AI视频总结怎么做?多模态AI从音视频到结构化知识的实践
摘要: 视频总结是内容从业者的刚需——但手动做视频总结太耗时间。本文探讨多模态AI技术(语音+视觉+文本)如何实现自动化视频总结,分析当前主流方案,并分享如何利用多模态能力高效完成视频转笔记、构建个人知识库。
一、多模态AI:不只是“能看能听”
2025-2026年,多模态大模型迎来了真正的爆发期。
ChatGPT、Gemini、Qwen等模型已经能同时理解文本、图像、音频和视频。但在“内容理解”这个具体场景下,多模态AI究竟能做什么?
核心能力拆解:
| 模态 | 输入 | 能力 | 典型场景 |
|---|---|---|---|
| 语音 | 音频文件 | ASR转录 + 说话人分离 | 播客、会议录音 |
| 视觉 | 视频帧 | OCR + 场景理解 | PPT教程、操作演示 |
| 文本 | 转录文本 | 摘要 + 结构化提取 | 所有音视频内容 |
| 多模态融合 | 音频+视频+文本 | 跨模态对齐与理解 | 带画面讲解的视频 |
真正的价值不在于单个模态的能力,而在于跨模态的融合理解。
二、技术架构:多模态内容理解Pipeline
2.1 整体架构
┌─────────────┐
│ 音视频输入 │
└──────┬──────┘
│
