Wild Visual Navigation:让机器人在荒野中快速学会“哪里能走”
1. 问题背景
自然环境中的导航难点,并不只是障碍物更多,而是**“视觉上像障碍物的东西”与“真实不可通过的东西”经常混在一起**。高草、灌木、细枝在相机图像中可能遮挡地面,传统占据栅格或几何建图容易把它们当成刚性障碍;但对四足机器人来说,部分草丛、浅灌木或松软地面可能完全可以通过。相反,一块看起来平整的湿滑斜坡、深坑边缘或被植被覆盖的沟壑,才可能是真正高风险区域。因此,越野导航中的核心问题不是简单识别“物体类别”,而是估计某个区域对当前机器人平台是否可通行,这就是 traversability estimation,即可通行性估计。

WVN 提出的角度很务实:不要假设世界中有固定类别,也不要要求提前标注大量森林、草地、山路图片。系统让机器人在现场由人类操作员短暂驾驶几分钟,通过自身运动反馈判断“刚才走过的地方是否好走”,再把这些经验投影回图像,在线训练一个轻量模型。换句话说,WVN 不是先在实验室学完再部署,而是在任务现场边走边学。论文报告中,系统可以在不到 5 分钟的现场训练后得到可用的可通行区域分割,并在森林、公园和草地等未知环境中支持机器人自主导航。
2. WVN 的核心思想:预训练视觉特征加在线自监督
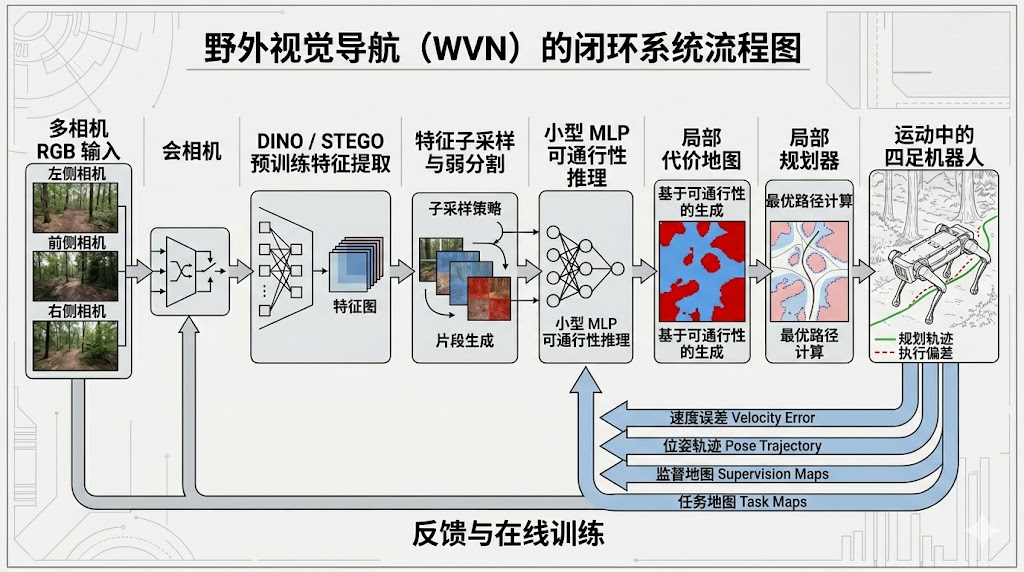
WVN 的核心可以拆成两句话:第一,用预训练视觉模型把 RGB 图像变成含有语义结构的高维特征;第二,用机器人自己的运动结果给这些特征打标签。这里的预训练模型不是为了直接输出“草地”“树木”“道路”等固定类别,而是作为特征提取器,提供更容易被小模型学习的视觉表示。论文中使用了 DINO-ViT 和 STEGO。DINO 是一种自监督 Vision Transformer,ICCV 2021 论文指出,自监督 ViT 特征会显现出较强的语义分割信息;STEGO 则是 ICLR 2022 的无监督语义分割方法,用对比学习把密集视觉特征压缩成更适合聚类的语义区域。
这一步非常关键,因为在线学习的样本量很小,训练时间又短。如果直接从原始像素开始训练一个大网络,机器人在野外几分钟内很难学到稳定规律。WVN 把难题改写成“在已有语义特征上做一个轻量回归”:图像特征由大规模自监督预训练模型负责,现场自适应由小型 MLP 负责。这样系统既继承了大模型从海量图像中学到的视觉先验,又能根据具体机器人、具体地形、具体任务实时调整判断标准。
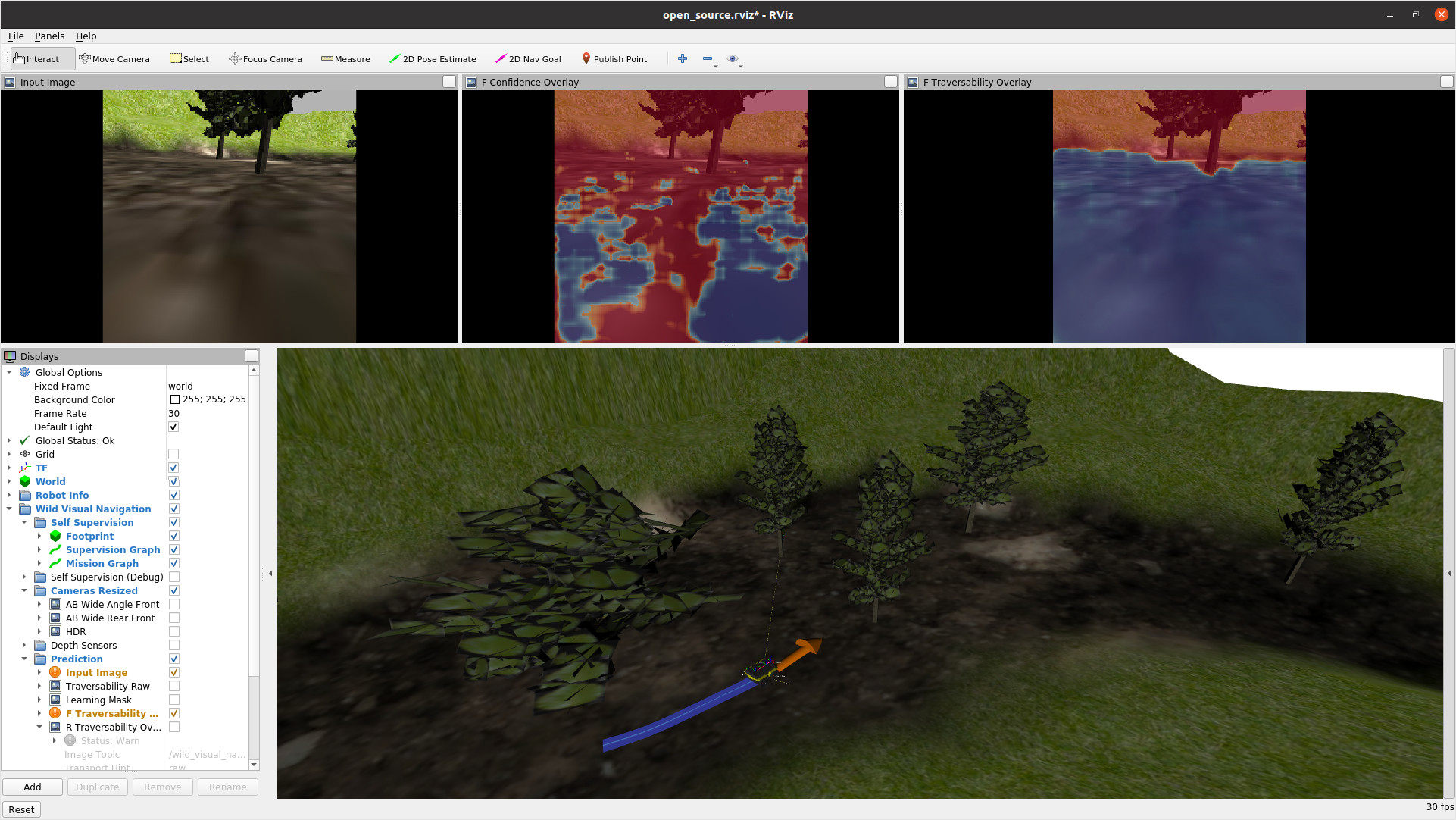
3. 系统全景:两个进程,一条用于看,一条用于学
论文将 WVN 实现为两个不同频率运行的进程。第一个进程负责 Feature Extraction & Inference,也就是从多路相机中选择当前要处理的图像,提取视觉特征,对图像中的区域预测可通行分数。第二个进程负责 Online Learning,也就是根据机器人速度误差生成自监督标签,把短期轨迹投影回历史图像,维护训练样本,并持续更新 MLP 模型。两个进程不是离线串行关系,而是在机器人运行时并行协作:视觉进程持续给导航模块提供最新预测,学习进程持续用新经验刷新模型。
可以把 WVN 理解成一个闭环系统。人类操作员先把机器人开过一段认为可通行的区域,机器人记录相机图像、位姿、速度命令和实际速度。如果实际速度跟命令速度接近,说明该区域对当前平台大概率可通行;如果差异变大,说明可能打滑、受阻或地面状态较差。随后系统把这段“身体经验”映射到图像特征上,训练模型预测其他视觉相似区域是否可走。等模型稳定后,预测结果被融合到局部地形图和代价地图中,供局部规划器选择前进方向。
4. 多相机处理:不是看一张图,而是管理视野资源
原始 WVN 更偏向单相机处理,但真实机器人导航会受视野限制。只看前方相机时,机器人对侧向可通行区域、转弯方向、局部避障空间的理解都不完整。扩展版论文加入了多相机机制,使用加权轮询调度器在不同相机之间分配处理机会。系统每个周期只处理一路相机图像,但可以给训练相机、推理相机和仅推理相机设置不同权重,从而在算力有限的机载 GPU 上维持可控延迟。
这个设计体现了野外机器人系统的现实约束。多相机同时全分辨率跑大模型当然更理想,但机载计算、功耗、散热和实时性都不允许无限扩张。WVN 选择了一个工程上更稳的折中方案:通过调度器选择图像,通过共享特征处理管线复用模型,通过后续地图融合把不同视角的可通行预测合成到局部地图中。这样机器人不是单纯依赖某一帧图像做决策,而是在运动过程中积累不同视角的地形判断。
