PLRDiff:基于低秩扩散模型的无监督高光谱全色锐化-Information Fusion2024
Unsupervised hyperspectral pansharpening via low-rank diffusion model
PLRDiff:基于低秩扩散模型的无监督高光谱全色锐化
期刊:Information Fusion
论文链接:Unsupervised hyperspectral pansharpening via low-rank diffusion model - ScienceDirect
年份:2024
关键词:高光谱图像全色锐化,扩散模型

创新点
1. 将低秩子空间表示与预训练扩散模型结合,用低维基张量代替完整高光谱图像建模
这篇文章最核心的思想是:不要让扩散模型直接生成完整的高光谱图像。
高光谱图像通常包含上百个波段,如果直接对完整高光谱数据建模,计算量很大,而且不同数据集的光谱维度也不统一。作者利用高光谱图像在光谱维度上的低秩特性,将高分辨率高光谱图像表示为一个低维基张量和一个系数矩阵的乘积:
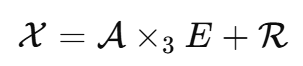
其中,A是低维基张量,E是光谱系数矩阵,R 是残差项。这样,扩散模型只需要恢复低维的 A,而不是直接恢复完整的 X。论文明确指出,低维基张量仍然处在图像域中,因此可以利用预训练遥感扩散模型来捕获其空间结构先验。
这个设计很聪明:
扩散模型负责空间结构,低秩系数负责光谱恢复。
2. 提出一种从 LRHS 图像中预估系数矩阵 EEE 的方法,避免依赖 HRHS 真值
在高光谱全色锐化任务中,真实的 HRHS 图像是未知的,输入只有低分辨率高光谱图像 LRHS 和高分辨率 PAN 图像。
作者发现:由于模糊和下采样只作用在空间维度,而不会改变光谱维度上的线性组合关系,因此 HRHS 图像和 LRHS 图像共享同一个系数矩阵 E。
于是,论文先从 LRHS 图像中选取若干代表性波段,构成低维基张量 ![]() ,然后通过最小二乘估计 E:
,然后通过最小二乘估计 E:
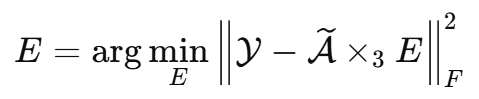
这样就可以在没有 HRHS 真值的情况下,先从观测到的 LRHS 图像中获得光谱组合关系。这个 E 在后续扩散采样过程中保持固定,用来把恢复出的低维基张量重新组合成完整高光谱图像。
3. 在扩散反向采样过程中加入 LRHS 和 PAN 的观测一致性约束
PLRDiff 不是让扩散模型自由生成一张图,而是在每一步反向采样中加入两个约束:
- 生成的 HRHS 经过模糊和下采样后,应该接近输入 LRHS;
- 生成的 HRHS 经过光谱响应后,应该接近输入 PAN。
也就是说,扩散模型提供图像先验,观测约束负责把生成结果拉回真实输入对应的解空间。论文将这种思想写成条件反向 SDE,并用 LRHS/PAN 一致性梯度来引导采样。
一句话概括:
PLRDiff 不是直接训练一个端到端融合网络,而是用预训练扩散模型提供图像先验,再用物理退化模型约束采样过程。
方法简介
这篇文章研究的是 高光谱全色锐化,即利用低分辨率高光谱图像和高分辨率全色图像,恢复高空间分辨率、高光谱分辨率的 HRHS 图像。
输入为:
![]()
表示低分辨率高光谱图像 LRHS;
![]()
表示高分辨率 PAN 图像;
目标是恢复:
![]()
即高分辨率高光谱图像 HRHS。
传统方法通常依赖手工先验,例如 TV 正则、低秩约束、稀疏约束等;深度学习方法虽然效果强,但往往需要大量配对训练数据,而且跨数据集泛化能力较弱。PLRDiff 想解决的问题就是:
如何在不使用配对训练数据的情况下,利用预训练扩散模型和物理退化约束,实现高质量的高光谱全色锐化?
