LangChain之核心组件(文本分割器Text splitters)
6. 文本分割器(Text Splitters)
6.1 概念:为什么要拆分?
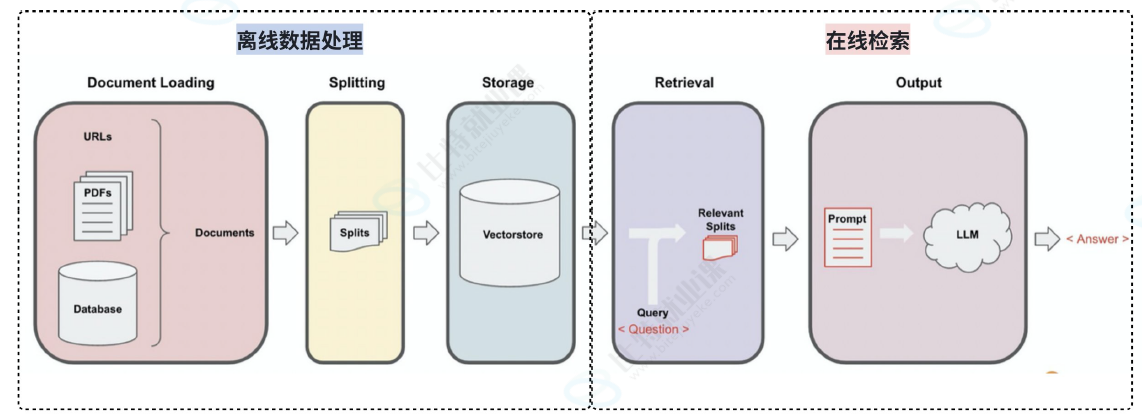
你已经用 PyPDFLoader 把 PDF 加载成了 Document 对象。一个 Document 可能包含一整页甚至整个文件的文本。
直接拿整个文档去检索有三大问题:
文本分割器的任务就是:把大文档切成小块,每块语义相对完整,大小可控。
一个 Document(整篇 MD 文件)
│
▼ 文本分割器
│
N 个 Document(每个小块都是一个 Document,保留原始 metadata)
我们已经知道可以通过文档加载器完成各种数据源的加载,将其转换为文档对象Document 。那么接下来要做的就是文档拆分。
文档拆分通常是将大文本分解为更小的、易于管理的块。这对于索引数据并将其传递到模型中都很有用。因为,大块更难搜索并且不适合模型的有限上下文窗口。拆分可以提高搜索结果的粒度,从而可以更精确地将查询与相关文档部分进行匹配。LangChain 的文本分割器便能将大型文档分解为更小的块。如下图所示:
6.2 按文档长度与语义拆分
拆分的核心矛盾:
块太小 → 语义断裂,搜到的片段缺少上下文
块太大 → 精度下降,浪费 token
分为两种: 基于字符长度拆分和基于Token长度拆分。
所以需要配置两个关键参数:chunk_size 和 chunk_overlap。
6.2.1 基于字符长度拆分 — CharacterTextSplitter
from langchain_text_splitters import CharacterTextSplitter所有参数:

代码:
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import CharacterTextSplitter
# 先加载文档
loader=UnstructuredMarkdownLoader("./file/Day 1 详解:总览.md")
data = loader.load()
# 创建文本分割器
text_splitter = CharacterTextSplitter(
separator="\n\n", # 先用双换行(段落间)切
chunk_size=100, # 目标:每块不超过 100 字符
chunk_overlap=20, # 相邻两块之间有 20 字符的重叠
length_function=len, # 用 Python 内置 len() 数字符
is_separator_regex=False, # separator 是普通字符串,不是正则
)