┌────▼────┐ ┌──────────┐ ┌──────────┐
│ 音频流 │───▶│ ASR引擎 │───▶│ 转录文本 │
└─────────┘ └──────────┘ └─────┬────┘
│
┌─────────┐ ┌──────────┐ ┌─────▼────┐
│ 视频流 │───▶│ 视觉理解 │───▶│ 视觉特征 │
└─────────┘ └──────────┘ └─────┬────┘
│
┌───────▼───────┐
│ 多模态融合 │
│ (Cross-Modal) │
└───────┬───────┘
│
┌──────────────────┼──────────────────┐
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ 结构化笔记│ │ 思维导图 │ │ 知识图谱 │
└──────────┘ └──────────┘ └──────────┘
2.2 关键技术点
音频侧:
- 带时间戳的逐句转录(word-level alignment)
- 说话人自动识别与标注
- 背景音乐/噪声过滤
视觉侧:
- PPT/屏幕文字OCR提取
- 关键帧场景切换检测
- 图表/流程图识别
融合侧:
- 音频时间戳与视频帧对齐
- 语音描述与画面内容互补理解
- 多信号交叉验证(说话人说"看这张图"时关联对应画面)
三、实战:我如何用多模态AI消化视频教程
作为技术内容从业者,我每天要看大量视频教程和技术分享。传统方式是边看边记笔记,效率极低。
后来我发现,很多工作其实可以交给多模态AI自动完成。
我的工作流
Step 1:输入来源
不管是B站的技术教程、被搬运的外网Conference Talk,还是小宇宙上的技术播客,直接把视频链接丢进去就行。
目前我主要用的是Ai好记这个工具,它支持十几种主流平台的链接直接解析,省去了手动下载的步骤。
不是在线的话,本地跟网盘的视频也可以随时解析,支持多种格式。

Step 2:自动多模态处理
平台在后台自动完成:
- 音频ASR转录(带时间戳和说话人标注)
- 视频关键帧提取和OCR识别
- 多模态内容融合
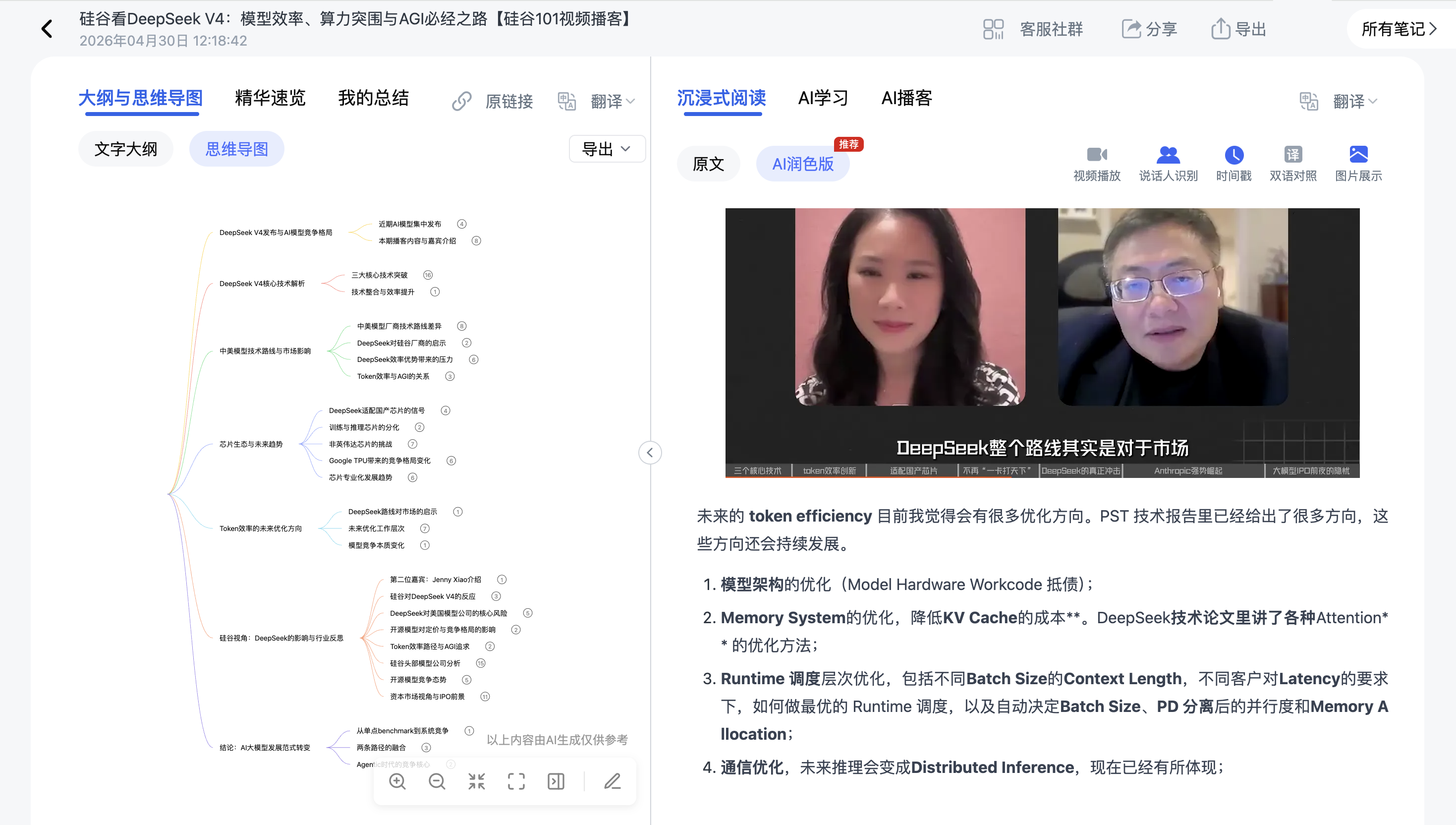
整个过程通常只需要内容时长的1/10到1/5。一期60分钟的视频,大概5-8分钟就能处理完。
Step 3:获取结构化输出
处理完成后会得到:
- AI总结:支持自定义模板(学习整理、会议纪要、技术拆解等)

- 思维导图:多层级知识结构,节点可跳转定位原文
- 精华速览:一页纸的核心要点
