RAG 检索增强生成
L3.1 RAG 检索增强生成
目标:不只是"会用 RAG",而是理解每个环节的为什么,能在生产环境做正确取舍。
前置认知:什么时候该用 RAG?
RAG 不是银弹,先搞清楚它解决什么、不解决什么。
|
场景 |
方案 |
|
LLM 答非所问、知识胡编 |
✅ RAG |
|
通用知识(常识、百科) |
❌ 不需要 RAG,LLM 本身知道 |
|
需要最新信息(新闻、价格) |
✅ RAG(实时检索) |
|
私有制度/文档/流程 |
✅ RAG |
|
需要 LLM 学会某种写作风格 |
❌ 微调 Fine-tuning |
|
结构化数据查询(订单、库存) |
❌ SQL / API |
Java 类比:RAG = 数据库索引查资料,不是微调 = 训练新算法。
一、整体架构全景
┌─────────────────────────────────────┐
│ RAG 全景图 │
└────────────────┬────────────────────┘
│
┌───────────────────────────┼───────────────────────────┐
│ │ │
┌────▼─────┐ ┌──────▼──────┐ ┌─────▼─────┐
│ Ingest │ │ Query │ │ LLM │
│ │ │ │ │ 生成 │
└────┬─────┘ └──────┬──────┘ └─────┬─────┘
│ │ │
▼ ▼ │
┌─────────┐ ┌──────────┐ │
│Chunking │ ┌─────────┐ │Embedding│◄──────────用户问题 │
│切分 │ │Embedding│ │向量化 │ │
└────┬────┘ │向量化 │ └────┬────┘ │
│ └────┬────┘ │ │
▼ ▼ ▼ │
┌──────────┐ ┌──────────┐ ┌──────────┐ │
│向量数据库│ │向量数据库│ │向量检索 │◄──── Top-K │
│ 存储 │ │ 存储 │ │排序结果 │ │
└─────────┘ └─────────┘ └────┬─────┘ │
│ ┌──────────▼────┐
┌────▼────┐ │ 拼装Prompt │
│Rerank │ │ LLM生成回答 │
│重排序 │ └───────────────┘
└────┬────┘
│
┌────▼────┐
│混合检 │
│索/查询 │ ← 进阶技巧
│改写 │
└────────┘Java 三层架构对照:
- Ingest ≈ DAO 层(数据入库)
- Query ≈ Service 层(业务编排)
- LLM 生成 ≈ Controller 层(结果输出)
二、Chunking — 切分的艺术
2.1 为什么必须切分?
LLM Context 有上限(4K~128K tokens),而且 Token 上限 ≠ 有效输入:
- 系统 Prompt 占 ~500-1000 tokens
- 对话历史占 ~N tokens
- 留给上下文的只剩下一部分
一本 300 页的 PDF 直接塞进去?Token 爆了。
2.2 切分策略对比
|
策略 |
原理 |
优点 |
缺点 |
|
固定字符 |
每 N 字符一切,用重叠衔接 |
简单稳定 |
可能切断句子/语义单元 |
|
滑动窗口重叠 |
窗口大小 W,重叠 O |
相邻块有上下文连贯性 |
存储膨胀(~W/(W-O)倍) |
|
语义段落 |
用 NLP 识别句子/段落边界 |
语义完整 |
实现复杂,效果不一定更好 |
|
递归字符 |
按 → → 句子 优先级降级切分 |
最常用,符合语义 |
需要调参 |
|
文档结构感知 |
Markdown/HTML 标题层级 |
保留标题层级信息 |
依赖文档格式 |
实用推荐:固定字符 500~1000 + 重叠 50~100,是大多数场景的稳健起点。
2.3 重叠为什么是必要的?
块1: [0:500] "本文介绍了Spring Boot的虚拟线程特性..."
块2: [400:900] "虚拟线程是Java 21引入的轻量级线程..." ← 块1末尾和块2开头重叠如果用 | 分隔,没有重叠:
块1: "本文介绍了Spring Boot的虚拟线程特性...(在第500字处切断)"
块2: "JVM调度而非OS调度..." ← "JVM调度"指什么?丢失了主语Java 类比:数据库跨页查询时,LIMIT 500 OFFSET 0 的结果和 LIMIT 500 OFFSET 500 的结果断在半句,JOIN 时需要靠 ORDER BY 和重叠索引字段对齐。RAG 的重叠就是防止段落的语义在边界处被切断。
2.4 Chunk size 怎么选?
|
使用场景 |
推荐 Chunk Size |
理由 |
|
问答(精准) |
200~500 字 |
问题短,相关段落也短,精确匹配 |
|
摘要生成 |
1000~2000 字 |
需要足够上下文 |
|
多跳推理 |
500~800 字 |
中等大小,保留逻辑链 |
经验法则:先设为 500,上线后根据 Recall 调整。
三、Embedding — 向量化的深度原理
3.1 直观理解:Embedding 是什么?