一、这篇文章到底想解决什么问题?
作者认为,现有高光谱全色锐化方法主要有两个问题。
第一个问题是:传统 Bayesian / model-based 方法依赖手工设计先验。
这类方法通常会显式建模 LRHS、PAN 与 HRHS 之间的退化关系,然后加入图像先验求解优化问题。优点是解释性强、泛化能力好;缺点是手工设计的先验通常不够强,很难完整描述复杂遥感图像的空间结构。
第二个问题是:深度学习方法依赖大量配对训练数据,泛化能力不足。
监督深度网络通常需要构造 LRHS/PAN/HRHS 训练对,然后学习从输入到输出的映射。但不同高光谱数据集之间光谱范围、波段数、空间纹理差异很大,训练好的网络容易在跨数据集测试时性能下降。
所以作者提出 PLRDiff,试图结合两类方法的优点:
- 像 Bayesian 方法一样,保留物理退化模型和观测一致性;
- 像深度生成模型一样,利用扩散模型提供更强的图像先验;
- 同时通过低秩子空间表示,避免扩散模型直接建模上百个高光谱波段。
二、整体框架:PLRDiff 是怎么搭起来的?
论文图 1 给出了 PLRDiff 的整体流程。整个方法可以分成三个阶段:
- 从 LRHS 图像中估计系数矩阵 E
- 利用预训练扩散模型恢复低维基张量 A
- 由 A×3E+R 重构 HRHS 图像
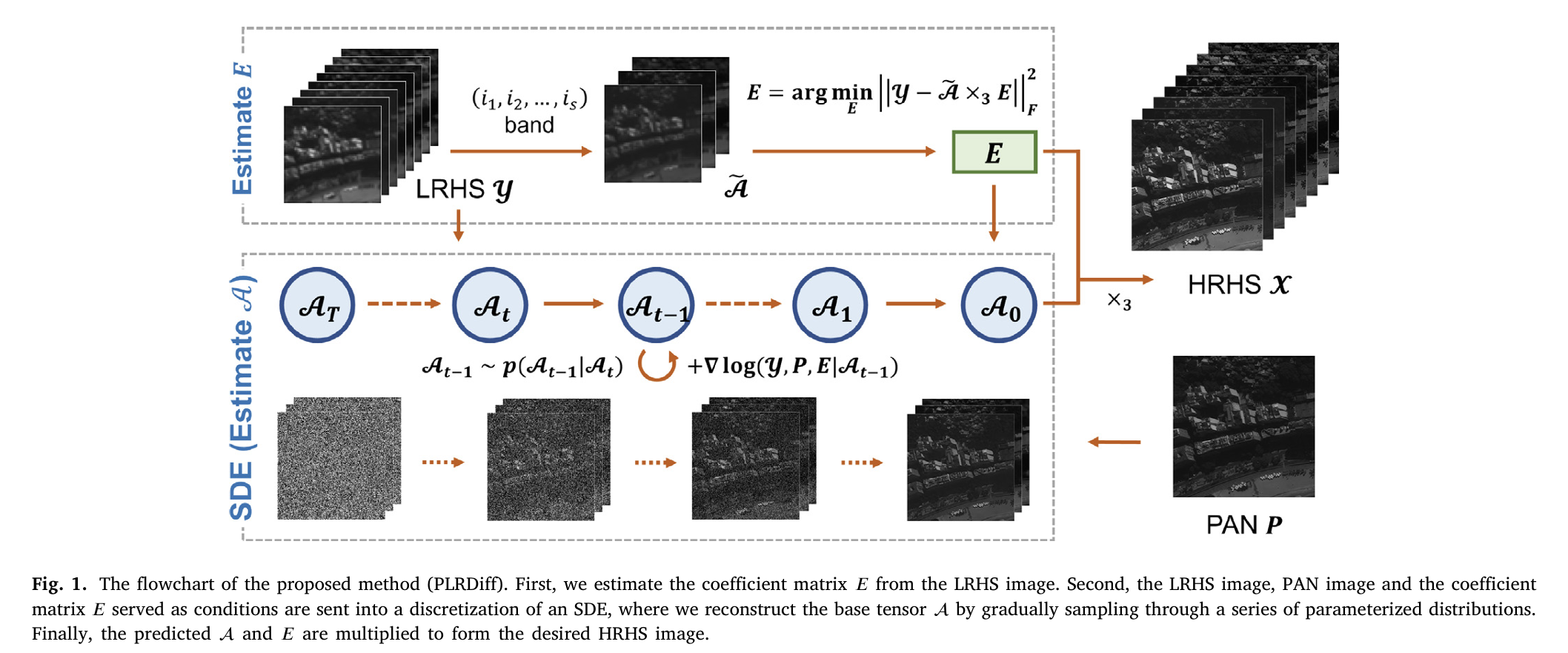
整体逻辑如下:
![]()
先从 LRHS 图像中选取若干代表波段,构成低分辨率基张量 ![]() ,并估计 E。
,并估计 E。
然后从随机噪声开始: ![]()
通过扩散反向采样逐步恢复:
![]()
在每一步采样中,都用 LRHS 和 PAN 的一致性约束修正采样方向。
最后得到:![]()
这就是最终恢复出的 HRHS 图像。
三、低秩分解:为什么可以只恢复 A?
高光谱图像虽然波段很多,但不同波段之间存在很强相关性,因此在光谱维度上通常具有低秩特性。
论文将 HRHS 图像分解为: X=A×3E+R
其中:

展开成 mode-3 矩阵形式:
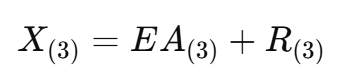
这里 ![]() ,而
,而 ![]() 。
