本地AI编程完全指南:Ollama + Continue 实现代码隐私与自由(七)
·
本地AI编程完全指南:Ollama + Continue 实现代码隐私与自由
关键词: Ollama, Continue, 本地AI, 离线编程, 代码隐私, LLM本地部署
1. 前言:为什么要本地AI编程?
AI编程工具很强,但有一个致命问题——你的代码要上传到云端。
对于:
- 🔒 金融、医疗等敏感行业
- 🏢 有严格代码安全政策的公司
- 🌐 网络受限的开发环境
- 💰 不想支付高额API费用的个人开发者
本地AI编程是唯一的解决方案。
本文手把手教你搭建一套完全本地化的AI编程环境:
- Ollama:本地运行大语言模型
- Continue:开源AI编程助手插件
- CodeLlama/Qwen2.5-Coder:适合编程的开源模型
实现代码不出本地、零API费用、完全可控的AI编程体验。
2. 方案概览
2.1 技术栈组成
┌─────────────────────────────────────────────┐
│ VS Code / JetBrains │
│ ↓ │
│ Continue插件 │
│ ↓ │
│ Ollama服务 │
│ ↓ │
│ 本地大模型 (CodeLlama/DeepSeek/Qwen) │
└─────────────────────────────────────────────┘
2.2 核心组件
| 组件 | 作用 | 特点 |
|---|---|---|
| Ollama | 本地LLM运行框架 | 一键部署、模型管理、API兼容 |
| Continue | IDE插件 | 开源、多IDE支持、灵活配置 |
| 开源模型 | 代码生成引擎 | CodeLlama、Qwen2.5-Coder、DeepSeek-Coder |
3. 环境搭建
3.1 硬件要求
| 模型规模 | 显存需求 | 推荐显卡 | 适用场景 |
|---|---|---|---|
| 7B | 8GB+ | RTX 3060 | 代码补全 |
| 13B | 16GB+ | RTX 3090/4090 | 复杂功能 |
| 34B | 24GB+ | RTX 4090/A100 | 企业级 |
Mac用户:M1/M2/M3 Pro以上,统一内存16GB+
3.2 安装 Ollama
# macOS
brew install ollama
# Linux
curl -fsSL https://ollama.com/install.sh | sh
# Windows
# 下载安装包: https://ollama.com/download
# 验证安装
ollama --version
3.3 下载编程模型
# CodeLlama 7B(轻量级,适合大多数场景)
ollama pull codellama:7b-code
# CodeLlama 13B(更强能力)
ollama pull codellama:13b-code
