(论文速读)UniConvNet: 意尺度卷积神经网络在保持渐近高斯分布的同时扩展有效接受野
论文题目:UniConvNet: Expanding Effective Receptive Field while Maintaining Asymptotically Gaussian Distribution for ConvNets of Any Scale(任意尺度卷积神经网络在保持渐近高斯分布的同时扩展有效接受野)
会议:ICCV2025
摘要:具有大有效感受野(ERF)的卷积神经网络(ConvNets)仍处于早期阶段,但受到高参数和FLOPs成本以及中断渐近高斯分布(AGD)提供ERF的限制,已显示出良好的有效性。本文提出了一种替代范例:与其仅仅使用非常大的ERF,不如通过适当组合较小的内核(如7×7, 9×9, 11×11)来扩展ERF,同时保持AGD提供ERF,这样更有效和高效。本文介绍了一种三层感受野聚合器,并从感受野的角度设计了一层算子作为基本算子。在保持ERF的AGD的前提下,通过所提出的模块栈将ERF扩展到现有的大核卷积神经网络的水平。使用这些设计,我们提出了一个通用的模型,任何规模的ConvNet,称为UniConvNet。在ImageNet-1K、COCO2017和ADE20K上进行的大量实验表明,UniConvNet在各种视觉识别任务上的表现优于最先进的cnn和ViTs,无论是轻量级模型还是大规模模型,都具有相当的吞吐量。令人惊讶的是,UniConvNet-T在30M参数和5.1G FLOPs下达到了84.2%的ImageNet top-1精度。此外,UniConvNet-XL在大数据和大型模型上也显示出了具有竞争力的可扩展性,在ImageNet上获得了88.4%的前1准确率。
代码和模型可在https://github.com/ai-paperwithcode/UniConvNet上公开获得。
UniConvNet:在保持渐近高斯分布的同时扩展有效感受野
1. 背景与动机
卷积神经网络(ConvNets)在计算机视觉领域有着悠久而辉煌的历史。然而,随着 Vision Transformer(ViT)的兴起,如何让卷积网络也能建立长程依赖成为了研究热点。一个核心思路是扩大有效感受野(Effective Receptive Field,ERF)——让每个输出像素能"看到"更大范围的输入区域。
1.1 已有工作的两条路线
路线一:堆叠小核(如3×3)
以 ResNet 为代表的传统方案通过大量堆叠3×3卷积来间接扩大感受野。这类方案的 ERF 遵循渐近高斯分布(Asymptotically Gaussian Distribution,AGD)——越靠近输出像素中心的输入像素影响越大,这与人类视觉直觉一致,如图1(A)所示。然而,其 ERF 范围较小,难以捕获全局上下文。
路线二:直接使用超大卷积核
近年来,RepLKNet(31×31核)、SLaK(51×51稀疏核)、UniRepLKNet 等工作通过重参数化、参数共享或稀疏化技术,将卷积核直接放大到极大尺寸,ERF 范围显著扩大。但代价是:
- 参数量和计算量(FLOPs)极高;
- 破坏了 AGD——ERF 在奇怪位置出现高响应,或不同尺度像素的影响趋于均匀(见图1(B)(C))。
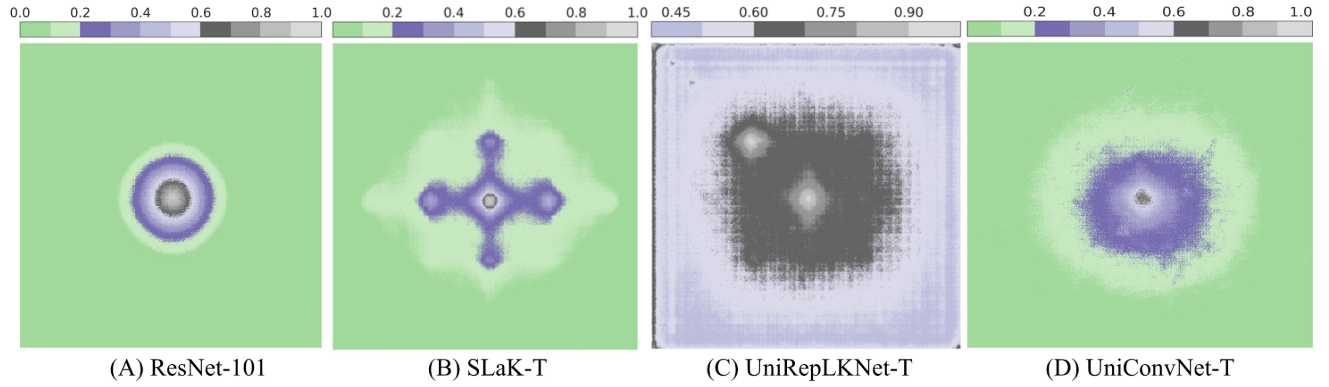
【配图位置:图1——ResNet-101、SLaK-T、UniRepLKNet-T、UniConvNet-T 的 ERF 热力图对比,展示 AGD 特性与 ERF 范围的差异】
可能的意思是:
A) ResNet-101 — 小核堆叠的典型代表
热力图呈现出非常标准的同心圆渐变,从中心向外颜色均匀变暗。这就是理想的渐近高斯分布(AGD):离中心越近影响越大,离中心越远影响越小,过渡自然连续。缺点是亮区范围很小,说明感受野范围有限,"看不远"。
(B) SLaK-T — 51×51稀疏大核
热力图出现了奇怪的十字形或星形亮斑,说明某些远离中心的特定位置反而比近处的像素影响更大。这就是AGD被破坏的典型表现——影响分布不符合"近大远小"的直觉,模型在"乱看"。
(C) UniRepLKNet-T — 超大核重参数化
热力图的亮区范围非常大(感受野很广),但整体近乎均匀的灰色,没有明显的从中心向外递减的层次感。这意味着远处和近处的像素影响差不多大,AGD同样被严重破坏,相当于模型"看得很远但不知道该重点看哪里"。
(D) UniConvNet-T — 本文提出的方法
热力图呈现出清晰的多层同心圆渐变,且亮区范围比ResNet-101大得多。这说明UniConvNet同时做到了两件事:感受野足够大(能"看得远"),同时保持了良好的AGD("越近越重要")。论文把这种多层清晰渐变称为"more stepped colour area",层次越多越分明,说明AGD质量越好。
1.2 核心问题
本文作者提出一个关键问题:
是否存在一种合适的小核组合方式,能在扩大 ERF 的同时,保持 ERF 的渐近高斯分布?