class WeightedRoundRobinScheduler:
def __init__(self, cameras):
self.queue = []
for name, weight in cameras.items():
self.queue.extend([name] * weight)
self.index = 0
def next_camera(self):
camera = self.queue[self.index]
self.index = (self.index + 1) % len(self.queue)
return camera
cameras = {
"front_training": 4,
"left_inference": 1,
"right_inference": 1,
}
scheduler = WeightedRoundRobinScheduler(cameras)
for _ in range(6):
print(scheduler.next_camera())
上面的代码只是对相机调度思想的简化表达。实际 WVN 中,相机还需要带有内参、外参、时间戳、是否参与训练、是否只参与推理等配置。调度器的意义在于把多传感器问题变成一个受控的资源分配问题:每次只让一张图进入特征提取器,但整个系统仍然能逐步覆盖多个方向的视觉信息。
下面是一个更接近 wild_visual_navigation 工程配置思路的 YAML 示例。真实项目中可以把前视相机作为训练和推理相机,左右相机作为仅推理相机,原因是人类示范时前方足迹更容易被投影回图像,而侧向相机更适合扩大局部避障视野。
camera_scheduler:
policy: weighted_round_robin
cameras:
front:
image_topic: /front_camera/color/image_raw
camera_info_topic: /front_camera/color/camera_info
frame_id: front_camera_optical_frame
use_for_training: true
use_for_inference: true
scheduler_weight: 4
left:
image_topic: /left_camera/color/image_raw
camera_info_topic: /left_camera/color/camera_info
frame_id: left_camera_optical_frame
use_for_training: false
use_for_inference: true
scheduler_weight: 1
right:
image_topic: /right_camera/color/image_raw
camera_info_topic: /right_camera/color/camera_info
frame_id: right_camera_optical_frame
use_for_training: false
use_for_inference: true
scheduler_weight: 1
5. 特征提取:为什么 DINO-ViT 和 STEGO 适合这个任务
WVN 对输入图像先缩放到 224 x 224,再提取像素级或 patch 级的高维特征。DINO-ViT 在论文实现中提供 384 维的像素级特征嵌入,STEGO 则基于 DINO-ViT 并加入对比学习层,提供更紧凑的 90 维特征和分割信息。这里的“特征”可以理解为每个图像位置的一串数字,它们不直接等于类别标签,却把视觉上、语义上相近的区域拉得更近。例如道路、草地、树干、天空虽然没有被人工标注,但在预训练模型的特征空间中往往已经呈现出可分结构。
DINO-ViT 的价值在于它通过无标签图像学习到了语义对应关系,而不是只学习纹理边缘。STEGO 的价值则更接近 WVN 的需求:它尝试把无监督特征蒸馏成更适合语义分割的紧凑簇。对 WVN 来说,这些模型不需要知道“这是一条森林小径”,只需要让“看起来像已走过小径的区域”和“看起来像树干或天空的区域”在特征上更容易区分。这样,小型 MLP 才能在现场少量样本下快速收敛。
import torch
import torch.nn as nn
class TraversabilityMLP(nn.Module):
