CLIP 原理详解:图文对齐如何连接理解与生成
📚目录
📌 引言:CLIP 在解决什么问题?
在 CLIP 出现之前,大多数视觉模型的训练方式都很像:
依赖一个人工标注的数据集,让模型学习“图像 -> 类别”的映射关系。
以 ImageNet 为例,任务可以简化成:
输入一张图片 -> 输出一个类别(cat / dog / car)
这种方式在封闭场景下效果很好,但问题也很明显:
- 类别是预先定义好的,扩展性差
- 对没见过的类别几乎没有泛化能力
- 大规模人工标注非常昂贵
CLIP 论文《Learning Transferable Visual Models From Natural Language Supervision》提出了一个关键变化:
不再让模型只学习“这张图属于哪个标签”,而是让它学习“这张图和哪段文本更匹配”。
换句话说,模型优化目标从分类变成了对齐。
这个变化看起来只是把标签换成了文本,但它真正打开的是另一扇门:
模型开始借助语言来理解视觉内容,而不是只在固定标签集合里做选择。
一个更直观的类比是:
- 传统分类模型更像选择题
- CLIP 更像匹配题
前者只能在已有选项里选答案,后者则是在图像和语言之间建立可泛化的语义连接。
这也是为什么 CLIP 不只是一个“更强的分类器”,而是后来一整代多模态模型和生成模型的重要前置能力。
一、CLIP 的核心思想
CLIP 的核心可以用一句话概括:
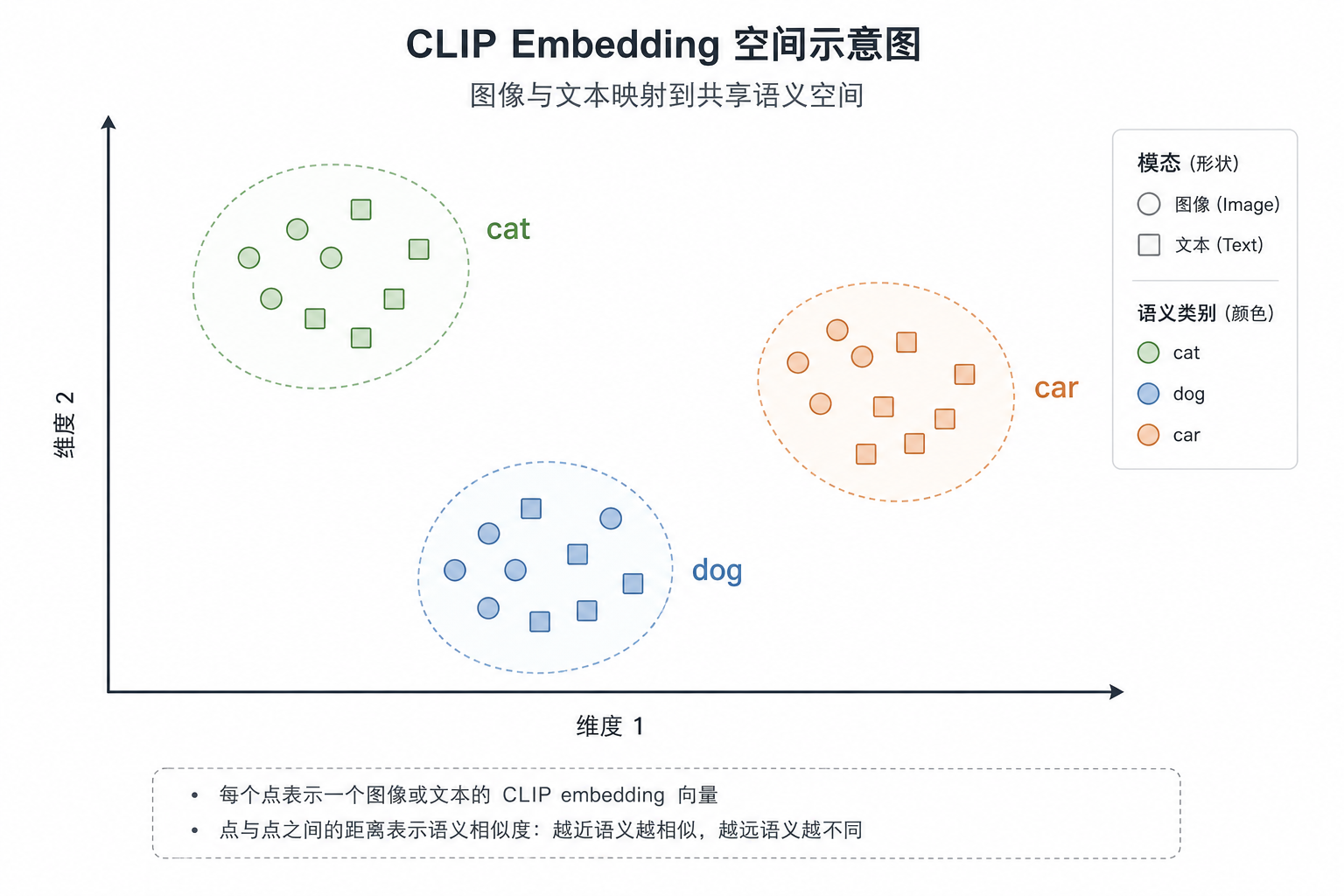
把图像和文本映射到同一个向量空间里,用距离表示它们是否在表达同一件事。
1.1 什么叫“同一个空间”?
