个人知识库搭建实战:用AI从0到1构建知识管理系统
摘要: 知识库搭建是信息时代的核心能力。本文从知识管理经典理论出发,结合AI时代新工具,分享一套可落地的知识库搭建方案——从信息收集、视频转笔记、内容结构化到知识图谱构建,手把手教你搭建AI知识库。
一、为什么你的知识管理是“假管理”?
先做个自测:
- 你收藏的文章/视频,三个月后还能找到并重新阅读吗?
- 你学过的知识点,能在需要时快速定位到原始出处吗?
- 不同来源的知识之间,有关联关系吗?
- 你的知识库是“活”的(持续更新),还是“死”的(堆在那里没人管)?
如果大部分答案是“否”,那你的知识管理本质上是信息囤积,不是知识管理。
真正的知识管理应该是一条完整的流水线:
信息收集 → 内容消化 → 知识结构化 → 关联建网 → 输出应用
每个环节都需要对应的工具和方法。
二、DIKW模型与知识管理框架
2.1 经典DIKW金字塔
┌─────────┐
│ Wisdom │ 智慧(洞察与判断)
│ 智慧 │
┌┴─────────┴┐
│ Knowledge │ 知识(结构化的理解)
│ 知识 │
┌┴───────────┴┐
│ Information │ 信息(有意义的数据)
│ 信息 │
┌┴─────────────┴┐
│ Data │ 数据(原始素材)
│ 数据 │
└───────────────┘
大多数人的知识管理停留在“Data”层——收藏了一堆原始素材,但从没有往上走。
2.2 信息收集层:打破信息茧房
高质量信息源:
| 类型 | 推荐来源 | 特点 |
|---|---|---|
| 学术论文 | arXiv、Semantic Scholar | 前沿但门槛高 |
| 技术博客 | CSDN、Medium、掘金 | 实用、易读 |
| 播客 | 小宇宙、Apple Podcast | 深度讨论、碎片时间可听 |
| 视频教程 | B站、小红书、抖音 | 直观、适合学操作 |
| 社交媒体 | Twitter/X、知乎 | 实时热点、观点碰撞 |
关键原则:宁可少而精,不要多而杂。5个高质量信源 > 50个低质量信源。
2.3 内容消化层:这是最大的瓶颈
收集信息容易,消化信息难。这也是大多数人知识管理"卡住"的地方。
传统的消化方式:
- 读文章 → 做笔记(耗时,且容易中断)
- 看视频 → 边看边记(分心,效果差)
- 听播客 → 听完就忘(信息留存率极低)
AI时代的解法:让AI先做第一轮消化,人再做第二轮深度理解。
