LDA-1B:让机器人基础模型真正学会利用异构具身数据
0. 简介
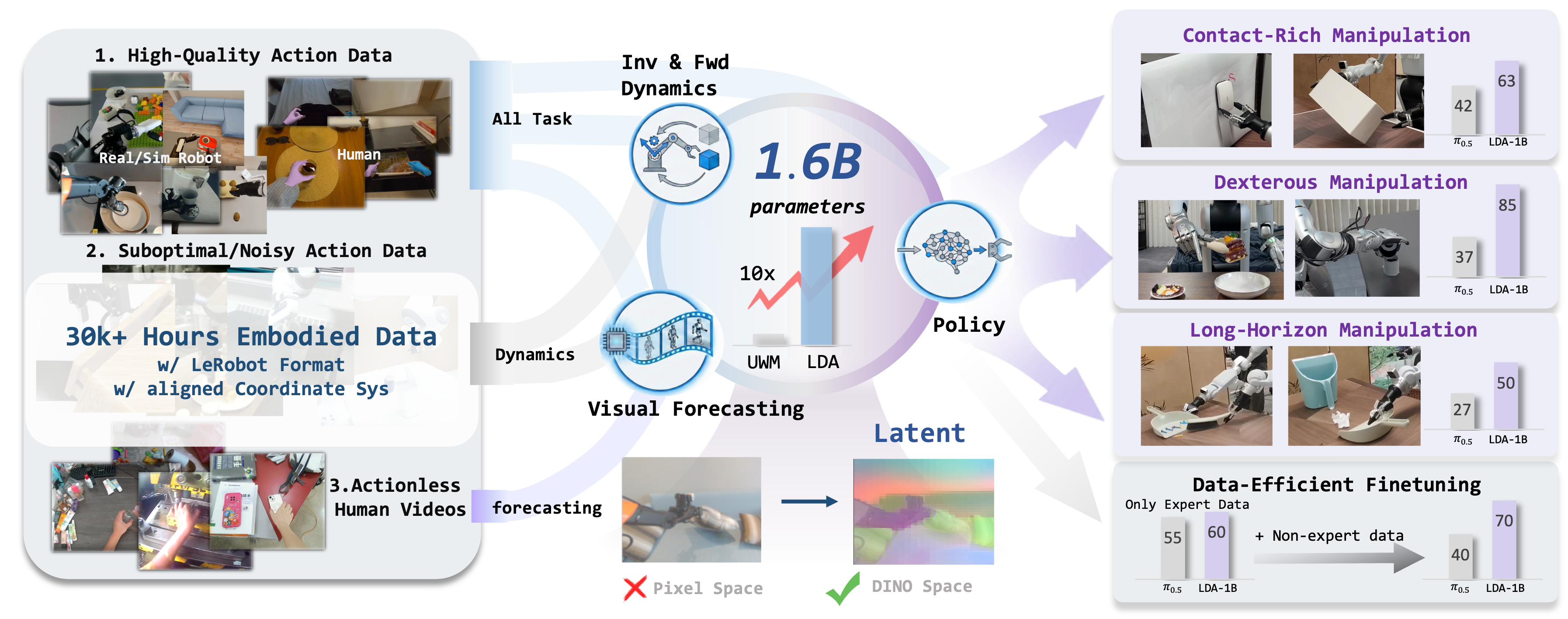
LDA-1B 要解决的不是“机器人能否模仿一个动作”,而是“机器人能否从大量质量参差、来源复杂、标注不完整的数据中持续学习世界如何变化”。过去很多机器人基础模型依赖行为克隆,也就是让模型看专家怎么做,然后学习在相似观察下输出相似动作。这条路线有效,但代价很高:需要大量高质量遥操作数据,需要严格对齐动作空间,还容易把低质量轨迹、人类视频、仿真数据排除在训练之外。LDA-1B 的核心贡献,是把这些原本难以共用的数据放进一个统一的世界-动作学习框架中,让不同质量的数据承担不同训练角色。论文 LDA-1B: Scaling Latent Dynamics Action Model via Universal Embodied Data Ingestion、项目页 PKU-EPIC LDA、开源仓库 jiangranlv/LDA-1B
1. 为什么行为克隆不够用
行为克隆的优点很清楚:训练目标直接,工程实现相对成熟,只要有足够专家轨迹,模型就能学到“在某个画面和指令下应该怎么动”。RT-1、Octo、OpenVLA、GR00T、π0 系列等工作都推动了这条路线的发展。问题在于,行为克隆把动作标签质量放在非常核心的位置,低质量数据会直接污染策略学习。例如一个人抓杯子时失败了,传统策略模型可能会把失败动作也当成可模仿对象;但从动力学角度看,杯子被碰倒后的运动过程仍然是真实物理反馈,不能简单视为无用数据。
论文对这个问题的表述很直接:现有机器人基础模型大多依赖大规模行为克隆,模仿专家动作,却丢弃了异构具身数据中可迁移的动力学知识。换句话说,机器人不应该只学习“高手怎么操作”,还应该学习“动作会如何改变世界”。这一区别非常关键。一个模型如果只记住抓取轨迹,在新物体、新背景、新位置下容易失效;如果它能理解接触、位移、遮挡、滑动、翻转等状态转移规律,就更可能在复杂任务中修正动作并处理长程误差。
2. LDA-1B 的基本思路
LDA-1B 的全称是 Latent Dynamics Action Model,可以理解为“在潜在空间里联合学习动力学和动作的模型”。它继承了统一世界模型的思想:同一个模型不仅要预测动作,还要预测未来视觉状态、根据前后状态反推动作,并在没有动作标注时进行视觉预测。论文把这些目标归纳为四类:策略学习、前向动力学、逆向动力学和视觉预测。这样设计以后,模型不再只回答“下一步怎么做”,还可以回答“如果这么做,画面中的物体会怎样变化”。
这四个训练目标在一个多模态扩散 Transformer 中共同优化。策略学习对应从当前观察和语言指令生成未来动作;前向动力学对应在给定动作后预测未来视觉表征;逆向动力学对应从前后视觉状态反推动作;视觉预测则不依赖动作标签,只根据当前观察推断未来状态。这个组合使 LDA-1B 能够利用不同监督强度的数据:专家机器人轨迹可以训练策略和动力学,噪声轨迹可以主要训练动力学,无动作人类视频可以训练视觉预测。数据的价值不再由“是否完美可模仿”决定,而由“它能监督哪一类能力”决定。
3. EI-30K:把数据先组织成可学习的形态
