具身智能TL常用算法面经:经典 VLA 模型与动作生成范式(二)
1. 博客导读
这篇适合在你已经知道 VLA 基础以后再看。它的目标不是把模型名字背下来,而是让你能在面试里快速回答“这个模型输入什么、怎么生成动作、为什么这样设计、和别的模型区别在哪”。
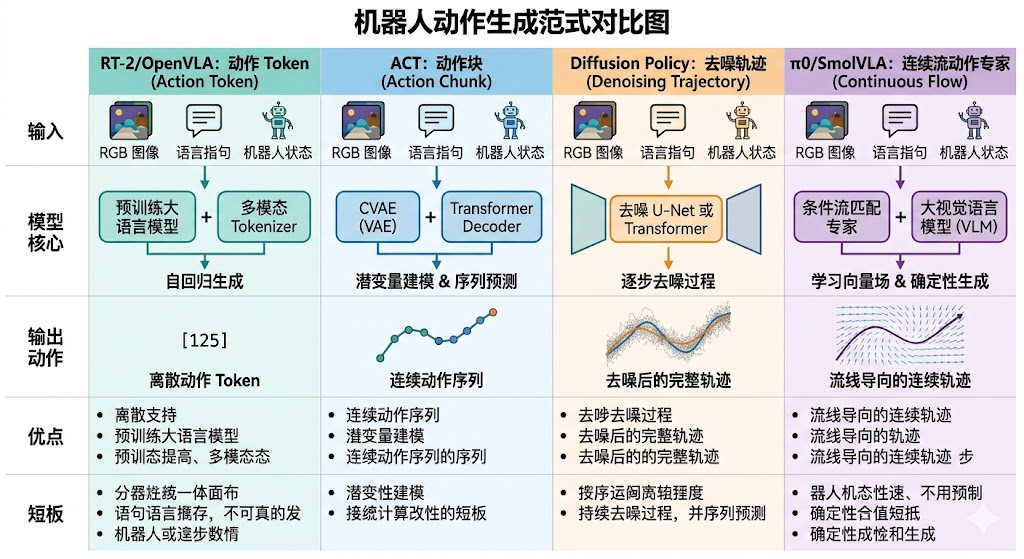
如果你只想应付面试,优先掌握 RT-2、OpenVLA、ACT、Diffusion Policy、π0、GR00T、SmolVLA、RDT-1B 这八个词。
如果你想讲出项目取舍,重点掌握“动作表示、推理延迟、数据规模、跨 embodiment、部署方式”这五个维度。
本文目标:把 RT-2、OpenVLA、ACT、Diffusion Policy、RDT-1B、π0、GR00T、SmolVLA 放到同一个框架里比较。面试时不要只背“某模型有什么创新”,而要能说清楚:输入输出、动作表示、训练数据、推理方式、适用场景、缺点和改进方向。
2. 阶段二总图谱
| 模型/方法 | 核心动作表示 | 典型优势 | 典型短板 | 面试关键词 |
|---|---|---|---|---|
| RT-2 | 离散 action token(动作 token) |
复用 VLM,语言和动作统一成 token | 离散误差、推理延迟、闭环控制压力 | web knowledge transfer(互联网知识迁移)、action tokenization(动作 token 化) |
| OpenVLA | 开源 action-token VLA(动作 token 路线 VLA) |
开源、可复现、适合二次微调 | 默认动作空间和数据混合要适配项目 | Prismatic、7B、Open X 数据 |
| ACT | CVAE(条件变分自编码器) + action chunk(动作块) |
小数据友好、工程闭环快、动作连贯 | 语言泛化弱,依赖任务内数据 | CVAE latent(条件 VAE 潜变量)、temporal ensemble(时间集成) |
| Diffusion Policy | 条件扩散生成连续轨迹 | 多峰动作、平滑轨迹、接触任务友好 | 多步采样慢,部署需加速 | denoising(去噪)、trajectory distribution(轨迹分布) |
| RDT-1B | Diffusion Transformer(扩散 Transformer) + action chunk |
大模型策略、输入模态丰富 | 算力和数据要求更高 | language + RGB + state |
| π0 | VLA + flow matching action model(流匹配动作模型) |
连续动作、跨 embodiment、推理更快 | 训练和数据工程复杂 | flow matching(流匹配)、action expert(动作专家模块) |
| GR00T | 快慢系统,VLM + DiT | 人形机器人、合成数据、系统化生态 | 对硬件和数据链路要求高 | System 1/2、humanoid foundation model |
| SmolVLA | 轻量 VLM + flow action expert(流式动作专家) |
小模型、开源、异步推理、低成本硬件 | 能力上限受模型和数据规模限制 | 450M、LeRobot、async inference(异步推理) |
3. Q1:RT-2 为什么能把动作也用“文本 token”表示?工程优势和问题是什么?
3.1 面试官问法
- RT-2 为什么可以直接用 VLM 生成机器人动作?
- action tokenization 的好处是什么?
- 离散动作 token 相比连续动作有什么问题?
