让 Claude Code 拥有「永久记忆」:claude-mem 暴涨 7.1 万 Star!
大家好,我是Java1234_小锋老师。
一、先讲结论:它到底是什么
claude-mem 是一个面向 Claude Code 的插件式「持久记忆压缩系统」。用官方 README 的话说:它会在你编码时自动捕获 Claude 在会话中做的事情,借助 Claude Agent SDK 把原始过程压缩成更可复用的观察(observations)与语义摘要,并在之后的会话里把相关信息回填给模型,让你少一点重复解释,多一点连续推进。
如果把它拟人化,它不是在替你做决定,而是在替你维护一本可查询的工程笔记——而且这本笔记是机器写、机器整理、机器检索的。

二、我们缺的不是模型能力,而是「会话之间的胶水」
做工程的人大多能接受这样一种分工:模型擅长推理与生成,人擅长目标、审美与取舍。真正让协作效率掉线的,往往是第三种成本——语境搬运成本。
你会反复交代:「这个仓库不要用某某脚本」「"生产环境"用的环境变量在 .env.example 里写了注释」「上次排障已经确认不是缓存」。这些话并不高贵,但它们很贵,因为它们每一次都要占用你的注意力与 token。
claude-mem 的切入点很直白:让高概率会被再次需要的信息,自动进入结构化记忆,而不是散落在聊天记录的历史滚动条里。
三、claude-mem 如何工作:从采集到注入
从架构视角看,它把「记忆」拆成一条清楚的流水线:钩子捕获 → Worker 服务处理与提供接口 → SQLite 持久化 →(结合向量检索)做混合搜索 → 在合适的时机把上下文塞回会话。
下面的流程图只描述主线,略去个别可选分支,便于你第一次读就建立整体心智模型。
这里有几个关键词值得记住:
- 生命周期钩子:把「什么时候该记」从人工习惯变成系统机制。
- Worker 服务:把记忆从「聊天副产品」提升为可被工具化访问的服务。
- SQLite + 向量检索:既照顾工程上的简单可靠,又为语义相关召回留出门路。
四、渐进式检索:省 token 的「三层节奏」
如果你做过 RAG,你会知道最常见的事故之一,就是一上来就把一大坨上下文喂给模型:看起来很多,实际上噪声更大,还贵。
claude-mem 在 MCP 工具层面推了一套很「工程化」的节奏:先索引,再时间线,再按需取全文。README 给出的直觉收益是:先过滤再拉细节,有机会带来数量级上的 token 节省(文档中常以约 10× 作为经验描述,具体收益随查询与数据分布变化)。
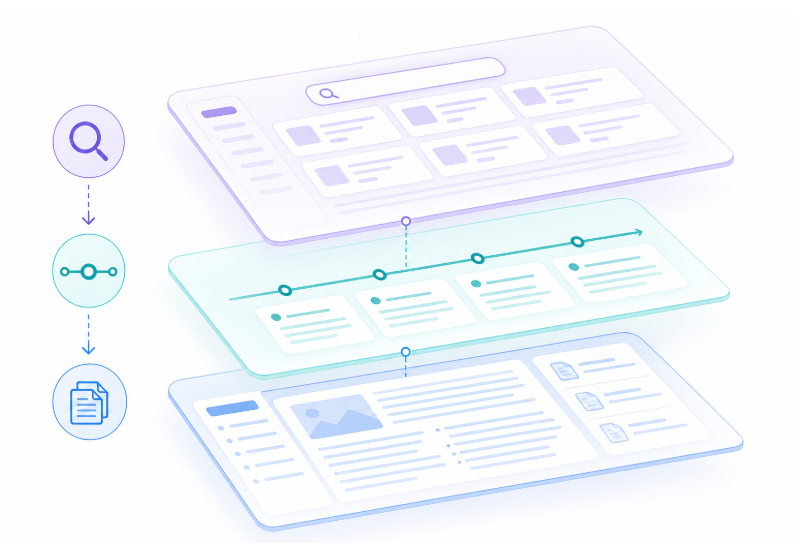
可以把三层节奏理解成「先买地图,再走路,最后拍照留档」:
search:拿到紧凑的索引与 ID(更省 token)。timeline:围绕感兴趣的条目补齐时间相邻的脉络。get_observations:只对筛选后的 ID 批量拉取更完整的观察细节。
这段设计最有价值的地方不在于「炫技」,而在于它把检索当成成本敏感的系统工程:每一次多读的字符,都应该换来确定性的信息增益。
五、安装与上手:尽量保持「一次命令,长期受益」
对大多数用户,官方推荐的路径足够短。你可以用一条命令完成安装(会处理插件钩子与 Worker 等配套,而不是只装一个 npm 包壳子):
npx claude-mem install
如果你更习惯在 Claude Code 里走插件市场,也可以:
/plugin marketplace add thedotmack/claude-mem
/plugin install claude-mem
避坑提示:README 里特别提醒,
npm install -g claude-mem往往只装到 SDK/库本体,不一定会帮你把插件钩子和 Worker 服务一整套注册好;想「装好就能用」,优先npx claude-mem install或/plugin流程。
