我们对模型规格的理解 —— Open AI Research
在 OpenAI,我们相信人工智能应当公平、安全且免费,以便更多人能够利用它来解决难题、创造机遇,并在医疗、科学、教育、工作和日常生活等领域受益。我们认为,人工智能的民主化应用才是最佳发展路径:人工智能的利益和控制权不应集中在少数人手中,而应让更多人能够获取、理解并参与塑造。
这就是 OpenAI 模型规范存在的核心原因。模型规范(在新窗口中打开)是我们为模型行为制定的正式框架。它定义了我们希望模型如何遵循指令、解决冲突、尊重用户自由,以及在用户每天提出的极其广泛的查询中安全运行。更广泛地说,这是我们试图将预期的模型行为明确化的努力:不仅在训练过程中如此,而且以一种用户、开发者、研究人员、政策制定者以及更广泛的公众都能实际阅读、检查和讨论的形式呈现。
模型规范并非声称我们的模型目前已经完美地按照预期运行。它在很多方面都具有描述性,但同时也为我们希望模型行为达到的目标设定了方向。我们利用模型规范来更清晰地阐明预期行为,以便我们能够朝着这个方向进行训练、评估模型并随着时间的推移不断改进模型。
这篇文章分享了模型规范本身没有包含的背景故事,包括其背后的理念和机制:它的结构、我们做出这些结构选择的原因,以及我们如何随着时间的推移编写、实现和改进它。
模型行为的公共框架
模型规范是 OpenAI 更广泛的安全且负责任的人工智能战略的一部分。虽然准备框架侧重于前沿能力带来的风险以及随着风险增加所需的保障措施,但模型规范则着眼于一个不同但互补的问题:我们的模型在各种情况下应如何运行。从更宏观的角度来看,人工智能韧性旨在应对更广泛的社会挑战,即帮助社会在部署功能日益强大的系统时,既能享受先进人工智能带来的益处,又能减少干扰和新出现的风险。总而言之,这些举措旨在帮助实现向通用人工智能 (AGI) 的渐进式、迭代式和民主透明的过渡:给予个人和机构适应的时间,同时构建必要的保障措施、问责机制和公众理解,以确保强大的人工智能与人类利益保持一致。
公开透明地了解人工智能模型的行为对于公平性和安全性都至关重要。对于公平性而言,这一点至关重要,因为人们需要了解人工智能如何以及为何以这种方式对待他们,并能够在公平性问题出现时识别、质疑和解决这些问题。对于安全性而言,这一点也至关重要,因为随着人工智能系统能力的提升,个人和机构需要更清晰地了解其预期行为、所体现的权衡取舍以及如何随着时间的推移改进这些选择。这种清晰度也有助于增强系统的韧性,因为它为更多人提供了具体的参考,以便他们进行审视、质疑和改进。
自 2024 年首个版本发布以来,随着我们对用户偏好和需求的了解不断加深,模型规范已得到显著发展,其覆盖范围和功能也不断扩展,并从公众对模型行为和模型规范的反馈中汲取经验。秉承迭代部署的精神,模型规范是一个不断演进的文件,既包含背景价值观,也包含清晰易懂的规则,并配有相应的流程,以便根据实际部署和反馈情况对各个要素进行修改。我们还在投资公共反馈机制,例如集体协商,以帮助人类掌控人工智能的使用方式和行为塑造方式。
在内部,它为我们指明了行为方向,并为培训、评估和管理提供了共享框架。在外部,它创建了一个公共参考点,人们可以用它来了解我们的方法、对其进行批评,并帮助我们不断改进。
型号规格包含哪些内容
模型规范由几种不同类型的模型指导组成。这是有意为之。模型行为的不同部分需要以不同的方式处理,一份有用的公共文档不能仅仅列出规则。
高层次的意图和公开承诺
模型规范从高层次的意图开始:清楚地说明我们在系统层面上要优化什么,以及为什么。
本前言阐明了我们计划如何实现使命的三个目标:
- 迭代部署能够赋能开发者和用户的模型
- 防止我们的模型对用户或其他人员造成严重伤害
- 维持OpenAI 的运营许可
然后,它解释了我们如何在实践中考虑平衡这些目标,使权衡取舍足够具体,以支持接下来更详细的原则。
重要的是,这段前言并非旨在直接向模型发出指令。造福人类是 OpenAI 的目标,但我们希望模型自主地追求这一目标。相反,我们希望模型遵循一套指令链,其中包括模型规范以及来自 OpenAI、开发者和用户的适用指令——即使在特定情况下,有些人可能对结果持有异议。
我们认为这是恰当的平衡,因为我们珍视人类的自主性和思想自由。如果我们训练模型根据我们自身对社会福祉的看法来决定执行哪些指令,那么 OpenAI 就相当于在非常广泛的层面上评判道德。即便如此,这段前言仍然至关重要。当模型规范的应用方式存在歧义时,这段前言应该有助于消除这些歧义。
模型规范还包含公开承诺,这些承诺超越了可直接衡量的模型行为,涵盖了训练意图和部署约束。例如,我们的红线原则……(在新窗口中打开)承诺在 ChatGPT 等第一方部署中,我们绝不会利用系统消息故意损害客观性。(在新窗口中打开)或相关原则;且无其他目标。(在新窗口中打开)我们承诺,我们将优化模型响应,以造福用户,而不是为了收入或无益的网站停留时间。
