ReAct:让AI既能“深思熟虑”又能“躬行实践”的秘诀!
ReAct是一种将推理和行动相结合的AI模型方法,通过交替进行“思考”(Thought)和“行动”(Action),并观察环境反馈(Observation)来解决问题。它克服了纯推理模型易产生幻觉和纯行动模型缺乏规划的局限,在多跳问答、事实验证和交互式决策等任务上表现优异。ReAct不仅是一种prompting技巧,更是一种高效的数据组织方式,已成为现代AI Agent设计的基础范式,并推动了如LangGraph、OpenAI Function Calling、Anthropic Extended Thinking等多Agent协作和模型内化推理的发展趋势。
- 引言:两条分开走的路
=============
2022 年 10 月,普林斯顿大学的 Shunyu Yao 和 Google Research 的合作者们提交了 ReAct 论文。当时的研究现状是:推理和行动是两条完全独立的研究路线,还没有人把它们放到同一个模型里。
一边是 Chain-of-Thought(Wei et al., 2022.1),让 LLM 在输出答案之前插入一段推理过程。模型在文本框里一步步想,但无法获取外部信息——没有搜索,没有 API 调用,纯靠模型内部的参数记忆。
另一边是行动导向的研究。WebGPT(OpenAI, 2021)通过微调让模型能搜索互联网;SayCan(Google, 2022)让语言模型驱动机器人执行物理动作。但这些都需要专门微调,不是通用 LLM 直接能做到的。
ReAct(Reasoning +Acting)的做法是:推理和行动交替进行,互相增强。
- 前置背景:推理与行动的分野
================
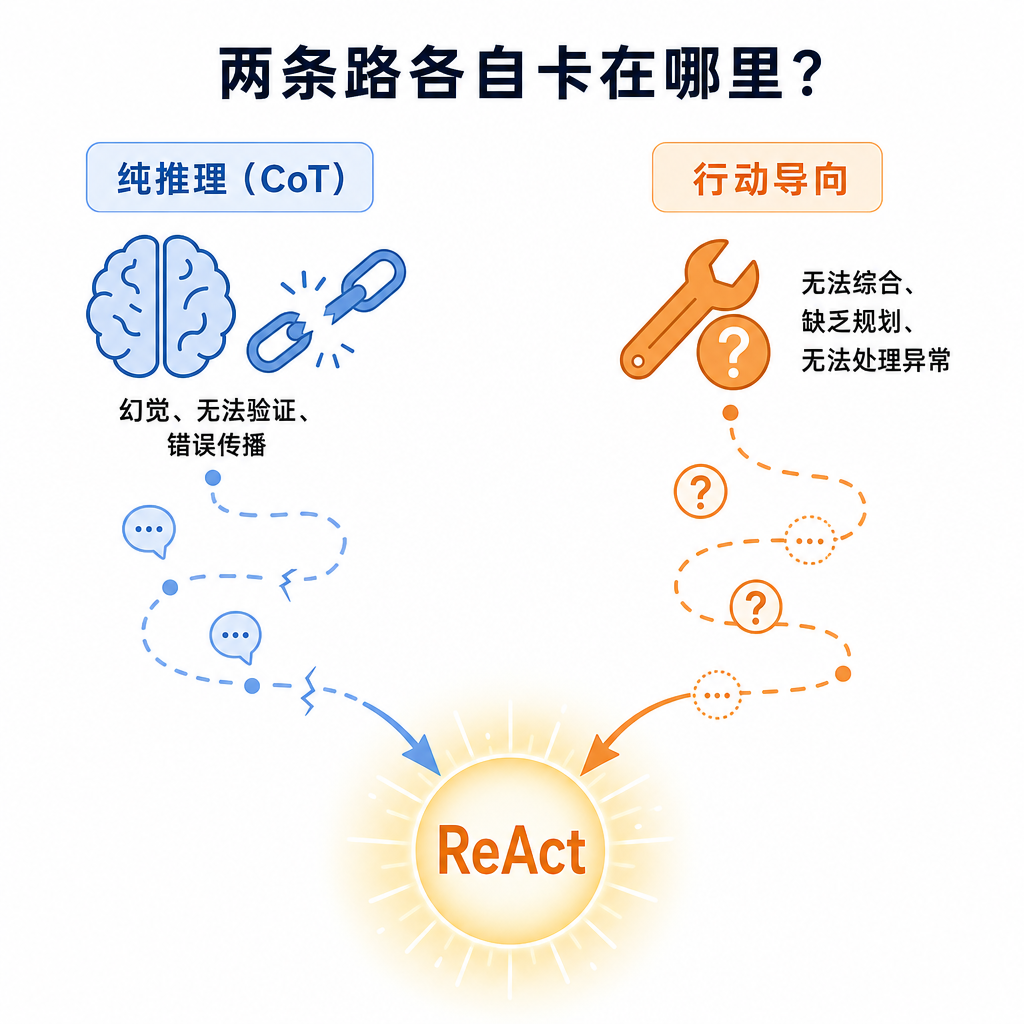
要理解 ReAct 的价值,先得看清楚它之前的两条路径各自卡在哪里。
Chain-of-Thought:能想但不能做
2022 年初,Wei et al. 提出了 Chain-of-Thought(CoT)prompting,在 LLM 输出答案之前插入一段推理过程。这在数学和逻辑任务上效果显著——模型学会了"一步步想"。
但 CoT 有一个致命问题:推理完全依赖模型内部的知识。模型没有能力去查证事实、获取最新信息、或者验证自己的假设。这导致了两个后果:
幻觉(Hallucination):模型会"编造"看似合理但实际错误的中间步骤,然后基于错误前提继续推理,最终得出错误结论。在多跳问答(multi-hop QA)任务中,这个问题尤为严重。
