LangChain vs LlamaIndex:从编排到数据,一文搞清核心区别
目录
四、用 LangChain 的知识理解 LlamaIndex
十一、给 LangChain 学习者的 LlamaIndex 学习路线
摘要
最近在学习 LlamaIndex 时,我有一个很直接的感受:它和 LangChain 真的很像。两者都能做文档加载、文本切分、Embedding、向量检索、RAG、Agent 和工具调用。如果只看入门示例,甚至会觉得它们是在重复造轮子。
但继续往下学之后会发现,二者虽然能力有重叠,设计重心却截然不同。LangChain 更像是一个 LLM 应用编排框架,擅长把模型、Prompt、工具、Agent 和流程串起来;LlamaIndex 更像是一个数据增强框架,擅长把私有数据组织成 LLM 可以高质量使用的上下文。
本文从一个已经学过 LangChain 的视角,梳理两者的相似点、核心差异、概念映射、使用场景以及学习路线。
一、核心区别:一句话版本

先给两个最直观的类比:
LangChain:让 LLM 会做事。 LlamaIndex:让 LLM 会用你的数据。
LangChain 擅长编排行为。 LlamaIndex 擅长组织知识。
用更工程化的方式理解:
LangChain = 应用编排层 LlamaIndex = 数据上下文层
这是贯穿全文最核心的一条线索,后面所有内容都围绕这个区别展开。
二、为什么我会觉得它们很像?
因为二者都处在 LLM 应用开发这一层,都在解决同一个问题:
如何把大语言模型从一个聊天接口,变成能够处理真实任务的应用系统。
因此,它们都会涉及很多相同概念:
-
文档加载
-
文本切分
-
Embedding
-
向量数据库
-
Retriever
-
RAG
-
Agent
-
Tool Calling
-
Memory
-
Workflow
比如一个最常见的 RAG 应用,基本流程在两个框架里都差不多:
加载文档 -> 切分文本 -> 生成向量 -> 存入向量库 -> 检索相关内容 -> 交给 LLM 回答
相似的是"能力模块",不同的是"默认思路"。
三、核心区别:完整对比
| 维度 | LangChain | LlamaIndex |
|---|---|---|
| 核心定位 | LLM 应用编排框架 | 数据增强型 LLM 应用框架 |
| 默认入口 | Prompt、模型、工具、Agent | 数据、文档、索引、检索 |
| 强项 | Agent、工具调用、流程编排、LangGraph | RAG、文档索引、检索优化、数据连接 |
| 典型问题 | LLM 如何完成一个多步骤任务? | LLM 如何使用我的私有数据? |
| 代表抽象 | Chain、Agent、Tool、Runnable、Graph | Document、Node、Index、Retriever、QueryEngine |
| 复杂工作流 | LangGraph 很强 | Workflows 也能做,但数据场景更自然 |
| RAG 易用性 | 灵活,但经常需要自己拼组件 | 默认体验更顺 |
四、用 LangChain 的知识理解 LlamaIndex
如果你已经学过 LangChain,学习 LlamaIndex 时可以做如下映射:
