论文笔记(一百二十八)Clutter-Robust Vision–Language–Action Models ... Object-Centric and Geometry Grounding
Clutter-Robust Vision–Language–Action Models through Object-Centric and Geometry Grounding
文章概括
引用:
@article{vo2025clutter,
title={Clutter-Resistant Vision-Language-Action Models through Object-Centric and Geometry Grounding},
author={Vo, Khoa and Hanyu, Taisei and Ikebe, Yuki and Pham, Trong Thang and Chung, Nhat and Vu, Minh Nhat and Minh, Duy Nguyen Ho and Nguyen, Anh and Gunderman, Anthony and Rainwater, Chase and others},
journal={arXiv preprint arXiv:2512.22519},
year={2025}
}
Vo, K., Hanyu, T., Ikebe, Y., Pham, T.T., Chung, N., Vu, M.N., Minh, D.N.H., Nguyen, A., Gunderman, A., Rainwater, C. and Le, N., 2025. Clutter-Resistant Vision-Language-Action Models through Object-Centric and Geometry Grounding. arXiv preprint arXiv:2512.22519.
主页:
原文:
代码、数据和视频:
系列文章:
请在 《 《 《文章 》 》 》 专栏中查找
宇宙声明!
引用解析部分属于自我理解补充,如有错误可以评论讨论然后改正!
ABSTRACT
摘要——近年来,视觉-语言-动作模型(Vision–Language–Action, VLA)通过对大型视觉-语言模型(Vision–Language Models, VLMs)进行后训练,使其能够进行动作预测,从而在通用机器人操作方面取得了令人印象深刻的进展。 然而,现有的VLA模型将感知与控制视为一个紧密耦合的整体式流程,并且该流程纯粹是为了动作优化而设计的。 这种端到端范式削弱了语言条件下的视觉定位能力:在我们的真实世界实验中,当被请求的目标物体不存在时,策略仍然会过度执行抓取动作;它们很容易受到杂乱物体的干扰,并且会过拟合于背景外观,从而导致其在包含干扰物、背景变化以及未见过物体的真实桌面场景中性能下降。
为了解决这些问题,我们提出了OBject-centric and gEometrY groundED VLA,即OBEYED-VLA,这是一个明确地将感知定位与动作推理解耦的框架。 OBEYED-VLA并不是直接在原始RGB图像上进行操作,而是为VLA模型增加了一个感知模块,该模块能够将多视角输入定位为与任务条件相关、以物体为中心并具有几何感知能力的观测表示。 该模块包括两个部分:一个基于VLM的物体中心定位阶段,用于在不同相机视角中选择与任务相关的物体区域;以及一个互补的几何定位阶段,用于突出这些物体的三维结构,而不是强调它们的外观。 随后,这些经过定位处理后的视图被输入到一个预训练的VLA策略中。 我们仅使用在没有环境杂乱物和非目标物体的情况下采集的单物体示范数据,对该策略进行微调。
他们微调 VLA 策略时,只使用“干净的单物体示范数据”。这些数据是在没有环境杂乱、没有其他非目标物体的场景中采集的。
在真实世界的UR10e桌面实验平台上,与强大的VLA基线方法相比,OBEYED-VLA在四类具有挑战性的情境以及多个难度等级下显著提升了鲁棒性,这四类情境包括:干扰物体、目标缺失拒绝、背景外观变化,以及在杂乱环境中操作未见过的物体。 消融实验表明,以物体为中心的定位和具有几何感知能力的定位对于这些性能提升都至关重要。 总体来看,这些结果表明,将感知设计为一个显式的、以物体为中心的组成部分,是增强并泛化基于VLA的机器人操作能力的一种有效方式。
索引词——用于抓取与操作的感知;机器人与自动化中的深度学习;面向自动化的计算机视觉;视觉-语言-动作模型。
I. INTRODUCTION
现在的VLA模型很厉害,可以根据图像和语言直接生成机器人动作。但是它们通常把“看懂场景”和“生成动作”混在一个端到端网络里面训练。这样在简单场景里可能没问题,但在真实杂乱场景里,模型很容易看错目标、抓错物体、被干扰物吸引,甚至目标根本不存在时也硬要抓。
近年来,视觉-语言-动作模型(Vision-Language-Action, VLA),例如Octo [1]、RoboFlamingo [2]、OpenVLA [3]、π0 [4]、π0-FAST [5]和Gr00T [6],在发展通用视觉运动策略方面取得了显著进展。这些模型将视觉、语言和机器人控制统一在一个单一框架之中,该框架以两个紧密耦合的阶段运行:(i)感知阶段从视觉场景和给定指令中获得语义理解;而(ii)动作推理阶段则基于这种理解生成可执行的控制序列。值得注意的是,通过在多样化的机器人示范数据集上进行大规模预训练,例如BridgeData V2 [7]、OXE [8]、DROID [9]和π dataset [4],这些数据集涵盖了广泛的操作任务,VLA模型展现出了有前景的可迁移动作推理能力,使它们能够有效适应新的下游任务和机器人本体。
 图1. 真实世界杂乱场景中基于感知定位的视觉运动操作。 (a)用于考验语言条件定位能力的真实世界场景,包括任务查询与场景不匹配的情况,即目标缺失;干扰物体;背景外观变化;以及未见过的物体。 (b)当前最先进VLA模型的典型失败模式:这些模型的视觉定位能力下降,会忽视任务指令,并且对视觉干扰十分脆弱,从而导致错误抓取、碰撞,或者抓取错误目标。 (c)本文提出的OBject-centric and gEometrY groundED VLA,即OBEYED-VLA框架:一个由VLM驱动的感知模块将原始RGB观测转换为任务条件相关、以物体和几何为重点的视图,使下游VLA能够:(i)在杂乱场景中保持可靠性,例如存在多个干扰物体或背景发生变化的场景;(ii)拒绝不可行或与场景不一致的指令,并忽略干扰物,例如目标缺失指令;以及(iii)在不使用合成杂乱数据或辅助训练损失的情况下,泛化到训练期间未见过的新目标物体。
图1. 真实世界杂乱场景中基于感知定位的视觉运动操作。 (a)用于考验语言条件定位能力的真实世界场景,包括任务查询与场景不匹配的情况,即目标缺失;干扰物体;背景外观变化;以及未见过的物体。 (b)当前最先进VLA模型的典型失败模式:这些模型的视觉定位能力下降,会忽视任务指令,并且对视觉干扰十分脆弱,从而导致错误抓取、碰撞,或者抓取错误目标。 (c)本文提出的OBject-centric and gEometrY groundED VLA,即OBEYED-VLA框架:一个由VLM驱动的感知模块将原始RGB观测转换为任务条件相关、以物体和几何为重点的视图,使下游VLA能够:(i)在杂乱场景中保持可靠性,例如存在多个干扰物体或背景发生变化的场景;(ii)拒绝不可行或与场景不一致的指令,并忽略干扰物,例如目标缺失指令;以及(iii)在不使用合成杂乱数据或辅助训练损失的情况下,泛化到训练期间未见过的新目标物体。
尽管VLA模型在动作推理方面具有很有前景的迁移能力,但它们受到感知阶段的限制;在真实世界的杂乱场景中,可靠的语言条件视觉定位能力往往会失效。在我们如图1(a和b)所示的真实世界实验中,我们观察到了现有VLA模型的这些失败模式:策略常常无法将指代表达与正确目标对齐,会锁定到与任务无关的干扰物上,或者即使指令与场景不一致时仍然执行动作,这表明语言线索并没有始终与正确的视觉证据绑定在一起。
我们将这种脆弱性归因于当前主流的VLA训练范式,在这种范式中,感知和控制是为了动作预测而进行端到端优化的。然而,仅仅最小化一个以动作为中心的目标函数,本身并不能保持稳定的物体级语言-视觉对齐。特别是,当微调数据中的杂乱变化有限,并且缺少困难负样本情况时,例如目标缺失指令,模型可以通过学习捷径来获得较高的训练似然,例如学习一种“物体存在先验”,即只要看到一个显著物体就倾向于执行抓取动作,或者依赖背景和特定上下文线索。 因此,VLA模型从预训练VLM骨干网络中继承来的视觉-语言表征,可能会偏移到“对动作有效但视觉定位能力较弱”的特征上,这表现为过度抓取、对干扰物敏感,以及在杂乱环境和分布偏移下鲁棒性较差。
虽然通过使用合成杂乱场景来扩大下游数据集,或者引入辅助感知目标,例如ECoT [10]、FAST-ECoT [11]和CoT-VLA [12],可以部分缓解这些问题,但这些方法需要在数据采集和标注方面投入过于庞大的工作量。此外,更大的数据集会显著延长训练时间,从而增加计算成本。这些挑战引出了一个核心问题:在不依赖合成杂乱数据或额外感知目标的情况下,我们能否增强VLA模型的感知能力,使其在杂乱环境中仍然可靠、能够抵抗干扰物,并且能够泛化到未见过的物体?