可以把这个空间想象成一个“语义坐标系”。
在这个空间里:
- 语义接近的内容会被放在一起
- 语义不相关的内容会被拉开
例如:
"a cat"和一张猫的图片 -> 很近"a car"和一张猫的图片 -> 很远
这里最关键的不是“猫”和“车”这两个类别本身,而是模型开始学习一种跨模态的语义对应关系:
语言里的描述,和图像里的内容,最终可以放进同一套比较标准里。
1.2 这个空间能解决什么问题?
一旦这个空间学好了,很多任务都可以统一成同一个问题:
哪一段文本最接近当前图像?
这就是 CLIP 能做 zero-shot 分类、图文检索、跨模态排序的基础。
它改变的不是某一个任务的技巧,而是把很多视觉任务重写成“语义匹配问题”。
二、模型结构:Dual Encoder
CLIP 的结构其实并不复杂,但这个设计非常关键。
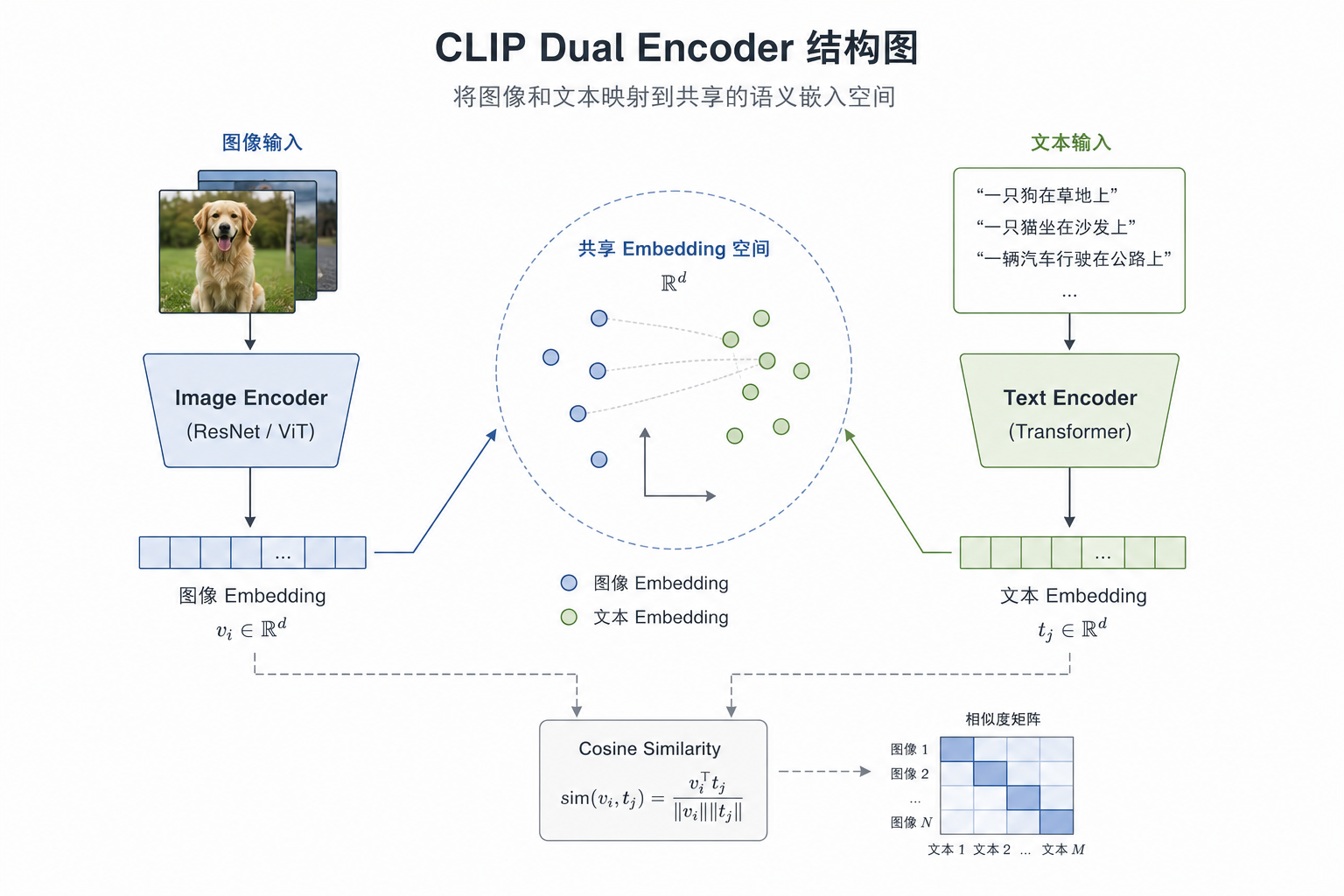
它使用两个独立的编码器:
- Image Encoder:处理图像,常见实现是 ResNet 或 ViT
- Text Encoder:处理文本,通常是 Transformer
2.1 表示方式
image -> image encoder -> embedding_i
text -> text encoder -> embedding_t
图像和文本先分别编码,再被投到同一个向量空间里。
2.2 相似度计算