| LangChain 概念 | LlamaIndex 对应概念 | 理解方式 |
|---|---|---|
| Document | Document / Node | LlamaIndex 更强调 Node,Node 是索引和检索的基本单元 |
| TextSplitter | NodeParser | 都是把长文档切成更适合检索的小片段 |
| Embeddings | Embeddings | 都是把文本转换成向量 |
| VectorStore | VectorStore / VectorStoreIndex | LlamaIndex 通常用 Index 做更上层的封装 |
| Retriever | Retriever | 都负责根据 query 找相关内容 |
| RetrievalQA Chain | QueryEngine | LlamaIndex 中常用 QueryEngine 做问答 |
| ConversationalRetrievalChain | ChatEngine | ChatEngine 更适合多轮对话式检索 |
| Tool | Tool / QueryEngineTool | 可以把查询引擎包装成 Agent 可调用工具 |
| Agent | Agent / AgentWorkflow | 二者都有 Agent,但 LangChain/LangGraph 更偏复杂编排 |
对 LangChain 使用者来说,LlamaIndex 最关键的几个概念是:Document、Node、Index、Retriever、QueryEngine、ChatEngine。理解了这几个,就基本抓住了 LlamaIndex 的主线。
五、LlamaIndex 的数据处理主线

学习 LlamaIndex 时,不建议一开始就从 Agent 入手。更推荐先抓住它的数据处理主线:
Data Source → Document → Node → Index → Retriever → QueryEngine / ChatEngine → Response
1. Document
Document 是数据进入 LlamaIndex 后的基础表示,相当于"原始资料进入系统后的统一格式"。
常见数据源:PDF、Markdown、网页、Notion 页面、数据库记录、Slack 消息、本地文本文件等。
2. Node
Node 是经过切分后的文档片段。LangChain 里常说 chunk,LlamaIndex 里更常见的说法是 Node。
为什么需要 Node?因为 LLM 和向量检索通常不适合直接处理整篇长文档,需要先切成较小的片段,再做 embedding、索引和检索。
3. Index
Index 是 LlamaIndex 里的核心抽象,负责组织数据,让后续查询变得高效。
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
这几行代码背后通常包含:文档读取 → 文档解析 → 节点切分 → embedding → 向量存储 → 构建可查询结构。
对比 LangChain 的等价写法,会感受到 LlamaIndex 把 RAG 数据侧流程封装得更自然:
