构建高可靠企业级 RAG 系统:从 Naive RAG 到面向生成优化的防幻觉实践
在企业级大模型落地过程中,最大的瓶颈并非模型的推理能力,而是事实性谬误。
设想一个真实的业务灾难:客户询问“尊享版 Plus 会员能否退款?”,客服机器人基于 Naive RAG 检索到了一段关于“普通会员 7 天无理由退款”的文档片段,大模型凭借自身的“逻辑推理”,自行补全了“尊享版 Plus 会员也享受此权益”的回答,最终导致企业面临合规客诉。
这就是大语言模型(LLM)面对私有领域知识时产生的“幻觉”。RAG(检索增强生成)技术的引入,本质上是将 LLM 从“知识存储器”降级为“逻辑推理与语言组织引擎”,通过引入外部“非参数化知识”来锚定事实边界。然而,简单的“检索+拼接提示词”依然无法有效抑制幻觉。
本文将深入探讨如何从工程维度构建一个高准确性、低幻觉的 Advanced RAG 系统,重点解析面向检索与面向生成的联合优化策略。
背景介绍: RAG 本质是什么?
RAG = “先检索,再生成”。典型做法是:
- 有一堆外部知识(文档、知识库、数据库);
- 对用户问题先做检索,捞出最相关的若干片段;
- 把这些片段和问题一起丢给大模型,让它基于这些信息生成回答。
这样做的好处是:减少幻觉、让回答“有据可查”,并且可以低成本更新知识(只更新外部知识库,不用重新训练模型)。
一、 核心机制:RAG 如何重塑知识边界?
理解 RAG 防幻觉的底层逻辑,需要区分两类知识:
- 参数化知识:存在于模型权重中,类似于“闭卷考试时靠记忆背诵的知识”,易受训练数据截止时间和偏见影响。
- 非参数化知识:存在于外部向量库中,类似于“开卷考试时查阅的最新版说明书”,事实确切。
Naive RAG 的标准流程(索引 -> 检索 -> 增强 -> 生成)防幻觉的核心假设极其脆弱:它假设检索模块总能召回完美匹配的上下文,且 LLM 能严格遵循上下文的边界。 一旦检索出现噪音,LLM 就会像开卷考试时找错了书页,凭借自己的臆想强行作答。
因此,向 Advanced RAG 的演进,必须从“检索质量”和“生成约束”两个维度进行深度联合优化。其架构演进如下图所示:
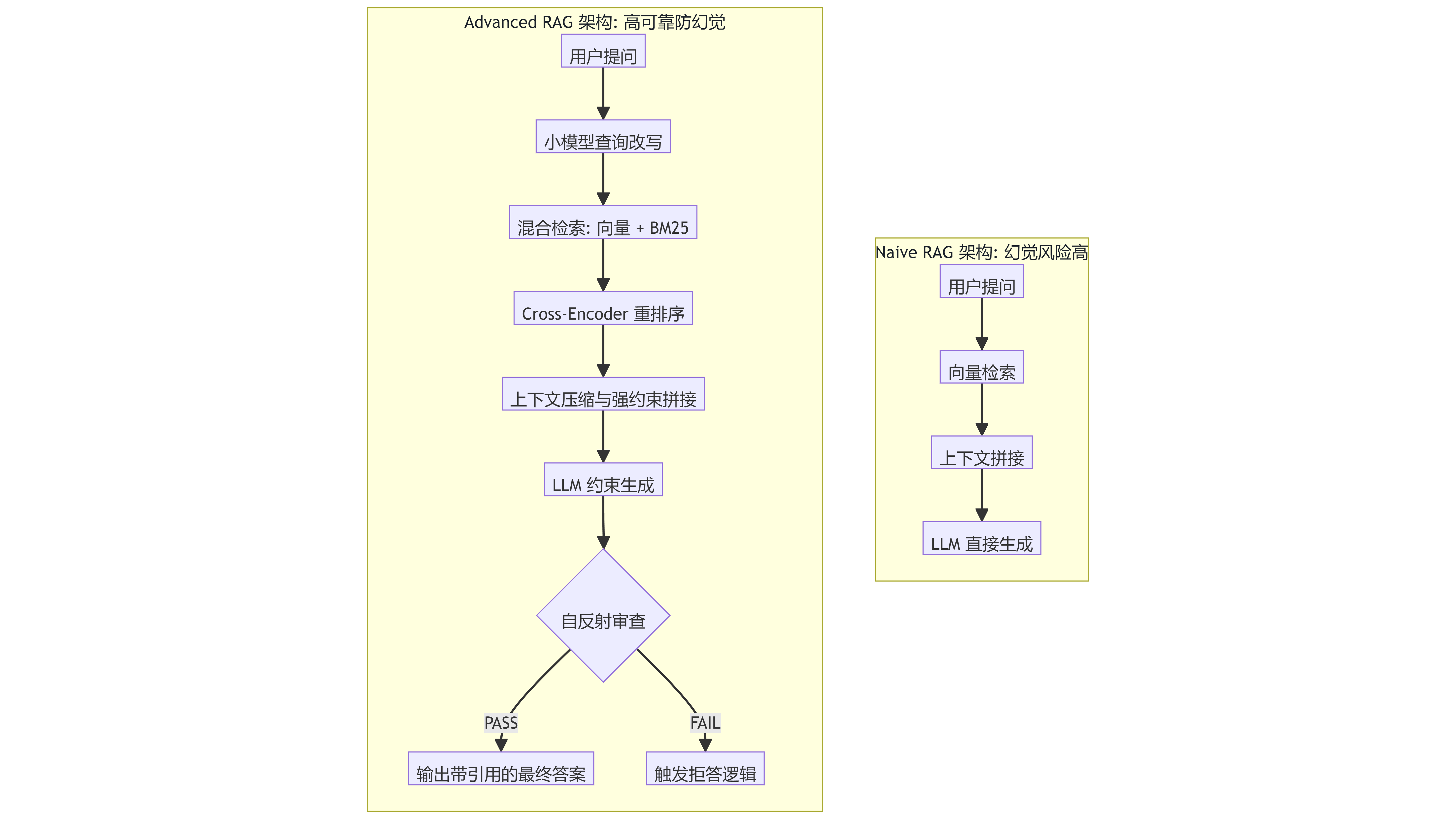
二、 面向生成优化的防幻觉工程实践
在上述 Advanced RAG 架构中,以下五个关键节点的优化,能够显著提升系统的事实准确性。
1. 从“物理切割”到“语义拓扑”的智能分块策略
传统固定长度分块(如每 512 Token 硬性截断)极易破坏语义完整性。
形象例子:
假设文档中有一句话:“*本合同在发生不可抗力因素导致的违约时,甲方不承担赔偿责任。*” 如果按固定字数正好在“违约时”切断,前一个 Chunk 变成了“*…不可抗力因素导致的违约时*”,后一个 Chunk 变成了“*甲方不承担赔偿责任*”。当用户问“不可抗力导致违约谁赔偿”时,检索到了前半个 Chunk,LLM 就会因为缺少主语而瞎猜。
