LLM实现记忆功能思路与常见记忆模式
LLM实现记忆功能思路
大多数的LLM应用程序都会有一个会话接口,允许我们和LLM进行多轮对话,并有一定的上下文记忆功能。但实际上,模型本身时不会记忆任何上下文,只能依靠用户的输入去产生输出。而实现这个记忆功能,就需要额外的模块去保存我们和模型对话的上下文信息,然后在下一次请求时,把所有的历史信息都输入给模型,让模型输出结果。
所有为LLM添加记忆其实非常简单,就是在Prompt中预留chat_history占位符,将Human/AI的历史对话信息插入到占位符中,并且实时保存Human/Ai的对话信息,在每一次对话时插入到预留占位符即可完成最简单的记忆功能。
流程如下: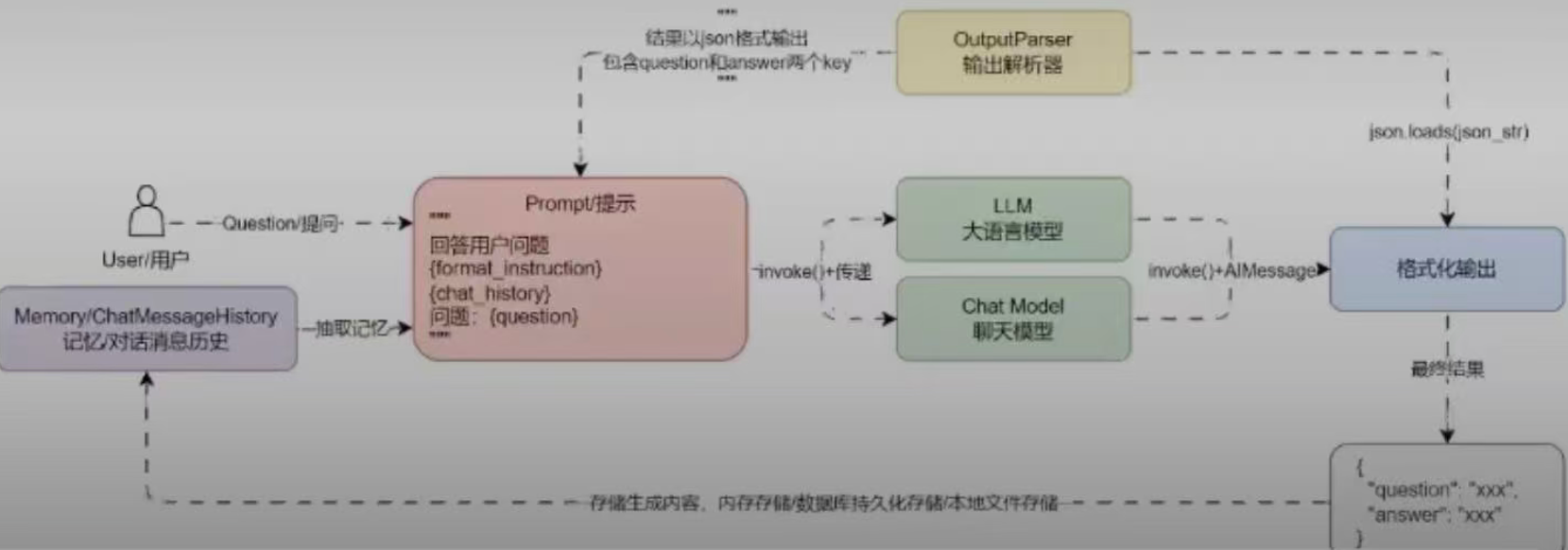
Chat Model 记忆功能演示实例
第一次提问请求:
[
{ "role": "system", "content": "你是openAI开发的聊天机器人,热衷于帮用户解决问题" },
{ "role":"human", "content": "你好,我是幕小课,我喜欢打篮球,你是?"}
]
AI响应内容:
[
{ "role":"ai", "content": "你好,幕小课!我是ChatGPT,一个由openAI训练的大模型语言。很高心认识你!有什么可以帮助你的吗?"}
]
第2次提问请求:
[
{ "role": "system", "content": "你是openAI开发的聊天机器人,热衷于帮用户解决问题" },
{ "role":"human", "content": "你好,我是幕小课,我喜欢打篮球,你是?"},
{ "role":"ai", "content": "你好,幕小课!我是ChatGPT,一个由openAI训练的大模型语言。很高心认识你!有什么可以帮助你的吗?"},
{ "role": "human", "content": "我喜欢什么运动呢?" }
]
AI响应内容:
[
{ "role":"ai", "content": "你喜欢篮球,对吗?你通常打什么位置?喜欢那支球队或球员?"}
]
LLM记忆功能演示示例
第一次发起提问请求:
你是openAI开发的聊天机器人,热衷于帮用户解决问题
<chat-history>
</chat-history>
用户的提问:你好,我是幕小课,我喜欢打篮球,你是?
