今天都做了什么?
2025年12月
2025.12.25 上午
用Gemini3提供的代码实现LeNet-5实现识别MNIST
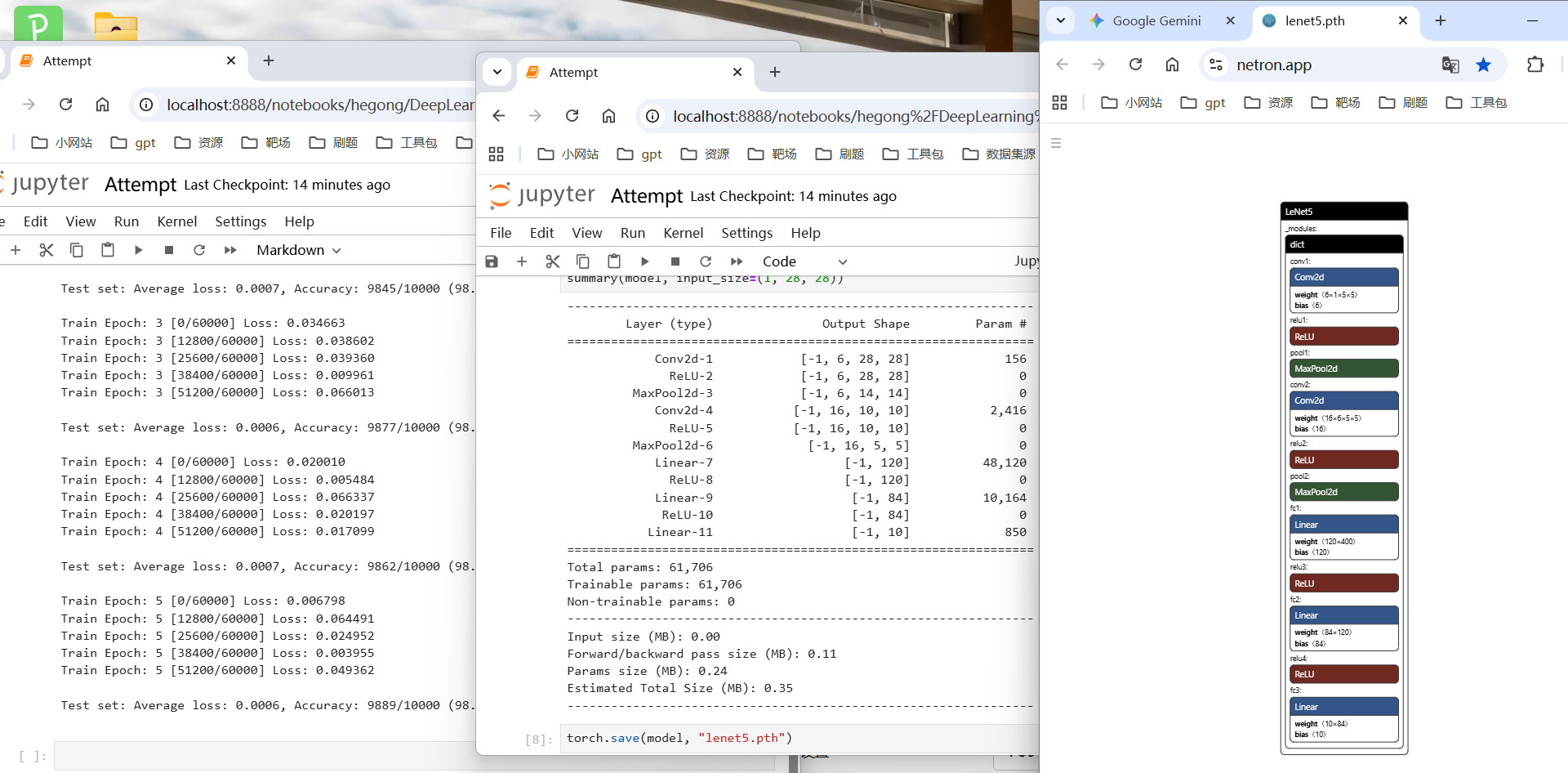
跟着上手推了一下LeNet、AlexNet、VGG的网络结构以及计算了常规的输出结果维度
2025.12.25 下午
1、复现AlexNet,效果并不理想,因为使用的是数据生成器生产的图。
2、速读了AlexNet的论文。
AlexNet的创新点:
①使用ReLU进行局部响应归一化。
②使用的Dropout,将每个隐藏神经元的输出以0.5的概率设为0。避免了过拟合。
③首次实现将多块GPU并行(2块GTX580),每个GPU训练一半的神经元。
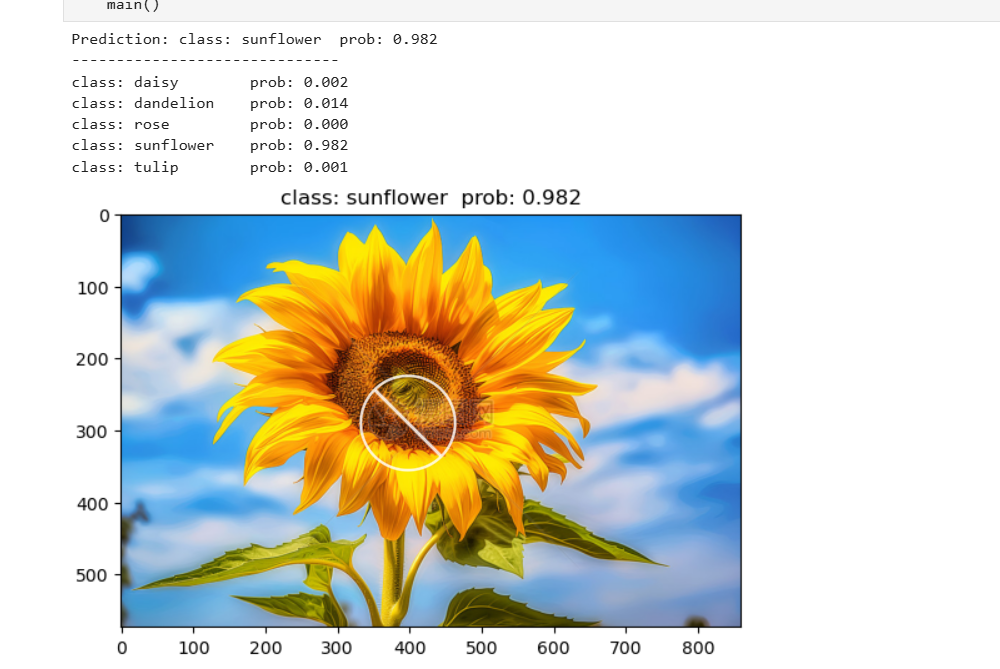
遂在网上找了一个使用AlexNet对花朵进行分类的文章复现了一下。
测试了一下,准确率还挺高的。
3、速读了VGG在kaggle的文章Kaggle--VGGNet-16
根据kaggle的代码复现了,效果中规中矩。
2025.12.26上午
1、重构了VGG,没有使用预训练模型,按照VGGNet-16 的模型框架构建,从头开始训练。从4096的全连接层改到512层全连接,基于flowers的数据集进行训练,还是有点大。
2、在训练过程中,看书上的Inception结果,搜了一下,看到一个CSDN 名称叫Dream_Bri的博主,又看了几篇他的文章。
没使用预训练模型,训练的好慢啊

使用了预训练模型去试,发现效果也还行,但是Gemini3 直接推荐使用ResNet
基于 PyTorch 的迁移学习训练脚本。
用预训练的 VGG16 网络,对花卉数据集进行分类训练
-
使用 VGG16 预训练模型
-
冻结卷积层,仅训练分类层
BATCH_SIZE = 32; LEARNING_RATE = 0.001;EPOCHS = 10

| 特性 | 原始 VGG16 | Demo Code (改进版) | 优势 |
| 权重初始化 | 随机或特定初始化 | 预训练权重 (ImageNet) | 训练收敛极快,精度更高 |
| 特征提取层 | 参与训练 | 冻结 (Frozen) | 节省大量计算资源,防止过拟合 |
| 分类头结构 | 4096 -> 4096 -> 1000 | 4096 -> 256 -> Num_Classes | 参数更少,更适合小数据集 |
| 优化器 | SGD + Momentum | Adam | 收敛速度更快,调参更简单 |
| 监控工具 | 简单的 Print 输出 | tqdm 实时进度条 | 用户体验更好,监控更直观 |



2025.12.26下午
1、看了InceptionV1的模型结构,
2、去跑步了
2025.12.27上午
1、去郑州领郑马物料
2025.12.27下午
1、去新郑面试了一个AI agent的岗位,底薪2k+单子提成,综合4k-6k,不管吃住,暂不考虑
2025.12.28上午
1、投了简历
2、投了简历
3、投了简历
4、投了简历
5、投了简历
2025.12.28下午
1、投了简历
2、投了简历
3、大概看了一下论文:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift。
批量归一化:通过减少内部协变量偏移来加速深度网络训练:通过给神经网络中间层做 “批量标准化”,解决了训练时的数据分布漂移问题,让深度模型训练更快、更稳、效果更好。而且 BN 只加了两个参数 per 特征,计算成本不高,还能替代部分传统正则化手段,后来成了深度学习里的 “标配” 技术之一。
深度神经网络有很多层,后面一层的输入,是前面所有层处理后的结果。训练时,前面层的参数一直在变,导致后面层的输入数据分布也跟着 “变来变去”—— 这就是「内部协变量偏移」
这种 “偏移” 会带来麻烦:
- 得用很小的学习率(不然参数容易乱),训练超慢;