错误传播(Error Propagation):推理链越长,累积错误越多。模型没有"纠错"机制——一旦中间某步推理出错,后续步骤全部偏离轨道。
用论文原话说,纯推理"没有与外部环境连接来获取和更新知识",所以它既不能验证自己的推理,也不能在出错时修正方向。
行动导向研究:能做但不能想
另一边是让 LLM 与外部环境交互的研究。WebGPT(2021.12)通过微调让模型能搜索互联网,SayCan(2022.4)让语言模型驱动机器人。但这些都需要专门的训练或微调,不是通用 LLM 的原生能力。ReAct 论文发表半年后,Toolformer(Meta, 2023.2)和 OpenAI Function Calling(2023.6)才让这条路真正产品化。
但行动导向的研究同样有问题:
无法综合信息:模型拿到搜索结果后,不知道怎么把多个来源的信息拼成一个连贯答案。能搜到信息,但不知道怎么想。
缺乏规划:面对复杂任务,模型不知道应该先做什么、后做什么。没有推理能力的行动是盲目的。
无法处理异常:如果某次工具调用失败或返回了意外结果,模型没有能力推理出"为什么会这样"并调整策略。
在 HotpotQA 的实验中,纯行动基线(Act-only)虽然能通过 Wikipedia API 获取正确信息,但无法综合这些信息得出最终答案。
两条路径的困境
| 纯推理(CoT) | 行动导向(WebGPT 等) | |
|---|---|---|
| 优势 | 能规划、能综合 | 能获取真实信息 |
| 劣势 | 幻觉、无法验证 | 无法规划、无法综合 |
| 失败模式 | 基于错误前提继续推理 | 拿到信息但不知道怎么用 |
- ReAct 的核心思想
==============
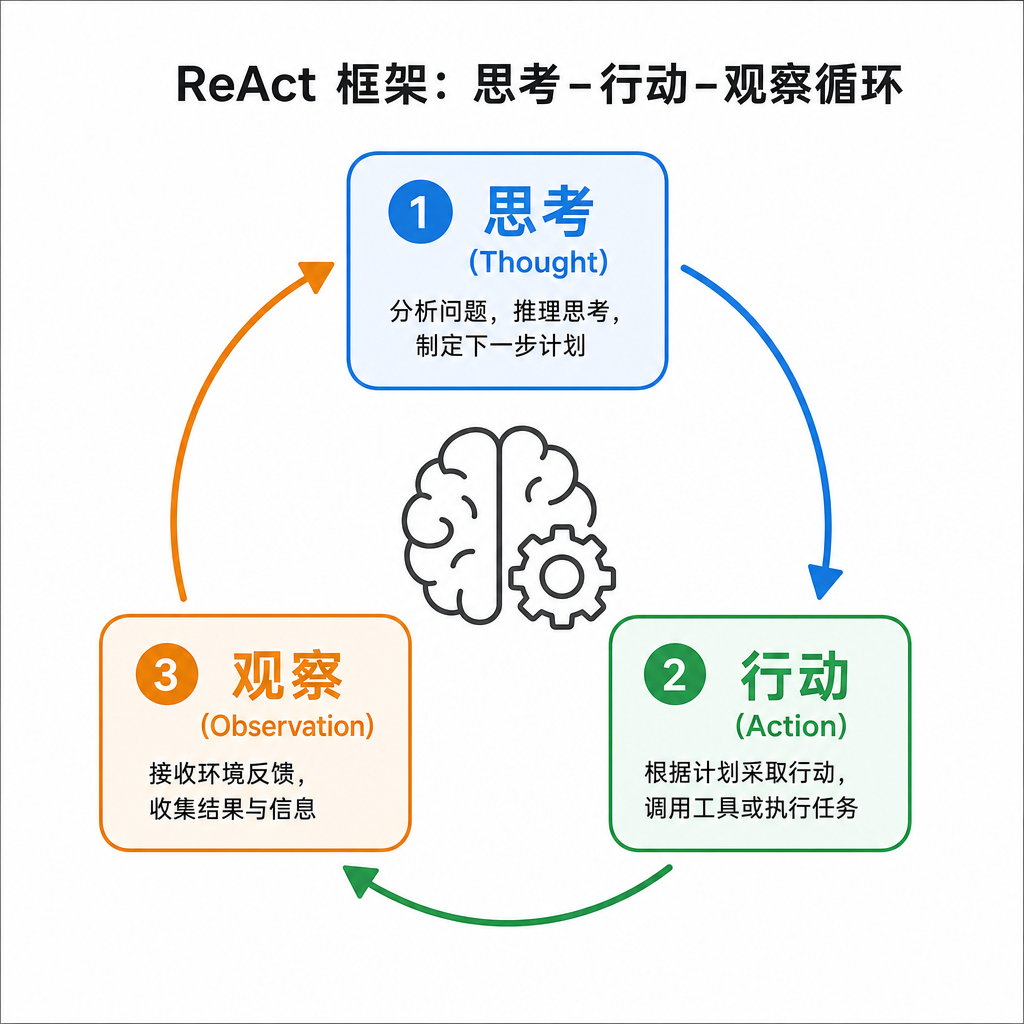
ReAct 的做法是让模型在推理和行动之间交替切换:推理为行动提供方向,行动为推理提供事实依据。
具体来说,模型在生成过程中会交替产出两种内容:
Thought(推理轨迹):模型对当前状态的分析、对下一步行动的规划、对已获取信息的总结。Thought 是自然语言,不是代码。
Action(行动):模型调用外部工具的指令。Action 有固定格式(如 Search[query]、Lookup[keyword]),对应具体的 API 调用。
环境会返回Observation(观察):工具调用的结果,比如搜索结果、页面内容、数据库查询结果。
然后模型基于 Observation 产生下一个 Thought,如此循环,直到得出最终答案。
Question: 邓紫棋的男朋友是什么星座的?
