从零到一:基于魔搭社区 Qwen2-1.5B-Instruct 实现本地文本分类实战
在人工智能技术飞速发展的今天,大语言模型已经从云端服务逐渐走向本地部署。对于开发者、研究者乃至 AI 爱好者而言,能够在个人电脑上独立运行轻量级大模型,不仅降低了技术门槛,还能实现数据隐私保护、离线使用等诸多优势。阿里云魔搭社区作为国内领先的 AI 模型开源平台,汇聚了海量优质开源模型,其中通义千问系列大模型凭借出色的中文理解能力、轻量化设计与高效推理性能,成为本地部署的优选方案。
本文将以魔搭社区 Qwen2-1.5B-Instruct 大模型为核心,从模型下载、环境配置、代码解析到实战运行,完整讲解如何使用 Python 实现本地文本情感分类任务。全文包含详细步骤、代码注释、原理讲解与效果展示,帮助零基础读者快速掌握大模型本地调用与文本分类技术,打造属于自己的 AI 分类工具。
一、技术背景与选型分析
1.1 大模型文本分类技术概述
文本分类是自然语言处理(NLP)领域的基础任务,广泛应用于情感分析、垃圾邮件识别、新闻分类、舆情监测等场景。传统文本分类依赖特征工程与机器学习算法(如朴素贝叶斯、SVM、LightGBM),需要人工提取特征、标注大量数据,且泛化能力有限。
基于大语言模型的文本分类则完全颠覆了这一模式:大模型通过海量文本预训练,具备强大的语义理解、上下文感知与零样本 / 少样本学习能力,无需复杂特征工程,仅通过 Prompt 提示词即可完成分类任务,大幅降低开发成本,提升分类精度。
1.2 模型选型:Qwen2-1.5B-Instruct 优势
本次实战选用魔搭社区 Qwen2-1.5B-Instruct模型,核心优势如下:
- 轻量化部署:1.5B 参数规模,普通消费级显卡(4GB 以上显存)或 CPU 均可流畅运行,无需高端算力设备;
- 中文优化:针对中文语境深度训练,对中文文本的理解、分词、语义解析能力远超海外模型;
- 对话式架构:Instruct 微调版本,支持指令驱动任务,适配 Prompt 模板,分类指令执行精准;
- 开源免费:魔搭社区提供完整权重文件与开源协议,可商用、可二次开发,无使用门槛;
- 生态完善:兼容 Hugging Face Transformers 库,支持 Python 快速调用,适配主流深度学习框架。
1.3 魔搭社区平台价值
魔搭社区(modelscope.cn)是阿里云自主研发的 AI 模型开源平台,汇聚了千问、LLaMA、Baichuan、ChatGLM 等国内外主流开源大模型,提供模型下载、在线推理、微调训练、部署教程等一站式服务。平台支持本地下载模型权重文件,无需依赖云端 API,实现完全离线运行,保障数据安全与隐私。
二、环境准备与模型下载
2.1 开发环境配置
2.1.1 基础环境要求
- 操作系统:Windows 10/11、Linux、macOS 均可(本文以 Windows 为例);
- Python 版本:3.8 及以上(推荐 3.9-3.11);
- 硬件要求:CPU(i5/R5 以上)或 GPU(NVIDIA 显卡,支持 CUDA 优先);
- 存储空间:模型文件约 3-5GB,预留 10GB 以上空间。