工程解法: 采用基于语义相似度的动态分块。通过计算相邻句向量的余弦相似度,当语义发生突变(相似度低于设定阈值)时进行切分,保证每个 Chunk 具备完整的微观语义拓扑。
2. 混合检索与 Cross-Encoder 重排序(投入产出比最高)
单一向量检索(稠密检索)像“文科生”,擅长理解“意思相近”但记不住专有名词;BM25(稀疏检索)像“理科生”,死板但能精准匹配“X90型号”、“免责条款”等词。
工程解法:
- 多路召回:并行执行向量检索与 BM25 检索,取并集。
- 精排重排:引入 Cross-Encoder 架构。为什么它能防幻觉?看下面的对比图:
| 架构类型 | 工作原理 | 缺陷与幻觉风险 |
|---|---|---|
| Bi-Encoder (双塔) | Query 和 Chunk 分别独立算向量,算余弦相似度。 | 二者没有“交流”,可能只因为几个模糊的词就高分,导致错误 Chunk 进入 Prompt。 |
| Cross-Encoder (交叉塔) | 将 Query 和 Chunk 拼接成一个长文本,输入模型进行深度的注意力交叉计算。 | 精准捕捉细粒度逻辑关联,把似是而非的 Chunk 狠狠压低分数,是阻断错误上下文的最强防线。 |
3. 查询意图重构与小模型选型策略
用户的自然语言提问往往存在指代不清(如“那个漏水的事怎么处理”),直接用于检索会导致严重的语义鸿沟。
工程解法: 在检索前引入 Query Rewriting(查询改写)环节,先让小模型把问题“翻译”成标准的搜索词(如转换为“房屋质保期内漏水维修流程及赔偿政策”)。找得准,才能答得对。
关于执行改写的“小模型”选型与微调策略:
这是工程落地的关键决策点。通常不需要从头训练,推荐采取“零样本提示词优先,LoRA 微调兜底”的策略,具体决策路径如下:

4. 基于强约束的 System Prompt 设计
即便检索完全准确,LLM 仍可能因为“乐于助人”的倾向,用先验知识对答案进行过度润色。
形象例子: 就像一个法庭上的证人,他不仅陈述了自己看到的(文档内容),还加了一句“我推测他当时肯定是故意的”(模型推断)。在严肃的企业应用中,这种“推测”就是毒药。
工程解法: 实施“强制溯源与拒答机制”。以下为工业级验证过的 Prompt 模板结构:
【系统角色设定】
你是一个严谨的数据分析助手。你的唯一任务是依据【参考信息】回答用户问题。
【核心规则】(违反任何一条都将导致回答失败)
1. 绝对忠实原文:回答必须 100% 基于下方【参考信息】,严禁调用先验知识进行补充、推测或逻辑外推。
2. 强制引用:每一个事实陈述,必须在句尾以 [1]、[2] 标注来源编号。无依据的陈述禁止输出。
3. 坚决拒答:如果【参考信息】不包含回答该问题所需的信息,必须且只能回答:“抱歉,根据目前提供的资料,无法回答该问题。”
【参考信息】
[1] {chunk_1}
[2] {chunk_2}
【用户问题】
{query}
![]()
引用
