打造Claude Code的宝藏经验!提示缓存就是一切
如果你体验过Claude Code,那种行云流水般的代码协作感背后,有一个概念功不可没:提示缓存(Prompt caching)。
Anthropic一篇官方博客文章告诉我们“缓存统治一切”,在AI智能体(Agent)的世界里,这句话是金科玉律。

为了极致的速度与成本,整个Claude Code的架构设计,都是围绕着一段不能随意变动的“文本前缀”来进行的。
从精心排列提示词的顺序,到死守不变的模型与工具集,再到设计巧妙的“Plan模式”和缓存安全的分叉压缩。Anthropic团队将这些来自实战一线的宝藏经验公开了。
给提示词排个队,越稳越靠前
提示缓存的工作原理很像一个苛刻的“前缀匹配”游戏。API会从你的请求开头开始匹配,只要内容一模一样,这部分计算就会被缓存复用。顺序在这里至关重要,牵一发而动全身。
Claude Code的策略是将最稳固的内容放在最前面。它的请求结构就像精心打包的行李箱,层次分明:

最外层是全局静态的系统提示词和工具定义,这部分对所有用户和会话都通用,是缓存命中率最高的部分。
紧接着是CLAUDE.md文件中的项目规则,在同一个项目中可以安全复用。
再往里是当前会话的上下文,只要还在这一轮对话中,它就保持不变。
最后,才是不断增长的、动态的对话消息。
这种先静态、后动态的布局,最大化了跨会话的缓存共享。
但这种精巧的设计也出奇的脆弱。团队有过不少次无意中打破缓存的教训。
比如,在静态系统提示词里塞进了一个精确到秒的时间戳;或者,工具定义的列表顺序因为某种非确定性算法而发生变动;再比如,仅仅是更新了某个工具的参数,像是修改了Agent工具可以调用的子智能体列表。
这些看似微小的改动,都会让整个前缀失效,导致缓存未命中。
想更新信息?别动提示词,发条消息就行。
执行任务时,信息很容易过时。比如系统里内置的时间不对了,或者用户修改了文件。一个直接的念头是去更新系统提示词里的内容,但这会立即引发缓存失效,对用户来说成本高昂。
Claude Code的做法是把这些更新当作下一轮对话的消息传递进去,而不是修改原有的提示词前缀。
他们会在下一条用户消息或工具返回的结果里,悄悄加入一个<system-reminder>标签,把最新的信息告诉模型。
这个小小的技巧,完美地保住了珍贵的缓存。
不改模型,不改工具
在同一个会话中途切换模型,听起来像是一个合理的省钱策略。
比如,当你用强大的Opus模型聊了10万个Token的上下文后,觉得下个简单问题可以用更便宜的Haiku模型来回答。但算一下账就会发现,这个操作实际上更贵。
原因是,提示缓存是跟特定模型绑定的。切换到Haiku后,之前为Opus构建的缓存全部作废,你需要为Haiku重新发送整个上下文并付费,成本反而更高。
真需要切换模型怎么办?
官方的做法是使用子智能体(subagents)。
可以让主模型Opus生成一个交接指令,然后派一个子智能体去用Haiku执行具体任务。
Claude Code的探索功能(Explore agents)就经常这么干,用Haiku来进行低成本的探索。
同样,在对话中增加或移除工具,是另一个常见的缓存破坏者。
你可能会想,模型当前不需要某个工具,那就别给它看了,省点Token。
但工具列表是缓存前缀的一部分,任何增减都会让整个会话的缓存瞬间失效。
Plan模式的精妙设计:把功能做成工具
Plan模式是围绕缓存约束设计功能的一个绝佳范例。
直觉上,进入Plan模式就该把编辑工具都换成只读工具。但如果这样做,缓存就断了。
Claude Code的做法是,从始至终保持工具集不变。
他们将EnterPlanMode和ExitPlanMode本身都当作工具。