3.2 考察点
面试官想看你是否理解 RT-2 的关键不是“用了大模型”,而是把机器人动作序列纳入语言模型的 token 生成范式。
3.3 30 秒回答
RT-2 把连续机器人动作离散化,再映射成类似文本 token(离散序列单元) 的形式,让 VLM(Vision-Language Model,视觉语言模型) 可以在同一个序列建模框架里同时学习语言、视觉和动作。优势是能复用互联网图文预训练带来的语义知识,工程上也能沿用 autoregressive generation(自回归生成) 框架;问题是动作精度受离散 bin 限制,多 token 生成有延迟,而且机器人闭环控制需要额外安全层。
3.4 2-3 分钟展开回答
RT-2 的核心思想是把机器人动作当成一种“新语言”。原始动作可能是末端位姿增量、旋转、夹爪开合等连续值,模型先把每个维度离散化到有限 bin(离散区间),再编码成 token。这样训练时可以把 web-scale(互联网规模) VLM 数据和机器人轨迹数据混合,让模型既学视觉语言语义,也学在给定图像和指令下生成动作 token。
工程优势有三点。
第一,统一接口。语言 token 和动作 token 都能放进 Transformer(基于注意力机制的序列建模架构) 自回归框架,不需要完全重写模型范式。
第二,语义迁移。VLM 在互联网图文中学到的物体、关系、常识可以迁移到机器人任务,比如识别“可乐罐”“抽屉”“垃圾”这些类别。
第三,任务泛化。语言指令可以组合新目标和新动词,模型有机会把语义泛化到动作。
但问题也很明确。机器人动作是连续控制,离散化会带来量化误差;自回归生成多个动作 token 会增加延迟;动作 token 不天然保证平滑、限速和碰撞安全。因此真实部署时要加动作后处理、低层控制器、安全过滤和频率管理。
3.5 常见追问
- 为什么不是直接输出浮点数?
- action token 的 bin 数怎么选?
- RT-2 类方案是否适合高精度装配?
3.6 高分追问回答
直接输出浮点数更贴近控制,但很难直接复用语言模型的 token 生成目标。RT-2 选择 tokenization 是为了把动作纳入 VLM 的生成空间。bin 数是精度和学习难度的折中:bin 太少,动作粗糙;bin 太多,类别稀疏、训练更难、生成更慢。
高精度装配不适合完全依赖离散 action token。更合理的是 VLM 负责语义和阶段选择,低层用连续控制、力控、视觉伺服或专门策略完成精细操作。
4. Q2:OpenVLA 为什么重要?和 RT-2 最大区别是什么?
4.1 面试官问法
- OpenVLA 的贡献是什么?
- OpenVLA 为什么能成为很多 VLA 项目的 baseline?
- 参数少是否一定说明模型更强?
4.2 考察点
这题考论文理解和实验判断。不要把“开源”当成唯一答案,要讲训练配方、数据混合、动作输出和可复现价值。
4.3 30 秒回答
**OpenVLA 的重要性在于它提供了一个开源、可复现的通用 VLA baseline。**它基于开源 VLM 架构和大规模机器人数据训练,让研究者可以微调、部署和对比。和 RT-2 相比,OpenVLA 的重点不是提出 action token 概念,而是把 VLA 做成开放生态下可用的模型和训练流程。
4.4 2-3 分钟展开回答
OpenVLA 常被问,是因为它连接了两个需求:一是学术上需要可复现 baseline,二是工程上需要能拿来 fine-tune(微调) 的开源模型。RT-2 很有代表性,但不少实现细节和训练数据不完全开放;OpenVLA 则让大家可以在自己的机器人数据上做二次训练。
OpenVLA 的典型输入是图像和语言,输出是离散化的机器人动作。它仍然保留 action token 路线,但更强调开放训练、数据混合和模型适配。面试里可以这样比较:
- RT-2 更像证明“VLM 的 web knowledge 可以迁移到机器人控制”。
- OpenVLA 更像提供“开源 VLA 基座和微调起点”。
- 两者都受 action token 离散化和自回归延迟影响。
- 如果项目强调连续控制和低延迟,可能要接 diffusion/flow action head 或改成 chunked continuous action。
参数少但成功率高,不一定说明架构绝对更强。 机器人 benchmark 受数据分布、动作空间、评测任务、控制频率、相机设置影响很大。回答时要避免简单说“参数少 7 倍所以更优”,而要说它在特定评测协议下实现了更好的数据/模型匹配。
4.5 常见追问
- 如果用 OpenVLA 迁移到自己的机械臂,第一步改什么?
- OpenVLA 的动作空间不匹配怎么办?
- OpenVLA 适合做高频控制吗?
4.6 高分追问回答
第一步不是直接训练,而是对齐 data schema(数据格式规范):相机视角、图像尺寸、语言标注、机器人状态、动作维度、控制频率和归一化方式。动作空间不匹配时,需要做 action adapter(动作适配器),例如把模型输出映射到本机 EEF delta(末端执行器增量) 或 joint command(关节命令);必要时重新定义 tokenization 或改连续 action head。
OpenVLA 默认不适合直接做高频低层控制。更稳的做法是让它输出低频动作或短轨迹,再由低层控制器插补执行;或者把 OpenVLA 作为高层语义基座,下面接 ACT/Diffusion/Flow 策略。
5. Q3:ACT 的训练和推理流程是什么?
5.1 面试官问法
- ACT 为什么要用 CVAE?
