从 ToT 到 PRM:Agent 的规划是如何被“训练”出来的?
前言:在上一篇《记忆深挖篇》里,我们给 Agent 装上了一个可学习的“海马体”,让它学会了动态检索、智能遗忘,甚至把高频知识直接“长”进了 LoRA 权重里。
现在,弹药库已经就绪。但问题是:面对一个复杂任务,Agent 知道什么时候该开枪,什么时候该撤退,什么时候该扔手雷吗?
如果只用 Prompt(比如那句万能的“请你一步一步想”),LLM 本质上在做单步贪心——它只管顺着概率预测下一个 Token,根本不在乎这步是不是掉进了死胡同。
今天这篇终章,我们把目光聚焦在 Agent 的“灵魂”——规划模块。看看我们如何用深度学习的老本行(搜索算法、价值网络、分层强化学习),把“拍脑袋做计划”变成一门硬核的算法艺术。
01. 痛点:为什么大模型天生不擅长“规划”?
在 CNN 时代,我们做图像分割,网络输出一张 Mask,哪怕中间有个洞,我们用个 CRF 后处理或者简单的形态学操作就能补上。因为图像是静态的空间分布。
但规划面对的是动态的决策树。假设你要写一个复杂的爬虫,第 2 步有 3 种写法,第 3 步又有 4 种工具可以调,组合起来是一棵指数级爆炸的树。
如果你只扔给 LLM 一个 Prompt 让它“做计划”,它在生成第 2 步时,根本没有“全局视野”。它不知道第 5 步会因为这第 2 步的选择而彻底卡死。
这就像下围棋只看眼前一步,必然被 AlphaGo 戏耍。
AlphaGo 是怎么做的?策略网络负责发散(生成候选),价值网络负责评估(打分剪枝),蒙特卡洛树搜索负责统筹。
Agent 的规划,也必须走这条路。
02. 第一层深挖:学会评判(引入过程奖励模型 PRM)
我们要让 Agent 会做计划,第一步不是教它“怎么计划”,而是教它“看懂什么是好计划”。
在强化学习里,这叫 Value Network(价值网络)。在当前的 Agent 领域,它有一个更具体的名字:Process Reward Model (PRM,过程奖励模型)。
以前我们只有 ORM(结果奖励):代码跑通了给 1 分,报错了给 0 分。这没法做梯度反传,因为你不知道是哪一行代码写错了。
PRM 的科学解法:对轨迹的每一步打分。
- 输入:当前任务目标 + 历史步骤 + 当前刚刚生成的这一步规划/代码。
- 输出:一个 0~1 的标量分数,代表“这一步走在正确道路上的概率”。
有了 PRM 之后,你再看之前高大上的 ToT(思维树)框架,就会发现它的核心瞬间被替换了:
- 以前:LLM 生成 3 条分支 → 让另一个大 LLM 用 Prompt 去评价哪条好(又慢又贵,而且经常给面子打高分)。
- 现在:LLM 生成 3 条分支 → 扔给 8B 大小的 PRM 模型打分 → 砍掉低分分支,顺着高分分支继续搜索。
这就是可学习的规划! PRM 就是你训练出来的“裁判”。你用大量成功/失败的轨迹数据(甚至可以用强规则的代码沙箱自动标注)去回归这个分数,它就学会了什么叫“好棋”。
03. 第二层深挖:学会转向(可学习的重规划策略)
有了 PRM 打分,下一个难题是:南墙撞到什么程度,该回头?
写死规则的话,你可能会写:if 连续 2 步 PRM < 0.3,触发重规划。
但这太生硬了。有时候即使当前步骤分数低,但再坚持一步就打通了(比如调试代码时,加一行 print 看起来没用,但很关键)。
在 DL 工程师眼里,“要不要重规划”本身就是一个强化学习的动作。
我们可以设计一个轻量级的策略网络 ![]() :
:
- State:当前环境状态 + 过去 3 步的 PRM 分数走势。
- 动作空间
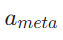 :
:
CONTINUE(硬着头皮继续执行当前计划)REFINE(局部修正,比如改改工具参数,不推翻大方向)REPLAN(彻底推倒重来,回到记忆里找新方案)
通过在环境中做 RL 训练,这个策略网络会学到一个非常微妙的“直觉”:它知道什么时候该“死磕”,什么时候该“止损”。这种动态的控制流,是任何静态 Prompt 都写不出来的。
04. 第三层深挖:学会封装(技能库与子目标抽象)
人类厉害的地方在于触类旁通。你学会了骑自行车(底层动作序列),下次骑摩托车时,你不需要重新学习“如何保持平衡”,你可以直接把“保持平衡”当成一个高层动作来调用。
Agent 能不能把成功的经验“封装”起来?