- 初始化参数要小心翼翼,不然模型容易 “饱和”(比如 sigmoid 函数输入太大或太小,梯度就没了,学不动);
- 容易过拟合,还得靠 Dropout 等技术补救。
BN 的核心思路:给中间层数据 “定规矩”
既然输入分布老变,那就主动给它 “归一化”:让每一层的输入数据,都变成「均值接近 0、方差接近 1」的样子(类似把不同尺度的数据统一成一个标准)。但直接归一化会丢了模型原本学到的特征,所以 BN 还加了两个可学习的参数(缩放因子 γ、偏移因子 β),允许模型根据需求调整 —— 相当于 “先标准化,再灵活微调”,既稳定了分布,又没丢特征。
关键是:BN 的标准化不是用整个训练集算均值方差(太费时间),而是用每次训练的 “小批量数据”(比如一次练 32 张图片)来估算 —— 这样既能实时适配数据,又能跟着梯度一起反向传播优化,不耽误训练效率。
BN解决的问题:
- 学习率能调大很多(不用怕参数乱飘),训练速度飙升(比如文档里 ImageNet 实验,用 1/14 的训练步数就达到了原来的精度);
- 不用小心翼翼初始化参数,容错率变高;
- 能直接用 sigmoid 这类容易 “饱和” 的激活函数(以前用这些函数训练容易卡住,现在 BN 稳住了输入分布,梯度不会消失);
- 自带正则化效果,很多时候不用 Dropout 也能防过拟合,还能减少权重正则化的强度;
- 模型最终效果更好(文档里用 BN 的模型,在 ImageNet 上的错误率比之前的最好结果还低,甚至超过了人类标注的精度)。
2025.12.29上午
1、看完了批量归一化的论文,
2、大概看了看论文:Rethinking the Inception Architecture for Computer Vision:重构计算机视觉中的Inception架构:通过 “拆大卷积、先降维再聚合、平衡深度宽度、加标签平滑” 等技巧,在不浪费算力的前提下,把 Inception 模型的分类 accuracy 拉到新高度,还给出了可复用的设计原则,让后续模型升级有章可循 —— 核心就是 “聪明用算力,不做无用功”。
- (1)大卷积核 “拆小”:省算力不丢效果
比如 5×5 卷积费算力,就拆成两个 3×3 卷积;7×7 卷积拆成三个 3×3 卷积 —— 这样计算量能省 28% 以上,还能保持同样的 “感知范围”(相当于原来能看到的图像区域没变)。更绝的是 “不对称拆分”:3×3 卷积拆成 1×3 + 3×1 卷积,算力直接省 33%,比拆成两个 2×2 还划算。
- (2)优化特征图缩小:不丢信息还省钱
原来缩小特征图(比如从 35×35 变成 17×17),要么会丢信息,要么费算力。新方法是 “并行处理”:一边用卷积(步长 2)缩小,一边用池化(步长 2)缩小,最后把结果拼起来 —— 既避免了信息瓶颈,计算量还省了不少。
- (3)辅助分类器:不是帮 “早训练”,是帮 “防过拟合”
之前以为中间加辅助分类器(相当于训练中的 “小考官”)是为了帮深层网络早点收敛,实际发现:它是 “正则器”—— 能让模型不盲目自信,减少过拟合(比如给辅助分类器加 BatchNorm,效果还能再提一点)。
- (4)标签平滑(LSR):让模型 “不钻牛角尖”
原来训练时,模型会拼命把 “正确标签” 的概率拉到 100%,容易过拟合(比如只记训练数据,不会泛化)。标签平滑是给正确标签 “降点权重”(比如从 1.0 变成 0.9),剩下的 0.1 分给所有其他标签 —— 让模型不那么绝对,泛化能力更强,ImageNet 上能提 0.2% 的 accuracy。
- (5)BatchNorm 加持:之前的好技术接着用
把之前提出的 BatchNorm(批量归一化)加进去,尤其是辅助分类器里,能让训练更稳、更快,还能当正则器用。
3、改了.cache的默认路径:重装Anaconda需要做的事情
4、复现了基于Inception V1的Flowers

2025.12.29下午
1、将单图预测改为多图同时预测。
2、看了ResNet模型,看了Youtube的视频:Leaf Disease Classification Using PyTorch