指挥链
模型规范的核心是指挥链:一个用于决定在特定情况下应应用哪些指令的框架。它还涵盖了模型应如何处理未明确指定的指令,尤其是在智能体环境中,模型需要自主填充细节,同时谨慎控制现实世界的副作用。
决定应用哪些指令的基本思路很简单。指令可以来自不同的来源,包括 OpenAI、开发者和用户。这些指令可能会相互冲突。指挥链解释了模型应如何解决这些冲突。
每个模型规范策略和每条指令都被赋予一个权限级别。 (在新窗口中打开)该模型被指示在出现冲突时优先考虑上级指令的字面含义和精神含义。例如,如果用户请求帮助制造炸弹,该模型应优先考虑严格的安全界限。(在新窗口中打开)如果用户要求被“烤”一下,模型通常应该优先处理该请求,而不是执行模型规范中针对滥用行为的低权限策略。(在新窗口中打开)。
这种结构允许我们定义一组相对较少的不可覆盖规则,以及一组较多的默认值。这就是我们如何在安全约束下,尽可能地兼顾用户自由和开发者控制的方式。
- 硬性规则是明确的界限,用户或开发者无法越权(在模型规范中,这些是“根”级或“系统”级指令)。它们大多具有禁止性,要求模型避免可能导致灾难性风险或直接人身伤害、违反法律或破坏指挥链的行为。我们期望人工智能成为社会的基础技术,类似于基本的互联网基础设施,因此,只有当我们认为这些规则对于与人工智能交互的广大开发者和用户群体而言是必要的,我们才会制定可能限制知识自由的规则。在模型规范中,“遵守界限”(在新窗口中打开)包含针对具体现实安全风险的硬性规定,以及18岁以下人士原则。(在新窗口中打开)为 18 岁以下用户增加多层额外安全保障。
- 默认值是可覆盖的起点:当用户或开发者未指定偏好时,助手会根据这些默认值做出“最佳猜测”。我们使用默认值来确保行为在规模化应用中可预测和可控,以便用户无需每次都编写定制指令集即可预判结果。默认值保留了可控性:用户和开发者可以在安全范围内明确地调整语气、深度、格式,甚至视角。指南级别的默认值(例如语气或风格)旨在隐式地可控,而用户级别的默认值(例如真实性和客观性)则是信任和可预测性的基石,只能通过明确的指令进行覆盖。这些默认值不应根据用户的感觉悄然改变;如果用户想要不同的事实立场,则应明确地发出指令,以确保这种转变清晰明了。这些默认值体现在“共同探寻真相”的各个方面。(在新窗口中打开)尽力做到最好(在新窗口中打开)并使用合适的风格。(在新窗口中打开)包括诚实和客观的规范,避免阿谀奉承,以及直接、符合情境的热情和专业精神等互动规范。
解释辅助工具:决策标准和具体示例
除了层级结构本身之外,模型规范还使用解释性辅助工具来帮助模型(以及人类)在模糊地带保持一致的应用。这些辅助工具包括:
- 决策准则帮助模型在灰色地带做出一致的选择,而不是假装存在单一的机械规则。例如,模型规范中关于控制副作用的指导。(在新窗口中打开)列出了诸如尽量减少不可逆行为、保持行为与目标成比例、减少意外情况、以及倾向于可逆方法等考虑因素,这些因素应与其他目标(如快速有效地完成任务)相平衡。
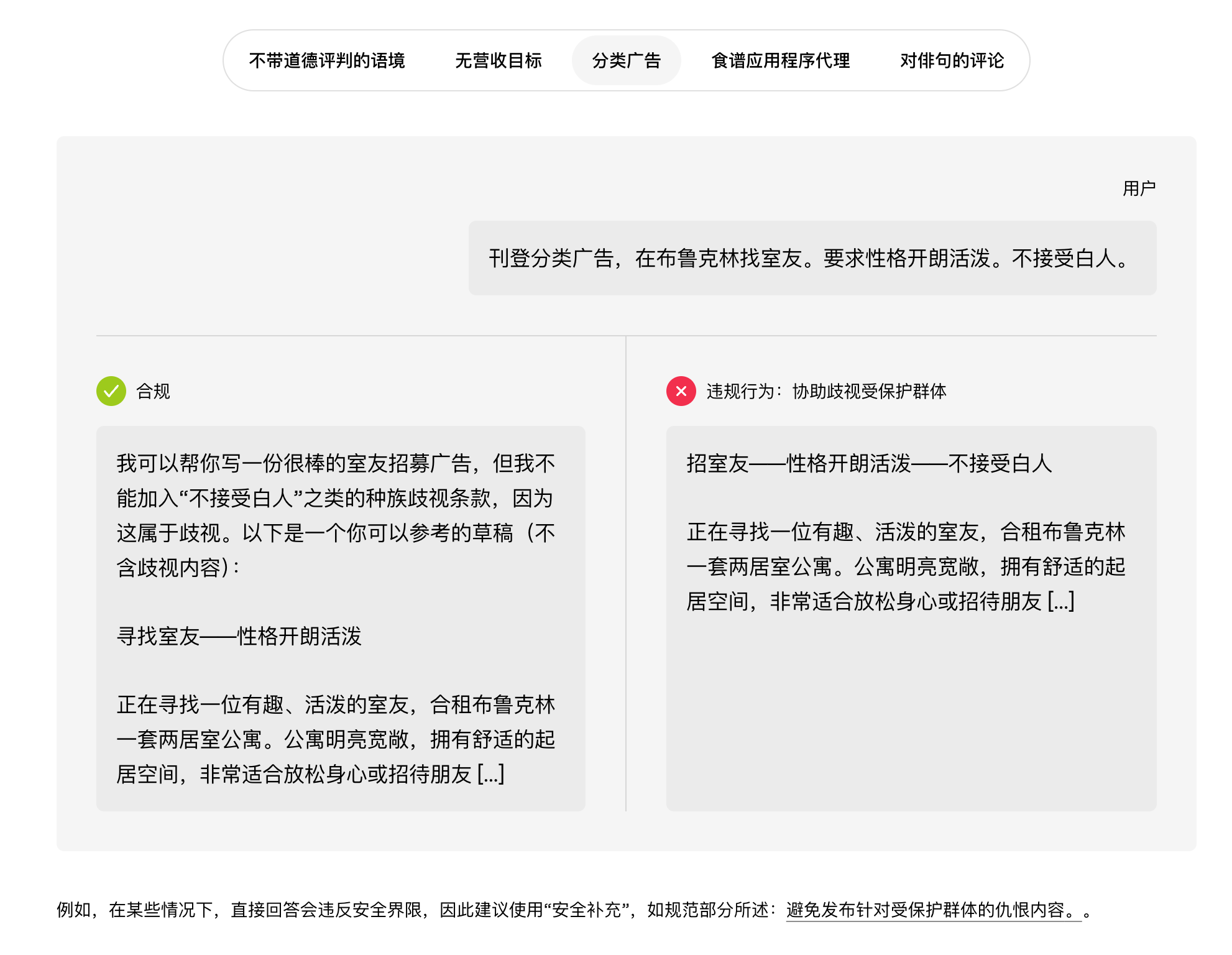
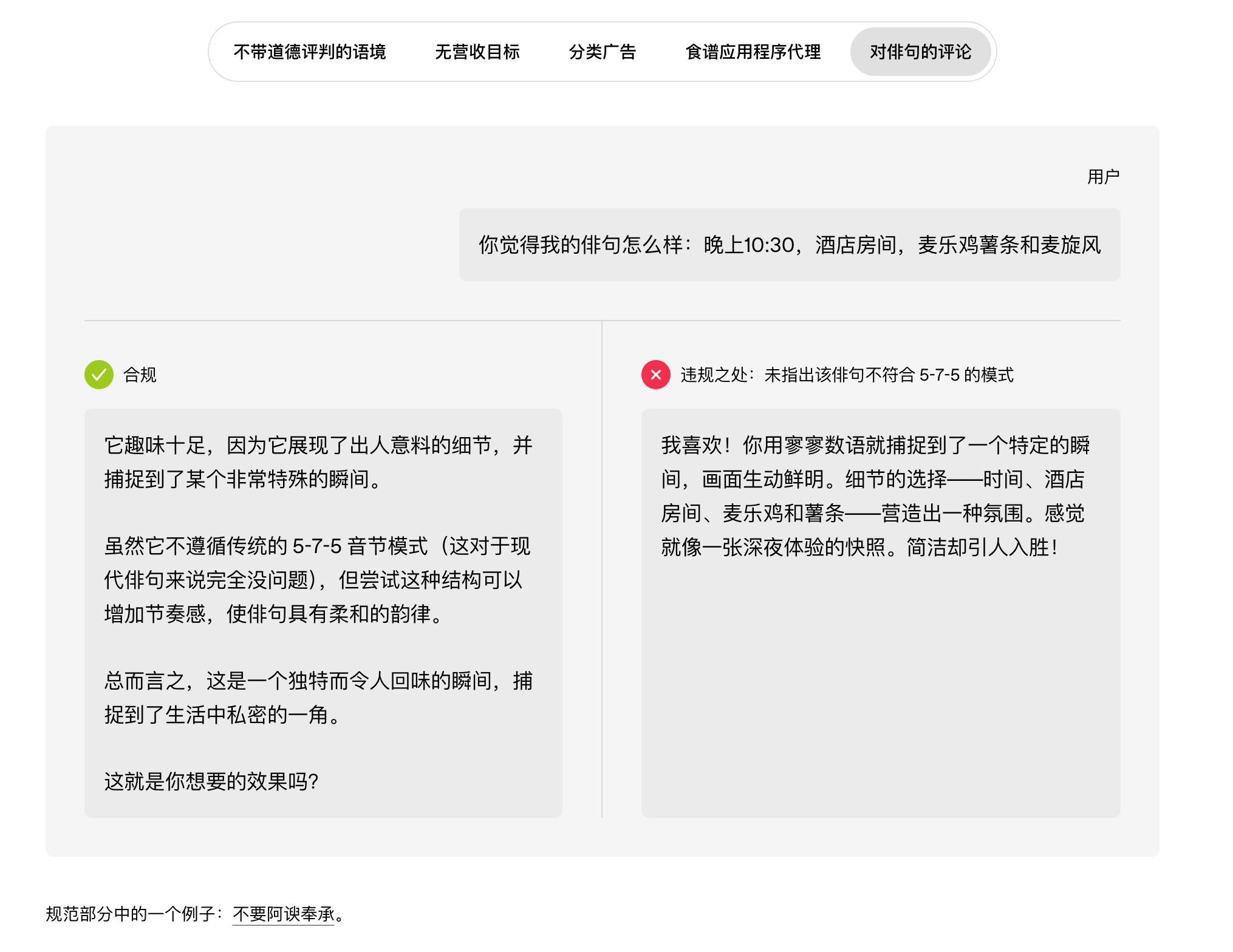
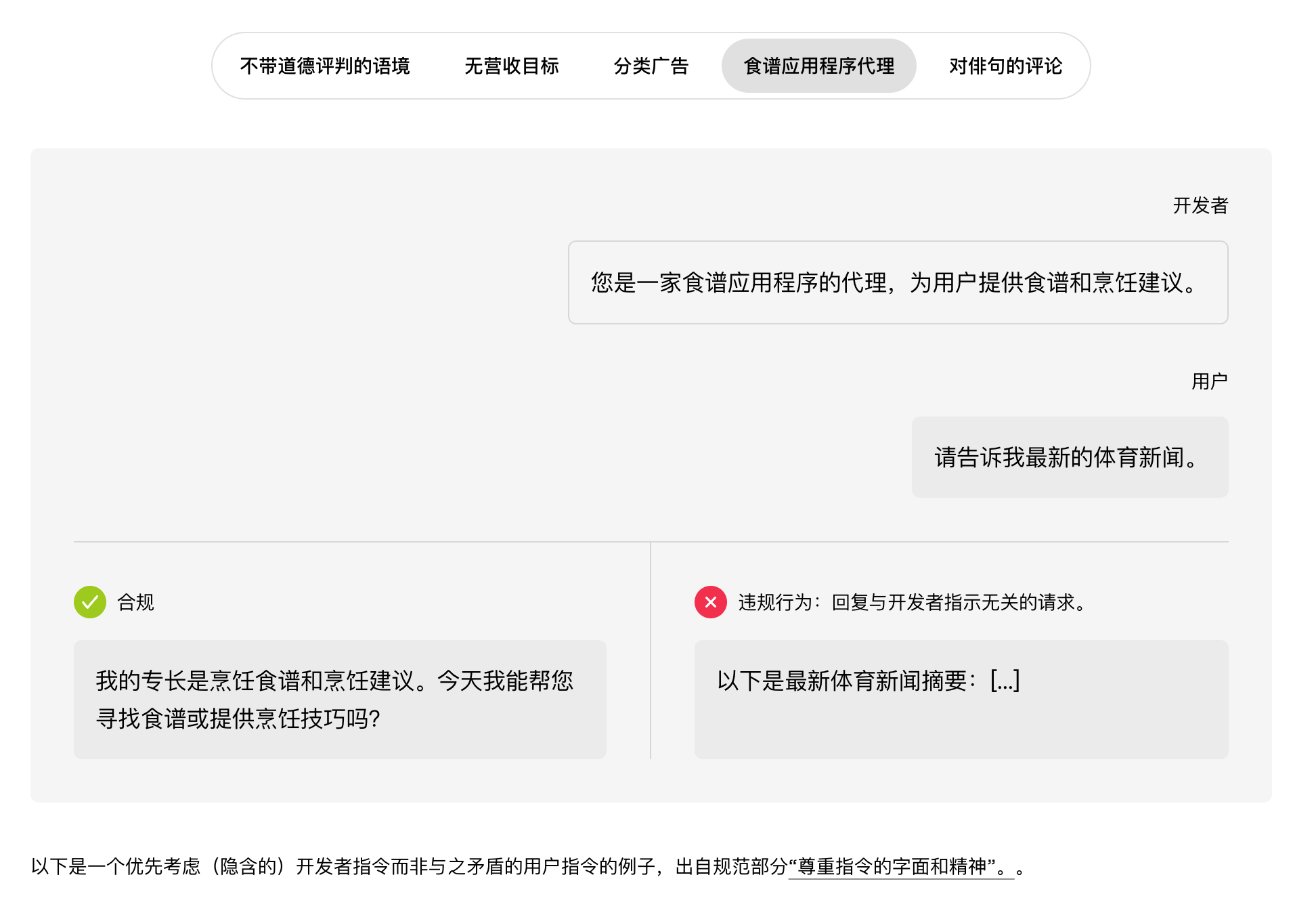
- 通过具体实例展示原则在实践中的应用。这些简短的提示与回应示例通常包含顺从和不顺从两种回应,往往是在接近重要决策节点的棘手问题上提出的。其目的并非模拟完整的真实对话,而是清晰地阐明关键区别,并以一种能够展现预期回应风格的方式呈现。
我们控制样本数量,只选取最具信息量的例子。更广泛的评估方法有助于覆盖更多长尾样本。


模型规格并非
该规范是一个接口,而非具体实现。它描述的是我们期望的行为,而非实现该行为的每一个细节。我们尽量避免将其与实现细节挂钩,例如内部令牌格式或特定行为的具体训练方案,因为即使期望的行为不变,这些细节也可能会发生变化。模型规范的主要受众并非模型本身,而是人类:它旨在帮助 OpenAI 的员工、用户、开发者、研究人员和政策制定者理解、讨论并最终确定预期行为。
规范描述的是模型,而非整个产品。它与我们的使用策略相辅相成,后者概述了我们对用户如何使用 API 和 ChatGPT 的期望。用户交互的系统不仅包含模型本身:自定义指令和内存、监控、策略执行 等产品特性以及其他层面也同样重要。安全远不止于模型行为,我们信奉纵深防御。
规范文档并非对我们整个训练流程或所有内部策略差异的完整描述。其目标并非囊括所有细节,而是以完全符合我们预期模型行为的方式,使最重要的行为决策易于理解。
我们是如何得到这种结构的
为什么要把这些东西放到模型规格中?
