PIE 视觉 Parkour 复现路线:从三个开源项目到单阶段隐式显式估计
0. 摘要
四足机器人 parkour 要求机器人在 gap、台阶、楼梯和高台组合地形上提前感知并做出动态动作。传统盲走策略依赖本体状态和接触反馈,难以及时处理需要提前起跳或抬腿的障碍;两阶段视觉策略虽然可行,但存在蒸馏损失和工程链路复杂的问题。PIE 的核心思想是把深度图和本体历史融合为双层隐式显式估计:显式预测高度图、基座速度和足端离地量,隐式预测下一步本体状态,并将这些估计量输入 Actor。本文基于 LeggedGym-Ex、parkour 和 MoRE 三个开源项目,整理出一条从现有视觉 parkour 代码到 PIE 复现的完整路径。
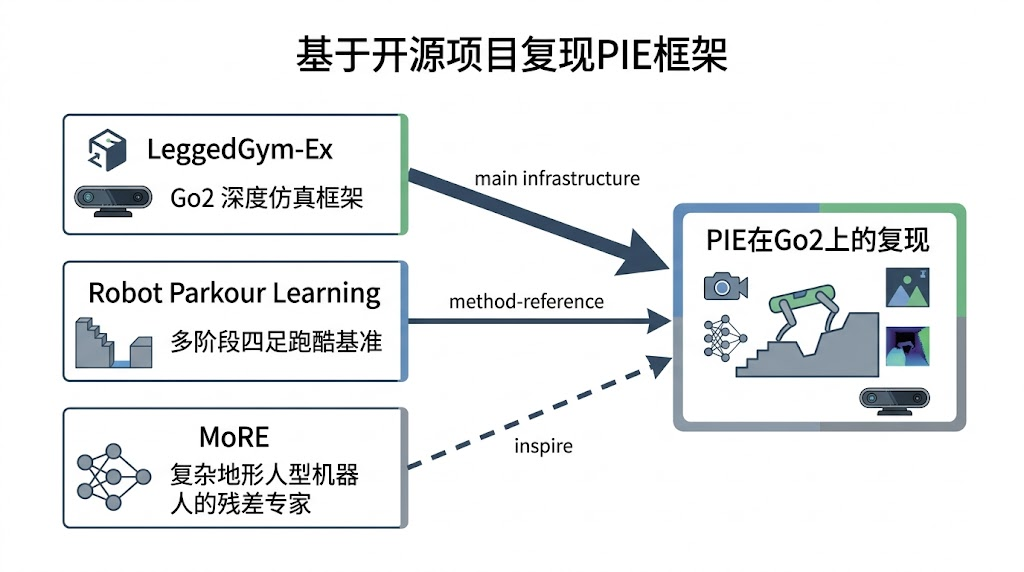
1. 三个开源项目的基本介绍
1.1 LeggedGym-Ex:适合作为 PIE 复现主线的训练框架
LeggedGym-Ex 是一个基于 legged_gym 风格扩展的足式机器人强化学习框架。它保留了 legged_gym 中任务注册、环境配置、PPO 训练、rsl_rl 模块化网络等常见结构,同时加入了多仿真器支持,公开说明中列出 IsaacGym、Genesis 和 IsaacSim 三类后端。对视觉 parkour 复现来说,这个项目最关键的价值不是“它支持很多机器人”,而是本地已经有 legged_gym/envs/go2/go2_ts_depth 任务。该任务包含 Go2 机器人、深度相机配置、复杂地形 curriculum、深度图返回接口、Actor-Critic 训练结构和可视化入口,是把普通粗糙地形行走扩展到视觉 parkour 的最短路径。
在 go2_ts_depth_config.py 中,项目已经打开了深度相机,并设置了常见的 egocentric depth camera 参数,例如 resolution=(60,80)、相机安装位置 pos=(0.3,0.0,0.1)、俯视角 euler=(0.0,1.57+0.3,0.0) 和 decimation=5。这些设置说明深度图不是每个控制步都刷新,而是以低于控制频率的节奏提供视觉信息,这更接近真实 RealSense 等深度相机部署环境。PIE 论文强调低成本深度相机存在噪声和延迟,因此 LeggedGym-Ex 的这类配置非常适合作为复现起点。
# LeggedGym-Ex/legged_gym/envs/go2/go2_ts_depth/go2_ts_depth_config.py
class sensor:
add_depth = True
class depth_camera_config:
num_sensors = 1
num_history = 1
near_clip = 0.1
far_clip = 2.0
resolution = (60, 80)
horizontal_fov_deg = 75
pos = (0.3, 0.0, 0.1)
euler = (0.0, 1.57 + 0.3, 0.0)
decimation = 5
calculate_depth = True
这段配置不能只当作普通参数表来看,它决定了视觉 parkour 复现的输入边界。add_depth=True 表示环境会创建深度相机,并在 step() 或 get_observations() 中返回深度图;resolution=(60,80) 表示策略网络接收的是低分辨率深度图,而不是 RGB 图像或点云;pos 和 euler 决定相机安装在机身前部并朝前下方观察;decimation=5 表示深度图更新频率低于控制频率。如果控制策略以 50Hz 输出动作,深度图大约以 10Hz 更新。PIE 复现必须尊重这个事实,因为低频、有延迟、有噪声的深度图才接近真实机器人部署环境。
1.1.1 使用示例:先跑通 go2_ts_depth baseline
在正式写 PIE 之前,应先跑通 LeggedGym-Ex 自带的 go2_ts_depth。这一步的目标不是得到 PIE 结果,而是验证基础环境是否可用:Go2 能否正常创建,复杂地形能否生成,深度相机是否返回有效 tensor,PPO 训练和播放脚本是否能跑通。如果 baseline 没跑通就直接改 PIE,后续报错会混在环境、相机、网络、runner 和 storage 多个层面,很难定位。
cd /Users/pony.ai/Documents/文档/LeggedGym-Ex
pip install -e .
cd rsl_rl
pip install -e .
cd ..
