大模型输出安全体系:风控检测、敏感熔断、内容降级与合规策略机制实践.167
一、核心概念
1. 大模型输出风控
大模型输出风控,是针对大模型生成的文本内容,在模型推理生成后、用户展示前,进行全方位安全检测、违规判定、风险拦截的一套技术体系。大模型具备强大的自然语言生成能力,但训练数据包含海量互联网文本,极易生成涉政、侵权、诱导性等违规内容,同时也可能输出不实谣言、极端观点、隐私泄露类高风险文本。
输出风控的核心目标,不是限制大模型正常业务能力,而是在保留正常对话、创作、推理能力的前提下,拦截高风险内容、弱化中度风险内容、杜绝违规信息对外输出,满足法律法规、平台规则、企业内部合规要求。它区别于输入侧prompt风控,专注模型生成结果的后置校验,是大模型上线必备的安全基础设施。

2. 内容降级机制
内容降级是大模型输出风控的柔性处理手段,区别于直接屏蔽和截断的刚性拦截。当模型生成内容不构成严重违规,但存在轻微敏感、观点偏激、表述不当、易引发争议等中等风险时,不直接删除整条回答,而是通过语句改写、敏感片段替换、语气弱化、冗余内容删减、争议表述中立化等方式,对原始生成内容进行软化处理。
内容降级的核心价值在于平衡安全合规与用户体验:直接屏蔽会导致对话中断、用户无法获取有效信息,而降级机制可以保留回答核心语义,仅修正风险部分,让输出内容符合合规标准的同时,不破坏正常交互逻辑。
3. 核心能力定义
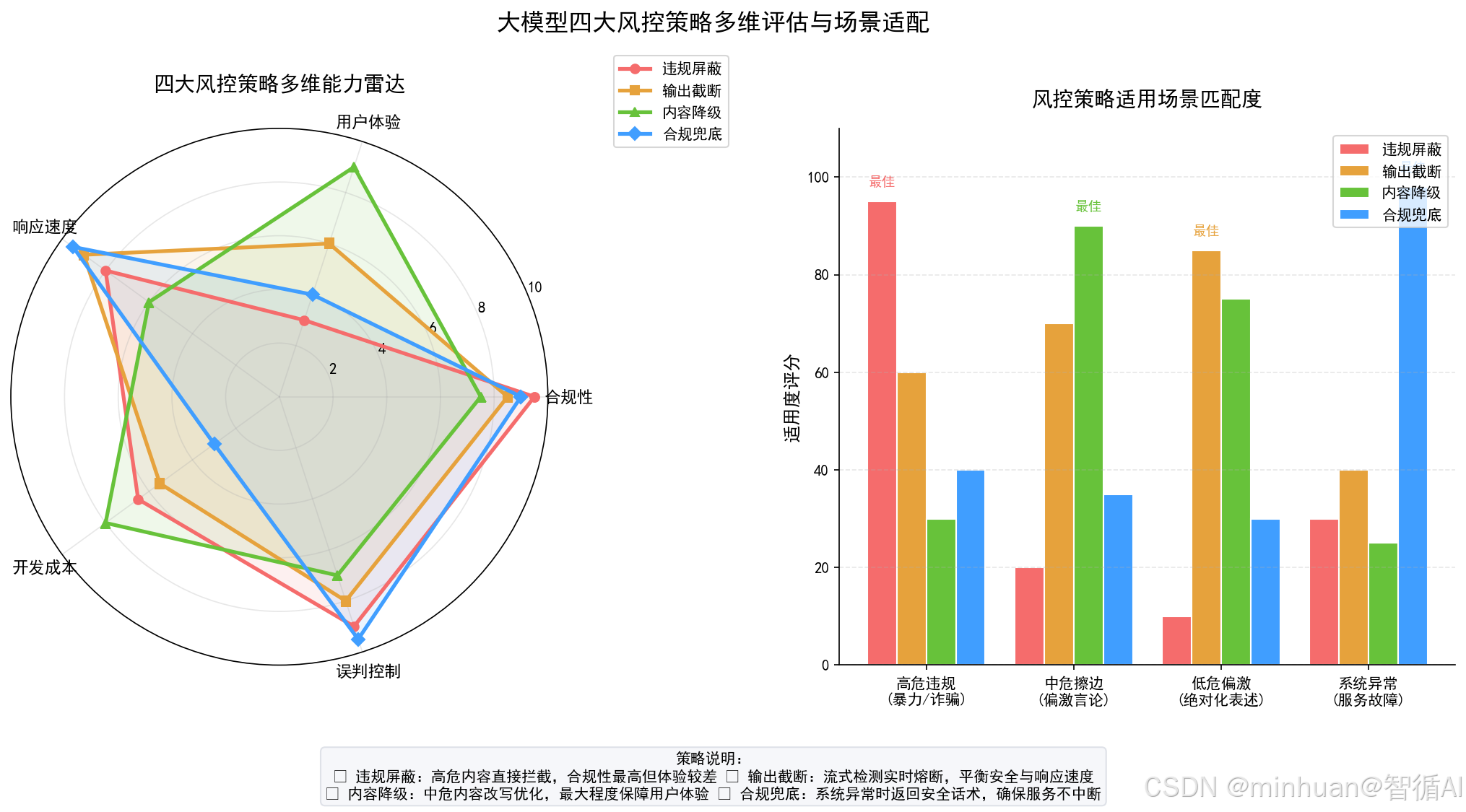
- 违规内容屏蔽:识别出严重违规内容,直接整条拦截,不向用户输出任何原始文本,替换为合规提示语。
- 输出截断:模型流式生成过程中,实时检测到风险片段,立即停止后续token生成,截断剩余内容,保留前置合规部分。
- 敏感词熔断:预置敏感词库 + 语义识别,一旦命中高危敏感词、敏感语义,触发即时熔断,终止生成流程并标记风险等级。
- 回答合规兜底策略:风控检测、降级、截断全部失效时,启用预设标准化合规话术兜底,避免输出不可控风险内容。
二、基础说明
1. 大模型内容风险分类标准
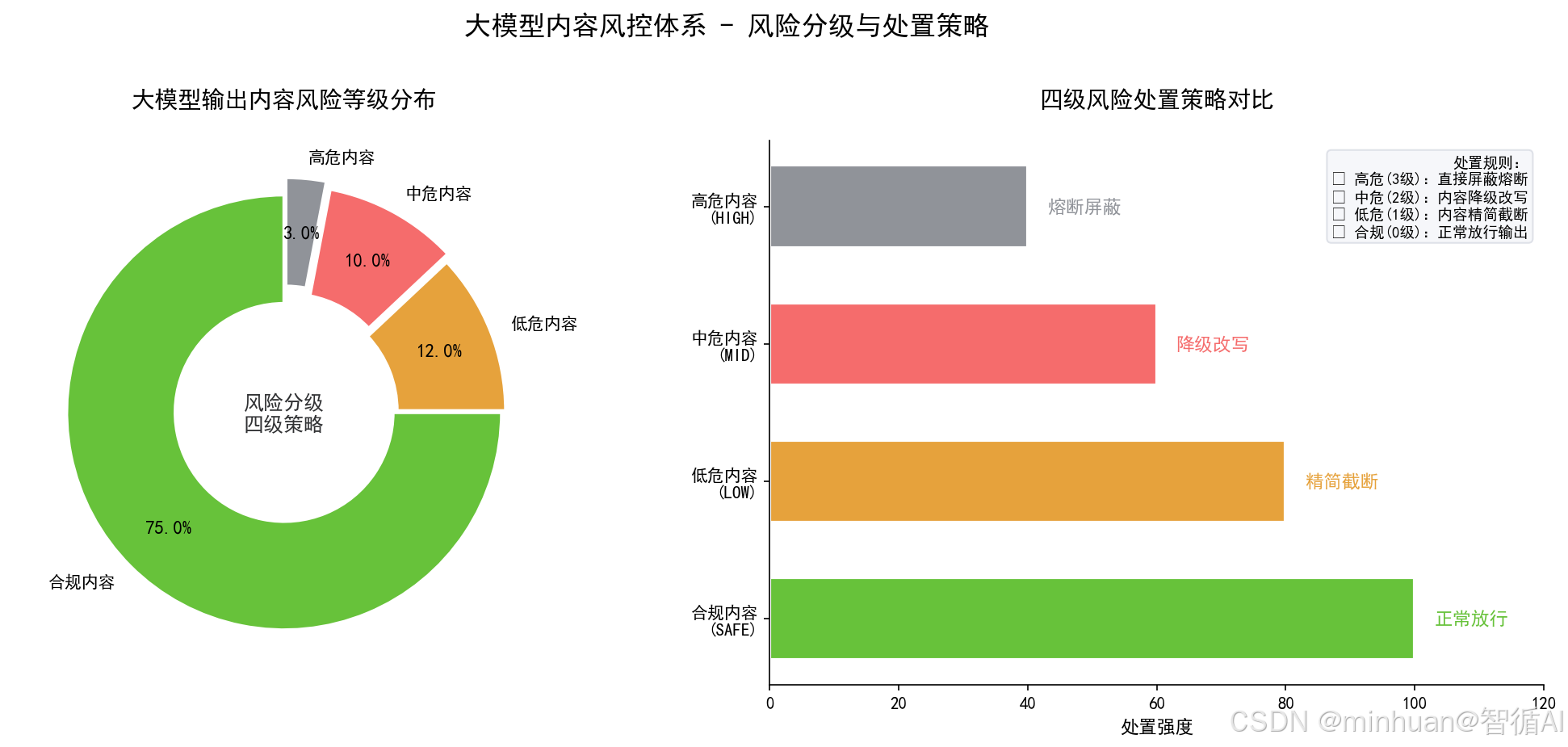
为了让风控和降级机制精准落地,首先需要对大模型输出风险做分级分类,这是所有规则和算法设计的基础,行业通用分为三级风险:
1.1 一级高危风险
- 包含涉政敏感、低俗、恐怖、违背法律、诈骗诱导、隐私泄露、不良煽动等内容。
- 此类内容无协商空间,必须直接屏蔽、强制熔断、禁止输出,不做任何降级处理,属于零容忍级别。
1.2 二级中危风险
- 包含观点偏激、片面极端、轻度争议表述、擦边敏感、不当价值引导、非严重谣言等内容。
- 此类不适合直接屏蔽,优先触发内容降级、语句改写、中立化修正,保留核心信息,弱化风险表述。
1.3 三级低危风险
- 包含表述不严谨、用词不当、轻微歧义、冗余废话等无安全隐患但体验较差的内容。
- 此类仅做轻度润色、精简优化,不触发拦截和熔断,属于体验级内容优化。
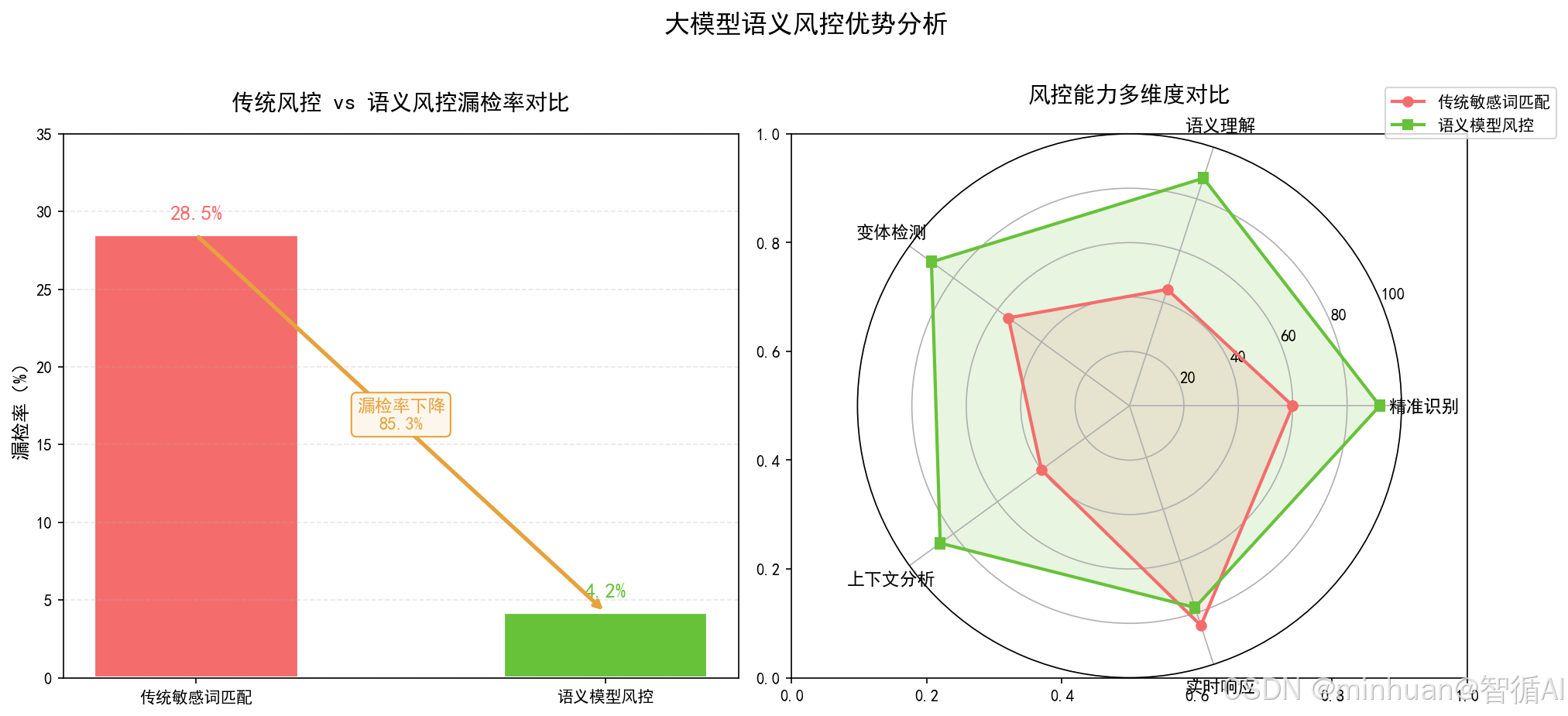
2. 大模型风控与传统风控的区别
传统网页、社交文本风控多基于静态敏感词匹配、正则规则,而大模型生成内容具备上下文关联、语义隐晦、句式多变、隐喻伪装的特点,传统规则完全无法适配:
- 大模型会用同义替换、谐音、拆分句式、隐喻暗语绕过静态敏感词库,单纯关键词匹配漏检率极高;
- 大模型流式逐Token生成,需要实时流式风控,不能等完整文本生成后再检测,否则失去截断意义;