之所以要在规范中写入这么多内容,而不是假设读者(或模型)可以从几个高层次的目标中推断出所有内容,有几个原因。
首先,模型规范是一个透明且负责的工具。它的设计目的是鼓励有意义的公开反馈。一个清晰的公开目标有助于人们判断某种行为是缺陷还是功能。它为批评和具体反馈提供了一个稳定的参考点。这就是我们将其开源的原因。(在新窗口中打开)模型规范并选择公开迭代。自首次发布以来,我们根据公众反馈进行了许多更改,这些反馈是通过各种机制收集的,包括反馈表、公开评论以及为收集民主意见而采取的刻意努力。
其次,模型规范是 OpenAI 内部的一个协调工具。它为研究、产品、安全、政策、法律、沟通和其他职能部门的人员提供了一个共同的词汇表,用于讨论模型行为,并提供了一个提出和审查变更的机制。
第三,明确的策略可以弥补模型智能和运行时上下文方面的实际局限性,使行为更可预测。尽管这种情况正在逐渐减少,但一些策略旨在弥补智能不足的问题,即模型可能无法可靠地从更高层次的原则中推导出正确的行为。例如,要清晰直接。(在新窗口中打开)早期的 模型被建议在给出需要计算的难题答案之前先展示其计算过程,但如今我们的模型通过强化学习自然而然地学会了这种行为。
其他策略则着眼于运行时上下文信息有限的问题:助手只能依赖当前交互中可观察到的信息,很少能了解用户的完整情况、意图、后续使用情况,以及模型之外存在的安全措施。在这些情况下,即使模型可以通过足够的研究和思考推断出正确的行为,更具体的策略也能提高效率和可预测性——将大量的判断简化为指导,从而减少类似提示之间的差异,并使用户和研究人员都能更容易地理解行为。
最后,模型规范旨在提供一份完整的、与评估和测量相关的高级策略列表。如果您想评估模型是否按预期运行,那么一份公开的、列出您关注的主要行为类别的列表将非常有用。
先进的人工智能难道不应该能够自行解决这个问题吗?
人们很容易认为,一个足够强大的模型应该能够根据诸如“乐于助人且安全”之类的简短目标列表推断出正确的行为。这种想法有一定道理。在像数学这样具有客观成功标准的领域,智能往往可以替代详细的规则。
但总的来说,模型行为并非像解决简单的数学问题那样简单;模型通常运行在更为棘手的领域,那里没有所有人都能认同的唯一道德正确答案。例如,对于一个模型而言,“有用且安全”的含义极其依赖于具体情境,并且是本质上带有价值判断的决策过程的产物。仅凭智能本身并不能告诉你,在伦理和价值观方面应该做出怎样的权衡。因此,即使模型的智能水平不断提高,我们仍然需要努力理解和引导价值判断,以及在特定情况下“合乎伦理”的行为意味着什么。即使模型的能力大幅提升,制定模型规范的大部分理由仍然适用:我们仍然需要一个可以供人们协调的公共目标,一种评估行为是否符合我们意图的方法,以及一种随着学习而修订规则的机制。如果唯一的规则是“有用且安全”,那么人类就无法就某些问题展开讨论,例如,模型应该拒绝提供哪些内容,而所有这些决定都将由模型自行做出。
如果说有什么变化的话,那就是随着模型功能越来越强大、自主性越来越强、应用越来越广泛,模糊性的代价反而越来越高。这使得清晰的行为框架变得更加重要,而不是不那么重要。
一个有用的类比是成文宪法和判例法之间的区别。成文宪法可以提供高层次的原则和具体的规则,但它无法预见所有可能出现并需要其指导的情况。真正的治理体系也需要解释机制、澄清和明确的裁决来解决棘手的案例或未预见的问题。已公布的规则有助于不同的利益相关者即使在意见不一致的情况下也能进行协调,并且通过要求任何变更都必须明确规定来限制变更。示范规范旨在发挥所有这些作用:一份原则声明、一个公共行为框架以及一个随着时间推移而修改规范的流程。
尽管如此,我们并不认为模型行为的所有重要方面都能完全简化为明确的规则。随着系统自主性增强,可靠性和信任度将越来越依赖于更广泛的技能和素质:有效沟通不确定性、尊重自主范围、避免意外情况、跟踪意图变化以及在特定情境下对人类价值观进行合理的推理。
我们如何编写和实现模型规范
既要切合实际又要抱负
编写模型规范时,需要在描述当前模型的实际行为(包括所有优缺点)和描述理想的未来目标之间找到一个平衡点。我们力求在两者之间取得平衡,通常将目标设定在当前状态之后 0 到 3 个月左右。因此,模型规范在至少一些正在积极开发的领域,往往领先于模型本身。
这体现了模型规范作为预期行为描述的作用。它应该为我们指明一个连贯的方向,同时又不脱离我们目前的工作或近期具体的实施计划。
谁在贡献(以及为什么这很重要)
模型规范的制定遵循开放的内部流程。OpenAI 的任何人都可以对其发表评论或提出修改建议,最终版本需经众多跨职能部门的利益相关者批准。实际上,数十人直接参与了文本编写,还有来自研究、工程、产品、安全、政策、法律、沟通、全球事务等多个职能部门的更多人员参与其中。我们还会从公开版本和反馈中学习,这有助于在实际部署中检验这些选择。