# LangChain 的等价写法(需要手动拼组件)
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
loader = DirectoryLoader("data")
docs = loader.load()
splitter = RecursiveCharacterTextSplitter()
chunks = splitter.split_documents(docs)
vectorstore = Chroma.from_documents(chunks, OpenAIEmbeddings())
同样的功能,LlamaIndex 是"声明式的",LangChain 是"拼装式的"。
4. Retriever
Retriever 负责根据用户问题,从索引中找出最相关的 nodes,然后把这些内容作为上下文提供给后续的 LLM。
5. QueryEngine
QueryEngine 不仅负责检索,还会把检索到的内容交给 LLM 合成最终答案。可以把它理解为:
Retriever + Prompt + LLM + Response Synthesis = QueryEngine
query_engine = index.as_query_engine()
response = query_engine.query("LlamaIndex 和 LangChain 有什么区别?")
print(response)
这也是 LlamaIndex 在 RAG 场景中用起来很顺的根本原因。
六、LangChain 的应用编排主线
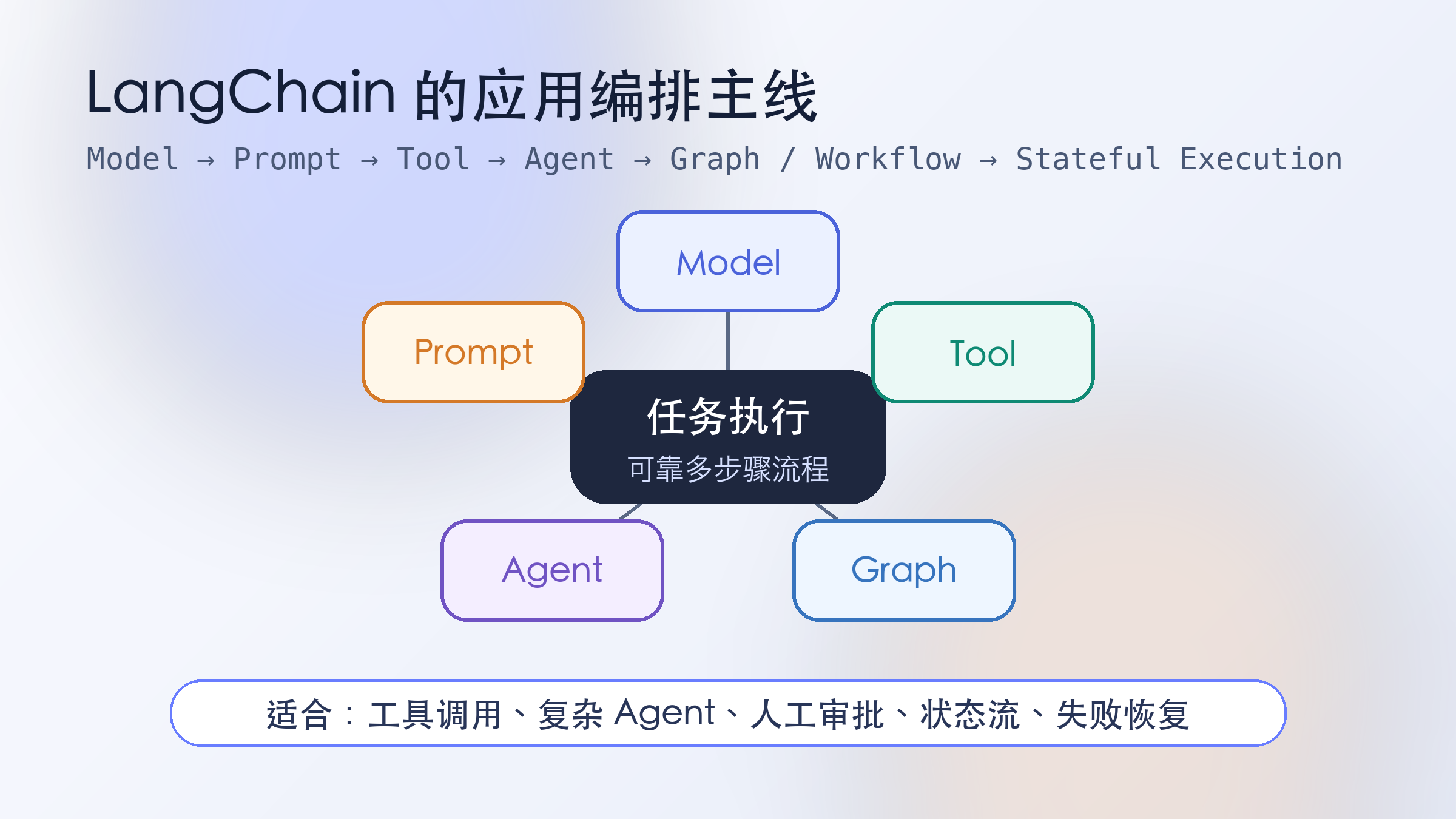
LangChain 的主线更偏应用行为编排:
Model → Prompt → Tool → Agent → Graph / Workflow → Stateful Execution
如果你要做的是:
-
让模型调用搜索工具
-
让模型查询数据库
-
让模型根据任务自动选择工具
-
让流程中间有人类审批
-
让长任务失败后可以恢复
-
构建复杂 Agent 系统
那么 LangChain,尤其是 LangGraph,通常更自然。它更关注的是:
如何让 LLM 在多个工具、多个步骤和多个状态之间可靠地执行任务。
七、RAG 场景下怎么选?
假设要做一个"公司内部知识库问答系统"。
使用 LlamaIndex 的思路
公司文档 -> 加载 -> 解析 -> 切成 nodes -> 构建 index -> 用户 query -> 检索相关 nodes -> 合成答案
LlamaIndex 在这个场景里更顺,因为它天然围绕数据和索引展开,RAG 是它的本职工作。
使用 LangChain 的思路
公司文档 -> loader -> splitter -> vectorstore -> retriever -> prompt -> model -> chain / agent
LangChain 也完全能做,而且灵活度很高。但在很多情况下,你会更明显地感觉自己在"拼组件"。
结论: 如果当前主要目标是做 RAG,尤其是文档问答、知识库检索、多数据源问答,优先考虑 LlamaIndex。
八、Agent 场景下怎么选?