Embedding 本质是把文字映射到向量空间,让语义相近的内容在空间中距离近。
文字: "如何开通云服务器"
↓ Embedding 模型
向量: [ 0.12, -0.34, 0.78, -0.21, ...] (N维)
相似问题: "购买CVM实例的步骤"
向量: [ 0.11, -0.33, 0.79, -0.20, ...] ← 距离近 ↑
无关问题: "今天吃什么"
向量: [-0.45, 0.22, -0.11, 0.33, ...] ← 距离远 ↓3.2 Embedding 模型是怎么训练的?
训练目标是让正样本(同义句对)距离近,负样本(无关句对)距离远:
loss = max(0, 负样本距离 - 正样本距离 + margin)训练数据:大量 (query, document) pairs,比如搜索点击日志。
3.3 关键参数:归一化
embeddings = model.encode(text, normalize_embeddings=True)为什么要归一化? 归一化后,余弦相似度 = 向量内积。计算从 cos(θ) = A·B/(|A||B|) 简化成 A·B,快很多且数值稳定。
3.4 中文 Embedding 模型选型
|
模型 |
维度 |
特点 |
适用场景 |
|
|
512 |
CPU 可跑,推理快(~50ms/条) |
优先选,性价比最高 |
|
|
1536 |
OpenAI API,通用好 |
需要调用 API 时 |
|
|
768 |
中文优化,开源可本地 |
中文场景生产可用 |
|
|
1024 |
精度更高,推理慢 |
精度优先场景 |
Java 类比:Embedding 模型 = 消息摘要算法(MD5/SHA-256),但输出是 N 维浮点向量而不是固定哈希值。bge-small ≈ 轻量级摘要算法,快但精度有限。
四、向量检索 — 索引的深度原理
4.1 为什么不能暴力检索?
假设知识库有 100 万条 Chunk,每条 512 维向量:
100万 × 512 维 × 4字节(float) = 2GB 内存
每条检索需要做 100万 次向量点积运算 → ~几秒/次查询 ❌必须用**近似最近邻(ANN)**索引。
4.2 主流 ANN 算法
HNSW(Hierarchical Navigable Small World)
原理:多层图结构,上层稀疏、下层密集,搜索从顶层最快定位近邻区域。
层3: A ─── B ─── C ← 最稀疏,相隔最远
│
层2: D ──[A]── E ─── F ← 中层
│
层1: G ──[D]── H ──[E]── I ← 最密集,所有邻居优势:近似 O(log N) 搜索速度,精度高(~95%+ recall)。
缺点:内存占用大,建索引慢。
Java 类比:HNSW = 跳表(Skip List)的多层级思想,上层快速缩小范围,下层精确定位。类似数据库的 B+Tree 根节点 → 中间节点 → 叶节点的层次结构。
IVF(Inverted File Index)
原理:先对向量做 K-Means 聚类,搜索时只扫描最近的 K 个聚类中心。
聚类1: [向量1, 向量2, 向量3, ...] ← "云计算"相关
聚类2: [向量4, 向量5, 向量6, ...] ← "数据库"相关
聚类3: [向量7, 向量8, 向量9, ...] ← "网络"相关搜索"云服务器"→ 只需扫描聚类1,不用扫全部 100 万。
HNSW + IVF 组合:工业级向量库(ChromaDB/FAISS)的默认配置。
4.3 相似度:余弦 vs 点积 vs L2
|
度量 |
公式 |
适用场景 |
前提 |
|
余弦相似度 |
cos(θ) = A·B/|A||B| |
语义相似度(长度无关) |
归一化后 = 内积 |
|
点积(内积) |
A·B = Σaᵢbᵢ |
未归一化的向量 |
必须先归一化 |
|
L2 欧氏距离 |
√Σ(aᵢ-bᵢ)² |
距离敏感任务 |
受向量长度影响 |
实际工程结论:
- 用 Embedding 模型默认的归一化 + 余弦相似度(等价于内积)
- 除非你有特殊理由,否则不要用 L2 距离
五、Rerank — 重排序的深度原理
5.1 为什么向量检索结果需要重排?
