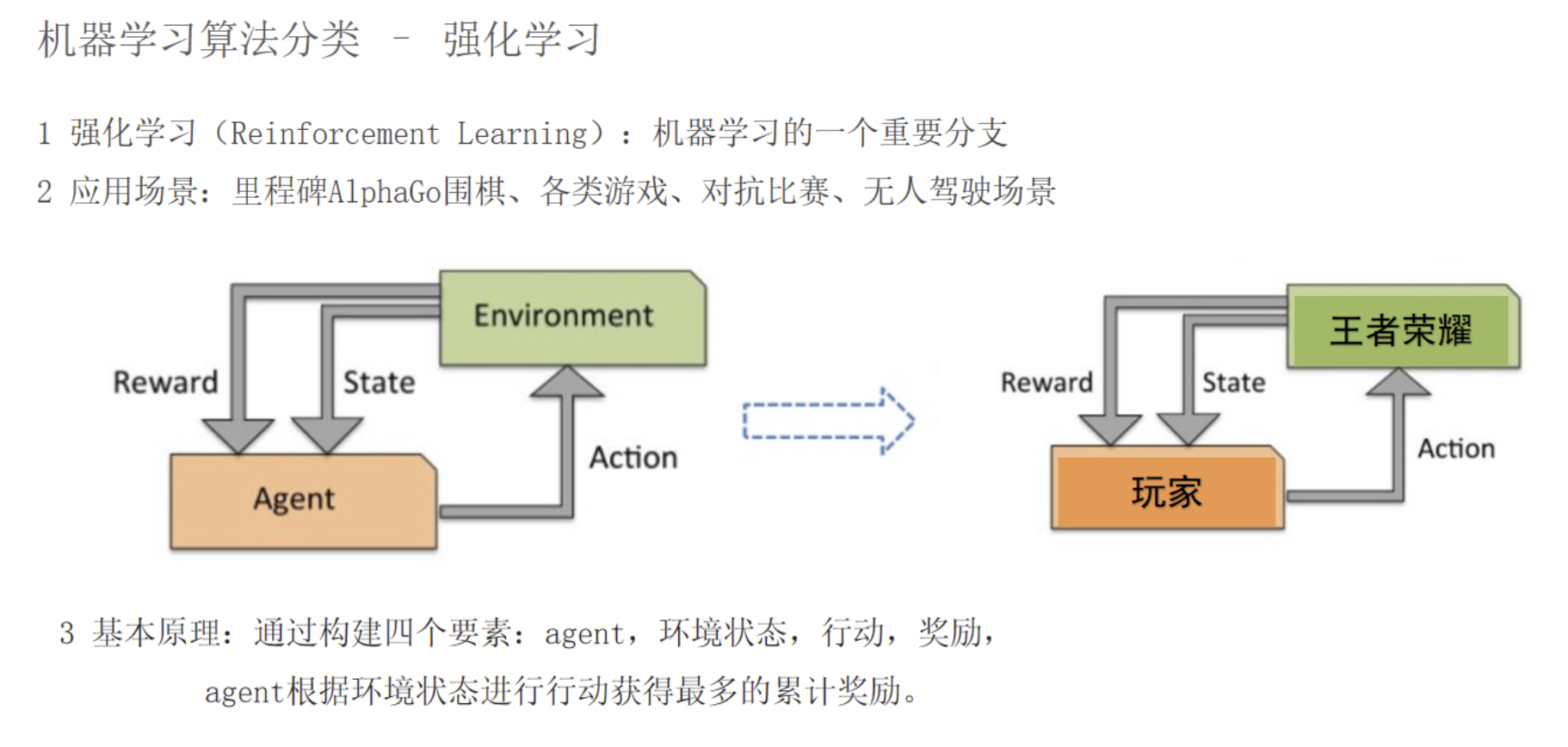
7.4 强化学习
-
智能体 + 环境 + 动作 + 奖励
-
目标:长期收益最大化(AlphaGo、游戏)
对比表
| 类型 | 数据 | 目标 | 例子 |
|---|---|---|---|
| 监督学习 | 有标签 | 预测 | 分类 / 回归 |
| 无监督 | 无标签 | 分组 | 聚类 |
| 半监督 | 部分标签 | 低成本学习 | 文本分类 |
| 强化学习 | 交互数据 | 最大奖励 | 游戏、机器人 |
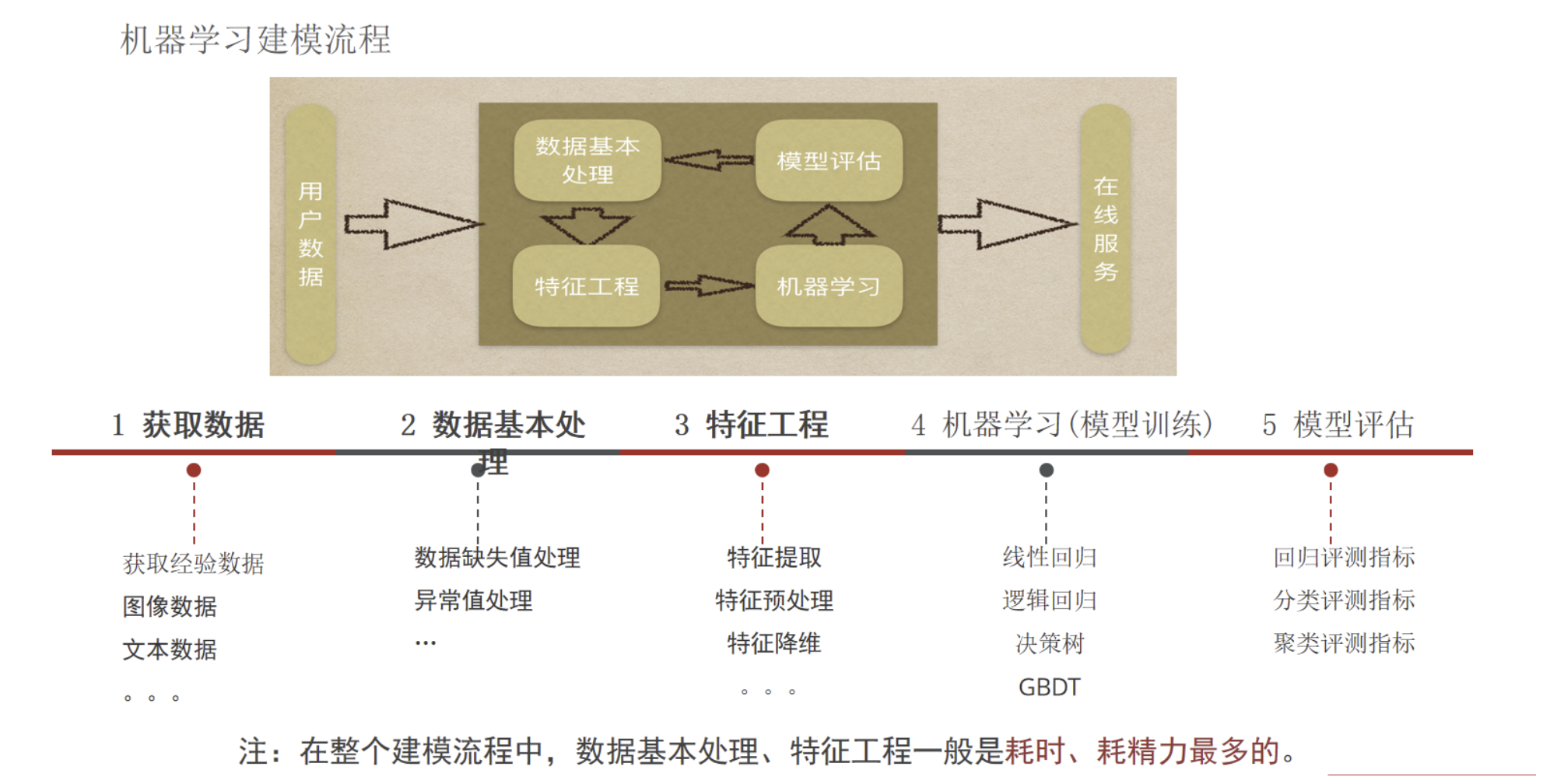
8 机器学习建模流程
-
获取数据
-
数据基本处理(缺失值、异常值)
-
特征工程
-
模型训练
-
模型评估
-
在线服务 / 预测
9 特征工程(核心)
名词解释
特征工程:用专业方法处理数据,让模型效果最优。
数据和特征决定上限,模型只逼近上限。
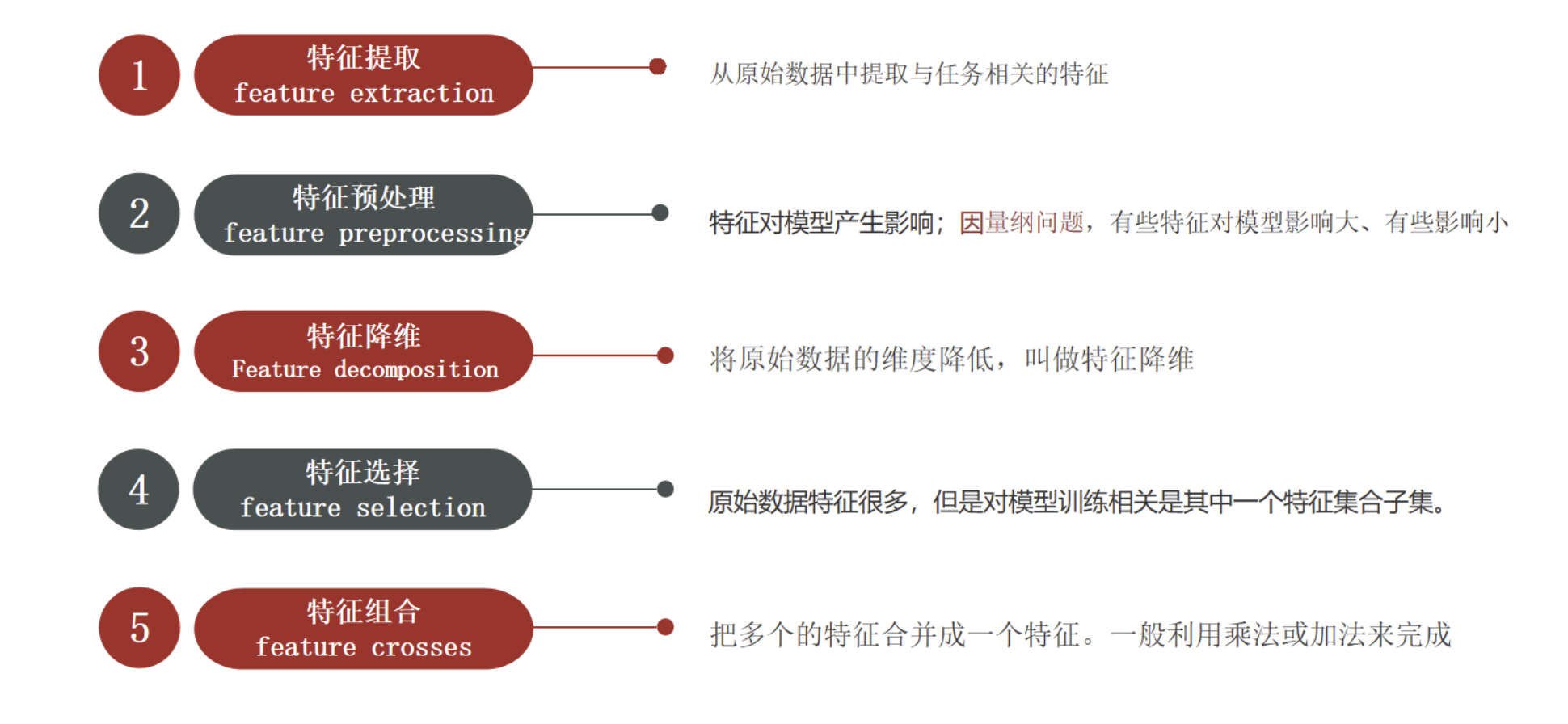
五大子领域
-
特征提取:从原始数据抽取有效信息
-
特征预处理:归一化、标准化
-
特征降维:减少特征数量,保留主要信息
-
特征选择:挑选重要特征,不修改原数据
-
特征组合:多特征合并(相乘 / 相加)
10 模型拟合问题
名词解释
拟合:模型对数据的模拟程度
泛化能力:模型在新数据上的表现