# 分割
texts = text_splitter.split_documents(data)
# 查看前 10 块
for doc in texts[:10]:
print("*" * 30)
print(f"{doc}\n")
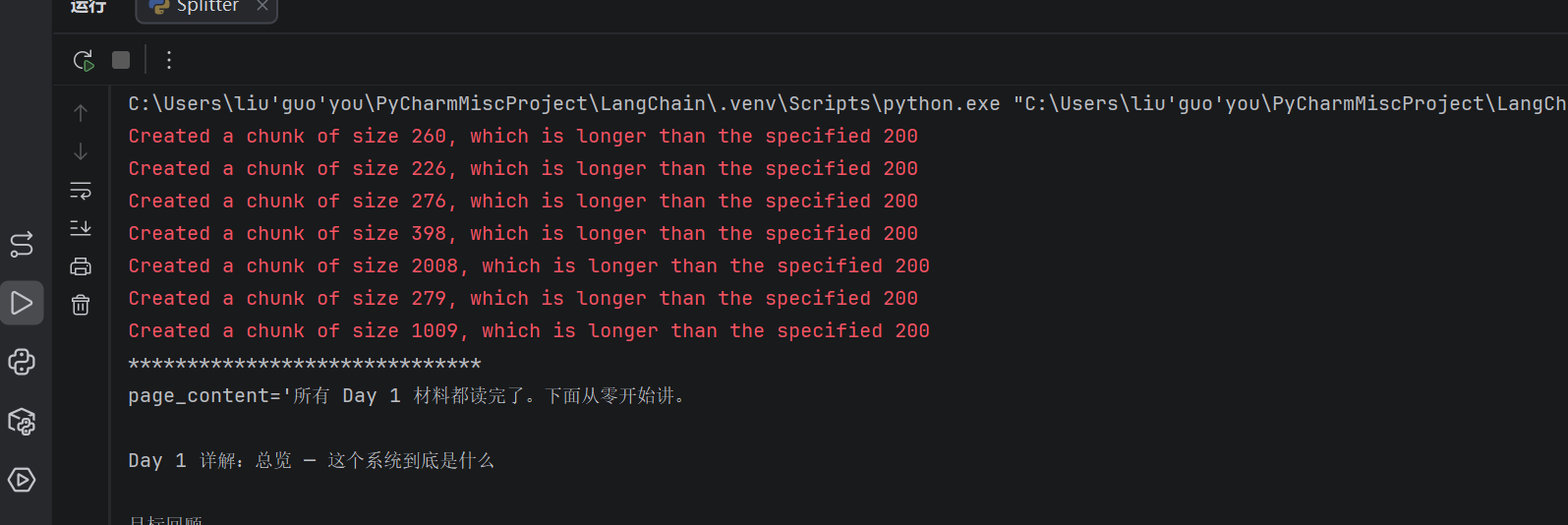
在这里要说明关于这里的爆红提示,这是一个在使用LangChain 的文本分割器时非常常见的问题。看到这个信息,不要担心,这不是错误,而是预期的行为。
原因是为了保持语义的完整性!当文本分割器用尽所有指定的分隔符都无法将一段文本分割到你的目标大小 chunk_size 以下时,它会选择保留整个文本块,而不是强行将其截断为无意义的片段,因此我们会看到这个提示信息。因此我们可以看到,被分割出来的段落,基本上都是语义完整的一段话。
那么分割逻辑到底是什么?

它宁愿保留一个超长但语义完整的块,也不强行在第 100 字符处截断——那样会把单词截断成乱码。
解决方案: 如果大部分块都超长,把 chunk_size 调大就行了。比如调到 2500:
#创建文本分割器
text_splitter=CharacterTextSplitter(
separator="\n\n",
chunk_size=2500,
chunk_overlap=20,
length_function=len,
is_separator_regex=False,
)
chunk_overlap 的作用
理解为相邻两块之间的"安全区"。块 1 的最后 20 个字符会出现在块 2 的开头:
块1: [....................ABCDEFGHIJ]
← 重叠区
块2: [ABCDEFGHIJ....................]
为什么需要重叠? 防止重要信息刚好卡在边界上被切开,后续检索时遗漏。
6.2.2 基于 Token 长度拆分
之前我们讲过,LLM 大模型实际上并不是直接接收字符串,而是需要先做 token 切分编码。这里我们可以借助 【tiktoken 分词器】来进行 token 的切分编码。
先看 tiktoken 怎么切分一段文本:
import tiktoken
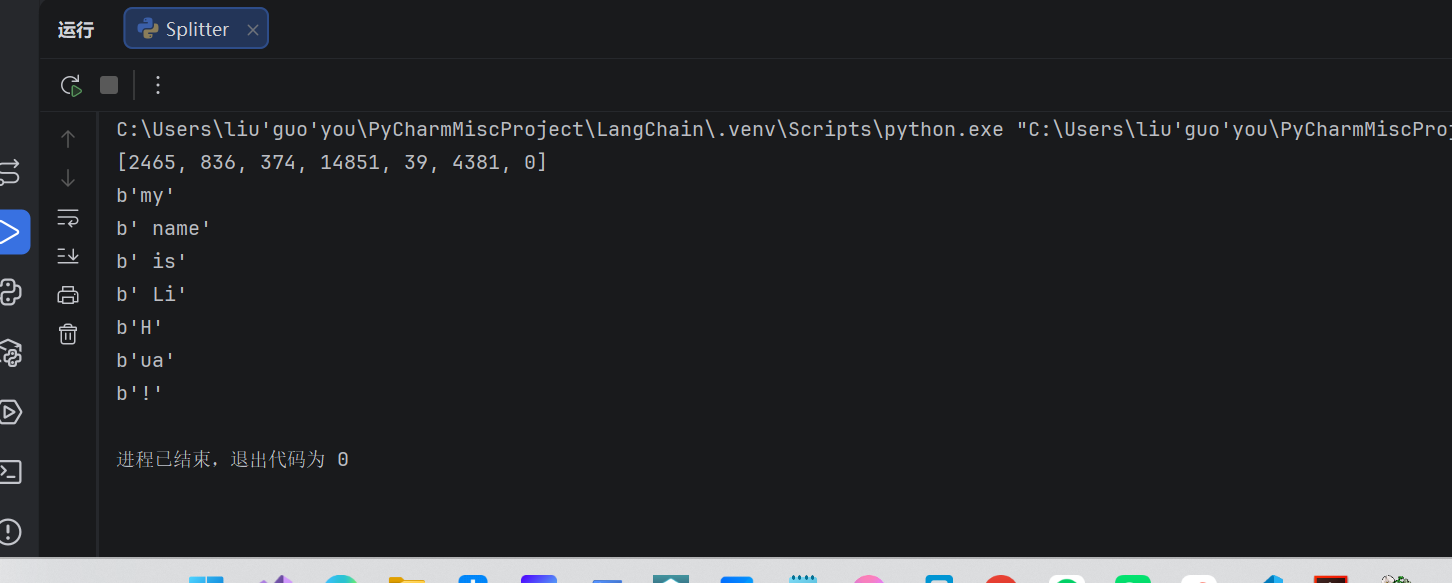
enc = tiktoken.get_encoding("cl100k_base")
tokens = enc.encode("my name is LiHua!")
print(tokens) # → [2465, 836, 374, 14851, 39, 4381, 0]
for token in tokens:
print(enc.decode_single_token_bytes(token))
