Python基于学生历次成绩的浙江高考「七选三」选科推荐分析
浙江高考改革后,学生需在物理、化学、生物、政治、历史、地理、技术中任选 3 门作为选考科目。如何利用学生多年来的考试成绩,量化「擅长程度」并给出个性化推荐?本文用 Python 完整实现一套打分模型,包含数据清洗、特征构建、综合评分、可视化及班级整体分析。
一、问题背景
浙江新高考采用“3+3”模式:语数英必考,另外 7 门选考科目(物化生政史地技)中任选 3 门计入高考总分。学校和学生面临的核心问题是:选哪三科能最大程度发挥自己的成绩优势?
传统的选科指导往往依赖单次考试分数或简单排名,缺乏对长期水平、进步趋势、稳定性的综合考量。本分析尝试用历次考试成绩的 Z-score(跨次标准分) 和 等第百分位 作为水平度量,再引入 趋势项 和 稳定性惩罚,为每位学生计算 7 科的“擅长得分”,并推荐得分最高的 3 门。
注:本文所有数据均已脱敏处理,仅演示方法论。
二、整体思路与公式
2.1 核心公式
对每位学生在每门候选学科上计算综合得分:
score=0.5×avgz+0.2×(1−avgdengdi)+0.2×trend−0.1×stdz score = 0.5 × avg_z + 0.2 × (1 - avg_dengdi) + 0.2 × trend - 0.1 × std_z score=0.5×avgz+0.2×(1−avgdengdi)+0.2×trend−0.1×stdz
各项含义:
- Z‾Z:该生该学科历次考试 Z-score 的均值。Z-score 已在每次考试内部标准化,可跨次比较。值越高越好。
- 1−rank‾1−rank:等第百分位的补数。原始等第(0~1)越小排名越靠前,用 1 减去后变成“越大越好”。
- trendtrend:进步趋势。将学生该学科的所有考试按时间排序,计算后半程 Z 均值 − 前半程 Z 均值。正值表示持续进步。
- σZσ**Z:Z-score 的标准差,反映成绩波动性。波动越大扣分越多(权重 -0.1)。
四个权重(0.5, 0.2, 0.2, -0.1)可根据学校的选拔偏好自由调整(例如更看重稳定性的学校可增加稳定性惩罚权重)。
2.2 数据来源
5_chengji.csv:历次考试成绩,字段包含学生 ID、学科、原始分、Z-score、T-score、等第百分位等。2_student_info.csv:学生基本信息(姓名、性别、班级)。1_teacher.csv:教师任课表(本分析暂未使用)。
三、数据清洗与预处理
3.1 合并技术类学科
原始数据中“技术”“通用技术”“信息技术”分开记录,按七选三规则统一归为 技术。
python
chengji['mes_sub_name'] = chengji['mes_sub_name'].replace({
'通用技术': '技术',
'信息技术': '技术'
})
3.2 剔除无效分数
python
# 2. 过滤 mes_Score 特殊值
n_before = len(chengji)
valid = chengji[chengji['mes_Score'] >= 0].copy()
print(f"过滤特殊值: {n_before} -> {len(valid)} (剔除 {n_before - len(valid)} 条缺考/免考/作弊记录)")
- 原始分
mes_Score中-1=作弊、-2=缺考、-3=免考,一律丢弃。 - 只保留正式考试类型:期中(2)、期末(3)、五校联考(6)、十校联考(7)、模拟(9)、期中考试(20)、期末考试(21)。