- action chunking 解决了什么问题?
- ACT 推理时 temporal ensemble 是怎么做的?
5.2 考察点
ACT 是小数据机器人项目里非常高频的 baseline。面试官会看你是否真懂训练/推理,而不是只知道名字。
5.3 30 秒回答
**ACT(Action Chunking with Transformers,基于 Transformer 的动作分块方法)用 Transformer 根据当前图像和机器人状态预测未来一段 action chunk(动作块)。**训练时用 CVAE(Conditional VAE,条件变分自编码器)学一个 latent style(潜在风格),让模型能处理同一任务下多种专家动作模式;推理时从 prior(先验分布) 采样或取均值,生成未来 K K K 步动作。为了减少 chunk 边界抖动,通常用 temporal ensemble(时间集成)融合多个时间步预测到的重叠动作。
5.4 2-3 分钟展开回答
ACT 的输入通常是多视角图像、机器人 proprioception(本体感知) 和当前时间信息,输出是未来 K K K 步动作。它和普通 BC 最大区别是:不是预测下一步,而是预测一段动作序列。这样可以降低有效 horizon,让模型学到局部行为片段,比如接近、闭合夹爪、抬起、移动。
**CVAE 的作用是建模动作多样性。**训练时 encoder(编码器) 看专家动作 chunk,把它压成 latent(潜变量) z z z;decoder(解码器) 根据视觉状态、机器人状态和 z z z 重建动作 chunk。这样同一个观测下,如果专家有多种合理轨迹,模型不必用 MSE(Mean Squared Error,均方误差) 学成平均动作。
推理时没有专家动作,所以从先验 z z z 采样或取均值,再由 decoder 输出动作 chunk。Temporal ensemble(时间集成) 的直觉是:每个时刻都会收到过去多次预测中对当前动作的估计,把它们加权平均,可以减少预测边界不连续和抖动。
ACT 的优点是工程简单、小数据可用、推理比多步 diffusion 快。缺点是语言泛化和跨任务泛化依赖数据;如果任务差异很大,需要引入语言条件或更强视觉语义 backbone(主干网络)。
5.5 常见追问
- ACT 和普通行为克隆区别是什么?
- CVAE 会不会 posterior collapse?
- chunk size 怎么选?
5.6 高分追问回答
普通 BC(Behavior Cloning,行为克隆) 学 a t = f ( o t ) a_t = f(o_t) at=f(ot),ACT 学 a t : t + K = f ( o t ) a_{t:t+K} = f(o_t) at:t+K=f(ot),它更像短 horizon trajectory policy(短时域轨迹策略)。CVAE 确实可能 posterior collapse(后验坍塌),所以要关注 KL 权重、latent 维度、重建质量和采样多样性。chunk size(动作块长度) 要根据控制频率和任务反应性选:太短退化成单步 BC,太长容易对新观测反应慢。
6. Q4:Diffusion Policy 和传统 BC 相比优势在哪里?
6.1 面试官问法
- Diffusion Policy 是怎么建模 action space 的?
- 它建模 joint distribution 还是 marginal?
- 为什么 diffusion 适合机器人连续动作?
6.2 考察点
这题是阶段四生成模型基础的预告。阶段二重点讲模型直觉和机器人意义。
6.3 30 秒回答
Diffusion Policy(扩散策略)把未来一段动作轨迹看作条件生成对象,在视觉和状态条件下从噪声逐步去噪得到 action trajectory(动作轨迹)。相比 BC 的单点回归,它能建模多峰动作分布和动作间相关性,通常是对整个 action chunk 的 joint distribution(联合分布) 建模,而不是每个时间步独立预测。
6.4 2-3 分钟展开回答
传统 BC 常用 MSE 回归动作。如果同一观测下有多种可行操作,比如从左边绕或从右边绕,MSE 会学到平均轨迹,而平均轨迹可能撞到物体。Diffusion Policy 用生成式建模,可以保留多峰分布。
它通常不是独立预测每一维动作,而是生成未来一段连续动作序列。模型在每个去噪步输入 noisy action chunk(加噪动作块)、视觉特征、机器人状态和时间步 embedding(向量表示),输出噪声或 denoised action(去噪后的动作)。这样动作维度之间、时间步之间的相关性都能被建模。
优势有三点:
- 连续性:动作轨迹天然连续,适合控制。
- 多峰性:能表达多个合理策略,而不是平均动作。
- 闭环性:每次只执行前几步,再根据新观测重采样。
缺点是采样步数多,推理延迟比 ACT 或直接回归高。工程上可以用 DDIM、少步采样、蒸馏、consistency model 或 flow matching 加速。
6.5 常见追问
- diffusion policy 会不会动作抖动?
- 为什么不是每个 action dimension 独立扩散?
- 多步采样慢怎么解决?