Thought 1: 我需要先搜索邓紫棋的男朋友是谁。
Action 1: Search[G.E.M. 邓紫棋 男友]
Observation 1: [搜索结果:邓紫棋的男朋友是 Mark Ngai…]
Thought 2: 根据搜索结果,邓紫棋的男朋友是 Mark Ngai。我需要搜索他的星座。
Action 2: Search[Mark Ngai 星座]
Observation 2: [搜索结果:Mark Ngai 是天蝎座…]
Thought 3: Mark Ngai 是天蝎座,我可以回答这个问题了。
Action 3: Finish[天蝎座]
Thought 为 Action 提供方向,Observation 为 Thought 提供事实。推理靠行动获取真实信息,行动靠推理找到正确方向。
- 方法论详解:Thought-Action-Observation 循环
======================================
Prompt 模板设计
ReAct 使用 few-shot prompting。研究者手工编写几个完整的 Thought-Action-Observation 轨迹作为示例,放在 prompt 中,让模型在推理时参照这些格式。
一个典型的 HotpotQA prompt 结构如下:
Question: [具体问题]
Thought 1: [对问题的分析,确定需要什么信息]
Action 1: Search[搜索关键词]
Observation 1: [搜索返回的结果]
Thought 2: [基于 Observation 1 的推理,确定下一步]
Action 2: Search[新的搜索关键词] 或 Lookup[查找关键词]
Observation 2: [结果]
… (循环)
Thought N: [最终推理]
Action Finish[最终答案]
三要素定义
Thought:纯文本推理。Thought 不直接产出答案,而是帮模型想清楚下一步该做什么。论文原话是"induce, track, and update action plans, and handle exceptions"。
Action:格式化的工具调用。在 HotpotQA 中,Action 有三种:
Search[query]:调用 Wikipedia Search API,返回相关页面摘要
Lookup[term]:在当前页面中查找特定关键词
Finish[answer]:输出最终答案
在 ALFWorld(交互式游戏环境)中,Action 对应的是游戏操作,如 go to countertop 1、put egg 1 in/on countertop 2。
Observation:环境的返回值。这是 Action 的执行结果,以文本形式呈现。模型读取 Observation 后产生下一个 Thought。
实际运行示例
以论文中的一个 HotpotQA 例子为例(简化):
Question: What is the elevation range for the area that the eastern
sector of the Colorado orogeny extends into?
Thought 1: The eastern sector of the Colorado orogeny extends into
the High Plains. I need to find the elevation range of the High Plains.
Action 1: Search[High Plains]
Observation 1: The High Plains are a subregion of the Great Plains,
elevation from around 1,800 to 7,000 ft…
Thought 2: The High Plains has an elevation range of approximately
1,800 to 7,000 ft. I can answer this now.