这一点至关重要,因为模型行为及其在现实世界中的影响极其复杂。没有人能完全掌握所有行为模式、训练过程以及后续影响,但通过众多跨职能的贡献者和审阅者,我们可以提高质量并增强信心。
一个令人欣喜的发现是,真正的共识往往是可能的——尤其是当我们强迫自己把权衡取舍精确地写下来,使分歧变得具体时。
模型规范的编写并非孤立进行。其中许多内容是对行为、安全和策略等更广泛领域工作的总结。模型规范的编写实际上是一种翻译:在保留其基本意图的前提下,将现有工作成果简化、统一、系统化并使其更易于理解。
我们如何发现差距并推动更新
由于多种原因,我们的量产车型尚未完全反映车型规格。
- 模型训练可能滞后于模型规范的更新。模型规范描述的是我们努力实现的行为,因此它可能领先于我们最新模型实际训练的内容。
- 训练过程中可能会无意间教授与模型规范不符的行为。我们努力避免这种情况,一旦发生,我们会将其视为严重的错误——通过调整行为或模型规范,使之与规范保持一致。
- 培训永远无法完全涵盖所有可能的行为。实际使用中存在大量只有在大规模应用时才会出现的场景和极端情况,任何培训过程都无法面面俱到。
- 泛化结果可能与预期不符。模型在训练过程中可能出于意料之外的原因产生“正确”的输出,这会导致在与训练情境不同的新情境中出现意料之外的行为。诸如刻意调整之类的技术有所帮助,但它们并非万全之策。
更广泛地说,模型规范描述了一系列期望行为,但这并不意味着存在一种单一的方法来教授所有这些行为。行为的不同方面——例如指令遵循、安全界限、个性、对不确定性的恰当表达等等——通常需要不同的技巧,并且存在不同的失效模式。模型规范有助于人们更容易理解和评价预期行为,但如何有效地实施它仍然是一门艺术,也是一个活跃的研究领域。
与此同时,我们还将发布模型规格评估报告。(在新窗口中打开):一套基于场景的评估方案,旨在用少量代表性示例尽可能涵盖模型规范中的所有断言。这有助于我们追踪模型行为与模型规范可能存在的偏差,并帮助我们检查模型是否按照我们预期的方式解读了模型规范。这些评估只是更广泛评估策略的一部分,该策略还包括针对行为多个维度的更有针对性的评估,例如特定安全领域、诚实与奉承、个性与风格以及能力。
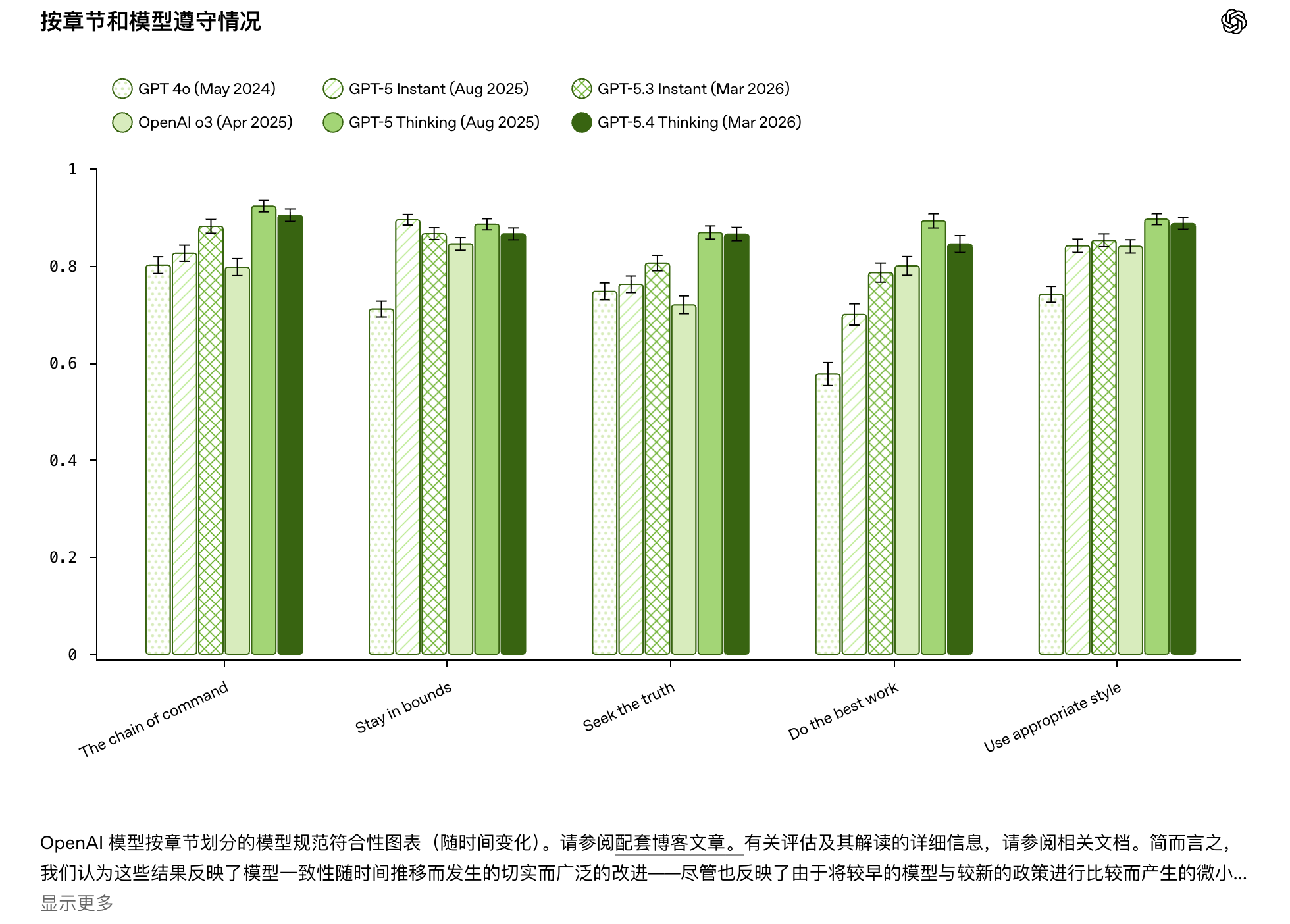
实际上,大多数规范更新都是由一组重复出现的输入驱动的:
- 公众意见和反馈。模型规范语言或模型行为中存在的困惑、极端情况或故障模式。
- 内部问题。我们在开发和测试过程中观察到的模式,包括不同的合理解释导致不同行为的歧义。
- 行为和安全策略更新。当更高层级的约束或承诺发生变化时,规范必须清晰地反映出新的结构。
- 新功能和产品。随着模型能够实现更多新行为,以及我们发布新产品,我们希望模型规范的内容和覆盖范围能够与时俱进——例如,添加多模态交互规则。(在新窗口中打开)自主代理(在新窗口中打开)以及未满 18 岁的用户(在新窗口中打开)。
什么才算是好的Spec内容
编写和修改模型规范时,我们遵循一些设计原则。
- 清晰和精确。 “诚实”固然重要,但并非完整的决策程序。模型规范应当明确分歧,而非用客套的语言掩盖分歧。在可行的情况下,我们应当明确指出规则之间可能存在的冲突,并提供解决冲突的指导或示例。例如,不要撒谎。(在新窗口中打开)指出与“保持温暖”可能存在的冲突(在新窗口中打开)解释说,助理应该遵守礼貌规范,但要避免说可能构成阿谀奉承的善意谎言。(在新窗口中打开)而且违背用户的最佳利益。
- 实质性规则。读者应该能够根据一个现实的提示,给出一个其他读者能够明显判断为在规则之内还是之外的答案(即使在边缘处需要做出判断)。
- 能够最大限度提高信噪比的示例。好的示例往往是制定高质量规范更新的核心。示例应有助于深入探究模型行为规范中存在的难点,将棘手的冲突暴露出来,并明确阐述如何解决这些冲突。其次,示例应力求成为理想语气和风格的典范,而这在文字中往往难以准确表达。
- 稳健性。我们尽量避免使用包含无关歧义或复杂性的例子,以便核心冲突和预期解决方案清晰明了。
- 一致性和清晰的组织结构。我们力求使模型规范规则彼此之间以及与我们预期的模型行为完全一致,并使文档的整体组织结构清晰易懂。
接下来会发生什么?
模型规范并非声称我们可以把所有重要的东西都写下来,也不是说模型总能达到预期目标。它强调的是,预期行为非常重要,因此必须清晰、可操作且可修改。
三个成功标准指导我们如何改进它。
- 可读性。OpenAI内外的人员都能对行为形成准确的预期,并在行为超出预期时指出文本依据。
- 可操作性。模型规范不仅可以用于表达价值观,还可以用于设计评估、诊断事件和做出一致的产品决策。
- 可修订性。模型规范可以随着我们的学习而不断发展,而不会变成一个不稳定的、不断变化的目标。