LDA-1B 背后的数据集叫 EI-30K,论文称其包含超过 30k 小时的具身交互轨迹,包括 8.03k 小时真实机器人数据、8.6k 小时仿真机器人数据、7.2k 小时带动作的人类演示,以及 10k 小时无动作标注的人类视频。这个数据规模本身并不是唯一重点,更重要的是它覆盖了真实与仿真、人类与机器人、高质量与低质量、有动作与无动作等多个维度。传统做法往往会把这些数据拆开处理,或者只取其中最干净的一部分;EI-30K 的目标则是把它们统一到同一训练语义下。
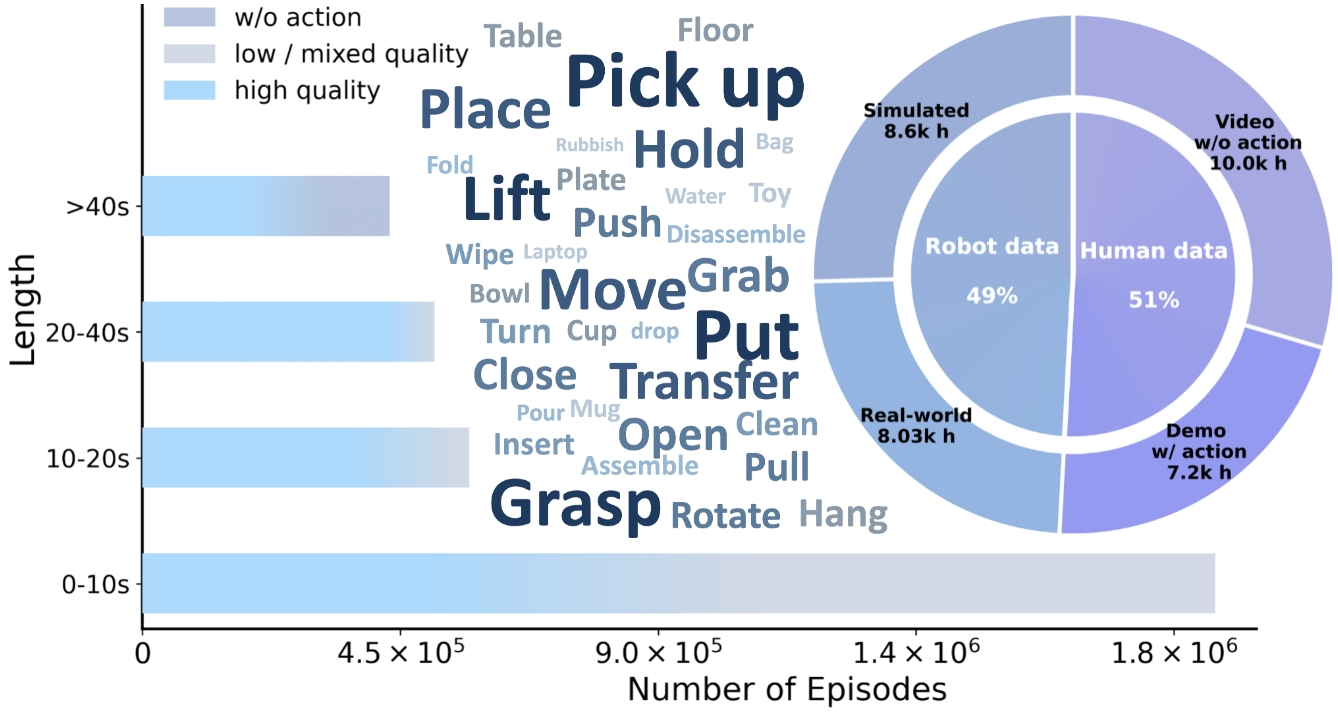
统一数据格式是这里的基础工程。论文说明 EI-30K 将数据转换为 LeRobot 格式,而 LeRobot 官方文档也将其描述为面向机器人学习数据的标准化格式,能够统一访问多模态时间序列、传感器运动信号、多相机视频以及元数据。对具身模型来说,格式统一不是琐碎细节,而是规模化训练的前提:如果每个数据集的视频、动作、时间戳、语言标注、相机参数都用不同方式存放,模型训练前的大量成本会消耗在数据清洗和适配上,而不是学习本身。
TRAINING_TASKS = ["policy", "forward_dynamics", "inverse_dynamics", "video_gen"]
VIDEOGEN_DATASET = ["egocentric_10k", "taste_rob", "rh20t"]
论文中把第四类任务称为 visual forecasting,代码中对应的任务名是 video_gen。在 get_vla_dataset 里,普通有动作数据进入 LeRobotSingleDataset;egocentric_10k、taste_rob、rh20t 这类无动作或视频预测数据进入 VideoTaskSingleDataset。如果混合数据里包含视频预测数据,函数会返回带动作数据集和全量数据集的组合;训练时实际用全量数据集,但每个样本会被任务采样器分配为 policy、forward_dynamics、inverse_dynamics 或 video_gen。这说明官方代码不是简单把所有数据混在一起,而是在 dataloader 层就把训练目标作为采样维度显式建模。
task_weights = cfg.datasets.vla_data.get(
"training_task_weights", [1.0] * len(TRAINING_TASKS)
)
sampler = DistributedTaskBatchSampler(
all_dataset,
batch_size=cfg.datasets.vla_data.per_device_batch_size,
tasks=TRAINING_TASKS,
task_weights=dict(zip(TRAINING_TASKS, task_weights)),
seed=cfg.seed,
drop_last=True,
)
DistributedTaskBatchSampler 是 LDA-1B 训练实现中很重要的一层。官方代码要求 batch_size >= len(tasks),并在每个 batch 中先放入四类任务各一个样本,再按照 training_task_weights 对剩余位置采样。这样做有两个效果:第一,保证 policy、forward dynamics、inverse dynamics、video_gen 不会因为数据量差异而长期缺席;第二,仍然允许通过权重调节任务比例。对于异构具身数据来说,这是比“随机混合数据集”更稳的做法,因为不同数据源天然对应不同监督信号,训练采样必须显式感知任务类型。
4. 动作空间如何跨本体对齐