Action 2: Finish[1,800 to 7,000 ft]
Thought 1 做了两件事:理解问题(东部科罗拉多造山带延伸到哪个区域?)并确定下一步行动(搜索 High Plains)。Thought 2 基于 Observation 1 的信息得出了结论。
与 CoT 和 Act-only 的对比
论文设计了消融实验来证明 ReAct 的优势:
纯 CoT(Reason-only):
Thought 1: The eastern sector of the Colorado orogeny extends into
the High Plains. The High Plains have an elevation of approximately
5,000 ft…
模型直接凭记忆回答,不查证。论文指出,这种方式"没有与外部环境连接来获取和更新知识",导致事实错误。
纯 Action(Act-only):
Action 1: Search[elevation range eastern sector Colorado orogeny]
Observation 1: …
Action 2: Finish[…]
模型能搜到信息,但没有推理过程来综合多个来源,也无法处理搜索结果不直接回答问题的情况。
ReAct:
Thought 1: 需要先确定东部科罗拉多造山带延伸到哪个区域。
Action 1: Search[…]
Observation 1: …
Thought 2: 它延伸到 High Plains。需要查 High Plains 的海拔。
Action 2: Search[…]
Observation 2: …
Thought 3: 海拔范围是 1,800-7,000 ft。
Action 3: Finish[1,800-7,000 ft]
- 实验验证:四个基准测试
==============
ReAct 在四个不同类型的基准测试上进行了验证,覆盖了问答、事实验证和交互式决策三大场景。
HotpotQA:多跳问答
HotpotQA 要求模型根据多篇 Wikipedia 文章回答问题,需要"多跳"推理——即从一篇文章中找到线索,再去查另一篇文章。
| 方法 | Exact Match |
|---|---|
| CoT(纯推理) | 较低(幻觉严重) |
| Act-only(纯行动) | 中等(无法综合) |
| ReAct | 最高 |
ReAct 每一步推理都通过 Wikipedia API 查证了事实,不会凭空编造;每一步行动都有推理引导,知道该搜什么、怎么综合结果。
FEVER:事实验证
FEVER 要求判断一条声明(claim)是否被 Wikipedia 支持(SUPPORTS)、反驳(REFUTES)或信息不足(NOT ENOUGH INFO)。
ReAct 在 FEVER 上同样表现最优。模型需要逐步验证声明中的每个事实断言,这正是推理+查证循环的用武之地。
ALFWorld:交互式决策
ALFWorld 是一个文本游戏环境,模拟家庭场景(找东西、做饭、清洁等)。模型需要通过一系列操作来完成任务。
| 方法 | 成功率 |
|---|---|
| 模仿学习(BC) | 较低 |
| 强化学习(RL) | 中等 |
| ReAct | 高出 34% |
34% 的绝对成功率提升是巨大的。模型能推理出"要找锅,得先去台面看"这样的中间步骤,RL 做不到这一点。
WebShop:网页购物决策
WebShop 模拟在线购物场景,模型需要根据用户描述搜索商品、比较选项、做出购买决策。
| 方法 | 成功率 |
|---|---|
| RL 方法 | 中等 |
| ReAct | 高出 10% |