向量检索找的是语义最接近的 K 个,但 RAG 最终只要 3~5 个塞进 Prompt。
问题在于:Top-5 可能内容高度重叠,都在讨论同一件事,Context 冗余。
5.2 MMR 算法(Maximal Marginal Relevance)
MMR 在相关性和多样性之间做权衡:
def mmr(query_vec, candidates, selected, lambda_param=0.7):
mmr_scores = []
for chunk, score in candidates:
relevance = score
redundancy = max(
cosine_sim(chunk.vec, sel.vec) for sel in selected
) if selected else 0
mmr = lambda_param * relevance - (1 - lambda_param) * redundancy
mmr_scores.append(mmr)
return candidates[argmax(mmr_scores)]λ 调参建议:
- λ=0.9:相关性优先,多样性几乎不考虑
- λ=0.7:平衡(生产默认)
- λ=0.5:多样性优先,适合文档检索而非问答
5.3 Cross-Encoder Rerank(更强的方案)
比向量检索更精确的二次排序:
向量检索(Bi Encoder): question → q_vec → 一遍内积排序 → Top-50
Cross Encoder Rerank : question + doc → 一起过 Transformer → 更精确的 0~1 得分 → Top-5原理:Bi-Encoder 分别 encode query 和 doc,Cross-Encoder 把 query+doc 拼接后一起 encode,能捕获更细粒度的交互信息。
Java 类比:
- Bi-Encoder = 索引时直接用分词权重(词频 TF),快但粗糙
- Cross-Encoder Rerank = 用户搜索后再用 Learning to Rank 模型(如 LambdaMART)精排
六、混合检索 — 稀疏 + 稠密双管齐下
6.1 单一检索的问题
|
检索方式 |
原理 |
擅长 |
不擅长 |
|
向量检索(稠密) |
语义匹配 |
同义改写、口语化查询 |
精确术语、ID exact match |
|
关键词检索(稀疏) |
BM25 / TF-IDF |
精确词匹配、专业术语 |
语义相关但词不同 |
6.2 混合检索 = 并行执行 + 融合
# Step 1: 并行执行
dense_results = vector_store.search(q_vec, top_k=20) # 语义检索
sparse_results = bm25_engine.search(query, top_k=20) # 关键词检索
# Step 2: RRF 融合(Reciprocal Rank Fusion)
# 每条结果根据排名给分,第一名10分,第二名9分... 最后求和
scores = {}
for rank, (chunk, _) in enumerate(dense_results):
scores[chunk.id] = scores.get(chunk.id, 0) + 1 / (60 + rank)
for rank, chunk in enumerate(sparse_results):
scores[chunk.id] = scores.get(chunk.id, 0) + 1 / (60 + rank)
final_ranked = sorted(scores.items(), key=lambda x: x[1], reverse=True)RRF 公式:score = Σ 1 / (k + rank),k=60 是平滑因子。
Java 类比:搜索引擎的「综合排序」,向量检索 ≈ PageRank,BM25 ≈ TF-IDF,最后用机器学习模型融合两个信号。
七、查询改写 — 让口语匹配文档
7.1 问题:用户问法和文档写法不一致