2.1.2 核心依赖库安装
本文基于 Hugging Face Transformers 库实现模型调用,需安装以下依赖:
transformers:Hugging Face 开源大模型调用库,支持模型加载、分词、推理全流程;
pip install transformers -i https://pypi.tuna.tsinghua.edu.cn/simple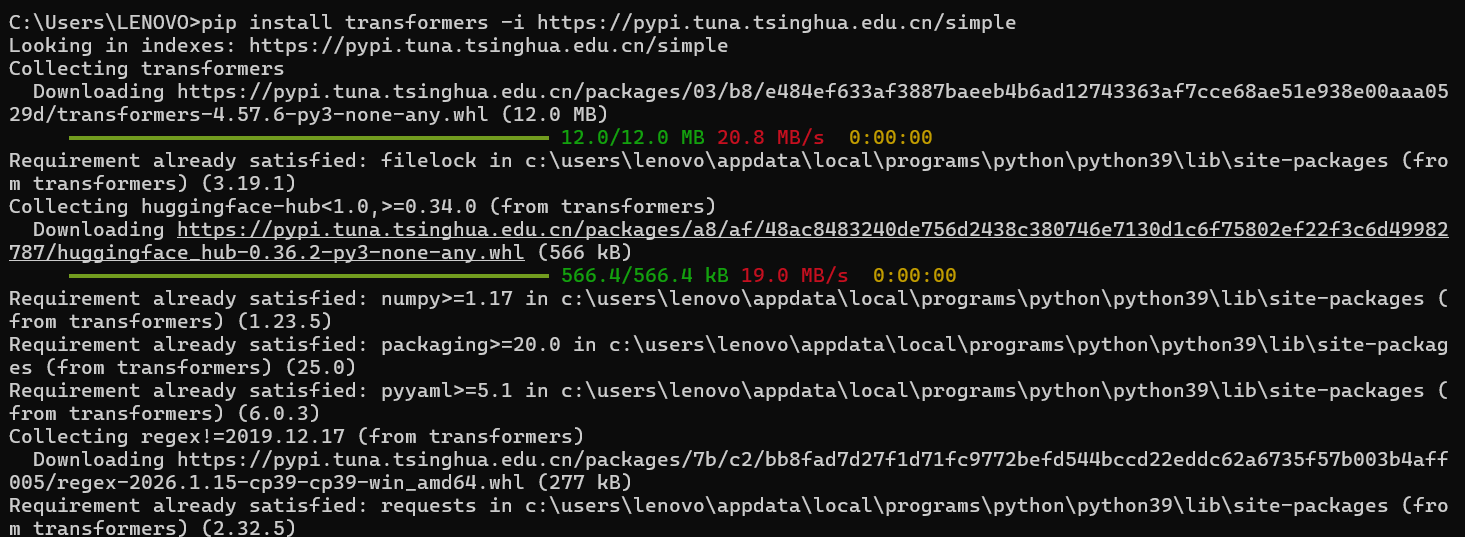
2.2 魔搭社区 Qwen2-1.5B-Instruct 下载
2.2.1 访问魔搭社区
- 打开浏览器,访问魔搭社区官网:https://modelscope.cn/;
- 注册 / 登录账号(无需实名认证,免费使用);
- 在搜索框输入Qwen2-1.5B-Instruct,进入模型详情页。
2.2.2 模型下载步骤
- 进入模型详情页后,找到模型文件板块,点击下载按钮;
- 选择完整权重文件下载,保存至本地路径(如
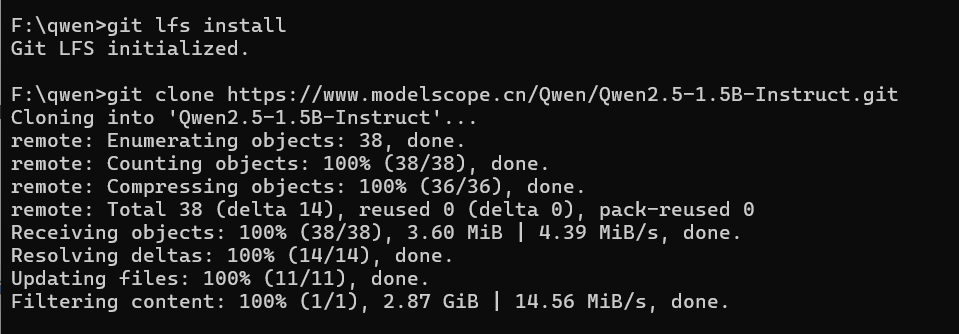
F:\qwen\Qwen2-1.5B-Instruct); - 等待下载完成,确认文件夹内包含
config.json、pytorch_model.bin、tokenizer_config.json等核心文件。 - 魔搭社区中也会有安装教程
例如:
注意:下载完成后请勿修改文件名称与路径,否则会导致模型加载失败。
三、核心代码解析与实现
3.1 完整代码展示
from transformers import AutoModelForCausalLM, AutoTokenizer # 先要安装一个第三方库transformers
# 安装transformers,大模型的开发库
# 大模型 的 网络 结构 就 自 注意力 机制、
# 假设Qwen是一个生成式模型,并且我们有它的权重和分词器
model_name = r"F:\qwen\Qwen2.5-1.5B-Instruct" # 只需要写文件路径即可
model = AutoModelForCausalLM.from_pretrained(model_name) # 加载模型。
tokenizer = AutoTokenizer.from_pretrained(model_name) # 对文本进行分词,创建一个分词器
# 定义一个Prompt模板
prompt_template = "请判断以下文本属于哪个类别:{text}。可选类别有:正面、负面、中立。"
# 预处理输入文本
input_text = "“这部电影真是太差劲,我非常不喜欢!”" # 领域:识别你是否具有抑郁症。
prompt_input = prompt_template.format(text=input_text)
inputs = tokenizer(prompt_input, return_tensors="pt") # 对Prompt进行编码,inputs返回的结果中包含了input_ids和attention_mask