这个博主分享了 Tez 库,Tez 比tqdm好用多了。
3、在Kaggle看了Plant Disease Classification - ResNet- 99.2%
4、大致看了知网的文章:残差网络研究综述
里面提到ResNet涉及到行人识别,我看了一下引用的文章:行人重识别的分步学习方法
- 单样本视频行人重识别(One-Shot Video Re-ID),即每个身份仅 1 个标注轨迹(tracklet)的条件下,利用无标注轨迹提升模型性能。
5、实现了植物病害分类 - ResNet。
6、ResNet网络结构,实现了基于ResNet的预训练模型对flowers数据集进行分类。
- 特点:
- 残差学习:通过优化HighWay(能训练超深网络,但训练速度慢且无法通过加深网络显著提升性能),用捷径连接取代网关单元,保留原始信息、减少参数,可加速超深网络训练、提升准确率,避免梯度消失 / 爆炸。

2025.12.30上午
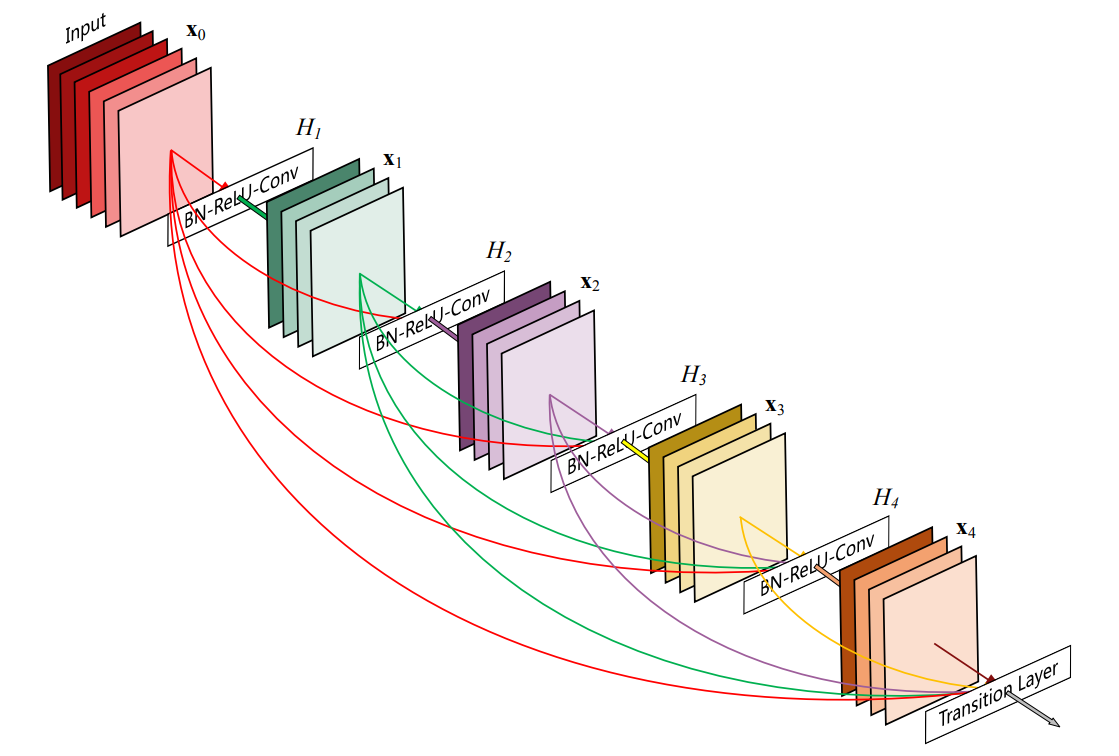
1、了解了一下DenseNet;
传统的卷积神经网络(如 ResNet)的层是串联的,每一层只接收来自前一层的信息。ResNet 通过 “跳跃连接”(Skip Connection)让信息可以跨层流动,但本质上还是一种 “加法” 操作。DenseNet 则走得更远,它提出了一种密集连接的模式:
- 每个层都与前面所有层直接相连。
- 每个层的输入是前面所有层输出的拼接(concatenation)。
- 每个层只学习一个很小的、独特的特征图集合。
2、大致看了一下MobileNet。神经架构搜索 (Neural Architecture Search, NAS) + 改进的激活函数 (h-swish)
- 特点:
- 利用 NAS 技术自动搜索最优的网络结构,包括每个块的卷积核大小、扩展因子等。
- 引入了h-swish激活函数,它是 swish 函数的近似版本,在保持类似性能的同时计算更快。
- 进一步优化了网络结构,如在早期层使用更小的卷积核。
3、看了一下迁移学习,使用在A任务上预训练好的模型作为特征提取器,提取目标任务数据的特征,然后用这些特征训练一个B任务的分类器或回归器。
- 步骤:
- 加载预训练模型(如 ResNet、VGG、MobileNet 等)。
- 冻结预训练模型的大部分层(通常是卷积层),只保留最后几层或全连接层。
- 将目标任务的数据输入预训练模型,提取特征。
- 用提取的特征训练一个新的分类器(如 SVM、逻辑回归或新的全连接层)。
4、看了几种改进的生成对抗网络模型
- 深度卷积生成对抗网络( Deep Convolutional Generative Adversarial Network)
- 基于能量的生成对抗网络(Energy-based Generative Adversarial Network)
- Wasserstein Generative Adversarial Network
5、大致看了一下强化学习和深度强化学习
6、规划了大致完成毕设的路线:基于背景抑制与表观特征融合的行人重识别模型设计与实现
2025.12.30下午
1、看了目标检测常用的深度学习网络结构
IoU:两个图形面积的交集和并集的比值
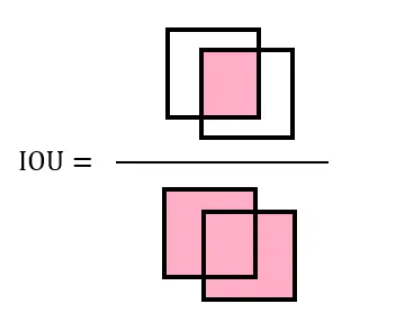
⚡️缺点
如果只使用IoU交并比来计算目标框损失的话会有以下问题:
- 预测框与真实框之间不相交的时候,如果|A∩B|=0,IOU=0,无法进行梯度计算;
- 相同的IOU反映不出实际预测框与真实框之间的情况,虽然这三个框的IoU值相等,但是预测框与真实框之间的相对位置却完全不一样;
非极大值抑制Non-Maximum Suppression:找到局部极大值,并筛除(抑制)邻域内其余的值。
2、YOLO(You Only Look Once)
YOLO的泛化能力很强,