答案是肯定的。作者提出了一种全新范式:与其使用极大的 ERF,不如通过适当组合较小的卷积核(如7×7、9×9、11×11)来扩展 ERF 同时保持 AGD,这样更高效也更有效。
2. 方法详解
本文的核心贡献是设计了感受野聚合器(Receptive Field Aggregator,RFA),并以此为基础构建了通用卷积网络 UniConvNet。
2.1 层操作算子(Layer Operator,LO)
LO 是 RFA 的基本构建单元,其设计出发点是直接从感受野视角出发来建模像素的影响分配。每个 LO 有三个不同的输入分支,通过两个子模块相互配合:
放大器(Amplifier,Amp)
- 将输入
经过大核(K×K)深度卷积 + GELU 激活后,与
做逐元素乘法;
- 这一操作的效果是:在 K×K 感受野范围内,每个位置的像素被该位置在
- 结果:扩展了感受野范围,同时放大了感受野内显著像素的影响。
判别器(Discriminator,Dis)
- 将输入
经过大核(K×K)和小核(k×k,k=3)深度卷积处理;
- 为大感受野引入来自小尺度新像素的影响,建立两层判别性AGD;
- 结果:在大感受野的基础上,靠近中心的小尺度像素也保有更强的响应。
最终,Amp 和 Dis 的输出被拼接,得到具有双层 AGD 的输出特征图 ,通道数也相应递增以供后续层使用。
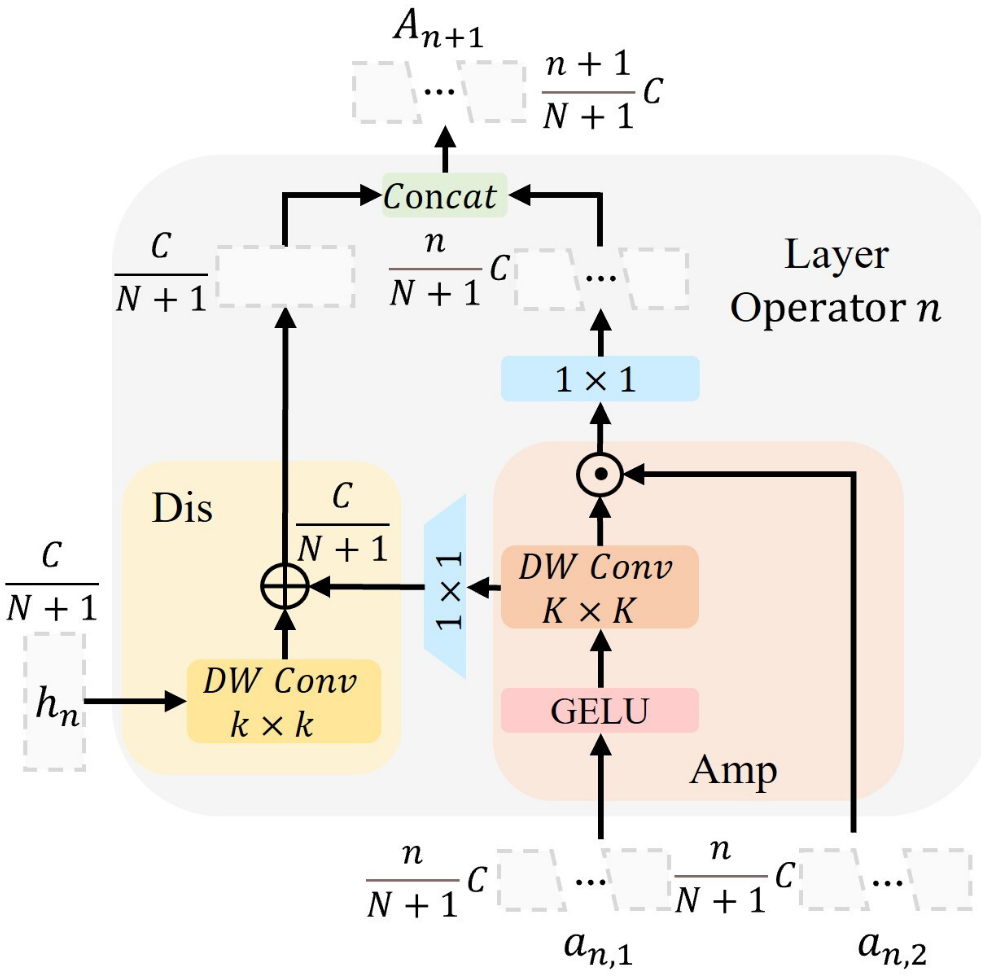
【配图位置:图3(右)——Layer Operator 的结构示意图,展示 Amp 和 Dis 两个子模块的连接关系】
2.2 感受野聚合器(RFA)
RFA 将多个 LO 按金字塔方式递归组织,其核心设计如下:
- 输入沿通道维度被分成 N+1 个头:
;
先进入 LO 1,输出
(通道数从
增长到
);
交互,输出
,通道继续递增……
- 以此类推,形成金字塔递增的通道结构,大幅降低了参数量和 FLOPs;
- 每个头在进入 LO 之前先经过 1×1 卷积投影,以增强特征多样性。
这种金字塔结构直接对不同尺度的感受野分配判别性影响,使得从中心到边缘形成连续的 AGD。
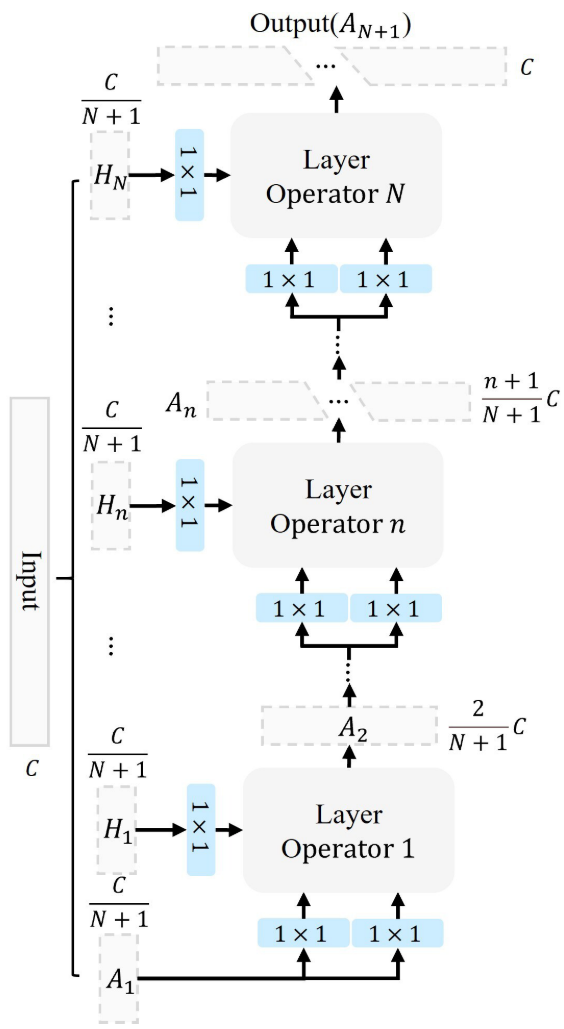
【配图位置:图3(左)——RFA 整体结构示意图,展示 N+1 个头的金字塔通道递增方式】