微调实验
论文还做了一个重要发现:用 ReAct 格式的轨迹来微调模型,效果优于用 CoT 或 Act-only 格式微调。微调后的小模型甚至能超越 prompting 的大模型。
- 为什么推理和行动必须结合
===============
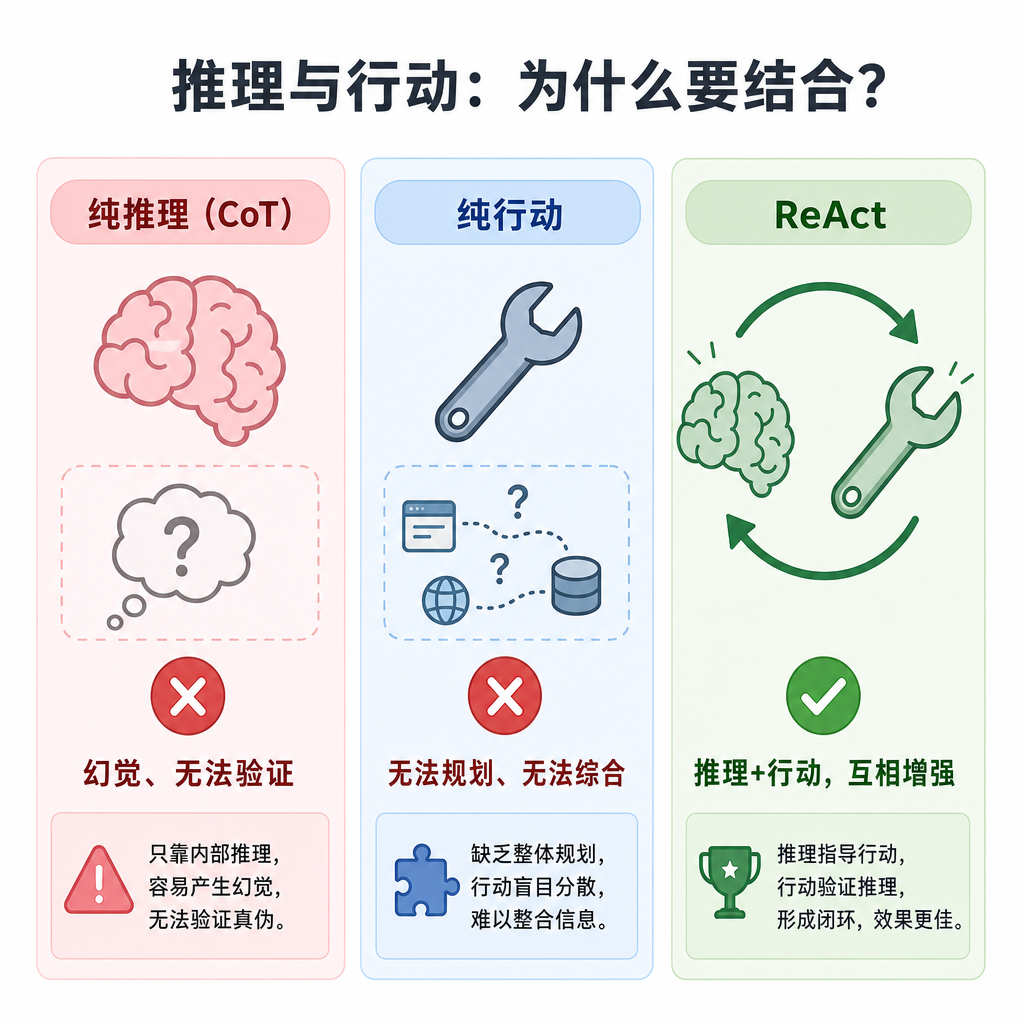
推理为行动提供方向
在 ALFWorld 中,纯行动基线不知道"先去台面找锅"比"先去冰箱找锅"更合理。Thought 步骤让模型能规划行动序列,而不是随机尝试。
行动为推理提供事实
在 HotpotQA 中,纯推理基线凭记忆回答问题,编造了错误的事实。Action 步骤让模型能查证事实,推理不再基于虚构的前提。
循环中的自我纠正
当 Observation 返回了意外结果,比如搜索没找到相关信息,模型的下一个 Thought 会意识到问题并调整策略。论文提到,“ReAct format allows easy human inspection and behavior correction by changing a couple of model thoughts”。这种自我纠正能力是纯 CoT 和纯 Action 都不具备的。
可调试性
ReAct 生成的轨迹是人类可读的。你可以看到模型在想什么、做了什么、得到了什么结果。模型出错时,能定位是 Thought 出了问题还是 Action 出了问题。
- 工业实现:从论文到框架
==============
LangGraph:图结构的 ReAct
LangChain 团队在 2024 年将 Agent 架构迁移到了 LangGraph——一个基于图的状态机框架。LangGraph 提供了 create_react_agent 预构建函数,核心是一个循环图:
用户输入 → LLM(生成 Thought + Action)→ Tool Node(执行 Action)
↑ ↓
←←←←←←←←←←← Observation ←←←←←←←←←←←←←←←←←←←←←←
↓
当 Action 为 Finish 或无更多工具调用时 → 输出最终答案
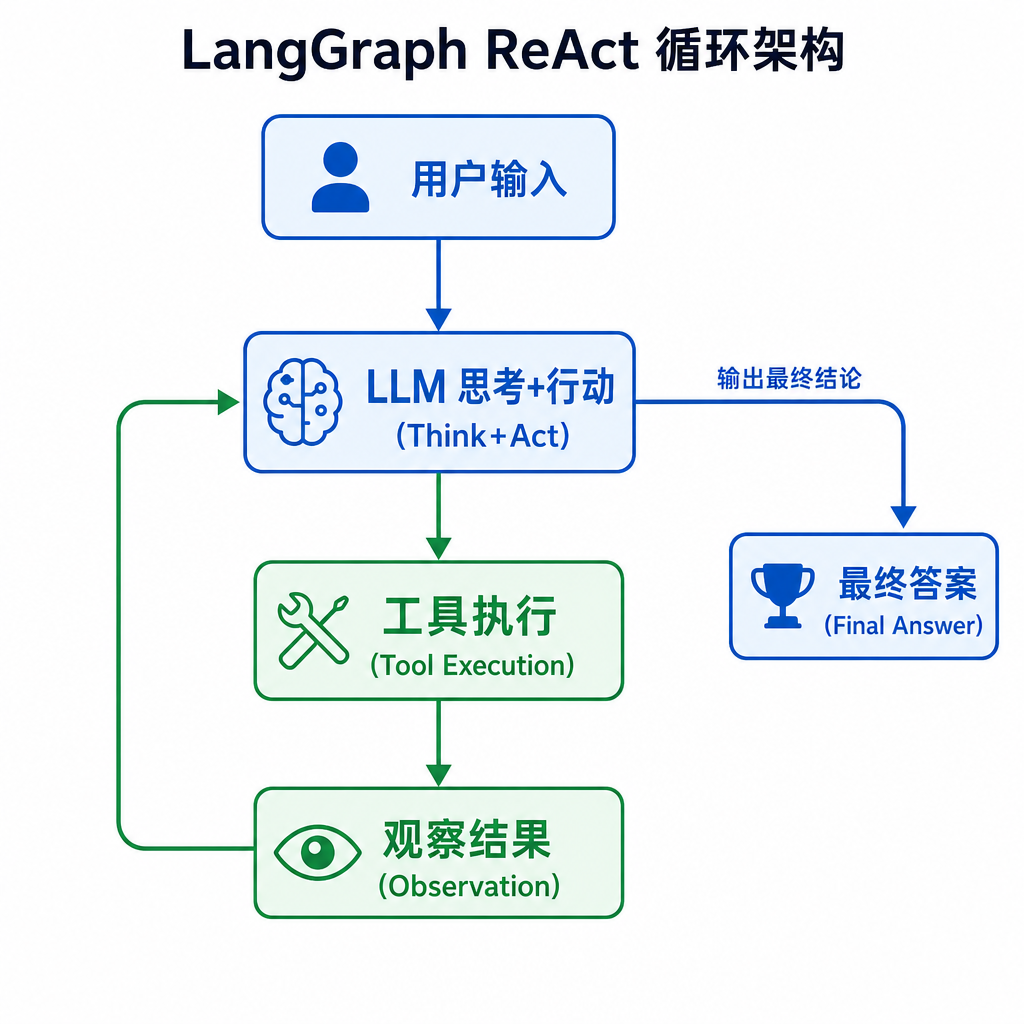
LangGraph 的实现比论文原始版本更灵活:
支持多个工具并行调用
支持状态持久化(Memory)
支持 Human-in-the-loop(人工介入)
可以自定义循环终止条件
OpenAI Function Calling:结构化的行动
OpenAI 的 Function Calling 虽然不叫 “ReAct”,但本质上是 ReAct 中 Action 部分的结构化实现。模型输出 JSON 格式的函数调用,你的代码执行后把结果返回给模型。
区别在于:Function Calling 没有显式的 Thought 步骤。推理被隐含在模型内部,不可见。更高效(节省 token),但可解释性更差。
Anthropic Extended Thinking + Tool Use
Anthropic 在 2025 年推出的 Extended Thinking + Tool Use 组合,结构上最接近论文原始 ReAct。Extended Thinking 让模型在行动之前进行可见的推理(类似 Thought),然后调用工具(类似 Action)。
异同对比
| 特性 | 论文原始 ReAct | LangGraph | OpenAI FC | Anthropic T+TU |
|---|---|---|---|---|
| 显式推理(Thought) | 有 | 可选 | 无(隐含) | 有(Extended Thinking) |