视觉-语言模型(Vision-Language Models, VLMs),例如GPT-4V [13]、BLIP-2 [14]、Qwen2.5-VL [15]和Qwen3-VL [16],是在网络规模的图像-文本数据集上训练的;当它们配备诸如set-of-mark [17]这类视觉提示策略时,能够在零样本设置下表现出很强的语言条件视觉定位能力。 这种能力推动了越来越多层级式机器人操作系统的发展,在这些系统中,高层VLM或多模态大语言模型(Multimodal Large Language Model, MLLM)会为下游控制生成与任务相关的中间表示。 在RoboGround [18]、CrayonRobo [19]、ManipLLM [20]、HAMSTER [21]、MOKA [22]和ReKep [23]中,高层模块会预测任务特定的掩码、提示、接触位姿、二维末端执行器路径、关键点或约束条件,然后这些结果会被下游策略或低层机器人控制器使用。 在HiRobot [24]中,一个VLM被训练用于在长时程任务中为下游VLA生成语言子任务指令。 这些方法展示了将感知与控制解耦的潜力。 然而,其中一些方法需要大量任务特定的高层训练数据或监督信号,这又重新带来了前文所讨论的数据采集和标注负担。此外,这些方法主要是为可泛化的、开放世界的或长时程的操作任务而设计的,同时在很大程度上假设场景是无杂乱干扰的。 最近,BYOVLA [25]通过测试时观测编辑直接处理场景干扰问题:它先定位干扰物并将其移除,然后再把编辑后的观测输入到一个预训练且冻结的VLA中进行动作预测。 然而,这种干预流程的计算开销很大,因为它在推理过程中需要多次执行VLA前向传播,以估计对干扰物敏感的区域,并且还需要一个基于扩散模型的图像修复步骤。
为了解决这一空缺,我们提出了OBject-centric and gEometrY groundED VLA,即OBEYED-VLA,这是一个层级式框架,用于提升VLA在杂乱场景中的语言条件视觉定位能力。 OBEYED-VLA不需要额外的高层训练。 相反,它使用现成的VLM定位能力和显式的跨视角推理,将杂乱的多视角观测转换为面向VLA的任务条件输入;这些输入在抑制干扰物的同时,保留目标物体及其相关几何结构。 随后,VLA不是在原始杂乱图像上进行推理,而是在无杂乱干扰、具有几何感知能力的观测上进行推理,如图1(c)所示。
具体来说,OBEYED-VLA包含两个相互耦合的定位阶段。 首先,以物体为中心的定位阶段使用现成的VLM来识别与指令相关的区域,并在不同相机视角之间对这些区域进行匹配,从而在抑制干扰物的同时,让目标物体对VLA保持可见。 其次,几何定位阶段将被选中的区域转换为基于深度的观测,使其更加突出三维结构,而不是外观信息。 随后,下游VLA仅使用干净的单物体示范数据进行微调,使其能够在这些经过定位处理的观测上执行动作推理,而不需要合成杂乱增强数据或辅助感知目标。 不同于BYOVLA,我们的方法只是直接在VLA输入中遮蔽干扰物区域,而不是通过代价高昂的多次前向传播和基于扩散模型的图像修复来移除干扰物,因此推理过程显著更加轻量。
总体而言,我们的主要贡献总结如下:
-
我们提出了OBEYED-VLA,这是一个层级式框架,它为VLA配备了物体几何定位能力,为VLA的视觉运动推理提供语义相关且具有空间定位信息的观测。
-
通过大量真实世界实验,OBEYED-VLA相比强大的VLA基线方法,在具有不同干扰设置和环境杂乱挑战的杂乱场景中表现出更强的鲁棒性,尽管它只是在干净的单物体示范数据上进行微调。
-
我们表明,OBEYED-VLA能够有效泛化到具有新颖场景组合的未见目标物体,并保持可靠的视觉运动性能。
II. RELATED WORK
A. Vision-Language-Action (VLA) models
基于VLM在跨模态理解任务中的成功 [26], [27], [15],近年来出现了一系列VLA模型,它们在机器人控制中展现出了很强的泛化能力 [3], [4], [6], [5], [12]。VLA模型的核心思想是,将预训练VLM所学习到的丰富语义知识和感知知识迁移到视觉运动策略学习中。VLA模型利用大规模机器人数据集 [7], [9], [8], [4],在动作预测任务上对VLM骨干网络进行后训练;这些数据集涵盖了广泛的操作技能和机器人本体。
在动作预测方面,通常使用两类主要架构。 自回归式VLA模型 [3], [5] 将机器人动作离散化为token,并将机器人控制建模为下一个token预测问题,从而使VLM中的语义推理能力能够直接迁移到具身控制中。 相比之下,基于流的VLA模型 [4], [28], [6] 通过学习到的连续时间动力学,例如flow matching [29],将噪声转换为动作轨迹,从而生成连续动作,并提供更加平滑且更高频率的控制。
尽管这些模型在动作推理方面展现出有前景的迁移能力,但如果它们仅仅使用机器人控制目标进行优化,就会导致视觉-语言感知能力退化,从而降低其面对干扰物、杂乱场景以及指令跟随任务时的鲁棒性。 如图1(b)所示,VLA模型很容易被无关物体干扰,常常无法适应背景变化,并且在杂乱场景或新物体场景中,难以将指代性指令与正确目标关联起来。 一些工作尝试通过引入以感知为重点的辅助目标来缓解这些问题,例如视觉重建损失、空间定位损失,或者对比式视觉-语言对齐项 [10], [11], [12]。 另一些方法则同时在视觉-语言推理数据和机器人控制示范数据上进行联合训练 [28], [6],这能够增强视觉-语言定位能力,但需要大量额外数据和计算资源。
关键在于,这些方法仍然是在一个整体式架构中实现感知和动作预测,并且该架构是以端到端方式进行优化的。 在它们原本的训练领域中,如果有丰富标注的支持,通过结合动作预测目标和面向感知的辅助目标来优化这种统一模型,确实可以维持较强的视觉-语言对齐能力。 然而,当同样的架构被适配到新的任务、机器人本体或环境中时,下游数据集通常缺少维持这些辅助目标所需要的监督信息。 因此,微调过程会退化为仅仅使用动作预测损失,而这又会再次削弱视觉-语言对齐能力。 如果想在适配过程中保留这些辅助感知目标,就需要为每一个新的部署场景额外采集感知标签,而这在实际中很少可行。 因此,这类整体式预训练方案并不适合在下游适配过程中保持VLA策略中可靠的语言条件视觉定位能力。
相比之下,我们提出的框架通过为现有VLA增加一个专门的感知定位模块,明确地将感知与控制解耦。 该模块作用于原始观测,并在这些观测被传递给VLA策略进行动作推理之前,生成语义上和空间上更加聚焦的输入——抑制无关区域,分离出与任务相关的物体,并突出以物体为中心的几何信息。 通过将感知定位与动作预测分离,我们在VLA训练过程中不需要额外的杂乱场景示范数据,也不需要辅助感知目标,就能够提升模型对不同类型场景杂乱的鲁棒性以及对未见物体的泛化能力;同时,我们还可以在不同的VLA模型、环境和机器人本体之间复用同一个感知模块。
B. Vision-Language Models (VLMs) as high-level perception experts
VLM在互联网规模的图像-文本数据上进行预训练,因此展现出很强的语义理解能力和泛化能力 [15], [16], [13]。 这些优势推动了机器人领域越来越多的研究尝试将VLM用作控制策略中的高层感知与推理模块。
一些近期工作仅仅将VLM作为现有策略之外的外部监控器来使用。 AHA [30]和FailSafe [31]对VLM进行微调,使其能够监控机器人行为、检测失败,并在必要时生成纠正性干预,以覆盖基础策略的输出。 在这些系统中,高层VLM并不会与低层策略持续通信,而是只在检测到失败时从外部进行干预。 虽然这些系统提高了可靠性,但它们需要大量任务特定的VLM微调,并且依赖外部干预,而不是直接提升底层VLA策略的视觉定位能力。

表I比较了机器人操作中具有代表性的层级式感知-控制方法,包括RoboGround [18]、CrayonRobo [19]、ManipLLM [20]、HAMSTER [21]、MOKA [22]、ReKep [23]和HiRobot [24]。 该表突出了这些方法在高层输出、训练数据、杂乱处理方式以及目标问题方面的差异。 尽管这些方法都将高层推理与低层执行解耦,但两者之间的接口形式差异很大。RoboGround使用模拟的问答数据(question-answering, QA)以及成对的目标放置掩码,来训练一个基于Transformer的机器人策略。相比之下,CrayonRobo和ManipLLM依赖以提示或位姿为中心的表示,这些表示由MLLM或位姿控制器执行。HAMSTER使用二维末端执行器路径以及视觉问答(visual question answering, VQA)数据来指导一个紧凑的三维策略;而MOKA和ReKep则使用关键点可供性或约束条件来指导下游运动规划与控制。HiRobot训练一个高层VLM,使其能够向下游VLA发布语言子任务指令,以完成长时程执行。这些方法中的一些还需要额外的高层训练数据或监督信息。更重要的是,它们通常并不研究杂乱桌面场景,而是主要关注在基本无杂乱条件下的可泛化、开放世界或长时程操作。
最近,BYOVLA [25]通过在推理过程中执行观测干预来提升VLA的鲁棒性。它首先查询一个VLM来识别干扰物体,并使用分割模型定位这些干扰物所在的区域。接着,它使用Grad-CAM [32]来确定敏感区域,最后通过基于扩散模型的图像修复模型移除这些区域。尽管这一过程提升了模型在杂乱场景中的性能,但它引入了显著的计算开销。每个干扰物区域都需要额外进行一次VLA前向传播,以测试该区域是否与VLA的敏感性相关;随后,最终编辑后的观测还需要通过代价高昂的图像修复步骤生成,因此使实时操作变得不切实际。
相比之下,我们提出的框架使用现成的VLM,将多视角观测定位为面向下游VLA的、以物体为中心的RGB输入和具有几何感知能力的输入,并且不需要额外的高层训练。与该设置下最接近的先前工作BYOVLA相比,我们的方法通过显式的跨视角定位和直接的干扰物抑制来解决杂乱问题,而不是依赖代价高昂的单视角测试时编辑和图像修复。
III. PRELIMINARY & PROBLEM STATEMENT
Preliminary. 我们通过一个视觉运动策略 π θ π_θ πθ 来描述机器人操作,该策略预测一个大小为 H H H 的短时域动作轨迹:
τ t = ( a t , … , a t + H ) ∼ π θ ( o t , q t , l ) (1) τ_t=(a_t,\ldots,a_{t+H})\simπ_θ(o_t,q_t,l)\tag{1} τt=(at,…,at+H)∼πθ(ot,qt,l)(1)
其中,在时间步 t t t,给定自然语言指令 l l l、视觉观测 o t o_t ot 以及机器人的本体感知状态 q t q_t qt。为了使表述更加清晰,在本文余下部分中,我们将省略时间步下标。
 图5. 实验设置:一台配备平行夹爪以及基座相机/腕部相机的UR10e机器人。 策略是在八种杂货类物体的单物体拾取-放置示范数据上进行训练的。 在评估阶段,我们既测试由这些训练类别构建的杂乱场景,也通过七种额外的、未包含在训练中的物体类别来测试模型的泛化能力。
图5. 实验设置:一台配备平行夹爪以及基座相机/腕部相机的UR10e机器人。 策略是在八种杂货类物体的单物体拾取-放置示范数据上进行训练的。 在评估阶段,我们既测试由这些训练类别构建的杂乱场景,也通过七种额外的、未包含在训练中的物体类别来测试模型的泛化能力。