2.3 三层 RFA 的感受野流动
针对224×224分辨率的输入图像,作者采用 N=3 的三层 RFA,渐进大核尺寸按公式 (
)计算,依次为 7×7、9×9、11×11,小核固定为 3×3。
感受野的扩展过程如下:
- LO 1:7×7卷积建立第一层大感受野,3×3卷积引入小尺度判别信息,形成双层AGD;
- LO 2:在LO 1输出的感受野基础上,9×9卷积继续扩展,再次引入3×3小尺度信息;
- LO 3:11×11卷积进一步扩展,最终形成四层感受野,从中心到边缘完整遵循AGD。
整个过程类似"滚雪球"——每一层 LO 都在上一层感受野的基础上进行放大和判别,最终在一个轻量级模块内达到与大核网络相当的 ERF 范围,同时保持良好的 AGD。
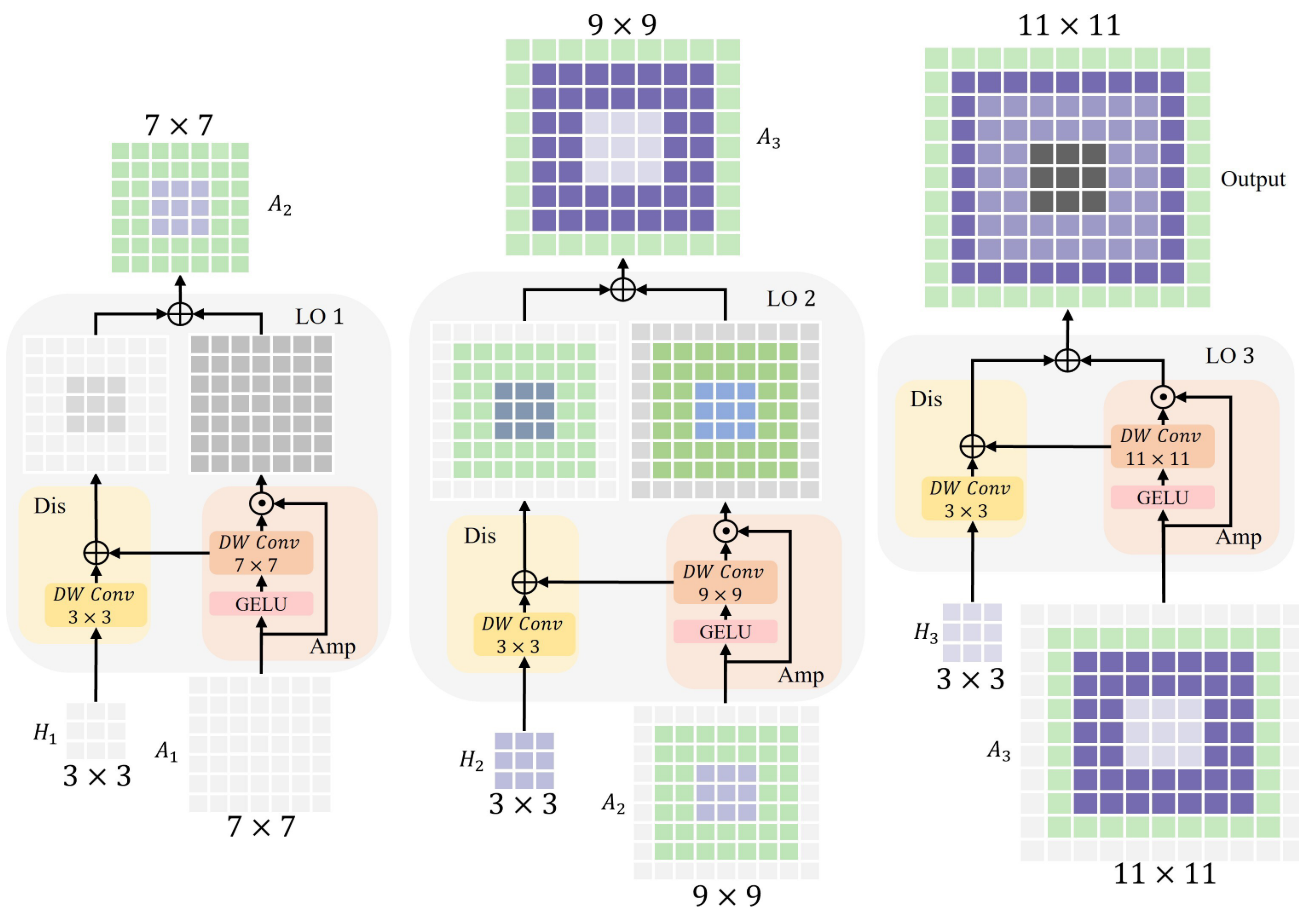
【配图位置:图4——三层RFA的感受野流动示意图,直观展示7×7→9×9→11×11的逐层扩展过程】
为什么选7×7、9×9、11×11?
- 7×7 比3×3、5×5 提供大得多的感受野,是扩展 ERF 的有效起点;
- 11×11 能在主特征提取阶段(Stage 3 的14×14特征图)保持合理的覆盖范围(padding=5 时,角落像素最多覆盖特征图的四分之一),避免中心像素过度重叠;
- 消融实验表明(见 表7),(7,9,11) 是效率与效果的最优配置:(5,7,9) 对 ERF 扩展不足,(9,11,13) 对深层模型的参数效率较低,极大核(27,29,31)则既不高效也不有效。
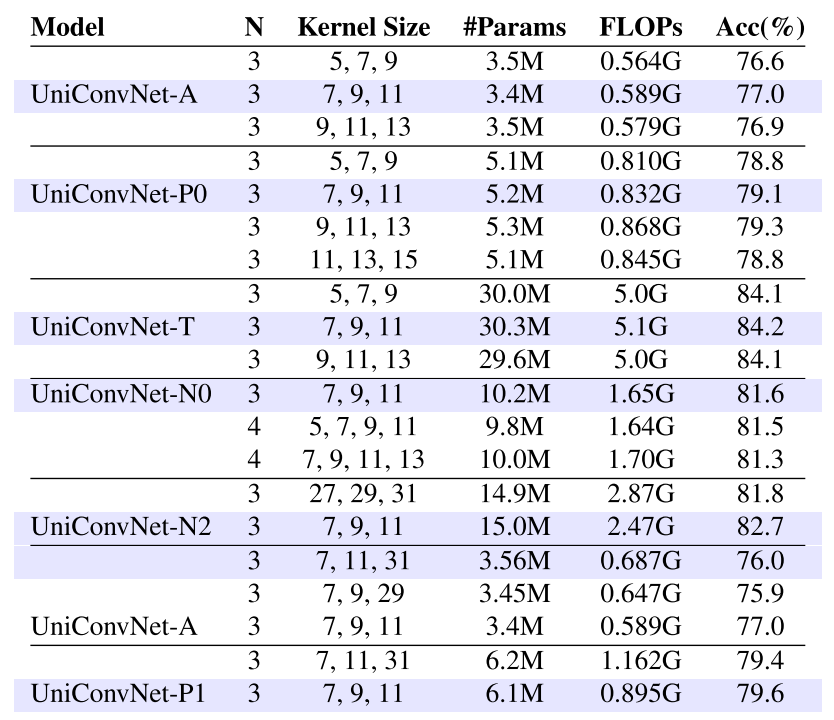
【配图位置:表7——核尺寸和层数的消融实验结果,对比不同配置下的参数量、FLOPs和Top-1精度】
2.4 UniConvNet 整体架构
UniConvNet 以 InternImage 为基础骨干,将三层 RFA 替换其中的关键卷积操作,并采用与 ConvNeXt、InternImage 类似的金字塔架构:
- Stem 块:由两个步长为2的3×3卷积 + LayerNorm + GELU 构成,将输入分辨率降低4倍;
- 下采样块:LayerNorm + 步长为2的3×3卷积,每阶段将分辨率减半;
