Agentic Engineering 深度解析:从 Vibe Coding 到生产级 AI 编程的方法论升级
"写代码从来不是软件工程师的核心工作。想清楚该写什么代码才是。" —— Simon Willison, Django 联合创始人
一、引言:AI 编程正在分化
2025 年 2 月,Andrej Karpathy 造了一个词:Vibe Coding(氛围编程)——让 AI 写代码,你忘记代码的存在就好。
一年后,Django 框架联合创始人 Simon Willison 发布了一份名为《Agentic Engineering Patterns》的指南,给出了完全不同的定义:Agentic Engineering 是用 AI 编程 Agent 来开发生产级软件的工程实践。
两个理念的分界线清晰得像一条鸿沟:
| 维度 | Vibe Coding | Agentic Engineering |
|---|---|---|
| 目标 | 原型 / 一次性脚本 | 生产级软件 |
| 人的角色 | 旁观者 | 指挥官 + 审查者 |
| 质量控制 | 无 | TDD + Code Review |
| 上下文管理 | 随意 | 精细管控 |
| 适用场景 | 探索、学习、Demo | 商业项目、团队协作 |
这不是风格之争,而是工程纪律之争。Vibe Coding 能让你在 10 分钟内搭出一个 Demo;Agentic Engineering 能让你在 10 天内交付一个可维护的系统。
本文将深度拆解 Agentic Engineering 的核心模式,帮你从"让 AI 随便写"升级到"让 AI 按规矩写"。
二、AI 编程 Agent 的底层架构
在讨论方法论之前,必须先理解 AI 编程 Agent 的底层原理。很多人天天用 Claude Code / Cursor / GitHub Copilot,但不知道它们到底在干什么。
2.1 四要素模型
一个 AI 编程 Agent 的核心架构可以用四个要素描述:
Agent = LLM + 系统提示词 + 工具集 + 执行循环
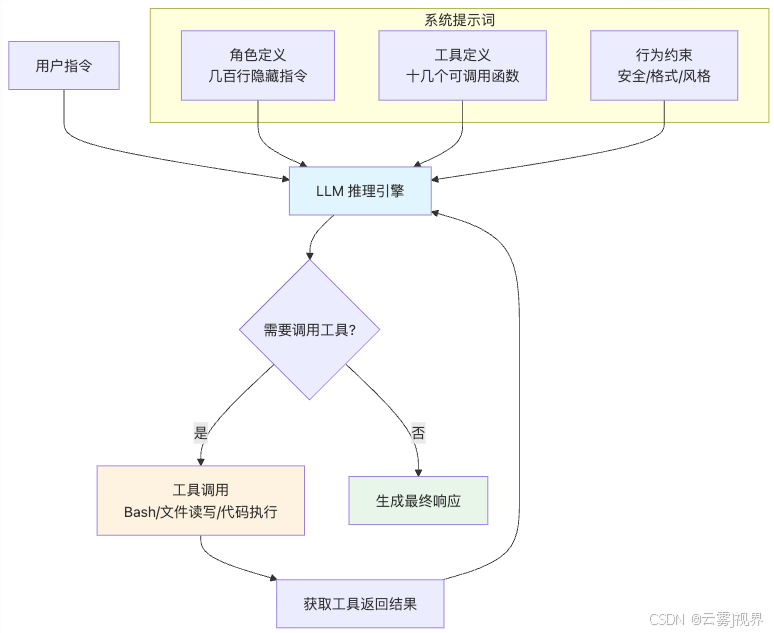
关键要素解释:
- LLM(大语言模型):核心推理引擎。本质上是一个文本续写器,但通过系统提示词和工具调用,被赋予了"行动能力"。
- 系统提示词(System Prompt):几百行的隐藏指令,定义了 Agent 的行为方式。Codex 的系统提示词已在 GitHub 公开,长度超过 800 行。
- 工具集(Tools):十几个可调用的函数——Bash 命令执行、文件读写、代码搜索、Web 浏览等。能执行才能验证,能验证才能迭代,这是 Agent 与普通聊天机器人的本质区别。
- 执行循环(Loop):LLM 调工具 → 拿到结果 → 继续推理 → 再调工具 → 直到任务完成。这个循环是自动的,一次用户指令可能触发几十轮内部循环。
2.2 两个反直觉的事实