在本工作中,我们的机器人实验设置,如图5所示,为每个观测提供来自不同视角的两个RGB输入:一个安装在机器人基座上的过肩相机,提供 I b a s e I^{base} Ibase ;以及一个腕部安装相机,采集 I w r i s t I^{wrist} Iwrist 。 我们将组合后的视觉观测表示为 o = ( I b a s e , I w r i s t ) o=(I^{base},I^{wrist}) o=(Ibase,Iwrist) ,不过在未来扩展中,也可以无缝地加入更多相机视角。
策略 π θ π_θ πθ 在一个机器人示范数据集上进行训练,其中每条示范都被分解为一系列逐帧样本;第 i i i 个样本包含一个视觉观测 o i o_i oi 、对应的本体感知状态 q i q_i qi 、一个短时域动作片段 τ i τ_i τi 以及相关联的语言指令 l i l_i li 。 这些样本构成如下数据集:
D = { ( o i , q i , τ i , l i ) } i = 1 N (2) \mathcal{D}=\{(o_i,q_i,τ_i,l_i)\}_{i=1}^{N}\tag{2} D={(oi,qi,τi,li)}i=1N(2)
并且,该策略通过最大似然估计进行优化,以匹配示范中的动作序列:
max θ E ( o , q , τ , l ) ∼ D [ log π θ ( τ ∣ o , q , l ) ] (3) \max_θ\mathbb{E}_{(o,q,τ,l)\sim \mathcal{D}}[\log π_θ(τ|o,q,l)]\tag{3} θmaxE(o,q,τ,l)∼D[logπθ(τ∣o,q,l)](3)
Problems of baselines. 在实际中,可以采用一个预训练的VLA模型作为视觉运动策略 π θ π_θ πθ,并在数据集 D \mathcal{D} D 上对其进行微调。 由于这类模型已经在多样化的大规模机器人数据集上进行了预训练,因此它们只需要相对较少的下游数据,就能够将其动作分布适配到新的机器人本体和工作空间中。 然而,由于感知和动作推理被紧密耦合在一起,并且仅仅为了动作预测而进行端到端优化,因此从底层VLM骨干网络继承而来的视觉-语言对齐能力,会逐渐被控制目标扭曲,从而削弱语言条件下的视觉定位能力。
 图2. 关于视觉-语言定位能力的目标缺失合理性检查。 我们报告每一组“请求物体”和“显示物体”配对的抓取率(%),该数值是在所有请求物体(行)与显示物体(列)的组合上,通过20次rollout计算得到的。 物体标签包括Ketchup、Mustard、Coffee(咖啡袋)和Olive(橄榄油瓶),因此非对角线位置的颜色强度可以直接反映出:当被请求的物体不存在时,策略仍然执行抓取的频率。
图2. 关于视觉-语言定位能力的目标缺失合理性检查。 我们报告每一组“请求物体”和“显示物体”配对的抓取率(%),该数值是在所有请求物体(行)与显示物体(列)的组合上,通过20次rollout计算得到的。 物体标签包括Ketchup、Mustard、Coffee(咖啡袋)和Olive(橄榄油瓶),因此非对角线位置的颜色强度可以直接反映出:当被请求的物体不存在时,策略仍然执行抓取的频率。
作者在测试VLA模型有没有真正听懂“我要哪个物体”,以及当目标物体不存在时,它会不会乱抓桌面上的其他物体。
纵轴:Requested object,也就是语言指令里要求的物体
横轴:Shown object,也就是桌面上实际出现的物体
颜色/数字:机器人执行抓取的比例
我们通过图2中总结的一个简单目标缺失合理性检查,显式地研究这种错位现象。 在这个实验中,我们在桌面上放置一个单一物体,例如番茄酱,然后给出一个匹配指令,例如“将番茄酱放入盒子中”,或者给出一个指向不同物体的不匹配指令,例如“将芥末酱放入盒子中”。 正确的行为很直接:只有当指令与桌面上显示的实际物体相匹配时,策略才应该抓起该物体;否则,策略应该避免执行抓取。 对于每一组“被请求的物体”和“实际显示的物体”的配对,我们测量经验抓取率,从而得到一张热力图;在这张热力图中,一个具有良好视觉定位能力的策略应该只在对角线上具有较高数值,而在其他位置接近于零。
图2中的热力图表明,Pi-0、Pi-0 FAST和Pi0.5系统性地违反了这一基本行为要求。 在几乎所有非对角线位置上,也就是被请求物体并不存在的情况下,它们的抓取率仍然很高,通常超过75%;这表明这些策略对语言指令赋予的权重很低,而是只要场景中存在一个看起来合理的物体,就默认执行抓取。
这个实验是在没有杂乱干扰的最简单单物体场景中进行的,它突出了当前VLA模型的根本局限:整体式端到端动作微调会鼓励一种几乎无条件的抓取行为,并逐渐削弱底层的视觉-语言对齐能力,从而导致较差的语言条件视觉定位能力。 这些基线方法的完整训练配置以及全面的定量比较将在第五节中给出。
Our objective. 我们的目标是增强VLA策略的感知能力。 我们在桌面拾取-放置任务设置中研究这一问题,其中数据集 D D D中的训练示范只包含干净的单物体场景。 为了系统性地考察模型在部署阶段的鲁棒性,我们考虑四种评估场景,如图1(a)所示:(i)包含干扰物体的杂乱场景,其中查询方式可以是基于物体身份,也可以是基于空间指代;(ii)目标缺失指令,即当被查询物体不存在时,要求策略不要执行动作;(iii)背景外观上的分布偏移;以及(iv)对新的、此前未见过的物体进行操作。 综合来看,这些场景用于测试一个策略是否能够在狭窄训练分布之外,仍然保持可靠的语言条件视觉定位能力。
IV. OBEYED-VLA
在本节中,我们介绍用于语言条件机器人操作的OBject-centric and gEometrY groundED VLA,即OBEYED-VLA。 从总体上看,OBEYED-VLA引入了一个感知定位模块,该模块对原始视觉观测进行定位,并将其转换为面向视觉-语言-动作模型(Vision-Language-Action model, VLA)的、抑制杂乱干扰且具有几何感知能力的视觉输入。 我们的目标是提升VLA模型在密集、干扰物较多的场景中,以及涉及新目标物体的场景中,对细粒度任务指令的执行性能。 在本节中,我们首先详细描述该定位模块及其输出(第四节A),然后解释这些输出如何与任意VLA模型进行集成(第四节B)。
A. Perception Grounding Module
给定视觉观测后,我们的方法首先为工作空间中所有存在的物体生成掩码候选。 这些掩码作为VLM的视觉提示 [17],使VLM能够对原始视觉观测进行定位,并选择与任务指令最相关的区域。 对于被选中的区域,我们首先在RGB图像中抑制所有背景以及无关物体,从而得到一个只有指令相关物体对下游VLA保持可见的视图,并因此使VLA的动作推理集中在与任务相关的内容上。
随后,我们将剩余像素转换为深度表示,在保留所选物体的三维形状和空间布局的同时,丢弃颜色、纹理等外观线索,这促使策略更多依赖几何信息,而不是依赖表层视觉相关性。 整体感知定位流程如图3所示,下面我们将详细介绍每一个步骤。
先把桌子上的每个东西都圈出来,然后让VLM根据指令判断哪个东西是目标。判断出来之后,把其他东西都遮掉,只留下目标。最后不让VLA太依赖颜色纹理,而是让它看目标的深度和几何形状,再去决定怎么动。
 图3. OBEYED-VLA架构概览。 来自基座相机和腕部相机的原始RGB图像首先被输入到一个分割网络中,以获得物体级掩码。 随后,基于VLM的物体中心定位模块会选择一部分与任务相关物体对应的掩码;与此同时,几何定位模块会对这些掩码应用深度估计,从而生成聚焦于这些区域的、抑制杂乱干扰且具有几何感知能力的观测。 随后,得到的经过感知定位处理的观测,会与语言指令和机器人本体感知信息一起输入到一个预训练VLA模型中,由该模型输出动作轨迹;在下游任务中,只有VLA需要被微调,而感知模块保持冻结,从而能够以即插即用的方式与不同VLA模型集成。
图3. OBEYED-VLA架构概览。 来自基座相机和腕部相机的原始RGB图像首先被输入到一个分割网络中,以获得物体级掩码。 随后,基于VLM的物体中心定位模块会选择一部分与任务相关物体对应的掩码;与此同时,几何定位模块会对这些掩码应用深度估计,从而生成聚焦于这些区域的、抑制杂乱干扰且具有几何感知能力的观测。 随后,得到的经过感知定位处理的观测,会与语言指令和机器人本体感知信息一起输入到一个预训练VLA模型中,由该模型输出动作轨迹;在下游任务中,只有VLA需要被微调,而感知模块保持冻结,从而能够以即插即用的方式与不同VLA模型集成。
Object Segmentation Proposals. 我们采用一个现成的分割模型来处理来自两个相机视角的RGB观测,即 I b a s e I^{base} Ibase 和 I w r i s t I^{wrist} Iwrist ,并生成覆盖工作空间中可见物体的物体掩码候选 M b a s e = { m k b a s e } k = 1 K b a s e \mathcal{M}^{base}=\{m^{base}_k\}_{k=1}^{K_{base}} Mbase={mkbase}k=1Kbase 和 M w r i s t = { m k w r i s t } k = 1 K w r i s t \mathcal{M}^{wrist}=\{m^{wrist}_k\}_{k=1}^{K_{wrist}} Mwrist={mkwrist}k=1Kwrist ,其中 K b a s e K_{base} Kbase 和 K w r i s t K_{wrist} Kwrist 分别表示基座视角和腕部视角中检测到的物体数量。 每一个掩码 m k { b a s e , w r i s t } m^{\{base,wrist\}}_k mk{base,wrist} 都定义了对应视角中的一个候选物体区域,该区域之后会被转换为基于标记的视觉提示,用于以物体为中心的定位步骤。
系统输入两个RGB视角:基座视角 I b a s e I^{base} Ibase 和腕部视角 I w r i s t I^{wrist} Iwrist ,然后分别输出两个mask集合: M b a s e \mathcal{M}^{base} Mbase 和 M w r i s t \mathcal{M}^{wrist} Mwrist 。每个mask对应图像中一个候选物体区域,后续会被转换成带标记的视觉提示,交给VLM根据语言指令选择真正的任务相关目标。
人们可以将SAM系列中的开放词汇分割模型 [33], [34], [35], [36] 应用于该任务;然而,由于其预训练数据集的性质,即SA-1B [33],这些模型经常会将物体过度分割成多个彼此分离的片段。 因此,VLM被迫推断哪些片段属于同一个物体,这会引入不必要的推理开销,并且经常导致错误定位。 像Co-DETR [37] 这样在Objects365 [38]+LVIS [39]上训练的闭合词汇但覆盖范围较大的模型,可以产生更加连贯的完整物体掩码;然而,它们并不是为机器人手臂和夹爪分割而训练的,因此在这些类别上生成的掩码并不可靠。 此外,基于SAM的方法和Co-DETR模型都具有较高的计算成本,这使得它们不适合在闭环操作系统中进行实时部署。