装完后重启 Claude Code。下一次你开始工作时,来自既往会话的脉络会更自然地出现在新一轮对话的起点——这才是「永久记忆」这句口号背后,最贴近日常体验的变化。
从官方说明看,典型环境要求包括 Node.js ≥ 18、较新的 Claude Code(需支持插件),以及会在安装过程中按需补齐的 Bun、uv(用于向量检索相关能力)等。第一次部署若遇到路径或依赖问题,不必急着否定方案——先看官方 Troubleshooting,Windows 用户还要特别确认 npm 已正确加入 PATH。
六、除了 Claude Code,还兼容谁
claude-mem 的定位很清晰:先把 Claude Code 的会话连续性做到极致。与此同时,它也在扩展「你日常用的命令行 AI」覆盖范围,例如 README 提到的 Gemini CLI、OpenCode,以及通过安装脚本集成到 OpenClaw Gateway 的路径。
这对普通开发者意味着:你不必先建立一整套自研记忆系统,也能先在自己正在用的工具链里获得接近原生的体验。
七、隐私、配置与协作边界
任何「记忆产品」都必须回答两个问题:记什么、不记什么。
claude-mem 提供了可配置项与隐私控制思路。根据官方文档描述,你可以用特定标签包裹内容,把敏感信息排除在存储之外(具体标签与规则以文档为准)。配置则集中在用户目录下的 ~/.claude-mem/settings.json,可以调整模型、Worker 端口、数据目录、日志级别,以及中文等多种模式(例如 CLAUDE_MEM_MODE 设为 code--zh)。
另外,它提供一个默认在本机 http://localhost:37777 打开的 Web Viewer,方便你以「信息流」的方式审视记忆是否被正确写入、检索是否命中预期。把它想象成记忆的「示波器」:不天天看,但一旦卡住,它往往比盲猜更快定位问题。
更完整的排障与最佳实践,建议直接阅读官方文档站:docs.claude-mem.ai。
八、开源协议与参与方式
项目以 GNU Affero General Public License v3.0(AGPL-3.0) 开源。通俗地说:你可以自由使用、修改与分发,但在某些网络部署场景下需要遵循「衍生作品也得 AGPL、并提供源码可得性」等义务——这对企业评估是否 fork/二次开发很关键。
如果你想参与贡献,仓库 README 给出的路径很标准:fork、开分支、带测试提交、更新文档、发 Pull Request。遇到复杂问题,也可以先走 GitHub Issues,把复现路径写清楚。
九、写在最后
claude-mem 之所以能在 GitHub 上冲到一个令人咋舌的 Star 量级,不是因为大家突然爱上了「记忆」这两个字,而是因为工程现实里确实存在大量低尊严、高频率的重复劳动:复述、对齐、回忆、纠错。把这类劳动自动化,并不是让 AI 代替你思考,而是把你从「上下文搬运工」里解放出来一点点。
如果你正在 Claude Code 里长期维护一个模块、一个系统、甚至一条产品线,我会建议你用半天时间把它装上,然后观察一周:当你发现自己更少解释「我们上次为什么这么做」时,你就明白这类工具真正的壁垒不在于模型,而在于把过程变成可检索的资产。
参考链接
- 项目仓库:https://github.com/thedotmack/claude-mem
- 官方文档:https://docs.claude-mem.ai/
- 作者 GitHub:@thedotmack

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献63条内容
已为社区贡献63条内容

所有评论(0)