。
也就是说,完整高光谱图像的 S 个波段可以由 s 个代表波段线性组合得到。
论文进一步让 A 直接由 HRHS 图像中的若干波段构成:
![]()
也就是:![]()
这个设计保证了 A 仍然是图像域中的数据,而不是抽象特征。因此,预训练遥感扩散模型可以直接被用来建模 A的图像先验。
四、系数矩阵 E 是怎么估计的?
如果 HRHS 图像 X 已知,那么 E 可以通过下面的最小二乘问题得到:
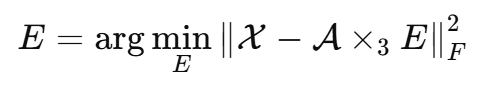
但是在真实任务中,X 不可见。
作者利用 LRHS 和 HRHS 的退化关系:![]()
其中 D 是下采样,B 是模糊操作。
将低秩分解代入:
![]()
由于 D 和 B 是空间维度操作,而 E 是光谱维度线性组合,因此可以写成:
![]()
令:
![]()
则有:
![]()
这说明 LRHS 和 HRHS 共享同一个系数矩阵 E。
而 ![]() 可以直接从 LRHS 图像中选取相同索引的波段得到:
可以直接从 LRHS 图像中选取相同索引的波段得到:
![]()
因此 E 可以通过 LRHS 图像估计:
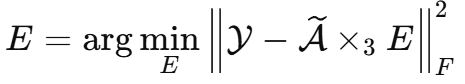
论文中波段索引采用等间隔选取:
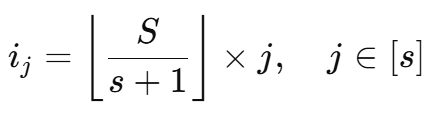
比如当 S=128,s=3 时,大致会选取第 32、64、96 个波段作为代表波段。
这个部分是 PLRDiff 的关键之一:
它不需要 HRHS 真值,就能从 LRHS 中获得光谱重建所需的系数矩阵。
五、残差 R 怎么处理?
低秩分解不能完全表示所有光谱细节,因此论文引入残差项: R
根据前面的推导,LRHS 中低秩部分为:
![]()
于是有:
![]()
因此,残差 R 可以通过下面的问题估计:
![]()
论文中给出两个版本:
- PLRDiff-plain:直接令 R=0
- PLRDiff-res:通过梯度下降估计 R
实验结果显示,PLRDiff-res 通常优于 PLRDiff-plain,说明残差项对提升重建质量有帮助。
六、扩散模型在这里到底干什么?