# 训练现有 Go2 深度图任务
python legged_gym/scripts/train.py --task go2_ts_depth --headless
# 播放训练好的 checkpoint
python legged_gym/scripts/play.py --task go2_ts_depth --load_run <run_dir>
重点 1:go2_ts_depth 是 PIE 复现的 baseline,不是 PIE 本身。 它的价值是验证深度相机、Go2 环境、复杂地形和训练脚本是否可用。PIE 还需要额外实现 estimator、多头监督目标、successor state prediction 和 PPO 联合优化,因此正确路线是先跑通 baseline,再新增 go2_pie_depth,不要直接覆盖原始任务。
1.1.2 使用示例:查看环境返回的 observation
go2_ts_depth 与普通行走任务不同,它返回的不只是 obs。在 LeggedGym-Ex 的深度任务中,通常会同时返回 obs、privileged_obs、depth_image_features 和 critic_obs。这四类数据分别对应部署输入、训练特权信息、视觉输入和 Critic 输入。PIE 复现中最重要的原则是:Actor 部署时只能使用真实机器人可获得的信息,而仿真特权信息只能用于 Critic 或 estimator 的监督。
from legged_gym.envs import task_registry
from legged_gym.utils.helpers import get_args
args = get_args()
args.task = "go2_ts_depth"
args.headless = True
env, env_cfg = task_registry.make_env(name=args.task, args=args)
obs, privileged_obs, depth_image_features, critic_obs = env.get_observations()
print("obs:", obs.shape)
print("privileged_obs:", privileged_obs.shape)
print("depth:", depth_image_features.shape)
print("critic_obs:", critic_obs.shape)
重点 2:obs 是部署侧 Actor 的主体输入。 它通常包含速度命令、重力方向、角速度、关节角、关节速度和上一时刻动作。真实机器人可以通过 IMU、关节编码器和上层命令获得这些信息,因此它可以进入 Actor。复现 PIE 时,不要把仿真地形高度或真实基座速度直接拼进 obs,否则训练策略会依赖真实部署中不可获得的信息。
重点 3:depth_image_features 是视觉 parkour 的关键入口。 深度图一般是 [num_envs, history, height, width] 或类似形状。网络里的 cnn_input_channel、depth_history_len 必须和这个 history 维度一致。如果配置里 num_history=2,而 CNN 第一层仍按 1 个输入通道构造,就会出现通道不匹配。调试 PIE 网络前,应先打印 depth shape,确认它和配置一致。
重点 4:privileged_obs 和 critic_obs 只能服务训练。 Asymmetric actor-critic 允许 Critic 在训练中看到更多仿真信息,例如真实速度、局部高度图、接触状态或 domain randomization 参数。这样可以提高 value function 的稳定性。但这些信息不能进入 act_inference(),否则仿真表现会虚高,真实部署无法复现。
1.1.3 使用示例:定位 go2_ts_depth 的任务入口
在 LeggedGym-Ex 中,任务通常通过 task_registry.register() 注册。理解注册入口很重要,因为后续新增 PIE 任务时,也要按同样方式注册 go2_pie_depth。可以先查看当前 go2_ts_depth 是如何注册的,再照着新增 PIE 环境和配置。
cd /Users/pony.ai/Documents/文档/LeggedGym-Ex
# 查看 go2_ts_depth 相关文件
find legged_gym/envs/go2/go2_ts_depth -maxdepth 1 -type f
# 查看任务注册位置
grep -n "go2_ts_depth" legged_gym/envs/__init__.py
重点 5:新增 PIE 时要保留原 baseline。 推荐新增目录 legged_gym/envs/go2/go2_pie_depth/,不要直接修改 go2_ts_depth。这样可以保证后续实验能比较 baseline 和 PIE,也方便在 PIE 代码出错时退回到原始任务检查环境是否正常。
LeggedGym-Ex 的优势是工程基础完整。它已经把环境、地形、传感器、runner、storage、PPO 和网络模块组织成可复用结构,因此复现 PIE 时不必从零写仿真环境。它的不足也很明确:现有 go2_ts_depth 更接近 teacher-student 或深度历史编码器方案,并不是 PIE 的官方完整实现。也就是说,LeggedGym-Ex 解决的是“在哪里复现”和“如何获取深度图与地形监督”,但 PIE 的 estimator、多头损失、单阶段训练逻辑仍然需要额外实现。
1.2 Robot Parkour Learning:两阶段视觉 parkour 的重要参照
parkour 项目对应 CoRL 2023 的 Robot Parkour Learning。它面向四足机器人在真实障碍环境中的跑酷能力,项目主页和 README 都强调了 climb、leap、crawl、tilt 等动作技能,以及最终部署到 Unitree Go1/Go2 的视觉策略。这个项目的价值在于,它证明了低成本四足机器人确实可以利用自我中心深度相机完成复杂障碍动作,也提供了与 parkour 强相关的地形、任务分解和真实部署经验。对于理解“为什么深度图能帮助机器人跳 gap、爬高台和通过障碍”,它是最直接的工程参考。
Robot Parkour Learning 的典型训练范式不是 PIE 的单阶段训练,而是更偏多阶段。公开说明中提到 RL 预训练、RL fine-tuning 和 vision policy distillation。换句话说,它通常先为不同障碍训练或微调专门技能,再使用约束和课程学习提高动作成功率,随后把带有特权信息或技能约束的 teacher 行为蒸馏给使用深度图的 student policy,最后再部署到真实机器人。这种路线的优点是容易把复杂动作拆成若干子问题,每个阶段更容易收敛;缺点是训练链条长,checkpoint 和配置多,最终 student 策略还可能损失 teacher 中的部分信息。