再换一个场景:你要做一个 AI 助手,它需要查询公司知识库、查天气、查数据库、调用内部 API、生成报告,并在关键步骤等待人工确认。
这时候问题就不只是"如何检索文档"了,而是:
如何让 AI 在多个工具之间做决策,并可靠完成多步骤任务。
这类场景下,LangChain / LangGraph 通常更合适。
九、最佳实践:两者组合使用
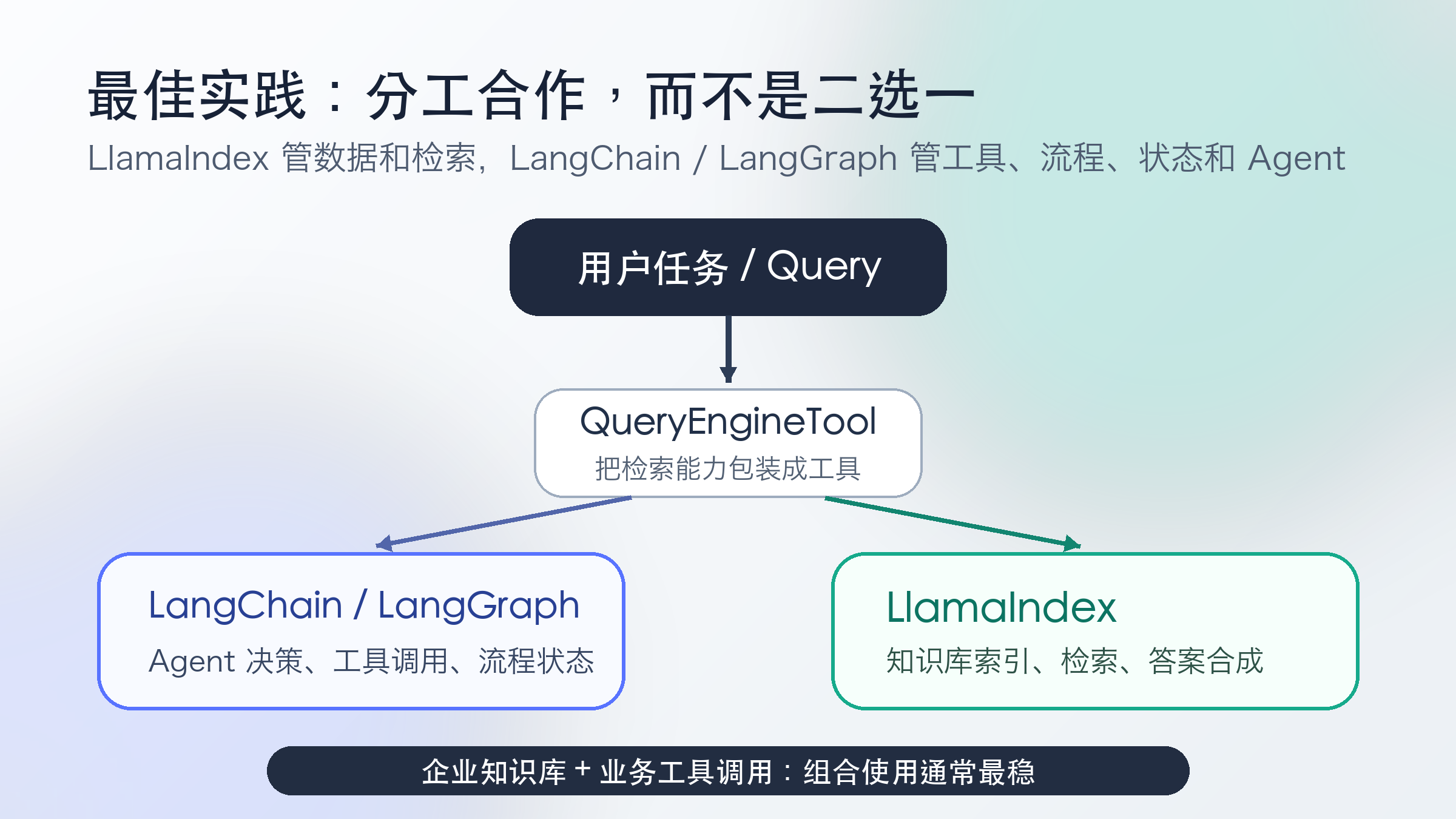
实际项目中,两者并不是非此即彼,最常见的成熟方案是分工合作:
LlamaIndex 负责知识库和 RAG LangChain / LangGraph 负责任务编排和工具调用
具体做法是把 LlamaIndex 的 QueryEngine 包装成一个 LangChain Tool,再交给 Agent 使用:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.tools import QueryEngineTool
from langchain.agents import initialize_agent
# LlamaIndex 负责建索引
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
# 包装成 LangChain 可调用的工具
kb_tool = QueryEngineTool.from_defaults(
query_engine=query_engine,
name="knowledge_base",
description="用于查询公司内部知识库"
)
# LangChain Agent 负责编排
agent = initialize_agent(tools=[kb_tool], ...)
agent.run("根据知识库内容,帮我生成一份季度总结")
这样既能利用 LlamaIndex 的检索能力,又能利用 LangChain 的复杂流程编排能力。
十、实际项目中怎么选?
| 你的目标 | 更推荐 |
|---|---|
| 快速做知识库问答 | LlamaIndex |
| 深入优化 RAG 检索质量 | LlamaIndex |
| 多数据源文档检索 | LlamaIndex |
| Agent 调多个工具完成任务 | LangChain / LangGraph |
| 复杂状态流、人类审批、任务恢复 | LangGraph |
| 企业知识库 + 业务工具调用 | LlamaIndex + LangChain 组合 |