def __init__(self, feature_dim: int):
super().__init__()
self.backbone = nn.Sequential(
nn.Linear(feature_dim, 256),
nn.ReLU(inplace=True),
nn.Linear(256, 32),
nn.ReLU(inplace=True),
)
self.traversability_head = nn.Sequential(
nn.Linear(32, 1),
nn.Sigmoid(),
)
self.reconstruction_head = nn.Linear(32, feature_dim)
def forward(self, features):
hidden = self.backbone(features)
tau = self.traversability_head(hidden)
reconstructed = self.reconstruction_head(hidden)
return tau, reconstructed
这段代码抽象了论文中两个头共享隐藏层的设计。一个输出头预测可通行分数,另一个输出头重建输入特征,用于异常检测式的置信度估计。真实系统还包含特征缓存、分割掩码、图像坐标、相机模型和 ROS 消息传递;但从学习结构看,WVN 并没有训练一个庞大的端到端分割网络,而是把高维预训练特征交给一个小网络做在线回归。
如果要写一个最小的特征提取接口,可以把 DINO、STEGO 或 DINOv2 都包装成统一的 FeatureExtractor。这样后续 MLP、子采样和在线训练都不需要关心底层模型差异,只需要知道输出是 H x W x C 的 dense feature。
from dataclasses import dataclass
import torch
import torch.nn.functional as F
@dataclass
class FeatureBatch:
dense_features: torch.Tensor
image_size: tuple[int, int]
feature_dim: int
class FeatureExtractor:
def __init__(self, backbone, image_size=(224, 224), device="cuda"):
self.backbone = backbone.to(device).eval()
self.image_size = image_size
self.device = device
@torch.no_grad()
def __call__(self, image_tensor: torch.Tensor) -> FeatureBatch:
image_tensor = image_tensor.to(self.device)
image_tensor = F.interpolate(
image_tensor,
size=self.image_size,
mode="bilinear",
align_corners=False,
)
features = self.backbone.forward_features(image_tensor)
if features.ndim == 3:
batch, patches, channels = features.shape
side = int(patches ** 0.5)
features = features.reshape(batch, side, side, channels)
return FeatureBatch(
dense_features=features[0],
image_size=self.image_size,
feature_dim=features.shape[-1],
)
6. 特征子采样:从五万多个位置压缩到约一百个区域
224 x 224 的图像包含 50176 个位置,如果每个位置都有 384 维或 90 维特征,在线存储和训练会迅速占满 GPU 或内存。WVN 因此引入特征子采样,把密集特征压缩到约 100 个代表性 embedding。论文讨论了三种策略:SLIC、STEGO 和 Random。SLIC 根据颜色与纹理生成超像素,速度快但语义一致性不一定好;Random 随机取样,简单但会丢失区域结构;STEGO 可以利用语义相似性形成更有意义的分割区域,更适合把“同一类地形”作为训练单位。