为了在一个高效模型中结合两类方法的优势,我们在一个混合数据集上对YOLO11-Seg [40]进行微调,该数据集结合了我们的机器人示范数据和经过筛选的LVIS [39]子集。 我们首先使用一个统一流程,对100条遥操作示范进行自动标注,该流程整合了Co-DETR和基于SAM的方法:工作空间中的物体使用来自Co-DETR [37]的完整物体掩码进行标注;而机器人手臂和夹爪则在初始帧中通过Grounding DINO [41]进行定位,使用SAM [33]进行分割,然后通过Cutie [42]进行时间上的传播。 为了提升模型在我们八种杂货物体之外的覆盖能力,我们还额外构建了一个LVIS子集:通过选择与室内桌面物品对应的类别,例如瓶子、罐子、盒子、杯子和餐具,并保留只包含这类实例的图像。 随后,YOLO11-Seg在由已标注示范数据和该LVIS子集按照50:50比例混合而成的数据上进行微调。 这种混合训练方式得到的分割模块,能够可靠地识别多样化的桌面物体和机器人手臂,同时支持我们的操作系统所需的实时运行。 更多训练细节请参见附录A。
离线用强模型自动标注数据,在线用轻量快速模型实时分割。具体做法是:用Co-DETR给100条遥操作示范中的桌面物体生成完整mask;用Grounding DINO在初始帧定位机器人手臂和夹爪,再用SAM分割,并用Cutie把这些mask传播到后续视频帧。同时,为了让模型不只会识别实验中的八种杂货物体,作者还从LVIS中筛选瓶子、罐子、盒子、杯子、餐具等室内桌面物体类别,构建额外训练子集。最后,将机器人示范标注数据和筛选后的LVIS子集按照50:50混合,用来微调YOLO11-Seg。
最终得到的YOLO11-Seg分割模块既能识别多样化桌面物体,也能识别机器人手臂和夹爪,同时速度足够快,可以用于实时闭环操作。这个模块的作用是为后续VLM
grounding提供稳定、完整、实时的候选物体mask。
Object-Centric Grounding. 人类天然地会以物体为中心的视角来感知场景。 例如,当被要求“将番茄酱瓶放入盒子中”时,我们会定位番茄酱瓶、盒子以及自己的手,从而完成该任务。 桌面上存在许多其他物体,对这种感知过程的影响很小。 无关物体和背景会自然地从注意力中退后,而注意力会缩小并集中到执行该指令动作所需要的实体上。 这种以物体为中心的感知能力,使人类即使在视觉密集且杂乱的环境中也能够可靠地行动。 受这一直觉启发,我们的方法使用VLM,具体而言是Qwen3-VL [16],利用其涌现出的视觉感知与推理能力,对视觉观测进行定位,并分离出与给定指令最相关的区域。
我们的方法被设计为一个两阶段的以物体为中心的定位过程:首先是任务感知的基座视角物体定位,随后是跨视角区域匹配,如图4所示。
 图4. 以物体为中心的定位模块。 该模块分为两个阶段运行。 首先,VLM解析任务指令,以提取与任务相关的物体;并且通过在基座视角的分割掩码上使用set-of-mark提示方法,选择与这些物体对应的区域。 我们裁剪被选中的基座视角区域,以生成以物体为中心的参考视图,并将这些参考视图与经过set-of-mark增强的腕部视角图像一起,在同一个提示中提供给VLM,由VLM预测匹配的腕部视角区域。 最终,在基座视角和腕部视角中得到的任务相关掩码,定义了经过语义定位的区域;这些区域能够消除干扰物和背景,只分离出与任务指令最相关的视觉内容。
图4. 以物体为中心的定位模块。 该模块分为两个阶段运行。 首先,VLM解析任务指令,以提取与任务相关的物体;并且通过在基座视角的分割掩码上使用set-of-mark提示方法,选择与这些物体对应的区域。 我们裁剪被选中的基座视角区域,以生成以物体为中心的参考视图,并将这些参考视图与经过set-of-mark增强的腕部视角图像一起,在同一个提示中提供给VLM,由VLM预测匹配的腕部视角区域。 最终,在基座视角和腕部视角中得到的任务相关掩码,定义了经过语义定位的区域;这些区域能够消除干扰物和背景,只分离出与任务指令最相关的视觉内容。
Task-aware base-view object grounding. 任务感知的基座视角物体定位。 我们首先对任务指令 l l l 执行一个仅基于语言的解析步骤:通过提示VLM列出完成该指令 l l l 所涉及的物体,例如被查询物体和容器,从而得到一个与任务指令相关的物体名称集合 E ( l ) = { e j } \mathcal{E}(l)=\{e_j\} E(l)={ej}。
随后,给定基座视角图像以及覆盖场景中所有候选物体的分割候选 M b a s e = { m k b a s e } \mathcal{M}^{base}=\{m^{base}_k\} Mbase={mkbase},我们采用set-of-mark视觉提示机制 [17],在原始RGB图像上,将一个数字标记,即一个正数,叠加到每个掩码区域 m k b a s e m^{base}_k mkbase 内部。 这会生成一张带有标记增强的基座视角图像,其中每个被分割出的区域都被赋予一个不同的、具有空间定位意义的符号。 将标记直接叠加到RGB图像上,可以使这些标识符与其下方对应的区域在视觉上对齐,从而提供明确的空间参照,帮助VLM对各个独立区域进行推理。
然后,我们将物体名称 E ( l ) \mathcal{E}(l) E(l) 和带有标记增强的基座视角图像一起输入给VLM进行查询。 该模型被提示去识别哪些标记对应于与任务相关的物体,从而产生一个掩码子集:
S b a s e ⊆ M b a s e (4) \mathcal{S}^{base}\subseteq \mathcal{M}^{base}\tag{4} Sbase⊆Mbase(4)
该子集表示VLM认为与该指令相关的掩码区域。 由于在我们的实验中,除了机器人手臂和正在被主动操作的物体之外,场景基本是静态的,因此我们只在每次rollout开始时调用一次VLM完成这一阶段,随后在剩余帧中跟踪被选中的掩码。
对于每一个 m k b a s e ∈ S b a s e m^{base}_k\in \mathcal{S}^{base} mkbase∈Sbase ,我们进一步从原始基座视角图像中,围绕该掩码提取一个紧凑的RGB裁剪区域,并在这个裁剪窗口内应用对应的二值掩码,以抑制背景。 这会得到以物体为中心的参考视图,其中只有被选中的物体保持可见,而周围的杂乱物体被移除,从而为后续的跨视角匹配阶段提供标准化的视觉锚点。
Cross-view region matching. 跨视角区域匹配。 腕部视角的观测通常会从俯视角或倾斜角度呈现物体,在这种情况下,物体外观会与VLM在预训练过程中主要见到的典型正面视角、直立物体外观存在显著差异。 因此,试图直接在腕部视角上对指令进行定位是不稳定的。 相反,我们将上一阶段得到的以物体为中心的参考裁剪图作为标准化视觉锚点,从而把从基座视角获得的指令感知定位结果迁移到腕部视角中。
给定腕部视角图像 I w r i s t I^{wrist} Iwrist 及其分割候选 M w r i s t = { m k w r i s t } \mathcal{M}^{wrist}=\{m^{wrist}_k\} Mwrist={mkwrist},我们再次采用set-of-mark [17]方法,在每一个掩码内部绘制数字标记,从而得到一张带有标记增强的腕部视角图像。 基于上一阶段的基座视角定位结果,我们复用与每一个任务相关物体名称 e j ∈ E ( l ) e_j\in \mathcal{E}(l) ej∈E(l) 相关联的物体中心参考裁剪图。 然后,我们为VLM构造一个单一提示,该提示:(i)按顺序列出每一个物体名称 e j e_j ej 及其对应的参考裁剪图;并且(ii)附加带有标记增强的腕部视角图像。 对于在基座视角中识别出的每一个任务相关物体,VLM会输出腕部视角中与同一物体对应的标记索引。 这些预测结果定义了一个腕部视角掩码子集:
S w r i s t ⊆ M w r i s t (5) \mathcal{S}^{wrist}\subseteq \mathcal{M}^{wrist}\tag{5} Swrist⊆Mwrist(5)
至此,我们获得了两个相机中与指令一致的区域集合,即 S b a s e ⊆ M b a s e \mathcal{S}^{base}\subseteq \mathcal{M}^{base} Sbase⊆Mbase 和 S w r i s t ⊆ M w r i s t \mathcal{S}^{wrist}\subseteq \mathcal{M}^{wrist} Swrist⊆Mwrist ,从而得到一个紧凑的、以物体为中心且跨视角对齐的场景描述。
Geometric Grounding. 在任务相关物体语义识别的基础上,几何定位阶段构建能够捕捉这些物体底层三维结构的表示。 我们首先将现成的Depth Anything v2 [43]应用于两个视角的RGB图像 I b a s e I^{base} Ibase 和 I w r i s t I^{wrist} Iwrist ,生成稠密深度估计。 为了增强几何线索的表达能力,灰度深度值会被线性映射到一个具有高动态范围的颜色空间中,从而使物体结构中的细微变化能够被更清楚地区分出来。 随后,经过语义定位的区域集合 S b a s e \mathcal{S}^{base} Sbase 和 S w r i s t \mathcal{S}^{wrist} Swrist 会作为掩码应用到深度估计上,以仅筛选出与相关物体对应的深度测量值。 最终得到的一对掩码化深度图,记为 Z b a s e Z^{base} Zbase和 Z w r i s t Z^{wrist} Zwrist,提供了以几何为中心的观测;这些观测补充了上一阶段的物体中心定位结果,并作为完整的、经过感知定位处理的视觉输入,提供给下游动作推理模块。
B. Perceptually Grounded Action Reasoning via Vision-Language-Action Models
如前所述,我们采用一个VLA模型作为策略 π θ π_θ πθ,该策略从经过感知定位处理的视觉输入 o ~ = ( Z b a s e , Z w r i s t ) \tilde{o}=(Z^{base},Z^{wrist}) o~=(Zbase,Zwrist) 中进行动作推理。 这使得该策略能够在以指令为中心且具有几何感知能力的视觉输入上运行,而这些输入对视觉杂乱和外观变化的敏感性显著更低。
如第三节所讨论的,我们采用一个预训练VLA作为视觉运动策略 π θ π_θ πθ,并在数据集 D D D上针对我们的机器人本体对其进行微调。 在每一个时间步 t t t,除了经过感知定位处理的视觉输入 o ~ t \tilde{o}_t o~t之外,该策略还以本体感知状态 q t ∈ R 7 q_t\in\mathbb{R}^7 qt∈R7作为条件;该本体感知状态由机器人的绝对关节角以及末端执行器的二值开合状态给出。 该策略会预测一个时间范围为 H H H的未来动作序列 a t : t + H − 1 a_{t:t+H-1} at:t+H−1,其中每一个动作元素都是同一关节-夹爪空间中的7维目标。
我们仅通过公式(3)中的最大似然目标来优化策略参数 θ θ θ,同时保持感知定位模块冻结。
V. EXPERIMENTS
在本节中,我们提出一系列实验,用来回答以下问题:
Q1. OBEYED-VLA能否在高度干扰的场景中遵循细粒度语言指令?