3.3 保留目标学科
python
target_subs = SEVEN + ['语文', '数学', '英语']
valid = valid[valid['mes_sub_name'].isin(target_subs)]
print(f"过滤学科后: {len(valid)}")
只保留七门选考科目(物化生政史地技)+ 语数英(语数英本分析未使用,但留作后续扩展)。
清洗后保留 219,415 条有效记录,覆盖 3,837 名学生(其中在校生 1,557 人,历史毕业生 2,280 人)。
各学科记录数:
mes_sub_name
英语 32452
语文 30596
数学 30272
物理 24787
化学 24468
生物 24168
政治 18071
地理 14484
历史 12796
技术 7321
Name: count, dtype: int64
四、特征构建:学生-学科粒度统计
对每个(学生, 学科)分组计算以下指标:
avg_z:Z-score 均值(必须至少有 2 次有效记录,否则该学科不参与推荐)avg_score:原始分均值(仅供参考)std_z:Z-score 标准差(稳定性)avg_dengdi:等第百分位均值n_exam:考试次数trend:按考试日期排序后,后半段 Z 均值 − 前半段 Z 均值(若总次数 <4,趋势=0)
python
def calc_stu_subject(df):
"""对单个 (学生, 学科) 子集计算指标"""
s_z = df['mes_Z_Score'].dropna()
s_score = df['mes_Score']
if len(s_z) == 0:
return pd.Series({'avg_z': np.nan, 'avg_score': s_score.mean(),
'std_z': np.nan, 'avg_dengdi': np.nan,
'n_exam': len(df), 'trend': np.nan})
# 按日期排序算趋势
df_sorted = df.sort_values('exam_sdate')
z_sorted = df_sorted['mes_Z_Score'].dropna().values
if len(z_sorted) >= 4:
half = len(z_sorted) // 2
trend = z_sorted[half:].mean() - z_sorted[:half].mean()
else:
trend = 0.0
return pd.Series({
'avg_z': s_z.mean(),
'avg_score': s_score.mean(),
'std_z': s_z.std() if len(s_z) > 1 else 0.0,
'avg_dengdi': df['mes_dengdi'].dropna().mean(),
'n_exam': len(df),
'trend': trend,
})
stu_subj = (valid.groupby(['mes_StudentID', 'mes_sub_name'])
.apply(calc_stu_subject)
.reset_index())
print(f"学生×学科 维度: {stu_subj.shape}")
print(f"覆盖学生数: {stu_subj['mes_StudentID'].nunique()}")
stu_subj.head(8)
五、推荐得分计算