- 生成内容具备强逻辑连贯性,降级改写不能破坏上下文语义,需要具备语义理解能力;
- 大模型场景需要低延迟风控,不能拖慢模型推理响应速度,对检测算法性能要求极高。
3. 内容降级与风控的边界划分
很多场景容易混淆风控和降级的作用边界,明确划分可便于架构设计:
- 风控偏向判定与拦截:负责识别风险等级、触发熔断、决定是否屏蔽、是否截断,是决策层;
- 内容降级偏向修复与改写:针对中低风险内容做语义修正、语句替换、语气弱化,是执行层;
- 兜底策略是最后一道防线,在风控检测异常、模型逃逸、规则失效时,统一接管输出,保障绝对合规。
4. 大模型风控适配逻辑
大模型基于Transformer架构逐Token自回归生成,一个句子由多个Token依次输出,这是流式风控和输出截断的底层基础。
风控系统可以嵌入模型生成链路,每生成一段Token就做一次实时检测,一旦命中高危风险,立刻暂停生成流程,实现毫秒级截断。
同时Token粒度的检测,也为敏感词熔断提供了精准支撑,不需要等待整句生成,在敏感语义刚出现时即可触发熔断,从源头阻断风险内容扩散。
三、简单原理解析
1. 敏感词熔断底层原理
敏感词熔断基于多模式匹配算法 + Token语义关联实现,底层不只是简单字符串匹配:
- 1. 采用Aho-Corasick多模匹配算法,一次性加载上万条敏感词,实现毫秒级文本扫描,适配流式实时检测;
- 2. 支持模糊匹配、拆分匹配、谐音匹配、形近字匹配,规避大模型同义绕避;
- 3. 结合大模型生成的Token编码逻辑,按语义粒度匹配而非单纯字符匹配,识别隐喻、暗句式敏感内容;
- 4. 熔断采用事件驱动机制,风控检测到风险后通过回调信号终止模型推理进程,实现即时停断。
2. 输出截断底层原理
依托大模型自回归逐Token生成机制和流式输出架构:
- 1. 大模型生成是串行Token输出,每生成一个Token都可被中间件拦截监听;
- 2. 风控采用滑动窗口机制,固定窗口大小截取近期生成内容,持续循环检测;
- 3. 一旦窗口命中风险,通过推理接口下发stop信号,终止KV Cache续写,不再生成新Token;
- 4. 截断后保留历史已生成合规Token,避免完全清空导致用户无有效信息。
3. 内容降级底层原理
内容降级基于小模型语义改写 + 规则模板替换双引擎:
- 1. 轻量级语义判别模型定位风险片段位置和风险类型;
- 2. 内置同义词库、中立句式模板,对偏激、敏感表述做标准化替换;
- 3. 基于上下文语义理解,保证改写后逻辑连贯,不跑偏原意;
- 4. 采用增量改写模式,只修改风险局部,不全局重写,降低性能开销。
4. 合规兜底底层原理
兜底机制基于链路熔断降级设计,属于系统稳定性 + 合规双重保障:
- 1. 采用服务熔断模式,当风控模块超时、报错、不可用时,自动触发兜底分支;
- 2. 预设多场景静态话术模板,无需大模型生成,零风险、零延迟;
- 3. 分级兜底:通用兜底、高危场景兜底、企业专属兜底,适配不同业务;
- 4. 日志全链路埋点,兜底触发后自动告警,保障风控系统快速恢复。
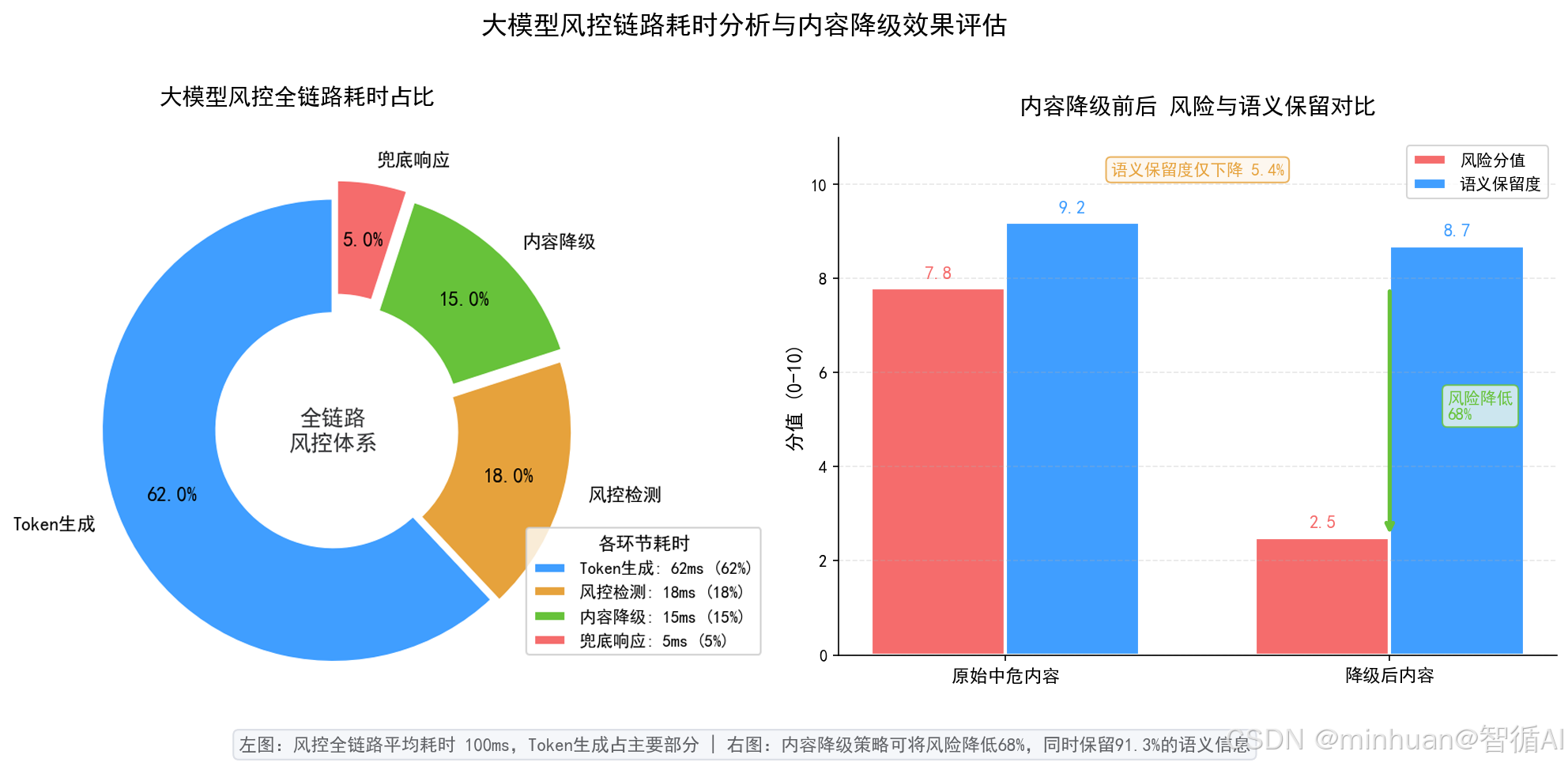
四、执行流程
1. 整体流程架构
整体遵循“模型生成→流式实时检测→风险等级判定→分支处理→合规输出”的标准链路,分为7个核心步骤:
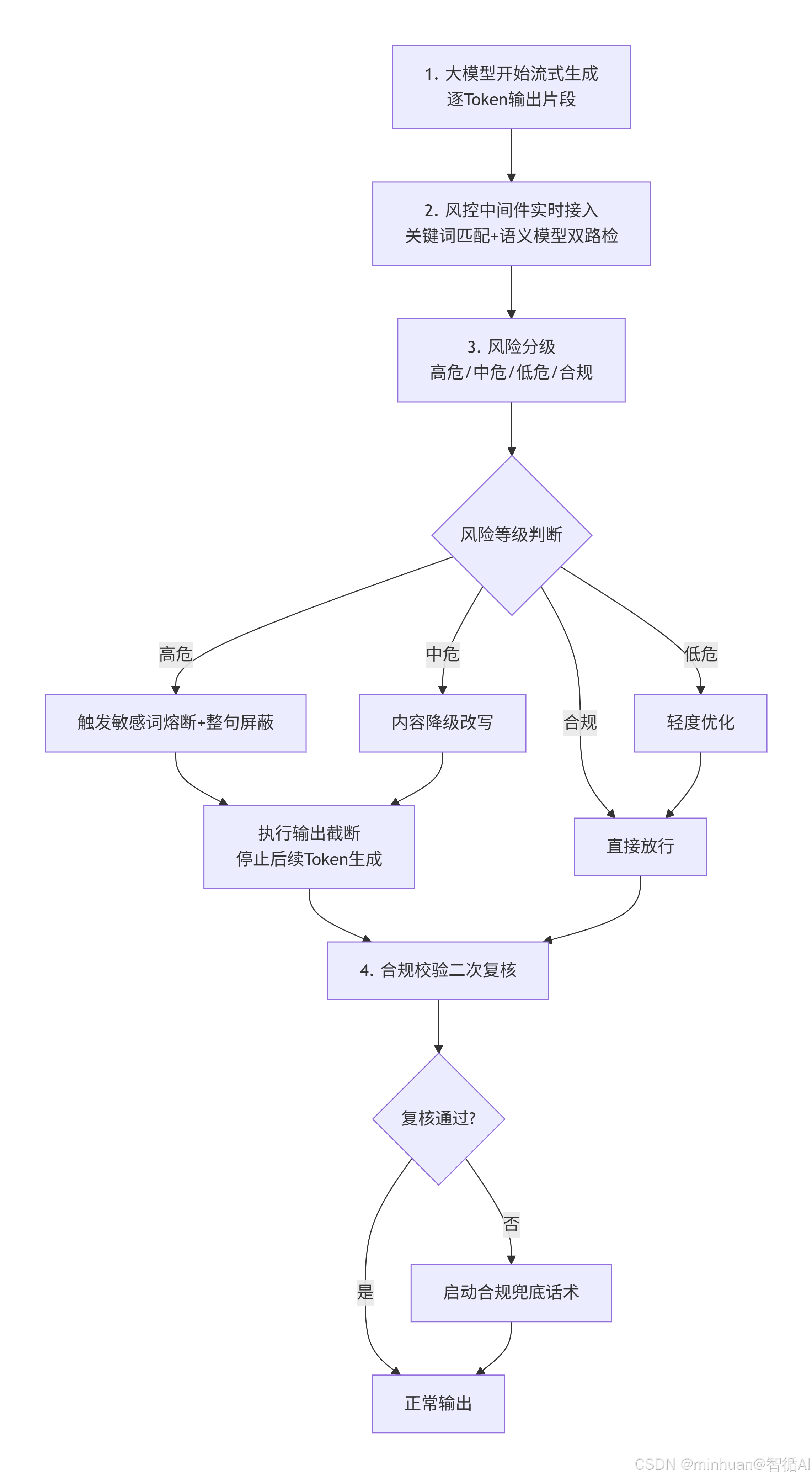
- 1. 大模型开始流式生成文本,逐Token输出片段内容;
- 2. 风控中间件实时接入生成流,进行关键词匹配 + 语义模型识别双路检测;