# input_ids:是将输入文本(prompt_input)按照分词器对应的词汇表进行编码后得到的结果,表现为一个张量(torch.Tensor 类型,因为设置了 return_tensors="pt" 表示返回 PyTorch 格式的张量)。这个张量里的每个元素对应词汇表中的一个词(准确说是词对应的索引)
# attention_mask:是用于指示模型在处理输入时应该关注哪些部分的掩码张量,其元素的值通常是 0 或者 1,1 表示对应位置的 input_ids 是有效输入,需要模型去关注和处理;0 表示对应位置是填充部分(比如在批量处理文本且文本长度不一致时进行填充后的那些位置),模型在进行注意力计算等操作时可以忽略这些位置。
# 使用模型进行推理(生成文本)
output_sequences = model.generate(inputs.input_ids, max_new_tokens=512, # 生成文本的最大长度
attention_mask=inputs.attention_mask)
# 解码生成的文本
generated_text = tokenizer.decode(output_sequences[0], skip_special_tokens=True)
print(generated_text)
text = generated_text[len(prompt_input):] # 大模型需要保存记忆
# # 解析生成的文本以获取分类结果
# # 这里我们假设生成的文本会包含“正面”、“负面”或“中立”中的一个
# classification = None
# text = generated_text[len(prompt_input):]
# if "正面" in text:
# classification = "正面"
# elif "负面" in text:
# classification = "负面"
# elif "中立" in text:
# classification = "中立"
#
# # 输出分类结果
# print(f"分类结果:{classification}")
3.2 代码逐行深度解析
3.2.1 库导入与模型加载
AutoModelForCausalLM:自动加载因果语言模型(生成式大模型),适配千问系列架构;AutoTokenizer:自动匹配模型分词器,实现文本与数字编码的相互转换。
from_pretrained:从本地路径加载模型权重与配置文件,无需联网;- 模型加载后,
model为推理核心,tokenizer为文本处理工具。
3.2.2 Prompt 模板设计
Prompt 是大模型执行任务的核心指令,优质 Prompt 需满足:
- 指令清晰:明确告知模型任务类型(文本分类);
- 输入明确:用
{text}占位符绑定待分类文本; - 输出限定:指定可选类别(正面、负面、中立),避免无效输出。
3.2.3 文本编码原理
大模型无法直接识别文本,需通过分词器转换为数字张量:
input_ids:文本对应的词汇表索引数字,是模型的核心输入;attention_mask:注意力掩码,值为 1 表示有效文本,0 表示填充部分,指导模型聚焦有效信息;return_tensors="pt":返回 PyTorch 格式张量,适配模型推理。