多机器人、多灵巧手、多数据源训练的一个难点是动作含义不一致。双指夹爪的“闭合宽度”、22 自由度灵巧手的关节配置、人类手部 MANO 参数,在原始形式上并不能直接混合。LDA-1B 采用手部中心的动作表示,将机器人末端执行器或人类手腕统一到共享坐标系下。机器人侧通常表示为 6 自由度末端位姿加夹爪宽度或手指关节;人类侧则记录 6 自由度腕部位姿和 MANO 手部参数,并保留相机外参以消除第一视角头部运动带来的干扰。

这种坐标系对齐的意义在于,把“身体形态差异”尽量转化为“统一坐标系中的手部运动差异”。如果没有这一步,同样是“向右推杯子”,不同数据集里的动作向量可能代表完全不同的坐标方向、尺度或执行器状态,模型只能学到噪声。坐标对齐之后,人类操作视频、双指夹爪轨迹、灵巧手轨迹之间才有共享结构:手接近物体、接触物体、施加力、物体移动或翻转。这些才是机器人跨本体泛化时真正需要迁移的部分。
if self.use_delta_action:
raw_data = self.get_delta_action_from_raw_data(
raw_data, embodiment_tag, dataset.history_action_indices
)
for action_key in dataset.modality_keys["action"]:
padded_action, mask = pad_action_state_with_key(
data[action_key][history_len:], action_key, dataset_single_arm
)
action.append(padded_action)
action_mask.append(mask)
action = np.concatenate(action, axis=1).astype(np.float16)
action_mask = np.concatenate(action_mask, axis=1)
action, action_mask = pad_action_state_to_max_length(
action, action_mask, self.action_dim
)
上面这段是官方代码中真正进入训练 batch 前的动作处理路径,位置在 LeRobotMixtureDataset.__getitem__。它会读取当前样本的动作字段,根据 use_delta_action 决定是否调用 get_delta_action_from_raw_data,再逐个 action key 做 padding 和 mask 生成,最后把多个动作子字段拼接为统一长度的 action tensor。这里的 mask 很关键,因为不同本体并不一定拥有同样的动作维度;代码通过 pad_action_state_to_max_length 把它们补到全局 action_dim,同时用 action_mask 标记哪些维度真实有效。论文中“跨本体动作对齐”的几何标定和清洗细节并未在当前开源仓库中完整释放,但训练代码已经能看到统一动作向量、历史动作、mask 和 embodiment id 如何进入模型。
EMBODIMENT_TAG_MAPPING = {
EmbodimentTag.AGIBOT_GRIPPER.value: 0,
EmbodimentTag.Galaxea.value: 1,