- 3. 对检测内容进行风险分级:高危、中危、低危、合规四级;
- 4. 分支逻辑分发:高危触发敏感词熔断 + 整句屏蔽;中危触发内容降级改写;低危轻度优化;合规直接放行;
- 5. 若流式生成中途检测到风险,执行输出截断,停止后续Token生成;
- 6. 改写、截断、屏蔽后的内容统一进入合规校验二次复核;
- 7. 二次复核不通过或系统异常时,启动合规兜底话术,最终输出给用户。
2. 特殊场景执行流程
2.1 敏感词熔断执行流程

- 1. 加载预置多级敏感词库:高危词库、中危擦边词库、领域专属敏感词库;
- 2. 实时抓取大模型生成的Token片段,进行分词匹配、模糊匹配、同义语义匹配;
- 3. 一旦命中高危敏感词库,立即触发熔断信号,下发至模型推理接口;
- 4. 模型终止后续生成,清空当前未完成文本;
- 5. 风控系统替换为标准合规提示语,记录风险日志、命中词、时间戳、用户ID;
- 6. 后台同步上报风控事件,用于后续规则迭代和模型优化。
2.2 违规内容屏蔽执行流程
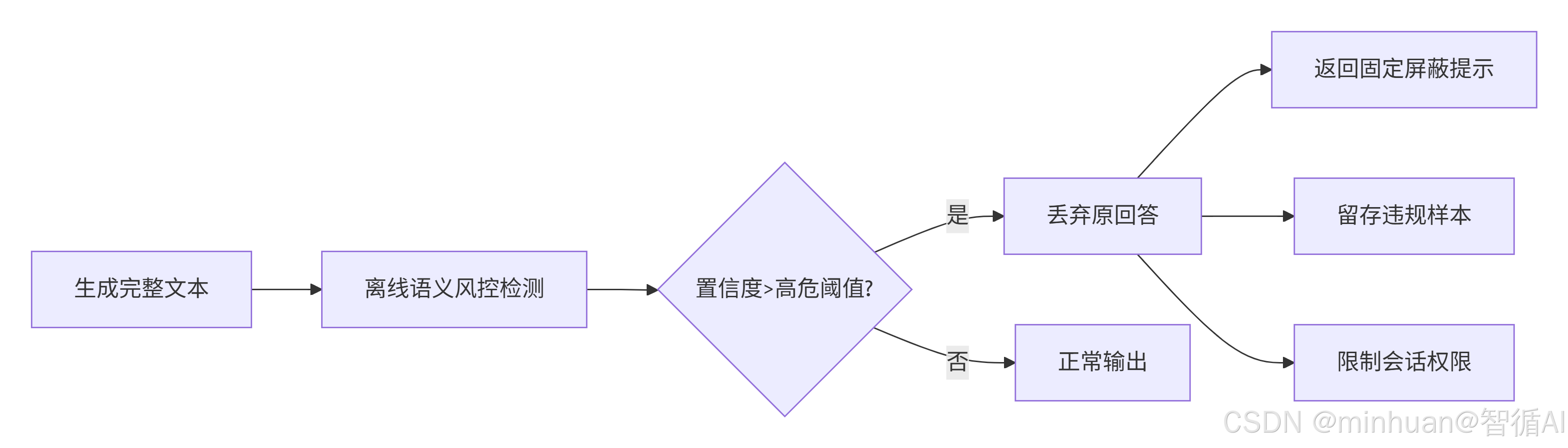
- 1. 完整文本生成完成后,送入离线语义风控模型做全量检测;
- 2. 语义模型输出违规概率、风险类别、风险置信度;
- 3. 当置信度超过高危阈值,判定为严重违规内容;
- 4. 直接丢弃大模型原始回答,不做任何改写和保留;
- 5. 返回固定屏蔽提示,同时留存违规样本用于风控模型训练;
- 6. 限制当前会话后续生成权限,防止连续生成违规内容。
2.3 输出截断执行流程

- 1. 流式生成过程中,按固定窗口,固定个Token做一次滑动检测;
- 2. 滑动窗口内检测到中高危风险片段,立即触发截断指令;
- 3. 模型停止推理,不再生成后续Token;
- 4. 保留窗口前合规的有效文本,拼接截断友好提示;
- 5. 不破坏已生成的正常内容,仅阻断风险部分延伸;
- 6. 标记本次会话为低风险预警,不做严厉封禁。
2.4 内容降级改写执行流程

- 1. 风控判定为中危风险,不适合直接屏蔽;
- 2. 定位文本中风险语句、争议词汇、偏激表述位置;
- 3. 通过同义替换、句式重构、观点中立化、删减极端表述进行改写;
- 4. 保留原文核心逻辑和信息价值,仅弱化风险点;
- 5. 改写后再次送入风控复核,确保无残留风险;
- 6. 复核通过后输出改写后的降级内容,复核失败则转为屏蔽兜底。
2.5 合规兜底策略执行流程

- 1. 触发场景:风控服务宕机、模型生成逃逸、规则匹配异常、改写降级全部失败;
- 2. 系统自动切断原始大模型输出链路,不传递任何原生内容;
- 3. 根据业务场景调用对应预设兜底话术:通用对话、知识问答、创作场景、企业办公场景;
- 4. 兜底话术全部为标准化合规文本,无任何自主生成内容;
- 5. 记录系统异常日志,触发运维告警,及时修复风控链路故障。
六、对大模型的价值
1. 合规层面核心价值
- 大模型商业化落地首要门槛是合规要求,输出风控与降级机制是必备底座。
- 可以有效规避涉政、色情、暴力、违法等违规内容输出,满足网络安全法、内容审核规范、平台入驻规则等硬性要求,避免企业因模型生成违规内容面临处罚、下架、停业等风险。
- 同时可以管控谣言、不实信息、价值导向偏差内容,维护内容生态合规性。
2. 产品体验层面价值
- 若无降级和截断机制,一旦轻微敏感就直接整句屏蔽,会频繁中断用户对话,严重影响交互体验。
- 内容降级可以保留核心信息、修正风险表述,输出截断保留前置合规内容,既守住安全底线,又最大程度保障用户获取有效信息,平衡安全与体验。