1.2.1 使用示例:把 parkour 当成方法和部署参考
parkour 项目不建议直接作为 PIE 复现主线,但它非常适合用来理解四足视觉 parkour 的任务设计和部署边界。第一步应该阅读它的 README、Go2 配置文件和 Go2 部署文档,而不是急着把它的训练代码搬进 LeggedGym-Ex。特别是 onboard_codes/Deploy-Go2.md,它能帮助读者理解真实机器人部署时需要处理相机、机器人状态、动作输出和安全限制。
cd /Users/pony.ai/Documents/文档/parkour
# 查看 Go2 部署说明
sed -n '1,180p' onboard_codes/Deploy-Go2.md
# 查看 Go2 相关配置
find legged_gym/legged_gym/envs/go2 -maxdepth 1 -type f
# 查看 parkour 项目的环境基类
find legged_gym/legged_gym/envs/base -maxdepth 1 -type f
重点 1:parkour 的价值是任务经验,不是 PIE 源码。 它展示了真实 parkour 任务需要考虑哪些动作技能,例如 leap、jump、crawl、tilt,也展示了两阶段或多阶段视觉策略如何部署到真实四足机器人。PIE 可以借鉴这些 terrain 和 evaluation 思路,但不应照搬它的多阶段蒸馏训练范式。
重点 2:它适合作为 baseline 对照。 如果后续要写实验,可以把 Robot Parkour Learning 代表的多阶段视觉路线作为对照,再和 PIE 的单阶段 estimator 路线比较。比较指标不应只看成功率,也应包括训练阶段数量、是否需要 teacher、是否存在蒸馏损失、checkpoint 管理复杂度和真实部署链路复杂度。
对 PIE 复现而言,Robot Parkour Learning 最适合作为对照组和地形参考,而不是直接作为代码底座。它可以帮助我们理解视觉 parkour 的动作需求,例如 gap 前需要提前加速,高台前需要抬高摆腿,低矮障碍需要调整身体高度;也可以帮助我们设计评估指标,例如不同 terrain type 下的成功率和碰撞率。但如果目标是复现 PIE 的“one-stage end-to-end training”,就不应继续沿用完整的多阶段蒸馏路线。
1.3 MoRE:复杂地形控制的残差专家思想参考
MoRE 项目对应 “Mixture of Residual Experts for Humanoid Lifelike Gaits Learning on Complex Terrains”。它面向的是人形机器人复杂地形步态,而不是 Go2 四足视觉 parkour。项目 README 中展示了 base locomotion policy、residual policy、mixture of experts 和 Mujoco 复杂地形验证流程。它的直接任务、机器人形态和网络目标都与 PIE 不同,因此不能把 MoRE 当成 PIE 的源码,也不应把它硬接到 Go2 parkour 训练链路中。
然而 MoRE 对本文仍有参考价值。复杂地形运动往往不是单一技能可以覆盖的,机器人在平地、楼梯、坑洞、gap 和高台上需要不同的动作模式。MoRE 的 residual experts 思路提醒我们:当 PIE 的 estimator 解决了“看见和估计地形”的问题后,如果后续希望策略具有更强的动作多样性,可以在 Actor 侧引入专家结构或残差策略。例如基础 Actor 负责稳定行走,残差专家负责跨 gap、上高台或低姿态通过。这属于 PIE 复现之后的扩展方向,而不是第一阶段必须完成的内容。
MoRE 对 PIE 复现的启发应放在策略结构层面,而不是第一阶段代码复用层面。更具体地说,第一阶段不应直接复用 MoRE 作为 Go2 parkour 主线,而应先完成 LeggedGym-Ex 上的 PIE estimator 和单阶段 PPO 训练;当视觉估计稳定后,再借鉴 residual experts 思想扩展多动作模式。对于复杂地形 parkour,可以把基础行走能力视为主策略,把跨 gap、上高台、低姿态通过等场景特化能力视为残差或专家分支,这样能减少单一 Actor 同时覆盖所有动作模式的压力。
1.3.1 使用示例:把 MoRE 当成复杂策略结构参考
MoRE 的 README 给出了 base locomotion policy 和 residual policy 的训练命令。对于本文来说,重点不是运行 MoRE 得到 Go2 parkour 策略,而是理解它如何把基础运动能力和 residual experts 分开。这个思想适合在 PIE 复现稳定之后使用:先让 PIE estimator 解决视觉和状态估计问题,再考虑是否需要专家 Actor 或 residual Actor 来提升不同地形动作的表达能力。
cd /Users/pony.ai/Documents/文档/MoRE
# 查看 MoRE 的方法图和复杂地形示例
find docs -maxdepth 1 -type f
# README 中的训练主线示例
python legged_gym/scripts/train.py --task g1_16dof_loco --headless
python legged_gym/scripts/train.py --task g1_16dof_resi_moe --headless
重点 1:MoRE 不直接参与第一阶段 PIE 复现。 MoRE 面向 humanoid,机器人形态、动力学模型、任务目标和部署链路都与 Go2 四足视觉 parkour 不同。第一阶段应该先把 go2_pie_depth 的 estimator、PPO 联合训练和可视化跑通,再考虑是否引入 MoRE 风格的专家结构。
重点 2:MoRE 的启发在 Actor 表达能力。 PIE 主要解决“如何从深度图和本体历史估计有用状态”的问题。如果后续发现单一 Actor 难以同时覆盖高速跨 gap、慢速上高台、稳定下台阶和低姿态通过,可以借鉴 MoRE 的 residual experts,把动作生成拆成基础策略和场景特化残差。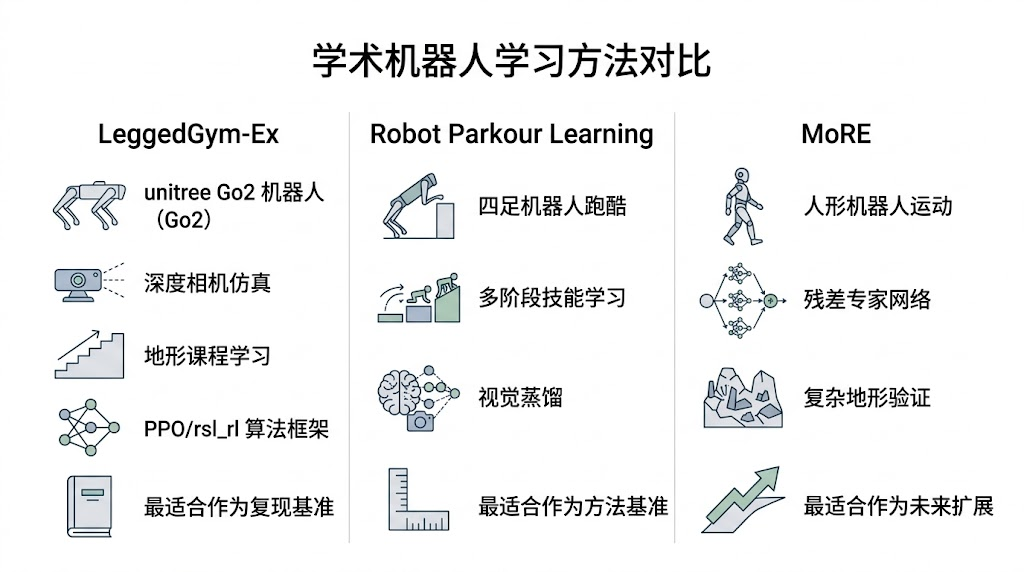
这张图建议放在三个项目介绍之后,用来帮助读者把工程定位固定下来。文章需要避免一个常见误区:把三个项目看成“需要合并的代码库”。更准确的理解是,LeggedGym-Ex 提供复现骨架,Robot Parkour Learning 提供任务经验和 baseline,MoRE 提供后续复杂策略表达的启发。PIE 复现不是把三套代码强行拼接,而是在 LeggedGym-Ex 的视觉 Go2 环境上实现 PIE 的 estimator 和单阶段训练。
2. 三个项目在视觉 Parkour 任务中的优劣势