6.6 高分追问回答
如果训练数据抖、条件信息不稳定或采样步数太少,diffusion policy 仍然会抖。解决方式包括动作 chunk、temporal smoothness(时间平滑约束)、低层限速、重叠 chunk 融合和更稳定的视觉状态对齐。每个维度独立扩散会破坏动作相关性,比如末端位移、旋转和夹爪开合必须配合,所以通常建模整个轨迹分布。
7. Q5:RDT-1B 和 Diffusion Policy 怎么选?
7.1 面试官问法
- RDT-1B 和 Diffusion Policy 的定位差异是什么?
- 什么场景下小模型 DP 更好?
- 什么场景下应该上大模型策略?
7.2 考察点
这是选型题。面试官看你是否会根据任务、数据、算力做判断,而不是盲目追大模型。
7.3 30 秒回答
Diffusion Policy 更像任务专家,适合数据量中等、任务边界明确、需要平滑连续控制的场景;RDT-1B(Robotics Diffusion Transformer,机器人扩散 Transformer)更像通用机器人策略基座,适合多任务、多模态、多机器人数据和更强泛化需求。数据少、任务单一、部署算力有限时我会先用 DP/ACT;跨任务和语言泛化是主目标时再考虑 RDT/VLA。
7.4 2-3 分钟展开回答
选型可以看四个维度,核心是不要为了追大模型牺牲可验证性和部署闭环。
第一是任务范围。单任务或少数任务,比如固定桌面 pick-and-place,Diffusion Policy 足够强,训练和调试成本更低。多任务、多物体、多语言、多场景时,大模型策略更有优势。
第二是数据规模。DP 可以在相对有限的专家数据上训练出不错结果;RDT 这类大模型更依赖大规模、多样化数据,否则容易过拟合或发挥不出泛化能力。
第三是部署算力。DP 可以做小网络和少步采样,ACT 更快;RDT-1B 对 GPU、显存和推理优化要求更高。
第四是研究目标。如果目标是验证新的 action generation、数据策略或控制闭环,小模型更容易做干净实验;如果目标是做通用策略和跨 embodiment 泛化,大模型更有意义。
7.5 常见追问
- 如果只能采 100 条 demo,你会选哪个?
- 如果要支持 20 个任务呢?
- 大模型策略失败时怎么 debug?
7.6 高分追问回答
100 条 demo(示教轨迹) 我会先选 ACT 或 Diffusion Policy,配合预训练视觉 encoder 和数据增强。20 个任务且语言变化明显时,可以考虑 VLA/RDT,但要保证任务标注、动作 schema 和评测协议统一。大模型失败时要拆开看:视觉是否看对、语言是否理解、状态是否对齐、动作头是否平滑、数据是否覆盖当前场景。
8. Q6:π0、π0.5、GR00T、SmolVLA 的 flow/diffusion action expert 怎么理解?
8.1 面试官问法
- π0 和传统 VLA 的差异是什么?
- GR00T 的快慢系统具体怎么分工?
- SmolVLA 为什么强调异步推理?
8.2 考察点
这是前沿模型理解题。核心不是记模型参数,而是理解“VLM 负责语义,连续生成模型负责动作”的趋势。
8.3 30 秒回答
这些模型共同趋势是把高层语义理解和低层连续动作生成分开:VLM/LLM 处理图像语言上下文,action expert 用 flow matching 或 diffusion transformer 生成连续 action chunk。这样比纯 action token 更适合机器人控制,也比纯小策略更有语义泛化潜力。GR00T 明确做快慢系统,SmolVLA 则把这种思路做轻量化,并通过异步推理减少执行等待。
8.4 2-3 分钟展开回答
π0 的代表性意义是把 VLA 和 flow matching(流匹配) 结合。它不是把动作完全当语言 token,而是让模型在语言和视觉条件下生成连续动作轨迹。Flow matching 学的是从噪声分布到真实动作分布的 velocity field(速度场),推理时沿着向量场把噪声搬运到动作,相比传统 diffusion 有潜在的少步推理优势。
GR00T 的表述更偏系统架构。System 2(慢系统) 类似高层 VLM,负责理解环境和指令、生成计划;System 1(快系统) 负责把计划转成连续机器人动作。这种架构适合人形机器人,因为人形任务既需要语义推理,也需要快速、稳定、全身协调的动作。
SmolVLA 的价值在轻量化和工程可用。它不是一味堆参数,而是强调 450M 级别模型、开源数据、flow matching action expert、视觉 token 减少和异步推理。异步推理的关键是机器人执行当前 action chunk 时,并行请求下一段 chunk,避免“执行完等模型”的空档。
8.5 常见追问
- flow matching 和 diffusion action head 本质区别是什么?
- 异步推理会不会用过期观测?
- 快慢系统是不是一定优于端到端?
8.6 高分追问回答
Flow matching 和 diffusion 都是生成动作分布的方法,但训练目标不同。Diffusion 通常学逐步去噪;flow matching 学连续时间向量场。工程上更关心推理步数、稳定性和是否容易蒸馏。异步推理确实有 stale observation 风险,所以要控制 chunk 长度、队列阈值、融合规则和安全中断。快慢系统不是绝对优于端到端,但在真实部署中更容易调试、插入安全约束和优化延迟。
9. Q7:离散动作 token、ACT、Diffusion、Flow Matching 到底怎么选?
9.1 面试官问法
- 你项目里为什么不用 RT-2 那种 action token?