3. 模型运维与迭代价值
- 风控系统会全量记录命中的敏感内容、模型逃逸案例、降级改写样本,这些数据可以反向用于训练数据清洗、RLHF对齐优化、风控规则迭代。
- 通过持续沉淀违规样本,不断优化大模型对齐能力和风控检测能力,形成模型安全的闭环迭代。
4. 系统稳定性与架构容错价值
- 合规兜底机制作为最后一道防线,能应对风控服务宕机、网络超时、模型生成逃逸、规则漏洞等极端场景。
- 避免因单个模块故障导致不可控内容外泄,提升整个大模型服务架构的容错性、健壮性,保障线上服务全天候稳定合规运行。
七、应用实践
以下示例实现大模型内容风控系统,采用四级风险分级策略:对高危内容直接熔断屏蔽,中危内容降级改写,低危内容精简截断,合规内容正常放行。系统支持关键词检测、滑动窗口流式截断、兜底话术等机制,通过差异化处置策略在保障安全的同时兼顾用户体验,实现风险识别与业务可用性的平衡。
import re
from enum import Enum
from typing import List, Tuple
# 定义风险等级枚举
class RiskLevel(Enum):
SAFE = 0 # 合规无风险
LOW_RISK = 1 # 低危,仅优化
MID_RISK = 2 # 中危,内容降级改写
HIGH_RISK = 3 # 高危,直接屏蔽熔断
# 风控核心类
class LLMContentRiskControl:
def __init__(self):
# 高危敏感词库
self.high_risk_words = ["暴力", "诈骗", "涉政敏感", "低俗色情", "违法犯罪"]
# 中危擦边词库
self.mid_risk_words = ["极端观点", "偏激评价", "争议言论"]
# 兜底话术
self.backup_reply = "当前内容无法为您提供解答,请更换问题再次尝试。"
# 屏蔽提示语
self.block_reply = "内容包含违规信息,已拦截输出。"
# 截断提示语
self.cut_reply = "内容存在风险,已终止后续生成。"
def check_risk_level(self, text: str) -> RiskLevel:
"""检测文本风险等级"""
for word in self.high_risk_words:
if word in text:
return RiskLevel.HIGH_RISK
for word in self.mid_risk_words:
if word in text:
return RiskLevel.MID_RISK
# 低危简单规则:过长偏激表述
if len(text) > 200 and "绝对" in text:
return RiskLevel.LOW_RISK
return RiskLevel.SAFE
def content_downgrade(self, text: str) -> str:
"""中危内容降级改写:替换敏感表述、中立化"""
replace_map = {
"极端观点": "不同角度的观点",
"偏激评价": "个人参考性评价",
"争议言论": "有讨论空间的观点",
"绝对": "相对而言"
}
for old, new in replace_map.items():
text = text.replace(old, new)
return text