- 在YOLO(You Only Look Once)模型中,端到端指的是将输入数据(如图像)直接映射到输出结果(如目标检测框和类别),通过一个统一的深度学习模型进行处理。
- 端到端(End-to-End)架构是指在机器学习和深度学习中,使用一个单一的模型直接将原始输入(如传感器数据、图像等)映射到最终输出(如控制指令、分类结果等),而不需要中间的手动特征提取或多个处理步骤。这种方法简化了模型的设计和训练过程,通常能够提高效率和性能。
3、大概看了一下R-CNN的思路。
R-CNN:利用候选区域与卷积神经网络做目标定位。
- 对输入图像使用选择性搜索来选取多个高质量的提议区域 (Uijlings et al., 2013)。这些提议区域通常是在多个尺度下选取的,并具有不同的形状和大小。每个提议区域都将被标注类别和真实边界框;
- 选择一个预训练的卷积神经网络,并将其在输出层之前截断。将每个提议区域变形为网络需要的输入尺寸,并通过前向传播输出抽取的提议区域特征;
- 将每个提议区域的特征连同其标注的类别作为一个样本。训练多个支持向量机对目标分类,其中每个支持向量机用来判断样本是否属于某一个类别;
- 将每个提议区域的特征连同其标注的边界框作为一个样本,训练线性回归模型来预测真实边界框。
尽管R-CNN模型通过预训练的卷积神经网络有效地抽取了图像特征,但它的速度很慢。 想象一下,我们可能从一张图像中选出上千个提议区域,这需要上千次的卷积神经网络的前向传播来执行目标检测。 这种庞大的计算量使得R-CNN在现实世界中难以被广泛应用。
4、大概看了Fast R-CNN、Faster R-CNN
- Fast R-CNN
- 与R-CNN相比,Fast R-CNN用来提取特征的卷积神经网络的输入是整个图像,而不是各个提议区域。此外,这个网络通常会参与训练。设输入为一张图像,将卷积神经网络的输出的形状记为 ;
- 假设选择性搜索生成了 个提议区域。这些形状各异的提议区域在卷积神经网络的输出上分别标出了形状各异的兴趣区域。然后,这些感兴趣的区域需要进一步抽取出形状相同的特征,以便于连结后输出。为了实现这一目标,Fast R-CNN引入了兴趣区域汇聚层(RoI pooling):将卷积神经网络的输出和提议区域作为输入,输出连结后的各个提议区域抽取的特征,形状为 ;
- 通过全连接层将输出形状变换为 ,其中超参数 取决于模型设计;
- 预测 个提议区域中每个区域的类别和边界框。更具体地说,在预测类别和边界框时,将全连接层的输出分别转换为形状为 ( 是类别的数量)的输出和形状为 的输出。其中预测类别时使用softmax回归。
- Faster R-CNN
与Fast R-CNN相比,Faster R-CNN只将生成提议区域的方法从选择性搜索改为了区域提议网络,模型的其余部分保持不变。具体来说,区域提议网络的计算步骤如下:
- 使用填充为1的 卷积层变换卷积神经网络的输出,并将输出通道数记为 。这样,卷积神经网络为图像抽取的特征图中的每个单元均得到一个长度为 的新特征。
- 以特征图的每个像素为中心,生成多个不同大小和宽高比的锚框并标注它们。
- 使用锚框中心单元长度为 的特征,分别预测该锚框的二元类别(含目标还是背景)和边界框。
- 使用非极大值抑制,从预测类别为目标的预测边界框中移除相似的结果。最终输出的预测边界框即是兴趣区域汇聚层所需的提议区域。
值得一提的是,区域提议网络作为Faster R-CNN模型的一部分,是和整个模型一起训练得到的。 换句话说,Faster R-CNN的目标函数不仅包括目标检测中的类别和边界框预测,还包括区域提议网络中锚框的二元类别和边界框预测。 作为端到端训练的结果,区域提议网络能够学习到如何生成高质量的提议区域,从而在减少了从数据中学习的提议区域的数量的情况下,仍保持目标检测的精度。
5 、F1-Score 是 精确率(Precision) 和 召回率(Recall) 的调和平均数,用来综合评价模型的整体表现,公式如下:
精确率(Precision):模型预测为 “正例” 的结果中,真正是正例的比例 → 衡量 “预测准不准”;