similarity = cosine(embedding_i, embedding_t)
如果图像和文本表达的是同一个语义,它们的余弦相似度就应该更高。
2.3 这个结构为什么有效?
关键点在于:
图像和文本虽然来自不同模态,但最终被约束到同一个可比较的表示空间。
这意味着:
- 图像和图像可以比较
- 文本和文本可以比较
- 图像和文本也可以直接比较
这就是跨模态任务成立的基础。
更重要的是,CLIP 并没有强迫模型预测一个离散标签,而是让模型学习“什么样的视觉内容应该和什么样的语言表达靠近”。这比分类边界更灵活,也更接近真实世界里的知识组织方式。
三、训练方法:对比学习
CLIP 的能力,本质上是通过对比学习学出来的。
3.1 数据形式
训练数据是大量图文对:
(image_1, text_1), (image_2, text_2), ..., (image_N, text_N)
这些图文对通常来自互联网,文本不一定是严格标签,更像自然语言描述。
这件事很重要,因为自然语言比类别标签包含更多信息:
它不只说“这是什么”,还可能同时说“它是什么样、出现在什么场景、具有什么风格”。
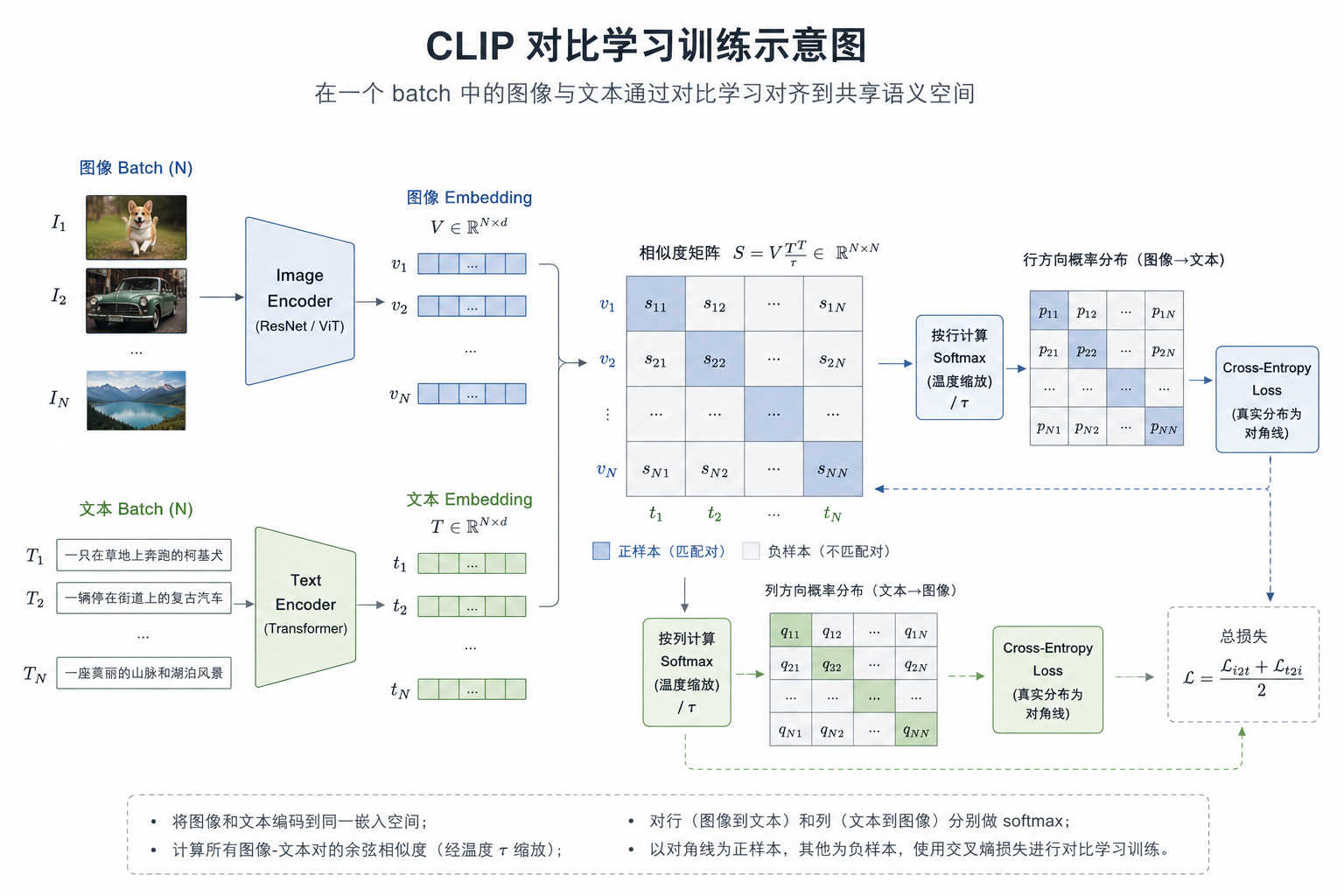
3.2 一个 batch 里发生了什么?
假设 batch size = N。
模型会先得到:
- N 个图像 embedding
- N 个文本 embedding