具体来说:
- AI自动转录+总结:把音视频变成结构化文本
- 人快速浏览精华速览:30秒判断内容价值
- 有价值的内容深度阅读:看润色稿、思维导图
- 导出到知识库:Obsidian、Notion等
这套流程我用了大半年了。目前用Ai好记处理音视频内容——它能直接输入B站、小宇宙等平台链接,还能总结本地/网盘视频:
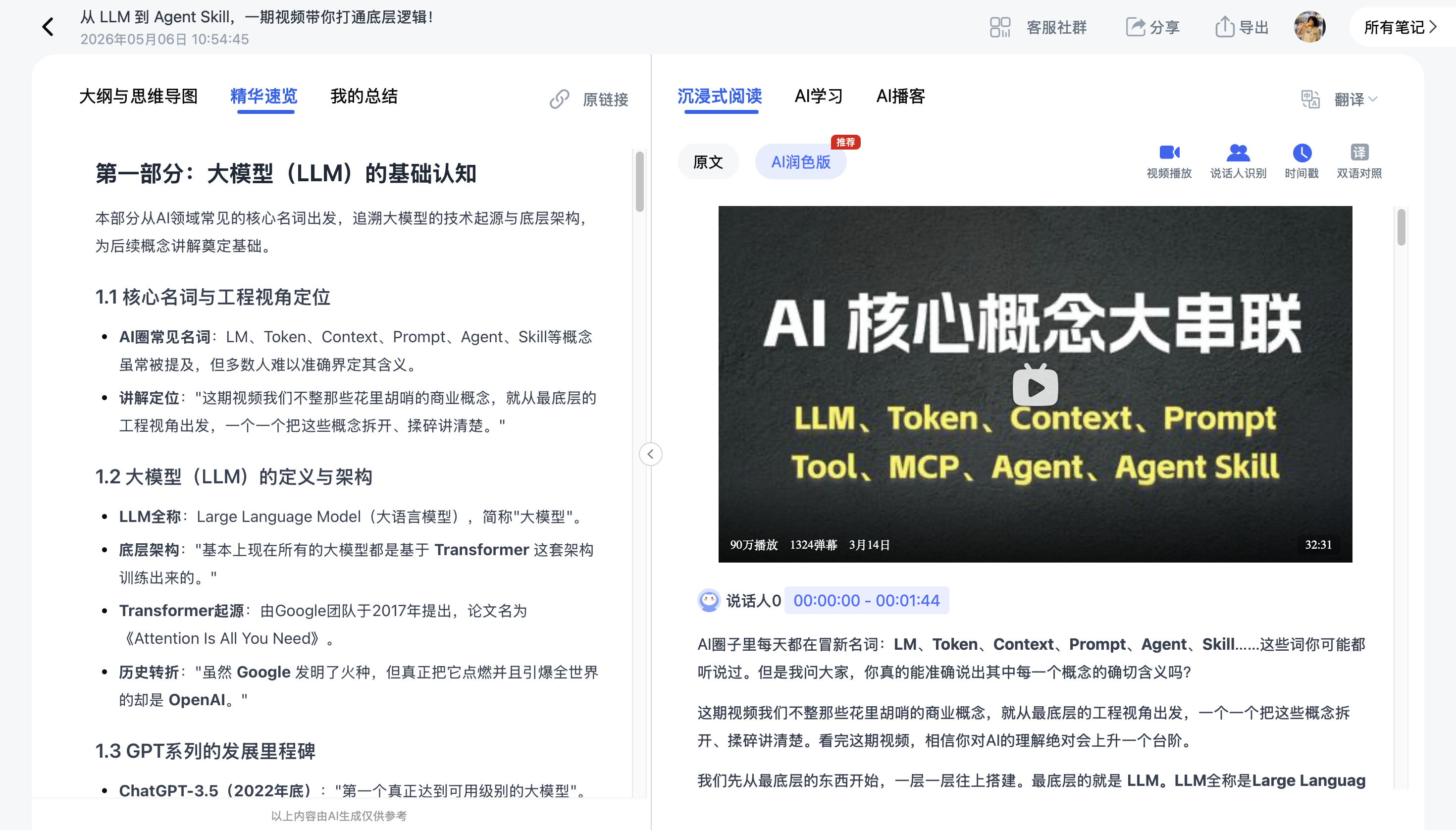
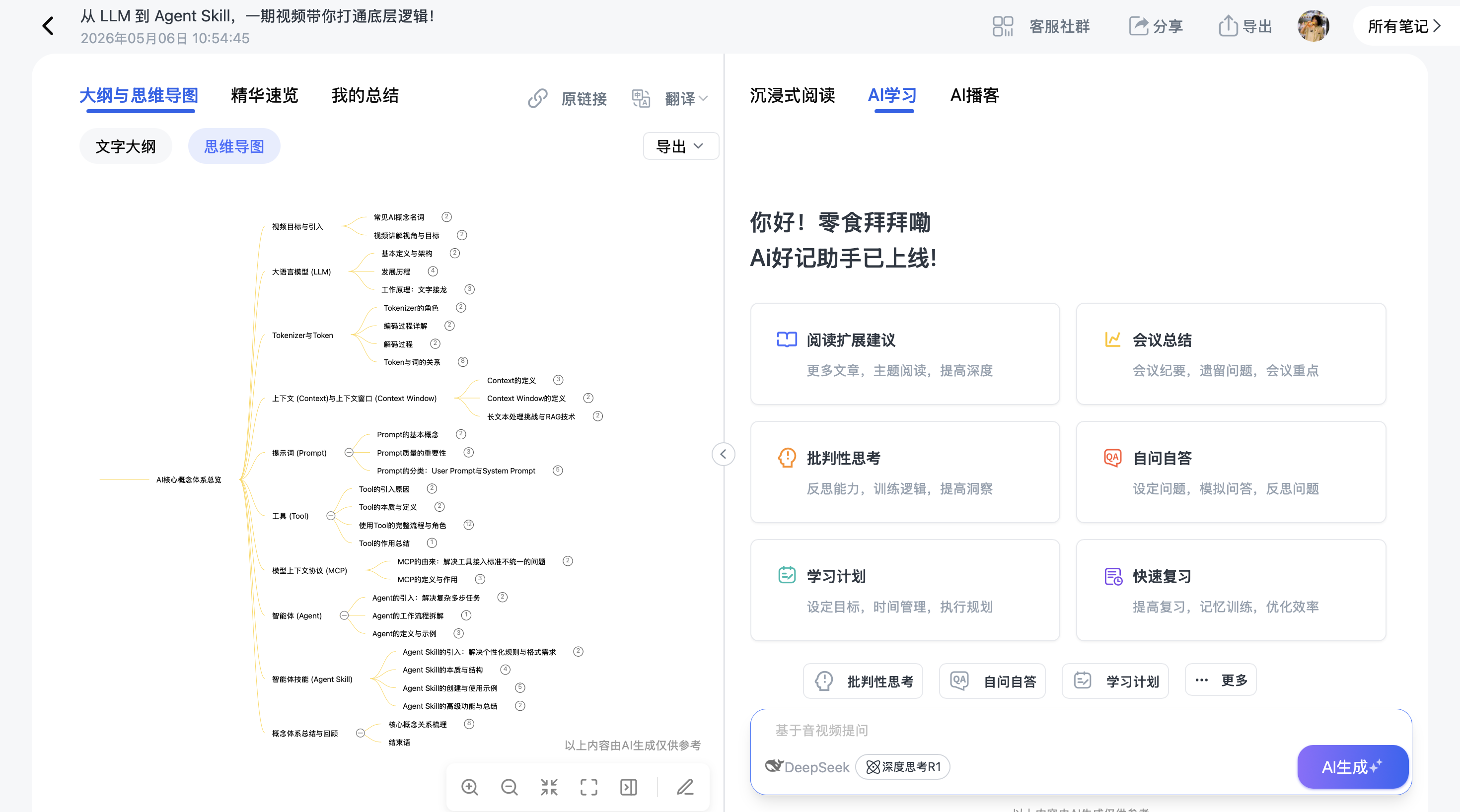
自动语音转文字,生成带PPT关键帧的逐字稿,还有重点总结和思维导图,你可以随时进行AI学习提问。
关键是能导出Markdown。处理完直接丢进Obsidian,整个流程非常顺滑。
以前一期60分钟播客要花1小时消化,现在10分钟搞定。
三、知识结构化:从笔记到知识网络
3.1 双链笔记 vs 文件夹
传统文件夹管理是树状结构——一个东西只能放在一个文件夹里。但知识之间的关系是网状的。
Obsidian的双向链接([[wikilink]])解决了这个问题:
## 多模态AI
多模态AI涉及 [[语音识别]]、[[计算机视觉]] 和 [[自然语言处理]] 的交叉领域。
在 [[音视频内容理解]] 场景下,多模态AI可以同时处理:
- 音频信号 → [[ASR转录]]
- 视频帧 → [[OCR识别]]
- 跨模态融合 → [[内容结构化]]
通过双向链接,知识自动形成网络。点击任何一个[[关键词]]就能看到所有相关内容。
3.2 知识图谱的构建
在双链笔记的基础上,可以进一步构建个人知识图谱:
┌────────────┐ ┌────────────┐ ┌────────────┐
│ 播客学习 │────▶│ AI笔记 │────▶│ Obsidian │
└────────────┘ └────────────┘ └────────────┘
│ │ │
▼ ▼ ▼
┌────────────┐ ┌────────────┐ ┌────────────┐
│ 视频教程 │────▶│ 思维导图 │────▶│ 知识图谱 │
└────────────┘ └────────────┘ └────────────┘
│ │ │
▼ ▼ ▼
┌────────────┐ ┌────────────┐ ┌────────────┐
│ 技术文章 │────▶│ 标签分类 │────▶│ 输出应用 │