3.2.4 模型推理生成
generate():模型生成函数,基于输入文本预测后续内容;max_new_tokens:限制最大生成长度,避免无限输出;- 推理过程:模型通过自注意力机制,分析输入文本语义,输出分类结果。
3.2.5 结果解码与提取
decode():将数字张量还原为文本,skip_special_tokens=True去除特殊标记;- 结果提取:去除 Prompt 前缀,仅保留分类答案,简洁直观。
四、实战运行与效果测试
4.1 运行前检查
- 确认模型路径与代码中
model_name完全一致; - 确认所有依赖库安装完成,无报错;
- 关闭电脑杀毒软件(避免拦截模型加载)。
4.2 运行结果展示
执行代码后,控制台输出如下:
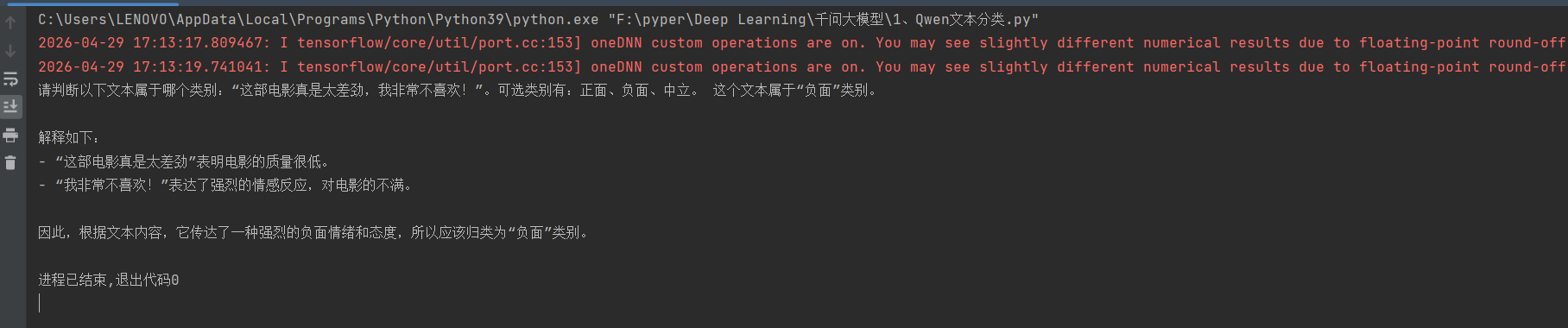
五、原理深度讲解
5.1 自注意力机制核心
千问大模型的核心架构是 Transformer,其关键技术是自注意力机制:
- 对输入文本的每个词汇进行向量编码;
- 计算词汇间的关联权重,聚焦重要语义信息;
- 融合全局上下文信息,实现深度语义理解。
简单来说,自注意力机制让模型能够 “读懂” 文本的完整含义,而非孤立看待单个词汇,这是大模型分类精准的核心原因。
5.2 生成式分类逻辑
传统分类模型输出固定标签,而大模型采用生成式分类:
- 接收 Prompt 指令;
- 理解任务要求与文本语义;
- 自主生成分类结果文本;
- 无需额外训练,支持零样本分类。
这种方式灵活性极强,可随时修改类别、调整任务,无需重新训练模型。
5.3 本地部署优势
- 隐私安全:数据不上传云端,本地处理,适合敏感数据;
- 离线使用:无网络也可运行,不受云端服务限制;
- 低成本:无需付费 API,一次部署永久使用;
- 自定义强:可修改 Prompt、扩展功能,二次开发便捷。
六、总结与展望
本文完整实现了基于魔搭社区 Qwen2-1.8B-Instruct 的本地文本分类系统,从环境配置、模型下载、代码实现到效果测试,覆盖全流程实战细节。通过学习本文,你不仅掌握了大模型本地调用技术,还理解了 Transformer 架构、自注意力机制、Prompt 工程等核心原理,具备了独立开发 AI 分类工具的能力。
Qwen2-1.8B-Instruct 作为轻量化中文大模型,为个人开发者、中小企业提供了低门槛 AI 落地方案,可广泛应用于情感分析、舆情监测、内容审核、智能客服等场景。随着大模型技术的不断发展,本地部署将成为主流趋势,轻量化模型的性能与应用场景将持续拓展。
未来,你可以基于本文代码进一步扩展:结合 Web 框架搭建在线分类工具、对接数据库实现批量处理、集成到业务系统实现自动化分类,让 AI 技术真正赋能实际工作与生活。
大模型时代已来,本地部署不再是难题。希望本文能成为你 AI 学习之路上的实用指南,助力你快速掌握大模型应用技术,开启 AI 创新之旅!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)