| 结构化行动 | 文本格式 | 图节点 | JSON Schema | JSON Schema |
| 循环控制 | prompt 控制 | 图结构 | 手动实现 | 手动实现 |
| 可解释性 | 高 | 高 | 中 | 高 |
| Token 效率 | 低(显式 Thought) | 中 | 高 | 中 |
| 模型无关 | 是 | 是 | 否 | 否 |
- 局限性与改进方向
===========
上下文窗口限制
ReAct 的每一步都会累积 Thought + Action + Observation,轨迹会越来越长。在 HotpotQA 的长篇文档中,上下文很快就会被填满。模型被迫在有限的 token 预算内完成推理,这限制了它能处理的问题复杂度。
论文使用的是 davinci-002 和 PaLM-540B,上下文窗口远小于今天的模型。但即便如此,上下文管理仍然是 ReAct 实际应用中的核心挑战。
错误级联
ReAct 的循环结构意味着:一步错误可能传播到后续所有步骤。如果模型的第一个 Thought 对问题的理解有偏差,后续的 Action 和 Observation 都会偏离正确方向。
ReAct 比纯 CoT 更容易发现错误(轨迹可读),但模型本身缺乏回头检查的机制。
成本与延迟
每一步都需要调用一次 LLM,一个完整的 ReAct 轨迹可能需要 5-10 次 LLM 调用。这在生产环境中意味着:
延迟:串行调用,总延迟是各步之和
成本:每次调用都要付费,token 数量随步骤线性增长
对 Prompt 的敏感性
ReAct 是 few-shot prompting 方法,性能高度依赖于示例的质量和选择。论文使用的是手工编写的示例,换一组示例可能导致显著不同的结果。
改进方向
Tree of Thoughts(ToT):同样由 Shunyu Yao 提出,在推理阶段探索多条路径,然后选择最优的继续。这是 ReAct 的推理部分的增强版。
多智能体 ReAct:多个 Agent 各自执行 ReAct 循环,分工协作。如 CrewAI、AutoGen 等框架。
Memory 增强 ReAct:加入长期记忆机制,让 Agent 能跨会话保持上下文。
Plan-then-Execute:先生成完整计划,再逐步执行。如 HuggingGPT、LLMCompiler。这解决了 ReAct 缺乏全局规划的问题。
结构化输出:用 JSON 替代自由文本的 Action,减少解析错误。
- ReAct 在 AI Agent 范式中的位置
==========================
Agent 设计模式谱系
当前的 AI Agent 架构可以按"推理与行动的关系"来分类:
| 模式 | 推理与行动的关系 | 代表 |
|---|---|---|
| ReAct | 交替进行(循环) | LangGraph ReAct Agent |
| Plan-then-Execute | 先推理后行动 | HuggingGPT、LLMCompiler |
| Function Calling | 隐式推理 + 结构化行动 | OpenAI Assistants API |
| Multi-Agent | 多个 Agent 各自 ReAct/Planning | CrewAI、AutoGen |
| Reflection | 行动后反思,再行动 | Reflexion、LATS |
ReAct 是这些模式中最基础的——其他模式几乎都可以看作 ReAct 的变体或扩展。Plan-then-Execute 是 ReAct 的"先全局规划再执行"版本;Multi-Agent 是 ReAct 的"分工协作"版本;Reflection 是 ReAct 的"加入自我反思"版本。