事实一:LLM 是无状态的。
你以为你在"对话",其实软件每次都把整段对话历史重新喂给模型。所以对话越长,每轮花费越高,质量也会逐渐下降。实测数据表明:
| 上下文长度 | 推理质量 | 成本 |
|---|---|---|
| 0-50K tokens | 最佳 | 基准 |
| 50K-100K tokens | 良好 | 2-3x |
| 100K-200K tokens | 明显下降 | 4-6x |
| 200K+ tokens | 严重退化 | 8x+ |
事实二:Token 缓存能省钱。
大多数提供商对重复的前缀 token 收费更低(通常是正常价格的 10%-25%)。Claude Code 的设计刻意避免修改历史对话内容——不是偷懒,是为了保证缓存命中率。这是一个精巧的工程决策。
三、上下文管理:AI 编程中最昂贵的资源
上下文窗口是 AI 编程 Agent 最宝贵也最容易被浪费的资源。
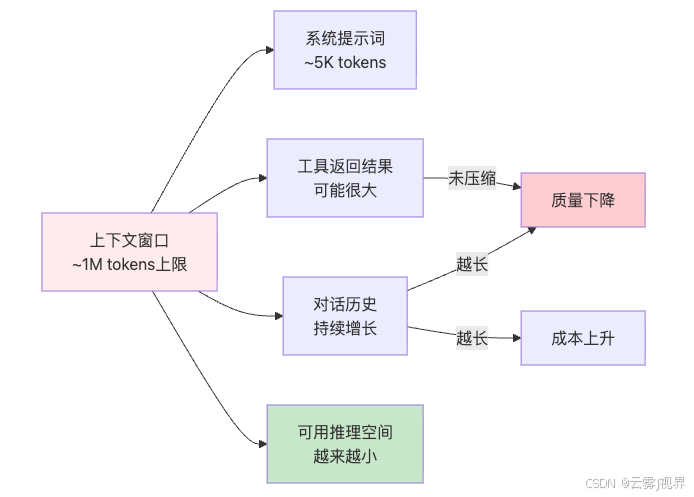
上下文管理的三条黄金法则:
- 及时开新会话:当对话超过 100K tokens 时,果断开新会话。带着明确的任务描述重新开始,效果远好于在退化的上下文中继续。
- 用子 Agent 隔离子任务:让子 Agent 在自己的上下文中处理子任务,只返回摘要结果,不污染主 Agent 的上下文。
- 控制工具输出大小:测试输出、日志输出、代码搜索结果——这些都可能产生大量 token。让 Agent 只返回关键信息。
四、子 Agent 模式:被低估的核心能力
子 Agent 是 AI 编程 Agent 中最被低估但最有价值的能力。主 Agent 可以派出"分身"来处理子任务,每个子 Agent 有自己独立的上下文窗口。
4.1 探索型子 Agent
场景:面对一个不熟悉的代码库,需要先摸清结构再动手。
Simon Willison 给出了一个真实案例:让 Claude Code 修改博客的 diff 展示功能。Claude Code 的第一步不是写代码,而是派了一个 Explore 子 Agent 去摸底:
# Claude Code 自动生成的子Agent探索指令(伪代码还原)
explore_prompt = """
找到这个 Django 博客中实现 diff 视图的代码。我需要找到:
- 渲染 diff 的模板(找带红/绿背景的 HTML/CSS)
- 生成 diff 的 Python 代码(找 difflib 的用法)
- 跟 diff 渲染相关的 JavaScript
- diff 视图的 CSS 样式
彻底搜索 templates/、static/、blog/ 目录。
关键词搜 "diff"、"chapter"、"revision"、"history"、"compare"。
"""
# 子Agent返回结果摘要(不是原始文件内容)
explore_result = {