PLRDiff 使用的是一个预训练的无条件遥感扩散模型。
普通 DDPM 的正向过程是不断给图像加噪声:
![]()
当 t=T 时,图像基本变成高斯噪声:
![]()
反向过程则是从噪声逐步恢复图像:
![]()
如果只是普通扩散模型,它只能生成“像遥感图像”的样本,但不能保证生成结果和输入的 LRHS/PAN 对得上。
所以 PLRDiff 在反向采样中加入了观测约束,使采样目标从无条件分布: p(A)
变成条件分布:![]()
也就是说,模型要生成的不是任意遥感图像,而是必须符合当前 LRHS 和 PAN 观测的基张量。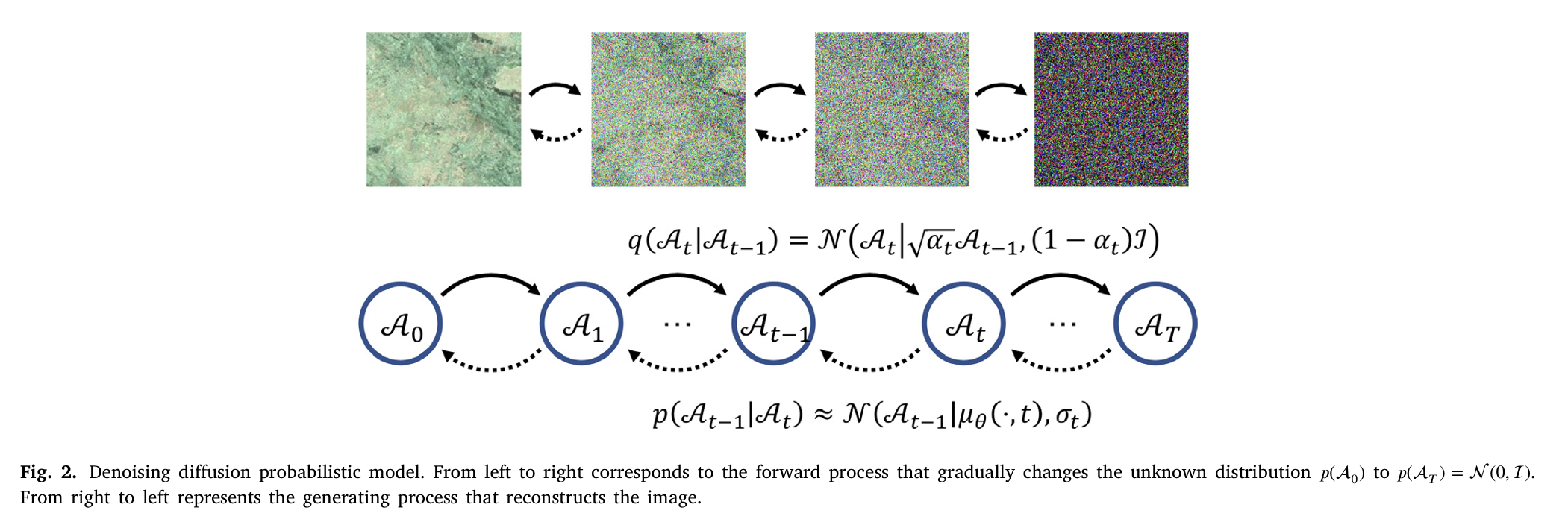
七、条件采样:LRHS 和 PAN 怎么约束扩散过程?