- 基础块:包含三个残差子组件——三层RFA、修改版DCNV3(去除softmax归一化)、前馈网络(FFN);
- 完整模型从 UniConvNet-A(3.4M参数)到 UniConvNet-XL(226.7M参数),覆盖全尺度需求。
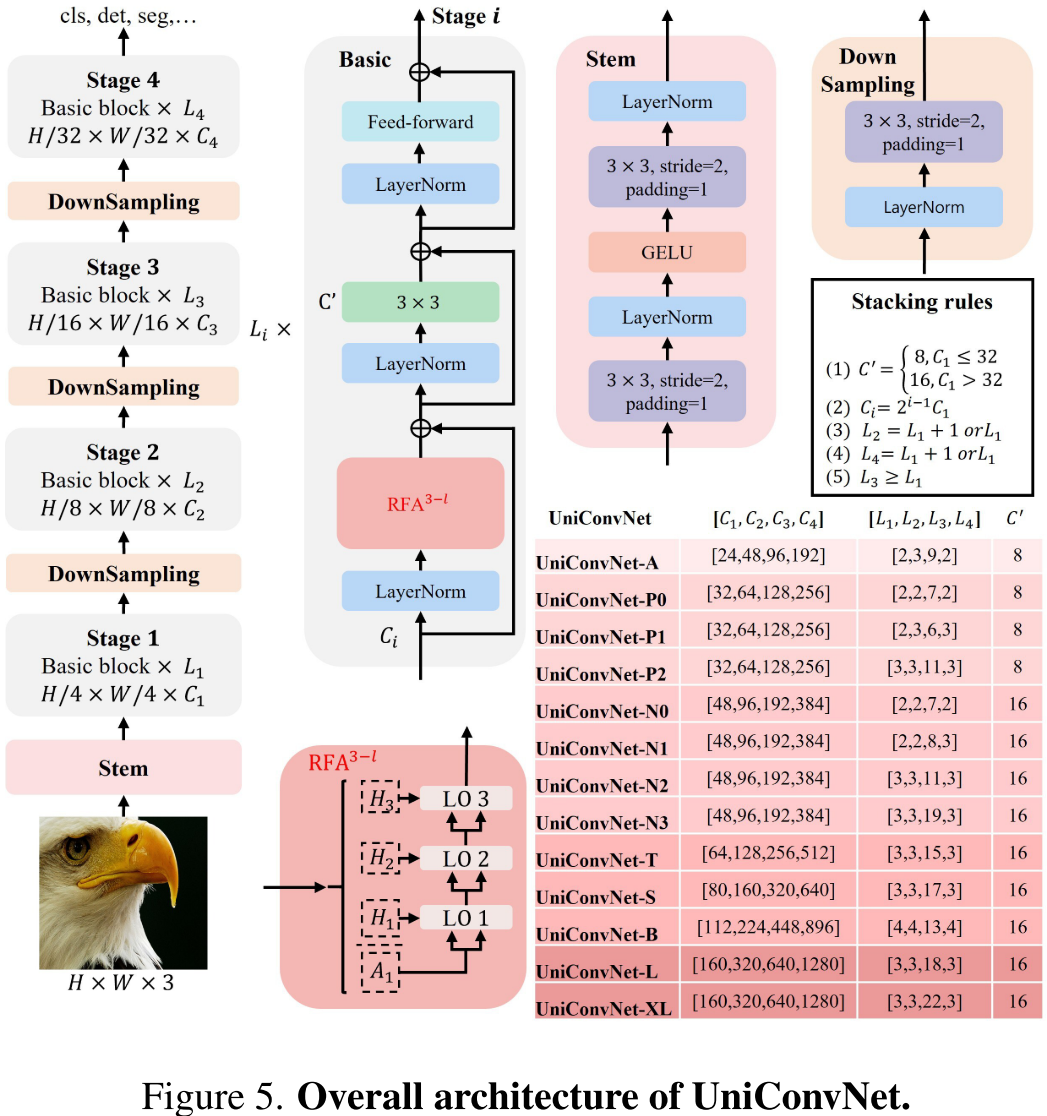
【配图位置:图5——UniConvNet整体架构图,展示四个Stage、Stem、下采样块及基础块的组成,以及各变体的通道配置】
3. 实验结果
3.1 ImageNet-1K 图像分类
轻量级模型对比:UniConvNet 的轻量级系列在相近参数量和FLOPs下全面超越现有纯CNN和混合ViT模型。以代表性结果为例:
- UniConvNet-N1(13.1M参数,1.88G FLOPs):82.2% Top-1,超越同量级的UniRepLKNet-N(18.3M,81.6%),在更少参数下获得更高精度;
- UniConvNet-N2(15.0M参数,2.47G FLOPs):82.7%,超越HorNet-T(23.0M,83.0%)的同时参数仅为其65%;
- UniConvNet-N3(19.7M参数,3.37G FLOPs):83.2%,与UniRepLKNet-T(31.0M)并列,但参数量仅为其63%。
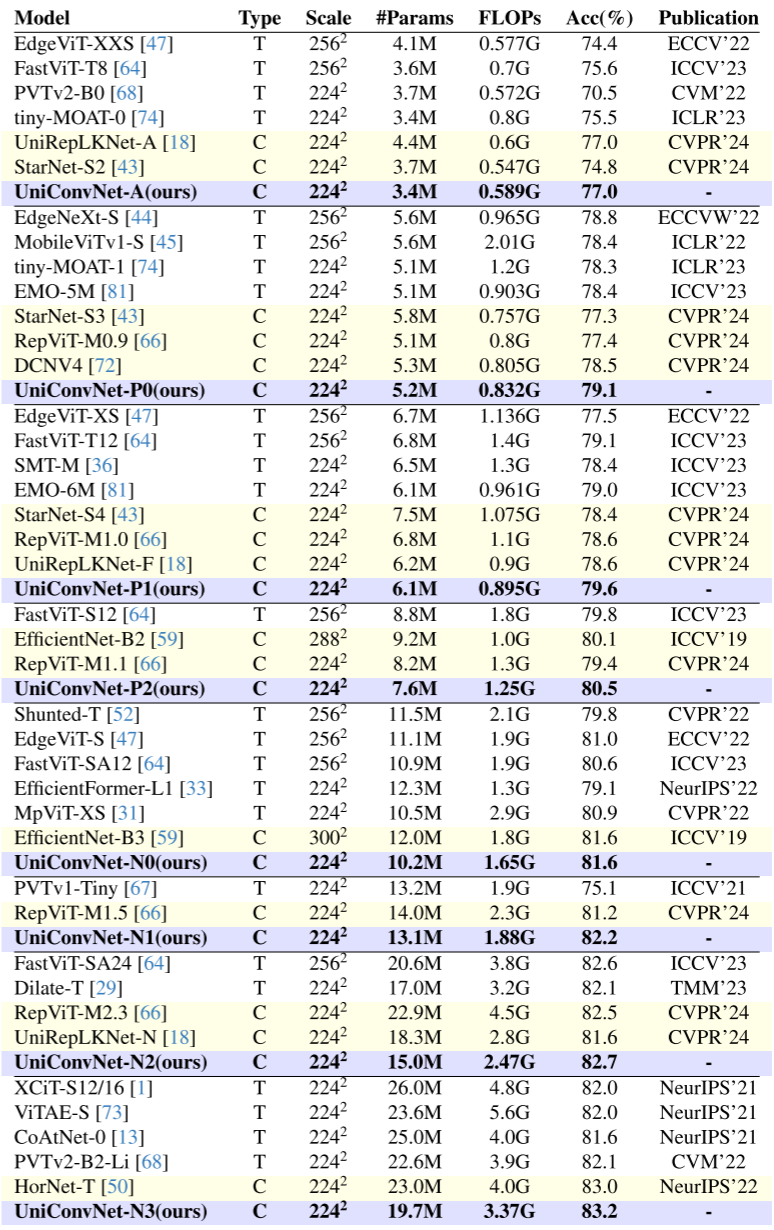
【配图位置:表1——轻量级变体在ImageNet验证集上的分类性能对比,涵盖ViT和CNN各系列代表模型】
大规模模型对比:
- UniConvNet-T(30.3M参数,5.1G FLOPs):84.2%,超越 InternImage-T(83.5%)、FlashInternImage-T(83.6%)、SLaK-T(82.5%),在相近参数下领先至少0.6个百分点;
- UniConvNet-S(50M参数,8.48G FLOPs):84.5%,超越 FlashInternImage-S(84.4%);
- UniConvNet-B(97.6M参数,15.9G FLOPs):85.0%,超越 InternImage-B(84.9%);
- UniConvNet-L(201.8M,预训练于ImageNet-22K):88.2%,与MOAT-3(188.0M,141.2G FLOPs)持平,但FLOPs更低;
