ACL 2026 | 百度安全 2 篇成果入选 让模型兼顾“智能”与“安全”
近日,第 64 届国际计算语言学年会 ACL 2026 论文录用结果正式公布。百度共 23 篇研究成果成功入选,其中主会长文 17 篇,Findings 长文 6 篇,入选成果覆盖大模型安全、强化学习、多模态、高效网络结构和信息检索等多个前沿方向,体现了百度在人工智能、大模型等领域的前沿探索和技术积累。在此次入选的众多顶尖研究中,百度安全贡献了两篇 ACL 高分主会论文,作为突破性重点研究为大模型在复杂推理优化与安全对齐层面的底层算法演进提供了重要的技术支撑。

ACL 2026 将于 7 月 2 日至 7 日在美国加利福尼亚州圣地亚哥举行。作为全球计算语言学与自然语言处理(NLP)领域最具影响力的顶级学术会议之一,同时也是中国计算机学会(CCF)推荐的 A 类会议, ACL 长期以来以严格评审标准和高竞争强度闻名。近年来, ACL 的论文投稿数量持续攀升,本届 ACL 2026 论文投稿总数达到 12148 篇,较往年显著增长。其中,主会(Main Conference)录用率仅为 19% ,Findings of ACL 录用率为 18% 。
30秒论文速览
论文一:
Safety-Utility Conflicts Are Not Global: Surgical Alignment via Head-Level Diagnosis——Conflict-Aware Sparse Tuning(CAST)缓解大模型安全对齐中的通用能力下降
-
痛点:行业内普遍存在“对齐税”现象:为了让大模型遵循安全规范,如拒绝恶意问题,研究人员通常会对模型参数进行全局更新。但这种“一刀切”的方式往往会影响模型原有的逻辑推理能力,甚至导致其面对正常复杂问题时也过度拒绝。
-
解法: CAST 引入了一种精准的“局部对齐”策略。它在训练前对模型进行诊断,找出那些“既负责通用推理又与安全目标冲突”的关键参数区。在安全微调时,CAST 巧妙地避开这些核心区域,仅更新冲突较低的安全参数区。
-
效果:实验证明,应用 CAST 后,模型在达到同等安全防御率的同时,数学和逻辑等通用能力得到了有效保留,化解了安全与效用之间的零和博弈。
论文二:
Token-Level Policy Optimization: Linking Group-Level Rewards to Token-Level Aggregation via sequence-level likelihood——Token-Level Policy Optimization(TEPO)提升大模型推理训练的稳定性与效率
-
痛点:大模型在进行复杂的数学或逻辑推理时,通常需要输出长篇解题步骤。但传统的训练方法往往只能基于最终结果给出一个整体评分。这导致模型在长上下文中难以定位具体哪一步是对是错,容易陷入低效试错。
-
解法: TEPO 提出了一种创新的分配机制,能够将最终的整体反馈,合理、平滑地分配给过程中的每一个 Token(词元)。同时,它能精准识别出策略过度更新的节点,并适时进行干预,防止模型出现性能退化。