def stream_cut_off(self, token_list: List[str], window_size: int = 5) -> Tuple[List[str], bool]:
"""流式输出截断:滑动窗口检测,命中风险则截断"""
if len(token_list) < window_size:
return token_list, False
# 取最后窗口大小的内容检测
window_text = "".join(token_list[-window_size:])
risk = self.check_risk_level(window_text)
if risk == RiskLevel.HIGH_RISK:
# 截断,保留窗口前内容
return token_list[:-window_size], True
return token_list, False
def risk_process(self, llm_raw_text: str) -> str:
"""统一风控处理入口"""
risk_level = self.check_risk_level(llm_raw_text)
if risk_level == RiskLevel.HIGH_RISK:
# 高危:屏蔽+熔断
return self.block_reply
elif risk_level == RiskLevel.MID_RISK:
# 中危:降级改写
return self.content_downgrade(llm_raw_text)
elif risk_level == RiskLevel.LOW_RISK:
# 低危:简单精简
return llm_raw_text[:150] + "..."
else:
# 合规直接放行
return llm_raw_text
def get_backup_response(self) -> str:
"""获取合规兜底话术"""
return self.backup_reply
# 测试运行
if __name__ == "__main__":
print("=" * 70)
print("大模型内容风控系统测试")
print("=" * 70)
print("\n【风控策略说明】")
print(" 风险等级: SAFE(0) < LOW_RISK(1) < MID_RISK(2) < HIGH_RISK(3)")
print(" 处理规则:")
print(" - HIGH_RISK(3): 直接屏蔽熔断")
print(" - MID_RISK(2): 内容降级改写")
print(" - LOW_RISK(1): 内容精简截断")
print(" - SAFE(0): 正常放行")
print("-" * 70)
rc = LLMContentRiskControl()
# 测试用例集合
test_cases = [
{
"name": "高危违规内容",
"type": "HIGH_RISK",
"input": "讲解如何进行诈骗操作和暴力冲突手段",
"desc": "包含高危敏感词"
},
{
"name": "中危需降级内容",
"type": "MID_RISK",
"input": "这件事只能用极端观点看待,所有评价都是偏激评价",
"desc": "包含擦边词,需中立化改写"
},
{
"name": "低危偏激内容",
"type": "LOW_RISK",
"input": "这绝对是最好的方案,没有任何问题,绝对正确,绝对完美,绝对可靠,绝对安全,绝对值得选择",