然后两两计算相似度,形成一个 N x N 的相似度矩阵。
对于其中一张图像来说:
- 和它配对的那条文本是正样本
- 其他
N - 1条文本都是负样本
对于一条文本来说也一样:
- 对应图像是正样本
- 其他图像是负样本
所以 CLIP 其实是双向训练的:
- image -> text 的匹配
- text -> image 的匹配
3.3 损失函数在做什么?
可以把它理解成一句话:
在一个 batch 里,让正确的图文对更接近,让错误的组合更远离。
常见写法是对相似度做 softmax,再用交叉熵约束正确配对的概率尽可能高。
loss = cross_entropy(softmax(similarity / temperature))
你不一定要记住公式,但最好记住它优化的方向:
不是学一个固定标签,而是学一个稳定的匹配结构。
3.4 temperature 是干嘛的?
temperature 可以理解为相似度分布的“锐利程度”:
- 小一些,模型会更挑剔,更强调最匹配的样本
- 大一些,分布会更平滑
它本质上影响的是“模型在多大程度上拉开正负样本之间的差距”。
四、为什么 CLIP 泛化能力强?
CLIP 强的地方不在结构本身,而在它的学习方式。
4.1 不再依赖固定标签
传统分类模型面对的是:
cat / dog / car
而 CLIP 面对的是:
"a photo of a cat"