| 学习如何让 LLM 用好私有数据 | LlamaIndex |
| 学习 LLM 应用整体编排生态 | LangChain |
十一、给 LangChain 学习者的 LlamaIndex 学习路线
如果你已经学过 LangChain,再学 LlamaIndex 时可以按下面的顺序:
-
先理解
Document、Node、Index、Retriever、QueryEngine这五个核心概念 -
用一个本地 Markdown 或 PDF 做最小 RAG 示例
-
调整 chunk size、top_k、metadata filter,观察检索结果变化
-
加入 reranker,观察回答质量变化
-
学习 QueryEngine 和 ChatEngine 的区别
-
学习 Agent,把 QueryEngine 包装成工具
-
最后再看 Workflows、多索引路由、高级检索等内容
不要一开始就陷入所有集成和高级 API。LlamaIndex 的核心价值在于数据管线和检索质量。
十二、总结
刚开始学 LlamaIndex 时觉得它和 LangChain 很像,是正常的。因为二者都服务于 LLM 应用开发,很多组件名称和使用流程确实有重叠。
但从设计重心上看:
LangChain 更关注:LLM 如何行动。 LlamaIndex 更关注:LLM 如何理解和使用数据。
在实际项目中,不必纠结二选一,更合理的思路是根据任务拆分职责:
用 LlamaIndex 管数据、建索引、做检索; 用 LangChain / LangGraph 管工具、流程、状态和 Agent。
理解了这一点,再看 LlamaIndex 就不会觉得它只是"另一个 LangChain",而是能清楚看到它在 RAG 和数据增强应用中的独特价值。
参考资料
-
LlamaIndex 官方文档:https://docs.llamaindex.ai/
-
LlamaIndex RAG 介绍:https://docs.llamaindex.ai/en/stable/understanding/rag/
-
LangChain 官方文档:https://docs.langchain.com/oss/python/langchain/overview
-
LangGraph 官方文档:https://docs.langchain.com/oss/python/langgraph/overview

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)