按照前面的公式实现 compute_score,对缺失值做保守处理(等第缺失填充 0.5,趋势缺失填 0,标准差缺失填 1.0),若 avg_z 缺失则返回 -999(后续过滤)。
python
def top3(g):
g = g.sort_values('score', ascending=False).head(3)
subs = g['mes_sub_name'].tolist()
scores = g['score'].tolist()
return pd.Series({
'top1': subs[0] if len(subs) >= 1 else None,
'top1_score': scores[0] if len(scores) >= 1 else None,
'top2': subs[1] if len(subs) >= 2 else None,
'top2_score': scores[1] if len(scores) >= 2 else None,
'top3': subs[2] if len(subs) >= 3 else None,
'top3_score': scores[2] if len(scores) >= 3 else None,
'combo': '+'.join(sorted(subs[:3])) if len(subs) >= 3 else None,
})
recommend = (seven_only.groupby('mes_StudentID')
.apply(top3)
.reset_index())
# 关联学生信息
recommend = recommend.merge(
stu[['bf_StudentID', 'bf_Name', 'bf_sex', 'cla_Name']],
left_on='mes_StudentID', right_on='bf_StudentID', how='left'
)
print(f"推荐覆盖 {len(recommend)} 名学生\n")
recommend.head(10)
然后为每位学生选出 得分最高的 3 门学科 作为推荐组合。
六、可视化分析
图1:七门学科 Z-score 分布箱线图
横轴为学科,纵轴为所有学生在该学科的 avg_z 分布。Z 值整体围绕 0 波动,箱体高度反映学生分化程度。
- 全班同学在哪门学科上"分化"最大(箱体高 = 学生水平差距大)
- 哪门学科整体偏强/偏弱(中位数高/低)
注:因为 Z-score 是按每次考试内标准化的,理论上每门的整体均值都应在 0 附近, 分布的形状差异主要体现"分化程度"。
order = (seven_only.groupby('mes_sub_name')['avg_z']
.median()
.sort_values()
.index.tolist())
fig, ax = plt.subplots(figsize=(11, 5.5))
sns.boxplot(data=seven_only.dropna(subset=['avg_z']),
x='mes_sub_name', y='avg_z',
order=order, palette='Set2', ax=ax)
ax.axhline(0, color='red', linestyle='--', alpha=0.6, label='平均水平 (Z=0)')
ax.set_title('七选三各学科 平均 Z-score 分布', fontsize=14)