从工程复现角度看,LeggedGym-Ex 的最大优势是“可落地”。它已经有 Go2 深度相机环境,任务注册方式清晰,代码结构接近 legged_gym,适合新增 go2_pie_depth 任务。它的短板在于,现有 go2_ts_depth 更像一个视觉 teacher-student 或深度历史编码任务,PIE 论文中强调的多头 estimator、successor state reconstruction、height map reconstruction 和单阶段联合优化并不完整。因此,LeggedGym-Ex 是主线,但不是开箱即用的 PIE。
Robot Parkour Learning 的优势是“任务真实性”。它围绕 parkour 本身设计,展示了低成本四足机器人通过真实障碍的可能性,也包含 Go1/Go2 部署说明。它的不足是工程链路更重,训练阶段更多,策略蒸馏带来额外复杂度。对本文目标来说,它更适合作为方法和实验对照:我们可以用它理解 parkour 需要哪些地形、哪些动作、哪些部署风险,但不应沿着它的多阶段范式去复现 PIE,否则会偏离 PIE 的核心贡献。
MoRE 的优势是“复杂动作表达”。它通过 residual experts 处理复杂地形上的人形步态,强调基础策略和残差专家的组合。这对未来构建更强的 parkour 策略很有启发,因为一个单一 MLP Actor 很可能难以同时覆盖高速跨越、慢速攀爬、低姿态通过和稳定下台阶。但 MoRE 的不足也明显:它不是四足视觉策略,也不是深度图 parkour 训练代码。第一阶段复现 PIE 时,它应该停留在“思想参考”层面。
| 维度 | LeggedGym-Ex | Robot Parkour Learning | MoRE |
|---|---|---|---|
| 机器人形态 | Go2 等多种足式机器人 | Go1/Go2/A1 等四足机器人 | Humanoid |
| 视觉支持 | 已有 Go2 depth 任务 | 视觉蒸馏策略 | 主线不是视觉 parkour |
| 训练范式 | PPO/rsl_rl,可扩展 | 多阶段技能 + 蒸馏 | base policy + residual experts |
| 适合本文的位置 | 主复现平台 | parkour baseline 和地形参考 | 后续策略扩展参考 |
| 主要不足 | PIE estimator 需补齐 | 多阶段链路复杂 | 任务形态不同,不能直接复用 |
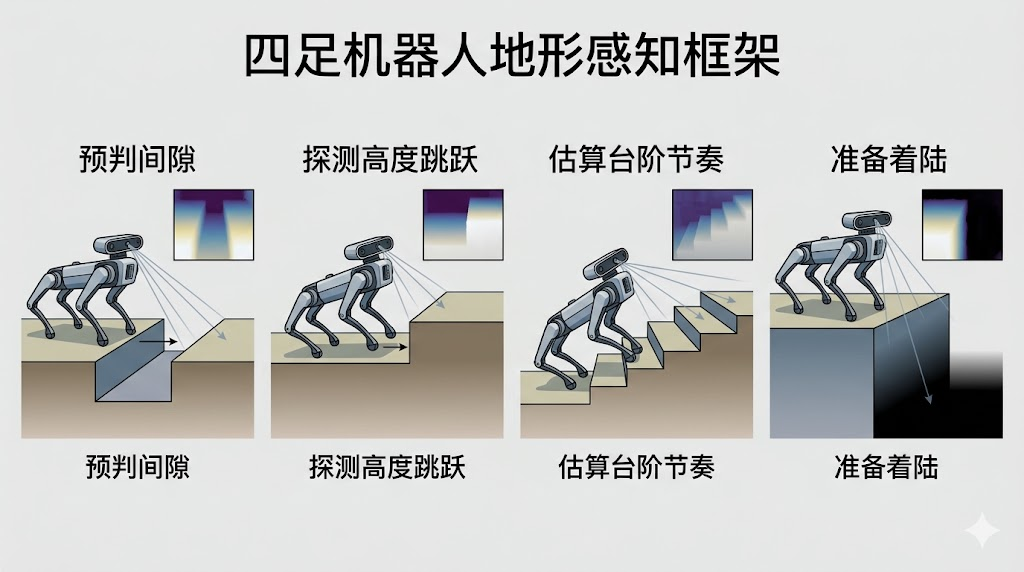
3. 为什么视觉 Parkour 必须使用深度图
普通盲走策略依赖本体状态,包括 IMU、关节角、关节速度、历史动作和接触反馈。这类策略在随机粗糙地形上往往表现很好,因为机器人可以在接触地形后逐步修正动作。但 parkour 的难点在于动作准备必须发生在接触之前。跨越 gap 时,机器人需要在到达边缘前建立速度并规划落脚;上高台时,摆腿轨迹必须提前抬高,否则会撞到小腿或膝部;下台阶时,身体姿态和落地缓冲要提前调整,否则容易俯冲或摔倒。深度图的作用不是让机器人“看起来更智能”,而是提供行动窗口之前的几何信息。
对于 Go2 这类机器人,通常使用机身前方朝下的自我中心深度相机。仿真中,terrain mesh 会被渲染为一张低分辨率深度图,例如 60x80。这张图不需要重建成完整全局地图,也不需要像导航系统那样长期维护 SLAM 地图;它只需要告诉策略未来一小段距离内的高度变化、空洞和边缘位置。这样的视觉输入计算量低、部署简单,并且能够与真实 RealSense 等传感器对齐。问题在于,深度图存在延迟、噪声、空洞和标定误差,因此策略不能完全依赖视觉,还必须与本体历史融合。
| 场景 | 没有深度图的问题 | 深度图的关键作用 | 策略应形成的动作 |
|---|---|---|---|
| Gap | 到边缘才知道前方为空,已经来不及起跳 | 提前看到空洞和落地区 | 加速、起跳、收腿、落地 |
| 高台 | 碰撞后才知道高度,容易撞腿 | 提前看到高度突变和平台顶面 | 抬腿、前冲、身体姿态调整 |
| 下台阶 | 把落差当平地,落地冲击大 | 看到地面下降和边缘 | 减速、缓冲、稳定落脚 |
| 楼梯 | 接触反馈滞后,步态节奏混乱 | 看到周期性高度变化 | 连续抬腿和节奏控制 |
 |
4. 从两阶段视觉策略到 PIE 单阶段训练
Robot Parkour Learning 代表了一条成熟的两阶段或多阶段视觉策略路线:先让 teacher 或技能策略在带有特权信息的环境中学习动作,再把这些动作蒸馏给使用深度图的 student。这个路线工程上很有效,因为复杂行为被拆解成更容易优化的子问题。但它也有明显代价:训练链条长,配置和 checkpoint 管理复杂,student 最终学习的是 teacher 行为的近似,不一定充分利用深度图和本体状态之间的互补信息。对于研究复现来说,多阶段训练还会让失败原因更难定位。
PIE 的核心改进是把这一过程压缩为单阶段端到端训练。Actor 部署时只使用真实机器人可获得的本体状态和深度图;Critic 在训练中可以使用 privileged observations,以获得更稳定的 value 估计;Estimator 从深度图历史和本体历史中输出多个估计量,并通过高度图、基座速度、足端离地量和下一步本体状态进行监督。这样,视觉特征不是被动模仿 teacher,而是在 PPO 训练过程中直接服务于最终动作。
两阶段视觉 parkour 的核心逻辑是先训练一个能看见更多特权信息的 teacher policy,再让只能使用深度图的 student policy 去模仿它。这个设计在工程上容易拆分任务,但 student 最终学到的是 teacher 行为的近似,视觉表示本身并没有在最终控制目标中被充分约束。PIE 单阶段路线则不同,它从一开始就把本体历史和深度图历史交给 estimator,estimator 产生显式物理量和隐式 latent,Actor 直接使用这些估计量输出关节目标。训练时,PPO 的策略损失和 estimator 的回归损失一起优化,因此视觉表示从训练开始就服务于最终动作,而不是训练结束后再去模仿另一个策略。
5. PIE 的双层隐式显式估计
PIE 中的“隐式显式”并不是一个装饰性术语,而是对状态估计问题的拆解。第一层关注机器人如何理解自身和周围环境。显式估计指高度图重建、速度估计、足端离地量估计等有物理意义的量;隐式估计指预测下一步本体状态 o_{t+1},让网络学习“当前动作、接触、地形和身体响应”之间的动态关系。深度相机只能看到前方,无法看到脚下和身后,而本体历史恰好记录了刚刚接触过的地形,两者结合可以弥补单一视觉输入的不可靠。
第二层关注估计向量的表达形式。PIE 不只输出一个不可解释 latent,而是同时输出显式物理量和压缩 latent。v_hat 对应基座速度估计,影响速度跟踪和起跳冲量;h_f_hat 对应四个足端离地量,直接关系到是否踢到台阶或绊到边缘;z_m 是用于重建高度图的 latent;z 是 VAE 形式的纯 latent,用来表达难以手工命名的地形和状态因素。这种组合比只预测高度图更完整,也比只使用黑箱 latent 更容易调试。