论文还指出,原始 STEGO 通常依赖全数据集上的 prototype,这不适合现场任务,因为机器人出发前不知道会遇到什么环境。WVN 的修改方式是在每张图像内用聚类生成固定数量的 prototype,既保证每帧都有稳定数量的段,又避免提前限定语义类别。这个改动看似细节,实际上很重要:野外导航不能假设类别集合固定,也不能要求部署前为每片森林、每条小径重新准备 prototype。在线系统必须能在未知环境中自洽运行。

下面的代码展示了两种子采样思路。第一种按随机位置取样,适合快速调试;第二种按分割掩码对特征求平均,更接近 WVN 的训练数据组织方式。实际工程中,mask 可以来自 SLIC、STEGO 聚类或其他弱分割模块。
import torch
def random_subsample_features(dense_features: torch.Tensor, num_samples=100):
height, width, channels = dense_features.shape
flat = dense_features.reshape(height * width, channels)
indices = torch.randperm(height * width, device=dense_features.device)[:num_samples]
ys = indices // width
xs = indices % width
sampled = flat[indices]
locations = torch.stack([xs, ys], dim=-1)
return sampled, locations
def segment_average_features(dense_features: torch.Tensor, mask: torch.Tensor):
segment_ids = torch.unique(mask)
segment_features = []
segment_pixels = {}
for segment_id in segment_ids.tolist():
pixels = mask == segment_id
if pixels.sum() == 0:
continue
segment_features.append(dense_features[pixels].mean(dim=0))
segment_pixels[int(segment_id)] = pixels.nonzero(as_tuple=False)
return torch.stack(segment_features, dim=0), segment_pixels
7. 自监督标签:机器人用速度误差给视觉经验打分
WVN 不需要人工逐像素标注,而是从机器人自身运动中生成标签。论文定义了连续可通行分数 tau,范围是 0 到 1,其中 1 表示完全可通行,0 表示不可通行。分数来自命令速度与实际速度之间的均方误差。如果人类操作员或规划器希望机器人以某个速度前进,但机器人实际速度明显跟不上,系统会认为当前地形更难通行;如果二者接近,说明机器人身体层面验证了这段地形可行。
这个定义不是完美的,但它非常适合在线学习。可通行性本来就依赖平台能力:轮式车过不去的草沟,四足机器人可能可以跨过;小型机器人能穿过的灌木,大型机器人可能会卡住。用速度误差作为反馈,等于让系统以当前机器人自己的运动能力作为标尺。论文中还会先用一维 Kalman Filter 平滑速度误差,再通过 sigmoid 函数把误差映射到 0 到 1 的区间,避免原始传感噪声直接污染训练标签。
import math
def traversability_score(v_cmd, v_est, k=8.0, v_thr=0.15):
error = 0.5 * ((v_cmd[0] - v_est[0]) ** 2 + (v_cmd[1] - v_est[1]) ** 2)
tau = 1.0 / (1.0 + math.exp(k * (error - v_thr)))
return tau
print(traversability_score(v_cmd=(0.8, 0.0), v_est=(0.78, 0.02)))
print(traversability_score(v_cmd=(0.8, 0.0), v_est=(0.25, 0.05)))