Q2. OBEYED-VLA能否在背景外观和场景布局发生变化时保持鲁棒性?
Q3. OBEYED-VLA能否泛化到在包含未见干扰物的杂乱场景中操作未见物体?
此外,我们进一步进行消融实验,以探究我们的感知设计:
Q4. 在下游动作推理之前引入显式的以物体为中心的定位,能够带来多大提升?
Q5. OBEYED-VLA中解耦的两阶段物体中心定位模块有多关键?
Q6. 相比仅使用RGB定位,显式的几何感知定位,即掩码化深度输入,能够带来哪些额外提升?
A. Real-world Setup, Implementation, and Baselines
 图5. 实验设置:一台配备平行夹爪以及基座相机/腕部相机的UR10e机器人。策略是在八种杂货类物体的单物体拾取-放置示范数据上进行训练的。在评估阶段,我们既测试由这些训练类别构建的杂乱场景,也通过七种额外的、未包含在训练中的物体类别来测试模型的泛化能力。
图5. 实验设置:一台配备平行夹爪以及基座相机/腕部相机的UR10e机器人。策略是在八种杂货类物体的单物体拾取-放置示范数据上进行训练的。在评估阶段,我们既测试由这些训练类别构建的杂乱场景,也通过七种额外的、未包含在训练中的物体类别来测试模型的泛化能力。
Robot platform and control. 机器人平台与控制。 所有实验都在一台6自由度UR10e机械臂上进行,该机械臂配备Robotiq 2F-85平行夹爪,并在桌面工作空间中运行。 我们从两个同步的相机流中采集RGB观测:一个固定的基座视角相机,放置在机器人过肩视角位置;以及一个腕部视角相机,安装在腕部与夹爪接口附近。 在我们的桌面实验设置中,两个RealSense相机都会采集 1280 × 720 1280\times720 1280×720的RGB图像流。 我们通过缩放和中心裁剪,将这些RGB观测预处理为 720 × 540 720\times540 720×540的基座视角和腕部视角输入。 如图5底部所示,相机的位置经过设置,使桌面物体在两个视角中都能以足够大的尺度出现。 示范数据通过遥操作采集,机器人控制频率为10 Hz;在部署阶段执行动作时,也使用相同的10 Hz频率。
Training data curation. 训练数据整理。 我们的训练数据由遥操作拾取-放置示范组成,这些示范是在无杂乱场景中采集的;每个场景中只有一个物体放在桌面上,并且位于盒子旁边。 对于每一个episode,我们从一组改写后的自然语言模板中采样一条指令,这些模板如下所列,它们都指定了同一个目标:将被查询的物体放入盒子中。 然后,操作者控制机器人抓取被查询的物体,并将其放入盒子中。 我们选择了八种具有不同形状和外观的杂货类物体,如图5顶部所示,并为每个物体采集250条示范,总共得到2000条真实世界训练示范。 训练物体包括:香料瓶、绿色咖啡袋、芥末瓶、番茄酱瓶、蛋黄酱瓶、食品罐头、午餐肉罐头、绿色油瓶。
Language prompts. 语言提示。 我们使用一小组改写后的指令模板,以降低模型对单一表达方式的敏感性:
- “place <object> in the bin”
- “put <object> into the bin”
- “pick up <object> and place it in the bin”
- “grasp <object> and drop it into the bin”
Implementation details. 实现细节。
-
Perception grounding module (frozen). 感知定位模块,冻结。 我们采用Qwen3-VL的8B-Instruct模型作为VLM骨干网络,因为它在可控延迟下具有出色的推理能力。 该VLM使用两块A6000 GPU进行部署。 对于所有定位调用,VLM接收的是整个系统中使用的预处理RGB观测,不进行额外裁剪或上采样。
-
Action policy (trainable). 动作策略,可训练。 我们使用Pi-0和Pi-0 FAST骨干网络来实例化动作策略。 我们将由此得到的定位增强策略记为OBEYED Pi-0和OBEYED Pi-0 FAST。 这两个模型都从公开发布的checkpoint进行初始化,并在采集到的示范数据上使用低秩适配方法 [44] 微调50K次迭代,固定学习率为 1 × 10 − 5 1\times10^{-5} 1×10−5,batch size为128。 微调过程分布在四块NVIDIA A6000 GPU上进行,而推理则在机器人工作站上的单块GPU上运行。 在Pi-0或Pi-0 FAST进行推理之前,经过定位处理的基座视角和腕部视角观测会按照OpenPI策略变换,被调整为 224 × 224 224\times224 224×224大小。 在所有实验中,感知定位模块始终保持冻结;在微调过程中,只有VLA策略参数会被更新。 在推理阶段,我们遵循先前工作,对于Pi-0和Pi-0 FAST,都会在再次基于下一次观测查询策略之前,先执行预测轨迹中截断时域为 H = 10 H=10 H=10的动作。
-
Closed-loop test-time execution. 测试时闭环执行。 在测试时,任务感知的基座视角定位阶段只在初始帧上运行一次,用于识别与指令相关的物体;这是因为在一次rollout过程中,场景基本保持静态,而且这样可以避免在每个控制周期重复执行代价较高的基座视角定位步骤。 随后,被选中的基座视角掩码会在该rollout的剩余过程中进行传播。 在每一个控制周期中,我们会对当前观测运行分割,使用被跟踪的基座视角锚点来执行腕部视角的跨视角匹配,并应用几何定位,以形成输入给VLA的无杂乱观测。 随后,VLA预测下一段动作轨迹,我们按顺序执行这些动作。 然后,我们获得下一次观测,并进入下一个控制周期。
Baselines. 基线方法。 我们将OBEYED-VLA与当前最先进的VLA模型进行比较,包括Pi-0 [4]、Pi-0 FAST [5]、Pi-0.5 [28]和Gr00T N1.5 [6]。 所有基线方法都从其公开checkpoint进行初始化,并在我们的遥操作数据集上进行微调。 与OBEYED-VLA不同,它们直接在来自两个相机视角的原始RGB观测上运行,而不是在经过感知定位处理的输入上运行。 为了公平比较,我们对所有基线模型使用与上述相同的优化超参数。 在测试时,我们也只执行预测序列中的前10个动作,然后重新规划,以与OBEYED-VLA的实现保持一致。
B. Fine-grained language following in distracting scenes
B. 干扰场景中的细粒度语言跟随能力
Experimental setting. 实验设置。 为了回答Q1,我们引入了三个真实世界桌面基准测试,用于考察在存在视觉干扰物的情况下,模型进行细粒度、语言条件定位的能力。 每一次试验都包含一条自然语言指令和一个桌面场景;当指令与场景一致时,策略必须对被查询物体执行正确的拾取-放置操作,而当指令与场景不一致时,策略必须避免执行动作。
(1) Distractor objects. 干扰物体。 我们在工作空间中放置一个目标物体和多个干扰物体,所有这些物体都从八个训练类别中采样得到。 干扰物是指当前指令中没有提到的物体。 指令会明确命名一个可见物体,成功的条件是只抓取该目标物体。
(2) Absent-target rejection. 目标缺失拒绝。 我们在桌面上放置一个单一物体,但发出一条指向另一个不存在物体类别的指令。 正确行为是通过不抓取任何物体来拒绝该指令。 该设置显式地考察模型是否倾向于对虚假的视觉线索过度执行动作,而不是严格保持语言与场景之间的一致性。
(3) Spatial reasoning. 空间推理。 我们均匀采样三个物体,将它们以随机顺序水平排列成一行,并发出纯关系型指令,例如“将左边的物体放入盒子中”。 该任务迫使策略依赖关系推理和空间推理,而不是依赖基于类别或外观的匹配。
Evaluation protocol. 评估协议。 对于干扰物体任务,我们评估三个难度等级,即在单个目标周围放置 { 1 , 4 , 7 } \{1,4,7\} {1,4,7} 个干扰物,并在每次试验中随机采样物体和摆放位置。 对于目标缺失任务,我们通过将一个实际存在的物体与一条命名另一个不同物体的指令配对来进行rollout试验,并且只有当模型没有执行抓取时才计为成功。 对于关系定位任务,每次试验会采样三个物体,并随机排列它们在桌面上的位置,即左、中、右。 在所有任务和难度等级中,我们报告每个模型和每种配置在100次rollout上的成功率和置信区间(confidence interval, CI)。 总体而言,这些基准测试揭示了互补的失败模式:在严重杂乱环境中的混淆、在不可执行指令下过度自信地抓取,以及对关系型语言定位的泛化能力较弱。
 图7. 在干扰物从八个训练物体中采样得到的情况下,细粒度语言跟随任务的成功率(%)。 当我们将干扰物数量从0个,即无干扰物,增加到1个、4个和7个时,对OBEYED-VLA与当前最先进VLA模型进行比较。 我们报告平均成功率及其95%置信区间。
图7. 在干扰物从八个训练物体中采样得到的情况下,细粒度语言跟随任务的成功率(%)。 当我们将干扰物数量从0个,即无干扰物,增加到1个、4个和7个时,对OBEYED-VLA与当前最先进VLA模型进行比较。 我们报告平均成功率及其95%置信区间。