- UniConvNet-XL(226.7M,预训练于ImageNet-22K):88.4%,超越 InternImage-XL(88.0%)和 FlashInternImage-L(88.1%)。
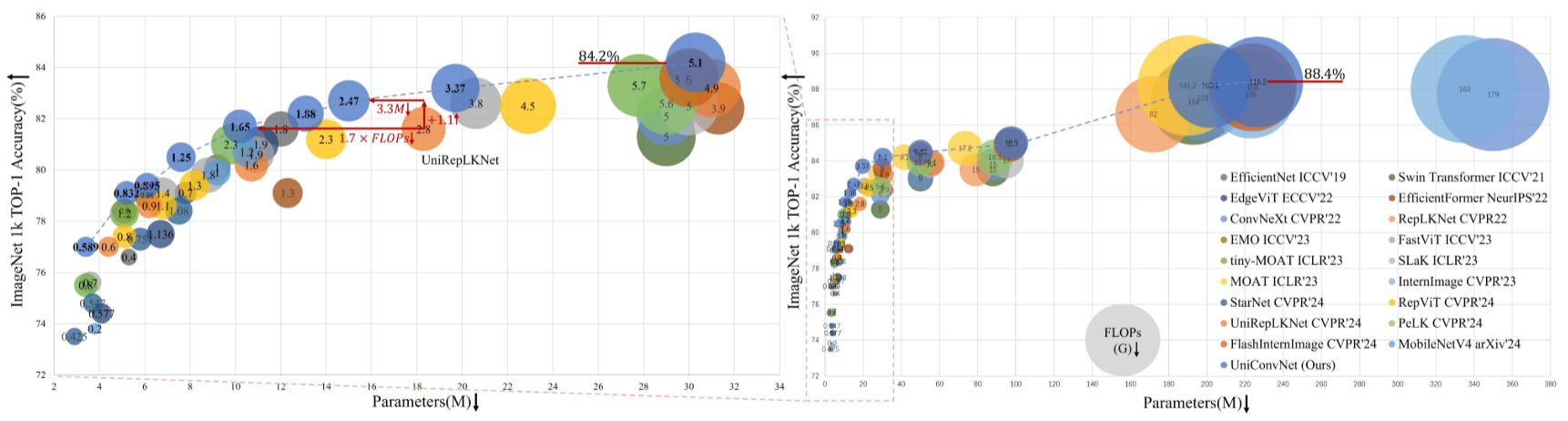
【配图位置:图2——UniConvNet与其他模型的参数量-精度及FLOPs-精度气泡图对比,直观展示帕累托前沿优势】
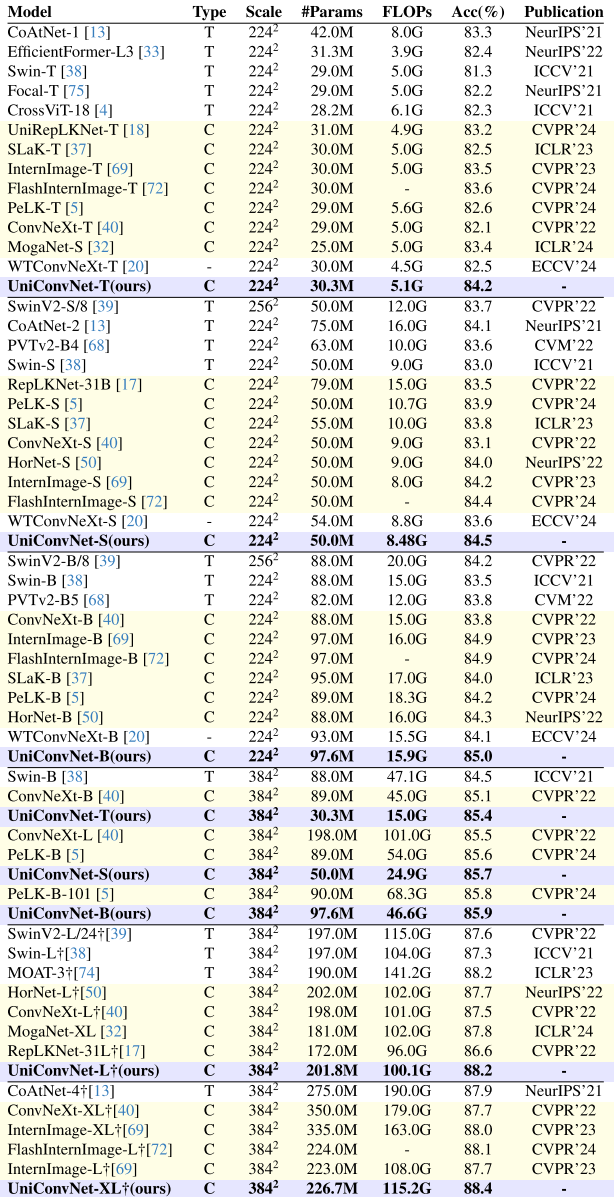
【配图位置:表2——大规模变体在ImageNet验证集上的分类性能对比】
3.2 目标检测与实例分割(COCO2017)
使用 RetinaNet(重型检测头)和 SSDLite(轻型检测头)在 COCO val2017 上评估轻量级变体:
- UniConvNet-A 在 SSDLite 框架下达到 29.5 mAP,超越同量级的 MobileViTv1-Small(27.7 mAP)和 EMO-5M(27.8 mAP),FLOPs更低(1.3G vs. 3.4G);
- UniConvNet-N2 在 RetinaNet 框架下达到 45.5 mAP,超越 Shunted-S(45.4 mAP,32.1M参数)且参数更少(26.0M)。
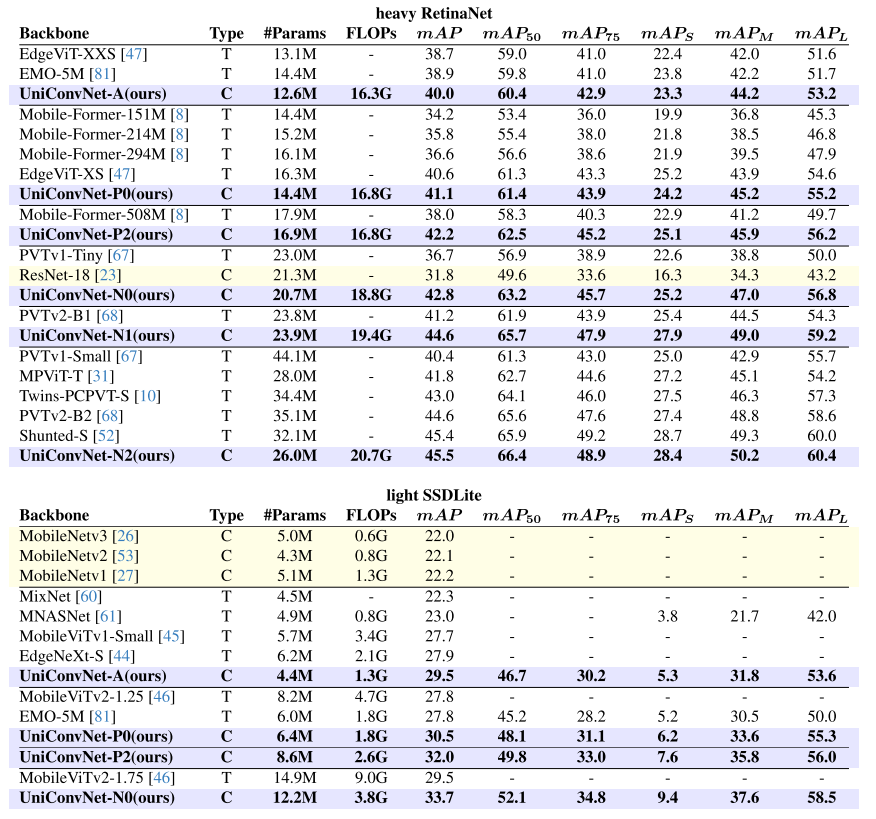
【配图位置:表3——RetinaNet和SSDLite框架下的目标检测结果对比】
使用 Mask R-CNN 和 Cascade Mask R-CNN 评估大规模变体:
- UniConvNet-T 在 Mask R-CNN 1× 下达到 48.2 box AP,超越 FlashInternImage-T(48.0);在 3× 训练下达到 50.1 box AP,实例分割达到 44.5 mask AP;
- UniConvNet-L 在 Cascade Mask R-CNN 3× 下达到 56.6 box AP 和 48.9 mask AP,超越 FlashInternImage-L(56.7 box AP,48.9 mask AP)中的 mask AP持平,box AP微低,但参数相近(254.8M vs. 277M)。