"template": "templates/blog/entry_diff.html",
"python": "blog/views.py:diff_view() line 234-280",
"css": "static/css/diff.css",
"js": "无相关JS",
"key_functions": ["generate_diff()", "render_diff_html()"]
}
# 主Agent拿到摘要后才开始修改代码
关键点:子 Agent 返回的是摘要,不是原始文件内容。这极大节省了主 Agent 的上下文空间。
4.2 并行子 Agent
场景:需要修改多个互不依赖的文件。
# 触发并行子Agent的prompt示例
"用子Agent并行找到并更新所有受这个改动影响的模板文件。
每个模板由独立的子Agent处理,完成后汇总结果。"
并行子 Agent 的效率提升是线性的——3 个子 Agent 并行,速度提升接近 3 倍。
4.3 专业子 Agent
场景:给子 Agent 分配不同的"专家角色"。
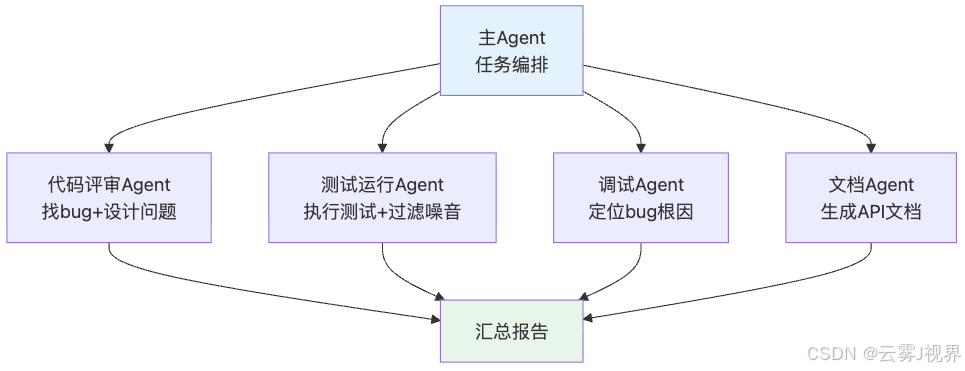
测试运行 Agent 特别有价值:测试输出通常很长(几千行),直接塞进主 Agent 的上下文会严重污染。让专业子 Agent 运行测试并返回"3 个测试失败,失败原因是 XXX",比把整个测试日志丢进去高效 100 倍。
Simon 的提醒:别过头。子 Agent 的核心价值是节省上下文,不是让你搞几十个微服务式的 Agent 编排。保持简单。
五、Red/Green TDD:AI 编程的质量保障
Simon Willison 说他在 Claude Code 里用得最多的一句话只有六个字:
Use red/green TDD
所有主流模型都理解这个缩写的完整含义:
- Red(红色):先写测试,确认测试是失败的
- Green(绿色):再写实现代码,让测试通过
5.1 为什么 TDD 和 AI 编程天生契合?
AI 编程有两个高频问题:
- 写的代码不能用——没有验证机制
- 写了一堆没人需要的代码——没有需求约束
测试先行同时解决了这两个问题:测试定义了"做对了是什么样",AI 按着这个标准迭代。
5.2 完整的 TDD + AI 工作流
# Step 1: 先写测试(人类或AI写)
def test_calculate_power_loss():
"""测试功率损耗计算函数"""
# 输入:开关频率100kHz, 负载电流10A, 导通电阻50mΩ
result = calculate_power_loss(
switching_freq=100e3,
load_current=10,
rds_on=50e-3
)
# 预期:导通损耗 = I²×Rds(on) = 100×0.05 = 5W
assert result['conduction_loss'] == pytest.approx(5.0, rel=0.01)