- ACT 和 Diffusion Policy 谁更适合你的任务?
- Flow matching 是不是一定比 diffusion 好?
9.2 考察点
这是综合 tradeoff 题。高分回答要把“任务类型、数据规模、动作精度、推理延迟、泛化需求”放到一起。
9.3 30 秒回答
如果任务语言语义复杂、动作精度要求中等,可以考虑 action token VLA;如果数据少、任务明确、想快速落地,ACT 是强 baseline;如果动作多峰、接触复杂、需要平滑轨迹,Diffusion Policy 更合适;如果要连续动作同时追求少步推理和大模型融合,可以考虑 flow matching action head。但最终要看数据和部署频率,不是范式越新越好。
9.4 2-3 分钟展开回答
我会先问五个问题。
第一,任务是否强依赖语言泛化?如果只是固定任务,没必要上大 VLA;如果语言组合多,VLA 更有价值。
第二,动作是否需要高精度连续控制?高精度装配、接触、插拔等任务不适合粗离散 token,连续 action head 更合理。
第三,数据量有多少?几十到几百条 demo,ACT/DP 更现实;大规模多任务数据才支撑通用 VLA。
第四,推理预算是多少?自回归 token 和多步 diffusion 都可能慢,需要 action chunk、缓存、少步采样或异步推理。
第五,失败成本多高?如果失败成本高,必须保留安全层、低层控制和 fallback(失败兜底策略),不应该让端到端模型直接裸控。
面试里可以给一个明确结论:我会把 ACT 作为最小可行 baseline,把 Diffusion/Flow 作为动作质量升级方向,把 OpenVLA/π0/SmolVLA 作为语言泛化和多任务扩展方向。
10. Q9:UniVLA、late action model、VQ-VAE 这类思路怎么理解?
10.1 面试官问法
- UniVLA 的 late action model 是什么?
- latent action 和直接 action 输出有什么区别?
- 为什么要在中间加 VQ-VAE 这类模块?
10.2 考察点
这类问题通常是在看你是否理解“先压缩再解码”的分层建模思路。即使你没完整复现过,也要能讲清楚它解决的是动作空间太复杂、直接回归太难、长时序太不稳定这几个问题。
10.3 30 秒回答