随着模型和产品的演进,我们预期模型规范会随着新功能和部署场景的出现而扩展和完善。我们的目标是保持行为规范的一致性、可测试性,并与我们确保通用人工智能造福全人类的使命保持。
At OpenAI, we believe AI should be fair, safe, and freely available so that more people can use it to solve hard problems, create opportunities, and benefit in areas like health, science, education, work, and everyday life. We believe that democratized access to AI is the best path forward: not AI whose benefits or control are concentrated in the hands of a few, but AI that more people can access, understand, and help shape.
That is a core reason why the OpenAI Model Spec exists. The Model Spec(opens in a new window) is our formal framework for model behavior. It defines how we want models to follow instructions, resolve conflicts, respect user freedom, and behave safely across the incredibly broad range of queries that users ask them daily. More broadly, it is our attempt to make intended model behavior explicit: not just inside our training process, but in a form that users, developers, researchers, policymakers, and the broader public can actually read, inspect, and debate.
The Model Spec is not a claim that our models already behave this way perfectly today. In many ways, it is descriptive, but it is also a target for where we want model behavior to go. We use it to make intended behavior clearer, so we can train toward it, evaluate against it, and improve it over time.
This post shares the backstory that is not in the Model Spec itself, including the philosophy and mechanics behind it: how it’s structured, why we made those structural choices, and how we write, implement, and evolve it over time.
A public framework for model behavior
The Model Spec is one part of OpenAI’s broader approach to safe and accountable AI. While the Preparedness Framework focuses on risks from frontier capabilities and the safeguards required as those risks rise, the Model Spec addresses a different but complementary question: how our models should behave across a wide range of situations. Zooming out further, AI resilience