# 预期:总损耗在合理范围
assert 5.0 < result['total_loss'] < 15.0
# Step 2: 运行测试,确认是红色(失败)
# $ pytest test_power.py → FAILED ✅ 确认测试有效
# Step 3: 让AI实现代码
# Prompt: "实现 calculate_power_loss 函数,让所有测试通过。
# Use red/green TDD."
# Step 4: AI实现
def calculate_power_loss(switching_freq, load_current, rds_on,
v_ds_off=400, t_rise=50e-9, t_fall=30e-9):
"""
计算MOSFET功率损耗
Args:
switching_freq: 开关频率 (Hz)
load_current: 负载电流 (A)
rds_on: 导通电阻 (Ω)
v_ds_off: 关断电压 (V)
t_rise: 上升时间 (s)
t_fall: 下降时间 (s)
Returns:
dict: 各项损耗分解
"""
# 导通损耗 P_cond = I² × Rds(on)
conduction_loss = load_current ** 2 * rds_on
# 开关损耗 P_sw = 0.5 × V × I × (t_rise + t_fall) × f_sw
switching_loss = (0.5 * v_ds_off * load_current
* (t_rise + t_fall) * switching_freq)
return {
'conduction_loss': conduction_loss,
'switching_loss': switching_loss,
'total_loss': conduction_loss + switching_loss
}
# Step 5: 运行测试 → GREEN ✅
关键:Step 2(确认红色)不能省。不然你可能写了一个本来就能通过的测试——等于白写。AI 特别容易犯这个错:写一个永远为真的断言。
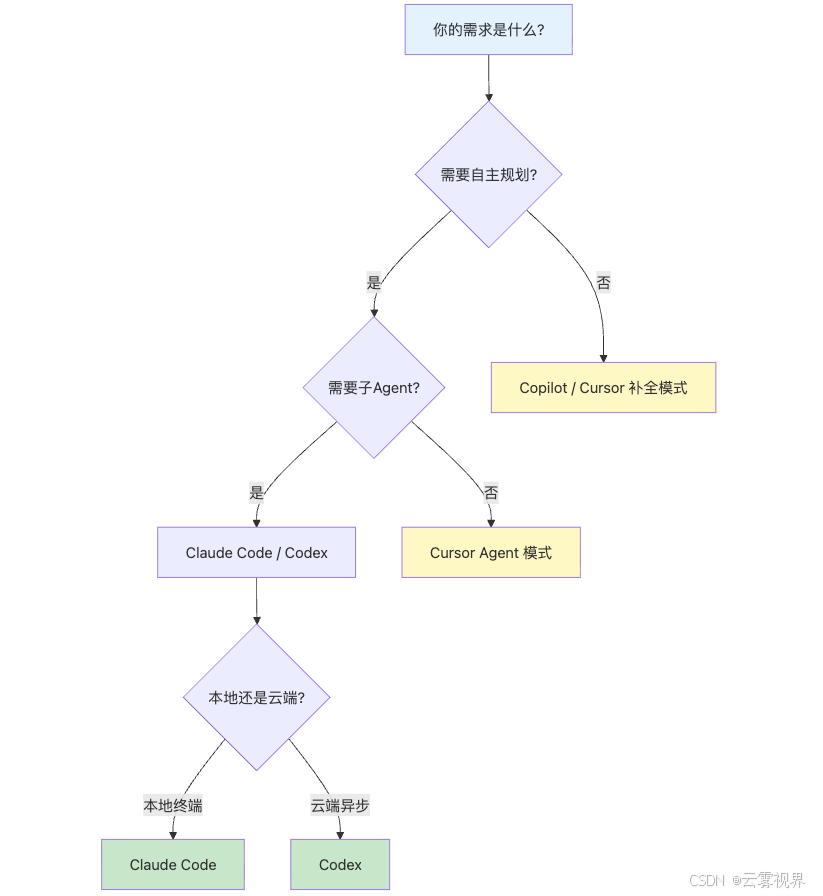
六、主流 AI 编程工具对比
2026 年主流 AI 编程工具已经形成清晰的分层:
| 工具 | 类型 | 核心能力 | 上下文窗口 | 子Agent | 适用场景 |
|---|---|---|---|---|---|
| Claude Code | 终端Agent | 自主规划+执行+验证 | 200K | ✅ | 复杂重构、全栈开发 |
| Cursor | IDE集成Agent | 代码库理解+内联编辑 | 128K | 部分 | 日常开发、快速迭代 |
| GitHub Copilot | 补全+Agent | 行级补全+Workspace Agent | 128K | ❌ | 代码补全、简单任务 |
| Codex (OpenAI) | 云端Agent | 异步执行+PR生成 | 200K | ✅ | CI/CD集成、批量任务 |
| Gemini CLI | 终端Agent | 多模态+长上下文 | 1M | ✅ | 大代码库分析 |
| Windsurf | IDE集成Agent | Cascade流+上下文感知 | 128K | 部分 | 全栈开发 |
选型建议
七、工程师能力模型的变化
Agentic Engineering 正在重塑软件工程师的能力模型:
7.1 从"写代码"到"编排 Agent"
| 传统能力 | 权重变化 | Agentic 时代对应能力 |
|---|---|---|
| 语法熟练度 | ⬇️ 大幅降低 | Prompt 精确表达 |
| 算法手写 | ⬇️ 降低 | 算法选型 + 验证 |
| 框架记忆 | ⬇️ 降低 | 架构决策 + 权衡 |