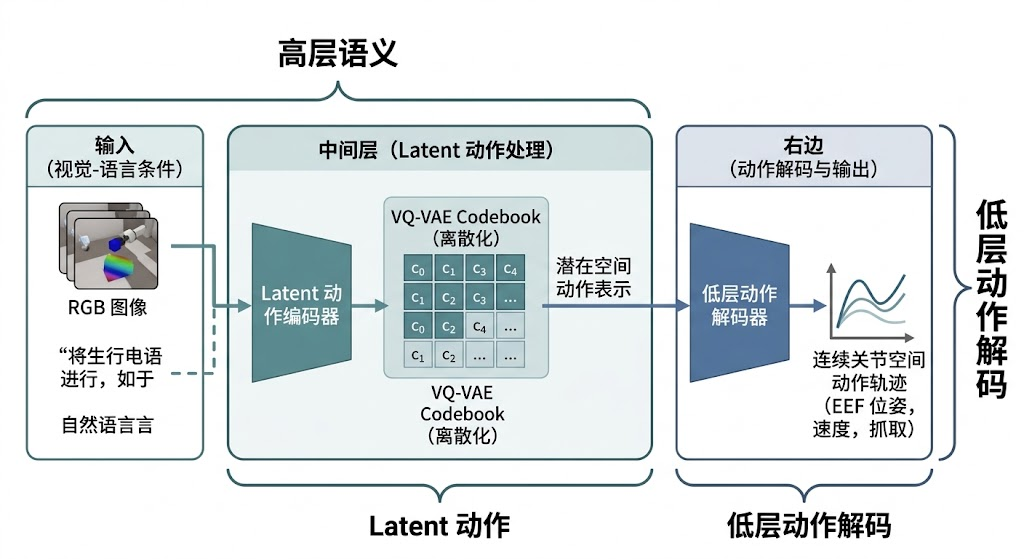
UniVLA 这类思路一般是先把复杂动作压缩成 latent action,再通过解码器生成最终动作。late action 的意思是 “先做语义或潜在规划,后做具体动作展开”。这样可以 减少动作空间维度、提高序列建模稳定性,也方便把高层语义和低层控制分开。
10.4 2-3 分钟展开回答
如果面试官提 UniVLA,你可以把它理解成 “分层式 VLA”。它的核心不是某个具体名字,而是这种建模逻辑:
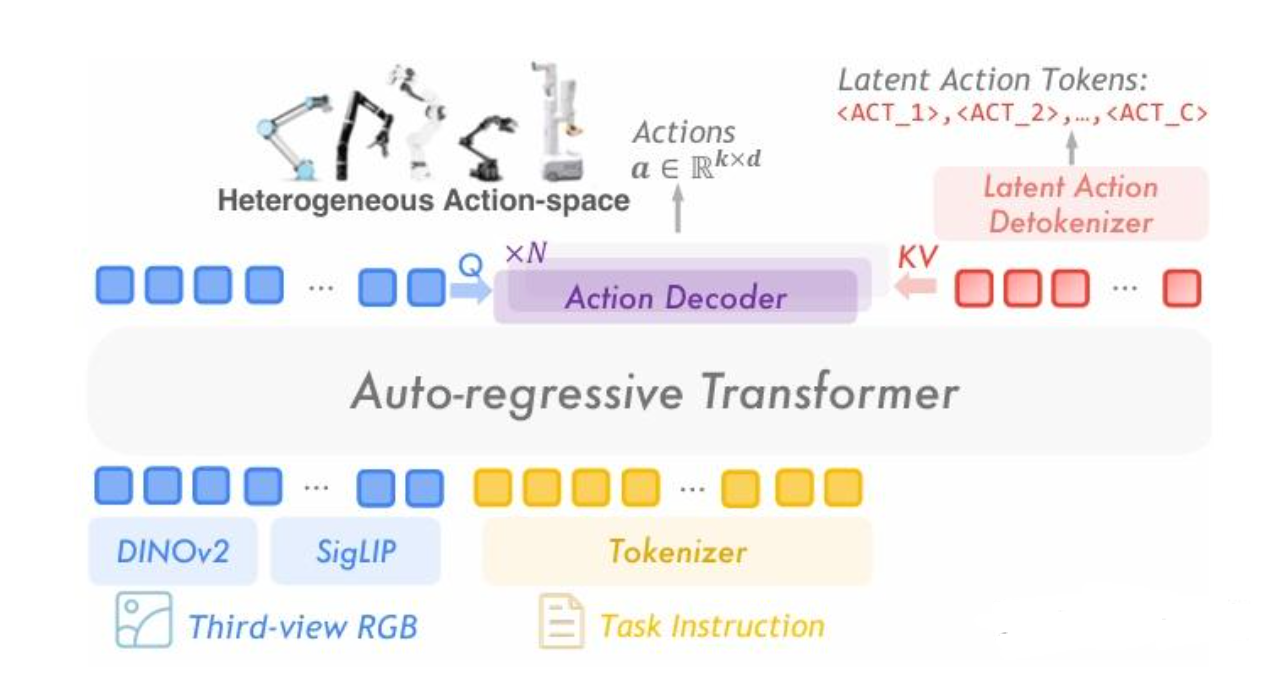
- 先用视觉语言模块理解当前场景和任务。
- 再把动作映射到一个更低维、更结构化的
latent space(潜空间)。 - 最后由
action decoder(动作解码器)或 VQ-VAE 解码成可执行动作。
这样做的原因有两个。
第一,动作直接回归太难。特别是长时序任务、连续控制、多人类风格示教时,动作分布会非常复杂。latent action 可以把**“连续多解”压缩成更紧凑的表示**。
第二,分层更适合工程。高层可以先决定“做什么”,低层再决定“怎么做”。这和大脑/小脑、快慢系统的思路一致。
VQ-VAE(Vector Quantized VAE,向量量化变分自编码器) 在这里通常承担 “离散化 latent” 的角色。VQ(Vector Quantization,向量量化) 意味着把连续 latent 映射到一组 codebook(码本) 向量里,形成更稳定的符号空间。它的优点是更容易序列化,缺点是会引入量化误差。
10.5 常见追问
- latent action 为什么有时比直接回归更稳?
- VQ-VAE 会不会损失动作细节?
- 这种结构适合什么任务?
10.6 高分追问回答
latent action 更稳,是因为它把高维连续动作先投影到一个结构化空间,减少了直接学习复杂动作分布的难度。VQ-VAE 确实会损失一部分细节,所以它更适合中高层动作计划或短轨迹块,而不是特别精细的力控任务。它适合长时序、多任务、需要层次结构的 VLA 场景。
11. Q10:RTC / real-time chunking 是什么?为什么它和动作 chunk 一起被问?
11.1 面试官问法
- RTC 你看过吗?解决什么问题?
- 动作分块增大时,怎么平衡推理延迟和控制精度?
- 异步推理怎么避免模型等控制器?