Results and analysis. 结果与分析。 图7比较了随着干扰物数量增加,OBEYED Pi-0和OBEYED Pi-0 FAST相对于当前最先进VLA模型的表现。 在无干扰物设置下,即0个干扰物,所有方法都取得了较高的成功率,均不低于80%。 然而,随着我们加入更多干扰物,先前的VLA模型性能急剧下降到10%以下;相比之下,OBEYED Pi-0和OBEYED Pi-0 FAST在有一个干扰物时仍然保持90%以上的成功率,即使在最严重的杂乱设置下也保持在约80%左右。 在所有杂乱等级上取平均后,我们框架的两个实例相较于最强基线方法都带来了4倍提升,这表明我们基于感知定位的设计在很大程度上防止了由杂乱干扰导致的性能崩溃,并使模型能够在物体密集的场景中可靠地遵循细粒度语言指令。 图6中的定性rollout进一步表明,在所有难度等级下,OBEYED Pi-0都能始终将指令定位到正确的相关物体上,并在接近和抓取的整个过程中保持对这些物体的注意,同时忽略附近的干扰物,即使这些干扰物在视觉上离夹爪更近。
 图6. 在包含干扰物的杂乱场景中的定性实验,这些干扰物从八种训练物体中采样得到。 对于每一条指令,我们展示原始RGB观测,以及由OBEYED Pi-0生成的对应感知定位视图。 经过定位处理的输入会抑制干扰物体,并突出被查询的目标,从而使策略能够忽略杂乱干扰并精确执行任务。
图6. 在包含干扰物的杂乱场景中的定性实验,这些干扰物从八种训练物体中采样得到。 对于每一条指令,我们展示原始RGB观测,以及由OBEYED Pi-0生成的对应感知定位视图。 经过定位处理的输入会抑制干扰物体,并突出被查询的目标,从而使策略能够忽略杂乱干扰并精确执行任务。
我们在图8中总结了目标缺失拒绝任务和空间推理任务的结果。 对于目标缺失拒绝任务,OBEYED Pi-0和OBEYED Pi-0 FAST都取得了接近完美的成功率,约为95%;而Pi-0.5最高只能达到约40%,其余VLA模型则保持在约10%到15%之间,这揭示了它们在没有有效目标存在时仍然执行虚假抓取的强烈倾向。 对于空间推理任务,由于类别线索没有信息量,策略必须完全依赖空间信息,OBEYED-VLA的两个实例都达到了约75%的成功率,比最佳基线方法Pi-0 FAST高出超过40个百分点。 这些结果表明,我们基于感知定位的框架显著增强了可行性检查和关系定位能力,超过了当前端到端VLA所表现出的水平。
 图8. 在目标缺失拒绝和空间推理基准测试上的成功率(%)。 目标缺失拒绝衡量的是:当被请求物体缺失时,策略正确避免抓取的频率;而空间推理评估的是模型对空间关系型指令的跟随能力,例如“左边的物体”。 我们报告平均成功率及其95%置信区间。
图8. 在目标缺失拒绝和空间推理基准测试上的成功率(%)。 目标缺失拒绝衡量的是:当被请求物体缺失时,策略正确避免抓取的频率;而空间推理评估的是模型对空间关系型指令的跟随能力,例如“左边的物体”。 我们报告平均成功率及其95%置信区间。
补充视频展示了不同干扰物设置下,即0到7个干扰物,以及目标缺失拒绝任务和空间推理任务中的代表性rollout。
C. Robustness to background changes
C. 对背景变化的鲁棒性
Experimental setting. 实验设置。 为了回答Q2,我们专门测试在最简单的交互设置下,背景外观如何影响策略性能:桌面上只有一个目标物体,并且语言指令与该物体完全匹配。 这样可以将背景变化的影响从杂乱干扰和指令歧义中分离出来。 先前工作 [25] 已经表明,VLA模型可能对背景变化较为脆弱;在这里,我们考察我们的感知定位模块是否能够在这类情况下提升鲁棒性。
Evaluation protocol. 评估协议。 我们评估四种背景变化形式,并按照背景偏移严重程度递增的顺序排列:(1)在桌面上铺设一块颜色和图案完全不同的桌布;(2)将背景板替换为不同的视觉场景;(3)在桌面上随机铺散多色纸张;以及(4)同时使用新的桌布和新的背景板。 对于每一种背景条件,我们对每个模型运行50次rollout,并报告成功率及其95%置信区间。
 图9. 在分布外背景变化情况下的成功率(%)。 我们在四种背景变化设置下对OBEYED-VLA和当前最先进VLA模型进行定量比较,这些变化从轻微到严重,包括桌面和背景板的变化。 我们报告平均成功率及其95%置信区间。
图9. 在分布外背景变化情况下的成功率(%)。 我们在四种背景变化设置下对OBEYED-VLA和当前最先进VLA模型进行定量比较,这些变化从轻微到严重,包括桌面和背景板的变化。 我们报告平均成功率及其95%置信区间。
Results and analysis. 结果与分析。 图9报告了四种分布外背景条件下的成功率。 在所有条件下,OBEYED Pi-0都保持高度稳定,成功率不低于80%,相比无杂乱单物体设置只出现轻微下降;而所有基线方法都出现了明显下降。 单独使用恐龙背景板只会使Pi-0、Pi-0 FAST和Gr00T N1.5出现轻微性能下降,但会导致Pi-0.5性能急剧下降,这表明其泛化能力较差。 当扰动影响与物体直接接触的区域时,性能损失最大:多色纸张和桌布通常会分别使基线方法的成功率下降约10–15个百分点,以及额外下降5–15个百分点;其中Pi-0.5在多色纸张条件下几乎崩溃到接近零。 在桌布基础上再加入恐龙背景板几乎不会产生明显变化,这表明桌面区域的变化相比远处背景变化占据主导影响。 相比之下,在这一系列背景变化中,OBEYED Pi-0只出现轻微性能下降,这突出表明我们显式的物体中心定位能够显著缓解背景过拟合问题。 在所有背景设置下,OBEYED Pi-0和OBEYED Pi-0 FAST取得了相近的成功率,这表明我们的框架在很大程度上与具体策略无关,并且能够稳定提升模型对背景诱发干扰物的鲁棒性。 在图10中,经过感知定位处理后的视图在多色纸张、桌布以及桌布加背景板这些背景条件下保持视觉上一致,同时抑制了原始RGB观测中的大幅外观变化。 因此,尽管背景发生了显著变化,策略在整个rollout过程中仍然能够稳定地关注与指令相关的目标物体和容器。
 图10. 背景外观变化下的定性结果。 在不同分布外背景下的示例rollout,展示了原始RGB观测以及对应的经过感知定位处理后的视图。 经过定位处理的输入会抑制目标物体和容器周围具有干扰性的背景变化,使策略即使在周围外观发生较大变化的情况下,也能够稳定执行给定任务。
图10. 背景外观变化下的定性结果。 在不同分布外背景下的示例rollout,展示了原始RGB观测以及对应的经过感知定位处理后的视图。 经过定位处理的输入会抑制目标物体和容器周围具有干扰性的背景变化,使策略即使在周围外观发生较大变化的情况下,也能够稳定执行给定任务。
补充视频展示了所有背景变化场景中的代表性rollout。
D. Fine-grained language following on unseen objects
D. 未见物体上的细粒度语言跟随能力
Experimental setting. 实验设置。 为了回答Q3,我们评估这些策略是否能够正确感知命名新物体的语言指令,并在完全由未见物体组成的场景中执行动作。 如图5所示,我们使用七种保留的杂货类物体来构建干扰物体任务,这些物体与八种训练物体互不重叠。 在该场景中,所有物体都被随机放置在桌面上。 指令采用与之前相同的语言跟随格式,但现在会命名一个单独的未见类别;策略必须对被查询的未见物体完成拾取-放置操作,同时忽略未见干扰物。 未见物体列表如图5所示,包括:绿色咖啡袋、橙色咖啡袋、白色酱料瓶、海鲜酱瓶、调味酱瓶、Nutella榛子可可酱、黄色油瓶。
Evaluation protocol. 评估协议。 我们采用与干扰物体任务中讨论的相同评估协议。 我们对每个模型运行100次rollout,并报告成功率及其95%置信区间。
 图11. 在杂乱环境中面对未见物体时,细粒度语言跟随任务的成功率(%)。 每个场景包含一个未见目标物体和四个未见干扰物,这些物体均从七个保留类别中采样得到,并且指令会命名该未见目标类别。 我们报告平均成功率及其95%置信区间。
图11. 在杂乱环境中面对未见物体时,细粒度语言跟随任务的成功率(%)。 每个场景包含一个未见目标物体和四个未见干扰物,这些物体均从七个保留类别中采样得到,并且指令会命名该未见目标类别。 我们报告平均成功率及其95%置信区间。
Results and analysis. 结果与分析。 图11显示,OBEYED Pi-0 FAST在未见物体语言跟随任务中始终取得最高成功率,尽管场景中的每一个物体都属于新类别。 与已见干扰物体设置类似,标准Pi-0和Pi-0 FAST出现显著性能下降,而Pi-0.5和Gr00T N1.5在未见杂乱场景下几乎失败;相比之下,OBEYED Pi-0 FAST保持了较高性能,并且远高于所有基线方法。 这些结果证实,显式的物体中心定位和几何感知定位,是使视觉运动技能能够可靠迁移到真实杂乱场景中新物体上的关键。 在这一未见物体设置下,OBEYED Pi-0的表现紧随OBEYED Pi-0 FAST之后,绝对成功率仅落后约 5 5% 5。 补充视频进一步展示了这些未见物体杂乱场景中的代表性rollout,突出显示了OBEYED-VLA即使面对新物体也能够跟随语言指令的能力。
E. Ablation Studies
E. 消融实验
Effect of explicit object-centric grounding (Q4). 显式物体中心定位的影响(Q4)。 为了衡量引入解耦式感知-控制接口所带来的提升,我们将基线Pi-0(表II第5行)与仅使用单阶段物体中心定位的配置(表II第4行)进行比较。 在这一设置中,在每个控制周期内,定位会分别独立应用于当前的基座视角图像和腕部视角图像,不使用跨视角区域匹配或几何定位;随后,得到的掩码化RGB观测会被直接输入到Pi-0中。 即使是这种最小化的感知定位,也已经在全部三个设置中带来了显著提升,尤其是在杂乱已见物体操作和未见物体操作上。 这一结果表明,鲁棒性提升中的很大一部分来自于在下游动作推理之前,显式地将场景过滤到与任务相关的物体。