AI响应内容:
你好,幕小课!我是chatGPT,一个由openAI训练的大型语言模型。很高兴认识你!有什么我可以帮助你吗?
第二次提问:
你是openAI开发的聊天机器人,热衷于帮用户解决问题
<chat-history>
human: 你好,我是幕小课,我喜欢打篮球,你是?
ai: 你好,幕小课!我是chatGPT,一个由openAI训练的大型语言模型。很高兴认识你!有什么我可以帮助你吗?
</chat-history>
用户的提问:我喜欢什么运动呢?
AI响应内容:
你喜欢篮球,对吗?你通常打什么位置?喜欢那支球队或球员?
常见记忆模式
基于Prompt中插入记忆内容,可以划分成几种记忆模式,列如:缓存记忆、缓冲窗口记忆、令牌缓冲记忆、摘要总结记忆、摘要缓冲混合记忆、向量存储库记忆等,不同的记忆模式有不同的适用场景。
缓存记忆
最基础的记忆模式,将所有Human/AI生成的消息全部存储起来,每次需要使用时将保存的所有聊天消息列表传递到Prompt中,通过往用户的输入中添加历史对话信息/记忆,可以让LLM能理解之前的对话内容,而且这种记忆方式在上下文窗口限制内是无损的。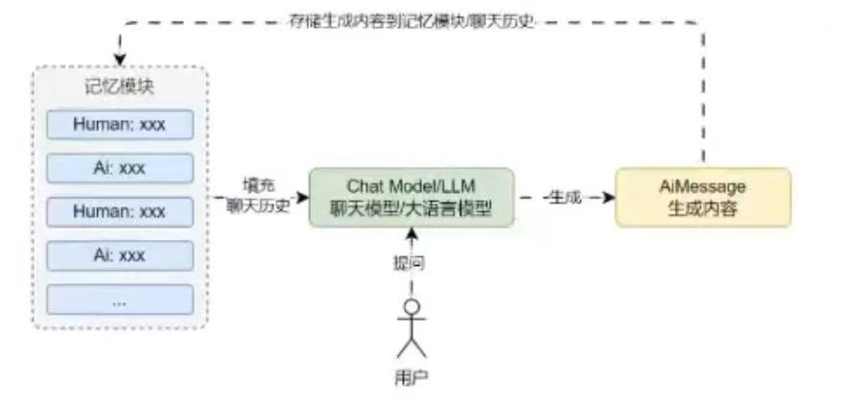
优点:
- 无损记忆,用户输入什么内容都会被记忆
- 实现方式简单,兼容性最好,所有大模型都支持
缺点:
- 直接将存储的所有内容给LLM,因为大量信息意味着新输入中包含更多的Token
- 当达到LLM的令牌数限制,太长的对话无法被记住。
- 记忆内容不是无限的,对于上下文长度较小的模型来说,记忆内容会变得极短。
缓存窗口记忆