└────────────┘ └────────────┘ └────────────┘
3.3 我的Obsidian知识库结构
knowledge-base/
├── 00-Inbox/ # 新内容暂存区
│ ├── ai-notes/ # Ai好记导出的笔记
│ ├── web-clips/ # 网页剪藏
│ └── manual-notes/ # 手动笔记
├── 01-Topics/ # 按主题组织
│ ├── AI/
│ ├── Development/
│ ├── Business/
│ └── Content/
├── 02-Projects/ # 项目相关
├── 03-MOC/ # Map of Content(索引页)
├── 04-Templates/ # 笔记模板
└── 05-Assets/ # 图片、附件
四、知识输出:让知识“活”起来
知识管理的最终目的是输出。没有输出的知识库,本质上还是信息囤积。
4.1 输出驱动输入
反过来想:先确定输出目标,再决定输入什么。
比如我的输出目标是每周发2篇CSDN技术文章,那么:
- 每周至少听5期相关播客(输入)
- 每期通过Ai好记快速消化(处理)
- 精选2个主题深度加工(结构化)
- 写成文章发布(输出)
4.2 知识复利
当你积累的知识足够多,它们之间会自发产生联系。一篇关于ASR的笔记,可能在三个月后帮你写一篇关于播客总结的文章。
这就是知识复利——和金融复利一样,时间越长,价值越大。
五、工具链总结
| 环节 | 工具 | 说明 |
|---|---|---|
| 音视频消化 | Ai好记 | 转录+总结+思维导图,一站式 |
| 网页剪藏 | Omnivore / Readwise | 保存和标注网页文章 |
| 笔记管理 | Obsidian | 双链笔记,本地存储 |
| 知识图谱 | Obsidian Graph View | 自动可视化知识网络 |
| 写作输出 | Typora / VS Code | Markdown写作 |
| 发布 | CSDN / 公众号 / Notion | 多平台分发 |
六、总结
个人知识管理的核心不是工具,而是流程:
- 精选信息源,减少噪音
- AI辅助消化,突破效率瓶颈
- 结构化存储,建立知识网络
- 输出驱动输入,形成正循环
AI时代的知识管理,比拼的不是谁收藏得多,而是谁消化得快、连接得好、输出得多。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)