11.2 考察点
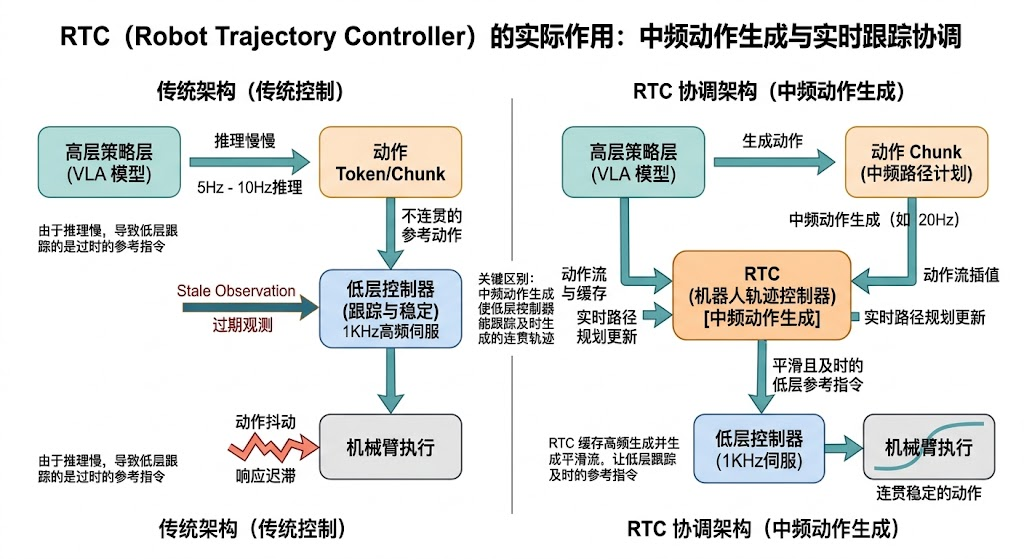
这题本质是在看你是否理解“机器人不是一次性生成答案,而是边执行边推理”。RTC 的价值在于把大模型生成和机器人执行解耦,减少空等时间。
11.3 30 秒回答
RTC(Real-Time Chunking,实时动作分块)可以理解成边执行边生成动作块:模型不是每次只输出一个动作,而是输出一段短动作块,并在执行当前块时并行生成下一块。这样能降低等待推理的空档,兼顾连续性和实时性。chunk 越大,动作越平滑,但响应越慢;chunk 越小,响应越快,但推理开销和边界抖动会更明显。
11.4 2-3 分钟展开回答
RTC 这类问题通常和 action chunk 一起问,是因为它们解决的是同一个矛盾:机器人需要实时控制,但大模型推理不是瞬时完成的。
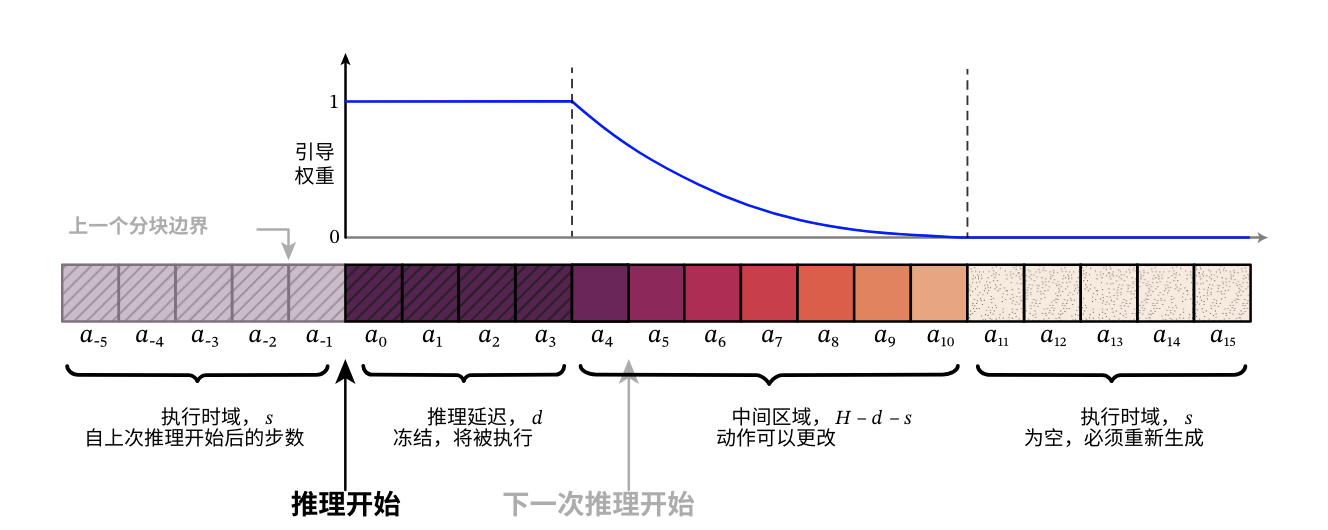
可以把控制过程理解为:
- 当前时刻 t t t,模型根据观测输出 K K K 步动作。
- 机器人先执行前 M M M 步, M ≤ K M \le K M≤K。
- 在执行期间,模型并行预测下一段动作块。
- 两段动作之间通过重叠、
interpolation(插值)或 temporal ensemble 缝合。
这样做的好处是减少“机器人在等模型”的空档,也让动作更连续。风险是观测会过期,所以需要设置 chunk 长度上限、重规划触发条件和安全中断机制。
11.5 常见追问
- RTC 和低层控制器插补是什么关系?
- 异步推理会不会带来 stale observation?
- 什么时候不适合用 RTC?