这就涉及到了分层强化学习中的经典概念:Options(选项框架)。
在 Agent 架构里,它的实现方式是动态构建“技能库”:
- 轨迹抽象:Agent 成功完成了一个“用 Selenium 抓取动态网页”的任务,产生了一条长达 20 步的 Action 轨迹。
- LLM 提炼:让 LLM 把这 20 步压缩成一条高层技能描述:“
Skill_Selenium_Scraper(target_url)”。 - 存入记忆:这个技能描述,被作为最高等级的“语义记忆”,存入我们上一篇讲到的长期记忆库中。
下一次 Agent 面对新任务时,它的规划空间发生了本质改变:
它不再是“步骤 1:打开浏览器 → 步骤 2:输入网址…”,而是直接在高层规划:“步骤 1:调用 Skill_Selenium_Scraper → 步骤 2:调用 Skill_Data_Cleaner”。
这不就是把大模型微调时的“算子融合”思想,搬到了系统规划层吗? 把高频的底层子图,融合成了一个高层节点,极大降低了搜索空间的复杂度。
05. 终局融合:规划与记忆的“双螺旋”进化
如果你把前三篇的内容连起来看,你会发现一个极其惊艳的系统级闭环。这不再是什么“LangChain 调包”,而是一个真正具备“自我进化”能力的数字生命雏形。
我用一张最终的架构图来展示这种“双螺旋”结构(请仔细看数据流的箭头):
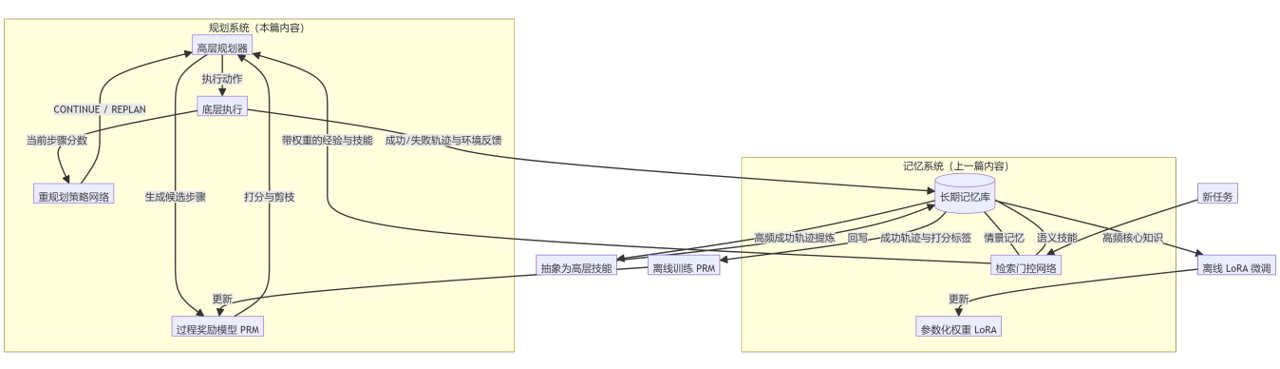
这张图是整个系列最核心的精华:
- 记忆反哺规划:规划器不再裸奔,它通过“门控网络”动态调用过去的经验和抽象出来的“高层技能”。
- 规划沉淀记忆:规划产生的每一条执行轨迹,无论是成功还是失败,都流入了记忆库。
- 闭环形成智能:
- 记忆库里积累的“轨迹 + 结果”,变成了离线训练 PRM(裁判) 的完美数据集。
- 记忆库里被高频调用的“底层动作”,被抽象成了高层技能,降低了未来的规划难度。
- 记忆库里最核心的知识,被内化成了 LoRA 权重,实现了物理级别的加速。
规划让记忆有了用武之地,记忆让规划变得越来越聪明。它们像 DNA 的双螺旋一样,在任务的循环中交替上升,完成了一个不需要人类干预的“自我进化”过程。
06. 全系列结语:从“调参侠”到“造物主”
写到这里,这个系列的四篇博客就正式结束了。我们走过了:
- 概念篇:把行话翻译成了直觉。
- 架构篇:把零件拼成了闭环。
- 记忆深挖篇:把外部存储变成了可学习的门控与权重。
- 规划深挖篇:把瞎猜变成了带 PRM 评估的搜索与技能抽象。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)