ax.set_xlabel('学科'); ax.set_ylabel('Avg Z-score')
ax.legend()
plt.tight_layout()
plt.savefig(os.path.join(OUT_DIR, 'fig1_subject_distribution.png'), dpi=130)
plt.show()
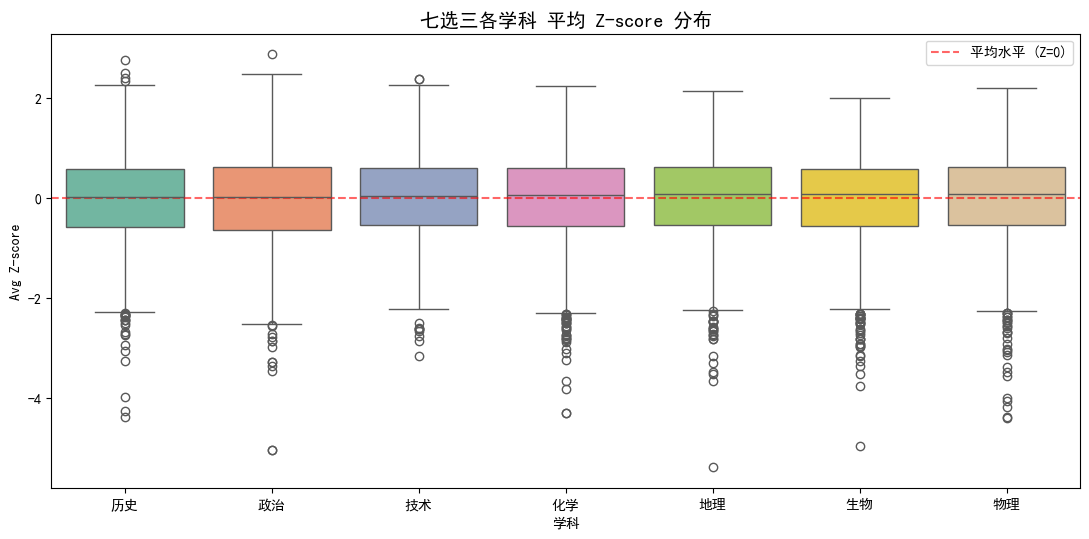
图2:最热门的推荐组合 Top15
将每位学生的 3 门推荐学科排序后拼接成组合字符串(如“物理+化学+生物”),统计频次。
combo_counts = recommend['combo'].value_counts().head(15)
fig, ax = plt.subplots(figsize=(10, 6))
combo_counts.plot(kind='barh', ax=ax, color='steelblue', edgecolor='black')
ax.set_title('推荐组合 Top 15', fontsize=14)
ax.set_xlabel('被推荐学生人数'); ax.set_ylabel('组合')
ax.invert_yaxis()
for i, v in enumerate(combo_counts.values):
ax.text(v + 0.5, i, str(v), va='center')
plt.tight_layout()
plt.savefig(os.path.join(OUT_DIR, 'fig2_combo_counts.png'), dpi=130)
plt.show()
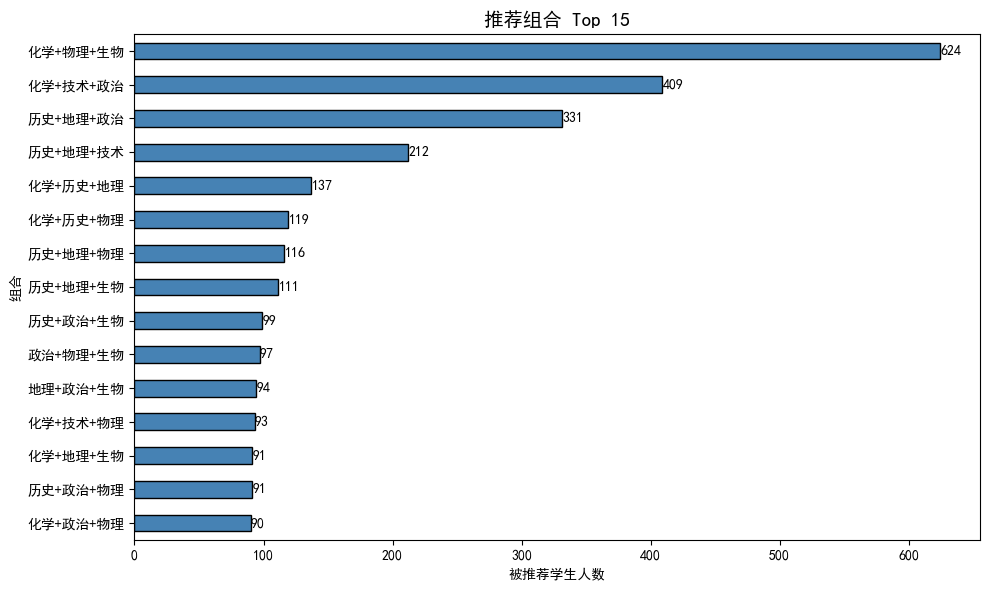
发现(基于实际数据):
- 第1名:化学+物理+生物(624 人推荐)
- 第2名:化学+技术+政治(409 人)
- 第3名:历史+地理+政治(331 人)
呈现“理科主流、文科主流、文理混合”的格局。
图3:学科间能力相关性热力图
计算每个学生 7 科 avg_z 的 Pearson 相关系数矩阵,求列间的 Pearson 相关。 正值高 = 两科"擅长这个的也擅长那个",负值 = 此消彼长。
pivot = seven_only.pivot_table(index='mes_StudentID',
columns='mes_sub_name',
values='avg_z')
corr = pivot.corr()
fig, ax = plt.subplots(figsize=(8, 6.5))
sns.heatmap(corr, annot=True, fmt='.2f', cmap='RdBu_r', center=0,
square=True, cbar_kws={'shrink': 0.8}, ax=ax,
linewidths=0.5, linecolor='white',
vmin=-0.2, vmax=1) # 固定色阶,让差异更明显
ax.set_title('七科 Z-score 相关性热力图', fontsize=14)
ax.set_xlabel(''); ax.set_ylabel('') # 去掉默认的列名标签
plt.tight_layout()
plt.savefig(os.path.join(OUT_DIR, 'fig3_corr.png'), dpi=130)
plt.show()
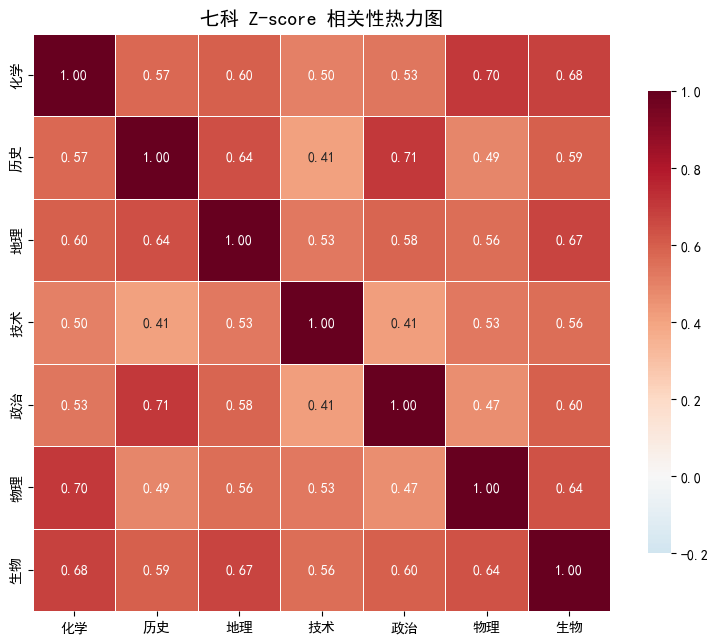