从输入角度看,PIE Estimator 同时接收本体历史和深度图历史。本体历史包含角速度、重力方向、速度命令、关节角、关节速度和上一时刻动作,它反映机器人自身状态与刚刚发生的接触反馈;深度图历史来自机身前方的自我中心深度相机,它反映未来一小段距离内的地形几何。二者必须同时使用,因为单独深度图看不到脚下和身后,单独本体历史又无法提前知道前方 gap 或高台。
从输出角度看,Estimator 不只是输出一个黑箱 latent,而是把估计结果拆成几类具有不同作用的变量。v_hat 表示基座速度估计,帮助 Actor 判断当前冲量和速度跟踪状态;h_f_hat 表示四个足端的离地量估计,帮助 Actor 避免踢到台阶或在边缘绊倒;z_m 是用于重建局部高度图的压缩表示,它让网络显式学习地形几何;z 是 VAE 风格的隐变量,用于表达难以手工命名的接触动态、地形不确定性和短期运动趋势。
从损失角度看,PIE 通过多个监督目标共同塑造 estimator 表示。高度图重建损失约束 z_m 必须携带地形结构,基座速度损失约束 v_hat 必须贴近真实运动状态,足端离地量损失约束网络关注脚与地形之间的空间关系,下一步本体状态重建损失让 z 学习动作、接触和身体响应之间的隐式动态关系。VAE 的 KL 项则限制 latent 空间过度发散,使模型在深度噪声和相机误差下更平滑。这样的设计比单独预测高度图更全面,也比单纯拼接深度 latent 更容易诊断。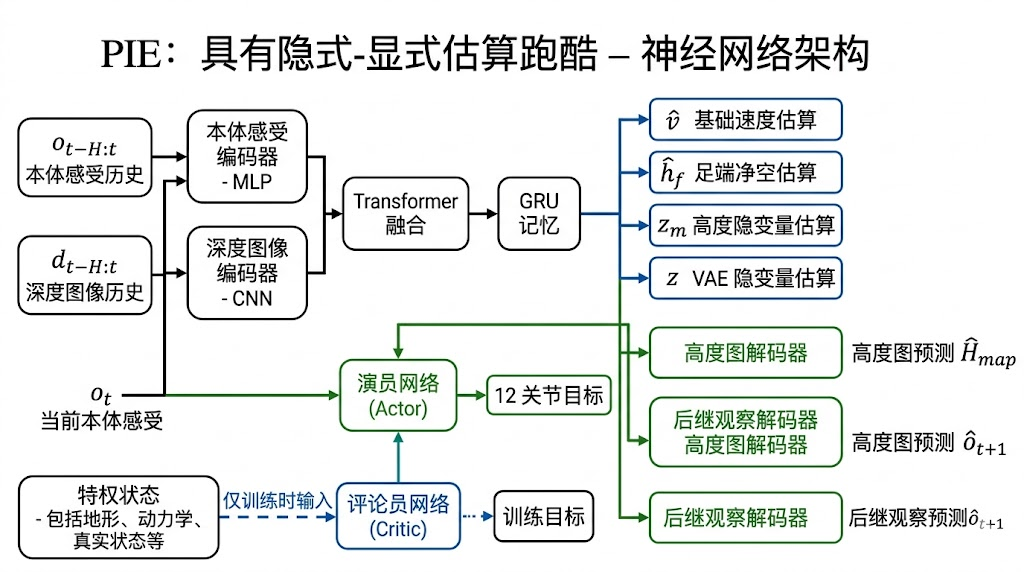
6. 基于 LeggedGym-Ex 复现 PIE 的总体流程
复现主线应建立在 LeggedGym-Ex/legged_gym/envs/go2/go2_ts_depth 之上,而不是从 parkour 或 MoRE 直接迁移。具体做法是新增 go2_pie_depth 任务,继承现有 Go2TSDepth 环境,保留 Go2 机器人、深度相机、地形 curriculum 和基础 reward;然后在环境 step() 返回的 infos 中加入 PIE estimator 需要的监督目标,包括局部高度图、真实基座速度和足端 clearance。这样可以最大限度复用 LeggedGym-Ex 的仿真与训练基础,同时避免破坏原有 baseline。
在 rsl_rl 侧,需要新增 ActorCriticPIE、PIEEstimator、PPO_PIE、RolloutStoragePIE 和 PIERunner。其中 PIEEstimator 负责深度图与本体历史融合,ActorCriticPIE 负责把 estimator 输出接入 Actor,PPO_PIE 负责把 PPO 损失和 estimator 回归损失合并,RolloutStoragePIE 负责保存额外监督目标,PIERunner 负责连接环境、算法和训练循环。这些模块构成 PIE 复现的最小闭环。
完整代码会在下面章节介绍,使用时应把这些文件复制到 LeggedGym-Ex 对应路径,然后按照第 11 章完成任务注册和算法注册。这里需要强调的是,代码文件之间有明确分工:环境文件负责提供训练监督目标,网络文件负责实现 estimator 和 actor-critic,storage 文件负责保存 rollout 中的额外目标,algorithm 文件负责联合优化 PPO 和 estimator loss,runner 文件负责把环境、storage 和算法串成训练循环。
| 文件 | 放入 LeggedGym-Ex 后的相对路径 | 作用 |
|---|---|---|
pie_actor_critic.py |
rsl_rl/modules/pie_actor_critic.py |
定义 PIEEstimator 和 ActorCriticPIE |
ppo_pie.py |
rsl_rl/algorithms/ppo_pie.py |
在 PPO 更新中加入 estimator loss |
rollout_storage_pie.py |
rsl_rl/storage/rollout_storage_pie.py |
保存下一步 observation、高度图、速度和足端 clearance 目标 |
pie_runner.py |
rsl_rl/runners/pie_runner.py |
连接环境、算法、storage 和训练循环 |
go2_pie_depth.py |
legged_gym/envs/go2/go2_pie_depth/go2_pie_depth.py |
继承 Go2TSDepth 并返回 PIE 监督目标 |
go2_pie_depth_config.py |
legged_gym/envs/go2/go2_pie_depth/go2_pie_depth_config.py |
定义 Go2 PIE 的地形、相机和训练配置 |
visualize_pie_depth.py |
legged_gym/scripts/visualize_pie_depth.py |
保存深度图和高度图,检查视觉输入是否正确 |
6A. PIE 复现完整代码
本节把 7 个核心文件的完整代码直接放入主文档。实际使用时,应按照每个小节标题中的路径,将代码复制到 LeggedGym-Ex 对应位置。复制后还需要完成第 11 章中的注册步骤,否则训练脚本无法通过 --task go2_pie_depth 找到新任务,也无法通过配置创建 ActorCriticPIE、PPO_PIE 和 PIERunner。这些代码构成的是基于公开 PIE 方法和本地 LeggedGym-Ex 接口整理的复现骨架,不是 PIE 作者官方源码;首次运行时建议先把并行环境数调小,确认 shape、storage 和 loss 都正常,再进行长时间训练。
6.1 完整代码一:rsl_rl/modules/pie_actor_critic.py
这是 PIE 复现中最核心的网络文件。它定义 PIEEstimator 和 ActorCriticPIE:前者负责把深度图历史和本体历史融合成显式物理量与隐式 latent,后者负责把这些估计量接入 Actor,并让 Critic 使用训练期的 critic observation。使用时应将该文件复制到 LeggedGym-Ex 的 rsl_rl/modules/pie_actor_critic.py,并在 rsl_rl/modules/__init__.py 中导入 ActorCriticPIE。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.distributions import Normal
from .actor_critic import get_activation
class PIEEstimator(nn.Module):
"""PIE estimator: depth + proprioception -> explicit and implicit estimates."""