-
效果:该方法不仅在各项数学推理测试中提升了准确率,还凭借高稳定性的梯度更新,将模型所需的强化学习收敛时间缩短了近 50% 。
在迈向大模型和智能体规模化落地的进程中,赋予模型“高阶推理能力”与守住“安全可控底线”,是行业面临的核心挑战。大模型智能体要真正成为新质生产力的核心引擎,不仅需要通过强化学习获得深度思考的能力,还需要在复杂的交互环境中配备可靠的安全机制。百度安全的这两篇 ACL 2026 入选论文,正是沿着这一脉络,从底层算法架构出发,为大模型与智能体的演进提供了全新的优化路径。值得一提的是,这两项前沿的学术突破并未停留在纸面,而是已深度融入并转化为“百度大模型安全护栏”的核心能力。
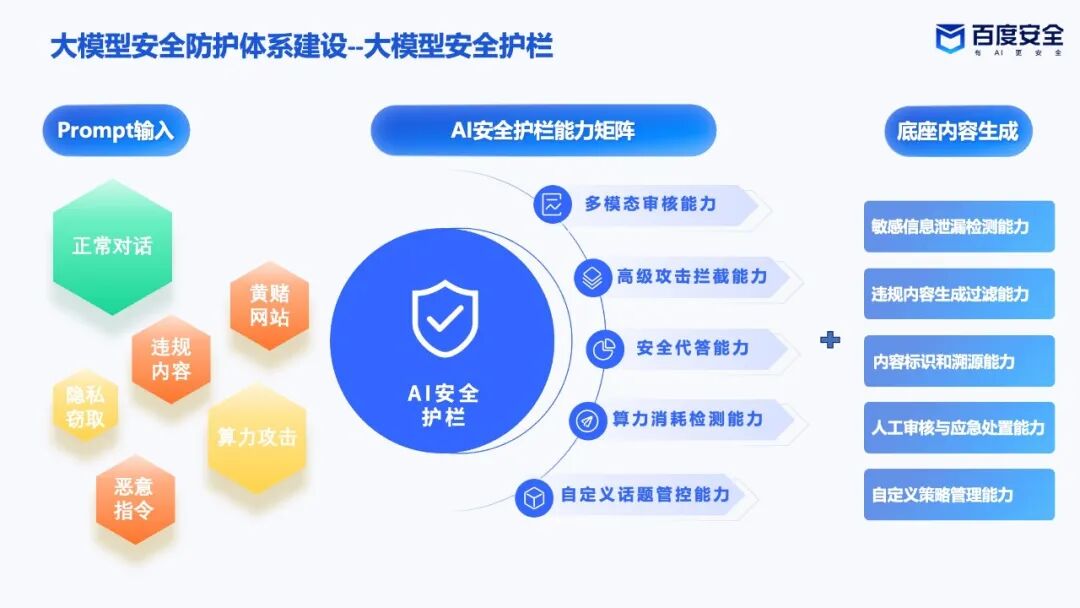
在企业级业务落地中,安全护栏往往面临着“复杂深层攻击识别难”与“业务可用性易受损,如“误杀、降低模型智力”的双重业务痛点。为此,借助 CAST 架构所代表的“局部微调与精准对齐”理念,百度大模型安全护栏能够在不干预模型正常业务逻辑、不损害通用推理能力的前提下,为企业级智能体提供“隐形且坚固”的安全防护,大幅降低了企业在实际调用中遭遇的大模型“过度拒绝”和“智商降级”问题;同时,TEPO 架构赋予了护栏底层模型更强大的思维链推理能力,使其在面对多轮次、隐蔽型安全威胁时能够进行高效、深度的逻辑判定。通过这两项技术,让百度大模型安全护栏兼具了“高阶智力”与“精准边界”。以下为百度安全团队两项重磅成果的核心技术解读:
论文一:
Safety-Utility Conflicts Are Not Global: Surgical Alignment via Head-Level Diagnosis——Conflict-Aware Sparse Tuning(CAST)缓解大模型安全对齐中的通用能力下降
论文链接:https://arxiv.org/abs/2601.04262
①研究背景
在将大语言模型与智能体投入应用之前,安全对齐是必不可少的环节。然而,现有模型普遍面临“对齐税”问题:当模型经过安全微调学会拒绝违规指令后,其原有的复杂逻辑推理、常识问答等通用能力往往会出现不同程度的下降。
现有的缓解策略多试图从全局优化层面解决此问题,对所有参数施加统一的更新规则。然而,百度安全团队指出,这种全局视角忽视了模型内部的“模块异质性”。大模型内部的注意力头(Attention Heads)存在专业化分工:部分参数更偏重通用推理,部分则更易受到安全对齐的影响。如果在安全对齐时盲目更新所有参数,就会不可避免地修改那些对通用能力敏感且与安全目标存在冲突的推理神经元,从而导致模型通用能力的下降。
②核心方法
为了缓解这一问题,百度安全提出了 CAST(Conflict-Aware Sparse Tuning ,冲突感知稀疏微调)框架。该框架将可解释性技术与参数高效微调相结合,实现了精准的参数级安全对齐。
-