为什么 ReAct 成为了基础范式
Thought-Action-Observation 循环足够简单,用 prompt engineering 就能实现,不需要复杂框架。它适用于几乎所有需要工具调用的任务——问答、搜索、代码执行、API 调用。而且很容易和其他技术组合:加 Memory 变成持久化 Agent,加 Planning 变成 Plan-then-Execute,多个 Agent 各自跑 ReAct 就是 Multi-Agent 系统。
2025-2026 年的演进趋势
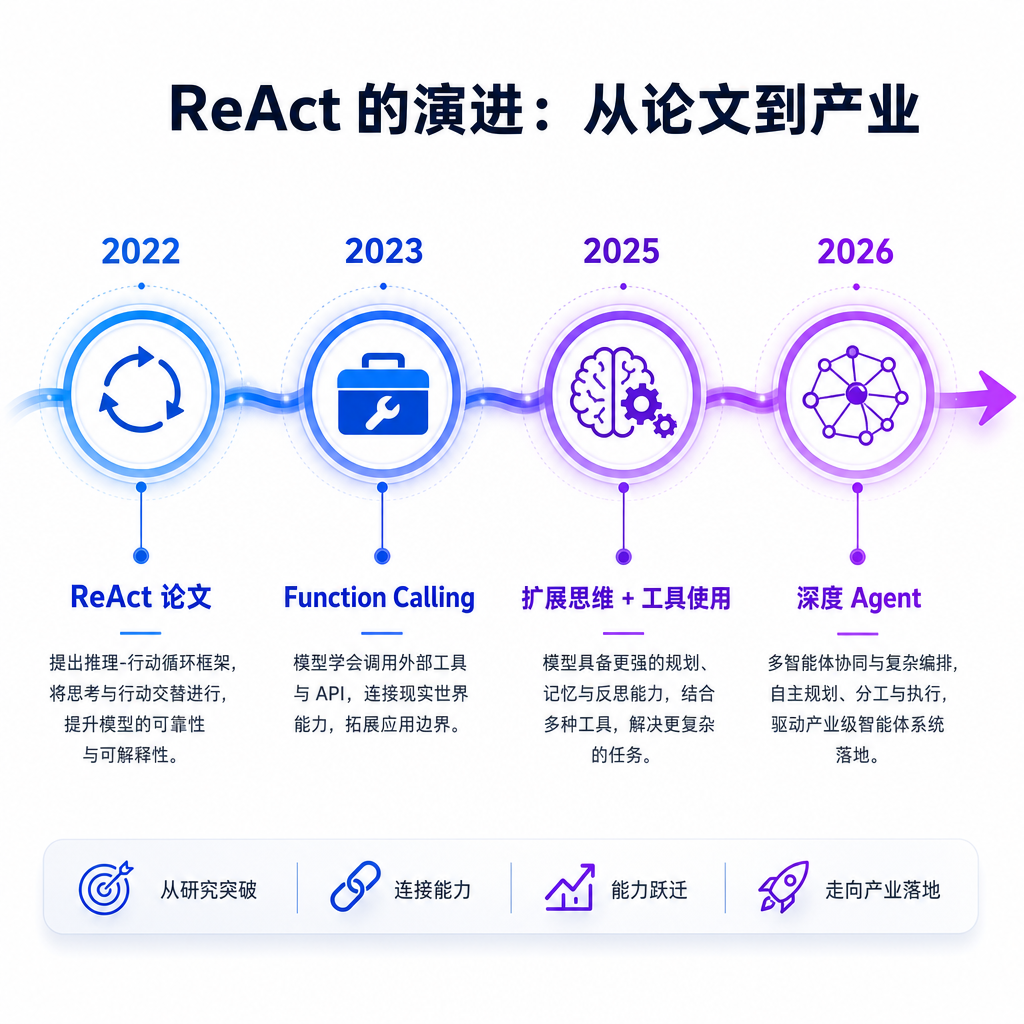
ReAct 论文发表三年后,推理-行动循环已经从一个 prompting 技巧演变为整个 AI Agent 产业的底层范式。几个可验证的变化:
Extended Thinking + Tool Use:推理重新可见
Anthropic 在 2025 年 5 月发布的 Claude Opus 4 和 Sonnet 4 中,将 Extended Thinking 与 Tool Use 结合——模型在思考过程中可以调用工具,观察结果,再继续思考。这正是 ReAct 的 Thought-Action-Observation 循环,只不过实现方式从 prompt 模板变成了模型原生能力。到 2026 年 4 月的 Claude Opus 4.7,上下文窗口扩展到 1M token,模型可以连续执行数千步、持续数小时的复杂任务。
从单轮循环到长期运行 Agent
LangChain 在 2025 年 7 月发布了 Deep Agents 框架,针对的问题是:标准 ReAct 循环(工具循环调用)在长任务上"太浅"。Deep Agents 加入了四个机制:详细系统提示、规划工具(Todo list)、子 Agent、虚拟文件系统。本质上是把 ReAct 的单轮循环扩展成了多层嵌套的长期运行架构。
推理模型内化了 Thought 步骤
OpenAI 在 2025 年 4 月发布 o3 和 o4-mini,将推理能力直接内化到模型中——模型自己决定何时深度思考、何时行动,不需要外部 prompt 引导 Thought 步骤。这意味着 ReAct 的 Thought 从"工程技巧"变成了"模型能力"。
Agent 产品的标准化
Anthropic 的 Claude Code 从实验性功能走向 GA(2025),支持 IDE 集成、SDK、GitHub 集成、后台任务。LangSmith 扩展为四个支柱:可观测性、评估、部署、Fleet(企业级 Agent 管理)。Agent 不再是学术概念,而是有完整工程基础设施的产品形态。
多 Agent 协作成为主流
Deep Agents 支持后台子 Agent 并行执行;CrewAI、AutoGen 等框架让多个 Agent 各自运行 ReAct 循环再协作。ReAct 从单 Agent 的设计模式变成了多 Agent 系统的基础模块。
- 结语
======
ReAct 只是一个 Thought-Action-Observation 的循环,技术上不复杂。但它把推理和行动从两条独立的路径拧成了一条,改变了 AI Agent 的设计思路。从 LangGraph 到 OpenAI Assistants,从 Anthropic 的 Extended Thinking 到各种 Multi-Agent 框架,这个循环无处不在。
论文最后提到,用 ReAct 格式微调的小模型能超越 prompting 的大模型。这说明 ReAct 不只是 prompting 技巧,也是一种高效的数据组织方式。
01
什么是AI大模型应用开发工程师?