缓存窗口记忆只保存最近的几次Human/AI生成的消息,它基于缓冲记忆思想,并添加了一个窗口值K,这意味着只保留一定数量的过去互动,然后忘记之前的互动。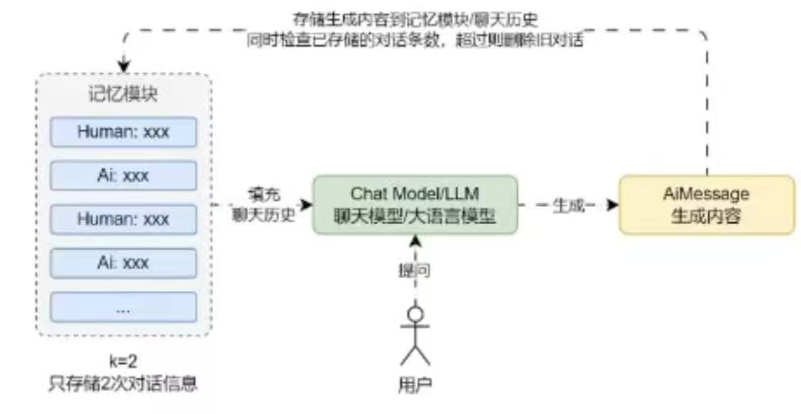
优点:
- 缓存窗口记忆在限制使用的Token数量表现优异。
- 对小模型也比较友好,不提问比较远的关联内容,一般效果最佳。
- 实现方式简单,性能优异,所有大模型都支持。
缺点:
- 缓存窗口记忆不适合遥远的互动,会忘记之前的互动。
- 部分对话内容长度较大,容易超过LLM的上下文限制。
令牌缓冲记忆
缓存窗口记忆只保存限定次数Human/AI生成的消息,它基于缓存记忆思想,并添加了一个令牌数max_tokens,当聊天历史超过令牌数时,会遗忘之前的互动。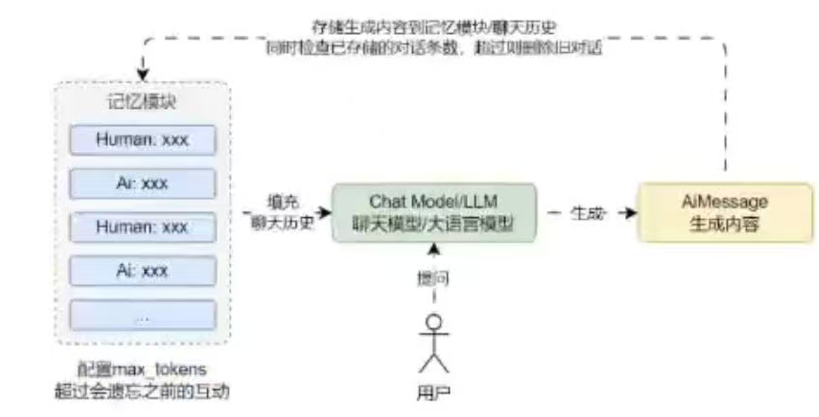
优点:
- 可以基于大语言模型的上下文限制分配记忆长度
- 对小模型也比较友好,不提问比较远的关联内容,一般效果最佳
- 实现方式简单,性能优异,所有大模型都支持
缺点:
- 令牌缓存记忆不适合遥远的互动,会忘记之前的互动
摘要总结记忆
除了将消息传递给LLM,还可以将消息进行总结,每次只传递总结的信息,而不是完整的消息。这种模式记忆对于较长的对话最有用,可以避免过度使用token,因为将过去的信息历史以原文的形式保留在提示中暂用太多Token。
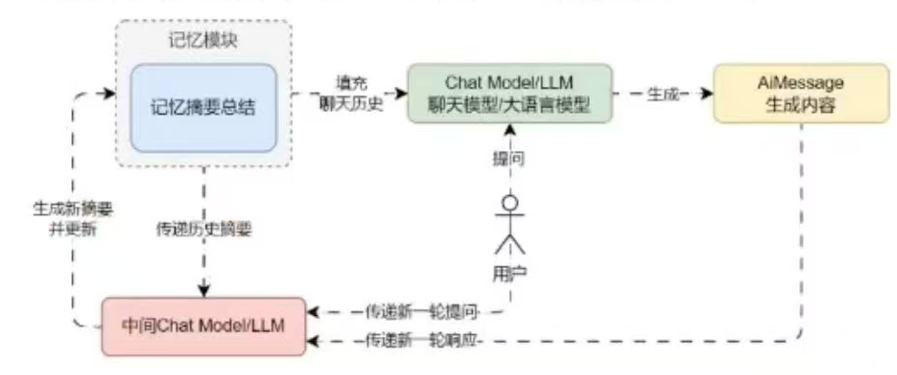
优点:
- 无论是长期还是短期的互动都可以记忆(模糊记忆)
- 减少长对话中使用Token的数量,能记忆更多轮的对话信息。
- 长对话时效果明显,虽然最初使用Token数量较多,随着对话进行,摘要方法增长速度减慢,与常规缓存内存模型相比具有优势。