6、召回率(Recall):所有真实的正例中,被模型找出来的比例 → 衡量 “找得全不全”;
7、为毕设做准备。先跑通了一个标准的Re-ID流程。
- 计划书如下
”基于背景抑制与表观特征融合的行人重识别模型设计与实现“计划书
2025.12.31
上午帮室友调了电脑,
下午收拾东西出去玩了
2026年1月
2026.1.1
去椰梦长廊
2026.1.2
看三亚千古情
2026.1.3
亚龙湾
2026.1.4
返程
2026.1.5
缓了缓,帮室友调代码
2026.1.6
帮室友调代码
2026.1.7
帮室友调代码
2026.1.8
帮室友调代码
2026.1.9上午
看了基于注意力机制行人重识别REID
数据集汇总:The Awesome Person Re-Identification Datasets
数据集汇总:行人重识别数据集汇总

Market-1501谷歌下载 参考这个博主:gmHappy
Kaggle下载链接:market_1501
夸克网盘下载链接:market_1501
Market-1501 是行人重识别(Re-ID)领域经典的大规模公开基准数据集,由清华大学团队于 2015 年发布,采集于清华大学校园超市前,用于推动跨摄像头行人检索算法的研发与评测。
- 核心优势:学界标准基准,数据规范、标注清晰,适合快速验证模型基础性能与消融实验。
- 关键指标:6 个摄像头(5 高清 + 1 低清),1501 个行人,32668 张图像;训练 / 测试 / 查询分别为 751/750 人、12936/19732/3368 张图。
- 适配点:背景以校园为主,复杂度适中,适合初期调试背景抑制与特征融合模块;低清摄像头数据可验证模型对分辨率变化的适应性。
- 缺点:场景相对单一,建议仅用于基准对比,不单独作为主实验数据。
CUHK03数据集下载: 密码:38ff
Kaggle下载:CUHK03
夸克网盘:CUHK03
CUHK03是香港中文大学(CUHK)校园内的 5 对不同视角的摄像头,也是第一个大到足以进行深度学习的人物再识别数据集。它提供了从可变形零件模型(DPM)中检测到的边界框和手动标记。对于这个数据集,人员检测质量相对较好。
- 核心优势:提供人工标注与机器检测两种边界框,适合研究背景抑制中的行人定位精度影响;样本量适中,适合快速迭代与小样本实验。
- 关键指标:2 个摄像头,1360 个行人,13164 张图像;训练 / 测试分别为 767/593 人,平均每人 9.6 张训练图。
- 适配点:两种标注方式可用于对比背景抑制对检测误差的敏感度;图像分辨率较高,适合精细的表观特征提取与融合实验。
- 缺点:摄像头数量少,跨视角背景差异有限,建议用于专项实验而非整体评估。
看了MSMT17,北大的行人数据集,下载需要先签订一个协议书,签了给他们发了邮件,还没回。其他渠道我也看了,不太好。
MSMT17(Multi-Scene Multi-Time2017)多场景多时段
下载链接1:modelscope
夸克网盘:MSMT17
- 核心优势:多场景、多光照、大样本,背景干扰丰富,适配背景抑制算法的强鲁棒性验证;表观变化(姿态、遮挡、季节)多样,适合特征融合的有效性测试。
- 关键指标:12 个摄像头(含高低清),4101 个行人,126441 张图像;训练 / 测试 / 查询分别为 3262/839 人、82161/44280/11659 张图。
- 适配点:跨摄像头背景差异大,能充分验证背景抑制模块;多季节、多光照下的表观变化,可检验特征融合的稳定性。
2026.1.9下午
1、研究了MSMT17数据集下载
2、复现了基于CUHK03数据集的行人重识别PersonReID-main
3、准备了看了考研复试的视频
2026.1.10上午
1、看了几篇关于“基于背景抑制与表观特征融合的行人重识别模型”的论文
2、汇总了一下数据集,
3、AI辅助读论文:
- 1、请提炼一下这篇文章的核心观点。
- 2、这篇文章的主题是什么?