发现:
- 理科群组:化学-物理 0.70,化学-生物 0.68
- 文科群组:政治-历史 0.71,历史-地理 0.64
- 技术与其他学科相关性最低(0.41~0.56),是相对独立的能力维度
图4:单个学生的七科能力雷达图
随机选取一位在校且 7 科跨度大的学生,绘制雷达图,并标注推荐结果。
# 选一位"画像鲜明"的在校学生作为示例:
# 1) 必须在学生信息表里(才有姓名/班级)
# 2) 七科覆盖齐全
# 3) avg_z 跨度大(最大最小差至少 1.5),才能在雷达图上看出形状
# 先把每位学生七科 avg_z 透视成行
pivot_radar = (seven_only.pivot_table(index='mes_StudentID',
columns='mes_sub_name',
values='avg_z'))
# 必须七科齐全
pivot_radar = pivot_radar.dropna(thresh=7)
# 跨度
pivot_radar['range'] = pivot_radar.max(axis=1) - pivot_radar.min(axis=1)
# 必须在学生表里
in_school = set(stu['bf_StudentID'].tolist())
candidates = pivot_radar[pivot_radar.index.isin(in_school)].copy()
candidates = candidates.sort_values('range', ascending=False)
# 取跨度最大的那位(画像最有特点)
sample_id = int(candidates.index[0])
sample_name = stu.loc[stu['bf_StudentID']==sample_id, 'bf_Name'].iloc[0]
sample_class = stu.loc[stu['bf_StudentID']==sample_id, 'cla_Name'].iloc[0]
print(f"示例学生: {sample_id} ({sample_name}) - {sample_class}")
print(f"七科 avg_z 跨度: {candidates.loc[sample_id, 'range']:.2f}")
# 取该学生七科 avg_z
sample = (seven_only[seven_only['mes_StudentID'] == sample_id]
.set_index('mes_sub_name')
.reindex(SEVEN)['avg_z']
.fillna(0))
# 推荐结果
rec_row = recommend[recommend['mes_StudentID']==sample_id].iloc[0]
rec_str = f"推荐: {rec_row['top1']} + {rec_row['top2']} + {rec_row['top3']}"
angles = np.linspace(0, 2*np.pi, len(SEVEN), endpoint=False).tolist()
values = sample.tolist()
angles += angles[:1]; values += values[:1]
fig, ax = plt.subplots(figsize=(7.5, 7.5), subplot_kw=dict(polar=True))