奥卡姆剃刀原则:给定两个具有相同泛化误差的模型,倾向选择较简单的模型
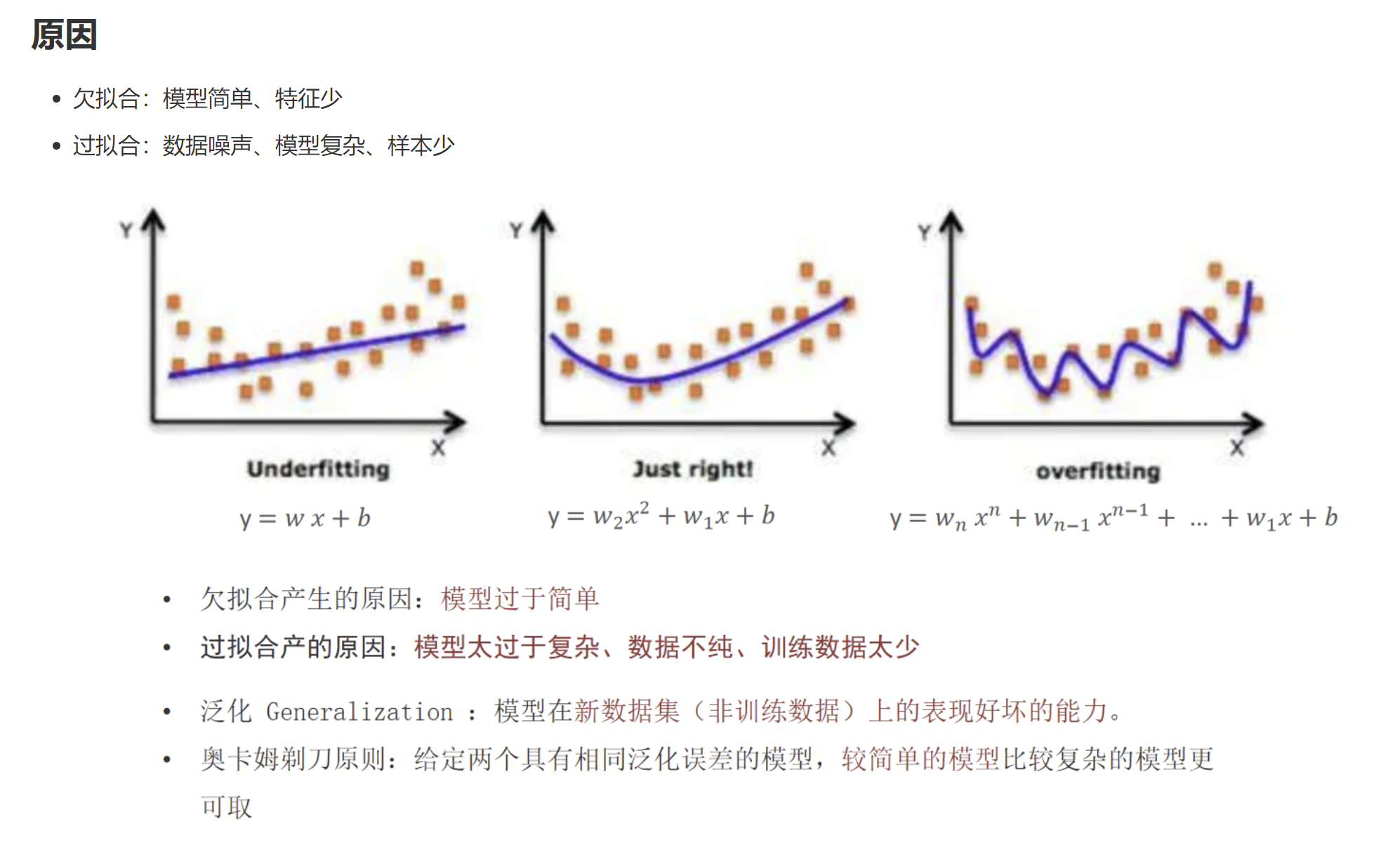
1. 欠拟合(under-fitting)
-
模型太简单
-
训练集差、测试集差
2. 过拟合(over-fitting)
-
模型太复杂
-
训练集极好、测试集极差
原因
-
欠拟合:模型简单、特征少
-
过拟合:数据噪声、模型复杂、样本少
11 机器学习开发环境
scikit-learn
-
Python 机器学习库
-
基于 NumPy、SciPy、matplotlib
-
简单高效、开源免费
安装:
pip install scikit-learn
12 核心知识点总结
-
AI → ML → DL 是包含关系
-
学习方式分:规则学习、模型学习
-
核心术语:样本、特征、标签、训练集 / 测试集
-
四大算法:监督、无监督、半监督、强化学习
-
建模六步:数据→处理→特征→训练→评估→上线
-
特征工程决定模型上限
-
欠拟合(太简单)、过拟合(太复杂)
-
开发工具:scikit-learn
AI → ML → DL 是包含关系
本质:从大到小的 “套娃” 层级
-
AI(人工智能):最大的概念,目标是让机器模拟人类智能(包括推理、感知、学习等)。
-
ML(机器学习):AI 的一个分支,核心是让机器从数据中自动学习规律,而不是靠人工写死规则。
-
DL(深度学习):ML 的一个子集,用多层神经网络自动学习特征,是现在 AI 的主流技术(比如大模型、CV、NLP 都用它)。