用户问:“怎么买服务器”
文档写:“CVM云服务器购买流程”
直接检索可能匹配不上。
7.2 HyDE(Hypothetical Document Embeddings)
# Step 1: 让 LLM 基于问题生成一个"假设答案"
hypo_doc = llm.generate(f"假设你是文档作者,请写一段回答:{question}")
# Step 2: 用假设答案去检索,而不是原问题
hypo_results = store.search(embed(hypo_doc), top_k=5)
# Step 3: 结合原始问题一起检
combined_results = fuse(hypo_results, vector_store.search(embed(question)))原理:LLM 生成的假设答案在向量空间里更接近真实文档。
八、评估 — RAG 系统质量度量
8.1 RAG 三元指标(RAGAs 框架)
|
指标 |
含义 |
评估方式 |
|
Faithfulness |
回答是否忠实于检索内容 |
LLM 判断生成内容与上下文的一致性 |
|
Answer Relevancy |
回答与问题的相关度 |
LLM 判断回答是否切题 |
|
Context Precision |
Top-K 上下文的精准度 |
每条相关文档是否在 Top-K 中 |
8.2 端到端评估:RAGTriad
┌─────────────┐
Question ─────►│ Retrieve │──── Chunks ────►│ Generate │──── Answer
└─────────────┘ └──────────────┘
│ │
Precision@K │ Correctness / Hallucination
Recall@K │ Faithfulness核心链路:检索质量 × 生成质量 = 最终效果。
8.3 常见失败模式及诊断
|
失败现象 |
根因 |
解决方向 |
|
答案胡编(幻觉) |
检索到的文档质量差或 Prompt 没说"不知道就说不知道" |
提高检索精度,优化 Chunking |
|
答案太短/没答到点 |
检索到的文档本身不含答案 |
扩充知识库,或用 HyDE 改写查询 |
|
相邻轮次答案矛盾 |
上下文窗口太小,历史被截断 |
增大窗口或接入历史摘要 |
|
精确术语查不到 |
向量检索无法 exact match |
加 BM25 关键词检索(混合检索) |
要点回顾
RAG = Ingest(切分→向量化→入库) + Query(检索→重排→生成)
Chunking: 固定500+重叠100是稳健起点
Embedding: bge-small-zh-v1.5 (512维, CPU可跑) 优先
向量检索: HNSW索引,余弦相似度(归一化后=内积)
Rerank: MMR平衡相关性与多样性,或Cross-Encoder二次精排
混合检索: 向量+BM25双路并行,RRF融合
评估: Faithfulness + Answer Relevancy + Context Precision思考题(3道)
- 知识库有 1000 万条文档,Chunk size 500 字,RAG 系统延迟高,你怀疑向量检索慢,你的第一步诊断是什么?用什么指标判断?
- 公司有一份 500 页的技术规范 PDF,你想让 LLM 能回答"这个规范里 X 流程怎么走",但每次问都说不知道。请列出至少 3 个可能的失败环节(从 Ingest 到 Query 的全链路)。
- "余弦相似度"和"向量内积"在 Embedding 归一化后等价,为什么?数学上给出一个简短推导。
(思考)...
(思考)...
(思考)...
(思考)...
(思考)...
(思考)...
(思考)...
(思考)...
思考题答案
第1题:10亿文档 + 高延迟,第一步诊断什么?
核心原则:先定位瓶颈在哪,再针对性优化。别猜,要量化。
诊断步骤
Step 1: 打日志分段计时,拆解各环节耗时def ask(question):
t0 = time.time()