PLRDiff 将条件反向 SDE 写成:
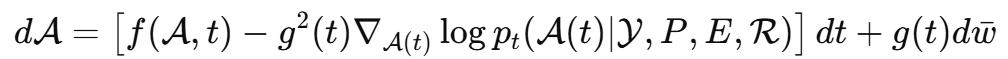
根据贝叶斯分解:
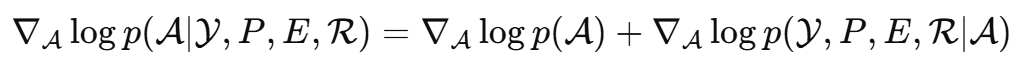
这里可以理解成两部分:
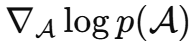 :扩散模型提供的图像先验;
:扩散模型提供的图像先验;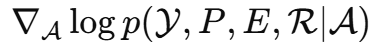 :LRHS 和 PAN 提供的数据一致性约束。
:LRHS 和 PAN 提供的数据一致性约束。
论文用 Tweedie’s formula 从当前带噪样本估计干净基张量:
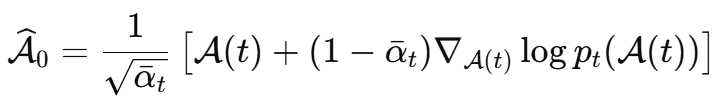
然后构造两个观测误差。
第一个是 LRHS 一致性:
![]()
它要求恢复出的 HRHS 经过模糊和下采样后接近输入 LRHS。
第二个是 PAN 一致性:
![]()
它要求恢复出的 HRHS 经过光谱响应后接近输入 PAN。
最终反向采样可以理解成:
![]()
也就是说:
扩散模型负责让 A看起来像真实遥感图像,
LRHS 约束负责保持光谱一致性,
PAN 约束负责补充高分辨率空间细节。
八、PLRDiff 算法流程
论文 Algorithm 1 可以概括如下:
- 输入 LRHS 图像 Y、PAN 图像 P、波段索引 (i1,⋯ ,is)、参数 η1,η2、扩散步数 T;
- 从 LRHS 中构造
 ;
; - 通过最小二乘估计系数矩阵 E;
- 估计残差 R,或者直接设 R=0;
- 从高斯噪声初始化 AT;
- 从 t=T到1逐步反向采样;
- 每一步先利用扩散模型去噪,再利用 LRHS/PAN 约束修正;
- 最后输出:
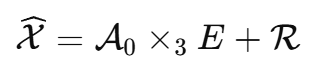
这个流程的本质是: 低秩分解+扩散先验+物理退化约束
