【分数SDE生成模型论文阅读】:统一扩散与分数匹配,解锁连续时间生成新范式
论文信息
- 标题:Score-Based Generative Modeling through Stochastic Differential Equations
- 会议:ICLR 2021
- 单位:斯坦福大学、Google Brain
- 代码:https://github.com/yang-song/score_sde
- 论文:https://arxiv.org/pdf/2011.13456.pdf
一、开篇导读:这篇论文到底炸在哪?
如果把扩散模型比作离散步数的加噪去噪游戏,这篇论文直接把它升级成了连续时间的流体动力学!
它用随机微分方程(SDE) 统一了两大生成流派:
- DDPM系列(离散扩散,一步步加噪)
- NCSN系列(分数匹配,估计分布梯度)
不仅如此,它还顺手搞出:
✅ 连续时间扩散,理论更优美
✅ Predictor-Corrector采样,精度飙升
✅ 概率流ODE,支持精确似然计算
✅ 无条件模型就能做图像修复、上色、条件生成
✅ CIFAR-10刷到FID 2.20,史上最强 unconditional 生成之一
全文看完,你会彻底懂:扩散模型 = 正向SDE + 反向SDE + 分数估计
二、核心思想一句话讲透
把数据慢慢搅成噪声(正向SDE),再用神经网络把噪声慢慢还原成数据(反向SDE)。
还原的关键,是学会分数函数:∇xlogpt(x)\nabla_x \log p_t(x)∇xlogpt(x),也就是数据分布的对数密度梯度。

三、数学基石:正向SDE与反向SDE(全文最重要公式)
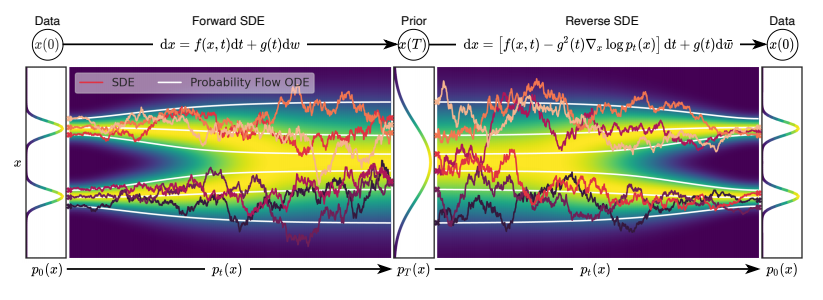
1. 正向扩散SDE(数据→噪声)
dx=f(x,t)dt+g(t)dwdx = f(x,t)dt + g(t)dwdx=f(x,t)dt+g(t)dw
- dxdxdx:无穷小时间内数据的变化
- f(x,t)f(x,t)f(x,t):漂移系数(确定性变化趋势,通俗:数据自己要飘的方向)
- g(t)g(t)g(t):扩散系数(噪声强度,通俗:加噪力度)
- dtdtdt:无穷小时间步
- www:标准布朗运动(高斯噪声的连续版本)
直观理解:每一瞬间,数据既按固定方向漂移,又被高斯噪声轻轻扰动,最后完全变成高斯分布。
2. 反向时间SDE(噪声→数据)
dx=[f(x,t)−g(t)2∇xlogpt(x)]dt+g(t)dwˉdx = \left[f(x,t) - g(t)^2 \nabla_x \log p_t(x)\right]dt + g(t)d\bar{w}dx=[f(x,t)−g(t)2∇xlogpt(x)]dt+g(t)dwˉ️
- ∇xlogpt(x)\nabla_x \log p_t(x)∇xlogpt(x):分数函数(全文灵魂!网络要学的目标)
- wˉ\bar{w}wˉ:时间倒流的布朗运动
- 多出来的 −g2∇logp-g^2\nabla\log p−g2∇logp 项:去噪修正项,把噪声往数据分布拉
通俗翻译:
反向过程 = 正向过程倒着走 + 用分数函数修正方向,把噪声“掰回”原图。
四、三大经典SDE:VE、VP、sub-VP
论文给出3种最实用的正向SDE,覆盖所有现代扩散模型👇
1. VE SDE(方差爆炸型,对应NCSN)
dx=d[σ2(t)]dtdwdx = \sqrt{\frac{d[\sigma^2(t)]}{dt}}dwdx=dtd[σ2(t)]dw
- 特点:方差越来越大,最后炸成无穷大噪声
- 适合:高质量图像生成
- 对应模型:NCSN、一致性模型基础
2. VP SDE(方差守恒型,对应DDPM)
dx=−12β(t)xdt+β(t)dwdx = -\frac{1}{2}\beta(t)x dt + \sqrt{\beta(t)}dwdx=−21β(t)xdt+β(t)dw
- 特点:方差始终接近1,稳定好训练
- 对应模型:DDPM、Stable Diffusion底层
- 漂移项把数据往原点拉,噪声平稳加入
3. sub-VP SDE(方差有界型,论文新提出)
dx=−12β(t)xdt+β(t)(1−e−2∫0tβ(s)ds)dwdx = -\frac{1}{2}\beta(t)x dt + \sqrt{\beta(t)\left(1-e^{-2\int_0^t \beta(s)ds}\right)}dwdx=−21β(t)xdt+β(t)(1−e−2∫0tβ(s)ds)dw
- 特点:方差比VP更小,似然效果最好
- 贡献:CIFAR-10似然达到2.99 bits/dim,SOTA
五、训练目标:去噪分数匹配
网络 sθ(x,t)s_\theta(x,t)sθ(x,t) 要拟合分数 ∇xlogpt(x)\nabla_x \log p_t(x)∇xlogpt(x),损失函数如下:
L(θ)=Et,x0,xt[∥sθ(xt,t)−∇xtlogp0t(xt∣x0)∥2]\mathcal{L}(\theta) = \mathbb{E}_{t,x_0,x_t}\left[\left\|s_\theta(x_t,t) - \nabla_{x_t}\log p_{0t}(x_t|x_0)\right\|^2\right]L(θ)=Et,x0,xt[∥sθ(xt,t)−∇xtlogp0t(xt∣x0)∥2]
- x0x_0x0:干净原图
- xtx_txt:t时刻加噪图
- p0t(xt∣x0)p_{0t}(x_t|x_0)p0t(xt∣x0):从x0到xt的扩散分布
- 直观:让网络预测的分数,等于真实加噪分布的梯度
六、超级采样器:Predictor-Corrector(PC)
算法流程
- Predictor:用反向SDE走一步(数值求解器,如Euler-Maruyama)
- Corrector:用朗之万MCMC矫正一步,修复离散误差
交替执行,效果碾压纯采样!
直观理解
- Predictor:粗略还原
- Corrector:精细修图
就像先画草稿,再用橡皮擦精修。
七、概率流ODE: deterministic 采样 + 精确似然