"a futuristic flying car"
"a dog running on the beach"
类别不再是提前写死的编号,而是由语言动态定义的。
这意味着模型不是在背一个封闭答案集,而是在学习视觉内容和语言表达之间的对应关系。
4.2 语言本身提供了更丰富的语义
一句话往往不只包含类别,还包含:
- 属性
- 场景
- 动作
- 风格
- 关系
这让 CLIP 学到的表示更接近真实语义,而不是仅仅学到“某个像素模式对应某个标签”。
4.3 数据规模足够大
CLIP 使用的是大规模互联网图文对。
它的覆盖范围远大于传统分类数据集,这会带来两个后果:
- 模型接触到的视觉概念更多
- 模型看到的语言表达方式也更多
这种大规模弱监督并不完美,但它显著扩大了模型的知识边界。
小结
CLIP 学到的不是“类别边界”,而是“语义结构”。
也正因为这样,它才有能力作为后续生成模型的语义底座。
五、推理机制:Zero-shot 分类
CLIP 在推理时,不需要额外训练一个新的分类头。
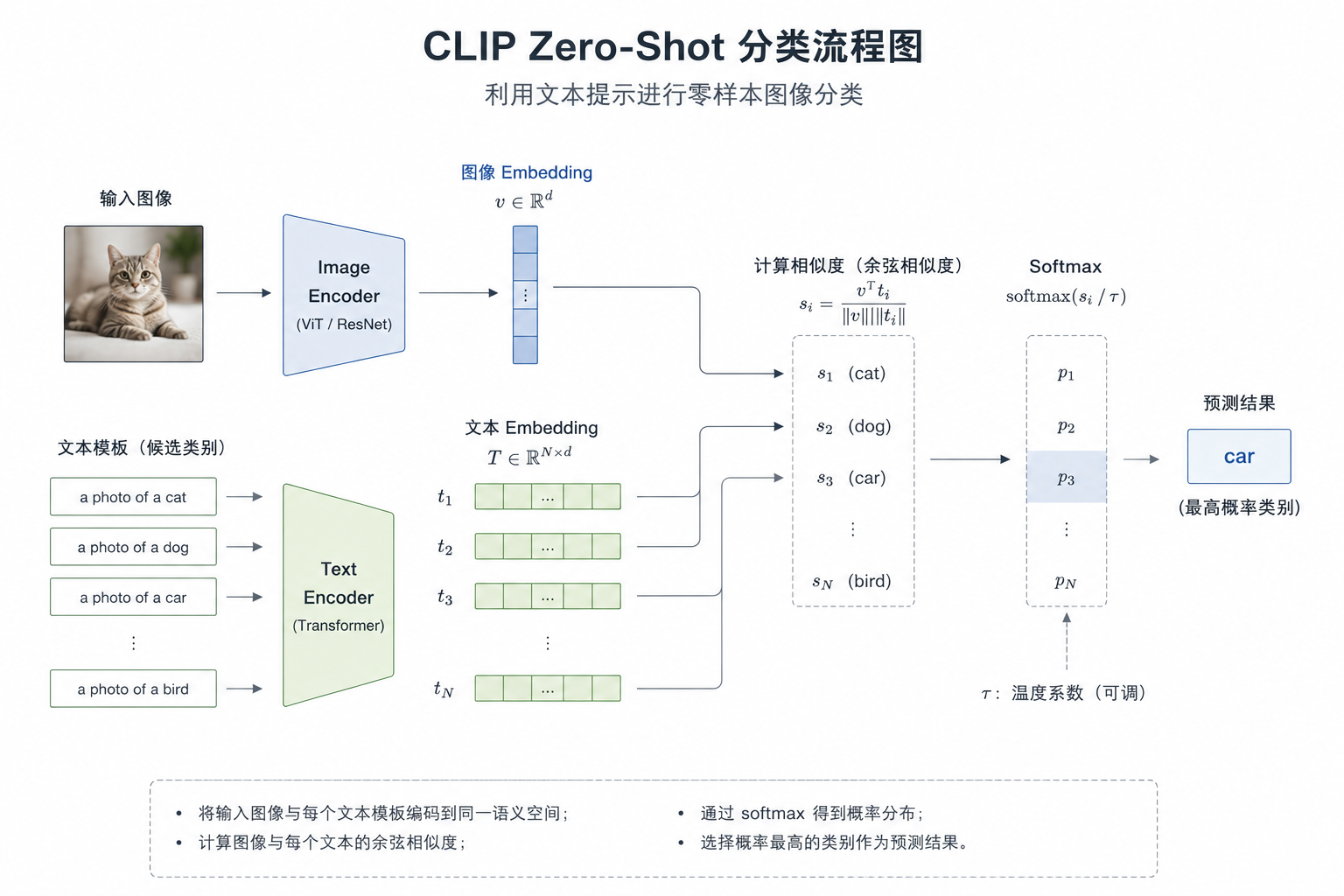
5.1 推理流程
假设我们要在这几个类别里做分类:
["cat", "dog", "car"]
先把它们写成自然语言模板:
"a photo of a cat"
"a photo of a dog"
"a photo of a car"
然后执行四步:
- 图像输入 image encoder,得到图像 embedding
- 文本输入 text encoder,得到文本 embedding
- 计算图像与每个文本之间的相似度
- 取相似度最高的那个类别
本质上,分类问题被重写成了匹配问题。
5.2 Prompt Engineering 为什么有用?
不同文本表达会影响结果,例如:
"a photo of a dog"
"a cartoon dog"
"a blurry dog"
这说明 CLIP 并不是在比对一个抽象标签,而是在比对一段具体语言描述。
常见做法有两个:
- 为同一个类别设计多个 prompt 模板,再做平均
- 使用更贴近数据分布的自然语言表述
这也是很多人第一次直观感受到“Prompt 会改变模型行为”的地方。
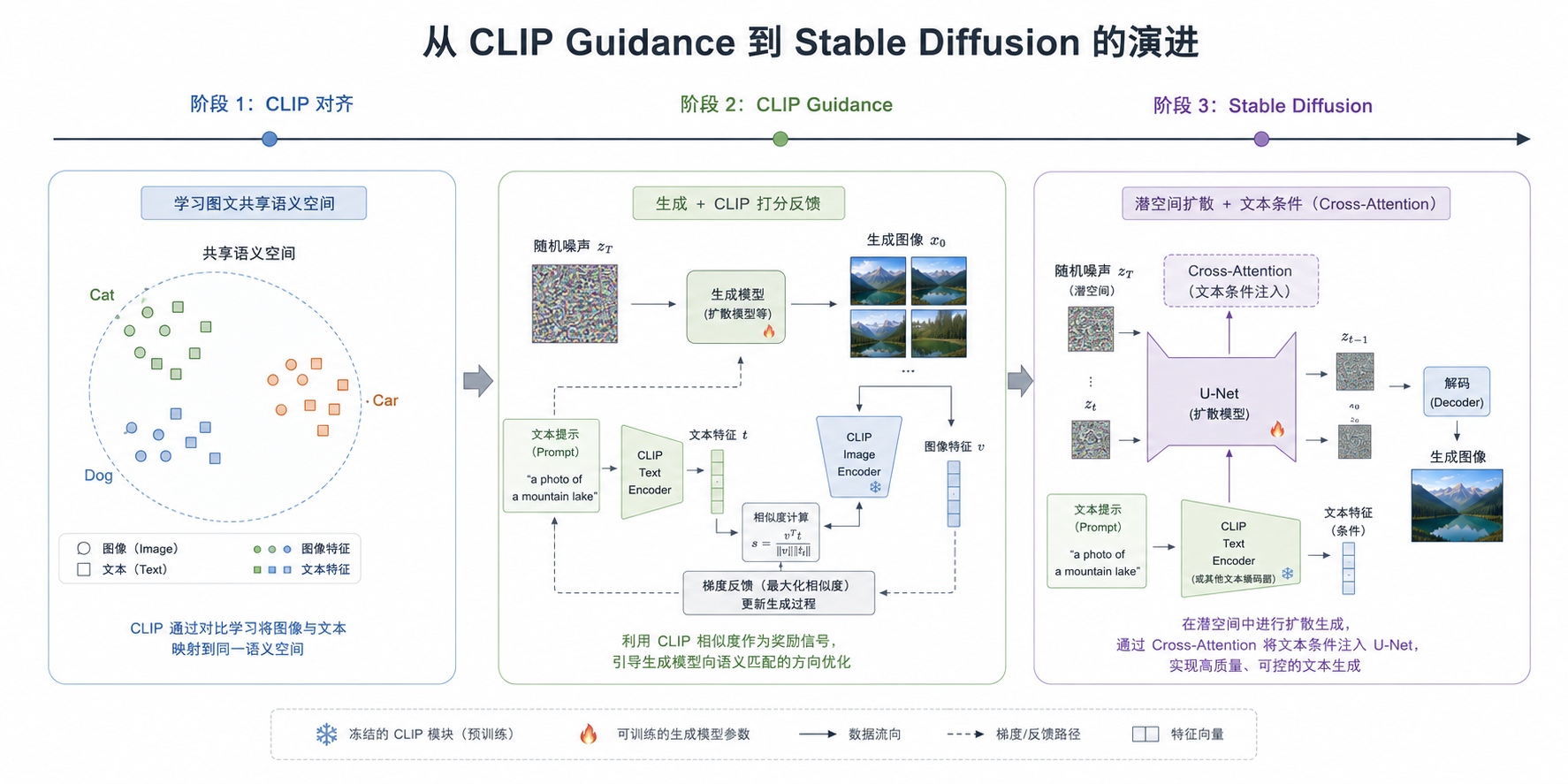
六、从 CLIP 到 Stable Diffusion
标题里这两个名字看起来属于不同世界:
- CLIP 更像理解模型
- Stable Diffusion 更像生成模型
但它们之间真正相连的,是“图文对齐”这件事。
6.1 早期阶段:CLIP 先做语义评分器