# b'my' ← 1 个 token
# b' name' ← 1 个 token(注意前面有空格)
# b' is'
# b' Li'
# b'H'
# b'ua'
# b'!'解释: cl100k_base 是tiktoken 分词器中的一种编码方式。gpt-4 、gpt-3.5-turbo 等
都采用这种切分编码方式。
可以看到采用切分编码cl100k_base ,拆解后的文本字符串为["my", "name", "is", "Li", "H", "ua", "!"] 。token 编码表示为[2465, 836, 374, 14851, 39, 4381,0] 。
在 LangChain 中,用 CharacterTextSplitter.from_tiktoken_encoder() 按 token 数拆分:
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", # 编码方式
chunk_size=200, # 每块最多 200 个 token
chunk_overlap=50, # 重叠 50 个 token
)
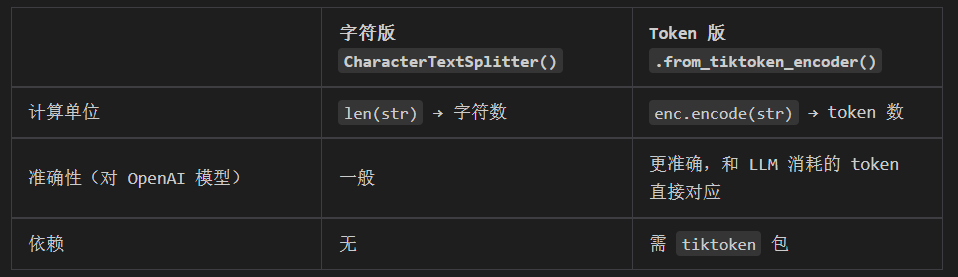
texts = text_splitter.split_documents(data)和基于字符长度拆分的区别:
6.2.3 硬性约束长度拆分 — RecursiveCharacterTextSplitter
前面两种都允许超长块(为了语义完整)。如果你要求任何块都不能超过指定大小,用这个RecursiveCharacterTextSplitter.from_tiktoken_encoder 方法,它会严格遵守对块大小的硬约束
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=100,
chunk_overlap=0,
)
texts = text_splitter.split_documents(data)
输出(严格不超 100 token):

注意第二块和第三块的关系: "加深对 Java" → "编程语言和相关技术的理解..." ,句子被硬生生截成两半。没有 chunk_overlap 时,检索可能漏掉信息。
对比:

你的场景:
├─ 一般情况 → CharacterTextSplitter.from_tiktoken_encoder()(Token 版)
│ 理由:和 LLM 消耗对齐,语义完整
│
├─ 上下文窗口紧,必须严格限制 → RecursiveCharacterTextSplitter
│ 理由:绝不让任何块超限
│
└─ 不需要 tiktoken 依赖 → CharacterTextSplitter()(字符版)
理由:最简单,零额外依赖