EmbodimentTag.Droid.value: 2,
EmbodimentTag.Unitree.value: 3,
EmbodimentTag.FRANKA.value: 4,
EmbodimentTag.OXE.value: 5,
}
embodiment_id 不是装饰性字段,它会影响动作编码器和解码器的参数选择。官方 FlowmatchingActionHead 在 max_num_embodiments > 1 时启用 CategorySpecificMLP 和 MultiEmbodimentActionEncoder,为不同本体使用 category-specific 的线性层;当只有单一本体时,退化为普通 MLP 和普通 ActionEncoder。这相当于在共享 MM-DiT 主干之外,为不同机器人保留一层轻量本体适配能力:共享层学习通用视觉-动作动力学,本体相关层负责把统一隐空间映射到具体动作维度和执行器语义。
5. 为什么不用像素预测未来
传统世界模型常常尝试在像素空间预测未来画面,但像素级目标会把大量训练能力浪费在背景纹理、光照、相机噪声和无关细节上。机器人真正需要的不是把下一帧渲染得好看,而是理解杯子、抽屉、锤子、扫帚等对象在动作作用下如何变化。LDA-1B 因此选择在 DINOv3 的视觉潜空间中建模未来状态。DINOv3 官方资料强调其能够产生高质量 dense features,并在多类视觉任务上表现出较强通用性,这类特征更适合保留物体结构、空间关系和语义信息。
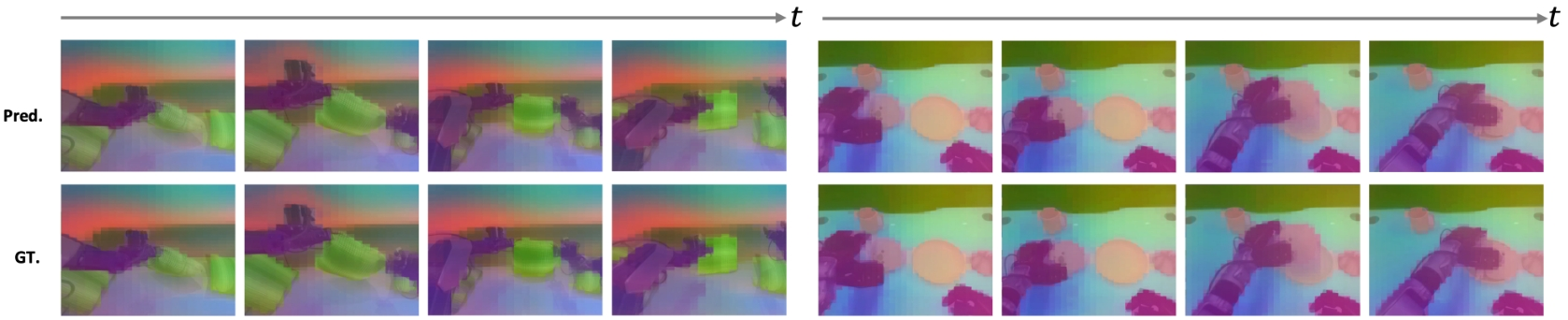
可以把 DINO 潜空间理解为“压缩后的视觉世界”。模型不再预测每个像素的颜色,而是预测图像块级别的语义与几何表征。这样做有两个直接好处:一是训练目标更接近机器人控制所需的物体级变化,二是减少光照和背景干扰对损失函数的支配。论文中的消融实验也支持这一点:在 RoboCasa-GR1 上,使用 VAE 视觉表征的 UWM 变体即使扩到 1B 参数,成功率仍明显低于使用 DINO 表征的 LDA;从 VAE 切换到 DINO 后,性能出现大幅提升。
if self.vision_encoder_type == "dinov3":
pretrained_model_name = os.path.join(
config.vision_encoder_path,
f"dinov3-vit{self.vision_encoder_size}16-pretrain-lvd1689m",
)
self.transform = AutoImageProcessor.from_pretrained(pretrained_model_name)
self.vision_encoder = DINOv3ViTModel.from_pretrained(
pretrained_model_name
).eval()
register_tokens = self.vision_encoder.config.num_register_tokens
self.glob_len = 1 + register_tokens