def __init__(
self,
num_obs,
depth_image_resolution,
prop_history_len=10,
depth_history_len=2,
height_dim=171,
zm_dim=32,
z_dim=32,
transformer_dim=128,
transformer_heads=4,
transformer_layers=2,
gru_hidden_size=256,
activation="elu",
):
super().__init__()
self.num_obs = num_obs
self.prop_history_len = prop_history_len
self.depth_history_len = depth_history_len
self.height_dim = height_dim
self.zm_dim = zm_dim
self.z_dim = z_dim
self.output_dim = 3 + 4 + zm_dim + z_dim
act = get_activation(activation)
h, w = depth_image_resolution
self.depth_cnn = nn.Sequential(
nn.Conv2d(depth_history_len, 16, kernel_size=5, stride=2, padding=2),
act,
nn.Conv2d(16, 32, kernel_size=3, stride=2, padding=1),
act,
nn.Conv2d(32, transformer_dim, kernel_size=3, stride=2, padding=1),
act,
)
cnn_h = (h + 7) // 8
cnn_w = (w + 7) // 8
self.depth_pos = nn.Parameter(torch.zeros(1, cnn_h * cnn_w, transformer_dim))
self.prop_encoder = nn.Sequential(
nn.Linear(num_obs * prop_history_len, transformer_dim),
act,
nn.Linear(transformer_dim, transformer_dim),
act,
)
enc_layer = nn.TransformerEncoderLayer(
d_model=transformer_dim,
nhead=transformer_heads,
dim_feedforward=transformer_dim * 4,
batch_first=True,
activation="gelu",
norm_first=True,
)
self.transformer = nn.TransformerEncoder(enc_layer, num_layers=transformer_layers)
self.gru = nn.GRU(transformer_dim * 2, gru_hidden_size, num_layers=1)
self.v_head = nn.Linear(gru_hidden_size, 3)
self.foot_head = nn.Linear(gru_hidden_size, 4)
self.zm_head = nn.Linear(gru_hidden_size, zm_dim)
self.z_mu = nn.Linear(gru_hidden_size, z_dim)
self.z_logvar = nn.Linear(gru_hidden_size, z_dim)
decode_in = zm_dim + z_dim + 3 + 4
self.height_decoder = nn.Sequential(
nn.Linear(zm_dim, 128),
act,
nn.Linear(128, height_dim),
)
self.next_obs_decoder = nn.Sequential(
nn.Linear(decode_in, 128),
act,
nn.Linear(128, num_obs),
)
self.hidden_states = None
def reset_hidden_states(self, dones=None):
if self.hidden_states is None or dones is None:
return
self.hidden_states[:, dones, :] = 0.0
def detach_hidden_states(self):
if self.hidden_states is not None:
self.hidden_states = self.hidden_states.detach().clone()
def _ensure_histories(self, obs_history, depth_history):
if obs_history.dim() == 2:
obs_history = obs_history.unsqueeze(1).repeat(1, self.prop_history_len, 1)
if depth_history.dim() == 3:
depth_history = depth_history.unsqueeze(1)
if depth_history.shape[1] == 1 and self.depth_history_len > 1:
depth_history = depth_history.repeat(1, self.depth_history_len, 1, 1)
if depth_history.shape[1] > self.depth_history_len:
depth_history = depth_history[:, -self.depth_history_len:]
return obs_history, depth_history
def forward(self, obs_history, depth_history, hidden_states=None, masks=None, sample=True):
batch_mode = masks is not None
obs_history, depth_history = self._ensure_histories(obs_history, depth_history)
if batch_mode:
t, b = obs_history.shape[:2]
obs_flat = obs_history.reshape(t * b, -1)
depth_flat = depth_history.reshape(t * b, *depth_history.shape[2:])
else:
obs_flat = obs_history.reshape(obs_history.shape[0], -1)
depth_flat = depth_history
visual = self.depth_cnn(depth_flat).flatten(2).transpose(1, 2)
visual = visual + self.depth_pos[:, :visual.shape[1]]
prop = self.prop_encoder(obs_flat).unsqueeze(1)
fused = self.transformer(torch.cat([prop, visual], dim=1))
summary = torch.cat([fused[:, 0], fused[:, 1:].mean(dim=1)], dim=-1)
if batch_mode:
summary = summary.view(t, b, -1)
if hidden_states is None:
hidden_states = torch.zeros(1, b, self.gru.hidden_size, device=summary.device)
rnn_out, _ = self.gru(summary, hidden_states)
flat_out = rnn_out.reshape(t * b, -1)
else:
rnn_in = summary.unsqueeze(0)
rnn_out, self.hidden_states = self.gru(rnn_in, self.hidden_states)
flat_out = rnn_out.squeeze(0)
v_hat = self.v_head(flat_out)
hf_hat = self.foot_head(flat_out)
zm = self.zm_head(flat_out)
mu = self.z_mu(flat_out)
logvar = torch.clamp(self.z_logvar(flat_out), -8.0, 4.0)
if sample and self.training:
eps = torch.randn_like(mu)
z = mu + eps * torch.exp(0.5 * logvar)
else:
z = mu
estimates = torch.cat([v_hat, hf_hat, zm, z], dim=-1)
decoded_height = self.height_decoder(zm)
decoded_next_obs = self.next_obs_decoder(torch.cat([zm, z, v_hat, hf_hat], dim=-1))
return {
"estimates": estimates,
"v_hat": v_hat,
"hf_hat": hf_hat,
"zm": zm,
"z": z,
"mu": mu,
"logvar": logvar,
"decoded_height": decoded_height,
"decoded_next_obs": decoded_next_obs,
}
def loss(self, out, next_obs, height, base_vel, foot_clearance, weights=None):
weights = weights or {}
kl = -0.5 * torch.mean(1 + out["logvar"] - out["mu"].pow(2) - out["logvar"].exp())
losses = {
"next_obs": F.mse_loss(out["decoded_next_obs"], next_obs),
"height": F.mse_loss(out["decoded_height"], height),
"base_vel": F.mse_loss(out["v_hat"], base_vel),
"foot_clearance": F.mse_loss(out["hf_hat"], foot_clearance),
"kl": kl,
}
total = (
weights.get("next_obs", 1.0) * losses["next_obs"]
+ weights.get("height", 1.0) * losses["height"]
+ weights.get("base_vel", 1.0) * losses["base_vel"]
+ weights.get("foot_clearance", 1.0) * losses["foot_clearance"]
+ weights.get("kl", 1.0e-3) * losses["kl"]
)
losses["total"] = total
return losses
class ActorCriticPIE(nn.Module):
def __init__(
self,
num_actor_obs,
num_actions,
num_privilege_encoder_input,
num_latent_dims,
num_critic_obs,
depth_image_resolution,
height_dim=171,
prop_history_len=10,
depth_history_len=2,
zm_dim=32,
z_dim=32,
actor_hidden_dims=(512, 256, 128),
critic_hidden_dims=(1024, 256, 128),
activation="elu",
init_noise_std=1.0,
clip_actions=10.0,
**kwargs,
):
super().__init__()