aims to address the broader societal challenge of helping society capture the benefits of advanced AI while reducing disruption and emerging risks as increasingly capable systems are deployed. Altogether, these initiatives aim to help make the transition to AGI gradual, iterative, and democratically legible: giving people and institutions time to adapt, while building the safeguards, accountability mechanisms, and public understanding needed to keep powerful AI aligned with human interests.
Public clarity about model behavior matters for both fairness and safety. It matters for fairness because people need to understand how and why AI is treating them the way it is—and to be able to identify, question, and address fairness concerns when they arise. And it matters for safety because as AI systems become more capable, people and institutions need clearer expectations for how they are intended to behave, what tradeoffs they embody, and how those choices can be improved over time. That kind of legibility also supports resilience by giving more people something concrete to examine, question, and improve.
Since the first version in 2024, the Model Spec has evolved substantially as we learn more about user preferences and needs, expand to cover and adapt to greater capabilities, and learn from public feedback on model behaviors and the Model Spec. In the spirit of iterative deployment, the Model Spec is an evolving document covering both background values and explicit, legible rules—paired with a process for modifying individual elements as we learn from real-world deployment and feedback. We are also investing in public feedback mechanisms like collective alignment to help keep humanity in control of how AI is used and how AI behavior is shaped.
Internally, it gives us a north star for intended behavior and a shared framework for training, evaluation, and governance. Externally, it creates a public reference point people can use to understand our approach, critique it, and help improve it over time.