这段来自官方 FlowmatchingActionHead.__init__。代码中 vision_encoder_type 支持 dinov3、vjepa2 和 vae,其中 LDA-1B 主线使用 dinov3。加载后立即 .eval(),训练脚本默认冻结 action_model.vision_encoder,对应脚本中的 freeze_module_list='qwen_vl_interface,action_model.vision_encoder'。这意味着 DINOv3 在训练中主要作为固定特征抽取器:输入图像先经过 AutoImageProcessor 预处理,再由 DINOv3ViTModel 输出 last_hidden_state,后续动力学预测目标是在这些 token 上计算,而不是在 RGB 像素上计算。
def encode_future_img(self, next_obs, microbatch_size=72):
if self.vision_encoder_type == "dinov3":
next_obs = rearrange(next_obs, "b v t c h w -> (b v t) c h w")
transformed_imgs = []
for i in range(0, next_obs.shape[0], microbatch_size):
batch_next_obs = next_obs[i : i + microbatch_size]
with torch.no_grad():
output = self.vision_encoder(batch_next_obs)
batch_next_obs = output.last_hidden_state
transformed_imgs.append(batch_next_obs)
next_obs = torch.cat(transformed_imgs, dim=0)
return next_obs
encode_future_img 展示了官方实现为什么适合大 batch 训练:图像按 (batch, view, time) 展开为 (b v t) 后分 microbatch 送入视觉编码器,并且在 torch.no_grad() 中运行,避免对冻结视觉编码器保存梯度。对于 DINOv3,输出保留包含 cls/register/local patch token 的序列;后面代码会用 rearrange 将其恢复为 batch 维度,并通过 obs_merger 把当前观察和带噪未来观察在通道维拼接后映射到 MM-DiT 的输入维度。这个实现细节比“直接预测未来图片”更具体:LDA-1B 实际预测的是视觉 token 的 flow-matching velocity。
6. MM-DiT:让动作 token 和视觉 token 在同一模型里交互
LDA-1B 使用 Multi-Modal Diffusion Transformer,也就是 MM-DiT。开源仓库 README 中给出的结构信息包括:Qwen3-VL 作为语言和视觉语义编码器,DINOv3-ViT-S 作为视觉潜变量编码器,MM-DiT 主干为 16 层、hidden size 1536、32 个注意力头。模型输入包含当前观察、语言指令、扩散时间步、任务 embedding、动作 token 和未来视觉 token;输出则包括去噪后的动作块和未来视觉特征。仓库说明其单个 MMDiT backbone 会共同预测 DINOv3 token 和 16 步 action chunk。
…详情请参照古月居

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)