ax.plot(angles, values, 'o-', linewidth=2.2, color='darkorange')
ax.fill(angles, values, alpha=0.28, color='darkorange')
ax.set_xticks(angles[:-1])
ax.set_xticklabels(SEVEN, fontsize=12)
# 加 z=0 参考圈
ax.plot(angles, [0]*len(angles), '--', color='red', alpha=0.4, linewidth=1, label='平均水平 (Z=0)')
ax.set_title(f'学生 {sample_id} ({sample_name}) - {sample_class}\n七科能力画像 {rec_str}',
y=1.1, fontsize=12)
ax.legend(loc='lower right', bbox_to_anchor=(1.15, -0.05))
ax.grid(True)
plt.tight_layout()
plt.savefig(os.path.join(OUT_DIR, 'fig4_radar.png'), dpi=130)
plt.show()
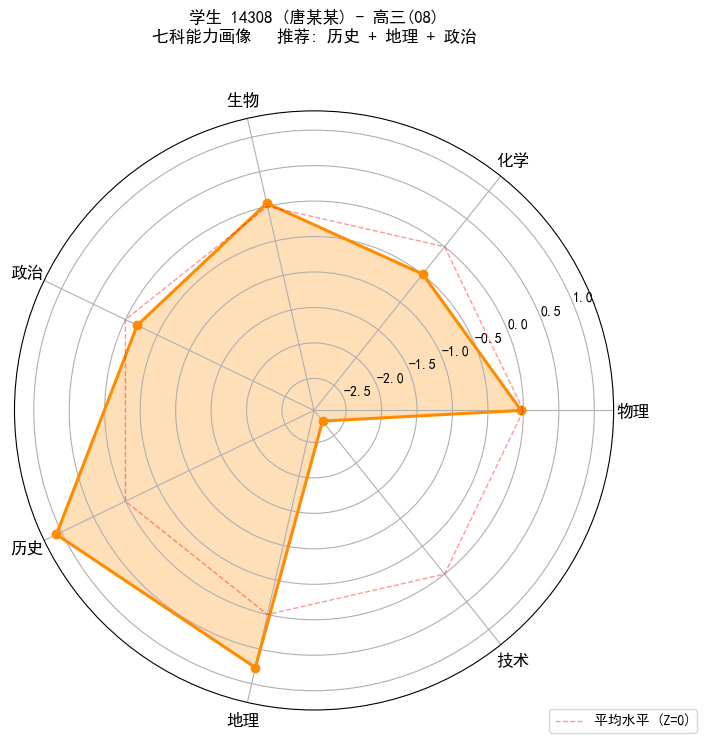
案例(高三(08) 唐某某):历史 Z≈+1.0,地理≈+0.7,生物≈+0.5,物理化学约 -0.5,技术跌至 -2.7。最终推荐 历史+地理+政治,与画像高度吻合。
图5:学科水平 vs 稳定性散点图
# 散点图密度高时,改用六边形 hexbin 看密度更清楚;同时分学科画 6 个小图,避免颜色叠在一起糊成一团
fig, axes = plt.subplots(2, 4, figsize=(15, 7.5), sharex=True, sharey=True)
axes = axes.flatten()
palette = sns.color_palette('tab10', n_colors=len(SEVEN))
for i, (sub, color) in enumerate(zip(SEVEN, palette)):
ax = axes[i]
sub_df = seven_only[seven_only['mes_sub_name']==sub].dropna(subset=['avg_z','std_z'])
ax.scatter(sub_df['avg_z'], sub_df['std_z'],
alpha=0.35, s=14, color=color, edgecolor='none')
ax.axvline(0, color='gray', linestyle='--', alpha=0.5)
ax.set_title(f'{sub} (n={len(sub_df)})', fontsize=11)
ax.grid(alpha=0.2)
if i % 4 == 0:
ax.set_ylabel('Std Z-score')
if i >= 4:
ax.set_xlabel('Avg Z-score')
横轴 avg_z(水平),纵轴 std_z(波动)。每个点代表一个(学生, 学科)。
- 右下区域(高水平 + 低波动):该学科是学生的“压舱石”
- 右上区域(高水平 + 高波动):偶有爆发,需稳定
- 左下区域(低水平 + 低波动):稳定地不擅长,建议放弃