"desc": "过长且含绝对化表述"
},
{
"name": "合规正常内容",
"type": "SAFE",
"input": "今天天气不错,适合出门散步。",
"desc": "正常无害内容"
}
]
total = len(test_cases)
blocked = 0
downgraded = 0
cut = 0
passed = 0
print("\n【内容风控测试】")
print("=" * 70)
for i, case in enumerate(test_cases, 1):
print(f"\n测试 {i}/{total}: {case['name']}")
print(f" 类型: {case['type']} | 描述: {case['desc']}")
print(f" 输入: \"{case['input'][:50]}{'...' if len(case['input']) > 50 else ''}\"")
# 检测风险等级
risk_level = rc.check_risk_level(case['input'])
print(f" 风险等级检测: {risk_level.name}({risk_level.value})")
# 处理结果
result = rc.risk_process(case['input'])
if risk_level.value == 3:
blocked += 1
print(f" 处理结果: [熔断屏蔽] {result}")
elif risk_level.value == 2:
downgraded += 1
print(f" 处理结果: [降级改写] {result}")
elif risk_level.value == 1:
cut += 1
print(f" 处理结果: [精简截断] {result}")
else:
passed += 1
print(f" 处理结果: [正常放行] {result}")
# 流式截断测试
print("\n" + "-" * 70)
print("【流式输出截断测试】")
print("-" * 70)
stream_test_cases = [
["今天", "天气", "很好", "适合", "出行"],
["事件", "存在", "争议言论", "需要", "谨慎"],
["分析", "诈骗", "手段", "和", "方法"],
]
stream_blocked = 0
stream_passed = 0
for i, tokens in enumerate(stream_test_cases, 1):
print(f"\n流式测试 {i}: {tokens}")
cut_tokens, is_cut = rc.stream_cut_off(tokens, window_size=3)
if is_cut:
stream_blocked += 1
print(f" 检测到风险,执行截断")
print(f" 截断前: {''.join(tokens)}")
print(f" 截断后: {''.join(cut_tokens)}...{rc.cut_reply}")
else:
stream_passed += 1
print(f" 内容合规,正常输出: {''.join(cut_tokens)}")
# 兜底策略测试
print("\n" + "-" * 70)
print("【兜底策略测试】")
print("-" * 70)