act = get_activation(activation)
self.estimator = PIEEstimator(
num_actor_obs,
depth_image_resolution,
prop_history_len=prop_history_len,
depth_history_len=depth_history_len,
height_dim=height_dim,
zm_dim=zm_dim,
z_dim=z_dim,
activation=activation,
)
actor_in = num_actor_obs + self.estimator.output_dim
critic_in = num_critic_obs
actor = []
for i, dim in enumerate(actor_hidden_dims):
actor.append(nn.Linear(actor_in if i == 0 else actor_hidden_dims[i - 1], dim))
actor.append(act)
actor.append(nn.Linear(actor_hidden_dims[-1], num_actions))
actor.append(nn.Hardtanh(-clip_actions, clip_actions))
self.actor = nn.Sequential(*actor)
critic = []
for i, dim in enumerate(critic_hidden_dims):
critic.append(nn.Linear(critic_in if i == 0 else critic_hidden_dims[i - 1], dim))
critic.append(act)
critic.append(nn.Linear(critic_hidden_dims[-1], 1))
self.critic = nn.Sequential(*critic)
self.std = nn.Parameter(init_noise_std * torch.ones(num_actions))
self.distribution = None
Normal.set_default_validate_args = False
def reset(self, dones=None):
self.estimator.reset_hidden_states(dones)
def detach_hidden_states(self):
self.estimator.detach_hidden_states()
@property
def action_mean(self):
return self.distribution.mean
@property
def action_std(self):
return self.distribution.stddev
@property
def entropy(self):
return self.distribution.entropy().sum(dim=-1)
def update_distribution(self, observations, depth_images, hidden_states=None, masks=None):
out = self.estimator(observations, depth_images, hidden_states, masks)
obs_for_actor = observations
if masks is not None:
obs_for_actor = observations.reshape(-1, observations.shape[-1])
elif observations.dim() == 3:
obs_for_actor = observations[:, -1, :]
mean = self.actor(torch.cat([obs_for_actor, out["estimates"]], dim=-1))
std = torch.clamp(self.std, min=1e-6)
self.distribution = Normal(mean, mean * 0.0 + std)
return out
def act(self, observations, depth_images, hidden_states=None, masks=None):
self.update_distribution(observations, depth_images, hidden_states, masks)
return self.distribution.sample()
def act_inference(self, observations, depth_images):
out = self.estimator(observations, depth_images, sample=False)
obs_for_actor = observations[:, -1, :] if observations.dim() == 3 else observations
return self.actor(torch.cat([obs_for_actor, out["estimates"]], dim=-1))
def get_actions_log_prob(self, actions):
return self.distribution.log_prob(actions).sum(dim=-1)
def evaluate(self, critic_observations, **kwargs):
return self.critic(critic_observations)
def get_hidden_states(self):
return self.estimator.hidden_states
6.2 完整代码二:rsl_rl/algorithms/ppo_pie.py
这个文件实现 PIE 的单阶段训练逻辑。普通 PPO 只优化策略损失、价值函数损失和熵项,而 PIE 还需要把高度图、速度、足端离地量和下一步本体状态的估计损失加入同一次更新。使用时应将该文件复制到 rsl_rl/algorithms/ppo_pie.py,并在算法初始化入口中暴露 PPO_PIE。
import torch
import torch.nn as nn
import torch.optim as optim
from rsl_rl.algorithms.ppo import PPO
from rsl_rl.storage.rollout_storage_pie import RolloutStoragePIE
class PPO_PIE(PPO):
def __init__(
self,
actor_critic,
num_learning_epochs=1,
num_mini_batches=1,
clip_param=0.2,
gamma=0.998,
lam=0.95,
value_loss_coef=1.0,
entropy_coef=0.0,
learning_rate=1e-3,
max_grad_norm=1.0,
use_clipped_value_loss=True,
schedule="fixed",
desired_kl=0.01,
use_spo=False,
device="cpu",
estimator_loss_coef=1.0,
estimator_loss_weights=None,
**kwargs,
):
super().__init__(
actor_critic,
num_learning_epochs,
num_mini_batches,
clip_param,
gamma,
lam,
value_loss_coef,
entropy_coef,
learning_rate,
max_grad_norm,
use_clipped_value_loss,
schedule,
desired_kl,
use_spo,
device,
)
self.estimator_loss_coef = estimator_loss_coef
self.estimator_loss_weights = estimator_loss_weights or {}
self.optimizer = optim.Adam(self.actor_critic.parameters(), lr=learning_rate)
self.transition = RolloutStoragePIE.Transition()
def init_storage(self, storage):
self.storage = storage
def act(self, obs, privileged_obs, depth_image_features, critic_obs):
self.transition.actions = self.actor_critic.act(obs, depth_image_features).detach()
self.transition.values = self.actor_critic.evaluate(critic_obs).detach()
self.transition.actions_log_prob = self.actor_critic.get_actions_log_prob(self.transition.actions).detach()
self.transition.action_mean = self.actor_critic.action_mean.detach()
self.transition.action_sigma = self.actor_critic.action_std.detach()
self.transition.observations = obs.detach()
self.transition.privileged_observations = privileged_obs.detach()
self.transition.depth_image_features = depth_image_features.detach()
self.transition.critic_observations = critic_obs.detach()
self.transition.hidden_states = self.actor_critic.get_hidden_states()
return self.transition.actions
def process_env_step(self, next_obs, rewards, dones, infos):
self.transition.rewards = rewards.clone()
self.transition.dones = dones
self.transition.next_observations = next_obs.detach()
self.transition.height_targets = infos["pie_height_targets"].detach()
self.transition.base_vel_targets = infos["pie_base_vel_targets"].detach()
self.transition.foot_clearance_targets = infos["pie_foot_clearance_targets"].detach()
if "time_outs" in infos:
self.transition.rewards += self.gamma * torch.squeeze(
self.transition.values * infos["time_outs"].unsqueeze(1).to(self.device), 1
)
self.storage.add_transitions(self.transition)
self.transition.clear()
self.actor_critic.reset(dones)
def update(self):
mean_value_loss = 0.0
mean_surrogate_loss = 0.0
mean_estimator_loss = 0.0
batches = 0
generator = self.storage.pie_mini_batch_generator(self.num_mini_batches, self.num_learning_epochs)
for (
obs_batch,
depth_batch,
critic_obs_batch,
