Agent 记忆不只是一个向量库:检索门控、遗忘策略与参数化记忆
前言:在上一篇《架构篇》里,我们跑通了一个“检索记忆 →→ 制定计划 →→ 执行报错 →→ 反思写入”的完美闭环。但作为一名曾经的“炼丹师”,当我看到那个闭环时,我的雷达疯狂报警——这里面硬编码的味道太重了。
比如,在检索记忆时,系统凭什么断定“相关性”占 50%,“时间近”占 30%?在写入记忆时,系统凭什么决定“所有报错都要存下来”?这种靠工程师拍脑袋写死的
if-else和权重系数,在 CNN 时代我们就知道是不可靠的。今天这篇《记忆深挖篇》,我们把 Prompt 和中间件抛到脑后,下沉到算法层,死磕一个问题:如何把 Agent 的记忆系统,变成一个“可学习”的网络层?
01. 痛点:传统 RAG 检索为什么这么“傻”?
在斯坦福那个著名的“小镇实验”里,Agent 检索记忆用了一个极其经典的公式:
Score=α×相关性+β×时效性+γ×重要性
很多工程师做 RAG 时也是这么干的:算一下向量余弦相似度(相关性),加个时间衰减因子(时效性),最后按总分排序,取 Top-K 塞进 Prompt。
这在算法工程师看来,简直是“手动设计特征”的远古操作。
假设用户问了两句话:
- *“我昨天布置了什么任务?”* (需要极高的时效性 β)
- *“这个 Kubernetes OOM 报错怎么修?”* (需要极高的相关性 α 和重要性γ)
如果 α,β,γ 是写死的,系统根本无法根据不同的 Query 动态调整注意力。这就像你做图像分类时,不管图片里是猫是狗,卷积核的权重永远不变一样荒谬。
02. 第一层深挖:可学习的检索(MoE 门控机制)
既然写死不行,那就让它学。在 DL 工具箱里,处理“根据不同输入动态分配权重”最成熟的组件是什么?Attention 机制,或者更轻量的 MoE(专家混合)门控。
前沿的 Agent 记忆研究,正在把检索打分变成一个极轻量的门控网络:
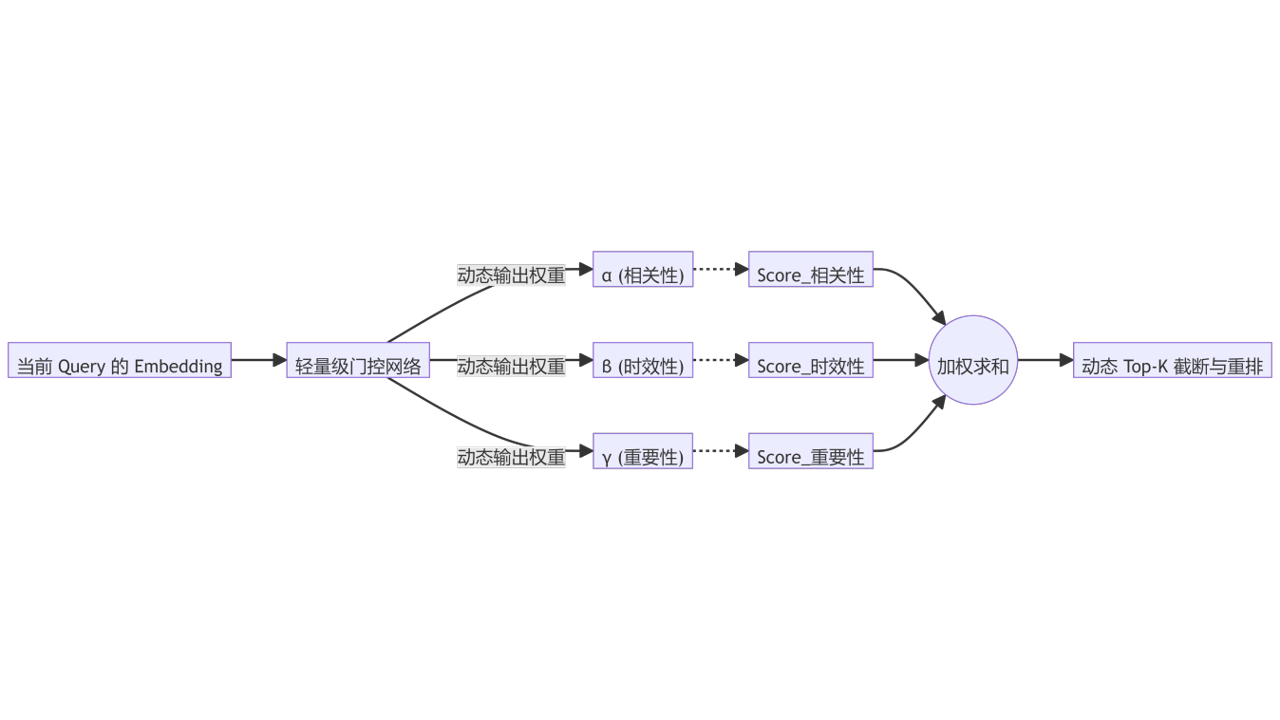
怎么训练这个门控网络?不需要从头搞 RL,用你手头的日志就行:
你在现在的系统里记录下 [Query, 召回的 Top-10 记忆, 最终被 LLM 采用并导致任务成功的记忆]。这就自动构成了偏好数据。被采用的那条是 Positive,没被采用的类似的是 Negative。
直接用 DPO(直接偏好优化)或者简单的对比学习,去训练这个门控网络。它很快就能学会:看到“昨天”这种词,就把 β 的输出拉到 0.9;看到“报错”这种词,就把 α 拉满。
03. 第二层深挖:可学习的写入与遗忘(策略驱动的断舍离)
人类大脑最牛逼的不是记住了什么,而是忘记了什么。
如果一个 Agent 跑了一个月,向量库里塞了几百万条“成功执行 print(‘hello’)”的无聊日志,它的检索必然被噪声淹没,引发严重的幻觉。
传统的记忆写入是“来者不拒”。我们需要一个写入/遗忘策略网络:
- 输入:新产生的事件 + 当前任务状态。
- 输出:动作空间 ∈
[直接丢弃, 压缩成一句话再存, 原样存入, 覆盖旧相似记忆]。
这完全就是一个强化学习(RL)问题!
- State:当前记忆库的饱和度、新事件的类型。
- Action:丢弃 / 压缩 / 存储。
- Reward:如果保留这条记忆,在未来 5 轮任务里让 Agent 避开了坑,给正奖励;如果这条记忆导致了检索变慢或引发幻觉,给负奖励。
经过 RL 训练后,策略网络会展现出非常惊艳的“直觉”:它会学到“包含 Traceback 栈且最终被修复的日志”价值极高,必须原样保存;而“连续 100 次成功调用了天气 API 的日志”价值极低,应该直接丢弃或压缩成一条规则。
04. 终极深挖:参数化记忆(把经验“长”进脑子里)
上面两步,我们还是在“外部记忆库”(向量库)里做文章。但只要知识还在外部,就永远逃不开两个物理限制:检索延迟 和 上下文窗口长度。
你有没有想过,人类是怎么处理高频知识的?你不需要每次想打字时,去大脑档案室里检索“键盘上 A 键在哪”,你已经把它内化成了肌肉记忆(神经突触的物理连接)。
在 Agent 领域,这就叫参数化记忆。
前沿研究正在探索一种极其优雅的架构:将外部记忆“烘焙”进 LLM 的权重里。
具体怎么做?用最熟悉的 LoRA(低秩微调)。

工作流如下:
- Agent 白天在业务里跑,把高频命中且验证有效的知识(比如“公司内部某 API 的标准调用格式”)沉淀下来。
- 晚上跑一个离线脚本,用这批高质量知识作为 SFT 数据,对 LLM 跑一次极小规模的 LoRA 训练。
- 第二天上线,当 Agent 再遇到这个问题时,它不需要去查向量库了,直接通过前向传播y=f(x))就能瞬间输出正确答案。
这完成了一次史诗级的认知跃迁:从“情景记忆”彻底跨越到了“语义记忆”。
作为 DL 工程师,你太熟悉这意味着什么了:只要算力够,我们可以定期把“外部知识”蒸馏进“模型权重”,让 RAG 变成发现知识的雷达,让 LoRA 成为储存知识的硬盘。
05. 小结与预告
在这篇深挖里,我们彻底撕掉了记忆系统“非黑即白”的伪装:
- 它的检索不应该是静态公式,而应该是可学习的门控;
- 它的存储不应该来者不拒,而应该是策略驱动的断舍离;
- 它的终极形态不应该依赖外部数据库,而应该是固化为模型权重的参数记忆。
当记忆系统从“死板的仓库”变成“可进化的神经网络”时,它就能为整个系统提供极其强大的经验支撑。
那么问题来了:当记忆系统准备好了完美的“经验弹药”,规划模块能接得住吗? 规划如何利用这些记忆?规划过程本身能不能也被“训练”出来?
在下一篇,也是本系列的终章《规划深挖篇》中,我们将直面 Agent 的“灵魂”——看看过程奖励模型(PRM)、思维树搜索以及反思机制,是如何把“拍脑袋做计划”变成一门硬核的算法艺术的。我们下篇见!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)