九、实验部分:效果到底怎么样?
9.1 实验数据集
论文在三个常用数据集上进行实验:
- Chikusei
- Houston
- Pavia Center
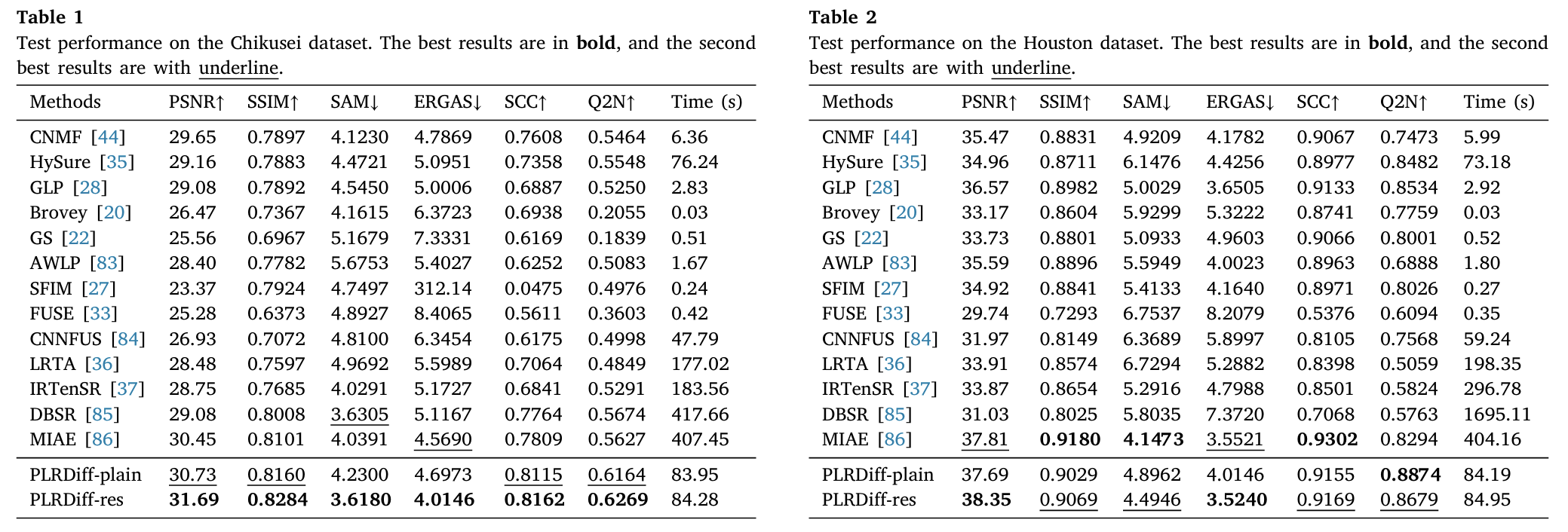
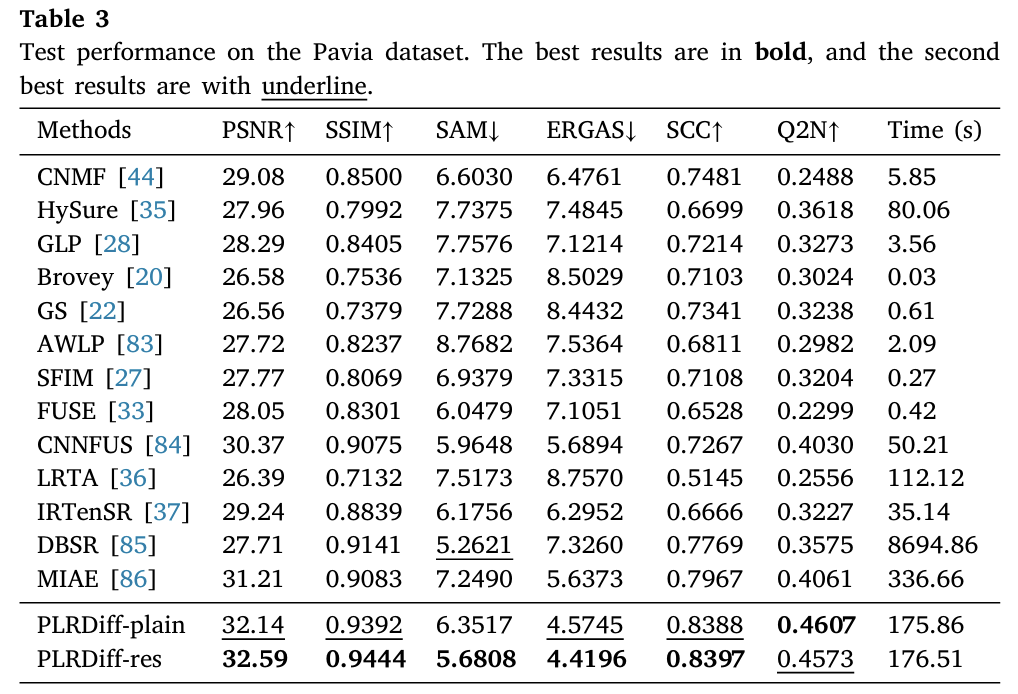
其中 Chikusei 和 Houston 按 Wald protocol 构造 LRHS 和 PAN,Pavia Center 使用数据集中提供的 HRHS、LRHS 和 PAN。论文使用的评价指标包括 PSNR、SSIM、SAM、ERGAS、SCC 和 Q2N。
参数设置方面:η1=2,η2=2,T=500,s=3
其中 η1,η2 是两个观测约束权重,T是扩散步数,s是低秩维度。论文通过参数敏感性实验发现,当 η1,η2≥1 时,模型表现相对稳定。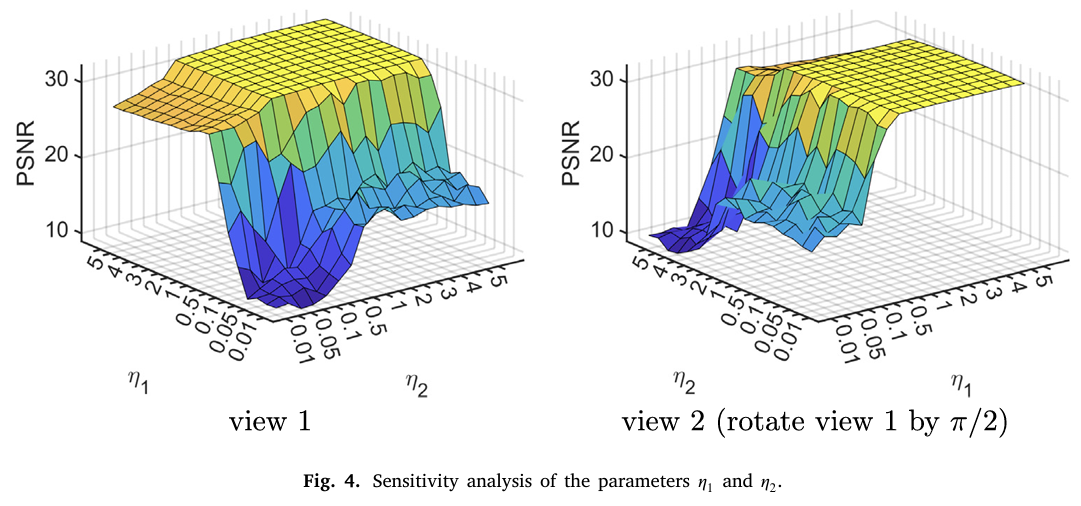
9.2 与传统方法和无监督方法比较
论文与 12 个方法进行比较,包括:CNMF,HySure,GLP,Brovey,GS,AWLP,SFIM,FUSE,CNNFUS,LRTA,IRTenSR,DBSR,MIAE
其中既有传统 CS/MRA 方法,也有 Bayesian 方法,还有 deep image prior 相关方法。
从结果来看,PLRDiff-res 在三个数据集上整体表现较强。比如:
在 Chikusei 上:
PSNR=31.69,SSIM=0.8284,SAM=3.6180,ERGAS=4.0146
在 Houston 上:
PSNR=38.35,SSIM=0.9069,SAM=4.4946,ERGAS=3.5240
在 Pavia 上:
PSNR=32.59,SSIM=0.9444,SAM=5.6808,ERGAS=4.4196