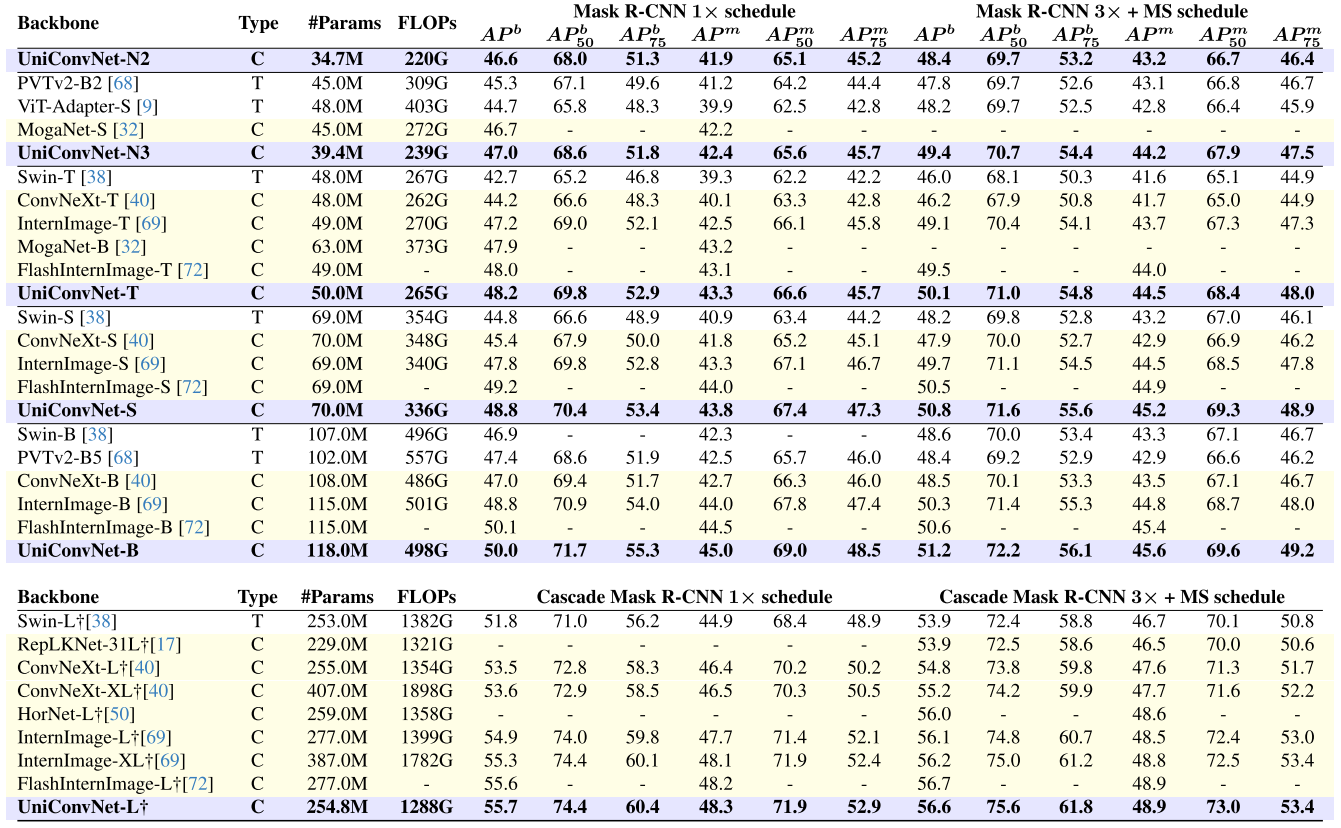
【配图位置:表4——Mask R-CNN和Cascade Mask R-CNN框架下的目标检测与实例分割结果对比】
3.3 语义分割(ADE20K)
轻量级模型(DeepLabv3 / PSPNet):
- UniConvNet-A 在 DeepLabv3 下达到 38.2 mIoU,超越 EMO-5M(37.8 mIoU),参数更少(7.9M vs. 10.3M);
- UniConvNet-N2 达到 42.9 mIoU,以22.5M参数超越 ResNet-50(42.4 mIoU,68.2M参数),参数量仅为后者的33%。
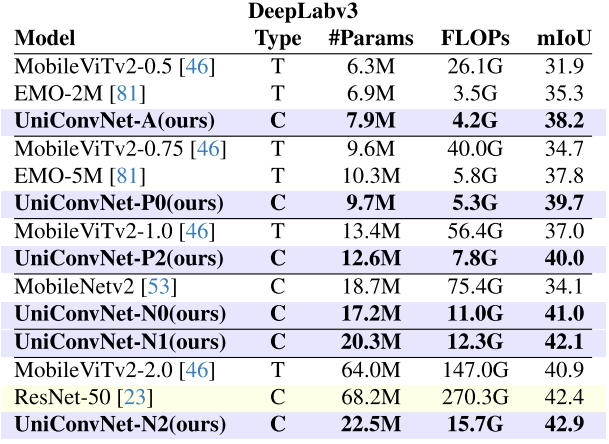
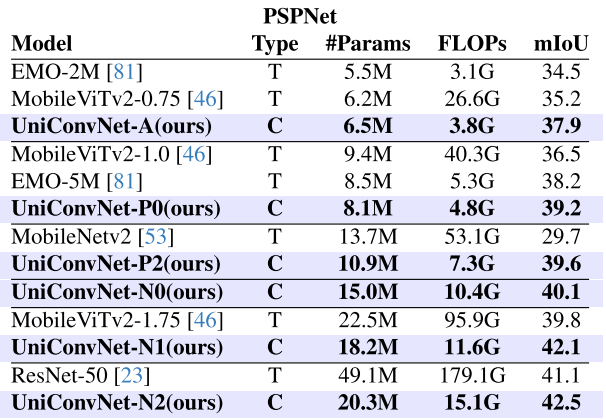
【配图位置:表5——DeepLabv3和PSPNet框架下的语义分割结果对比】
大规模模型(UperNet):
- UniConvNet-T 达到 50.3 mIoU(单尺度),超越 FlashInternImage-T(49.3)和 UniRepLKNet-T(48.6),参数相近;
- UniConvNet-S 达到 52.2 mIoU,超越 FlashInternImage-S(50.6)和 MogaNet-L(50.9);
- UniConvNet-L 达到 55.1 mIoU(单尺度),超越 InternImage-XL(55.0,368M参数),而 UniConvNet-L 仅有234M参数。
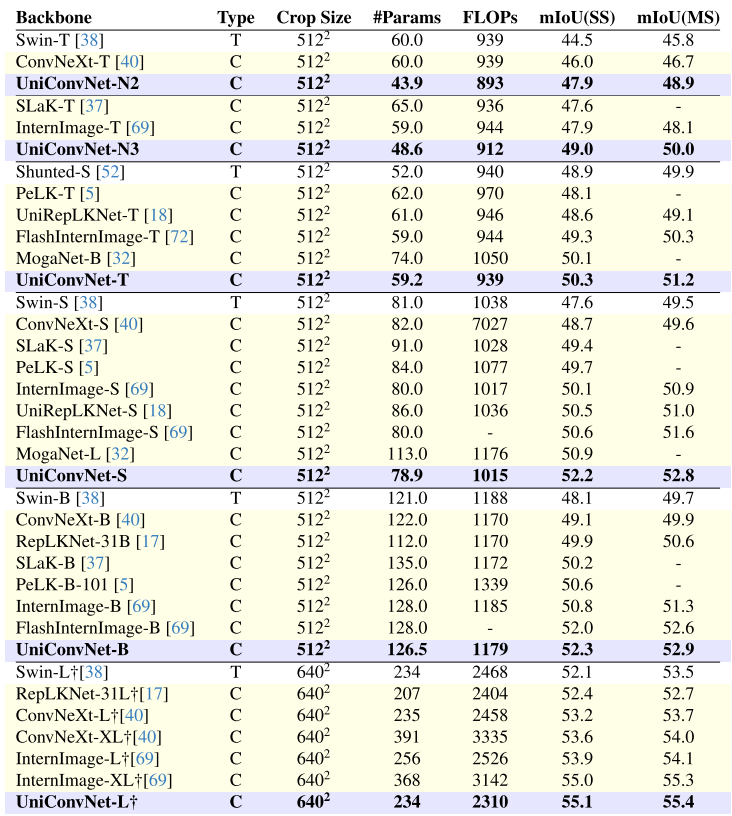
【配图位置:表6——UperNet框架下ADE20K语义分割结果对比】
4. 深入分析
4.1 为什么 AGD 比 ERF 范围更重要?
作者在附录 A 中给出了深刻的分析。通过对多组模型的 ERF 可视化(图6),可以得出以下结论:
- MogaNet-S vs. ConvNeXt-T:两者 ERF 范围相近,但 MogaNet-S 的 AGD 更好(小尺度像素响应更强)→ MogaNet-S 性能更优。这说明在 ERF 范围相当时,AGD 质量是决定性因素。