Effect of two-stage object-centric grounding (Q5). 两阶段物体中心定位的影响(Q5)。 为了量化我们两阶段物体中心定位的重要性,我们将完整模型(表II第1行)与启用几何感知定位的单阶段对应配置(表II第2行)进行比较,并将仅RGB的两阶段配置(表II第3行)与仅RGB的单阶段配置(表II第4行)进行比较。 在这两组比较中,单阶段版本会分别独立地对基座视角和腕部视角进行定位,而不是使用基座视角参考图来指导腕部视角匹配。 这种替换会导致各个基准测试中的性能明显下降,其中空间推理任务上的下降最大,同时在已见物体杂乱场景和未见物体杂乱场景中也出现了额外下降。 这些一致的差距表明,在部分可见和关系型提示条件下,基座视角参考裁剪图对于解决腕部视角中的歧义至关重要;在这些情况下,单阶段提示往往会锁定到视觉上显著但错误的区域。

Effect of geometry-aware grounding (Q6). 几何感知定位的影响(Q6)。 为了单独分析显式几何感知定位的贡献,我们将完整模型(表II第1行)与仅RGB的两阶段配置(表II第3行)进行比较,并将单阶段几何感知配置(表II第2行)与单阶段仅RGB配置(表II第4行)进行比较。 在这些仅RGB设置中,下游VLA接收的是掩码化RGB观测,而不是掩码化的基于深度的输入。 几何感知定位最明显的效果出现在未见物体杂乱场景中;在这一场景下,加入深度线索在两组配对比较中都稳定提升了性能。 相比之下,在已见物体杂乱场景和空间推理任务上的提升较小。 这种模式表明,掩码化深度线索在单纯物体中心过滤之外,提供了互补的几何结构,从而减少了动作推理对纹理和颜色的依赖。
F. Run-time analysis
F. 运行时间分析
OBEYED-VLA的推理时间可以分解为四个组成部分:(1)分割候选模块,它为两个视角预测物体掩码;(2)物体中心定位阶段,它包括跨视角区域匹配,并调用VLM将腕部视角裁剪区域与基座视角中的任务相关物体进行关联;(3)几何定位阶段,它将被选中的掩码反投影到三维空间中,并形成以物体为中心的裁剪区域;以及(4)VLA策略,即Pi-0或Pi-0 FAST,它解码下一段动作序列。 我们在机器人工作站上对这些组成部分进行性能分析,并在表III中报告它们每一步的实际墙钟延迟,该结果是在10次rollout上取平均得到的。 分割和定位的计算开销在所有变体中是共享的,而策略推理时间则反映了具体使用的骨干网络。 在跨视角区域匹配中,物体中心定位每次推理调用平均耗时0.41秒。 鉴于在一次rollout过程中场景基本保持静态,我们只在初始化帧对基座视角观测执行一次任务感知定位,随后依靠分割模型在后续帧之间传播被选中的掩码。 其余组成部分——分割(0.04秒)、几何定位(0.18秒)以及动作策略推理(Pi-0为0.15秒,Pi-0 FAST为0.53秒)——也都在亚秒级范围内运行。 总体而言,在顺序执行设置下,这使得使用Pi-0时的端到端控制周期为0.78秒,使用Pi-0 FAST时为1.16秒,约为0.8–1.2 Hz,这对于我们的真实世界桌面操作任务来说是足够的。
Geometric grounding in parallel. 并行几何定位。 一种提升推理速度的直接方法,是将彼此独立的模块并行化。 在我们的流程中,几何定位中的深度估计步骤直接作用于输入的RGB观测,因此我们将这一分支放在一个单独进程中,与分割和物体中心定位并行运行;一旦选中的掩码可用,在VLA推理之前只剩下轻量级的掩码组合操作。 我们实现了这种并行执行方式,并在表III下方的比较行中报告测得的端到端延迟。 与顺序执行设置相比,这使OBEYED Pi-0的单步延迟降低了约21%(0.62秒 vs. 0.78秒),使OBEYED Pi-0 FAST的单步延迟降低了约15%(0.99秒 vs. 1.16秒)。
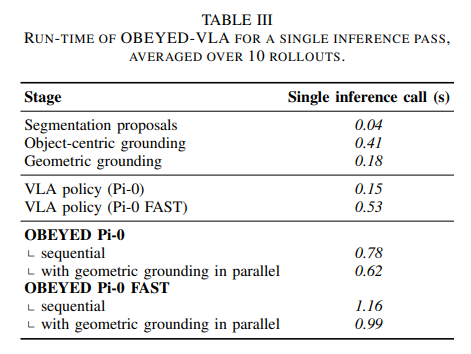
Object-centric grounding gating. 物体中心定位门控机制。 另一种降低推理成本的方法,是只在场景内容发生变化时调用物体中心定位,而不是在每个控制周期都调用。 具体而言,在物体中心定位识别出当前帧中的任务相关物体之后,我们使用ByteTrack [45]在后续帧中跟踪这些被选中的物体。 只要没有检测到新物体,并且被跟踪的任务相关物体没有消失,我们就复用之前的定位结果;否则,我们会触发一次新的定位调用。 这种门控机制减少了不必要的VLM调用,同时保持了传递给下游VLA的同一种定位输入接口。 我们在表IV中报告由此得到的、在10次rollout上取平均的rollout时间。 与表III不同,该表测量的是端到端实际墙钟rollout时间,其中不仅包括模型推理,还包括物理机器人执行时间,而在机器人执行期间控制循环处于空闲状态。
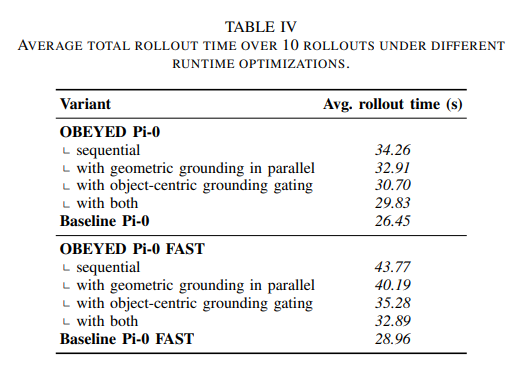
这一策略在较长rollout中特别有效,因为在较长rollout中,许多连续控制周期会共享同一组被跟踪物体。 在这些时间段中跳过不必要的物体中心定位调用,相比单独并行化几何定位,能够带来更大的rollout时间缩减。 当与并行几何定位结合时,经过定位增强的系统运行时间与原始Pi-0基线相差约13%(29.83秒 vs. 26.45秒),与原始Pi-0 FAST基线相差约14%(32.89秒 vs. 28.96秒)。 与此同时,该系统仍然保留了主实验中所展示的鲁棒性提升。
VI. CONCLUSION
Summary of contributions. 贡献总结。 我们提出了OBEYED-VLA,这是一个以物体为中心并以几何为基础的视觉-语言-动作框架,它显式地将视觉定位与动作推理解耦。 OBEYED-VLA并不是依赖一个整体式端到端VLA模型,而是为任意VLA增加一个模块化且冻结的感知流程,该流程能够从原始多视角RGB输入中生成任务条件相关、以物体为中心并具有几何感知能力的观测。 具体来说,一个由VLM驱动的物体中心定位模块通过set-of-mark提示方法,在多个相机视角中识别与指令相关的区域;同时,一个几何定位模块会将这些区域转换为掩码化深度表示,使模型更多关注三维结构,而不是外观。 随后,得到的经过感知定位处理的视觉输入被送入一个预训练VLA策略中;该策略仅在干净的单物体示范数据上进行微调,而定位模块保持冻结。
在真实世界UR10e桌面实验平台上,我们在四种具有挑战性的部署场景中验证了OBEYED-VLA:(i)包含干扰物体的杂乱场景;(ii)目标缺失指令拒绝;(iii)背景外观变化;以及(iv)未见物体的杂乱操作。这些实验对应我们关于鲁棒性、泛化能力,以及物体中心定位、两阶段物体中心定位和显式几何感知定位作用的六个实验问题(Q1–Q6)。 在这些设置中,OBEYED-VLA相较于强大的VLA基线方法,持续提升了可靠性和泛化能力,并且在VLA微调过程中不需要生成合成杂乱场景,也不需要辅助感知训练目标。 消融实验进一步证实,显式物体中心定位提供了主要的感知-控制接口,而两阶段物体中心定位和几何感知定位则带来了额外的互补提升。 总体而言,我们的结果表明,将感知定位视为一个显式的、模块化的组成部分,是一种有效且互补的路径,可以使VLA策略在杂乱环境中更加可靠,在干扰物存在时更加聚焦,并且更容易迁移到未见物体和未见背景中。
Limitations and future directions. 局限性与未来方向。 我们的框架也启发了若干未来扩展方向。 首先,OBEYED-VLA依赖其感知组件的可靠性,包括分割、基于VLM的定位以及深度估计。 例如,如果分割网络在密集杂乱场景中将相邻实例合并在一起,那么得到的定位视图可能会不够完善,并可能降低下游动作准确性。 在我们的设置中,这类失败主要出现在推理阶段,尤其是在非常密集的杂乱环境、严重遮挡或物体间距很近的情况下。 在用于训练的干净单物体示范数据上,我们的感知定位模块高度可靠,并且没有观察到明显的掩码错误。 这些严重遮挡情况最常影响基座视角,在该视角中,目标物体可能被附近物体部分遮挡,而定位区域可能同时包含目标物体和遮挡物。 即使腕部视角提供了更清晰的观测,下游VLA仍然会接收到不完善的基座视角输入,这可能会降低动作预测质量。 一个有前景的方向是,通过推理时引导,或者借助辅助奖励模型或动力学模型的指导,使下游生成式策略对不完善的定位观测更加容忍。
其次,在本文中,我们重点关注提升模型在杂乱场景下的鲁棒性,而效率并不是我们的主要关注点。 尽管如此,我们仍然采用了两种简单的运行时优化方法:一是将深度估计放在单独进程中运行,以实现并行执行;二是对腕部视角的物体中心定位进行门控,使其只在被跟踪的场景内容发生变化时才被调用。 即使有这些改进,使用现成模块进行分割、VLM推理和深度估计仍然会引入不可忽视的计算开销。 在可以使用RGB-D传感器的设置中,深度信息可以直接从相机获得,从而省去外部深度估计器并降低开销。 更广泛地说,一个有前景的方向是将定位流程蒸馏或摊销到更轻量的模型中,或者以我们显式流程作为监督,为VLA配备并训练一个内部的物体中心定位阶段。
最后,由于本文的目标是验证显式感知定位的有效性,我们的实验是在短时程桌面拾取-放置任务上进行的;将我们的框架扩展到长时程、多阶段任务以及更加动态的环境中,仍然是一个重要方向。 此外,本文中使用深度信息是为了强调物体几何结构,以服务于定位和泛化。 然而,几何信息也可以支持避障和轨迹规划,因此,将经过定位处理的表示进一步扩展到具备障碍物感知能力的动作推理,是一个自然的未来方向。
附录A YOLO11-Seg训练细节
为了保证可复现性,我们在这里详细说明第四节A中用于生成物体掩码候选的YOLO11-Seg模型的额外训练细节。 我们的训练数据由两个来源构成。
首先,我们使用在桌面实验设置中采集的100条遥操作机器人示范,其中80条用于训练,20条用于验证,并使用正文中描述的相同工具对其进行自动标注:Co-DETR为工作空间中的物体提供完整物体掩码,而Grounding DINO、SAM和Cutie则用于定位机器人手臂和夹爪掩码,并在帧之间传播这些掩码。 在数据集准备完成后,该机器人示范数据源包含76,871张训练图像和8,818张验证图像。 这些图像使分割模型能够接触到部署时会遇到的相机视角、机械臂外观和场景布局。