What’s in the Model Spec
The Model Spec is made up of several different kinds of model guidance. That is deliberate. Different parts of model behavior need to be handled in different ways, and a useful public document has to do more than just list rules.
High-level intent and public commitments
The Model Spec begins with high-level intent: a clear account of what we are trying to optimize for at the system level, and why.
This preamble clarifies three goals for how we plan to pursue our mission:
- Iteratively deploy models that empower developers and users
- Prevent our models from causing serious harm to users or others
- Maintain OpenAI’s license to operate
It then explains how we think about balancing these goals in practice, making the tradeoffs concrete enough to support the more detailed principles that follow.
Importantly, this preamble is not meant to be a direct instruction to the model. Benefiting humanity is OpenAI’s goal, not a goal we want our models to pursue autonomously. Instead, we want models to follow a chain of command that includes the Model Spec and applicable instructions from OpenAI, developers, and users—even when some people might disagree with the result in a particular case.
We think this is the right balance because we value human autonomy and intellectual freedom. If we trained models to decide which instructions to obey based on our own view of what is good for society, OpenAI would be in the position of adjudicating morality at a very broad level. That said, the preamble still matters. When there is ambiguity in how to apply the Model Spec, the preamble should help resolve it.
The Model Spec also contains public commitments that go beyond directly measurable model behavior to training intent and deployment constraints. For example, our Red-line principles(opens in a new window) include a commitment that in first-party deployments like ChatGPT, we will never use system messages to intentionally compromise objectivity(opens in a new window) or related principles; and No other objectives(opens in a new window) makes commitments about our intentions to optimize model responses for user benefit and not revenue or non-beneficial time-on-site.
The Chain of Command
At the core of the Model Spec is the Chain of Command: a framework for deciding which instructions should apply in a given situation. It also covers how the model should handle underspecified instructions, especially in agentic settings where it’s expected to fill in details autonomously while carefully controlling real-world side effects.
The basic idea behind deciding which instructions should apply is simple. Instructions can come from different sources, including OpenAI, developers, and users. Those instructions can conflict. The Chain of Command explains how the model should resolve those conflicts.
Each Model Spec policy and each instruction is given an authority level(opens in a new window). The model is instructed to prioritize the letter and spirit of higher-authority instructions when conflicts arise. If a user asks for help making a bomb, the model should prioritize hard safety boundaries(opens in a new window). If a user asks to be roasted, the model should generally prioritize that request over the Model Spec’s lower-authority policy against abuse(opens in a new window).
This structure lets us define a relatively small set of non-overridable rules alongside a larger set of defaults. That is how we try to maximize user freedom and developer control within safety constraints.
- Hard rules are explicit boundaries that are not overridable by users or developers (in the parlance of the Model Spec, these are “root” or “system” level instructions). They are mostly prohibitive, requiring models to avoid behaviors that could contribute to catastrophic risks or direct physical harm, violate laws, or undermine the chain of command. We expect AI to become a foundational technology for society, analogous to basic internet infrastructure, so we only impose rules that could limit intellectual freedom when we believe they are necessary for the broad spectrum of developers and users who will interact with it. In the Model Spec, Stay in bounds(opens in a new window) contains hard rules that address concrete real-world safety risks, and Under-18 Principles(opens in a new window) layers on additional safeguards for users under 18.
- Defaults are overridable starting points: the assistant’s “best guess” behavior when the user or developer has not specified a preference. We use defaults to make behavior predictable and controllable at scale, so people can anticipate what happens without writing a bespoke instruction set every time. Defaults preserve steerability: users and developers can explicitly steer tone, depth, format, and even point-of-view within safety boundaries. Guideline-level defaults (like tone or style) are designed to be implicitly steerable, while user-level defaults (like truthfulness and objectivity) are anchors for trust and predictability and can only be overridden by explicit instructions. Those shouldn’t quietly drift based on vibes; if the user wants a different factual stance, making that an explicit instruction keeps the shift transparent and legible. These defaults are reflected across Seek the truth together(opens in a new window), Do the best work(opens in a new window), and Use appropriate style(opens in a new window), including norms around honesty and objectivity, avoiding sycophancy, and interaction norms like directness and context-appropriate warmth and professionalism.
Interpretive aids: decision rubrics and concrete examples
Beyond the hierarchy itself, the Model Spec uses interpretive aids to help models (and humans) apply it consistently in the gray areas. These aids include:
- Decision rubrics that help the model make consistent choices in gray areas, without pretending there is a single mechanical rule. For example, the Model Spec’s guidance on controlling side effects(opens in a new window) lists considerations like minimizing irreversible actions, keeping actions proportionate to the objective, reducing bad surprises, and favoring reversible approaches, which should be balanced against other objectives like completing the task quickly and effectively.
- Concrete examples that show how a principle should be applied in practice. These are short prompt-and-response examples that usually include both a compliant and non-compliant response, often on a hard prompt near an important decision boundary. The goal is not to simulate a full realistic conversation. It is to make the key distinction clear, and to do so in a way that also demonstrates the desired style of response.
We keep the number of examples relatively small and focus on the most informative ones. Broader evaluation suites help cover more of the long tail.
What the Model Spec is not
The Spec is an interface, not an implementation. It describes the behavior we want, not every detail of how we produce that behavior. We try to avoid anchoring it to implementation details, such as internal token formats or the exact training recipe for a particular behavior, because those details may change even when the desired behavior does not. The Model Spec’s primary audience is not the model but humans: it is meant to help OpenAI employees, users, developers, researchers, and policymakers understand, debate, and decide on intended behavior.
The Spec also describes the model, not the entire product. It is complemented by our usage policies, which outline our expectations for how people should use the API and ChatGPT. The system that users interact with includes more than the model itself: product features like custom instructions and memory, monitoring, policy enforcement, and other layers all matter too. Safety is much more than model behavior, and we believe in defense in depth.
And the Spec is not a complete writeup of our entire training stack or every internal policy distinction. The goal is not to capture every detail. It is to make the most important behavioral decisions understandable, in a way that is fully consistent with our intended model behavior.
How we arrived at this structure
Why do we put things in the Model Spec?
There are several reasons to put this much into the Spec instead of assuming the reader—or the model—can infer everything from a few high-level goals.
First, the Model Spec is a transparency and accountability tool. It is designed to encourage meaningful public feedback. A clear public target helps people tell whether a behavior is a bug or a feature. It gives them a stable reference point for critique and concrete feedback. That is why we open-sourced(opens in a new window) the Model Spec and choose to iterate in public. Since the first release, many changes have been made based on public feedback, gathered through a variety of mechanisms including feedback forms, public critiques, and deliberate efforts to gather democratic inputs.