# Qwen2.5-Coder(中文友好)
ollama pull qwen2.5-coder:7b
# DeepSeek-Coder(开源最强之一)
ollama pull deepseek-coder:6.7b
# 列出已安装模型
ollama list
3.4 验证模型运行
# 交互式测试
ollama run codellama:7b-code
# 输入提示
>>> 写一个Python函数,计算斐波那契数列
# 退出
/bye
4. 安装 Continue 插件
4.1 VS Code 安装
- 打开 VS Code
- 扩展商店搜索 “Continue”
- 安装并重启
4.2 配置 Continue
点击左侧 Continue 图标 → 设置 → config.json:
{
"models": [
{
"title": "CodeLlama 7B",
"provider": "ollama",
"model": "codellama:7b-code",
"apiBase": "http://localhost:11434"
},
{
"title": "Qwen2.5 Coder",
"provider": "ollama",
"model": "qwen2.5-coder:7b",
"apiBase": "http://localhost:11434"
}
],
"customCommands": [
{
"name": "test",
"prompt": "为选中代码生成单元测试"
},
{
"name": "explain",
"prompt": "解释这段代码的作用"
}
],
"tabAutocompleteModel": {
"title": "CodeLlama 7B",
"provider": "ollama",
"model": "codellama:7b-code"
}
}
4.3 JetBrains 安装
- 打开 Settings → Plugins
- 搜索 “Continue” 并安装
- 配置同 VS Code
5. 核心功能实战
5.1 代码补全(Tab Completion)
使用方式:
- 开始写代码
- 灰色提示出现时,按
Tab接受 - 按
Ctrl+→接受部分建议

效果对比:
| 模型 | 延迟 | 准确率 | 中文支持 |
|---|---|---|---|
| codellama:7b | 200ms | 75% | ⭐⭐ |
| qwen2.5-coder | 300ms | 80% | ⭐⭐⭐⭐⭐ |
| deepseek-coder | 250ms | 82% | ⭐⭐⭐⭐ |
5.2 AI 聊天对话
使用方式:
- 选中代码
- 按
Ctrl+L打开聊天 - 输入问题,如:
- “解释这段代码”
- “优化这个函数的性能”
- “找出潜在的Bug”
示例对话:
用户:优化这个函数的内存使用
AI:这个函数的问题是创建了过多临时列表。建议改用生成器:
# 优化前
def process_data(items):
return [transform(x) for x in items if filter(x)]
# 优化后
def process_data(items):
return (transform(x) for x in items if filter(x))
内存使用从 O(n) 降至 O(1)。
5.3 代码编辑(Cmd+I)
使用方式:
- 选中要修改的代码
- 按
Ctrl+I(Mac:Cmd+I) - 描述想要的修改
- AI 生成 diff,确认后应用
示例:
选中代码 → Cmd+I → "添加类型注解"
AI生成diff:
+ def greet(name: str) -> str:
- def greet(name):
5.4 快速操作(Quick Actions)
Continue 提供一键操作:
/edit- 编辑选中代码/comment- 添加注释/test- 生成测试/doc- 生成文档/fix- 修复错误
6. 高级配置
6.1 多模型切换
针对不同任务使用不同模型:
{
"models": [
{
"title": "快速补全",
"model": "codellama:7b-code"
},
{
"title": "复杂推理",
"model": "deepseek-coder:6.7b"
},
{
"title": "中文场景",
"model": "qwen2.5-coder:7b"
}
]
}
6.2 上下文配置
{
"context": {
"includeFileContext": true,
"includeImports": true,
"includeRecentlyEdited": true
}
}
6.3 自定义命令
{
"customCommands": [
{
"name": "refactor",
"description": "重构选中代码",
"prompt": "重构以下代码,提高可读性和性能:\n\n{{code}}"
},
{
"name": "security",
"description": "安全检查",
"prompt": "检查这段代码的安全漏洞:\n\n{{code}}"
}
]
}
7. 性能优化
7.1 模型量化
使用量化模型减少显存占用:
# 4-bit量化版本(显存减半)
ollama pull codellama:7b-code-q4_0
# 对比
# 原版: 7GB+ 显存
# Q4量化: 4GB+ 显存
7.2 GPU 加速
确保 Ollama 使用 GPU:
# 检查GPU使用情况
ollama ps
# 设置GPU层数(更多层=更快但占用更多显存)
ollama run codellama:7b-code --num-gpu 35
7.3 并发优化
# 启动多个Ollama实例处理并发请求
OLLAMA_NUM_PARALLEL=4 ollama serve
8. 优缺点分析
✅ 优点
- 完全隐私:代码永不离开本地