chunk_size 决定块的大小,chunk_overlap 决定相邻块的重叠量。文本分割器优先保语义完整,RecursiveCharacterTextSplitter 才做硬性截断。
6.3 特殊文档结构拆分
前面的 CharacterTextSplitter 和 RecursiveCharacterTextSplitter 是通用分割器——它们把文本当"一大段字符"来切,不关心内容是什么。
但对代码、Markdown、HTML 这类有结构的文本,用理解语法的专用分割器效果更好。
对于这类代码等特殊文本,可以尝试使用 Language 提供的不同的分割器(如PythonCodeTextSplitter 、HTMLHeaderTextSplitter 等)效果会更好,它会理解代码的
语法结构。这里了解下常见的拆分原则即可: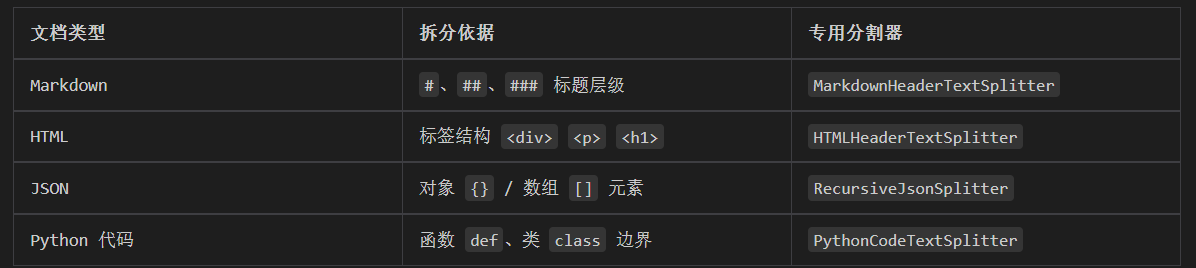
这里我们以 Python 代码举例,其他的使用姿势可以参考官网接口,实际上用法与我们上面讲解的类似。
from langchain_text_splitters import PythonCodeTextSplitter
PYTHON_CODE = """
def hello_world():
print("Hello, World!")
def hello_python():
print("Hello, Python!")
"""
python_splitter = PythonCodeTextSplitter(
chunk_size=50,
chunk_overlap=0
)
python_docs = python_splitter.create_documents([PYTHON_CODE])
for doc in python_docs[:2]:
print(doc)PythonCodeTextSplitter 理解了 def 的语法意义,以函数为边界切分,而不是在代码中间某个字符位置截断。每个函数单独成块,语义完整。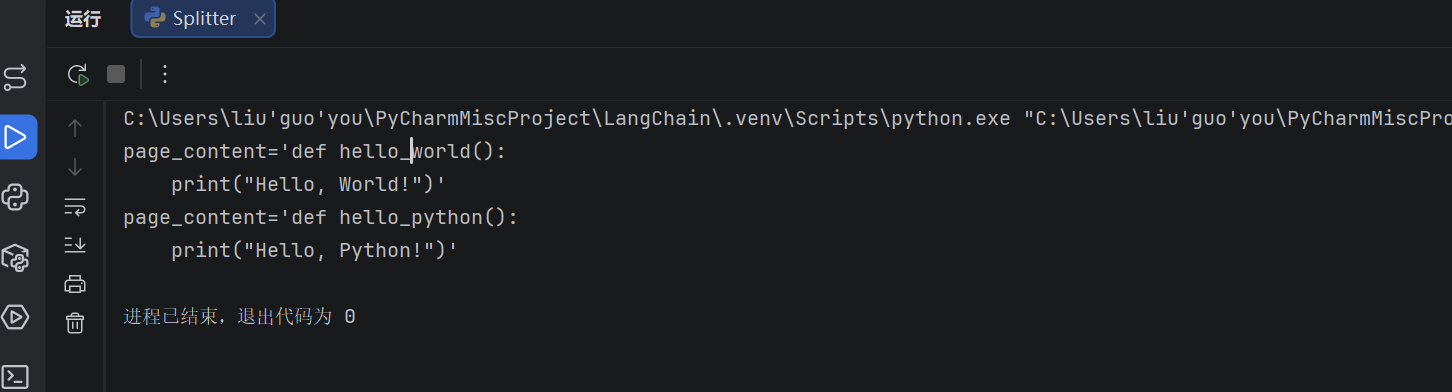
你的文档类型:
├─ 纯文本、文章、聊天记录 → CharacterTextSplitter / RecursiveCharacterTextSplitter
├─ Markdown → MarkdownHeaderTextSplitter(按标题层级分块)
├─ HTML → HTMLHeaderTextSplitter(按标签结构分块)
├─ Python / JS / Java 等代码 → PythonCodeTextSplitter 或对应语言的专用分割器
└─ JSON 数据 → RecursiveJsonSplitter

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)