这段简化代码体现了公式的直觉:速度误差越小,可通行分数越接近 1;速度误差越大,分数越接近 0。真实系统会根据平台运动规格调节 sigmoid 的斜率和中点,并结合滤波后的误差,而不是直接使用瞬时值。这样做可以减轻短时打滑、状态估计抖动、操作员轻微变速造成的误判。
在真实系统里,速度误差不应直接进入 sigmoid。下面的代码给出一个简单一维 Kalman Filter 的写法,用来平滑速度误差。它不是论文实现的逐行复刻,但能说明 WVN 为什么要先滤波再打分:标签质量直接决定在线训练是否稳定。
class ScalarKalmanFilter:
def __init__(self, process_var=0.01, measurement_var=0.1):
self.x = 0.0
self.p = 1.0
self.q = process_var
self.r = measurement_var
def update(self, measurement):
self.p = self.p + self.q
gain = self.p / (self.p + self.r)
self.x = self.x + gain * (measurement - self.x)
self.p = (1.0 - gain) * self.p
return self.x
def filtered_traversability(v_cmd, v_est, kalman_filter, k=8.0, v_thr=0.15):
raw_error = 0.5 * ((v_cmd[0] - v_est[0]) ** 2 + (v_cmd[1] - v_est[1]) ** 2)
smooth_error = kalman_filter.update(raw_error)
return 1.0 / (1.0 + math.exp(k * (smooth_error - v_thr)))
8. 监督图与任务图:把“走过的轨迹”投影回“看过的图像”
WVN 的监督生成不是在当前帧立刻完成,因为机器人需要先走过某个区域,才能知道它是否真的可通行。论文借鉴图优化和 SLAM 系统的思想,维护两个图结构:Supervision Graph 和 Mission Graph。Supervision Graph 是短期环形缓冲区,记录最近一段时间的位姿、时间戳和可通行分数;Mission Graph 保存整个任务中用于训练的图像节点,每个节点包含 RGB 图像、弱分割掩码、区域特征和对应的监督标签。
当新的任务节点加入时,系统会把机器人足迹轨迹和可通行分数投影回历史相机视角。假设某个分割区域与投影足迹重叠,系统就把足迹上的 tau 平均后赋给该区域;没有被足迹覆盖的区域初始视为未知或保守不可通行。这个“事后回看”的机制使 WVN 可以用真实交互结果监督视觉模型,而不是只凭当前相机图像猜测。它也解释了为什么短暂人工示范有效:示范路径会逐渐在图像空间留下带分数的样本,模型再把这些样本泛化到视觉相似区域。
def assign_segment_labels(segments, projected_track):
labels = {}
for segment_id, pixels in segments.items():
overlaps = []
for pixel in pixels:
if pixel in projected_track:
overlaps.append(projected_track[pixel])
if overlaps:
labels[segment_id] = sum(overlaps) / len(overlaps)
else:
labels[segment_id] = 0.0
return labels
上面的伪代码省略了相机投影、深度遮挡和坐标变换,只保留了核心逻辑:把机器人已经验证过的足迹分数分配给图像分割区域。真实实现还要考虑相机内参、外参、位姿同步、图像时间戳、局部地图遮挡关系等问题。对于工程落地而言,这一部分通常比 MLP 本身更容易出错,因为任何坐标系或时间同步问题都会把正确标签投到错误图像位置。
…详情请参照古月居

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 2
2 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)