| 调试能力 | ➡️ 不变 | 调试 + 指导 Agent 调试 |
| 系统设计 | ⬆️ 大幅提升 | 系统设计 + Agent 编排 |
| 代码审查 | ⬆️ 大幅提升 | 审查 AI 产出质量 |
| 需求分析 | ⬆️ 大幅提升 | 精确定义"做对了是什么样" |
| 测试设计 | ⬆️ 大幅提升 | TDD 驱动 Agent 迭代 |
7.2 薪资数据印证
根据 2026 年 Q1 招聘数据(来源:LinkedIn Talent Insights, 猎聘大数据):
- 熟练使用 AI 编程工具的工程师:平均薪资比同级别高 30-45%
- 能编排多 Agent 协作的高级工程师:年薪中位数达到 80-120 万(一线城市)
- AI 编程培训市场:2026 年同比增长 210%
这不是未来,这是现在。
八、实战 Prompt 清单
以下是 Simon Willison 和社区总结的高频实用 Prompt:
8.1 启动类
# 让Agent先摸底再动手
"在修改任何代码之前,先用子Agent探索代码库结构,
找到所有相关文件,然后给我一个修改计划。"
# TDD驱动
"Use red/green TDD. 先写测试,确认失败,再写实现。"
# 控制修改范围
"只修改 src/power/ 目录下的文件,不要动其他模块。"
8.2 质量控制类
# 代码审查
"用一个子Agent审查刚才写的代码,
重点检查:边界条件、错误处理、性能问题。"
# 测试覆盖
"检查当前测试覆盖率,找出未覆盖的分支,补充测试。"
# 重构
"重构这个函数,但不改变任何外部行为。
先运行现有测试确认全部通过,重构后再运行一次。"
8.3 效率类
# 并行处理
"用子Agent并行更新所有受影响的模板文件。"
# 控制上下文
"总结当前的修改内容为一段简短描述,
然后我们开一个新会话继续后续工作。"
九、总结与展望
Agentic Engineering 不是一个工具的使用技巧,而是一套与 AI 协作的工程方法论。它的核心思想可以浓缩为三句话:
- 你是指挥官,不是旁观者——AI 写代码,你做决策、定标准、审结果
- 上下文是最贵的资源——用子 Agent 隔离、用 TDD 约束、用新会话重置
- 测试是你和 AI 之间的合约——测试定义了"做对了是什么样",AI 按合约交付
从 Vibe Coding 到 Agentic Engineering,不是工具的升级,而是工程纪律的回归。AI 越强大,工程纪律越重要——因为没有纪律的强大 AI,只会更快地制造更大的灾难。
Simon Willison 说得好:LLM 不会从过去的错误中学习,但 Agent 可以——前提是我们主动更新指令和工具来反映我们学到的东西。
这不就是"授人以渔"吗?工具一直在进化,方法论才是长期有用的东西。
参考资料
- Simon Willison, Agentic Engineering Patterns, 2026
- Andrej Karpathy, "Vibe Coding" 概念提出, 2025.02
- OpenAI Codex System Prompt (GitHub 公开版)
- LinkedIn Talent Insights, 2026 Q1 AI Engineering Salary Report
- 猎聘大数据研究院, 《2026年AI工程人才供需报告》Django创始人Simon Willison发布《Agentic Engineering Patterns》,首次系统定义了AI编程Agent的工程方法论。本文深度解析Vibe Coding与Agentic Engineering的本质区别,拆解Agent底层架构(LLM+系统提示词+工具+循环),详解子Agent三模式(探索/并行/专业)与Red/Green TDD实战,附主流工具对比与工程师能力模型演变分析。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)