PLRDiff-res 通常优于 PLRDiff-plain,说明残差估计确实带来了收益。论文也指出,PLRDiff 在 PSNR、Q2N、SCC 等指标上的优势说明预训练扩散模型有效恢复了空间细节,而低秩表示和系数矩阵估计帮助模型保留了光谱信息。
9.3 可视化结果
论文展示了 Chikusei、Houston 和 Pavia 三个数据集上的伪彩色可视化结果。



从视觉效果上看,一些传统方法会出现明显模糊或颜色失真,而 PLRDiff 的结果在空间细节和光谱保持上更加稳定。
论文还展示了沿光谱维度的误差曲线,说明 PLRDiff 能较好重建光谱信息。同时,论文对比了预测的 base tensor A 和真实 HRHS 中对应波段,结果显示扩散模型生成的基张量在空间结构和光谱表现上都比较接近真实图像。
十、泛化能力实验:PLRDiff 相比监督深度网络有什么优势?
论文还专门做了泛化能力实验。
作者选择了一些监督深度学习方法进行比较,包括 HyperPNN、FusionNet、DBDENet、DSNet、HyperTrans、MTNet 和 MDANet。这些监督方法在 Pavia training dataset 上训练,然后测试到 Chikusei、Houston 和 Pavia 上。结果显示,监督模型在跨数据集时性能下降明显,而 PLRDiff 在 Chikusei 和 Houston 上仍然保持较高性能。
例如在 Houston 数据集上:
- MDANet 的 PSNR 为 28.58;
- HyperTrans 的 PSNR 为 27.99;
- PLRDiff-res 的 PSNR 达到 38.35。
这说明 PLRDiff 不依赖某个数据集上的成对训练样本,而是通过预训练扩散先验和显式退化模型进行无监督恢复,因此具有更好的跨数据集泛化能力。
这个实验是文章里非常重要的一部分,它支撑了作者的核心观点:
监督深度学习方法容易受到训练集和测试集分布差异影响,而 PLRDiff 更适合处理不同数据集、不同退化条件下的高光谱全色锐化任务。
十一、消融实验:扩散先验真的有用吗?