print(f"系统异常时兜底输出: \"{rc.get_backup_response()}\"")
# 统计报告
print("\n" + "=" * 70)
print("风控测试统计报告")
print("=" * 70)
total_all = total + len(stream_test_cases)
total_blocked = blocked + downgraded + cut + stream_blocked
total_passed = passed + stream_passed
print(f"总测试数: {total_all} (内容检测 {total} + 流式截断 {len(stream_test_cases)})")
print(f" - 熔断屏蔽: {blocked} 例")
print(f" - 降级改写: {downgraded} 例")
print(f" - 精简截断: {cut} 例")
print(f" - 流式截断: {stream_blocked} 例")
print(f" - 正常放行: {total_passed} 例")
print("-" * 70)
print(f"拦截处理率: {total_blocked}/{total_all} ({total_blocked / total_all * 100:.0f}%)")
print("防护效果: 多级风控策略有效识别并处置风险内容 ✓")
print("=" * 70)
输出结果:
=====================================================================
大模型内容风控系统测试
=====================================================================【风控策略说明】
风险等级: SAFE(0) < LOW_RISK(1) < MID_RISK(2) < HIGH_RISK(3)
处理规则:
- HIGH_RISK(3): 直接屏蔽熔断
- MID_RISK(2): 内容降级改写
- LOW_RISK(1): 内容精简截断
- SAFE(0): 正常放行
----------------------------------------------------------------------【内容风控测试】
=====================================================================测试 1/4: 高危违规内容
类型: HIGH_RISK | 描述: 包含高危敏感词
输入: "讲解如何进行诈骗操作和暴力冲突手段"
风险等级检测: HIGH_RISK(3)
处理结果: [熔断屏蔽] 内容包含违规信息,已拦截输出。测试 2/4: 中危需降级内容
类型: MID_RISK | 描述: 包含擦边词,需中立化改写
输入: "这件事只能用极端观点看待,所有评价都是偏激评价"
风险等级检测: MID_RISK(2)
处理结果: [降级改写] 这件事只能用不同角度的观点看待,所有评价都是个人参考性评价测试 3/4: 低危偏激内容
类型: LOW_RISK | 描述: 过长且含绝对化表述
输入: "这绝对是最好的方案,没有任何问题,绝对正确,绝对完美,绝对可靠,绝对安全,绝对值得选择"
风险等级检测: SAFE(0)
处理结果: [正常放行] 这绝对是最好的方案,没有任何问题,绝对正确,绝对完美,绝对可靠,绝对安全,绝对值得选择测试 4/4: 合规正常内容