一句话记: AI 是目标,ML 是方法,DL 是实现 ML 的热门技术。
学习方式分:规则学习、模型学习
本质:机器 “怎么学会做事” 的两种思路
-
规则学习(传统方式):人工写死规则,比如 “如果邮件包含‘中奖’,就判定为垃圾邮件”。优点是简单透明,缺点是规则复杂时写不完、覆盖不全。
-
模型学习(机器学习):给机器大量数据,让它自己学规律,比如用 KNN / 逻辑回归自动判断垃圾邮件。优点是能处理复杂场景,缺点是需要数据、结果可能不透明。
一句话记: 规则学习是 “人教它怎么做”,模型学习是 “它自己从数据里学怎么做”。
核心术语:样本、特征、标签、训练集 / 测试集
本质:机器学习的 “基本零件”,必须分清
易错点: 测试集只能用来评估模型效果,绝对不能用测试集调参,否则会导致过拟合。
四大算法:监督、无监督、半监督、强化学习
本质:根据数据是否带标签、学习目标不同的分类
-
监督学习:数据有标签,模型学 “输入→输出” 的映射。比如分类(猫狗识别)、回归(房价预测)。
-
无监督学习:数据无标签,模型自己找规律。比如聚类(客户分群)、降维(PCA)。
-
半监督学习:大部分数据无标签,少量有标签,结合两者优点。比如用少量标注数据 + 大量无标注数据训练模型。
-
强化学习:模型通过和环境交互,靠 “奖励 / 惩罚” 学最优策略。比如 AlphaGo、游戏 AI、机器人控制。