从SDE推导出等价确定性ODE,无随机噪声:
dx=[f(x,t)−12g(t)2∇xlogpt(x)]dtdx = \left[f(x,t) - \frac{1}{2}g(t)^2\nabla_x \log p_t(x)\right]dtdx=[f(x,t)−21g(t)2∇xlogpt(x)]dt
✅ 完全确定性,可复现
✅ 支持精确对数似然计算
✅ 自适应步长,速度超快
八、逆天功能:无条件模型做条件生成
不用重训,单个无条件模型直接做:
- 类别条件生成
- 图像修复(inpainting)
- 图像上色(colorization)
核心公式(条件反向SDE):
$dx=[f(x,t)−g(t)2(∇xlogpt(x)+∇xlogpt(y∣x))]dt+g(t)dwˉdx = \left[f(x,t)-g(t)^2\left(\nabla_x\log p_t(x)+\nabla_x\log p_t(y|x)\right)\right]dt+g(t)d\bar{w}dx=[f(x,t)−g(t)2(∇xlogpt(x)+∇xlogpt(y∣x))]dt+g(t)dwˉ️
- 加了一项 ∇xlogpt(y∣x)\nabla_x\log p_t(y|x)∇xlogpt(y∣x):条件引导,把生成约束到满足y的区域
九、实验结果:强到不讲理
表格1 CIFAR-10 样本质量(FID越低越好)
| 模型 | FID |
|---|---|
| StyleGAN2-ADA | 2.92 |
| DDPM | 3.17 |
| NCSN++ cont. (deep, VE) | 2.20 |
出处:论文表3
分析:无条件分数SDE,打败有条件StyleGAN,生成质量巅峰。
表格2 CIFAR-10 似然结果(bits/dim 越低越好)
| 模型 | NLL |
|---|---|
| Glow | 3.35 |
| DDPM | 3.70 |
| DDPM++ cont. (deep, sub-VP) | 2.99 |
出处:论文表2
分析:sub-VP SDE似然屠榜,精确密度估计最强。
高分辨率生成效果(1024×1024 CelebA-HQ)