q_vec = embedder.embed(question) # Embedding
t1 = time.time()
raw_results = store.search(q_vec, top_k=20) # 向量检索
t2 = time.time()
reranked = reranker.rerank(q_vec, raw_results, top_k=3) # Rerank
t3 = time.time()
answer = llm_generate(question, reranked) # LLM 生成
t4 = time.time()
print(f"各环节耗时: embed={t1-t0:.0f}ms search={t2-t1:.0f}ms "
f"rerank={t3-t2:.0f}ms llm={t4-t3:.0f}ms")
return answer关键指标
|
指标 |
含义 |
正常值 |
说明 |
|
Search QPS |
每秒检索次数 |
- |
超过索引承载上限会炸 |
|
Recall@K |
Top-K 结果中相关文档的比例 |
>0.85 |
<0.7 说明检索质量差,LLM 自然答不上 |
|
P99 Latency |
99%请求的延迟 |
<500ms |
关注尾部延迟,不是平均值 |
|
Index Size / Memory |
索引占用内存 vs 机器内存 |
<70% |
超过会OOM或swap,延迟暴涨 |
实战技巧
怀疑检索慢 → 看 search time 是 1ms 还是 100ms
如果是 100ms+:
→ 检查向量维度(512 vs 1024)和索引类型(HNSW/IVF参数)
→ 检查是否发生磁盘交换(top / free 查看)
→ 检查 CPU 负载(向量化运算吃 CPU)
如果是 LLM 占了 90% 时间:
→ 优化 Prompt 长度(减少 context tokens)
→ 换更快的模型或加缓存Java 类比:数据库慢查询,先看 EXPLAIN 执行计划。RAG 的 EXPLAIN 就是分段日志:Embedding 是"解析 SQL",向量检索是"索引扫描",Rerank 是"排序",LLM 是"结果返回"。
第2题:500页PDF,LLM总说不知道,列出3个以上失败环节
全链路逐一排查:
环节1:Ingest — 文档根本没成功入库
症状:搜索任何关键词都返回空
# 自查
store_size = len(vector_store)
print(f"知识库 chunk 数量: {store_size}")
# 如果是 0 → Ingest 环节出问题
# 可能原因:
# 1. PDF 解析失败(PyMuPDF 未安装)
# 2. 空文档(全是图片没有文字)
# 3. Chunk 后全部被过滤(内容太短)环节2:Ingest — Chunking 切太碎,上下文丢失
症状:知识库有数据,但查不到
500页 PDF ≈ 20万字,按 chunk_size=500 切 → 400 个 chunk。
如果"X流程怎么走"这个答案跨了 3 页,而每个 chunk 只有 500 字:
Chunk 47: "第一步:登录系统...(在第47页末尾被切断)"
Chunk 48: "进入流程配置页面...(第48页开头,丢失了上下文)"检索时 Chunk 47 和 Chunk 48 单独看都不完整,LLM 拿到的是残缺的流程描述。
修复方向:
- 增大 chunk_size 到 800~1000
- 重叠从 50 提到 100
- 或者用语义切分,按"步骤一/步骤二/步骤三"分段
环节3:Embedding — 模型和文档不匹配
症状:知识库有数据,但语义检索全偏
500页技术规范里的术语:
- “QoS 保障机制”
- “SLA 99.95%”
- “熔断器 pattern”
这些专业术语和口语化问题"这个规范里 X 流程怎么走"在向量空间里可能距离很远,因为:
- Embedding 模型训练数据以通用文本为主,没见过这个领域术语
- 用户问的是口语"怎么走",文档写的是"执行流程见 4.2.1 章节" → 语义表达方式不一致
修复方向:
- HyDE 查询改写