11.6 高分追问回答
RTC 不能替代低层控制器。它只是让策略层推理更符合实时系统。低层控制器负责高频稳定跟踪,RTC 负责中频动作生成。stale observation(过期观测) 可以通过缩短 chunk、实时重规划、冲突检测和安全层来缓解。特别是接触任务、动态障碍任务和高频视觉伺服任务,不适合过长的 chunk。
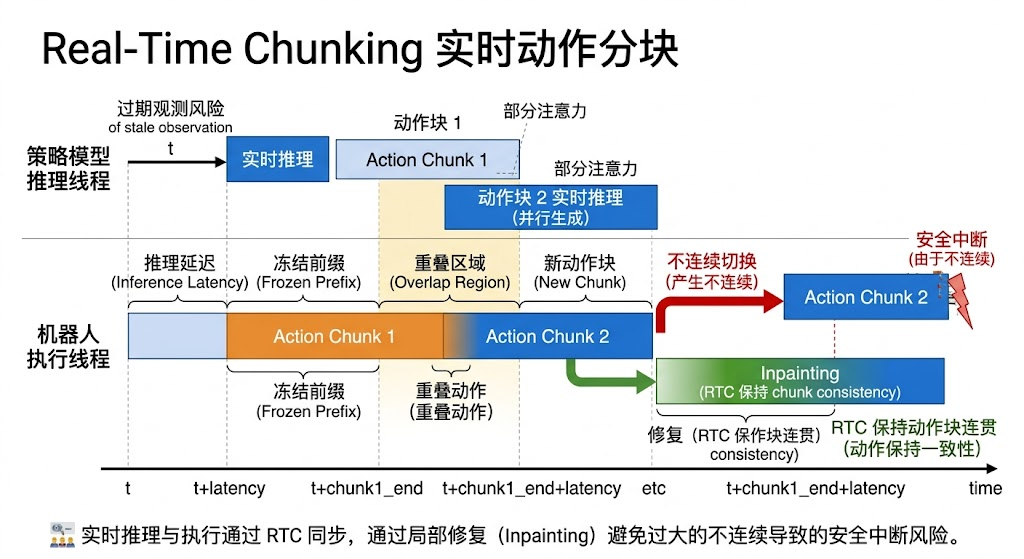
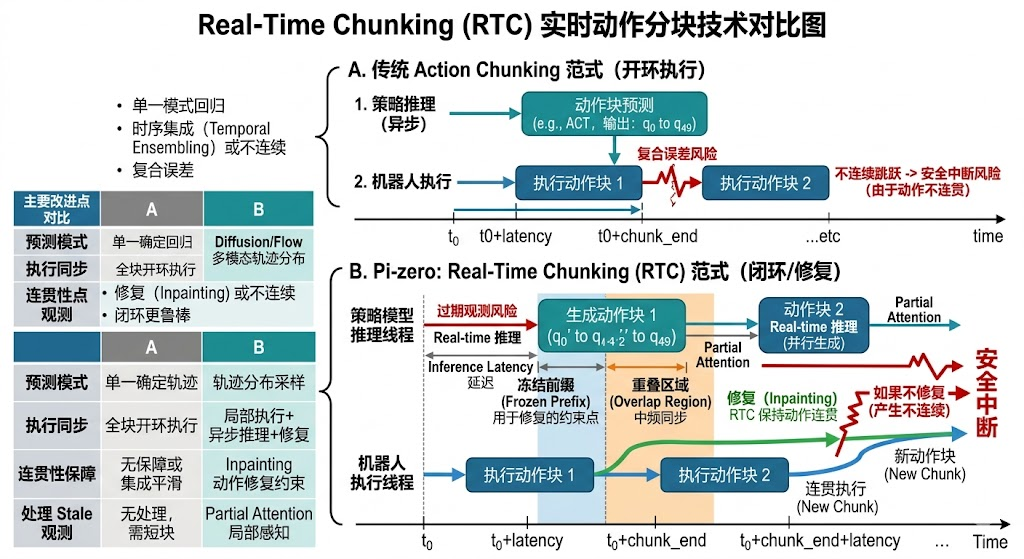
传统的 Action Chunking(动作分块) 范式(图 A 部分)通过让策略模型一次性预测未来的一段时间步序列(动作块),有效减少了逐帧推理的复合误差。然而,其本质上是一种开环执行模式:机器人完整执行完上一个动作块后,才开始根据最新的观测进行下一次推理。这种方式在块与块的切换处容易产生物理上的不连续跳跃,增加安全中断风险,且难以应对Stale Observation(过期观测)。
相比之下, π 0 \pi_0 π0 模型提出的 Real-Time Chunking(RTC,实时动作分块)(图 B 部分)则是针对大范式模型(如 Diffusion/Flow-based)高推理延迟问题的一种闭环工程优化。RTC 的核心在于引入了异步执行和局部修复(Inpainting)机制:在生成新的动作块时,RTC 算法利用上一个动作块的末端(冻结前缀)作为强约束点,通过轨迹修复(Inpainting)技术生成与当前运动状态完美对齐的新轨迹。这种方式避免了传统的“时序集成”可能带来的“平均动作”偏差,在保证动作稳定连贯的同时,实现了基于实时反馈的闭环控制。
12. Q11:π0.5、π*0.6、π0.7 到底怎么区分?
…详情请参照古月居

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)