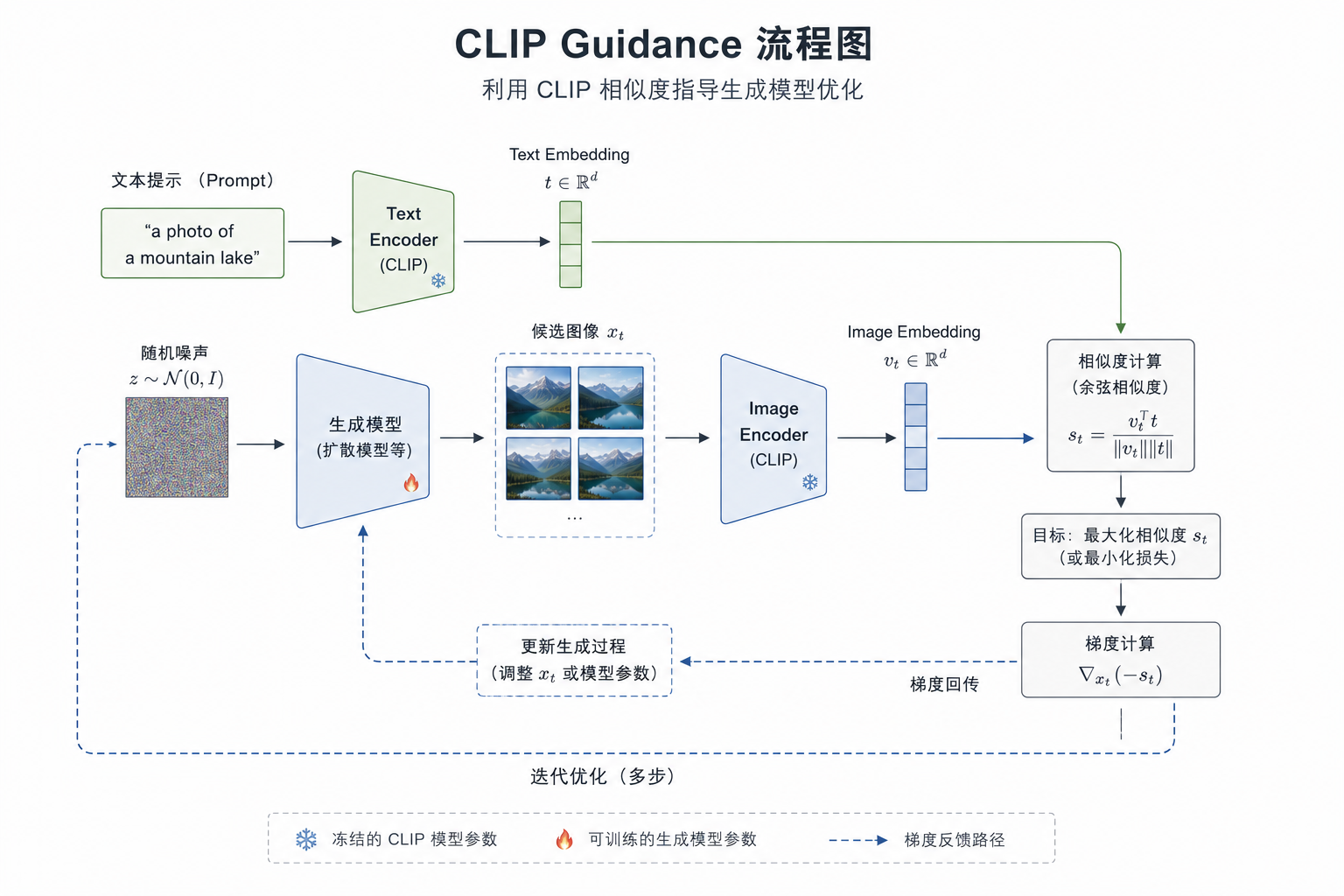
在早期图像生成方案里,CLIP 常被拿来做一个外部评估器。
思路很简单:
- 输入文本,得到 text embedding
- 生成模型从噪声出发生成一张候选图像
- 再用 CLIP 的图像编码器把这张图编码成 image embedding
- 计算图文相似度
- 根据这个分数反向调整图像
如果把生成模型看成画家,那 CLIP 更像评委:
- 分数高,说明图像更符合文本
- 分数低,说明图像还偏离语义目标
这类方法的代表性直觉就是:先会“评”,再去“引导生成”。
6.2 关键变化:从“外部打分”到“内部条件控制”
后来扩散模型逐渐走向成熟,核心变化不是“不要语义对齐了”,而是:
语义对齐能力不再作为外部打分器附加在生成之后,而是直接进入生成过程本身。
这一步很关键。
在 CLIP Guidance 里,图文对齐更像事后评分;
在后来的文本生成图像模型里,文本条件会直接参与每一步去噪。
也就是说,模型不是先画完再让 CLIP 纠正,而是在生成过程中一直带着语言条件前进。
6.3 到 Stable Diffusion,这件事是怎么落地的?