对齐前冲突诊断:在正式训练前, CAST 使用少量校准数据对模型的注意力头进行评估。它综合考量安全目标与通用能力在梯度方向上的对立程度,以及该注意力头对维持通用能力的重要程度。结合这两个指标, CAST 生成了一张“冲突地图”,明确了安全与效用的冲突绝非弥漫全局,而是稀疏地集中在少数特定层的注意力头上。
-
预算匹配的安全对齐:基于诊断结果, CAST 摒弃了全局更新,将模型参数划分为高敏感的危险区和低冲突的安全区。在进行安全微调时, CAST 冻结掌管核心逻辑的危险区参数,仅对安全区的注意力头进行稀疏微调。
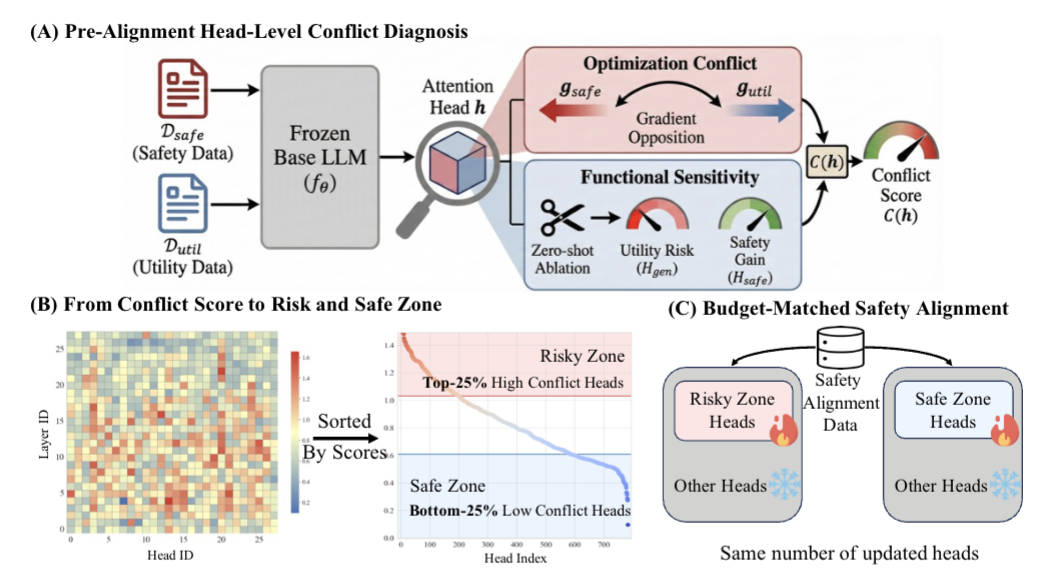
清晰展示 CAST 两阶段流程—— A 预对齐冲突诊断、 B 冲突分数分区、 C 预算匹配稀疏微调,直观体现只更新低冲突头的核心思路,是技术原理的最佳可视化。
③实验成果
百度安全在 Llama-3.1-8B、 Qwen2.5-7B 和 Mistral-7B 等开源模型上进行了对比实验。结果表明, CAST 在安全与效用的平衡上优于全量微调、随机稀疏微调等基线方法。
-
通用能力的有效保留:以 Llama 模型为例,在达到同等安全防御率的前提下,传统的全量微调导致 MMLU 准确率从 59.38% 降至 46.28% , MATH 数学推理准确率从 44.40% 降至 19.20% 。而采用 CAST 策略后, MMLU 得分保持在 55.73% , MATH 得分保持在 43.00% 。
-
改善典型失效模式: CAST 改善了传统大模型在对齐后常见的两类问题。一是缓解了推理衰退,保护了关键推理参数,使模型能保持步骤清晰的计算并给出正确答案;二是改善了过度拒绝现象,使得模型在面对长文本正常数学题时能够正确识别良性意图并完成解答。
论文二:
Token-Level Policy Optimization: Linking Group-Level Rewards to Token-Level Aggregation via sequence-level likelihood——Token-Level Policy Optimization(TEPO)提升大模型推理训练的稳定性与效率
论文链接:https://arxiv.org/abs/2510.09369
①研究背景
大模型智能体在解决复杂数学和逻辑问题时,思维链(Chain-of-Thought, CoT)推理成为了最核心的能力。为了提升这种能力,业界广泛采用了强化学习(RL)技术,特别是近期备受瞩目的组相对策略优化(GRPO)。 GRPO 因其去除了 Critic 网络的轻量化设计,有效推动了模型的推理表现。
然而,现有的大模型强化学习方法在处理思维链时,面临着一个底层的技术挑战: Token 级别的奖励极度稀疏。当智能体在推导复杂的数学题时,可能生成数千个 Token 的推理步骤。但传统的强化学习只能在最终结果出来后,给出一个全局的“组级奖励”。这就产生了一个“信用分配”难题:智能体难以区分长序列中具体哪一步是关键的正确推导,哪一步是导致最终计算错误的失误。在这种稀疏奖励下,现有的方法往往只能依赖无差别的全局约束,这容易导致模型策略出现退化,使训练过程变得不稳定。