- 3、作者在哪些方面提供了新颖的见解?
- 4、这篇文章主要采用了什么研究方法?
- 5、文献中的数据支持了哪些观点?
- 6、作者使用了哪些重要论据来支持观点?
- 7、这篇文章对该领域有何贡献?
- 8、能帮我找出文献的论文陈述吗?
- 9、这篇文章的主要结论是什么?
2026.1.10下午
1、准备了组会的 内容
2、数据集汇总:夸克网盘
3、缓缓
期间在忙其他事情
2026.1.17下午
1、下午查找文献,找到了一个关于可视化搜索的网站:
2、准备周日(明天)需要讲的ppt
2026.1.19上午
1、复现并完善:结合前景分割的多特征融合行人重识别
2、文章提出了一种叫做MFSNet(结合前景分割的多特征融合网络)的方法该网络基于ResNet50骨干网络,主要由以下三个创新模块组成:
| 模块 | 内容 |
| 前景分割模块 | 通过重识别任务来约束缺陷膜预测,既能去除背景,又能保持前景图像的平滑性和缺陷,避免因“硬切割”导致的特征丢失。 |
| 多粒度特征引导分支 | 提取不同粒度(从粗到细)的特征 |
| 多尺度特征融合分支 | 提出了一种多尺度非局部拓扑(Multi-scale Non-local)方法,将不同尺度的特征映射到统一空间进行融合,增强了特征的表达能力。 |
3.损失函数(Loss Function)
模型采用了联合损失函数进行结果训练,包含三部分:
-
前景分割损失 :优化提高了准确性。
-
难样本采样三元组损失 :拉近同类距离,推远异类距离。
-
Softmax 交叉损失 :用于分类任务。
4.准确率
-
Market-1501:
-
一级准确率:96.8%
-
mAP(平均精度均值):91.5%
-
-
DukeMTMC-reID:
-
一级准确率:91.5%
-
mAP:82.3%
-
-
MSMT17:
-
一级准确率:83.9%
-
mAP:63.8%
-
2026.1.19下午
1、在几个数据集上运行,对比了一下结果,在Market-1501数据集上运行都需要2小时,太慢了
2、先计划先把模型框架整理好,把可视化图在Market-1501数据集上运行一遍,全部弄好再去泛化其他数据集。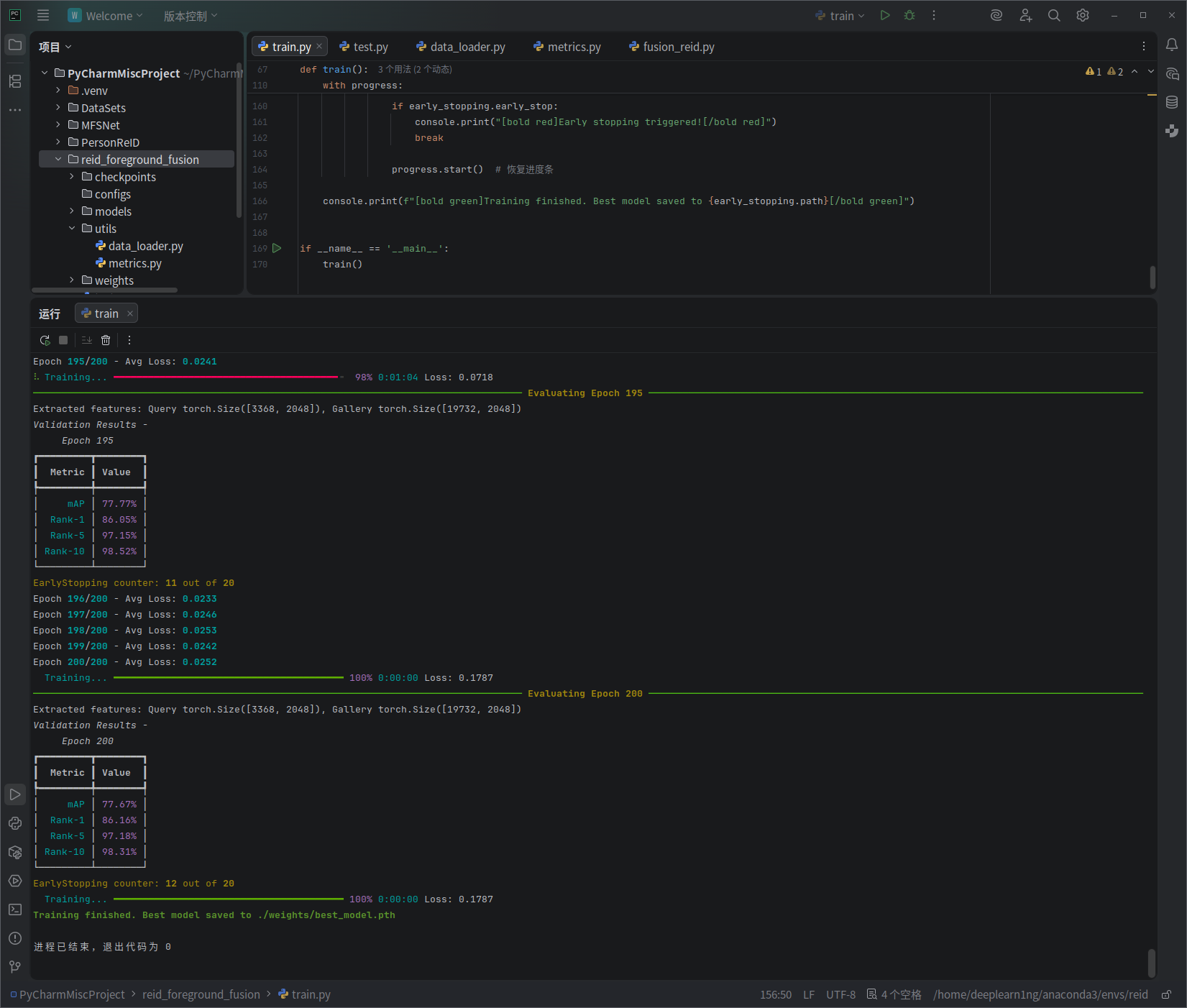
2026.1.20上午
1、我现在做了一个模型叫:reid_foreground_fusion 基于结合前景分割的多特征融合行人重识别,我通过Gemini3做了一个项目,训练结果还不是很好。
2、基于MFSNet的mAP太低,我参考论文添加了MFGB + MFFB + FSM(MFSNet),结果还行
3、几个模型都运行了一遍,效果还不是很好。准备不复现模型了,准备自己搞一个。
2026.1.21
1、基于谷歌的Gemini3,我想做一个:ReID_AMGN_BS。AMGN(基于注意力的多粒度网络)+BackgroundSuppressionLoss(基于高斯先验)的模型,mAP还可以,87了
2026.1.22
1、修复模型,添加:特征归一化 (Feature Normalization) —— 最关键的缺失步骤
2、调整 Re-ranking 参数 (Aggressive Parameters)
3、 查询扩展 (Query Expansion, QE)
4、调整 DBA (Database Augmentation / Gallery Augmentation)。
2026.1.23
1、增大输入图像分辨率:ReID 任务中,图像分辨率越高,细节(如鞋子、背包纹理)越清晰。将分辨率提升到 **384 x 128** 是刷分的常规手段,
增加之后,模型训练很慢,eval模块在CPU上运行,太慢了。
2、引入 GeM 池化 (Generalized Mean Pooling)
3、换用余弦退火学习率 (Cosine Annealing LR)
修改完模型mAP最好能上90了
2026.1.24上午
1、修复了“热身 (Warmup)”缺失的问题
问题描述: 配置文件 `configs/amgn_baseline.yml` 中定义了 `WARMUP_EPOCHS: 10`,但在 `train.py` 代码中,直接使用了 `CosineAnnealingLR`,完全忽略了 Warmup 配置。 这意味着模型一开始就用较大的学习率(0.00035)训练,可能会导致训练初期梯度震荡,影响最终收敛效果。