- SLaK-T vs. UniConvNet-T:两者 ERF 范围相当,但 UniConvNet-T 的 AGD 更好 → UniConvNet-T Top-1精度高出 1.7 个百分点。
- UniRepLKNet-T:拥有更大的 ERF,但 AGD 严重劣化(小尺度像素暗区明显)→ 尽管 ERF 更大,但受限于高参数和FLOPs,综合效率不如 UniConvNet-T。
- RepLKNet-31B vs. UniConvNet-B:前者 ERF 更大但 AGD 较差 → Top-1精度低 1.0 个百分点。


【配图位置:图6——多模型ERF热力图对比(UniConvNet-T、MogaNet-S、SLaK-T、ConvNeXt-T、UniRepLKNet-T、ResNet-101、UniConvNet-B、RepLKNet-31B),直观展示AGD质量差异】
核心结论:在 ERF 范围可比的情况下,对小尺度像素保持正确的渐近高斯分布,比单纯扩大 ERF 范围更重要。
4.2 效率分析
从各子模块的参数量和FLOPs分布(表8)可以看出,三层 RFA 相比修改版 DCNV3 具有更少或相近的参数和计算量,这意味着引入大感受野几乎不带来额外开销。
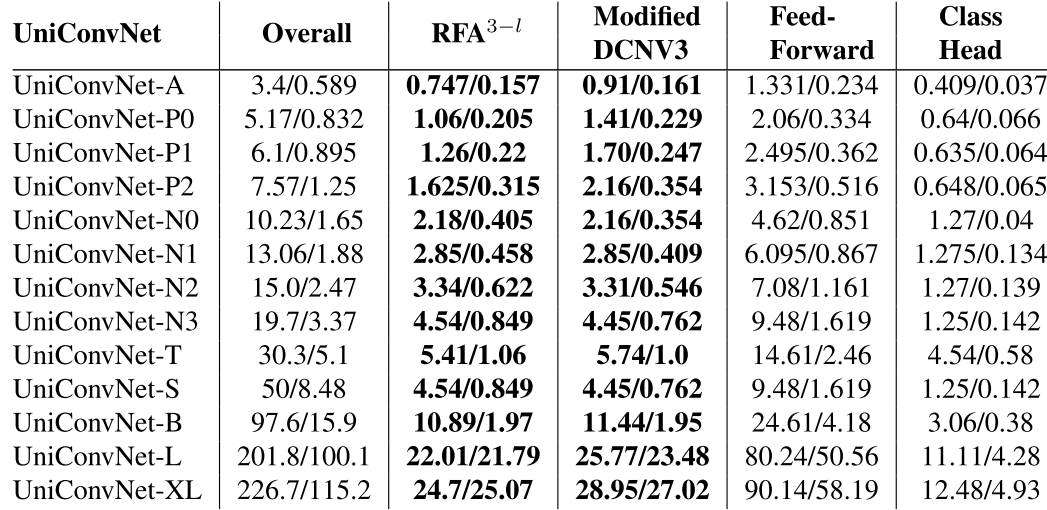
【配图位置:表8——UniConvNet各变体中不同子模块的参数量/FLOPs分布】
4.3 消融实验:模块组合的有效性
通过对 UniConvNet-P0(5.2M参数)、N2(15M)和T(30M)三个规模的消融(表9):
| 配置 | UniConvNet-P0 Top-1 |
|---|---|
| 三层RFA + Modified DCNV3(完整模型) | 79.1% |
| 仅三层RFA | 78.4% |
| 仅 DCNV4(FlashInternImage) | 78.5% |
| 三层RFA + DW 3×3 | 78.9% |
| DW 7×7 + DW 3×3(ConvNeXt风格) | 77.0% |
| 仅 DW 3×3 | 77.0% |
几个关键观察:
- 三层 RFA 单独使用即可达到与 DCNV4 相近的性能(78.4% vs. 78.5%),证明其特征感知能力不依赖于传统小核卷积;