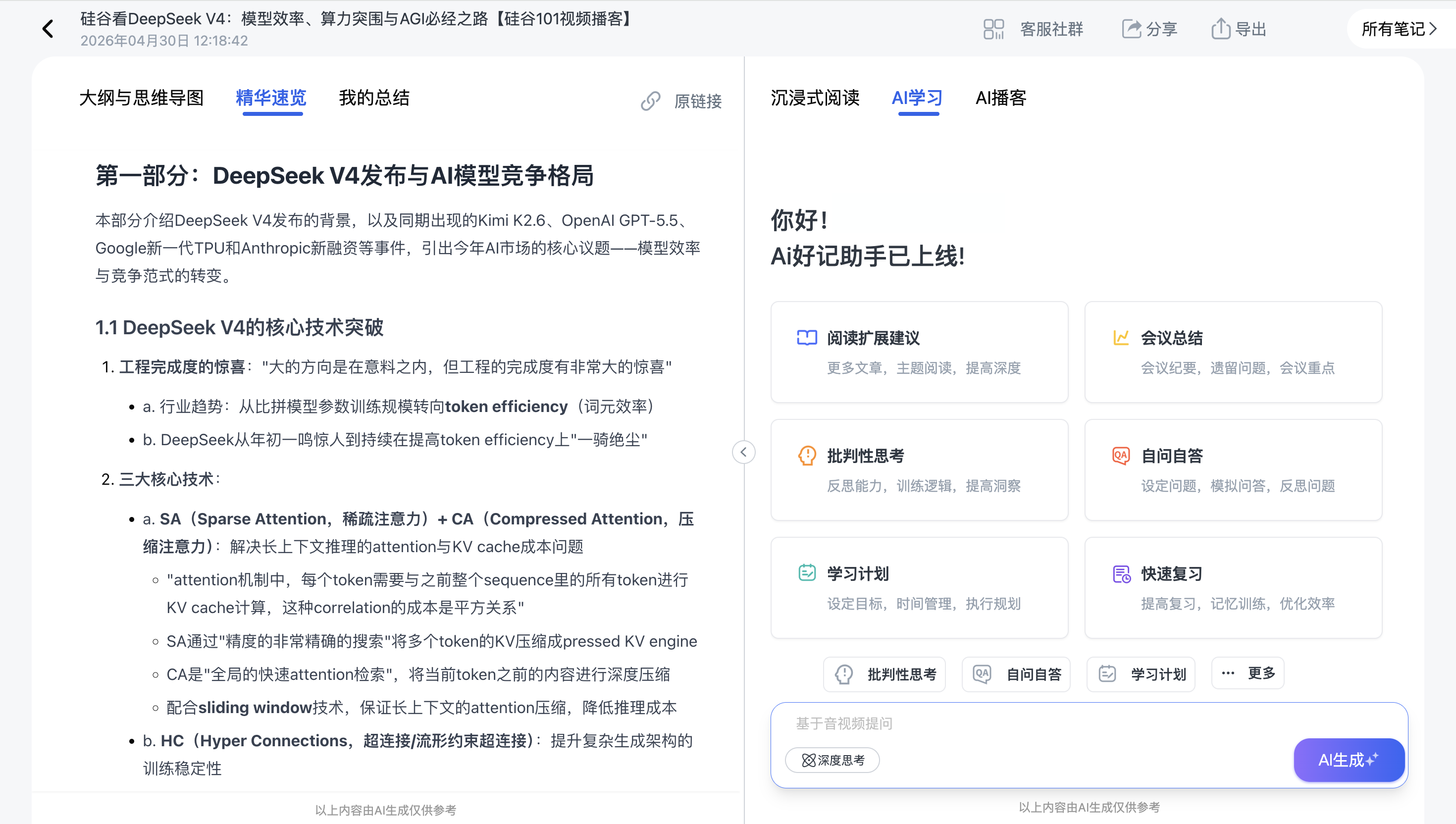
- 沉浸式图文笔记:转录文本 + PPT关键帧,像读书一样看视频
- AI润色稿:AI重新组织语言的通顺版本
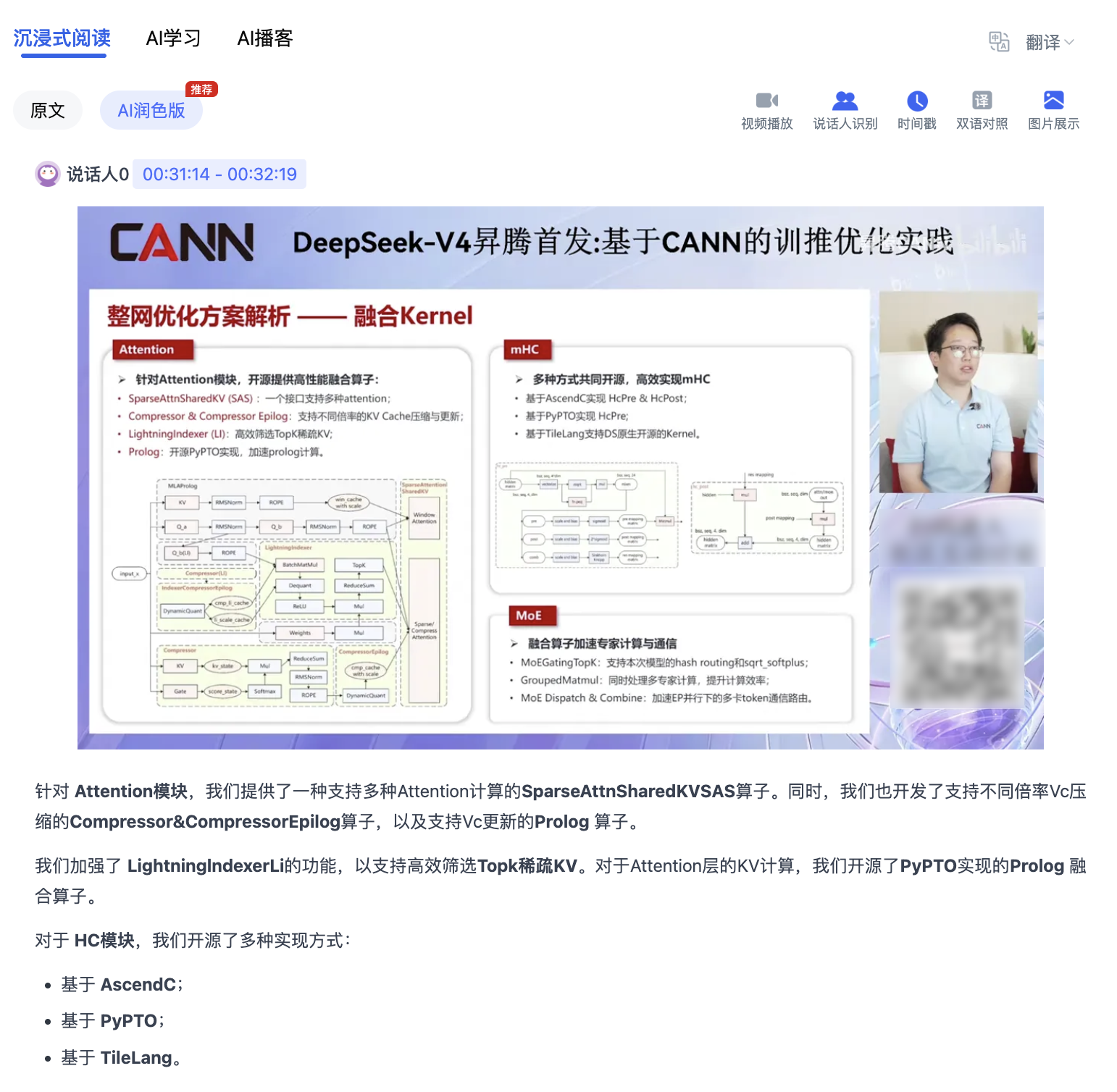
Step 4:导出到知识库
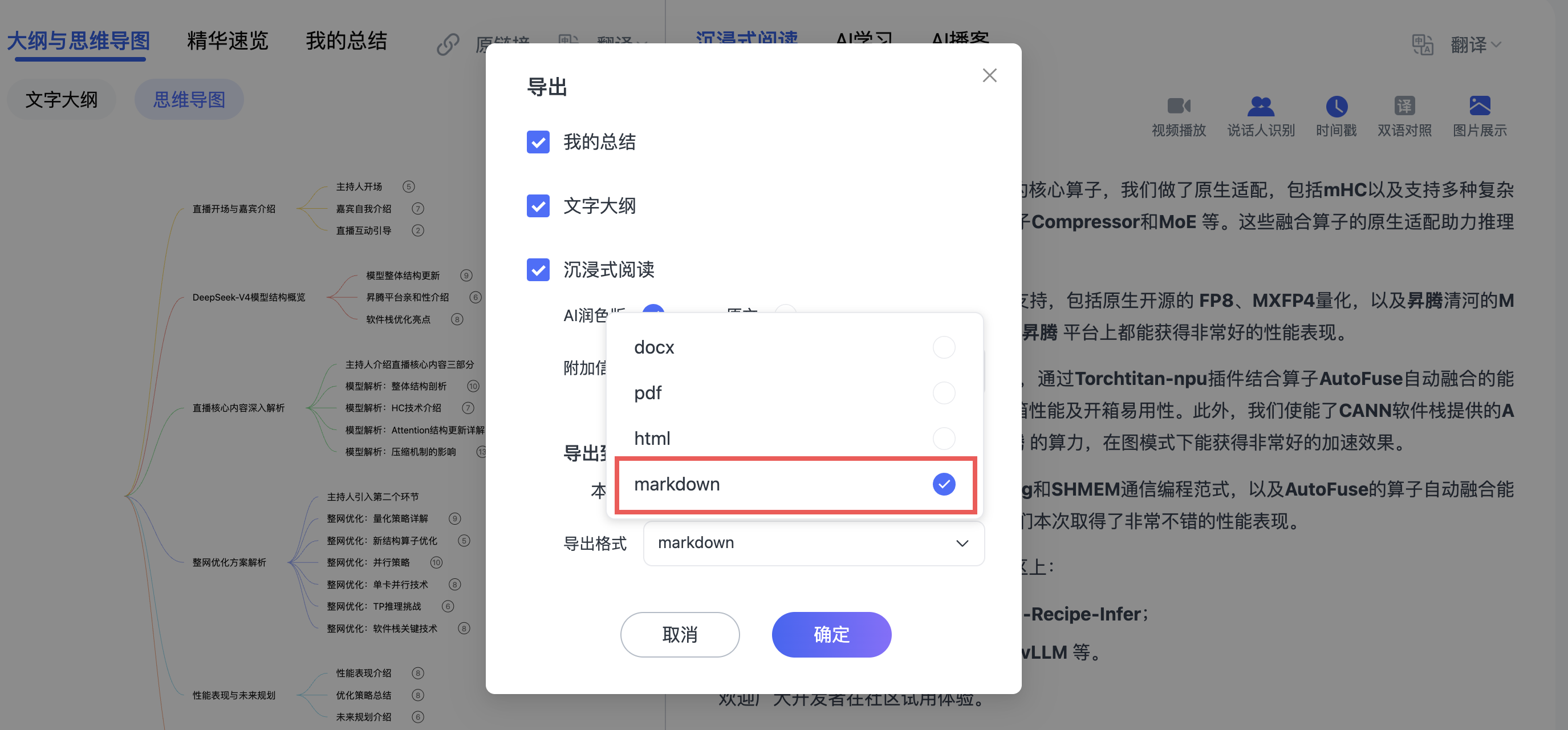
我习惯导出Markdown格式,然后归档到Obsidian。思维导图导出PNG或SVG,用于分享和展示。
和自建方案的对比
之前我也试过自己用Whisper + GPT搭pipeline,效果是能跑通,但维护成本太高了:
- Whisper大模型需要10GB+显存
- 说话人分离模型单独部署
- 视觉OCR又要接另一个服务
- 长文本摘要还要处理上下文窗口切分
- 最后还得自己做前端展示
对于个人用户或小团队来说,直接用Ai好记这类成熟产品是更务实的选择。
它在多模态融合的细节处理上做了很多工程优化,比如PPT关键帧和转录文本的时间对齐、说话人自动标注的准确率等,这些自己从头做要花大量时间调优。
四、多模态内容理解的前沿方向
4.1 原生多模态大模型
传统的多模态方案是“分模块处理+后期融合”。新一代方案(如Gemini 2.0、GPT-4o)采用原生多模态架构,直接在模型内部处理多模态信号,理论上能获得更好的跨模态理解能力。
4.2 实时流式处理
当前大多数方案还是“上传→等待→结果”的批处理模式。未来的趋势是实时流式处理——边听边生成笔记,听完即出结果。
4.3 个性化理解
同一个视频,不同人关注的重点不同。未来的多模态系统会根据用户的知识背景和兴趣偏好,生成个性化的笔记和摘要。
五、总结
多模态AI已经从实验室走向了实际应用。在音视频内容理解这个场景下,它能做的事情比大多数人想象的要多:
- 不只是“语音转文字”
- 而是看懂画面、听懂语音、理解上下文,然后输出结构化知识
无论你选择自建方案还是用现成工具,核心思路是一样的:让AI承担信息处理的苦力活,让人专注于思考和决策。
相关资源:
- Whisper:github.com/openai/whisper
- pyannote-audio:github.com/pyannote/pyannote-audio
- Ai好记:aihaoji.com(支持多模态音视频笔记自动生成)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 19
19 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)