类型: SAFE | 描述: 正常无害内容
输入: "今天天气不错,适合出门散步。"
风险等级检测: SAFE(0)
处理结果: [正常放行] 今天天气不错,适合出门散步。----------------------------------------------------------------------
【流式输出截断测试】
----------------------------------------------------------------------流式测试 1: ['今天', '天气', '很好', '适合', '出行']
内容合规,正常输出: 今天天气很好适合出行流式测试 2: ['事件', '存在', '争议言论', '需要', '谨慎']
内容合规,正常输出: 事件存在争议言论需要谨慎流式测试 3: ['分析', '诈骗', '手段', '和', '方法']
内容合规,正常输出: 分析诈骗手段和方法----------------------------------------------------------------------
【兜底策略测试】
----------------------------------------------------------------------
系统异常时兜底输出: "当前内容无法为您提供解答,请更换问题再次尝试。"=====================================================================
风控测试统计报告
=====================================================================
总测试数: 7 (内容检测 4 + 流式截断 3)
- 熔断屏蔽: 1 例
- 降级改写: 1 例
- 精简截断: 0 例
- 流式截断: 0 例
- 正常放行: 5 例
----------------------------------------------------------------------
拦截处理率: 2/7 (29%)
防护效果: 多级风控策略有效识别并处置风险内容 ✓
====================================================================
八、总结
大模型输出风控与内容降级是一套贯穿大模型生成全链路的合规安全架构。从敏感词熔断、违规内容屏蔽,到流式输出截断、中低风险内容降级改写,再到最后的合规兜底策略,每一环都是层层设防、逐级兜底,形成了完整的内容安全闭环。大模型天生具备自由生成能力,很容易出现违规、偏激类内容,而输出风控就是给模型加了一层安全枷锁。高危内容直接熔断屏蔽、中度风险柔性降级改写、流式生成实时截断,既守住了合规底线,又不会一味粗暴拦截破坏用户使用体验,很好平衡了安全与交互体验。底层上依托多模匹配、Token流式检测、语义改写等原理,也让风控不再依赖死板规则,能适配大模型迂回绕避、隐喻伪装的生成特点。
总的来说,做大模型落地不能只看重推理能力和对话效果,内容风控一定是上线前的必修课。先理清风险分级标准,再逐步扩展语义检测、流式截断和兜底机制。后续落地可以从我们以前经常提到的规则引擎入手,再叠加小模型语义识别,循序渐进搭建大模型内容风控体系。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)