此模板通过 [x] 标记将生成内容与物理文本强绑定,一旦出现幻觉,溯源验证即可轻易证伪,剥夺了模型“自由发挥”的空间。
5. 自反射机制
对于合规要求极高的场景(如医疗、法律),可引入类似“学术论文交叉盲审”的自反射审查机制。
工程解法: LLM 生成初版答案后,不直接返回,而是将其连同上下文输入给一个“审查者”。若审查者判定答案中存在无法被上下文完全覆盖的推断,则触发拒答逻辑。这是用额外的推理延迟换取极致的事实安全性。
三、 工程落地 ROI 评估与架构演进
在企业资源有限的情况下,优化措施应遵循严格的优先级排序。基于大量落地经验的 ROI 评估矩阵如下:
| 优先级 | 优化措施 | 防幻觉收益 | 工程成本/延迟损耗 | 核心价值 |
|---|---|---|---|---|
| P0 | 强约束 Prompt (含拒答) | 极高 | 极低 | 建立生成边界,立竿见影 |
| P0 | 混合检索 + 重排序 | 极高 | 中等(需部署Reranker) | 净化输入源,决定系统下限 |
| P1 | 语义分块 | 高 | 低 | 消除物理截断导致的语义畸变 |
| P2 | 小模型查询改写 | 中高 | 低(增加一次小模型推理) | 提升召回率,解决长尾查询 |
| P3 | 自反射 RAG | 中 | 高(延迟翻倍,Token消耗大) | 兜底防线,仅限极高风险场景 |
最小可行性防幻觉架构(MVP)定义:
如果需要在一周内交付一个高可靠系统,只需确保包含三个核心组件:基础分块(允许固定长度但必须设置重叠区) + 混合检索与重排 + 强约束 Prompt 模块。此 MVP 架构足以在绝大多数业务场景中将幻觉率压降至可接受阈值。
四、 生产环境验证指标与自查清单
系统上线前,不能仅凭主观感受,必须通过标准化测试集进行验证。请对照以下清单逐项核对:
- [ ] 噪音隔离度:文档解析阶段是否有效剥离了页眉、页脚、目录等非结构化噪音?
- [ ] 拒答触发率(核心指标):在测试集中注入一定比例的“库外问题”(文档中绝对不存在答案的问题),系统是否能做到 100% 拒答?(若出现编造,说明拒答 Prompt 存在逻辑漏洞)。
- [ ] 引用准确率:随机抽样答案中的引用标记
[x],验证其对应的原文是否存在且语义一致。(若出现“张冠李戴”的引用,通常是上下文过长导致注意力稀释,需缩减 Top-K 或优化分块)。 - [ ] 零推断验证:检查答案是否仅是对原文的同义改写或抽取,是否包含未经文档证实的“因此”、“说明”等连词引发的逻辑推导?
结语
构建高可靠 RAG 系统的核心哲学在于“悲观地对待模型能力,乐观地对待工程约束”。不要试图寻找一个“绝对不会幻觉”的大模型,而是要通过精密的检索链路(找得准)和严苛的指令工程(管得严),在物理层面上封死模型产生幻觉的通路。当系统真正做到了“知之为知之,不知为不知”,企业级 AI 的落地才算是迈过了最危险的深水区。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)