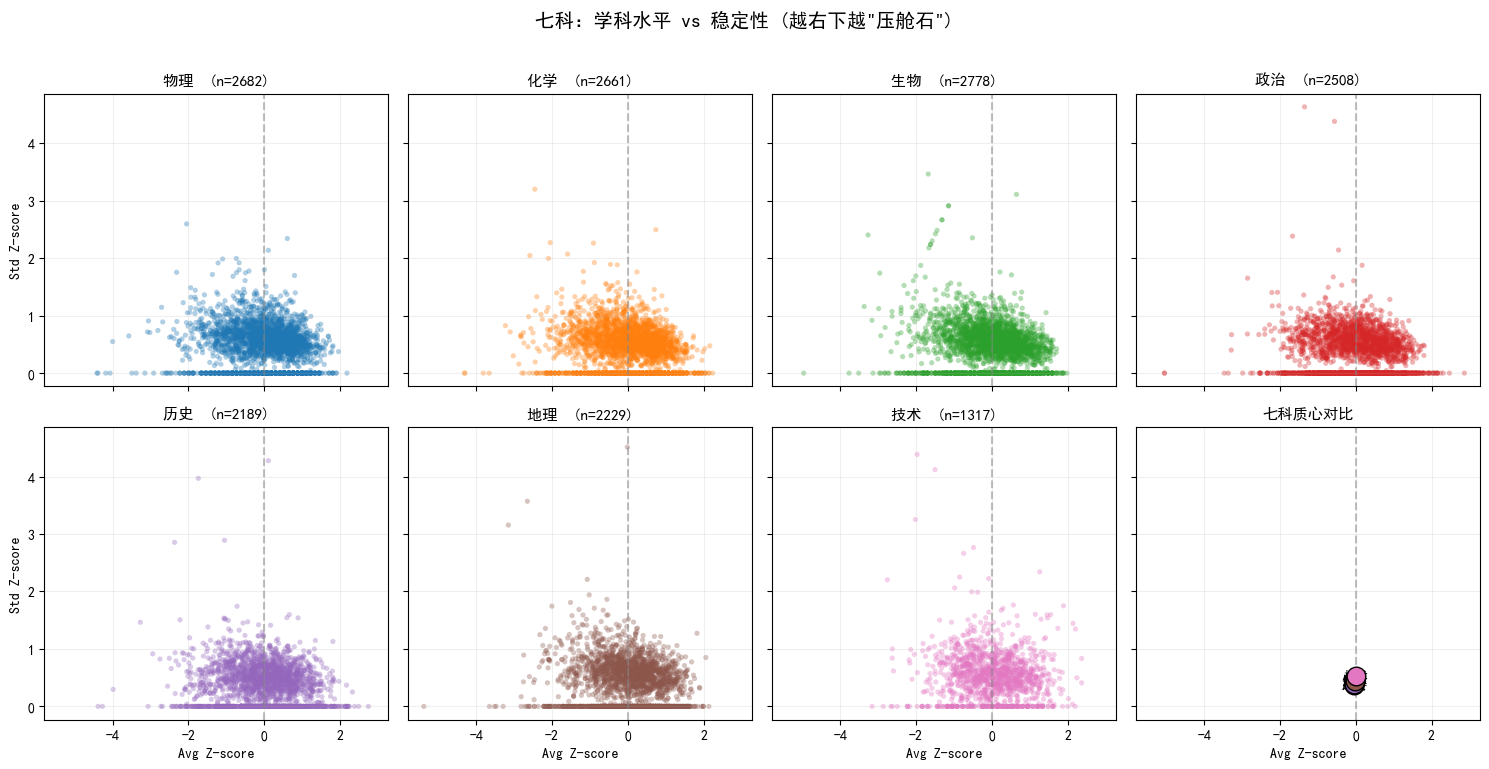
图6:各班级 × 推荐组合 人数热力图
按班级聚合,展示每个班最主流的推荐组合,对学校排课、师资调配有直接参考价值。
# 班级 × 组合 透视表
class_combo = (recommend.dropna(subset=['cla_Name', 'combo'])
.groupby(['cla_Name', 'combo']).size().unstack(fill_value=0))
# 只看最热门 8 个组合,班级按总人数排序取前 12 个
top_combos = recommend['combo'].value_counts().head(8).index.tolist()
class_sizes = recommend.groupby('cla_Name').size().sort_values(ascending=False).head(12).index.tolist()
plot_mat = class_combo.loc[class_sizes, top_combos]
fig, ax = plt.subplots(figsize=(12, 6.5))
sns.heatmap(plot_mat, annot=True, fmt='d', cmap='YlOrRd', ax=ax,
cbar_kws={'label': '人数'}, linewidths=0.5)
ax.set_title('各班级 × 推荐组合 人数分布(前12大班级 × 前8热门组合)', fontsize=13)
ax.set_xlabel('推荐组合'); ax.set_ylabel('班级')
plt.xticks(rotation=30, ha='right')
plt.tight_layout()
plt.savefig(os.path.join(OUT_DIR, 'fig6_class_combo.png'), dpi=130)
plt.show()
# 配套打印:每个班最主流的组合是什么
print("\n各班最主流推荐组合 (Top 5 班级):")
for cla in class_sizes[:5]:
top_for_class = class_combo.loc[cla].sort_values(ascending=False).head(3)
print(f" {cla}: {top_for_class.to_dict()}")
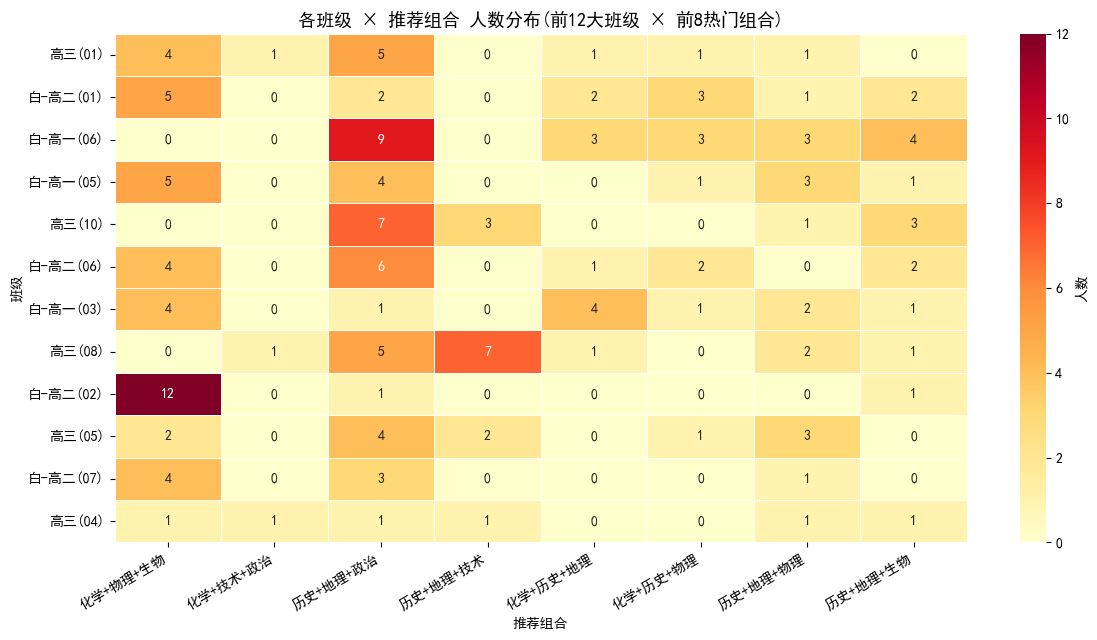
各班最主流推荐组合 (Top 5 班级):
高三(01): {‘历史+地理+政治’: 5, ‘化学+技术+物理’: 4, ‘化学+物理+生物’: 4}
白-高二(01): {‘化学+地理+物理’: 6, ‘化学+物理+生物’: 5, ‘地理+政治+生物’: 4}
白-高一(06): {‘历史+地理+政治’: 9, ‘历史+政治+生物’: 5, ‘历史+地理+生物’: 4}
白-高一(05): {‘化学+地理+生物’: 6, ‘化学+物理+生物’: 5, ‘化学+政治+生物’: 5}
高三(10): {‘历史+地理+政治’: 7, ‘地理+技术+政治’: 5, ‘技术+政治+生物’: 5}
七、推荐结果导出
# 标注是否在校(学生表只覆盖当前在校学生 1765 人;成绩表覆盖近 5 年共 3869 人)
recommend['in_school'] = recommend['bf_Name'].notna()