actions_batch,
target_values_batch,
returns_batch,
old_actions_log_prob_batch,
advantages_batch,
old_mu_batch,
old_sigma_batch,
next_obs_batch,
heights_batch,
base_vel_batch,
foot_batch,
) in generator:
est_out = self.actor_critic.update_distribution(obs_batch, depth_batch)
actions_log_prob_batch = self.actor_critic.get_actions_log_prob(actions_batch)
value_batch = self.actor_critic.evaluate(critic_obs_batch)
entropy_batch = self.actor_critic.entropy
mu_batch = self.actor_critic.action_mean
sigma_batch = self.actor_critic.action_std
if self.desired_kl is not None and self.schedule == "adaptive":
with torch.inference_mode():
kl = torch.sum(
torch.log(sigma_batch / old_sigma_batch + 1.0e-5)
+ (old_sigma_batch.square() + (old_mu_batch - mu_batch).square())
/ (2.0 * sigma_batch.square())
- 0.5,
axis=-1,
)
kl_mean = torch.mean(kl)
if kl_mean > self.desired_kl * 2.0:
self.learning_rate = max(1e-5, self.learning_rate / 1.5)
elif kl_mean < self.desired_kl / 2.0 and kl_mean > 0.0:
self.learning_rate = min(1e-2, self.learning_rate * 1.5)
for param_group in self.optimizer.param_groups:
param_group["lr"] = self.learning_rate
ratio = torch.exp(actions_log_prob_batch - torch.squeeze(old_actions_log_prob_batch))
surrogate = -torch.squeeze(advantages_batch) * ratio
surrogate_clipped = -torch.squeeze(advantages_batch) * torch.clamp(
ratio, 1.0 - self.clip_param, 1.0 + self.clip_param
)
surrogate_loss = torch.max(surrogate, surrogate_clipped).mean()
if self.use_clipped_value_loss:
value_clipped = target_values_batch + (value_batch - target_values_batch).clamp(
-self.clip_param, self.clip_param
)
value_losses = (value_batch - returns_batch).pow(2)
value_losses_clipped = (value_clipped - returns_batch).pow(2)
value_loss = torch.max(value_losses, value_losses_clipped).mean()
else:
value_loss = (returns_batch - value_batch).pow(2).mean()
estimator_losses = self.actor_critic.estimator.loss(
est_out,
next_obs_batch,
heights_batch,
base_vel_batch,
foot_batch,
self.estimator_loss_weights,
)
loss = (
surrogate_loss
+ self.value_loss_coef * value_loss
- self.entropy_coef * entropy_batch.mean()
+ self.estimator_loss_coef * estimator_losses["total"]
)
self.optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(self.actor_critic.parameters(), self.max_grad_norm)
self.optimizer.step()
mean_value_loss += value_loss.item()
mean_surrogate_loss += surrogate_loss.item()
mean_estimator_loss += estimator_losses["total"].item()
batches += 1
return mean_value_loss / batches, mean_surrogate_loss / batches, mean_estimator_loss / batches, 0.0
6.3 完整代码三:rsl_rl/storage/rollout_storage_pie.py
这个文件负责保存 PIE 训练中额外需要的监督目标。相比普通 rollout storage,它需要额外记录下一步 observation、局部高度图、真实基座速度和足端 clearance。没有这个 storage,PPO update 阶段就无法计算 estimator loss。使用时应复制到 rsl_rl/storage/rollout_storage_pie.py,并在 storage 包中导入。
import torch
from .rollout_storage_ts_depth import RolloutStorageTSDepth
class RolloutStoragePIE(RolloutStorageTSDepth):
class Transition(RolloutStorageTSDepth.Transition):
def __init__(self):
super().__init__()
self.next_observations = None
self.height_targets = None
self.base_vel_targets = None
self.foot_clearance_targets = None
def __init__(
self,
num_envs,
num_student,
num_transitions_per_env,
obs_shape,
privileged_obs_shape,
depth_image_features_shape,
critic_obs_shape,
actions_shape,
height_shape,
foot_clearance_shape,
device="cpu",
):
super().__init__(
num_envs,
num_student,
num_transitions_per_env,
obs_shape,
privileged_obs_shape,
depth_image_features_shape,
critic_obs_shape,
actions_shape,
device,
)
self.next_observations = torch.zeros(num_transitions_per_env, num_envs, *obs_shape, device=self.device)
self.height_targets = torch.zeros(num_transitions_per_env, num_envs, *height_shape, device=self.device)
self.base_vel_targets = torch.zeros(num_transitions_per_env, num_envs, 3, device=self.device)
self.foot_clearance_targets = torch.zeros(
num_transitions_per_env, num_envs, *foot_clearance_shape, device=self.device
)
def add_transitions(self, transition):
super().add_transitions(transition)
idx = self.step - 1
self.next_observations[idx].copy_(transition.next_observations)
self.height_targets[idx].copy_(transition.height_targets)
self.base_vel_targets[idx].copy_(transition.base_vel_targets)
self.foot_clearance_targets[idx].copy_(transition.foot_clearance_targets)
def pie_mini_batch_generator(self, num_mini_batches, num_epochs=8):
batch_size = self.num_envs * self.num_transitions_per_env
mini_batch_size = batch_size // num_mini_batches
obs = self.observations.flatten(0, 1)
depth = self.depth_image_features.flatten(0, 1)
critic_obs = self.critic_observations.flatten(0, 1)
actions = self.actions.flatten(0, 1)
values = self.values.flatten(0, 1)
returns = self.returns.flatten(0, 1)
old_logp = self.actions_log_prob.flatten(0, 1)
advantages = self.advantages.flatten(0, 1)
old_mu = self.mu.flatten(0, 1)
old_sigma = self.sigma.flatten(0, 1)
next_obs = self.next_observations.flatten(0, 1)
heights = self.height_targets.flatten(0, 1)
base_vel = self.base_vel_targets.flatten(0, 1)
foot = self.foot_clearance_targets.flatten(0, 1)
for _ in range(num_epochs):
indices = torch.randperm(batch_size, device=self.device)
for start in range(0, batch_size, mini_batch_size):
ids = indices[start : start + mini_batch_size]
yield (
obs[ids],
depth[ids],
critic_obs[ids],
actions[ids],
values[ids],
returns[ids],
old_logp[ids],
advantages[ids],
old_mu[ids],
old_sigma[ids],
next_obs[ids],
heights[ids],
base_vel[ids],
foot[ids],
)
6.4 完整代码四:rsl_rl/runners/pie_runner.py
…详情请参照古月居

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)