如果说AI大模型是蕴藏着巨大能量的“后台超级能力”,那么AI大模型应用开发工程师就是将这种能量转化为实用工具的执行者。
AI大模型应用开发工程师是基于AI大模型,设计开发落地业务的应用工程师。
这个职业的核心价值,在于打破技术与用户之间的壁垒,把普通人难以理解的算法逻辑、模型参数,转化为人人都能轻松操作的产品形态。
无论是日常写作时用到的AI文案生成器、修图软件里的智能美化功能,还是办公场景中的自动记账工具、会议记录用的语音转文字APP,这些看似简单的应用背后,都是应用开发工程师在默默搭建技术与需求之间的桥梁。
他们不追求创造全新的大模型,而是专注于让已有的大模型“听懂”业务需求,“学会”解决具体问题,最终形成可落地、可使用的产品。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

02
AI大模型应用开发工程师的核心职责
需求分析与拆解是工作的起点,也是确保开发不偏离方向的关键。
应用开发工程师需要直接对接业务方,深入理解其核心诉求——不仅要明确“要做什么”,更要厘清“为什么要做”以及“做到什么程度算合格”。
在此基础上,他们会将模糊的业务需求拆解为具体的技术任务,明确每个环节的执行标准,并评估技术实现的可行性,同时定义清晰的核心指标,为后续开发、测试提供依据。
这一步就像建筑前的图纸设计,若出现偏差,后续所有工作都可能白费。
技术选型与适配是衔接需求与开发的核心环节。
工程师需要根据业务场景的特点,选择合适的基础大模型、开发框架和工具——不同的业务对模型的响应速度、精度、成本要求不同,选型的合理性直接影响最终产品的表现。
同时,他们还要对行业相关数据进行预处理,通过提示词工程优化模型输出,或在必要时进行轻量化微调,让基础模型更好地适配具体业务。
此外,设计合理的上下文管理规则确保模型理解连贯需求,建立敏感信息过滤机制保障数据安全,也是这一环节的重要内容。
应用开发与对接则是将方案转化为产品的实操阶段。
工程师会利用选定的开发框架构建应用的核心功能,同时联动各类外部系统——比如将AI模型与企业现有的客户管理系统、数据存储系统打通,确保数据流转顺畅。
在这一过程中,他们还需要配合设计团队打磨前端交互界面,让技术功能以简洁易懂的方式呈现给用户,实现从技术方案到产品形态的转化。
测试与优化是保障产品质量的关键步骤。
工程师会开展全面的功能测试,找出并修复开发过程中出现的漏洞,同时针对模型的响应速度、稳定性等性能指标进行优化。
安全合规性也是测试的重点,需要确保应用符合数据保护、隐私安全等相关规定。
此外,他们还会收集用户反馈,通过调整模型参数、优化提示词等方式持续提升产品体验,让应用更贴合用户实际使用需求。
部署运维与迭代则贯穿产品的整个生命周期。
工程师会通过云服务器或私有服务器将应用部署上线,并实时监控运行状态,及时处理突发故障,确保应用稳定运行。
随着业务需求的变化,他们还需要对应用功能进行迭代更新,同时编写完善的开发文档和使用手册,为后续的维护和交接提供支持。
03
薪资情况与职业价值
市场对这一职业的高度认可,直接体现在薪资待遇上。
据猎聘最新在招岗位数据显示,AI大模型应用开发工程师的月薪最高可达60k。
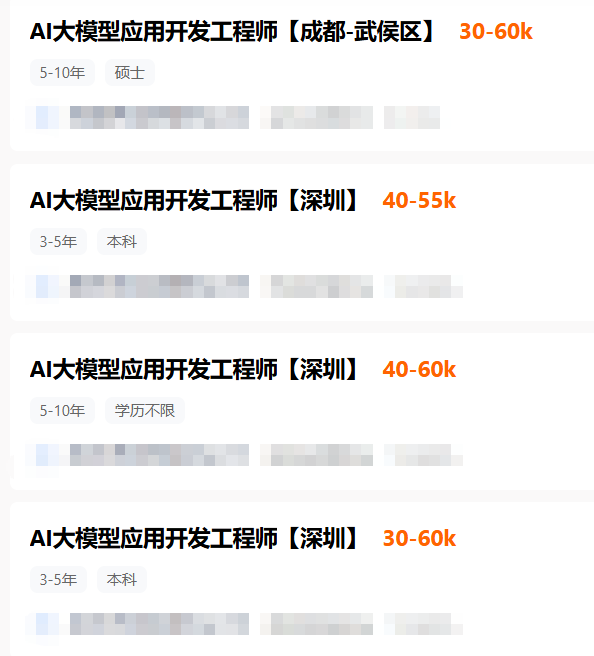
在AI技术加速落地的当下,这种“技术+业务”的复合型能力尤为稀缺,让该职业成为当下极具吸引力的就业选择。
AI大模型应用开发工程师是AI技术落地的关键桥梁。
他们用专业能力将抽象的技术转化为具体的产品,让大模型的价值真正渗透到各行各业。
随着AI场景化应用的不断深化,这一职业的重要性将更加凸显,也必将吸引更多人才投身其中,推动AI技术更好地服务于社会发展。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献115条内容
已为社区贡献115条内容

所有评论(0)