缺点:
- 虽然能同时记忆近期和长远的互动内容,但是记忆的细节部分会丢失;
- 对于较短的对话可能会增加Token使用量
- 对话历史的记忆完全依赖于中间摘要LLM的能力,需要为摘要LLM分配Token
摘要缓冲混合记忆
摘要缓冲记忆结合了摘要总结记忆与缓冲窗口记忆,它旨在对对话进行摘要总结,同时保留最近互动中的原始内容,但不是简单地清除旧的交互,而是将它们编译成摘要并同时使用,并且使用标记长度而不是交互数量来确定何时清除交互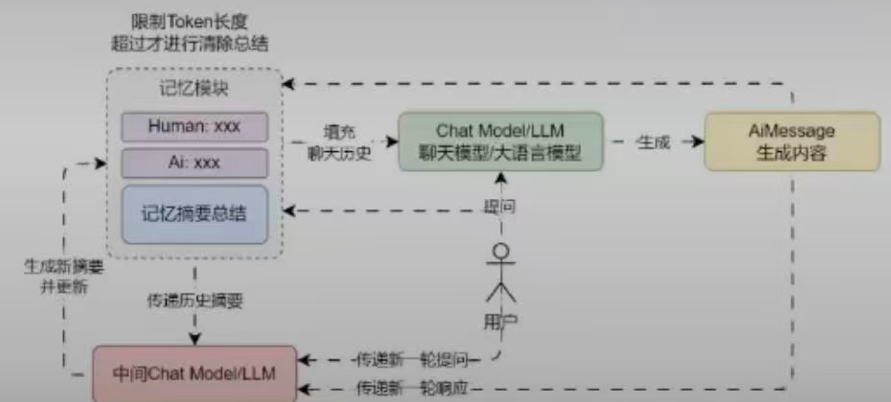
优点:
- 无论是长期还是短期的互动都可以记忆,长期为模糊记忆,短期为精准记忆
- 减少长对话中使用Token的数量,能记忆更多轮的对话信息。
缺点:
- 长期互动的内容依然为模糊记忆
- 总结摘要部分完全依赖于中间摘要LLM的能力,需要为摘要LLM分配Token,增加成本且未限制对话长度
向量存储库记忆
将记忆存储在向量存储中,并在每次调用时查询前K个最匹配的文档。这类记忆模式能记住所有内容,在细节部分比摘要总结要强,但是比缓冲记忆弱,消耗Token方面相对平衡。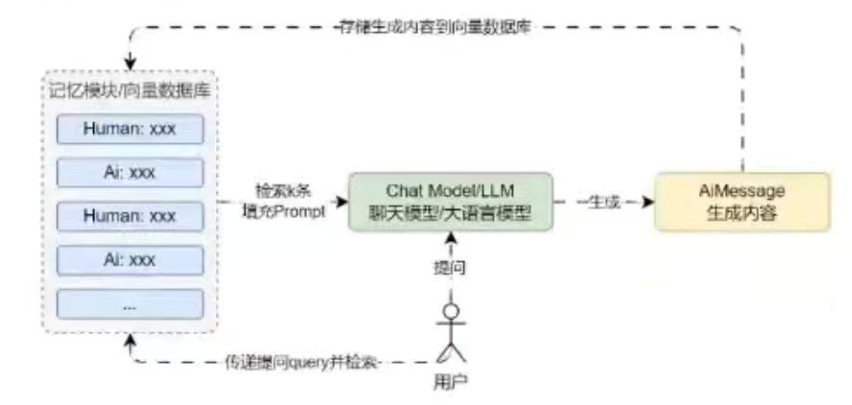
优点:
- 拥有比摘要总结更强的细节,比缓冲记忆能记忆更多的内容,甚至无限长度的内容
- 销毁的Token也相对平衡
缺点:
- 性能相比其它模式相对较差,需要额外的Embedding+向量数据库支持
- 记忆效果受检索功能的影响。好的非常好,差的非常差

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)