②核心方法
为了解决这一难题,百度安全提出了一种微观级优化框架——TEPO(Token-Level Policy Optimization),在全局奖励与微观 Token 之间建立了有效的连接。该框架包含两大核心创新机制:
-
序列级似然的软聚合:传统的 Token 级重要性采样会带来较大的噪声和梯度方差。TEPO 摒弃了这一做法,转而利用数学分解原则,计算整个序列似然的几何平均值。这一“软聚合”机制,成功地将稀疏的组级奖励,平滑且稳定地分配到了每一个单独的 Token 上。这不仅大幅降低了梯度估计的方差,还有效缓解了状态分布偏移问题。
-
有条件的稳定性控制:针对无差别正则化带来的模型不稳定问题, TEPO 引入了选择性 KL 散度掩码。该机制能够精准锁定那些表现良好且策略趋于过度自信的特定 Token。只有当这些 Token 面临过快更新的风险时,掩码才会进行干预。这种精准的正则化控制,较好地平衡了探索与利用的关系。
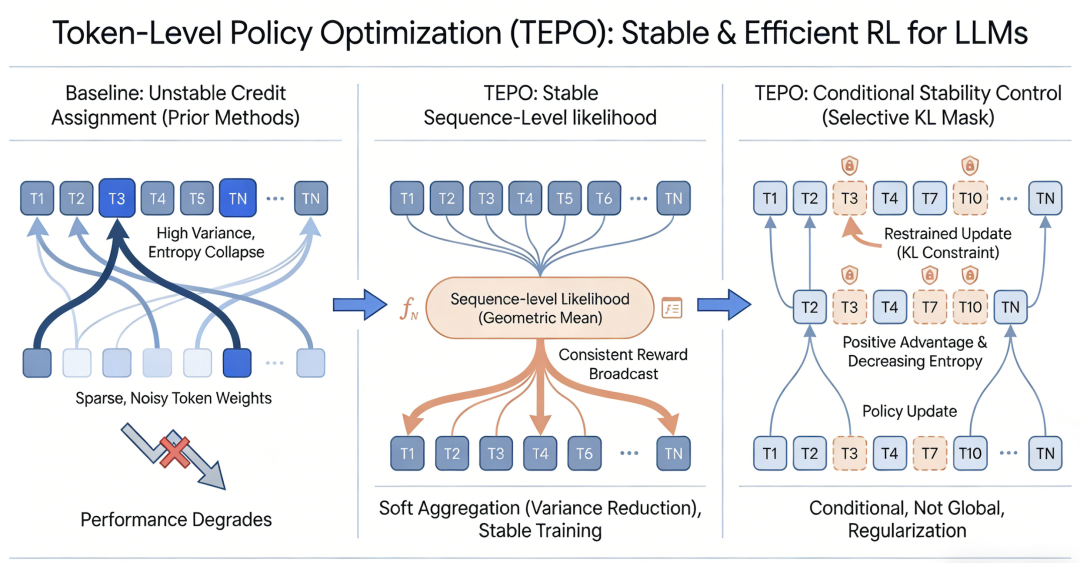
直观呈现TEPO两大核心创新——用序列级似然替代GRPO稀疏噪声的词元级信用分配,通过软聚合将分组奖励传导到单个词元;搭配词元级KL掩码,仅约束优势为正且熵递减的词元,防止策略突变,兼顾性能与训练稳定。
③实验成果
百度安全在 Qwen2.5-7B、Qwen3-14B、DeepSeek-R1-Distill 等多个主流基础模型上进行了广泛测试。
-
推理性能提升:在包含 MATH-500、AIME24/25 等在内的七大权威推理基准测试中,TEPO 优于多种基线方法,实现了平均准确率的提升。例如在 Qwen3-14B 模型上,TEPO 在 AIME24 赛事题集中取得了 24.37% 的得分,比传统 GRPO/DAPO 方法提升了 5.21 个百分点。
-
更高的收敛效率:得益于稳定的梯度更新机制,TEPO 仅需 72 个优化步骤即可达到较优性能,而基线方法则需要 132 步。这意味着,TEPO 在维持较高性能水平的同时,将智能体强化学习的收敛时间缩短了近 50% ,节约了大量的算力成本。
结语与展望
从基础大语言模型向具备复杂任务执行能力的智能体演进,是当前 AI 技术发展的重要趋势。在此进程中,提升复杂推理能力与确保系统的安全可控至关重要。此次百度安全入选 ACL 2026 的两篇研究论文,从底层算法层面提出了有效的优化思路。 TEPO 框架为智能体提供了更高效的强化学习方案,缓解了长上下文推理中的奖励分配难题;而 CAST 架构则通过精准的参数诊断与局部微调,为大模型构建了更为精细的安全对齐机制,有效减少了对齐过程对模型通用能力的损耗。未来,百度安全将继续深耕 AI 基础安全与算法研究,探索前沿技术在工业界的规模化落地应用,携手学术界及产业界,共同完善人工智能的安全基础设施,助力大模型与智能体生态的健康、长远发展。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)