print(f"在校学生: {recommend['in_school'].sum()}, 历史毕业生: {(~recommend['in_school']).sum()}")
out_csv = os.path.join(OUT_DIR, 'student_recommendations.csv')
recommend_export = recommend[['mes_StudentID', 'in_school', 'bf_Name', 'bf_sex', 'cla_Name',
'top1', 'top1_score', 'top2', 'top2_score',
'top3', 'top3_score', 'combo']]
recommend_export.to_csv(out_csv, index=False, encoding='utf-8-sig')
print(f"已导出: {out_csv}")
print(f"共 {len(recommend_export)} 条推荐")
# 只看在校学生
print("\n=== 在校学生推荐 (前15) ===")
recommend_export[recommend_export['in_school']].head(15)
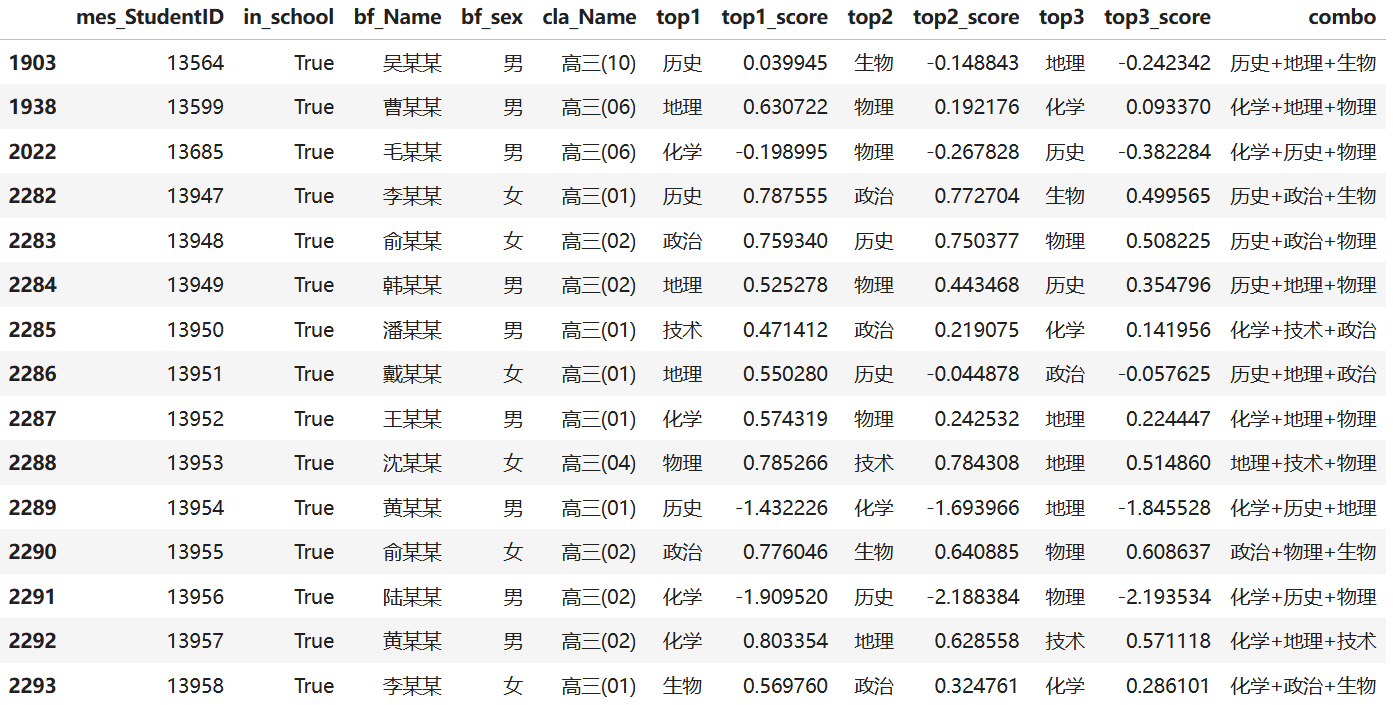
生成 student_recommendations.csv,在校学生推荐 (前15)包含字段分布是:
八. 结论与解读
推荐组合分布(图2)
- Top1 组合 「化学+物理+生物」:624 人推荐,占比最大
- Top2 「化学+技术+政治」:409 人
- Top3 「历史+地理+政治」:331 人
- 整体呈现"理科主力 + 文科主力 + 文理混合"三足鼎立的结构
学科相关性发现(图3)
七科 Z-score 两两正相关,相关系数集中在 0.41 ~ 0.71 区间,说明学生在七门学科上整体水平有一定共变。其中:
- 「化学-物理」相关 0.70、「化学-生物」相关 0.68 —— 理科群组强相关
- 「政治-历史」相关 0.71、「历史-地理」相关 0.64 —— 文科群组强相关
- 「技术」与其他科目相关性最低(0.41-0.56),是相对独立的能力维度
班级分流落地(图6)
- 白-高二(02) 12 人推荐「化学+物理+生物」,物化生重点班特征明显
- 白-高一(06) 9 人推荐「历史+地理+政治」,纯文班特征明显
- 部分混合班如高三(05) 各组合分布较均匀,说明该班生源构成多元
个体层面应用
- 图4 雷达图(示例:高三(08) 唐某某,七科 z-score 跨度 3.84)显示该学生历史 ≈+1.0、地理 ≈+0.7、生物 ≈+0.5 显著高于平均水平,物理与化学约 -0.5,技术则跌至 -2.7。综合打分推荐「历史+地理+政治」,与画像直观吻合
student_recommendations.csv给出每位学生 Top3 学科及对应得分,可作为一对一选科咨询的量化依据
方法论说明
综合得分公式 0.5×avg_z + 0.2×(1-avg_dengdi) + 0.2×trend - 0.1×std_z 中四个权重分别对应:水平、等第稳健性、进步趋势、稳定性。这四项可根据学校选拔倾向重新分配权重 —— 例如更看重稳定性的学校可把 std_z 权重从 -0.1 调到 -0.2,或将 trend 权重提升以更重视成长性

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)