修复方案:需要在 `train.py` 中自定义一个带有 Warmup 功能的 Scheduler。
2、增强 Triplet Loss 的约束力
问题描述: 在 `train.py` 的训练循环中,只对全局特征 (`feats[0]`) 计算了 Triplet Loss: `l_tri = loss_tri(feats[0], labels)`。
而 AMGN Head 提取了三个特征:全局 (`feats[0]`)、上半身 (`feats[1]`)、下半身 (`feats[2]`)。 **局部分支如果不加 Triplet Loss 约束,可能学不到这就具有判别力的特征**,导致“表观特征融合”的效果打折。
**修复方案:** 让局部分支也参与度量学习。修改 `train.py` 中的 Loss 计算部分:
经过两天的修修补补,再修改re_rank之后,mAP还蛮可以的。
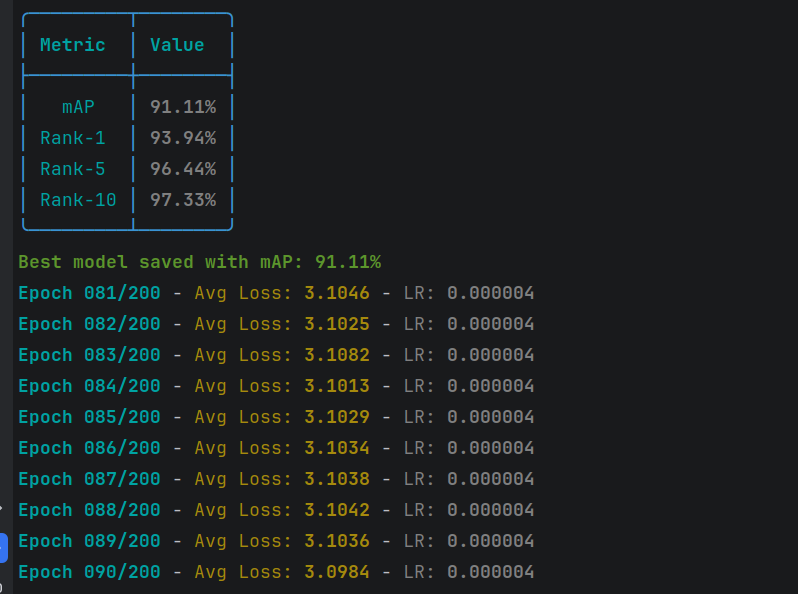
2026.1.25
1、IBN 模块设计**:手动定义了 `IBN` 类,通过 `torch.split` 将特征图通道一分为二,分别通过具有仿射参数的 `InstanceNorm2d` 和标准的 `BatchNorm2d`,最后通过 `torch.cat` 融合。这种设计允许网络同时学习**风格不变特征**(通过 IN,这对跨摄像头检索至关重要)和**内容判别特征**(通过 BN)。
- **IBN-a 架构策略**:遵循 ResNet-IBN 的标准设计(Pan et al., CVPR 2018),仅替换了 ResNet50 浅层(Layer 1-3)中 Bottleneck 结构的第一个 BN 层。Layer 4 保持不变,以保留用于身份分类的高级语义信息。
- **参数热启动 (Warm Start)**:为了最大化预训练权重的效益,在替换层时执行了“参数切片迁移”。将 ImageNet 预训练的 BN 参数切分并初始化给新的 IBN 模块,这使得模型在训练初期更加稳定,能够更快收敛。
2、引入 Center Loss (最显著的提分点)
目前的 Loss 组合是 `CrossEntropy + Triplet + BG_Loss`。在 ReID 中,加入 **Center Loss** 通常能稳定提升 1%~2% 的 mAP,因为它能显著减小类内距离。
- 原理:Triplet Loss 拉大类间距离,Center Loss 聚拢类内特征。
- 修改建议:
1. 新建 `losses/center_loss.py`。
2. 在 `train.py` 中初始化 `CenterLoss`,注意 **Center Loss 的参数需要定义一个新的优化器**(通常学习率要大一些,如 0.5)。

2026.1.26
我将代码添加到Github,新建了一个项目:BSFF-ReID
- 理论框架:AMGN + IBN 主干:集成 ResNet50-IBN-a 以增强领域不变性和对风格/背景变化的鲁棒性。
架构:采用 AMGN(基于注意力的多粒度网络)结构,提取全局和部分级(头部-肩部/上半身)特征。
- 核心模块:显式背景抑制空间注意力:引入了一个轻量级的空间注意力模块来生成软掩码,重新加权特征图以专注于人体。
物理引导损失:设计了一个自定义背景抑制损失(基于高斯先验),以明确地惩罚背景区域中的高激活值。
- 高级特征融合融合策略:将全局特征和零件特征连接成统一的表示(6144 维)。
BNNeck 优化:通过添加专用的 fusion_classifier 和批量归一化层解决了“融合训练”问题,确保融合特征在训练期间具有区分性。
- “技巧包”集成损失函数:交叉熵(标签平滑)+三元组损失(困难挖掘)+中心损失。
数据增强:随机擦除 + 颜色抖动(亮度/对比度/饱和度)。
后处理(“皇家同花顺”):- TTA:测试时增强(翻转融合)。
DBA:数据库增强(图库自我完善)。
AQE:平均查询扩展(向量化实现)。
2026.1.27
1、读了一些文献,帮别人复现了代码。解决了中文用户名创建虚拟环境的问题
2、我感觉我的模型还能再优化一点。
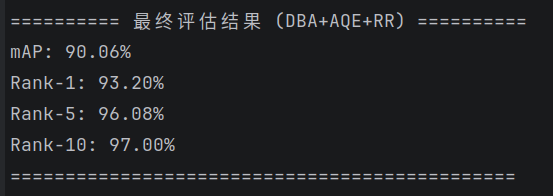