一句话记: 监督是 “带答案做题”,无监督是 “自己找规律”,半监督是 “半带答案半自学”,强化学习是 “靠奖惩试错学”。
建模六步:数据→处理→特征→训练→评估→上线
本质:机器学习项目的完整流水线,按顺序执行
-
数据获取:收集业务数据(比如用户行为、业务日志)。
-
数据处理:清洗数据(去重、补缺失值、处理异常值)。
-
特征工程:把原始数据转成模型能用的特征(比如文本转词向量、类别编码)。
-
模型训练:选算法(KNN / 随机森林 / 神经网络),用训练集拟合模型。
-
模型评估:用测试集看效果(准确率、MAE 等),调参优化。
-
模型上线:把模型部署到生产环境,提供预测服务。
关键考点: 特征工程和数据处理占项目 80% 的工作量,模型训练只占 20%。
特征工程决定模型上限
本质:数据和特征决定了模型的天花板,算法只是在逼近这个上限
-
再好的算法,用垃圾特征也做不出好效果;而好的特征,用简单的算法也能出好结果。
-
比如预测房价,“地段、学区、地铁距离” 这些高质量特征,比用复杂的深度学习模型更重要。
-
特征工程包括:特征选择、特征构造、特征变换(标准化 / 归一化)、特征降维。
一句话记: 数据和特征是 “地基”,算法是 “房子”,地基差,房子再豪华也不牢。
欠拟合(太简单)、过拟合(太复杂)
本质:模型在训练集和测试集上的表现失衡,是调参的核心问题
-
欠拟合:模型太简单,连训练集的规律都没学会,训练集和测试集效果都差。比如用线性回归拟合非线性数据。解决:增加模型复杂度(比如换随机森林)、增加特征。