当用户开启Plan模式时,模型并不会拿到新的工具列表,而是会收到一条系统消息,告诉它:“你现在已经进入Plan模式了,你的任务是探索代码库,不要编辑任何文件,规划完成后请调用ExitPlanMode工具。”
工具定义纹丝未动,缓存安然无恙。
这个设计还有一个额外的好处:因为进入Plan模式本身就是一个工具调用,模型可以在遇到难题时,完全自主地决定进入规划模式,整个过程没有任何缓存中断。
这个原则同样适用于大量MCP工具的加载。
如果一股脑全发出去,成本极高;但如果中途移除,又会破坏缓存。
他们的解决方案是“延迟加载”(defer_loading)。所有工具都以轻量级“存根”(stub)的形式存在,只包含工具名和一个defer_loading: true的标记。
当模型通过工具搜索发现并选中它时,才会去加载完整的工具模式。
这样一来,缓存前缀里始终只有那些稳定不变的轻量存根,既节省了输入成本,又保全了缓存。
压缩上下文,也要缓存安全
当上下文窗口快要塞满时,压缩(Compaction)就登场了。
这个过程会将漫长的对话历史总结成一个摘要,然后用这个摘要替代原始消息,开启一段新的会话。
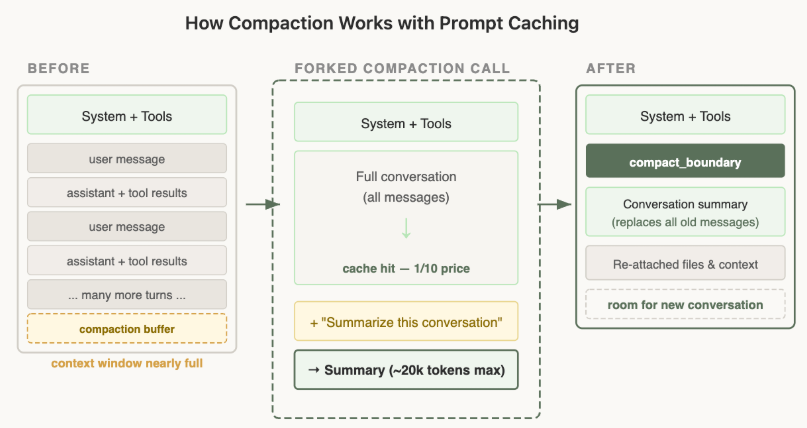
压缩与缓存的结合,是最容易踩坑的地方。
最直观的做法是发起一个新的API调用,用一个类似“总结这段对话”的系统提示,不带任何工具。但这正中成本陷阱。
原因很简单:这个新的总结请求,其系统提示和工具集与主对话完全不同。
两者的请求前缀从第一个Token开始就分道扬镳了,主对话的缓存完全没法复用。
你需要为传入的整个长对话,支付全额的、未缓存的输入费用。对话越长,这次总结就越昂贵。
Claude Code的解法是“缓存安全的分叉”(cache-safe forking)。
执行压缩时,他们创建的新请求,其系统提示词、用户上下文、会话上下文和工具定义,与父对话完全一致。
他们先把父对话的所有消息放进去,然后在最后面追加一个压缩指令,作为一个新的用户消息。
从API的视角看,这个新请求跟父对话的最后一个请求几乎一模一样。
相同的前缀,相同的工具,相同的历史。因此,那庞大的缓存前缀得以完全复用。唯一新增的Token,只是末尾那条压缩指令本身。聪明至极。
当然,这个机制需要精心预留一个“压缩缓冲区”,确保有足够的上下文窗口空间来容纳压缩指令和生成的摘要。
基于这些经验,Anthropic已经将压缩功能直接内置到了API中,方便开发者直接在自己的应用里运用这些模式。
来自一线的缓存心法
Claude Code团队关于优化提示缓存的实用模式:
提示缓存是严格的前缀匹配。前缀里任何位置的任何改动,都会让它后面所有内容缓存失效。整个系统的设计都应该围绕这个约束展开。顺序摆对了,大部分缓存就是免费的。
用消息,而不是修改系统提示词。想切换Plan模式?更改日期?把这些信息塞进对话的消息里,比直接修改系统提示词划算得多。
中途坚决不换模型和工具。用工具来模拟状态切换(比如Plan模式),用延迟加载来代替移除工具。
像监控在线率一样监控缓存命中率。团队对缓存错过设置了警报,并将其当作事故来处理。少掉几个百分点的缓存命中率,都会对成本和延迟产生巨大影响。
任何分叉操作,都必须和父进程共享前缀。需要运行一个计算侧任务(比如压缩、总结、技能执行)时,使用与父进程完全相同的、缓存安全的参数。
Claude Code从第一天起就被设计成围绕提示缓存来构建。
如果你也打算动手打造下一个伟大的智能体,不妨也从这条规则开始。
参考资料:
https://claude.com/blog/lessons-from-building-claude-code-prompt-caching-is-everything

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献101条内容
已为社区贡献101条内容

所有评论(0)