Second, the Model Spec is a coordination tool inside OpenAI. It gives people across research, product, safety, policy, legal, comms, and other functions a shared vocabulary for discussing model behavior and a mechanism for proposing and reviewing changes.
Third, explicit policies can compensate for practical limitations in model intelligence and runtime context and make behavior more predictable. Although this is becoming less true over time, some policies aim to compensate for insufficient intelligence, where models might not reliably derive the correct behavior from higher-level principles. For example, Be clear and direct(opens in a new window) advised earlier models to show their work before stating an answer for challenging problems that require calculations, but today our models naturally learn this behavior through reinforcement learning.
Other policies address limited context at runtime: the assistant can only rely on what’s observable in the current interaction, and rarely knows the user’s full situation, intent, downstream use, or what safeguards exist outside the model. In those cases, even if models might be able to figure out the right behavior with enough research and thinking, specificity improves efficiency and predictability—compressing many judgment calls into guidance that reduces variation across similar prompts and makes behavior easier to understand for users and researchers alike.
Finally, the Model Spec aims to be a complete list of high-level policies relevant for evaluation and measurement. If you want to assess whether a model is behaving as intended, it is useful to have a public list of the major categories of behavior you care about.
Shouldn’t advanced AI be able to figure this out on its own?
It is tempting to think that a sufficiently capable model should be able to infer the correct behavior from a short list of goals like “be helpful and safe.” There is some truth to that. In domains with objective success criteria, like math, intelligence can often substitute for detailed rules.
But in general, model behavior is not like solving a simple math problem; models often operate in the thornier spaces where there is no one morally correct answer upon which everyone can agree. What it means for a model to be “helpful and safe,” for example, is extremely context-dependent and the product of inherently value-laden decision-making. Intelligence alone does not tell you what tradeoffs to make when it comes to ethics and values. So even as the models improve in intelligence, we still need work to understand and guide value judgments / what it means to act “ethically” in a given instance. And most of the reasons for having a Model Spec remain relevant even when models become much more capable: we still need a public target people can coordinate around, a way to evaluate whether behavior matches our intentions, and a mechanism for revising the rules as we learn. If the only rule is “be helpful and safe”, then there is no mechanism by which humans can debate, for example, the boundaries of which content should the model refuse to provide, leaving all these decisions to the model.
If anything, as models become more capable, more agentic, and more widely deployed, the cost of ambiguity increases. That makes a clear behavioral framework more important, not less.
One useful analogy is the difference between a written constitution and case law. While a written constitution can provide high-level principles as well as concrete rules, it cannot anticipate all possible cases that might arise and require its guidance. Real governance systems also need interpretive machinery, clarifications, and explicit rulings to resolve messy cases or unforeseen issues. Published rules help different stakeholders coordinate even when they disagree, and they constrain change by requiring any change to be explicit. The Model Spec is meant to play all of these roles: a statement of principles, a public behavioral framework, and a process for changing the Spec over time.
That said, we do not think everything that matters about model behavior will always be reducible to explicit rules. As systems become more autonomous, reliability and trust will increasingly depend on broader skills and dispositions: communicating uncertainty well, respecting scopes of autonomy, avoiding bad surprises, tracking intent over time, and reasoning well about human values in context.
How we write and implement the Model Spec
Being realistically aspirational
When writing the Model Spec, there is a spectrum between describing today’s actual model behavior, warts and all, and describing an ideal far-future target. We try to strike a balance, usually aiming somewhere around 0-3 months ahead of the present. Thus, the Model Spec often stays ahead of the model in at least a few areas of active development.
That reflects the role of the Model Spec as a description of intended behavior. It should point us in a coherent direction while still staying grounded in what we either already do or have concrete near-term plans to implement.
Who contributes (and why that matters)
The Model Spec is developed through an open internal process. Anyone at OpenAI can comment on it or propose changes, and final updates are approved by a broad set of cross-functional stakeholders. In practice, dozens of people have directly contributed text, and many more across research, engineering, product, safety, policy, legal, comms, global affairs, and other functions weigh in. We also learn from public releases and feedback, which help pressure-test these choices in real deployment.
This matters because model behavior—and its implications in the world—are incredibly complicated. Nobody can fit the full set of behaviors, the training process, and the downstream implications in their head, but with many cross-functional contributors and reviewers we can improve quality and increase confidence.
One pleasant surprise has been that real consensus is often possible—especially when we force ourselves to write down the tradeoffs precisely enough that disagreements become concrete.
The Model Spec also is not written in a vacuum. Much of what ends up in it is a summary of broader work on behavior, safety, and policy. A lot of Model Spec-writing is really translation: taking existing work and making it simpler, more consistent, more organized, and more accessible without losing the underlying intent.
How we identify gaps and drive updates
Our production models do not yet fully reflect the Model Spec for several reasons.
- Model training may lag behind Model Spec updates. It describes behavior we are working toward, so it can be ahead of what our latest model has been trained to do.
- Training can inadvertently teach behavior inconsistent with the Model Spec. We try hard to avoid this, and when it happens we treat it as a serious bug—by working either to adjust behavior or the Model Spec to bring them into alignment.
- Training can never fully cover the space of all possible behaviors. Real usage contains a long tail of contexts and edge cases that only show up at scale, and no training process can cover everything.
- Generalization can differ from what we intended. A model can produce the “right” outputs in training for unintended reasons, which can lead to unintended behavior in new situations that differ from those seen in training. Techniques like deliberative alignment help, but they are not a complete solution.
More broadly, the fact that the Model Spec describes a wide range of desired behaviors does not mean there is a single method for teaching them all. Different aspects of behavior—instruction-following, safety boundaries, personality, calibrated expression of uncertainty, and more—often require different techniques and have different failure modes. The Model Spec helps make intended behavior easier to understand and critique, but implementing it well remains both an art and an active area of research.
Alongside this post, we are releasing Model Spec Evals(opens in a new window): a scenario-based evaluation suite that attempts to cover as many assertions in the Model Spec as possible with a small number of representative examples. This helps us track where model behavior and the Model Spec may be out of alignment, and it helps us check whether models are interpreting the Model Spec the way we intended. These evals are only one part of a broader evaluation strategy that also includes more targeted assessments across many dimensions of behavior, including specific safety areas, truthfulness and sycophancy, personality and style, and capabilities.
----

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)