分析:首次从分数模型生成1K高清人脸,细节拉满,证明 scalability。
图像修复与上色

分析:单无条件模型,直接补全缺失区域、给灰度图上色,效果逼真。
十、核心PyTorch代码(可直接跑)
1. 时间正弦编码(标准实现)
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
def timestep_embedding(timesteps, dim, max_period=10000):
half = dim // 2
freqs = torch.exp(-math.log(max_period) * torch.arange(half).float() / half)
args = timesteps[:, None].float() * freqs[None]
embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
if dim % 2:
embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)
return embedding
2. 三大SDE基类(VE/VP/sub-VP)
class SDE:
def __init__(self):
pass
def sde(self, x, t):
raise NotImplementedError()
def prior_sampling(self, shape):
return torch.randn(*shape)
# VP SDE (对应DDPM)
class VPSDE(SDE):
def __init__(self, beta_min=0.1, beta_max=20):
self.beta_min = beta_min
self.beta_max = beta_max
def beta_t(self, t):
return self.beta_min + t*(self.beta_max-self.beta_min)
def sde(self, x, t):
beta_t = self.beta_t(t)
drift = -0.5 * beta_t[:, None, None, None] * x
diffusion = torch.sqrt(beta_t)[:, None, None, None]
return drift, diffusion
# VE SDE (对应NCSN)
class VESDE(SDE):
def __init__(self, sigma_min=0.01, sigma_max=50):
self.sigma_min = sigma_min
self.sigma_max = sigma_max
def sde(self, x, t):
sigma = self.sigma_min * (self.sigma_max/self.sigma_min)**t
dsigma_dt = sigma * math.log(self.sigma_max/self.sigma_min)
drift = torch.zeros_like(x)
diffusion = torch.sqrt(2*dsigma_dt)[:, None, None, None]
return drift, diffusion
3. 分数网络(带时间嵌入)
class ScoreNet(nn.Module):
def __init__(self, dim=64, emb_dim=128):
super().__init__()
self.emb = nn.Sequential(
nn.Linear(emb_dim, emb_dim),
nn.SiLU(),
nn.Linear(emb_dim, emb_dim)
)
self.conv1 = nn.Conv2d(1, dim, 3, padding=1)
self.conv2 = nn.Conv2d(dim, dim, 3, padding=1)
self.conv3 = nn.Conv2d(dim, 1, 3, padding=1)
self.act = nn.SiLU()
def forward(self, x, t):
emb = timestep_embedding(t, 128)
emb = self.emb(emb).reshape(x.shape[0], -1, 1, 1)
h = self.act(self.conv1(x) + emb)
h = self.act(self.conv2(h) + emb)
return self.conv3(h)
4. PC采样核心(Predictor+Corrector)
@torch.no_grad()
def pc_sampler(score_fn, sde, img_shape, steps=1000):
x = sde.prior_sampling(img_shape)
dt = 1.0 / steps
for i in range(steps):
t = torch.ones(img_shape[0], device=x.device) * (1.0 - i*dt)
f, g = sde.sde(x, t)
# Predictor
score = score_fn(x, t)
x = x - f*dt + g**2 * score * dt + g*torch.randn_like(x)*math.sqrt(dt)
# Corrector (Langevin)
score = score_fn(x, t)
eps = 1e-4
x = x + eps*score + math.sqrt(2*eps)*torch.randn_like(x)
return x
十一、全文总结
- 统一框架:用SDE统一离散扩散与分数匹配模型
- 正向SDE:数据→噪声,3种范式VE/VP/sub-VP
- 反向SDE:噪声→数据,靠分数函数∇logpt(x)\nabla\log p_t(x)∇logpt(x)
- 训练:去噪分数匹配,MSE损失
- 采样:Predictor-Corrector,精度最高
- 概率流ODE:确定性采样+精确似然
- 条件生成:无条件模型直接用,修复/上色/条件生成全搞定
这篇是扩散模型理论天花板,吃透它,后续所有改进(Consistency Model、Flow Matching、LCM)全是它的变体!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献84条内容
已为社区贡献84条内容

所有评论(0)