为了证明扩散先验不是摆设,论文设计了两个替代方法:
- PLR-GD:去掉扩散先验,只用观测一致性约束做梯度下降;
- PLR-TV:用传统 TV 正则替代扩散先验。
对应优化问题大致可以写成:
![]()
实验发现,PLRDiff-plain 在所有设置下都优于 PLR-GD 和 PLR-TV。论文指出,PLR-GD 对初始化非常敏感,容易陷入不理想的局部最优;PLR-TV 相对稳定一些,但提升有限;相比之下,扩散先验带来的性能收益更明显。
这个实验说明:
仅靠 LRHS/PAN 观测约束不足以解决病态逆问题,强图像先验对于高质量恢复非常关键。
十二、关于系数矩阵 EEE 的讨论
论文还讨论了系数矩阵 EEE 的影响。
作者测试了两种替代方案:
- 用 SVD 得到 E;
- 随机生成 E。
结果发现,即使 EEE 设置不合理,扩散模型和观测约束仍然能恢复一些空间结构,但光谱信息会被明显破坏。原因是 EEE 主要决定不同波段之间的光谱组合关系,如果 EEE 与真实基张量不匹配,那么最终 HRHS 的光谱保真度会受到严重影响。
这个结论很重要:
扩散模型可以提供空间先验,但光谱信息能不能保住,很大程度上取决于 EEE 是否估计准确。
这也是 PLRDiff 的低秩设计为什么要强调“从 LRHS 中估计 EEE”的原因。
十三、扩散步数 T 的影响
论文还测试了不同扩散步数 T 对性能和时间的影响。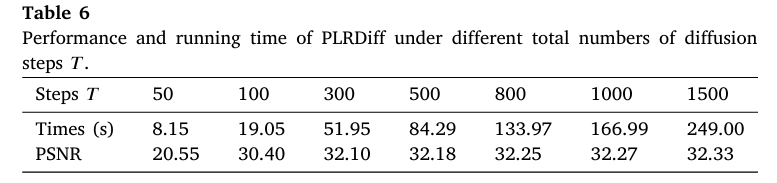
当 T 从 50 增加到 1500 时,PSNR 会逐步提升,但计算时间也明显增加。比如论文表 6 显示,在 Chikusei validation dataset 上:
- T=50:时间约 8.15s,PSNR 为 20.55;
- T=500:时间约 84.29s,PSNR 为 32.18;
- T=1500:时间约 249.00s,PSNR 为 32.33。
可以看到,当 T 超过 500 后,性能提升已经很有限,但时间成本继续增加。因此论文最终选择 T=500作为精度和效率之间的折中。
十四、总结
PLRDiff 提出了一种非常有意思的无监督高光谱全色锐化框架。
它的核心思想可以概括为三句话:
- 用低秩子空间表示降低高光谱扩散建模难度;
- 用预训练遥感扩散模型恢复低维基张量;
- 用 LRHS 和 PAN 的物理退化一致性约束引导反向采样。
最终,PLRDiff 实现了:低秩表示+扩散先验+观测一致性→HRHS重建
这篇文章最大的启发在于:扩散模型不一定要直接生成完整的高维高光谱图像,可以只生成低维子空间中的图像基底,再通过物理模型和系数矩阵恢复完整光谱。
对于后续做 HSI-MSI 融合、文本引导融合、退化感知融合等任务,这种思路都很值得借鉴。尤其是“扩散先验只负责低维空间结构,光谱一致性由显式物理模型保护”这个设计,非常适合高光谱图像重建类任务。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)