- 将 Modified DCNV3 替换为 DW 3×3 仅下降 0.2%,说明 DCNV3 的作用是锦上添花;
- 将三层 RFA 替换为 DW 7×7 性能骤降至77.0%,充分证明三层 RFA 设计的有效性;
- 在15M和30M规模上,这一结论完全一致,体现了三层 RFA 的跨尺度泛化能力。
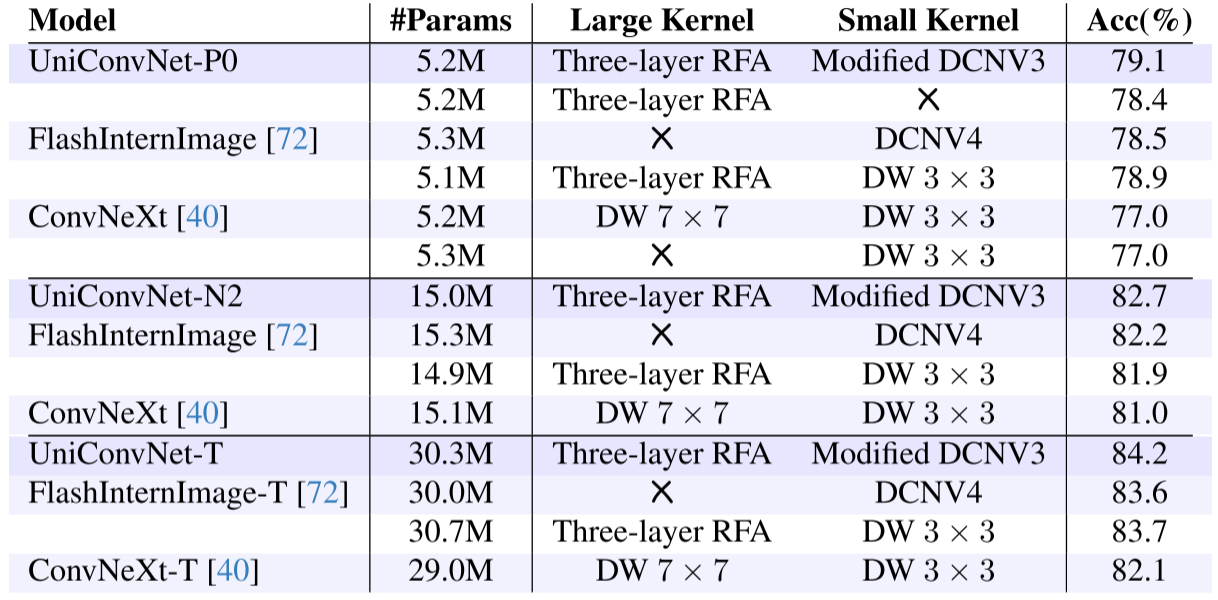
【配图位置:表9——不同大核/小核卷积组合的消融对比实验】
4.4 吞吐量分析
在 A100 GPU(PyTorch 1.13,FP32/FP16)上测试推理速度(表10):
- UniConvNet-T:1480/1825 images/s(FP32/FP16),相比 InternImage-T(1409/1746)提升约5%,而精度从83.5%提升至84.2%;
- UniConvNet-XL:168/228 images/s,相比 InternImage-XL(125/174)提升约34%(FP32),精度从88.0%提升至88.4%。
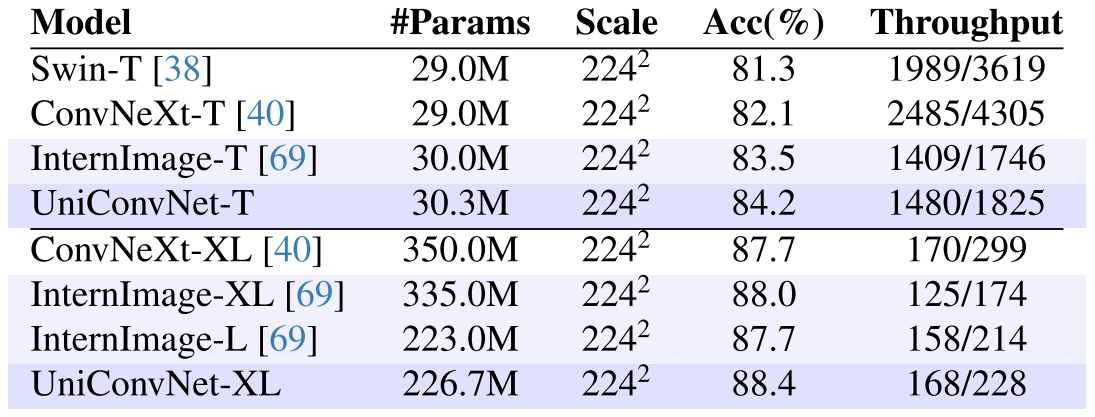
【配图位置:表10——UniConvNet与代表性模型的推理吞吐量对比】
5. 总结与展望
UniConvNet 提出了一条清晰的设计哲学:扩展有效感受野不必依赖极大卷积核,通过多层较小核的合理组合,同样可以达到甚至超越大核网络的效果,同时避免 AGD 的破坏和参数的膨胀。
三层RFA的核心贡献在于:
- 以7×7、9×9、11×11三种渐进核尺寸,构建出四层感受野的连续AGD;
- 通过放大器(Amp)和判别器(Dis)的协作,实现多尺度影响的精确分配;
- 金字塔通道递增结构确保参数效率,使得轻量到超大规模模型均可受益。
从ImageNet分类、COCO检测分割到ADE20K语义分割的全面实验表明,UniConvNet 在各规模、各任务上均达到了最先进水平,真正实现了"任意规模的通用卷积网络"这一目标。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 27
27 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)