其次,为了确保分割模型能够泛化到机器人示范中有限的已见杂货物体之外,我们加入了一个经过筛选的LVIS v1子集,其中包含室内桌面类别。 我们定制了一份室内物体类别名称列表,并移除了一些有歧义的类别,使最终得到的LVIS子集在规模上与机器人示范数据源大致匹配。 随后,我们保留至少包含一个所选类别的LVIS图像,最终得到70,813张训练图像和13,732张验证图像。 这使得机器人示范数据和经过筛选的LVIS子集能够在微调过程中以大约50:50的比例进行采样。
在训练过程中,我们应用图像增强方法,包括以0.15的概率进行MixUp图像插值,以及以0.30的概率进行Copy-Paste物体插入。 此外,我们还使用概率为0.5的随机水平翻转、最大幅度为 ± 3 ∘ ±3^\circ ±3∘的小角度随机旋转、范围为 ± 15 ±15% ±15的随机缩放,以及幅度为0.5的剪切增强。 表V总结了主要的微调参数。

附录B 额外实验与失败分析
A. Prediction Horizon Sensitivity
A. 预测时域敏感性
在正文中,OBEYED Pi-0在基于下一次观测再次查询策略之前,会先执行一个截断时域为 H = 10 H=10 H=10的动作序列。在这里,我们研究我们的框架对预测时域 H H H选择的敏感性。作为一个具有代表性的杂乱设置,我们评估包含一个目标物体和四个干扰物体的情况,其中所有物体都属于训练中已见过的类别。我们在 H ∈ { 5 , 10 , 15 , 20 } H\in\{5,10,15,20\} H∈{5,10,15,20}范围内改变执行时域,同时保持部署流程的其余部分不变。 结果总结于表VI中。

总体而言,改变动作时域主要影响的是控制执行,而不是感知定位:在所有测试时域下,该框架在大多数rollout中仍然能够正确定位目标并成功接近目标。 较短的时域 ( H = 5 ) (H=5) (H=5)带来了最高的抓取成功率,这说明过冲失败更少,即机器人在接近目标时撞到目标物体的情况更少;但是,它最终的拾取-放置成功率低于默认的 H = 10 H=10 H=10,这表明在释放阶段出现了额外失败。 具体来说,在到达盒子上方之后,机器人经常在盒子上方来回移动,却没有释放物体;这说明释放动作本身可能需要超过五个动作,而截断时域会截断夹爪打开阶段。 相比之下,较长的时域 ( H ≥ 15 ) (H\geq15) (H≥15)会同时降低抓取成功率和最终成功率,这与接近过程中出现更多过冲和物体接触失败的现象一致。 因此,在测试过的设置中, H = 10 H=10 H=10在我们的实验设置下产生了最可靠的整体行为,这也支持了我们沿用先前工作并使用这一默认时域的选择。
B. Additional Clutters: Toppled Objects
B. 额外杂乱情况:倒伏物体
Additional demonstrations. 额外示范数据。 为了将我们的评估扩展到直立杂货物体之外,我们还研究了物体倒伏情况下的杂乱操作。 我们针对三个已见物体,即橄榄油、番茄酱和芥末,每个物体额外采集200条示范;其中100条示范对应物体仰面躺倒的情况,100条示范对应物体侧躺的情况,总共得到600个episode。 这600个倒伏物体episode会被追加到正文中用于训练的直立物体示范数据之后,一起用于训练。
Training setup. 训练设置。 在这项研究中,我们重点关注OBEYED Pi-0,因为在主实验中,它的性能趋势与OBEYED Pi-0 FAST大体一致。 我们在上述组合数据集上重新训练Pi-0策略,其中所有观测都会首先经过我们的感知定位模块进行定位处理。 在整个过程中,定位模块始终完全冻结,只有下游VLA策略会被更新。 这样可以单独考察:当动作策略接触到新的物体姿态之后,同一个冻结的定位流程是否能够支持倒伏物体操作。
Evaluation on object distractors. 在物体干扰物上的评估。 我们使用正文中相同的干扰物体协议来评估OBEYED Pi-0,干扰物数量分别为0、1、4和7。 这是本研究中最相关的评估,因为它直接考察了在倒伏物体姿态这一额外挑战下,模型对杂乱场景的鲁棒性。 在这一设置中,所有物体都会被随机放置为侧躺或仰面躺倒状态。 为了便于对照,表VII还包含了正文中的直立物体结果。

总体而言,即使物体处于倒伏状态,OBEYED Pi-0仍然保持了相当强的鲁棒性。 与直立设置相比,在0个、1个和4个干扰物条件下,成功率几乎没有变化,这表明冻结的感知定位模块仍然能够很好地迁移到这些新的物体姿态上。 在7个干扰物设置下出现了轻微下降,约为5个百分点;这可能是因为倒伏物体配置增加了遮挡,并导致实例之间更频繁地重叠。 图12顶部两行中的定性示例进一步表明,在仰面躺倒和侧躺姿态下,经过定位处理的输入仍然能够保留被查询的物体。
 图12. 额外评估中的定性结果。 顶部两行:倒伏物体的拾取-放置任务,其中被查询的芥末瓶以仰面躺倒和侧躺姿态出现。 底部一行:打开/关闭评估,其中策略打开左侧水壶,同时忽略另一个视觉上相似的水壶。 对于每个示例,我们展示了随时间变化的原始观测以及对应的经过感知定位处理的视觉输入。
图12. 额外评估中的定性结果。 顶部两行:倒伏物体的拾取-放置任务,其中被查询的芥末瓶以仰面躺倒和侧躺姿态出现。 底部一行:打开/关闭评估,其中策略打开左侧水壶,同时忽略另一个视觉上相似的水壶。 对于每个示例,我们展示了随时间变化的原始观测以及对应的经过感知定位处理的视觉输入。
C. Additional Task: Open/Close
C. 额外任务:打开/关闭
Task setting & training demonstrations. 任务设置与训练示范。 为了进一步测试同一个基于感知定位的框架是否能够应用到拾取-放置任务之外,我们将评估扩展到打开/关闭这一操作任务。 我们使用一个电水壶额外采集了一组单独的示范数据。 在每条示范中,一个单独的水壶被放置在工作空间的左侧或右侧。 机器人被指令执行两种动作之一:通过按下打开开关来打开水壶,或者通过向下按压壶盖来关闭水壶。 我们为每一种“位置-动作”设置采集150条示范,总共得到600条示范。
Training setup. 训练设置。 按照附录B-B中的倒伏物体研究设置,我们使用OBEYED Pi-0作为具有代表性的定位增强策略。 我们仅在这组打开/关闭示范数据上微调预训练Pi-0策略,并将其与主实验中使用的拾取-放置数据保持分离。 在策略微调之前,所有观测都会由同一个感知定位模块进行处理;该定位模块始终完全冻结,只有下游VLA策略会被更新。 这一设置进一步考察了定位模块在杂货物体拾取-放置任务之外的泛化能力,覆盖了不同的物体类别以及基于按压动作的打开/关闭操作。
Evaluation protocol. 评估协议。 我们在包含两个电水壶的杂乱设置中评估OBEYED Pi-0。 由于这些水壶外观相似,因此该评估使用空间关系型指令来指定目标。 在测试时,两个水壶会同时被放置在桌面上,一个在左侧,一个在右侧。 每条指令都会同时指定目标位置和期望动作,要求策略只打开或关闭被查询的那个水壶,同时忽略另一个水壶。 我们评估四种场景:打开左侧水壶、关闭左侧水壶、打开右侧水壶和关闭右侧水壶;每种场景进行20次真实机器人rollout。 结果总结于表VIII中。

结果表明,在这种双水壶设置中,OBEYED Pi-0能够可靠地同时遵循空间目标指代和被请求的打开/关闭动作。 该策略总体上取得了接近完美的成功率,这表明同一个感知定位模块能够支持拾取-放置之外更加多样化的桌面操作设置;同时,即使存在一个视觉上相似的干扰物,它也能使下游VLA聚焦于被查询的水壶。 图12底部一行展示了打开左侧水壶任务中的一个代表性rollout。
D. Failure-Mode Analysis
D. 失败模式分析
图13展示了我们在真实机器人rollout中观察到的两种代表性失败模式。 第一种也是更常见的情况是抓取执行失败:经过感知定位处理的输入正确地分离出了被查询物体,但下游策略并不总是能够产生足够精确的抓取动作。 在所展示的示例中,物体在一次不稳定抓取之后从夹爪中滑落;在其他rollout中,夹爪也可能在接近物体的过程中与物体发生碰撞。 这表明,即使视觉定位是正确的,最终操作结果仍然可能受到学习得到的动作策略在富接触抓取过程中的精度和鲁棒性的限制。
第二种较少出现的情况是由严重遮挡导致的感知定位失败。 在该示例中,一个蛋黄酱瓶在基座视角中遮挡了被查询的芥末瓶,导致经过定位处理的基座视角输入包含了遮挡物,并破坏了目标观测。 这种不完善的定位可能会误导下游策略,使其产生不精确的接近动作,最终导致夹爪与目标物体发生碰撞,而不是形成稳定抓取。 尽管腕部视角仍然能够正确定位芥末瓶,但当前策略没有显式机制,能够在夹爪接近目标时自适应地依赖更干净的腕部视角输入,同时抑制有缺陷的基座视角定位结果。
综合来看,这些示例阐明了OBEYED-VLA当前的容错边界。 本文提出的定位方法显著减少了由干扰物引起的目标选择错误,但严重遮挡和高精度抓取执行仍然具有挑战性,并推动未来研究更加能够容忍不完善定位观测的策略。
 图13. 代表性失败案例。 顶部:定位正确,但抓取执行不完善。 底部:遮挡情况下的感知定位失败,其中芥末瓶在基座视角中与遮挡它的蛋黄酱瓶被合并在一起。
图13. 代表性失败案例。 顶部:定位正确,但抓取执行不完善。 底部:遮挡情况下的感知定位失败,其中芥末瓶在基座视角中与遮挡它的蛋黄酱瓶被合并在一起。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)