- 或者用该领域的专业 Embedding 模型(如
acge text embedding支持中文 + 专业领域)
环节4:Query — 向量检索的 Top-K 设太小
症状:能检索到部分相关 chunk,但不够
# 问题代码:top_k=2 → 只返回2个chunk,不够回答复杂流程
results = store.search(q_vec, top_k=2)
# 修复:流程类问题至少 top_k=5~10
results = store.search(q_vec, top_k=10)500页的复杂流程可能需要多个相关段落才能完整回答。
环节5:LLM Prompt — 没有强制约束生成
症状:检索到了正确内容,但 LLM 仍然说不知道
# 问题 Prompt:LLM 有"不说不知道"的自由
bad_prompt = f"回答以下问题:{question}\n\n参考:{context}"
# 修复 Prompt:明确指令
good_prompt = f"""你是一个问答助手。基于以下参考内容回答问题。
如果参考内容包含答案,请给出具体步骤。
如果参考内容不包含答案,明确说"根据提供的文档,无法回答此问题"。
参考内容:
{context}
问题:{question}
回答:"""LLM 有幻觉倾向,如果 Prompt 不够强制,它可能自己"发挥"。
正确排查顺序
1. 打印 store_size → 确认文档入库了吗?
2. 打印检索结果 → 确认能检索到东西吗?
3. 打印检索结果 snippet → 确认检索到的和问题相关吗?
4. 打印 Prompt 内容和 LLM 原始输出 → 确认是生成问题还是检索问题?第3题:证明余弦相似度 = 向量内积(归一化后)
数学推导
余弦相似度定义:
cos(θ) = (A · B) / (|A| × |B|)其中分子是向量内积 A · B = Σ aᵢ × bᵢ,分母是两个向量的 L2 范数相乘。
向量内积:dot(A, B) = Σ aᵢ × bᵢ
归一化操作:对向量 A 做 L2 归一化:
 = A / |A| (每个维度除以向量的长度)
|Â| = √(Â · Â) = √( (A/|A|) · (A/|A|) )
= √( A·A / (|A| × |A|) )
= √( |A|² / |A|² ) = 1归一化后 |Â| = 1,|B̂| = 1,所以:
cos(θ) = (A · B) / (|A| × |B|)
= (|A|Â · |B|B̂) / (|A| × |B|) ← 把 A,B 替换成归一化形式
= Â · B̂ ← |A| 和 |B| 约掉
= dot(Â, B̂)结论:当两个向量都是单位向量(L2 归一化)时,余弦相似度 = 向量内积。
实际工程意义
# 归一化前:需要计算 cos(θ)
cos_sim = dot(a, b) / (norm(a) * norm(b)) # 2次开方 + 1次除法
# 归一化后:直接内积
a_norm = a / norm(a)
b_norm = b / norm(b)
cos_sim = dot(a_norm, b_norm) # 零开销性能差异:在 100 万次检索中:
- 余弦相似度:每条做 512次乘法 + 511次加法 + 2次开方 + 1次除法
- 归一化内积:每条只做 512次乘法 + 511次加法
1 次开方 ≈ 10 次乘加,所以归一化内积快 ~10%。
Java 类比:数据库索引列如果建立了 B+Tree,查询 WHERE age = 30 直接定位。但如果建了函数索引 md5(name),每次比较都要重新计算 MD5。归一化 = 把函数索引变成普通索引,查询时直接比。
三道题知识点回顾
Q1: 性能诊断 → 分段打时 + Recall@K + P99延迟
Q2: 全链路排查 → 入库/切分/Embedding/检索/Prompt
Q3: 归一化数学 → |A|=1 时 cos(θ)=A·B思维导图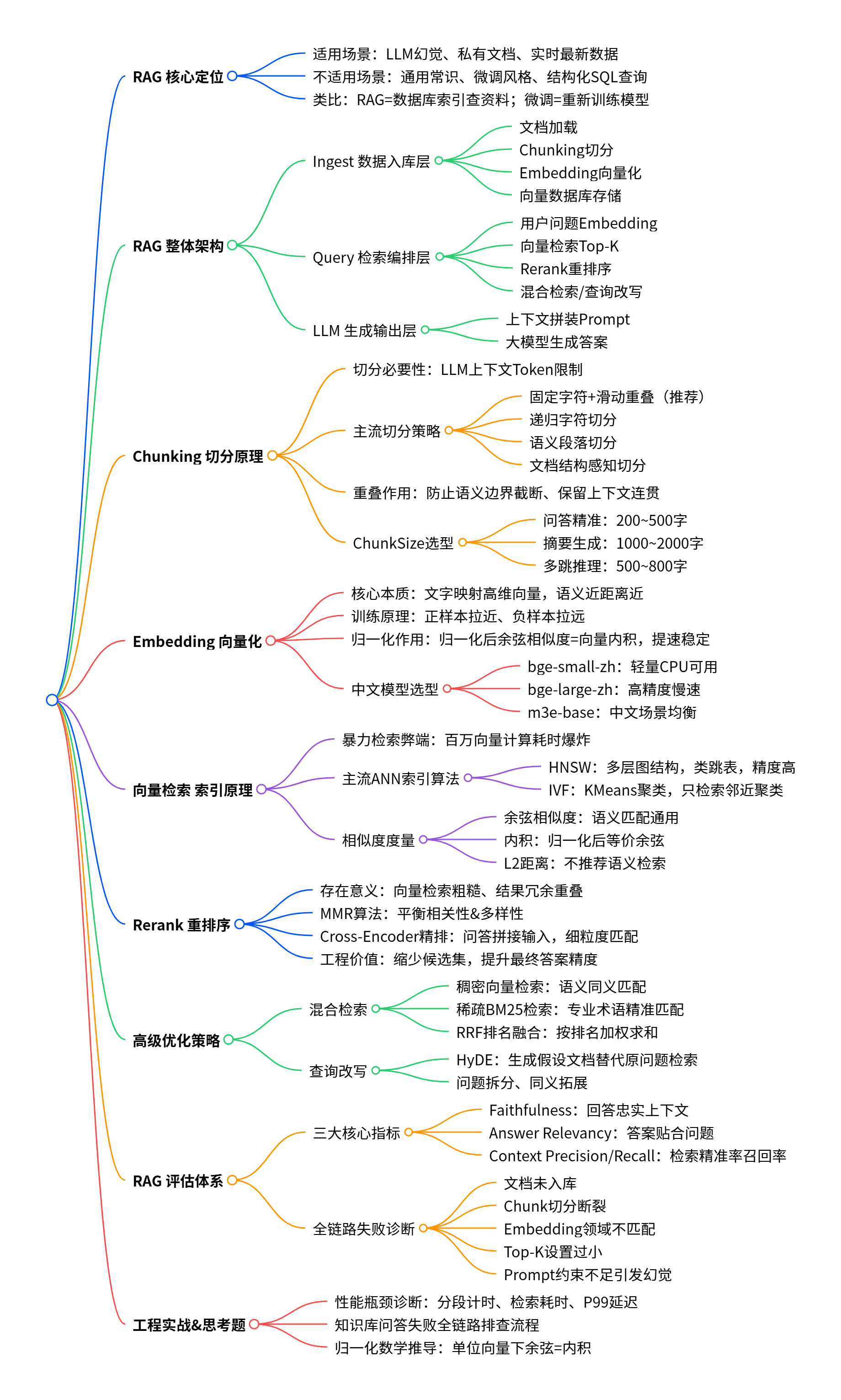

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)