-
过拟合:模型太复杂,把训练集的噪声也当成规律学了,训练集效果极好,测试集效果极差。比如 KNN 中 K=1,完全跟着训练数据走,泛化能力差。解决:降低模型复杂度(增大 K 值)、正则化、增加数据量、交叉验证。
一句话记: 欠拟合是 “没学会”,过拟合是 “学歪了,只会死记硬背训练题”。
开发工具:scikit-learn
本质:Python 中最主流的传统机器学习库,简单高效、开箱即用
-
核心功能:
-
分类 / 回归 / 聚类 / 降维等算法实现(比如 KNN、SVM、随机森林)。
-
数据预处理(标准化、编码、拆分训练 / 测试集)。
-
模型调优(网格搜索、交叉验证)。
-
-
适用场景:中小规模数据、传统机器学习任务(非深度学习),是入门学习和工业界原型开发的首选。
一句话记: scikit-learn 是传统机器学习的 “瑞士军刀”,所有基础算法和工具都集成好了。
🔗 知识点串联总结
这些知识点是一个完整的体系:AI的目标 → 用ML的方法实现 → 按数据类型选学习方式(监督/无监督等) → 按流水线建模(数据→特征→训练→评估) → 重点关注特征工程和过拟合/欠拟合问题 → 用scikit\-learn工具落地
(注:文档部分内容可能由 AI 生成)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)