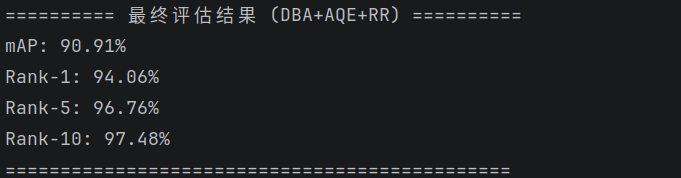
3、 换个新一点的模型试试
2026年5月
2026.5.6
经过最近两天搬迁服务器,已经成功运行market1501数据集,现在就出现DukeMTMC数据集出现的问题进行过程记载:
如果要复现情况,需要执行的requirements.txt
pip install -r requirements.txt因为服务器的torch问题,需要降低numpy版本
pip install "numpy<2.0.0" --force-reinstall
因为临时挂在,所有在每次开机需要:
mkdir -p /dev/shm/deepwrh_duke
cp -r /public/home/deepwrh/ViTBSHF/data/DukeMTMC/* /dev/shm/deepwrh_duke/使用 nohup 后台挂起(防止断网导致训练终端)
将训练任务提交到系统后台,并将日志重定向输出到文件中。即使关闭电脑或断网,服务器依然会静默计算。
nohup python tools/train.py \
--config_file configs/market_hbf_vit.yml \
--resume /public/home/deeplzy/ViTBSHF/logs/market1501/test1/vit_base_patch16_224_TransReID_latest.pth \
> nohup_train.log 2>&1 &监控方式:任务提交后,你可以随时重新连上服务器,输入以下代码:实时查看最新的训练打印信息
tail -f nohup_train.log
2026.5.6
开机切换目录代码:
cd /public/home/deeplzy/ViTBSHF临时挂载代码:
# 1. 在内存盘中创建一个临时数据文件夹
mkdir -p /dev/shm/deeplzy_market
# 2. 将挂载在公共盘的 Market 数据集全量拷贝到内存盘中 (速度很快)
cp -r /public/home/deeplzy/ViTBSHF/data/Market/* /dev/shm/deeplzy_market/短点重连代码:
nohup python tools/train.py \
--config_file configs/market_hbf_vit.yml \
--resume /public/home/deeplzy/ViTBSHF/logs/market/test1/vit_base_patch16_224_TransReID_latest.pth \
> /public/home/deeplzy/ViTBSHF/logs/market/test1/train_log.txt 2>&1 &-
nohup:即使用户退出终端或断开 SSH 连接,该进程仍会继续运行。 -
python tools/train.py:使用 Python 解释器运行位于tools/目录下的训练脚本train.py。 -
--config_file configs/market_hbf_vit.yml- 指定训练所用的配置文件路径。
-
--resume .../vit_base_patch16_224_TransReID_latest.pth:表示从指定的预训练模型或检查点(checkpoint)恢复训练。路径指向一个.pth文件, -
> /public/home/.../train_log.txt:将标准输出(stdout)重定向到指定的日志文件train_log.txt。所有print()输出或脚本正常日志都会写入此文件。 -
2>&1将标准错误(stderr)也重定向到标准输出(即同样写入train_log.txt)。 -
&将整个命令放入后台运行,立即释放终端,允许用户继续执行其他命令。
tail -f /public/home/deeplzy/ViTBSHF/logs/market/test1/train_log.txt持续跟踪并打印文件末尾新增的内容
删除指定路径代码:
rm /public/home/deeplzy/ViTBSHF/nohup_train.log
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)