Stable Diffusion 的核心不是“把 CLIP 拿掉”,而是把图文对齐换成了更内生的使用方式。
一个简化后的理解框架是:
- 文本先经过一个预训练文本编码器,得到文本表示
- 图像不在像素空间直接生成,而是在 latent space 中逐步去噪
- U-Net 在每一步去噪时,通过 cross-attention 读取文本条件
- 最终生成结果逐步被拉向与文本一致的方向
如果说 CLIP Guidance 是:
先生成 -> 再评分 -> 再修正
那么 Stable Diffusion 更像:
带着文本条件,一边去噪,一边生成
这里最值得注意的一点是:
Stable Diffusion 依然依赖图文对齐能力,只是这种能力不再表现为一个独立的“外部裁判”,而是变成生成模型内部的条件接口。
在具体实现上,Stable Diffusion 系列通常会使用 CLIP / OpenCLIP 体系中的文本编码器来提供文本条件。也就是说,CLIP 带来的那套“语言可以作为视觉语义坐标”的思想,并没有消失,而是被嵌进了生成系统的骨架里。
6.4 为什么这一步会改变生成模型?
因为它让生成模型第一次真正具备了稳定的文本控制能力。
过去我们当然也能“根据类别生成图像”,但控制粒度很粗。
而图文对齐进入生成链路之后,控制信号变成了自然语言,模型可以开始理解:
- 对象是什么
- 处于什么场景
- 有什么属性
- 采用什么风格
这也是为什么从 CLIP 往后看,生成模型的发展不只是“画得更清楚”,而是“更能听懂人话”。
七、工程实践:CLIP 可以做什么
理解了上面的主线之后,再看 CLIP 的工程价值会更清楚。
7.1 图像检索
最直接的用法是图文检索:
text -> embedding
image -> embedding
similarity -> ranking
本质上就是“用一句话找图”,或者“给一张图找最像的描述”。
7.2 结果筛选与 rerank
在生成任务里,一个很实用的做法是:
- 先生成多张候选图
- 用 CLIP 给候选结果打分
- 选择与目标文本最接近的样本
这在多候选采样、自动评估、工作流筛选里都很常见。
7.3 数据集清洗与标注增强
CLIP 还可以用来做:
- 弱监督打标
- 图文一致性过滤
- 低成本语义检索
很多多模态流水线真正节省人力的地方,不是在“生成一张图”,而是在“组织和筛选大量图文数据”。
7.4 Workflow 理解
如果你的方向里包含流程理解、图像变化解释或自动化分析,CLIP 也很适合作为中间语义层:
- 判断前后两张图的语义变化
- 把视觉状态映射成文本描述
- 给复杂流程增加一个可比较、可检索的语义坐标
它未必直接完成最终任务,但很适合做跨模态流水线中的“理解模块”。
八、局限性
CLIP 很强,但它并不意味着“已经理解图像”。
8.1 组合关系理解仍然有限
例如这类描述:
"a red cube on a blue sphere"
模型可能认识“red”“cube”“blue”“sphere”,但对它们之间的精确关系未必稳定。
8.2 细粒度细节理解不足
CLIP 对以下问题往往不够稳:
- 精确计数
- 细小目标
- 严格空间关系
- 局部属性差异
它更擅长把握整体语义,而不是做像素级理解。
8.3 数据偏见无法回避
CLIP 的训练数据大量来自互联网,这会带来明显问题:
- 数据分布不均衡
- 文本描述噪声很大
- 可能继承互联网语料中的偏见
所以 CLIP 的强大,很大程度上来自规模;而它的问题,也同样部分来自规模。
九、总结
如果把全文压缩成一句话,那就是:
CLIP 的真正贡献,不只是做出了一个能 zero-shot 分类的模型,而是建立了一种“语言和图像可以在同一语义空间中对齐”的范式。
这件事后面产生了两层影响。
第一层影响在理解侧:
- 图像检索更自然了
- zero-shot 分类成为可能
- 视觉任务开始能直接借助语言泛化
第二层影响在生成侧:
- 早期可以把 CLIP 当作语义评分器
- 后来图文对齐能力被进一步内化进扩散模型
- 到 Stable Diffusion,语言已经不只是标签,而是生成过程中的持续控制信号
所以从 CLIP 到 Stable Diffusion,真正改变生成模型的,不只是架构升级,而是:
语言第一次稳定地成为了视觉生成过程中的一等控制变量。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)