- 零API费用:一次性硬件投入
- 离线可用:无网络也能编程
- 完全可控:可定制模型和行为
- 开源生态:模型和工具都开源
❌ 缺点
- 硬件要求高:需要较好的显卡
- 模型能力有限:不如GPT-4/Claude-3.5
- 配置复杂:需要一定技术基础
- 响应较慢:本地推理比云端慢
- 中文支持参差:部分模型中文不好
9. 适用场景
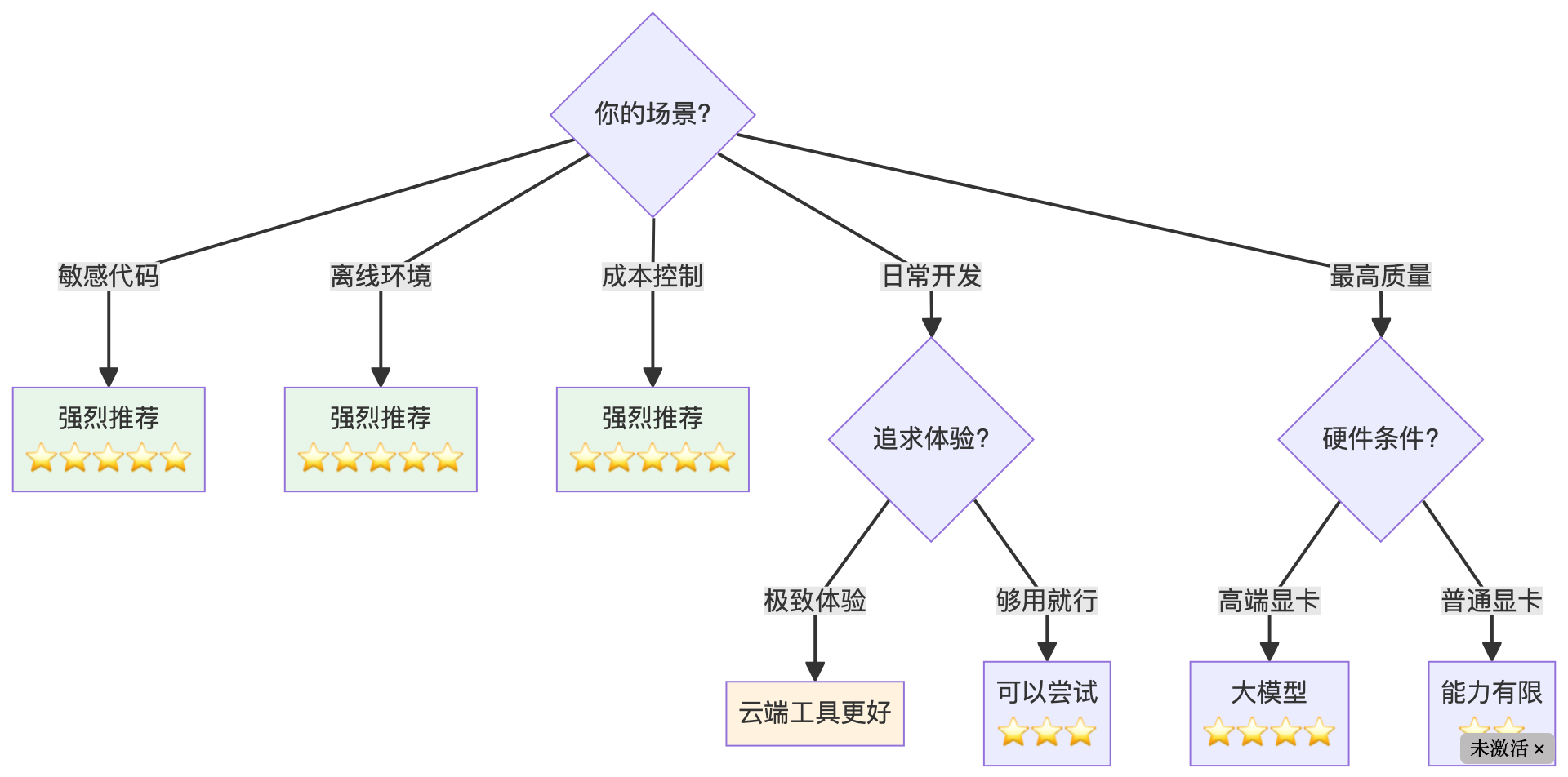
| 场景 | 推荐度 | 说明 |
|---|---|---|
| 敏感代码开发 | ⭐⭐⭐⭐⭐ | 金融/医疗/政务等 |
| 离线环境 | ⭐⭐⭐⭐⭐ | 内网/保密环境 |
| 成本控制 | ⭐⭐⭐⭐⭐ | 长期使用省钱 |
| 学习实验 | ⭐⭐⭐⭐ | 了解AI原理 |
| 日常开发 | ⭐⭐⭐ | 体验不如云端 |
| 追求最高质量 | ⭐⭐ | 本地模型能力有限 |
10. 模型选择指南
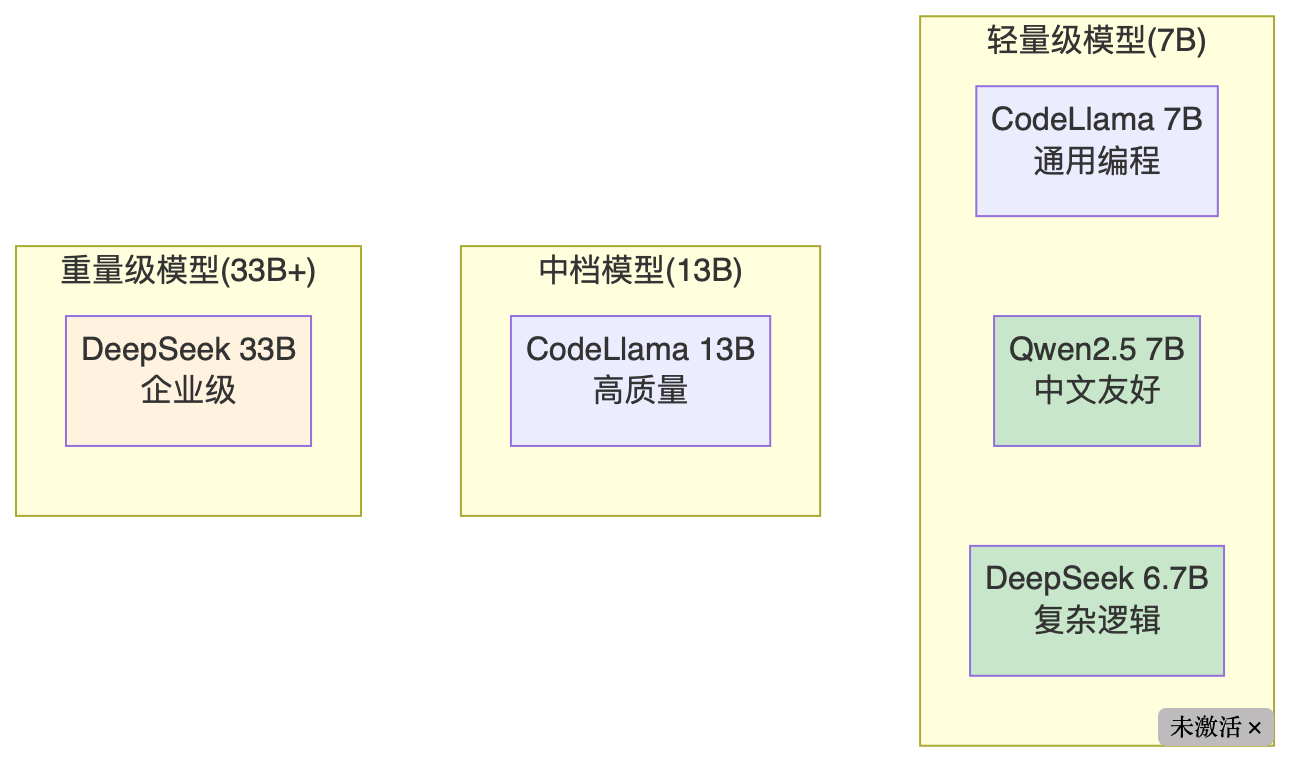
| 模型 | 大小 | 中文 | 速度 | 质量 | 推荐场景 |
|---|---|---|---|---|---|
| CodeLlama 7B | 7B | ⭐⭐ | 快 | 中等 | 通用编程 |
| Qwen2.5-Coder 7B | 7B | ⭐⭐⭐⭐⭐ | 中等 | 良好 | 中文项目 |
| DeepSeek-Coder 6.7B | 6.7B | ⭐⭐⭐⭐ | 中等 | 良好 | 复杂逻辑 |
| CodeLlama 13B | 13B | ⭐⭐ | 慢 | 好 | 高质量需求 |
| DeepSeek-Coder 33B | 33B | ⭐⭐⭐⭐ | 慢 | 很好 | 企业级 |
11. 常见问题
Q1: 显存不够怎么办?
- 使用量化版本(q4_0)
- 使用更小的模型(7B代替13B)
- 使用CPU模式(慢但省显存)
Q2: 中文支持不好?
- 使用 Qwen2.5-Coder
- 使用 DeepSeek-Coder
- 避免使用 CodeLlama 处理中文
Q3: 代码补全很慢?
- 检查GPU是否被正确使用
- 减少上下文长度
- 使用更快的模型(7B)
Q4: 与Copilot相比如何?
- 本地方案:隐私好、成本低、能力弱
- Copilot:隐私差、成本高、能力强
- 根据场景选择
12. 结语
本地AI编程不是云端的替代品,而是特定场景的最优解。
当你的代码涉及:
- 🔒 敏感信息
- 🏢 企业机密
- 🌐 网络限制
- 💰 成本敏感
本地AI是唯一的答案。
Ollama + Continue + 开源模型,让每个人都能拥有私有的、可控的、免费的AI编程助手。
这是程序员对代码主权的宣言。
📌 延伸阅读:
系列文章:
- 上一篇:Claude Code 实战
- [系列完结:AI编程工具全景回顾]

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)